hive-概述与安装
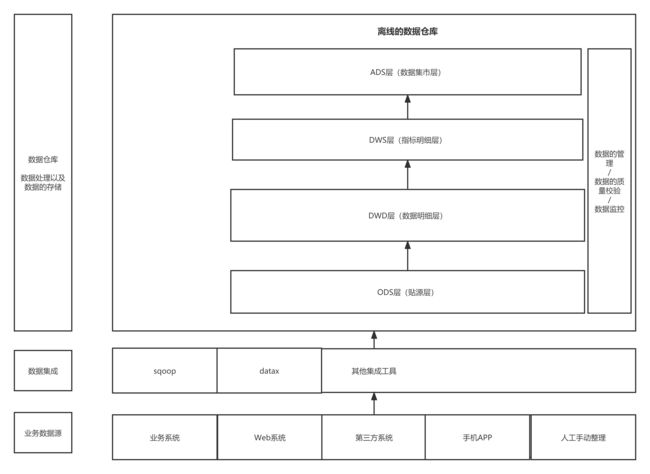
数据仓库架构(手绘,引出hive在其中的角色)
数据仓库层的划分:
2.1 什么是hive?(面试题)
1:hive是基于hadoop的数据仓库建模工具之一(后面还有TEZ,Spark)。
2:hive可以使用类sql方言,对存储在hdfs上的数据进行分析和管理。传入一条交互式sql在海量数据中查询分析结果的工具。
2.2 对于hive的理解
1、Hive是基于Hadoop的一个数据仓库工具,可以将 结构化的数据文件 映射为一张表(类似于RDBMS中的表),并提供类SQL查询功能;Hive是由Facebook开源,用于解决海量结构化日志的数据统计。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL ),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL ,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
2、Hive是SQL解析引擎,它将SQL语句转译成M/R Job然后在Hadoop的yarn上的执行。
3、Hive的表其实就是HDFS的目录,按表名把文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在M/R Job里使用这些数据。
4、Hive相当于hadoop的客户端工具,部署时不一定放在集群管理节点中,可以放在某个节点上。
可以将Hive理解为一个:将 SQL 转换为 MapReduce 任务的工具
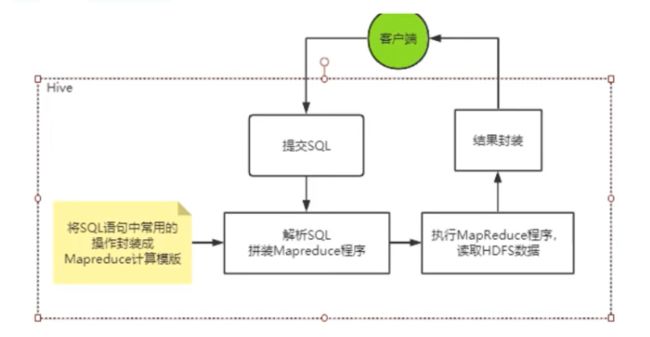
所以Hive不存储数据,自己也没有任何计算功能,只是相当于类SQL语句与Hadoop文件之间的一个解释器。他本质上只是一个对HDFS上的文件进行索引与计算的工具。他需要依赖Hadoop的Yarn来进行资源分配,也需要Hadoop的MapReduce来提供计算支持。后面我们就会知道,hive在进行数据计算时,不仅可以用MapReduce来支持,也可以集合其他更灵活,更高效的大数据计算框架(比如spark Spark SQL)
2.3 Hive的使用场景
从上面的理解介绍可以简单掌握Hive的特点:
优点:
1、使用SQL语法查询,不用再去写复杂的MapReduce程序,减少开发成版本,上手快。
2、基于MapReduce算法,所以在处理大数据时,优势非常明显
3、可以支持自定义函数,计算能力强
缺点:
1、Hive的执行延迟比较高,这是因为启动并运行一个MapReduce程序本身需要消耗非常多的资源
2、Hive的HQL语句表达能力有限,并且他是基于模板实现的,所以通常不够智能化,很多复杂的大数据计算无法支持,比如迭代式计算
3、Hive处理大数据量非常擅长,但是处理小数据量就没有优势了。
针对与优点和缺点总结:
所以,Hive通常适用于大数据的OLAP场景,做一些面向分析,允许有延迟的数据挖掘工作,并且结合其他组件也可以做一些数据清洗之类的简单数据处理工作。Hive是针对数据仓库来进行设计的,这种场景下,通常是读多写少。并且数据都是来自外部的HDFS,所以Hive中不建议做数据的修改操作,所有的数据最好是在加载的时候就已经确定好了。
2.4 Hive的整体架构
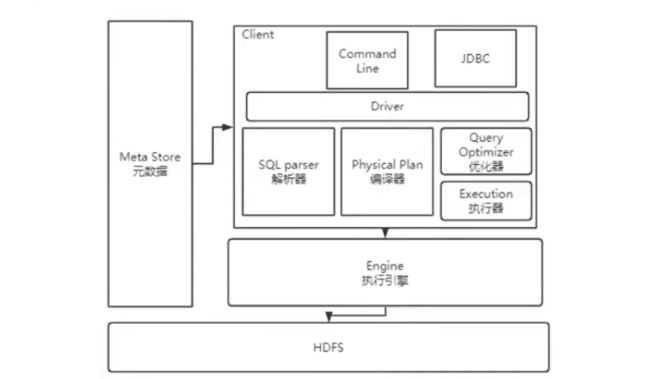
用户接口 CLI(Common Line Interface):Hive的命令行,用于接收HQL,并返回结果;JDBC/ODBC:是指Hive的java实现,与传统数据库JDBC类似;WebUI:是指可通过浏览器访问Hive。
Thrift Server:Hive可选组件,是一个软件框架服务,允许客户端使用包括Java、C++、Ruby和其他很多种语言,通过编程的方式远程访问Hive;
元数据管理(MetaStore) Hive将元数据存储在关系数据库中(如mysql、derby)。Hive的元数据包括:数据库名、表名及类型、字段名称及数据类型、数据所在位置等;
解释器 (SQLParser) :使用第三方工具(antlr)将HQL字符串转换成抽象语法树(AST);对AST进行语法分析,比如字段是否存在、SQL语义是否有误、表是否存在;
编译器 (Compiler) :将抽象语法树编译生成逻辑执行计划;
优化器 (Optimizer) :对逻辑执行计划进行优化,减少不必要的列、使用分区等;
执行器 (Executr) :把逻辑执行计划转换成可以运行的物理计划;
Hive通过CLI,JDBC/ODBC或HWI接受相关的Hive SQL查询,并通过Driver组件进行编译,分析优化,最后编程可执行的MapReduce任务。
2.5 Hive1.2.1安装
安装大致分为几大步骤:
- 将压缩包传到 linux 中,并解压
- 配置环境变量,配置各种配置文件
- 启动
版本介绍:
0.13和.14版本稳定版本,不支持但是不支持更新删除操作。
1.2.1和1.2.2 稳定版本,为Hive2版本(主流版本)
1.2.1的程序只能连接hive1.2.1 的hiveserver2java 1.8.0_171
hadoop 2.7.6
hive 1.2.1
mysql:5.7安装主要流程(详细见word文档)
安装MySQL服务
安装hive包,解压
修改配置文件,连接mysql,连接hadoop
启动
在之前博客中我有记录安装JDK和Hadoop和Mysql的过程,如果还没有安装,请先进行安装配置好。
(以上准备工作已经做好后=========================)
下面开始安装Hive
开始: 先启动Hadoop
将两个包使用Xftp拖至soft目录下

