java集合面试题总结
集合在我们的项目中,无论大小,都是必不可少的,所以面试的频率也挺高的,这里进行下总结。
java中集合间关系图:
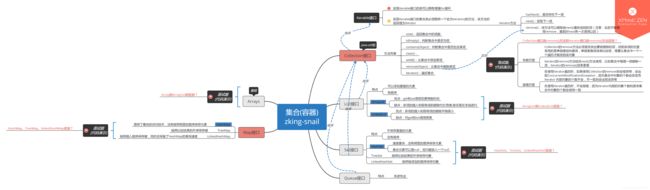
从图中可以看到Collection接口继承于Iterator接口(map系列的集合没有继承它),而list集合与set集合都继承于Collection接口,实现Iterator接口的类可以拥有增强for循环(即foreach循环),也必须提供一个名为iterator()的方法,方法返回值为iterator,所以list集合跟set集合都有foreach循环,而map集合没有。
Iterator核心的方法:
hasNext()(返回值为boolean):判断容器内是否还有可供访问的元素
next()(返回值为object):获取下一项 ,需要强制转换成自己需要的类型
remove()(无返回):删除迭代器刚越过的元素(即删除由next()最新返回的项)Collection方法列表:
size():返回集合中的项数
isEmpty():判断集合是否为空
contains(object):是否包含某项
add(E):添加某项
remove(object):删除某项
iterator():遍历集合
面试题1:Collection与iterator的remove方法的区别?
①性能方面
Collection的remove方法是有参的必须首先找出要被删除的项,找到该项的位置采用的是单链表结构查询,单链表查询效率比较低,需要从集合中一个一个遍历才能找到该对象;
collection的remove是每隔一行执行一次删除操作,意为着有的元素不会经过删除的操作.
例如:一个ArrayList,其包含的元素由[“1.001”,“1.002”,“1.003”], 写一个方法要求去除这个list中所有1.开头的String。用collection.remove进行移除,我们的初衷是删除会所有的, 结果会发现 1.002依然存在.
原因是:第一次遍历会把第0号元素"1.001"移除,于是"1.002"成为了第0位元素.再执行第二遍遍历时,collection操作认为第0号元素的遍历已经完成,就直接对第1号元素进行遍历,此时第1号元素是"1.003",就造成了"0.002"没有被遍历到.
Iterator的remove方法结合next()方法使用,比如集合中每隔一项删除一项,Iterator的remove()效率更高
②容错方面
在使用Iterator遍历时,如果使用Collection的remove则会报异常,会出现ConcurrentModificationException,因为集合中对象的个数会改变而Iterator内部对象的个数不会,不一致则会出现该异常。
在使用Iterator遍历时,不会报错,因为iterator内部的对象个数和原来集合中对象的个数会保持一致
结论:所有涉及到集合删除元素的操作时,使用迭代器去完成
List集合:有序,可以重复的集合,三个典型实现:
- List list1 = new ArrayList():底层数据结构是数组,查询快,增删慢;线程不安全,效率高
- List list2= new LinkedList():底层数据结构是链表,查询慢,增删快;线程不安全,效率高
- List list3 = new Vector():底层数据结构是数组,查询快,增删慢;线程安全,效率低,几乎已经淘汰了这个集合
面试题2:ArrayList和LinkedList的区别?
①存储结构不同:ArrayList是实现了基于动态数组的数据结构( 连续的存储结构),LinkedList基于链表的数据结构
②对于随机访问get和set(查询),ArrayList优于LinkedList
③对于新增和删除操作,LinkedList比较占优势
Arraylist是利用数组完成集合的,取值的时候是按存入数据的先后取值,先进先出,第一个存入他的下标为0,在0的基础上加值.
LinkedList利用堆栈完成集合,相比Arraylist,他的存储值是倒过来的,先进后出,第一个存入的最后一个输出。
面试题3:Array与ArrayList有什么区别?
①Array是Java中的数组,ArrayList是动态数组,也就是数组的复杂版本,它可以动态的添加和删除元素,被称为”集合“
②存储的数据类型:Array只能存储相同数据类型的数据,而ArrayList可以存储不同数据类型的数据
③长度的可变:Array的长度是固定的,而ArrayList的长度是可变的
面试题4:list与array的区别?
list是集合,array是数组,数组可以直接使用,list是接口,需要使用实现类,arraylist数组必须制定大小,list可以自己扩充大小。
面试题5:怎样将一个数组转成List,有什么方法?
