Spring Cloud Data Flow系列教程架构-2
架构
Spring Cloud Data Flow 简化了专注于数据处理用例的应用程序的开发和部署。
主要概念:
- 数据流的服务器组件。
- 服务器组件可以为流和批处理作业部署的应用程序类型。
- 已部署应用程序的微服务架构以及如何使用 DSL 进行定义。
- 部署它们的平台。
服务器组件
数据流有两个主要组件:
- 数据流服务器
- 船长服务器
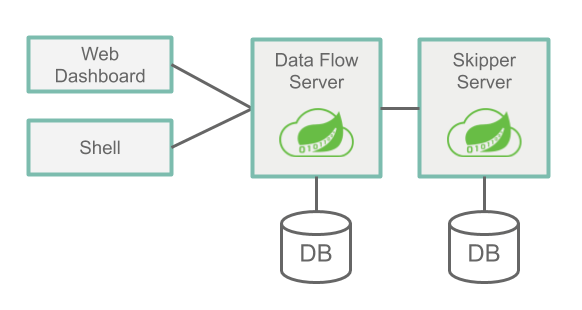
访问数据流的主要入口点是通过数据流服务器的 RESTful API。Web 仪表板由数据流服务器提供服务。Data Flow Server 和 Data Flow Shell 应用程序都通过 Web API 进行通信。
这些服务器可以在多个平台上运行:Cloud Foundry、Kubernetes 或您的本地计算机。每个服务器都将其状态存储在关系数据库中。
下图显示了架构和通信路径的高级视图:
数据流服务器
数据流服务器负责
- 基于域特定语言 (DSL) 解析流和批处理作业定义。
- 验证和持久化流、任务和批处理作业定义。
- 将 jar 和 Docker 映像等工件注册到 DSL 中使用的名称。
- 将批处理作业部署到一个或多个平台。
- 将作业调度委托给平台。
- 查询详细的任务和批处理作业执行历史。
- 将配置属性添加到配置消息输入和输出的流以及传递部署属性(例如初始实例数、内存要求和数据分区)。
- 将流部署委托给 Skipper。
- 审核操作(例如流创建、部署和取消部署以及批量创建、启动和删除)。
- 提供流和批处理作业 DSL 选项卡完成功能。
船长服务器
船长服务器负责:
- 将流部署到一个或多个平台。
- 使用基于状态机的蓝/绿更新策略在一个或多个平台上升级和回滚流。
- 存储每个流的清单文件的历史记录(代表已部署的应用程序的最终描述)。
数据库
Data Flow Server 和 Skipper Server 需要安装 RDBMS。默认情况下,服务器使用嵌入式 H2 数据库。您可以将服务器配置为使用外部数据库。支持的数据库有 H2、HSQLDB、MySQL、Oracle、Postgresql、DB2 和 SqlServer。每个服务器启动时都会自动创建模式。
安全
Data Flow 和 Skipper Server 可执行 jar 使用 OAuth 2.0 身份验证来保护相关的 REST 端点。您可以使用基本身份验证或使用 OAuth2 访问令牌来访问它们。对于 OAuth 提供程序,我们建议使用 CloudFoundry 用户帐户和身份验证 (UAA) 服务器,它还提供全面的 LDAP 支持。
默认情况下,REST 端点(管理、管理和运行状况)以及仪表板 UI 不需要经过身份验证的访问。
应用类型
应用程序有两种形式:
- 长期应用。有两种类型的长寿命应用程序:
- 消息驱动的应用程序,其中通过单个输入或输出(或两者)消耗或产生无限量的数据。
- 第二种是消息驱动的应用程序,可以有多个输入和输出。它也可能是一个根本不使用消息中间件的应用程序。
- 处理有限数据集然后终止的短期应用程序。短期应用程序有两种变体。
- 第一个是运行您的代码并在数据流数据库中记录执行状态的任务。它可以选择使用 Spring Cloud Task 框架,而不必是 Java 应用程序。但是,应用程序确实需要在 Data Flow 的数据库中记录其运行状态。
- 第二个是第一个的扩展,它包含 Spring Batch 框架作为执行批处理的基础。
基于 Spring Cloud Stream 框架编写长期应用程序和基于 Spring Cloud Task 或 Spring Batch 框架编写短期应用程序是很常见的。文档中有许多指南向您展示如何在开发数据管道时使用这些框架。但是,您也可以编写不使用 Spring 的长期和短期应用程序。它们也可以用其他编程语言编写。
根据运行时,您可以通过两种方式打包应用程序:
- 可以从 Maven 存储库、文件位置或通过 HTTP 访问的 Spring Boot uber-jar。
- 托管在 Docker 注册表中的 Docker 映像。
长期应用