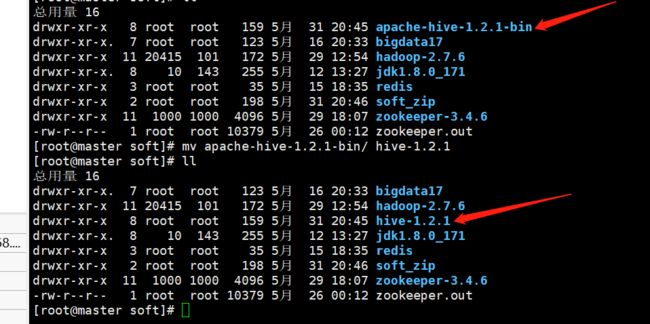
1、解压hive安装包
tar -zxvf apache-hive-1.2.1-bin.tar.gz
修改下目录名称
mv apache-hive-1.2.1-bin hive-1.2.1
2.配置环境变量
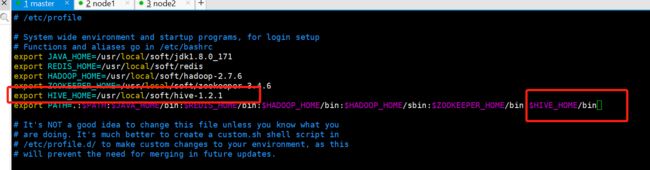
在配置完环境变量之后,必须要 source 一下,才能生效
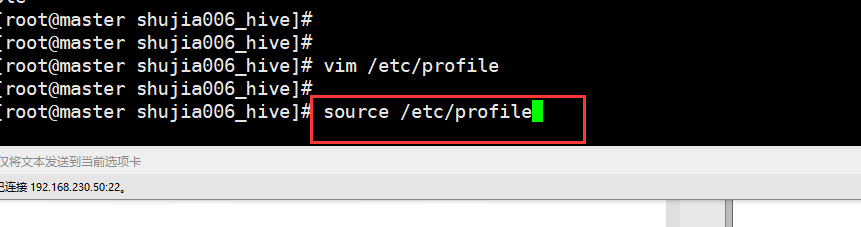
3、备份配置文件
cp hive-env.sh.template hive-env.sh
cp hive-default.xml.template hive-site.xml
3、修改配置hive的配置文件(在conf目录下)
3.1 修改hive-env,sh
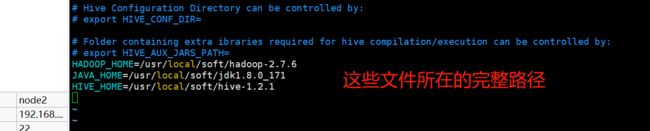
加入三行内容(大家根据自己的情况来添加,每个人安装路径可能有所不同)
HADOOP_HOME=/usr/local/soft/hadoop-2.6.0
JAVA_HOME=/usr/local/soft/jdk1.8.0_171
HIVE_HOME=/usr/local/soft/hive-1.2.1
3.2 修改hive-site.xml (找到对应的键对值进行修改,注意!!!是修改,而不是全部直接复制粘贴)
(注意:修改自己安装mysql的主机地址)
javax.jdo.option.ConnectionURL
jdbc:mysql://192.168.44.110:3306/hive?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=utf8&useSSL=false
JDBC connect string for a JDBC metastore

