Python pandas秘籍第一、二、三章笔记
关注微信公共号:小程在线

关注CSDN博客:程志伟的博客
关于使用到的数据、完成的python脚本会在微信公共上添加百度云链接
Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)]
Type "copyright", "credits" or "license" for more information.
IPython 7.12.0 -- An enhanced Interactive Python.
import pandas as pd
第一章
1.1 从 CSV 文件中读取数据
broken_df = pd.read_csv('bikes.csv')
broken_df[:3]
Traceback (most recent call last):
File "
broken_df = pd.read_csv('bikes.csv')
File "E:\anaconda3\lib\site-packages\pandas\io\parsers.py", line 676, in parser_f
return _read(filepath_or_buffer, kwds)
File "E:\anaconda3\lib\site-packages\pandas\io\parsers.py", line 448, in _read
parser = TextFileReader(fp_or_buf, **kwds)
File "E:\anaconda3\lib\site-packages\pandas\io\parsers.py", line 880, in __init__
self._make_engine(self.engine)
File "E:\anaconda3\lib\site-packages\pandas\io\parsers.py", line 1114, in _make_engine
self._engine = CParserWrapper(self.f, **self.options)
File "E:\anaconda3\lib\site-packages\pandas\io\parsers.py", line 1891, in __init__
self._reader = parsers.TextReader(src, **kwds)
File "pandas\_libs\parsers.pyx", line 529, in pandas._libs.parsers.TextReader.__cinit__
File "pandas\_libs\parsers.pyx", line 748, in pandas._libs.parsers.TextReader._get_header
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe9 in position 15: invalid continuation byte
将列分隔符改成 ;
将编码改为 latin1 ( 默认为 utf-8 )
解析 Date 列中的日期
告诉它我们的日期将日放在前面, 而不是月
将索引设置为 Date
fixed_df = pd.read_csv('bikes.csv', sep=';', encoding='latin1', parse_dates=['Date'], dayfirst=True, index_col='Date')
fixed_df[:3]
Out[3]:
Berri 1 ... St-Urbain (données non disponibles)
Date ...
2012-01-01 35 ... NaN
2012-01-02 83 ... NaN
2012-01-03 135 ... NaN
[3 rows x 9 columns]
1.2 选择一列
fixed_df['Berri 1']
Out[5]:
Date
2012-01-01 35
2012-01-02 83
2012-01-03 135
2012-01-04 144
2012-01-05 197
2012-11-01 2405
2012-11-02 1582
2012-11-03 844
2012-11-04 966
2012-11-05 2247
Name: Berri 1, Length: 310, dtype: int64
1.3 绘制一列
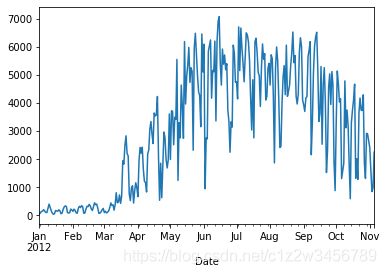
fixed_df['Berri 1'].plot()
Out[7]:
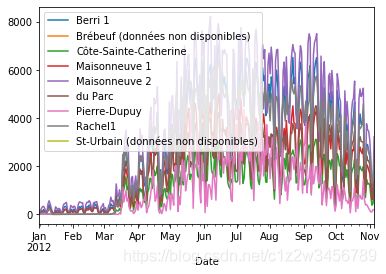
fixed_df.plot()
Out[8]:
第二章
import pandas as pd
complaints = pd.read_csv('311-service-requests.csv')
E:\anaconda3\lib\site-packages\IPython\core\interactiveshell.py:3063: DtypeWarning: Columns (8) have mixed types.Specify dtype option on import or set low_memory=False.
interactivity=interactivity, compiler=compiler, result=result)
查看一个大型数据框架, 而不是显示数据框架的内容, 它会显示一个摘要
complaints
Out[10]:
Unique Key ... Location
0 26589651 ... (40.70827532593202, -73.79160395779721)
1 26593698 ... (40.721040535628305, -73.90945306791765)
2 26594139 ... (40.84332975466513, -73.93914371913482)
3 26595721 ... (40.7780087446372, -73.98021349023975)
4 26590930 ... (40.80769092704951, -73.94738703491433)
... ... ...