数组转list,可以使用Arrays.asList(数组),例如:
String[] str={"test","aaa","bbb"};
List strings= Arrays.asList(str);
//注意:当数组转成list之后,list是不能执行add,remove等操作
//strings.add("ccc");//会报错
//如果想操作,则需要
List string2=new ArrayList(strings);
string2.add("ccc");
list转数组,使用list.toArray(),例如:
List strs=new ArrayList();
strs.add("aaa");
strs.add("bbb");
strs.add("ccc");
String[] strings=strs.toArray(new String[strs.size()]);
Set:无序,不重复元素(使用场景:去重复,对排序没有要求时,hibernate关系:一对多、多对多)
jdk1.7及以下:(实体类对象)无序,对象不能重复(每次排序不一样),integer,string等数据类型会按大小自动排序;
jdk1.8及以上:(实体类对象)无序,有特定的排序方式(散列排序(排一次)),对象不能重复,integer,string等数据类型会按大小自动排序,默认比较的内存地址,栈内存的地址不可以重复添加,重写父类的equals方法可消除重复的值;
HashSet:速度最块;没有明显的保存元素的顺序;不可重复;集合元素可以为 nullL,但只能放一个null;
TreeSet:有序、不可重复,必须放入同样类的对象(默认会进行排序)
LinkedHashSet:有序、先进先出、不可以重复,因为底层采用 链表 和 哈希表的算法。链表保证元素的添加顺序,哈希表保证元素的唯一性
面试题6:HashSet、TreeSet、LinkedHashSet的区别?
可以从集合的使用场合回答面试官
①需要速度快的集合,使用HashSet
②需要集合有排序功能,使用TreeSet
③需要按照插入的顺序存储集合,使用LinkedHashSet
jdk1.7及以下:Hashset是无序的,LinkedHashSet是怎么存怎么取,treeset有默认排序(comparable自然排序接口或comparator比较器接口)
jdk1.8及以上:Hashset和treese都是有序的,HashSet的排序方式是散列排序(自身特殊的排列方式);LinkedHashSet是怎么存怎么取,treeset有默认排序(comparable自然排序接口或comparator比较器接口)
共同点:1、都不允许元素重复
2、都不是线程安全的类
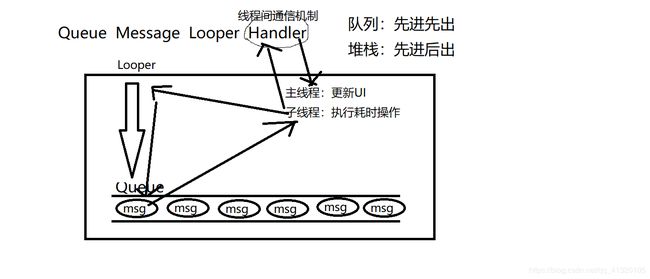
消息队列:
queue、message、looper、handler间的关系
Queue:队列
Message:消息
Looper:循环
Handler:处理
先进先出
数据
循环有序从queue里拿出manage
线程间通信机制,处理主线程与子线 程的关系:子线程拿数据,将消息传给 handler,handler再传给主线程
Map:key-value的键值对,key 不允许重复,value 可以
Map 集合没有继承于Collection 接口,也没有继承Iterable 接口,所以不能对 Map 集合进行 for-each 遍历。
子接口包括:HashMap、linkedMap与treeMap特点跟set的差不多
面试题7:HashMap、linkedMap与treeMap的区别(与HashSet、TreeSet、LinkedHashSet的区别一样)
可以从集合的使用场合回答面试官
①在Map中插入、删除和定位元素,HashMap是最好的选择
②需要集合有排序功能,使用TreeMap更好
③需要按照插入的顺序存储集合,使用LinkedHashMap
面试题8:HashMap和HashSet区别?
HashMap
HashSet
实现了Map接口
实现了Set接口
存储键值对
存储对象
调用put()向map中添加元素
调用add()向set中添加元素
HashMap相对于HashSet较快,因为它是使用唯一的键获取对象
HashSet较HashMap来说比较慢
HashMap使用key计算hashcode
HashSet使用成员对象计算hashcode
面试题9:List、Set、Map之间的区别?
List
Set
Map
可允许重复元素
不可允许重复元素
键值对存储,键必须唯一,值可以重复
可以插入多个null元素
只允许一个null元素
键只允许一个null,值可以允许有多个null
有序的容器,插入的顺序和输出的顺序一样
无序容器
无序容器
面试题10:如何将集合打乱?
使用Collections.shuffle(list)方法可将集合打乱,另反转集合中元素的顺序是使用reverse()方法
面试题11:如何使查询出来的结果是无序的?
-
可以将结果一次性查询出来然后set集合接收(适用于数据量较少的情况)
-
可以在SQL语句上下功夫,使每次查询的结果是无序的,如MySQL:
select * from tableName ORDER BY rand() limit 10;