长期应用程序预计将连续运行。如果应用程序停止,平台负责重新启动它。
Spring Cloud Stream 框架提供了一种编程模型来简化连接到通用消息系统的消息驱动微服务应用程序的编写。您可以编写与特定中间件无关的核心业务逻辑。要使用的中间件是通过将 Spring Cloud Stream Binder 库作为依赖项添加到应用程序来确定的。
数据流服务器委托给 Skipper 服务器来部署长期存在的应用程序。
带有源、处理器和接收器的流
Spring Cloud Stream 定义了绑定接口的概念,该接口在代码中封装了消息交换模式,即应用程序的输入和输出是什么。Spring Cloud Stream 提供了几个绑定接口,对应以下常见的消息交换合约:
Source:将消息发送到目的地的消息生产者。Sink:从目的地读取消息的消息消费者。Processor: 源和汇的组合。处理器使用来自目的地的消息并产生要发送到另一个目的地的消息。
这三种类型的应用程序通过使用source,processor和sink描述type正在注册的应用程序的 来向 Data Flow 注册。
以下示例显示了用于注册http源(侦听 HTTP 请求并将 HTTP 有效负载发送到目标log的应用程序)和接收器(从目标消费并记录接收到的消息的应用程序)的 shell 语法:
dataflow:>app register --name http --type source --uri maven://org.springframework.cloud.stream.app:http-source-rabbit:1.2.0.RELEASE
Successfully registered application 'source:http'
dataflow:>app register --name log --type sink --uri maven://org.springframework.cloud.stream.app:log-sink-rabbit:1.1.0.RELEASE
Successfully registered application 'sink:log'
使用Data Flowhttp并在其中log注册后,您可以使用 Stream Pipeline DSL 创建流定义,该 DSL 使用管道和过滤器语法,如以下示例所示:
dataflow:>stream create --name httpStream --definition "http | log"
管道符号http | log表示源输出到接收器输入的连接。数据流在部署流时设置适当的属性,以便source可以sink通过消息传递中间件进行通信。
具有多个输入和输出的流
源、汇和处理器都具有单一输出、单一输入或两者兼有。这使得 Data Flow 可以设置将输出目标与输入目标配对的应用程序属性。但是,消息处理应用程序可能有多个输入或输出目标。Spring Cloud Stream 通过让您定义自定义绑定接口来支持这一点。
定义包含具有多个输入的应用程序的数据流,则必须通过使用注册该应用程序app类型,而不是source,sink或processor类型。流定义使用流应用 DSL,它将单管道符号 ( |) 替换为双管道符号 ( ||)。将其||视为“并行”的意思,应用程序之间没有隐含的联系。
以下示例显示了一个虚构的orderStream:
dataflow:> stream create --definition "orderGeneratorApp || baristaApp || hotDrinkDeliveryApp || coldDrinkDeliveryApp" --name orderStream
当您使用|符号定义流时,Data Flow 可以将流中的每个应用程序配置为与其在 DSL 中的相邻应用程序通信,因为始终有一个输出与一个输入配对。使用该||符号时,您必须提供将多个输出和输入目标配对在一起的配置属性。
您还可以通过使用 Stream Application DSL 以及部署不使用消息传递中间件的应用程序来创建具有单个应用程序的流。
这些示例让您大致了解长期存在的应用程序类型。其他指南更详细地介绍了如何开发、测试和注册长期存在的应用程序以及如何部署它们。