(固定)
指定数据库的驱动包
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
Driver class name for a JDBC metastore

(mysql的用户名)
javax.jdo.option.ConnectionUserName
root
Username to use against metastore database

(mysql的用户密码)
javax.jdo.option.ConnectionPassword
123456
password to use against metastore database

(你的hive安装目录的tmp目录)
hive.querylog.location
/usr/local/soft/hive-1.2.1/tmp
Location of Hive run time structured log file

(同上)
hive.exec.local.scratchdir
/usr/local/soft/hive-1.2.1/tmp
Local scratch space for Hive jobs

(同上)
hive.downloaded.resources.dir
/usr/local/soft/hive-1.2.1/tmp
Temporary local directory for added resources in the remote file system.

4、
拷贝mysql驱动到$HIVE_HOME/lib目录下
cp /usr/local/soft/mysql-connector-java-5.1.17.jar ../lib/
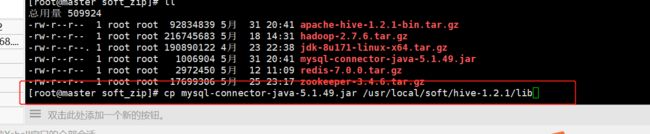
查看一下:存在;
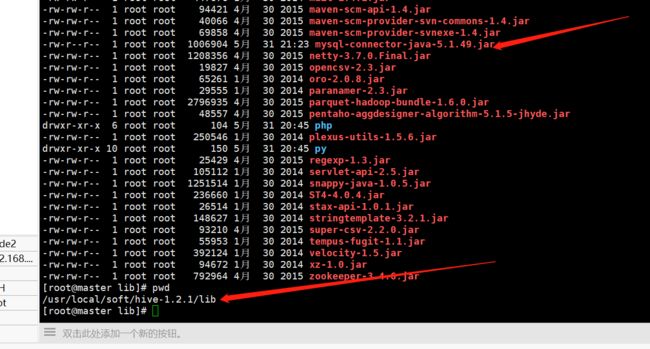
5、
将hadoop的jline-0.9.94.jar的jar替换成hive的版本。
hive的 jline-2.12.jar 位置在 /usr/local/soft/hive-1.2.1/lib/jline-2.12.jar
将Hadoop的删除
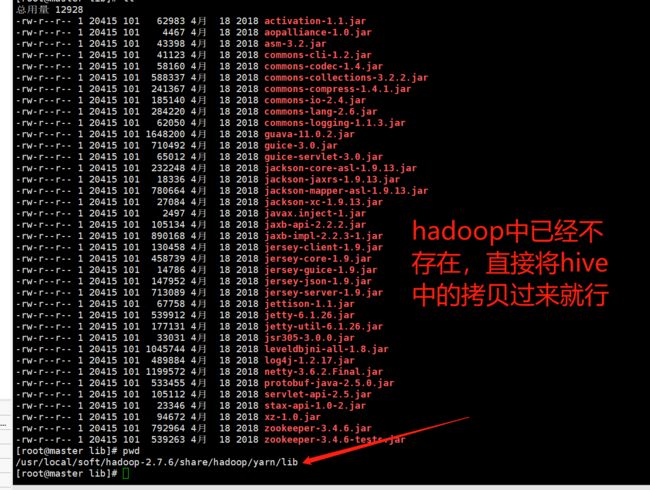
rm -rf /usr/local/soft/hadoop-2.6.0/share/hadoop/yarn/lib/jline-0.9.94.jar
然后将hive的jar拷过去hadoop下:
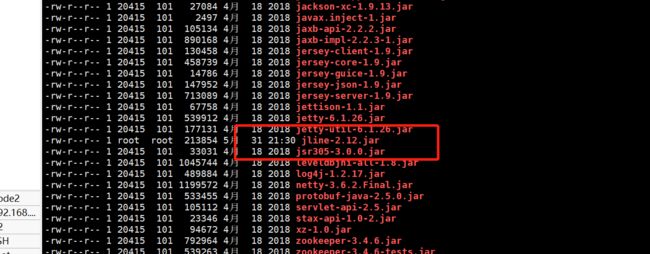
命令:
cp/usr/local/soft/hive-1.2.1/lib/jline-2.12.jar /usr/local/soft/hadoop-2.6.0/share/hadoop/yarn/lib/
最后启动Hive
命令: hive