111064 26426013 ... NaN
111065 26428083 ... (40.656160351546845, -73.76735262738222)
111066 26428987 ... (40.740295354643706, -73.97695165980414)
111067 26426115 ... (40.64018174662485, -73.95530566958138)
111068 26428033 ... (40.640024057399216, -73.90071711703163)
[111069 rows x 52 columns]
2.2 选择列和行
为了选择一列, 使用列名称作为索引, 像这样
complaints['Complaint Type']
Out[11]:
0 Noise - Street/Sidewalk
1 Illegal Parking
2 Noise - Commercial
3 Noise - Vehicle
4 Rodent
111064 Maintenance or Facility
111065 Illegal Parking
111066 Noise - Street/Sidewalk
111067 Noise - Commercial
111068 Blocked Driveway
Name: Complaint Type, Length: 111069, dtype: object
获得 DataFrame 的前 5 行
complaints[:5]
Out[12]:
Unique Key ... Location
0 26589651 ... (40.70827532593202, -73.79160395779721)
1 26593698 ... (40.721040535628305, -73.90945306791765)
2 26594139 ... (40.84332975466513, -73.93914371913482)
3 26595721 ... (40.7780087446372, -73.98021349023975)
4 26590930 ... (40.80769092704951, -73.94738703491433)
[5 rows x 52 columns]
complaints['Complaint Type'][:5]
Out[13]:
0 Noise - Street/Sidewalk
1 Illegal Parking
2 Noise - Commercial
3 Noise - Vehicle
4 Rodent
Name: Complaint Type, dtype: object
我们可以组合它们来获得一列的前五行
complaints[:5]['Complaint Type']
Out[14]:
0 Noise - Street/Sidewalk
1 Illegal Parking
2 Noise - Commercial
3 Noise - Vehicle
4 Rodent
Name: Complaint Type, dtype: object
2.3 选择多列
complaints[['Complaint Type', 'Borough']]
Out[15]:
Complaint Type Borough
0 Noise - Street/Sidewalk QUEENS
1 Illegal Parking QUEENS
2 Noise - Commercial MANHATTAN
3 Noise - Vehicle MANHATTAN
4 Rodent MANHATTAN
... ...
111064 Maintenance or Facility BROOKLYN
111065 Illegal Parking QUEENS
111066 Noise - Street/Sidewalk MANHATTAN
111067 Noise - Commercial BROOKLYN
111068 Blocked Driveway BROOKLYN
[111069 rows x 2 columns]
complaints[['Complaint Type', 'Borough']][:10]
Out[16]:
Complaint Type Borough
0 Noise - Street/Sidewalk QUEENS
1 Illegal Parking QUEENS
2 Noise - Commercial MANHATTAN
3 Noise - Vehicle MANHATTAN
4 Rodent MANHATTAN
5 Noise - Commercial QUEENS
6 Blocked Driveway QUEENS
7 Noise - Commercial QUEENS
8 Noise - Commercial MANHATTAN
9 Noise - Commercial BROOKLYN
调用 .value_counts() 方法:
complaints['Complaint Type'].value_counts()
Out[17]:
HEATING 14200
GENERAL CONSTRUCTION 7471
Street Light Condition 7117
DOF Literature Request 5797
PLUMBING 5373
Highway Sign - Damaged 1
Municipal Parking Facility 1
Snow 1
Trans Fat 1
Open Flame Permit 1
Name: Complaint Type, Length: 165, dtype: int64
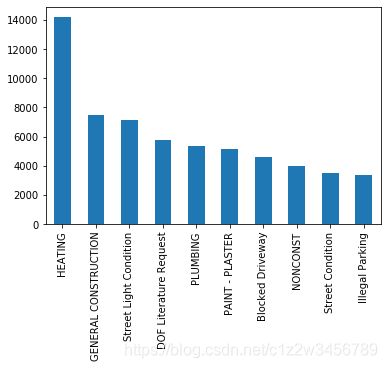
最常见的 10 个投诉类型
complaint_counts = complaints['Complaint Type'].value_counts()
complaint_counts[:10]
Out[18]:
HEATING 14200
GENERAL CONSTRUCTION 7471
Street Light Condition 7117
DOF Literature Request 5797
PLUMBING 5373
PAINT - PLASTER 5149
Blocked Driveway 4590
NONCONST 3998
Street Condition 3473
Illegal Parking 3343
Name: Complaint Type, dtype: int64
complaint_counts[:10].plot(kind='bar')
Out[19]:
第三章
3.1 仅仅选择噪音投诉
我想知道哪个区有最多的噪音投诉。 首先, 我们来看看数据, 看看它是什么样子:import pandas as pd
complaints = pd.read_csv('311-service-requests.csv')
E:\anaconda3\lib\site-packages\IPython\core\interactiveshell.py:3063: DtypeWarning: Columns (8) have mixed types.Specify dtype option on import or set low_memory=False.