下一个主要部分讨论已部署流的运行时架构。
短期应用
短期应用程序运行一段时间(通常是几分钟到几小时)然后终止。它们的运行可能基于计划(例如,每个工作日早上 6 点)或响应事件(例如,将文件放入 FTP 服务器)。
Spring Cloud Task 框架让您可以开发一个短暂的微服务,记录一个短暂的应用程序的生命周期事件(例如开始时间、结束时间和退出代码)。
任务应用程序通过使用名称task来描述应用程序的类型向数据流注册。
以下示例显示了用于注册timestamp任务(打印当前时间并退出的应用程序)的 shell 语法:
复制
dataflow:> app register --name timestamp --type task --uri maven://org.springframework.cloud.task.app:timestamp-task:2.1.0.RELEASE
任务定义是通过引用任务名称来创建的,如以下示例所示:
dataflow:> task create tsTask --definition "timestamp"
Spring Batch 框架可能是编写短期应用程序的 Spring 开发人员想到的。Spring Batch 提供了比 Spring Cloud Task 更丰富的功能集,建议在处理大量数据时使用。一个用例可能是读取许多 CSV 文件,转换每一行数据,并将每个转换后的行写入数据库。Spring Batch 提供了自己的数据库模式,其中包含关于 Spring Batch 作业执行的更丰富的信息集。Spring Cloud Task 与 Spring Batch 集成,因此,如果 Spring Cloud Task 应用程序定义了 Spring Batch 作业,则会创建 Spring Cloud Task 和 Spring Batch 运行表之间的链接。
使用 Spring Batch 的任务以与前面所示相同的方式注册和创建。
Spring Cloud Data Flow 服务器将任务启动到平台。
组合任务
Spring Cloud Data Flow 允许用户创建一个有向图,其中图的每个节点都是一个任务应用程序。
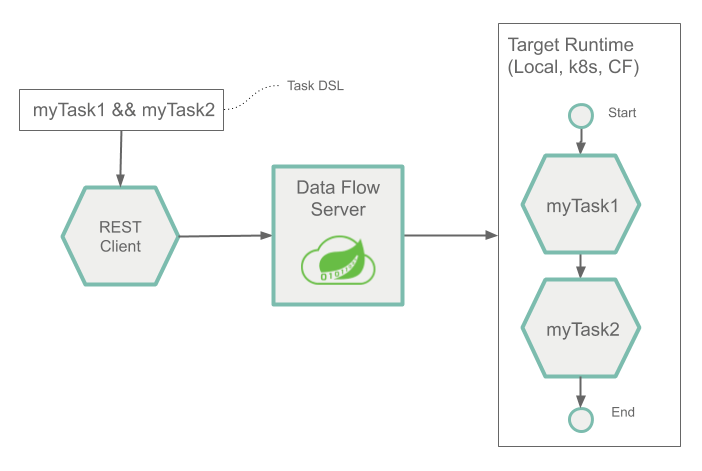
这是通过对组合任务使用组合任务域特定语言来完成的。Composed Task DSL 中有几个符号决定了整个流程。参考指南详细介绍。以下示例显示了如何使用双 & 符号 ( &&) 进行条件执行:
dataflow:> task create simpleComposedTask --definition "task1 && task2"
DSL 表达式 ( task1 && task2) 表示task2只有在task1成功运行时才启动。任务图通过名为Composed Task Runner的任务应用程序运行。
其他指南将更详细地介绍如何开发、测试和注册短期应用程序以及如何部署它们。
应用程序元数据
长期和短期应用程序可以提供有关支持的配置属性的元数据。Shell 和 UI 工具使用元数据在构建数据管道时提供上下文帮助和代码完成。
预建应用程序
为了启动您的开发,您可以使用许多预构建的应用程序来与常见的数据源和接收器集成。例如,您可以使用cassandra将数据写入 Cassandragroovy-transform的接收器和使用 Groovy 脚本转换传入数据的处理器。
安装说明展示了如何使用 Spring Cloud Data Flow 注册这些应用程序。
微服务架构风格
Data Flow 和 Skipper 服务器将流和组合的批处理作业作为微服务应用程序的集合部署到平台,每个微服务应用程序都在自己的进程中运行。每个微服务应用程序都可以相互独立地进行扩展或缩减,并且每个微服务应用程序都有自己的版本控制生命周期。Skipper 允许您在运行时独立升级或回滚流中的每个应用程序。
使用 Spring Cloud Stream 和 Spring Cloud Task 时,每个微服务应用程序都以 Spring Boot 作为基础库。这为所有微服务应用程序提供了功能,例如健康检查、安全性、可配置的日志记录、监控和管理功能,以及可执行的 JAR 打包。
需要强调的是,这些微服务应用程序“只是应用程序”,您可以通过使用java -jar和传入适当的配置属性来为自己运行它们。创建自己的用于数据处理的微服务应用程序类似于创建其他 Spring Boot 应用程序。您可以从使用 Spring Initializr 网站开始创建基于流或基于任务的微服务的基本脚手架。
除了将适当的应用程序属性传递给每个应用程序之外,数据流和 Skipper 服务器还负责准备目标平台的基础架构。例如,在 Cloud Foundry 中,它会将指定的服务绑定到应用程序。对于 Kubernetes,它将创建部署和服务资源。
数据流服务器有助于简化多个相关应用程序到目标运行时的部署,设置必要的输入和输出主题、分区和度量功能。但是,您也可以选择手动部署每个微服务应用程序,而根本不使用 Data Flow 或 Skipper。这种方法可能更适合从小规模部署开始,随着您开发更多应用程序逐渐采用数据流的便利性和一致性。手动部署基于流和任务的微服务也是一项有用的教育练习,可以帮助您更好地了解 Data Flow Server 提供的一些自动应用程序配置和平台定位步骤。流和批处理开发人员指南遵循这种方法。
与其他架构的比较
Spring Cloud Data Flow 的架构风格不同于其他流和批处理平台。例如,在 Apache Spark、Apache Flink 和 Google Cloud Dataflow 中,应用程序在专用的计算引擎集群上运行。与 Spring Cloud Data Flow 相比,计算引擎的性质为这些平台提供了更丰富的环境来对数据执行复杂的计算,但它引入了另一种执行环境的复杂性,而这在创建以数据为中心的应用程序时通常不需要。这并不意味着您在使用 Spring Cloud Data Flow 时无法进行实时数据计算。例如,您可以开发使用 Kafka Streams API 时间滑动窗口和移动平均功能以及将传入消息与参考数据集连接起来的应用程序。
这种方法的一个好处是我们可以在运行时委托给流行的平台。数据流可以受益于它们的功能集(弹性和可扩展性)以及您可能已经拥有的关于这些平台的知识,因为您可能会将它们用于其他目的。这减少了创建和管理以数据为中心的应用程序的认知距离,因为用于部署其他最终用户/Web 应用程序的许多相同技能都适用。
流
下图显示了一个简单流的运行时架构:
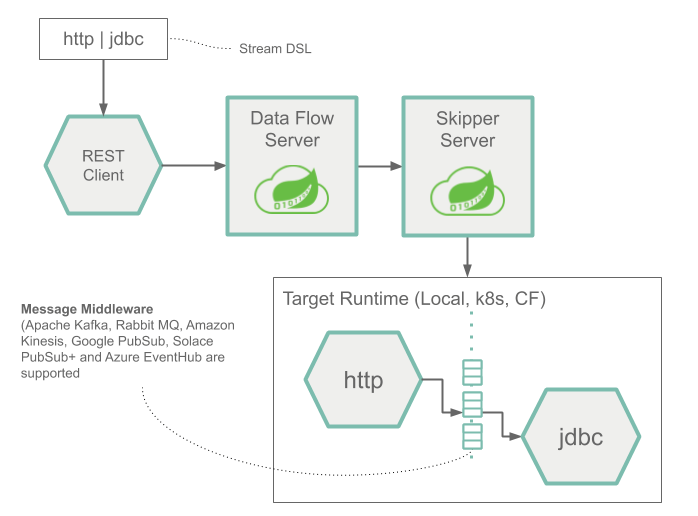
Stream DSL 由POST数据流服务器发送。基于 DSL 应用程序名称到 Maven 和 Docker 工件的映射,Skipper将http源和接收jdbc器应用程序部署到目标平台。然后将发布到 HTTP 应用程序的数据存储在数据库中。
该http源和jdbc汇的应用程序指定的平台上运行,并具有数据流或船长服务器连接。
下图显示了由可以具有多个输入和输出的应用程序组成的流的运行时架构:

在结构上,它是使用相同的时Source,Sink或Processor应用程序。定义此架构的 Stream Application DSL 使用双管道符号 ( ||) 而不是单管道 ( |) 符号。此外,当您部署此流时,您必须提供更多信息来描述如何使用消息传递系统将每个应用程序连接到另一个应用程序。
任务和批处理作业
下图显示了 Task 和 Spring Batch 作业的运行时架构:

组合任务
下图显示了组合任务的运行时架构:
平台
您可以在 Cloud Foundry、Kubernetes 和您的本地机器上部署 Spring Cloud Data Flow Server 和 Skipper Server。
您还可以将这些服务器部署的应用程序部署到多个平台:
- 本地:可以部署到本地机器、Cloud Foundry 或 Kubernetes。
- Cloud Foundry:可以部署到 Cloud Foundry 或 Kubernetes。
- Kubernetes:可以部署到 Kubernetes 或 Cloud Foundry。
最常见的架构是将数据流和 Skipper 服务器安装在部署应用程序的同一平台上。您还可以部署到多个 Cloud Foundry 组织、空间和基础以及多个 Kubernetes 集群。