interactivity=interactivity, compiler=compiler, result=result)
complaints[:5]
Out[2]:
Unique Key ... Location
0 26589651 ... (40.70827532593202, -73.79160395779721)
1 26593698 ... (40.721040535628305, -73.90945306791765)
2 26594139 ... (40.84332975466513, -73.93914371913482)
3 26595721 ... (40.7780087446372, -73.98021349023975)
4 26590930 ... (40.80769092704951, -73.94738703491433)
[5 rows x 52 columns]
为了得到噪音投诉, 我们需要找到 Complaint Type 列为 Noise -Street/Sidewalk 的行
noise_complaints = complaints[complaints['Complaint Type'] == "Noise - Street/Sidewalk"]
noise_complaints[:3]
Out[3]:
Unique Key ... Location
0 26589651 ... (40.70827532593202, -73.79160395779721)
16 26594086 ... (40.63618202176914, -74.1161500428337)
25 26591573 ... (40.55342078716953, -74.19674315017886)
[3 rows x 52 columns]
complaints['Complaint Type'] == "Noise - Street/Sidewalk"
Out[4]:
0 True
1 False
2 False
3 False
4 False
111064 False
111065 False
111066 True
111067 False
111068 False
Name: Complaint Type, Length: 111069, dtype: bool
is_noise = complaints['Complaint Type'] == "Noise - Street/Sidewalk"
in_brooklyn = complaints['Borough'] == "BROOKLYN"
complaints[is_noise & in_brooklyn][:5]
Out[5]:
Unique Key ... Location
31 26595564 ... (40.634103775951736, -73.91105541883589)
49 26595553 ... (40.6617931276793, -73.95993363978067)
109 26594653 ... (40.724599563793525, -73.95427134534344)
236 26591992 ... (40.63616876563881, -73.97245504682485)
370 26594167 ... (40.6429222774404, -73.97876175474585)
[5 rows x 52 columns]
哪个区的噪音投诉最多
is_noise = complaints['Complaint Type'] == "Noise - Street/Sidewalk"
noise_complaints = complaints[is_noise]
noise_complaints['Borough'].value_counts()
Out[10]:
MANHATTAN 917
BROOKLYN 456
BRONX 292
QUEENS 226
STATEN ISLAND 36
Unspecified 1
Name: Borough, dtype: int64
除以总投诉数量, 以使它有点更有意义
noise_complaint_counts = noise_complaints['Borough'].value_counts()
complaint_counts = complaints['Borough'].value_counts()
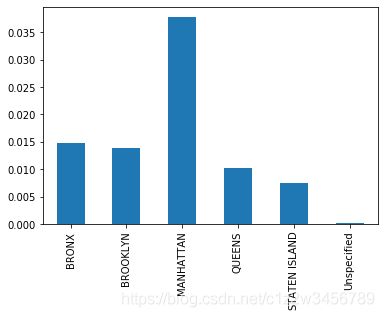
noise_complaint_counts / complaint_counts
Out[12]:
BRONX 0.014833
BROOKLYN 0.013864
MANHATTAN 0.037755
QUEENS 0.010143
STATEN ISLAND 0.007474
Unspecified 0.000141
Name: Borough, dtype: float64
(noise_complaint_counts / complaint_counts.astype(float)).plot(kind='bar')
Out[13]: