human evaluation-numericNLG
human evaluation-numericNLG
-
- case 1-1
- case 2-11
- case 3-12
- case 4-18
- case 5-19
- case 6-20
- case 7-27
- case 8-32
- case 9-36
- case 10-37
- case 11-44
- case 12-46
- case 13-50
- case 14-53
- case 15-62
- case 16-63
- case 17-64
- case 18-65
- case 19-66
- case 20-67
- case 21-70
- case 22-71
- case 23-75
- case 24-76
- case 25-77
- case 26-79
- case 27-80
- case 28-83
- case 29-85
- case 30-89
- case 31-93
- case 32-94
- case 33-95
- case 34-106
- case 35-108
- case 36-112
- case 37-116
- case 38-118
- case 39-130
- case 40-132
我们希望能够对每个模型的描述进行人工评测,分别从fluency(流利度)、coverage(覆盖性,侧重和gold的重合度)、relevance(对于表格内容是否真实的反应以及关联程度)、overal quality(整体印象的评分),分数从1-5分,1分最差,5分最好。
[0, 10, 11, 17, 18, 19, 26, 31, 35, 36, 43, 45, 49, 52, 61, 62, 63, 64, 65, 66, 69, 70, 74, 75, 76, 78, 79, 82, 84, 88, 92, 93, 94, 105, 107, 111, 115, 117, 129, 131]
case 1-1
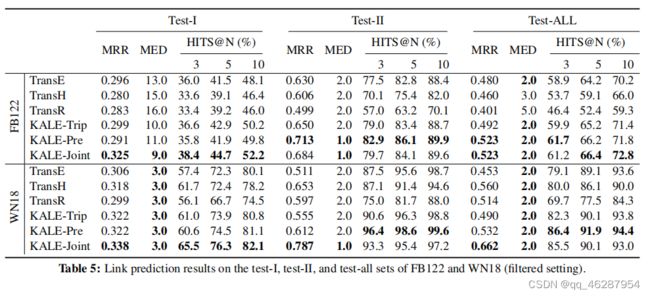
| link | https://www.aclweb.org/anthology/D16-1019.pdf-table_5 |
|---|---|
| gold | table 5 show the results in the filtered setting.on each dataset we report the metrics on three sets: test-i, test-ii, and the whole test set (denoted by test-all).from the results, we can see that in both settings: (i) kale-pre and kale-joint outperform (or at least perform as well as) the other methods which use triples alone on almost all the test sets, demonstrating the superiority of incorporating logical rules.(ii) on the test-i sets which contain triples beyond the scope of pure logical inference, kale-joint performs significantly better than kale-pre.on these sets kale-joint can still beat all the baselines by a significant margin in most cases, while kale-pre can hardly outperform kale-trip.(iii) on the test-ii sets which contain directly inferable triples, kale-pre can easily beat all the baselines (even kale-joint) |
| 1 | table 5 shows that our link-based models outperform all baselines on the test-i, test-ii, and test-all sets of fb122 and wn18. in addition, the extended models transe-trip and transhtrip achieve significant improvements against the original models in terms of hits@10 and hits@3 in all cases |
| 2 | table 5 shows the link prediction results on the test-i, test-ii, and test-all sets of fb122 and wn18. from the results, we can observe that: (1) kale-trip works better than its basic model, and it also outperforms its original method transr. (2) elmo achieves better performance than previous pathbased models like transe, transh, and konstrained inference |
case 2-11

| link | https://www.aclweb.org/anthology/D16-1220.pdf-table_3 |
|---|---|
| gold | finally, table 3 shows the effect of the different feature sets on vuamc used by klebanov et al. (2014).on this data, n features alone are significantly outperformed by b (p < 0.01).on the other hand, for the genres “academic” and “fiction”, combining n and b features improves classification performance over b, and the difference is always statistically significant.besides, the addition of n always leads to more balanced models, by compensating for the relatively lower precision of b |
| 1 | the cross-validation results on the vuamc dataset are shown in table 3. they show that our proposed n-gram attention model significantly outperforms all baselines, achieving the new state-of-the-art by a large margin. furthermore, with the nearest neighbor matching model, n achieves even better performance than b |
| 2 | table 3 shows the results on the vuamc dataset. our proposed model achieves significantly better performance than the state-of-the-art on both c and r, and comparable results on c. in addition, we find that the improvement on c is more significant than that on r, which indicates that our proposed method is more effective for detecting opinion words within a context. clearly, though different from n, our model achieves competitive performance for different dependency conversion conventions and tre |
case 3-12
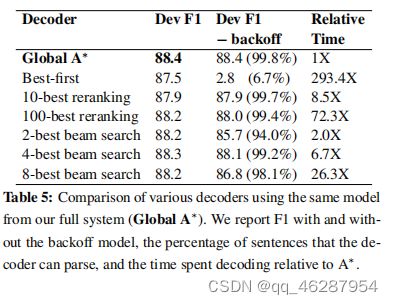
| link | https://www.aclweb.org/anthology/D16-1262.pdf-table_5 |
|---|---|
| gold | table 5 shows the f1 scores with and without the backoff model, the portion of the sentences that each decoder is able to parse, and the time spent decoding relative to the a* parser.results indicate that both approximate methods are less accurate and slower than a* |
| 1 | table 5 shows the development and test set f1 scores for various decoders using the same global system (global a∗). we report f1 with and without the backoff model, the percentage of sentences that the decoder can parse, and the decoding time relative to the predicted parse rate. our system achieves 88.4% in terms of f1 score, outperforming all but one decoder from david mccloskyfs thesis (mc |
| 2 | table 5 compares various decoders using the same model from our full system (global a∗). we report the performance of the decoder with and without the backoff model in both the dev and relative time. the relative time difference between the beam search and the reranking methods is close, possibly because the difference in query generation rate is so large (179.4x on an intel xeon cpu). backoff methods perform better than beam search on average, bu |
case 4-18
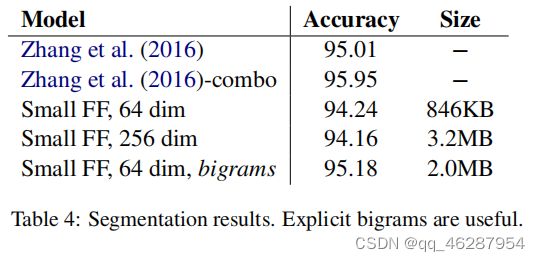
| link | https://www.aclweb.org/anthology/D17-1309.pdf-table_4 |
|---|---|
| gold | the results in table 4 show that spending our memory budget on small bigram embeddings is more effective than on larger character embeddings, in terms of both accuracy and model size.our model featuring bigrams runs at 110kb of text per second, or 39k tokens/second |
| 1 | table 4 shows the segmentation results. the results indicate that small data sizes are useful for zhang et al. (2016) as they achieved a small performance gain of 0.15% and up to 0.24% on accuracy and size metrics |
| 2 | the results in table 4 show that the explicit bigrams and small ff-dim models outperform the unsupervised approaches, and the results of zhang et al. (2016) are comparable with the performance of our model. we also compare them to other state-of-the-art segmentation methods reported in the literature. and we find that the model with no knowledge of syntax is more accurate and smaller data segmentation is more helpful |
case 5-19
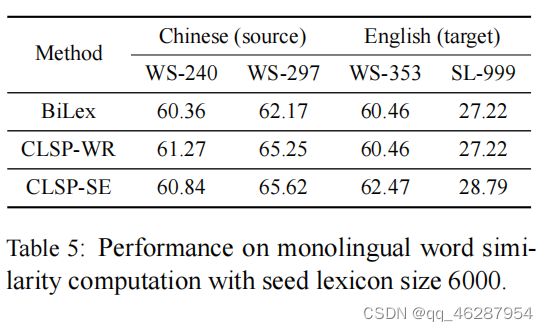
| link | https://www.aclweb.org/anthology/D18-1033.pdf-table_5 |
|---|---|
| gold | table 5 shows the results of monolingual word similarity computation on four datasets.from the table, we find that:.(1) our models perform better than bilex on both chinese word similarity datasets.(2) clsp-wr model does not enhance english word similarity results but clspse model does |
| 1 | table 5 shows the results of monolingual word similarity computation with seed lexicon size 6000. we can see that clsp-wr achieves the median accuracy of 60.46% compared to bilex, which indicates that clone-based methods are more effective than conventional word similarity methods |
| 2 | table 5 shows the results of monolingual word similarity computation with seed lexicon size 6000. we observe that clsp-se outperforms other models on all datasets except for ws-240 where the accuracy of bilex is slightly worse. |
case 6-20

| link | https://www.aclweb.org/anthology/D18-1049.pdf-table_4 |
|---|---|
| gold | table 4 shows that our model also outperforms transformer by 0.89 bleu points on french-english translation task |
| 1 | table 4 shows the performance of our system on the frenchenglish translation task. we compare our result with the transformer model (vaswani et al., 2017) on which our system is built. the evaluation metric is caseinsensitive bleu score. it shows that our transformer model can achieve a better performance than the transformer on this task, even without using any caseinear data |
| 2 | table 4 shows the comparison with transformer on the frenchenglish translation task. from the results, our method achieves a 35.40 bleu score. this is comparable to the transformer baseline, even if the case-insensitive embeddings are used |
case 7-27
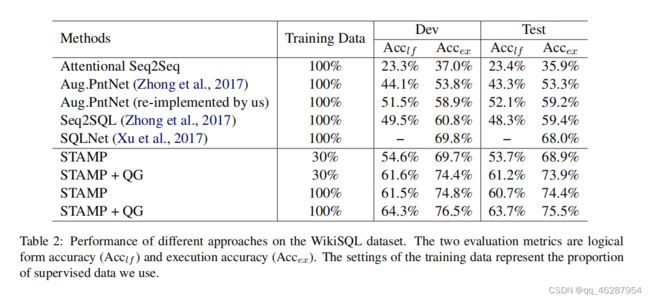
| link | https://www.aclweb.org/anthology/D18-1188.pdf-table_2 |
|---|---|
| gold | from table 2, we can see that stamp performs better than existing systems when trained on the full wikisql training dataset, achieving state-ofthe-art execution accuracy and logical form accuracy on wikisql.the second column “training data” in table 2 and the x-axis in figure 3 represent the proportion of wikisql training data we use for training the qg model and semantic parser.results show that qg empowers the stamp model to achieve the same accuracy on wikisql dataset with 30% of the training data.applying qg to the stamp model under the full setting brings further improvements, resulting in new state-of-the-art accuracies |
| 1 | table 2 shows the results of different approaches on the wikisql dataset. we can see that the best performance of the baselines is achieved by 100% of supervised data (acccex), which shows that our approach captures the semantic similarities of the input sentences better than the state-of-the-art approaches. although the accuracy of 100% is lower than 100% on the training data, the model achieves very competitive accuracy on this dataset given the small amount of training dat |
| 2 | from table 2 and figure 4, we can see that the logical form accuracy (acclf) is much lower than the explicit word embeddings (accex). the settings of the training data represent a good trade-off between the information coverage and the execution accuracy. we see that in the 100% to 100% setting, accex is about 2.5% lower than acclf, which indicates that the additional training data is helpful for improving the performance |
case 8-32
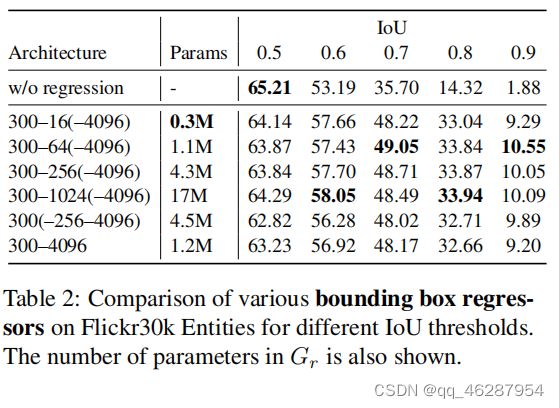
| link | https://www.aclweb.org/anthology/D18-1281.pdf-table_2 |
|---|---|
| gold | table 2 shows the results with and without regressor.the regressor significantly improved the accuracy with high iou thresholds, which demonstrates that the regressor improved the localization accuracy.in addition, the accuracy did not decrease as a result of sharing the hidden layer or reducing the number of units in the hidden layer.the number of parameters was significantly reduced by these tricks, to even fewer than in the linear transformation.the accuracy slightly decreased with a threshold of 0.5, because the regressor was not learned properly for the categories that did not frequently appear in the training data |
| 1 | table 2 shows that adding each component usually enhances the performance of the regression model. for example, the 300-64(-4096) baseline model only gives a 0.05% f-score increase compared to the baseline 300-4096 model (w/o regression) on flickr30k entities. adding the number of parameters in gr as described in section 3.2 does not help, since the parameters are likely to have different sizes across the four iou threshold |
| 2 | table 2 shows that, for various bounding box regressors, the performance of all models for different iou thresholds are similar across the three iou scores. in particular, we see that the 300-64(-4096) model performs best among all the bounding boxes. the performance deteriorates for the w/o regression model, while the improvements in accuracy are much more significant. we believe that this is due to the large increase in the number of parameters (ranging fro |
case 9-36
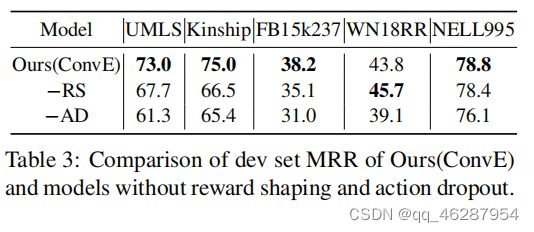
| link | https://www.aclweb.org/anthology/D18-1362.pdf-table_3 |
|---|---|
| gold | as shown in table 3, on most datasets, removing each component results in a significant performance drop.the exception is wn18rr, where removing the conve reward shaping module improves the performance.removing reward shaping on nell995 does not change the results significantly |
| 1 | table 3 shows the mrr results of different models without reward shaping and action dropout. the ablated version of our model shows that removing the kinship trait from the full model (conve) and replacing it with our reinforcement learning approach (ad) significantly decreases the performance gap between mrr and reward shaping, leading to stronger performance. we also observe that the word-level embeddings don’t work as well as the topiclevel ones, which i |
| 2 | table 3 shows the performance of our model and those models without the reward shaping and action dropout. our model (ours) significantly outperforms all baselines regarding all metrics, including fb15k237 and nell995. while the latter has a slightly lower mrr due to its more complex syntactic structure, it performs better compared to the other models. particularly, our model without reward shaping is able to achieve 75.0% in mrr, which is 3 |
case 10-37

| link | https://www.aclweb.org/anthology/D18-1363.pdf-table_3 |
|---|---|
| gold | table 3 shows that, for set3, four sources (column header"4") are generally better than two sources (“2”), which in turn are better than one source (“1”); thus, as expected, making additional sources available in training improves results |
| 1 | table 3 shows the best results of all the languages on 5 randomly selected languages with 1, 2, and 4 sources (“+pt”). we compare the results of our model with the state-of-the-art results in paradigm transduction (dutch 4, german 4, and spanish 1). our model significantly outperforms all the baselines both in terms of accuracy and of consistency. it also outperforms the best reported result (we |
| 2 | the results in table 3 show that med achieves the best results for all the languages from the “best” set of five randomly selected languages, together with paradigm transduction. for the languages with 1, 2, and 4 sources, med obtains better results than dutch, icelandic, and spanish. while the difference in accuracy between med and dutch is not statistically significant, the performance of each model is higher than that of welsh and icelan |
case 11-44
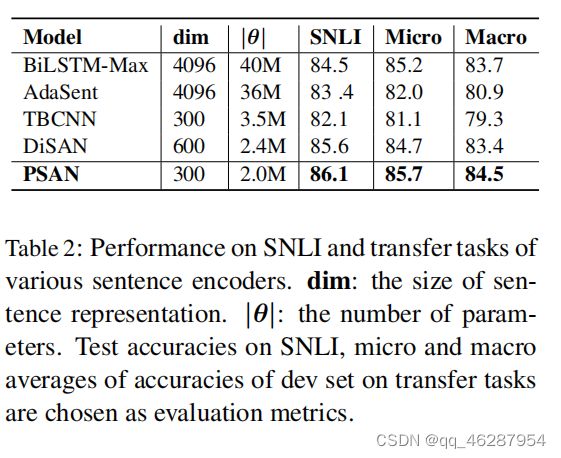
| link | https://www.aclweb.org/anthology/D18-1408.pdf-table_2 |
|---|---|
| gold | experiment results of our model and four baselines are shown in table 2.psan achieves the state-of-the-art performance with considerably fewer parameters, outperforming a rnn-based model, a cnn-based model, a fully attention-based model and a model that utilize syntactic information.especially when compared with previous best model bilstm-max, psan can outperform their model with only 5% of their parameter numbers, demonstrating the effectiveness of our model at extracting semantically important information from a sentence |
| 1 | table 2 shows the results. disan significantly outperforms the baselines on all three tasks, using a total of 3.7% (ws) and 3.9% (binary) improvement over the best baseline model, respectively |
| 2 | table 2 shows the results of various models on the development set. the adasent model achieves the best results on three tasks, followed by the psan model on the snli task. the models with no knowledge of syntax are able to recover a higher proportion of gold arcs.797 |
case 12-46
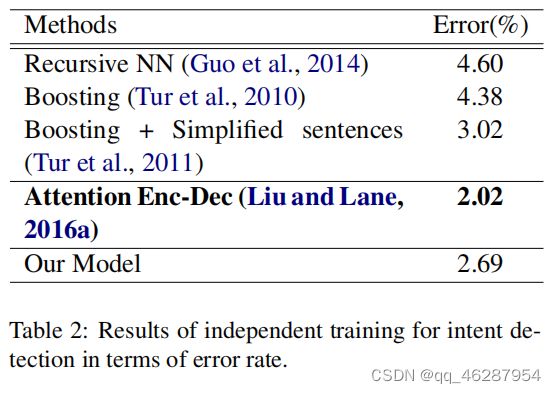
| link | https://www.aclweb.org/anthology/D18-1417.pdf-table_2 |
|---|---|
| gold | the results of separate training for slot filling and intent detection are reported in table 1 and table 2 respectively.table 2 compares the performance of our proposed model to previously reported results on intent detection task.our model gives good performance in terms of classification error rate, but not as good as attention encoder-decoder (with aligned inputs) method (liu and lane, 2016a) |
| 1 | table 2 shows the results of separate training for intent detection in terms of error rate. our model locates entities more accurately with a higher recall value (2.69%) than the comparing methods. it gives a reason why our model outperforms other state-of-the-art methods in recall value |
| 2 | table 2 shows the results of separate training for intent detection and intent detection in terms of error rate. our model achieves a 2.69% error reduction on the test set, which is significantly better than the baseline attention encoder-decoder model (liu and lane, 2016a) |
case 13-50

| link | https://www.aclweb.org/anthology/D18-1486.pdf-table_3 |
|---|---|
| gold | we simultaneously train our model mcapsnet on six tasks in table 1 and compare it with singletask scenario (table 3).as table 3 shows, mcapsnet also outperforms the state-of-the-art multi-task learning models by at least 1.1% |
| 1 | as table 3 shows, our multi-task network enhanced by mcapsnet 2 achieves the average improvements over the strongest baseline (bilstm) by 2.5% and 3.6% on sst-1, 2 and mr, respectively. furthermore, our model also outperforms the strong baseline mt-grnn by 3.3% on mr and subj, despite the simplicity of the model |
| 2 | as table 3 shows, our multi-task network enhanced by capsules is already a strong model. capsnet1 that has one kernel size obtains the best improvement on 2 out of 6 datasets, and gets competitive results on the others. and capsnet-2 with multiple kernel sizes further improves the performance and get best average improvements on 4 datasets. specifically, our capsule network outperforms conventional cnns like mt-grnn, mt-cnn, and mt-dnn wit |
case 14-53

| link | https://www.aclweb.org/anthology/D19-1068.pdf-table_3 |
|---|---|
| gold | table 3 shows the results.from the results, cl trans mlp, cl trans cnn, and cl trans hbrid behave poorly, as expected.cl trans self. yields relatively good performance.our syntactic order event detector yields the best performance |
| 1 | table 3 explores the impact of the shared syntactic order event detector. we find that cl_trans_hbrid outperforms all the other models in generating summaries with much higher precision (32.5% vs. 16.3%), recall (18.3%) and f1-score (27.8%) compared to the comparable results found by the monolingual sequence-to-event models |
| 2 | table 3 summarizes the results of our model and the baselines in exploring the shared syntactic order event detector. we observe that both the cl_trans_gcn and clertrans_cnn models outperform the baseline models in terms of all the evaluation metrics. the improvements in f1 measure are generally larger for the trans-gcn model, whereas in the case of the cnn model, the improvement is more significant. we also observe that the models with |
case 15-62
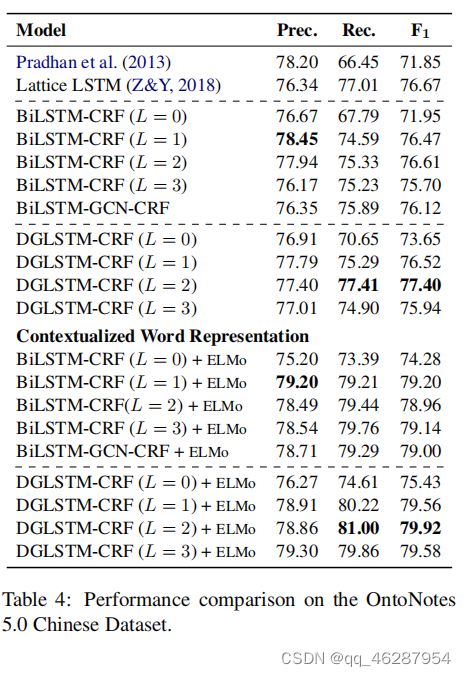
| link | https://www.aclweb.org/anthology/D19-1399.pdf-table_4 |
|---|---|
| gold | ontonotes chinese table 4 shows the performance comparison on the chinese datasets.similar to the english dataset, our model with l = 0 significantly improves the performance compared to the bilstm-crf (l = 0) model.our dglstm-crf model achieves the best performance with l = 2 and is consistently better (p < 0.02) than the strong bilstm-crf baselines. as we can see from the table, the improvements of the dglstm-crf model mainly come from recall (p < 0.001) compared to the bilstm model, especially in the scenario with word embeddings only.empirically, we also found that those correctly retrieved entities of the dglstm-crf (compared against the baseline) mostly correlate with the following dependency relations: “nn”, “nsubj”, “nummod”.however, dglstm-crf achieves lower precisions against bilstm-crf, which indicates that the dglstm-crf model makes more false-positive predictions |
| 1 | in table 4, we show the results of competitive baselines on the ontonotes 5.0 chinese dataset. although our method is not directly trained to make the final prediction, the performance of our model surpasses all baselines, which confirms that the breakdown charge-based analysis can indeed help the bilstm-crf model achieve better performance than other models |
| 2 | table 4 shows the results on the four language pairs in the chinese-to-english translation task. as can be seen, dglstm-crf outperforms all the baselines in 3 out of 4 settings, mainly because it considers the global structure of the sentences, which is 2.1 points higher than the previous best-performing model |
case 16-63

| link | https://www.aclweb.org/anthology/D19-1403.pdf-table_2 |
|---|---|
| gold | the proposed induction networks achieves a 85.63% accuracy, outperforming the existing state-of-the-art model, robusttc-fsl, by a notable 3% improvement |
| 1 | table 2 shows the results of our syntax-aware model on arsc. from the results, we can see that: 1) our model outperforms other models on mean accuracy by a large margin, and creates new state-of-the-art results by achieving an accuracy of 85.63% on the arsc test set. compared with the best previous model, our model obtains competitive results, which is the result of incorporating character-level word embeddings |
| 2 | table 2 shows the results. from the results, we can see that the proposed induction network significantly outperforms all previous baselines. it also outperforms the state-of-the-art graph network model (garcia and bruna, 2017) by a large margin |
case 17-64

| link | https://www.aclweb.org/anthology/D19-1450.pdf-table_2 |
|---|---|
| gold | the results from table 2 clearly confirm this.for example, without refinement, the mapping trained by the unsupervised gan method can only correctly predict 12% of the words from turkish to english.given that the quality of preliminary mappings can seriously affect the effect of refinement, the low-quality preliminary mappings for distant language pairs severely limits the improvements brought by post-refinement.notice that the method of lample et al. (2018) scores a null result for english to finnish on both bli-1 and bli2, indicating that totally unsupervised adversarial training can yields rather unpredictable results |
| 1 | table 2 presents the results of bilingual lexicon induction for similar and distant language pairs on the dataset bli-1. from the results, we can see that the proposed model is able to achieve the best result overall among all the methods. in particular, it-en achieves the highest accuracy and outperforms the previous best model, denoted as csls. the results indicate that language pairs learned from the muse method are very similar to those of the original muse and fr-e |
| 2 | table 2 shows the results of bilingual lexicon induction. our method outperforms all above models in both the supervised and unsupervised language pairs. it is shown in the table that our method also outperforms the supervised model in terms of bleu scores and the muse benchmark. for the bleu-recall, we achieve the best result overall and italics indicate that our model performs better than other models on the two columns without refinement |
case 18-65

| link | https://www.aclweb.org/anthology/D19-1491.pdf-table_1 |
|---|---|
| gold | table 1 shows that the seq model outperforms the current sota system on all three text genres for binary cwi (statistically significant using mcnemar’s test, p=0.0016, chi-square=9.95) |
| 1 | the results presented in table 1 show that the seq system outperforms the camb system on cwi on all three genres on the task of binary complex word identification. the largest performance increase for words is on the wikipedia test set (+3.68%). table 1 also shows that on the combined set of words and phrases (words+phrases) the two systems achieve similar results: the seq model beats the camber model only marginally, with the largest difference of + |
| 2 | table 1 shows the results on the cwi dataset. the seq system outperforms the camb system, with the largest difference of +14.14% on f-score. comparing seq and camb systems, we can see that the seq model always improves the performance of camb, even when the dataset is relatively simple (e.g., wikinews). furthermore, wikipedia seq, which is more complex (the system must predict multiple labels per token, includin |
case 19-66

| link | https://www.aclweb.org/anthology/D19-1497.pdf-table_3 |
|---|---|
| gold | table 3 presents the performance of different methods on citation count prediction.we can make the following observations.first, the four traditional baselines (lr, knn, svr and gbrt) perform worse than the two deep learning baselines (w&d, milam).second, milam performs consistently better than w&d, since it has designed a more elaborate architecture to model the review text.finally, our model outperforms all the baselines with a substantial margin, especially for the iclr dataset |
| 1 | table 3 presents the results of different methods for citation count prediction. we can see that our proposed model can achieve the better performance than all the baselines. it indicates that our approach can better extract and model effective features. besides, the results also indicate that our method is able to achieve higher ranking than the state-of-the-art methods |
| 2 | table 3 shows the results of our model as compared with different methods. we can see that our model outperforms all of the baselines regarding all metrics, and is comparable with the state-of-the-art result on tac ae-237 (tai et al., 2017). for example, our model with deep relevance ranking (t) outperforms the milam and the neural network based methods by 9.49% and 10.38% in terms of |
case 20-67

| link | https://www.aclweb.org/anthology/D19-1507.pdf-table_1 |
|---|---|
| gold | we performed comprehensive experiments to analyze the performance of query auto-completion.table 1 shows the generation result of mpc, the character baseline, and our model variants.for bpe models, we varied the maximum retrace step to 0 (without retrace algorithm), 1, 2, and ∞ (no limitation on retracing step size).for sr models, we compare decoding results without any techniques, with marginalization only, with retrace algorithm only, and with both.mpc is a very fast and remarkably strong baseline.it is worse than language models in the overall score (mrr, pmrr, and mrl), but better for previously seen queries.mrrs and pmrrs of our best methods are close to that of the character model with less than 0.02 point drop.notably, the sr model has better generalization ability in that their pmrr for unseen queries is higher than that of the character model |
| 1 | table 1 shows the results of completion generation. we group mpc, character language model baseline, and two subword language models separately. we observe that mpcmrr and mpc decode clearly outperform the sequence-to-action-sequence model of bpe+r1 (lample et al., 2016) in all results. the higher the model size, the better performance is achieved. we also observe that the final row of table 1 is the most informative for completin |
| 2 | table 1 shows the results of reranking with approximate marginalization. the higher the qps, the better results for each column related to accuracy are shown in bold for each segmentation algorithm (bpe and sr). sr model shows higher unseen pmrr scores (underlined). our models are faster than the character baseline. qps shows an improvement of about 2.2% over the mpc model, and over the character-based model |
case 21-70
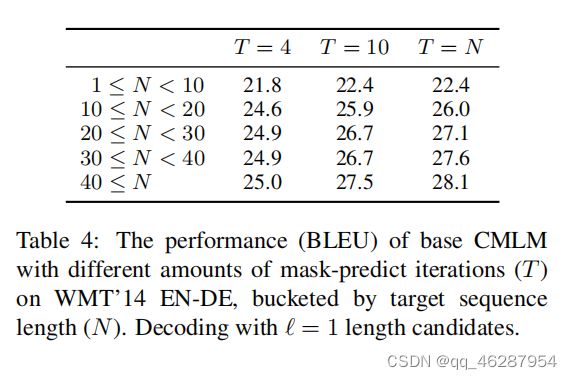
| link | https://www.aclweb.org/anthology/D19-1633.pdf-table_4 |
|---|---|
| gold | table 4 shows that increasing the number of decoding iterations (t) appears to mainly improve the performance on longer sequences.having said that, the performance differences across length buckets are not very large, and it seems that even 4 mask-predict iterations are enough to produce decent translations for long sequences (40 ? n) |
| 1 | table 4 shows that, when limiting the amount of parameters to a log of 10, the performance did not degrade. in fact, the model performed significantly better on wmt’14 en-de, bucketing by target sequence length (n). the importance of character-level information clearly shows in table 4: the number of parameters of the cmlm model is larger than that of the baseline. the model also performs better when using all available parameters, showing that there i |
| 2 | table 4 shows the results for the best performing model with different amounts of mask-predict iterations on wmt’14 en-de. the bucketed model outperforms the base cmlm by a large margin (p < 0.5), unsurprising given the near-human-like nature of the target sequence. however, the decoding with (cid:96) and 10-length candidates (n < 10) is not far in terms of ble |
case 22-71
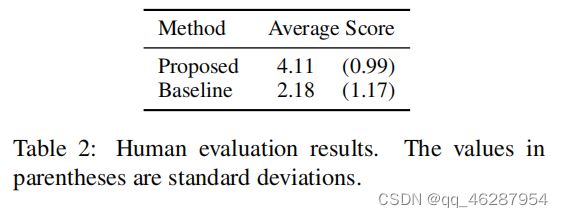
| link | https://www.aclweb.org/anthology/D19-1674.pdf-table_2 |
|---|---|
| gold | table 2 shows the human evaluation results, where we compute the average score by first computing the average score of the three evaluators for each of the top-k outputs, then selecting the maximum of the k scores as the score of the method. the average shown in the table is the average of such maximum scores.the proposed method failed to generate any anagram for 3 instances.we therefore set the score of the proposed method to 1.0 for them.we can see that the proposed method yielded significantly higher human evaluation scores |
| 1 | table 2 shows the human evaluation results. the proposed average of the deviations from the baseline is 4.11, which is close to the standard deviation of 3.49. proposed method significantly outperforms the baseline on average |
| 2 | table 2 shows the average of precision, recall and average score of the three human evaluation metrics. the proposed model significantly outperforms the baseline, although the difference in precision is small (0.17) |
case 23-75
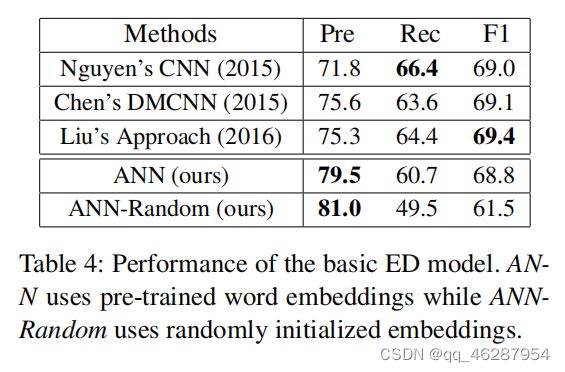
| link | https://www.aclweb.org/anthology/P16-1201.pdf-table_4 |
|---|---|
| gold | table 4 shows the experimental results, from which we can see that the three-layer ann model is surprisingly effective for event detection, which even yields competitive results compared with nguyen’s cnn and chen’s dmcnn.moreover, our basic model achieves much higher precision than state-of-the-art approaches (79.5% vs. 75.6%).the result shows that randomly initialized word embeddings decrease the f1 score by 7.3 (61.5 vs. 68.8) |
| 1 | table 4 shows the results of the basic ed model. we can see that the neural word embedding-based model performs poorly compared to the chen-based and liu-based models |
| 2 | table 4 shows that the pre-trained word embeddings improve the performance of the basic ed model and provide a significant boost in terms of f1-score (p < 0.05). while the improvement is comparable to that of the liu et al. approach (2016), we note that our method uses much more parameters (compared to theirs), and thus achieves comparable performance to their model |
case 24-76

| link | https://www.aclweb.org/anthology/P16-1201.pdf-table_5 |
|---|---|
| gold | table 5 shows the results of manual evaluations.through the comparison of ann and sf, we can see that the application of h1 caused a loss of 5.5 point.moreover, sl obtains a gain of 2.0% improvement compared with ann, which demonstrates that the ”same lu” hypothesis is very useful.finally, with all the hypotheses, the psl-based approach achieves the best performance, which demonstrates that our hypotheses are useful and it is an effective way to jointly utilize them as soft constraints through psl for event detection in fn |
| 1 | table 5 shows the manual evaluations. the psl-based approach achieves the best accuracy and precision, although the precision is slightly lower than the random baseline. the ann approach performs better than the baseline on precision, recall and f1-score, indicating that the topic of self-attention is more relevant for the task |
| 2 | table 5 shows the results of manual evaluations. we can see that the manual evaluations reveal that the proposed approach outperforms the baselines significantly. although the overall accuracy of the p-sl method is lower than sf, it is worth noting that the difference in precision is only about 1.5% for the human evaluation |
case 25-77
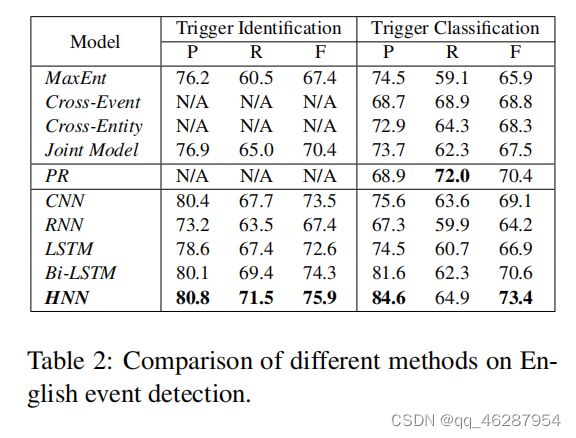
| link | https://www.aclweb.org/anthology/P16-2011.pdf-table_2 |
|---|---|
| gold | table 2 shows the overall performance of all methods on the ace2005 english corpus.we can see that our approach significantly outperforms all previous methods.(4) rnn and lstm perform slightly worse than bi-lstm |
| 1 | table 2 shows the comparison of different methods on english event detection. we can see that our joint model can achieve the state-of-the-art performance. compared with the best baselines, our method achieves a 6.3% f-score by considering richer commonsense knowledge, rather than only event knowledge. it also presents a significant improvement over the best baseline method (cnn) over the previous work (peters et al., 2017), which leverages a sourc |
| 2 | table 2 shows the comparison between our models and the state-of-the-art methods on english event detection. we can see that our joint model significantly outperforms all compared methods in terms of all metrics, and the improvements are statistically significant (t-test with p-value < 0.01). although the difference in precision between the best performing methods and the cross-event model is slightly smaller than in the joint model, we see comparable improvements across all metrics |
case 26-79
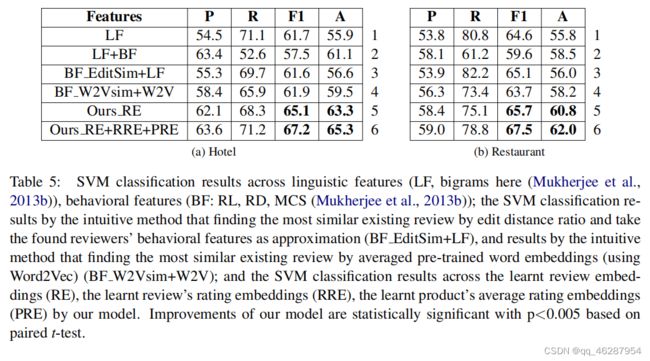
| link | https://www.aclweb.org/anthology/P17-1034.pdf-table_5 |
|---|---|
| gold | the results are shown in table 5.as table 5 showed, our model observably performs better in detecting review spam for the cold-start task in both hotel and restaurant domains |
| 1 | table 5 shows the svm classification results for five languages of different sizes of our model (mukherjee et al., 2013b) and the different evaluation splits. the results show that our model is able to achieve improvements of 0.005-0.08% over the best previously reported results (lf) for the learned review’s rating, and 0.05% over (lf+BF) for restaurant reviews. the improvements are statistically significant at a p |
| 2 | the results in table 5 show that our re+rre+pre method outperforming all the baselines, with a difference of 0.005 based on paired t-test. rl does not show significant differences between our re-rre and the baseline, which is likely due to the difference of coarsegrained features between the hotel and restaurant domains, although it is the case that the pre-trained word embeddings were necessary for the task. interestingly, our r |
case 27-80

| link | https://www.aclweb.org/anthology/P17-1054.pdf-table_2 |
|---|---|
| gold | table 2 provides the performances of the six baseline models, as well as our proposed models (i.e., rnn and copyrnn).for each method, the table lists its f-measure at top 5 and top 10 predictions on the five datasets.the results show that the four unsupervised models (tf-idf, textrank, singlerank and expandrank) have a robust performance across different datasets.the performance of the two supervised models (i.e., maui and kea) were unstable on some datasets, but maui achieved the best performances on three datasets among all the baseline models.as for our proposed keyphrase prediction approaches, the rnn model with the attention mechanism did not perform as well as we expected.the copyrnn model, by considering more contextual information, significantly outperforms not only the rnn model but also all baselines, exceeding the best baselines by more than 20% on average |
| 1 | table 2 shows the performance of our models on the five benchmark datasets. it can be observed that all of the models achieve higher f1 scores than tf-idf, which shows that considering global structure does not make a difference when selecting salient datasets for n/a keyphrases. the results in table 2 indicate that our proposed approach outperforms al |
| 2 | table 2 shows the performance of our model and the baselines for the various models on the five benchmark datasets. we can see that the xf1 scores are generally better than the standard fasttext embeddings, which indicates the model performs better at predicting keyphrases on multiple datasets |
case 28-83
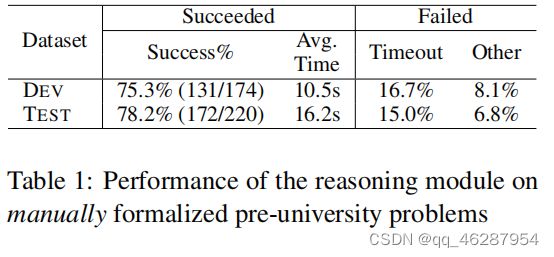
| link | https://www.aclweb.org/anthology/P17-1195.pdf-table_1 |
|---|---|
| gold | it solves 70% of the them in the time limit of 10 minutes per problem.table 1 shows the rate of successfully solved problems in the manually formalized version of the benchmark problems used in the current paper |
| 1 | table 1 shows the performance of the reasoning module on manually formalized pre-university problems. the module achieves significantly higher performance than the baseline in terms of success rate and other metrics (dev/test: 78.2% vs. 75.3%) |
| 2 | table 1 shows the performance of the reasoning module on manually formalized pre-university problems. as can be seen from the table, the model achieves a success rate of 75.3% on the dev set, which is about 2.5% faster than the state-of-the-art result on the test set. moreover, the average time of test timeout is about 16% lower than that of dev timeout |
case 29-85
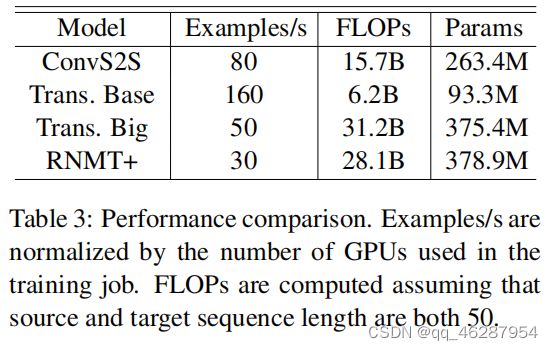
| link | https://www.aclweb.org/anthology/P18-1008.pdf-table_3 |
|---|---|
| gold | table 3 summarizes training performance and model statistics.the transformer base model is the fastest model in terms of training speed.rnmt+ is slower to train than the transforme |
| 1 | table 3 shows the results. we can see that the rnmt+ model performs significantly better than the transformer model (vaswani et al., 2017) on both 50.1 and 200. examples/s are computed assuming that the source and target sequence length are similar (50.1 vs. 50.2 in table 3) |
| 2 | table 3 shows the results of the ablation experiments. we find that the proposed rnmt+ model substantially outperforms the transformer base model (vaswani et al., 2017) by a large margin (over 5%), despite the unavailability of additional training data for the model. moreover, when limiting the number of parameters to a log of 800 translations, the performance drops dramatically. to further demonstrate the effectiveness of this tuning, we compute the flops of the models based o |
case 30-89

| link | https://www.aclweb.org/anthology/P18-1050.pdf-table_6 |
|---|---|
| gold | table 6 shows the comparisons of our results with the performance of several previous models, which were all trained with 1,500k event chains extracted from the nyt portion of the gigaword corpus (graff and cieri 2003).it is encouraging that by using event knowledge extracted from automatically identified narratives, we achieved the best event prediction performance, which is 2.2% higher than the best neural network model |
| 1 | table 6 shows that our results on the mcnc task are comparable to those achieved by (pichotta and mooney, 2016) when using the same set of features (with gold annotations) for both tasks. our system achieves comparable performance to the state-of-the-art methods using the gold annotations (see the second block in table 6) |
| 2 | in table 6, we compare our model to the state-of-the-art on the mcnc task for tasks of span identification, keyphrase extraction, and relation extraction. our model significantly outperforms all the baselines in both accuracy and precision, and achieves a 48% accuracy improvement by comparing our results with those of (granroth-wilding and clark, 2016) and (pichotta and mozzo, 2017) respectively |
case 31-93
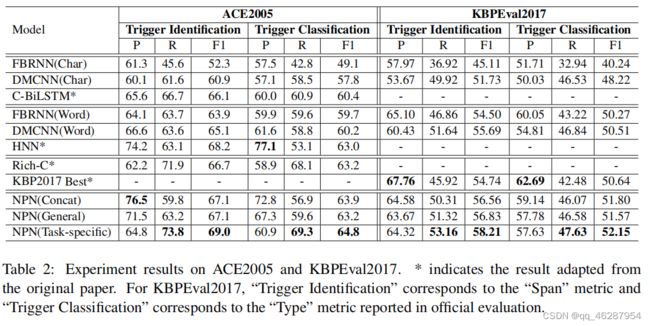
| link | https://www.aclweb.org/anthology/P18-1145.pdf-table_2 |
|---|---|
| gold | table 2 shows the results on ace2005 and kbpeval2017.from this table, we can see that:.1) npns steadily outperform all baselines significantly.compared with baselines, npn(taskspecific) gains at least 1.6 (2.5%) and 1.5 (3.0%) f1-score improvements on trigger classification task on ace2005 and kbpeval2017 respectively.as shown in table 2, npn(taskspecific) achieved significant f1-score improvements on trigger identification task on both datasets.comparing with corresponding characterbased methods3 , word-based methods achieved 2 to 3 f1-score improvements, which indicates that words can provide additional information for event detection |
| 1 | table 2 shows that dmcnn(char) can adapt to the test set according to the official evaluation metric reported in section 3.4. in particular, compared to the result in kbpeval2017, “trigger classification” corresponds to the “span” metric, which measures the performance of humans interacting with each other on a website. “word” is the most important component for “char”, with “bilstm |
| 2 | table 2 shows the results on the four datasets. for kbpeval2017, “trigger identification” corresponds to the “type” metric reported in official evaluation. in addition, in table 2, we note that dmcnn(word) outperforms c-bilstm(char) by a large margin, indicating that word shape information is very important for sequence labeling |
case 32-94

| link | https://www.aclweb.org/anthology/P18-1168.pdf-table_4 |
|---|---|
| gold | table 4 describes our main results.our weakly-supervised semantic parser with re-ranking (w.+disc) obtains 84.0 accuracy and 65.0 consistency on the public test set and 82.5 accuracy and 63.9 on the hidden one, improving accuracy by 14.7 points compared to state-of-theart.the accuracy of the rule-based parser (rule) is less than 2 points below maxent, showing that a semantic parsing approach is very suitable for this task.the supervised parser obtains better performance (especially in consistency), and with re-ranking reaches 76.6 accuracy, showing that generalizing from generated examples is better than memorizing manually-defined patterns.our weakly-supervised parser significantly improves over sup., reaching an accuracy of 81.7 before reranking, and 84.0 after re-ranking (on the public test set).consistency results show an even crisper trend of improvement across the models |
| 1 | table 4 shows the results for the development, public test and test-h sets. for each model, we report both accuracy and consistency scores. we compare the results of our models with the following baselines:. it can be seen from the table that the baselines we compare against are extremely competitive state-of-the-art neural network models. the performance gap between the best performing baselines and our models is close because the size of the model we are comparing against is eve |
| 2 | table 4 shows the results of our models on the development, public test (test-p) and test-h sets. first, our model outperforms the baselines in all cases, which shows the effectiveness of our approach. second, the rule-based model is more stable than the neural network based models, which confirms the benefits of joint learning. third, we can observe that the maxent accuracy scores are lower than the regularization scores on all datasets, which indicate |
case 33-95

| link | https://www.aclweb.org/anthology/P18-1177.pdf-table_5 |
|---|---|
| gold | table 5 shows the results of the human evaluation.bold indicates top scores.we see that the original human questions are preferred over the two nqg ssystemsfoutputs, which is understandable given the examples in figure 3.the humangenerated questions make more sense and correspond better with the provided answers, particularly when they require information in the preceding context.in terms of grammaticality, however, the neural models do quite well, achieving very close to human performance.in addition, we see that our method (corefnqg) performs statistically significantly better across all metrics in comparison to the baseline model (contextnqg), which has access to the entire preceding context in the passage |
| 1 | table 5 shows the results of human evaluation. our two-tailed t-test results confirm the effectiveness of the method. we see that corefnqg outperforms contextnqg in almost all metrics. adding textual description as a feature does not help, since it is intended for coarse types and only utilizes relation phrases. our method yields a significant improvement over the best performing baseline, and a smaller improvement on questions involving relations |
| 2 | table 5 shows the human evaluation results. our method significantly outperforms both corefnqg and contextnqg on all three standard metrics, and is comparable with the state-of-the-art. in addition, we find that the additional components are useful for improving both the grammaticality and the answerability. comparing the three baselines for question generation in table 5 shows that the addition of the human edits brings 0.14% and 0.18% improvement o |
case 34-106
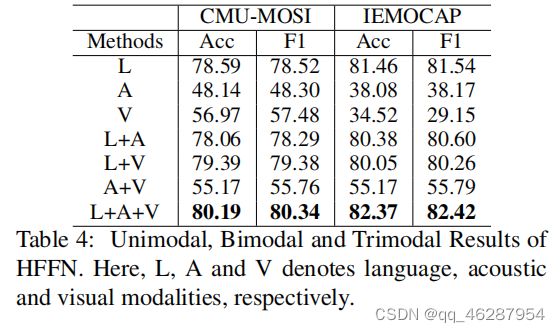
| link | https://www.aclweb.org/anthology/P19-1046.pdf-table_4 |
|---|---|
| gold | to explore the underlying information of each modality, we carry out an experiment to compare the performance among unimodal, bimodal and trimodal models.for unimodal models, we can infer from table 4 that language modality is the most predictive for emotion prediction, outperforming acoustic and visual modalities with significant margin.when coupled with acoustic and visual modalities, the trimodal hffn performs best, whose result is 1% ~ 2% better than the language-hffn, indicting that acoustic and visual modalities actually play auxiliary roles while language is dominant.however, in our model, when conducting outer product, all three modalities are treated equally, which is probably not the optimal choice |
| 1 | table 4 summarizes the results of hffn. we observe that the trimodal modality itself denotes language, acoustic and visual modalities, respectively. in addition, the dnn-based method achieves the best results, outperforming the baseline by 4% − 6% in terms of f1 score |
| 2 | table 4 shows the results of hffn on all language pairs with visual and acoustic modalities. we can see that the audio and visual modalities, on their own, do not provide good performance, but when used with text, complementary data is shared to improve overall performance. as shown in table 4, l+a+v+v gives the best performance on all languages, followed by a+v and l+v. however, for czech, hungarian an |
case 35-108

| link | https://www.aclweb.org/anthology/P19-1117.pdf-table_2 |
|---|---|
| gold | the main results on the one-to-many translation scenario, including one-to-two, one-to-three and one-to-four translation tasks are reported in table 2.we present a typical multi-nmt adopting johnson et al. (2017) method on transformer as our multi-nmt baselines model.obviously, multi-nmt baselines cannot outperform nmt baselines in all cases, among which four directions are comparable and twelve are worse.with respect to our proposed method, it is clear that our compact method consistently outperforms the baseline systems.compared with another strong one-to-many translation model three-stgy proposed by wang et al. (2018), our compact method can achieve better results as well.moreover, our method can perform even better than individually trained systems in most cases (eleven out of sixteen cases).the results demonstrate the effectiveness of our method |
| 1 | table 2 presents the results of our proposed language-sensitive methods to address multilingual translation. from the results we can see that our proposed models achieve improvements over the best performing baselines on all three tasks. first, the first line shows the bleu score of the proposed models on the original english-to-german translation task. second, the results indicate that the proposed methods can obtain comparable or better performance than the existing state-of-the-art methods on th |
| 2 | table 2 shows our proposed language-sensitive translation methods. note that the source language of all our experiments is english. our full model (rep+emb+attn) significantly outperforms all the baselines in one-to-two translation, and is comparable to the previous state-of-the-art in bilingual translation. our re-implementation of biaf obtains the best translation results in all cases, which demonstrates the effectiveness of the proposed model |
case 36-112
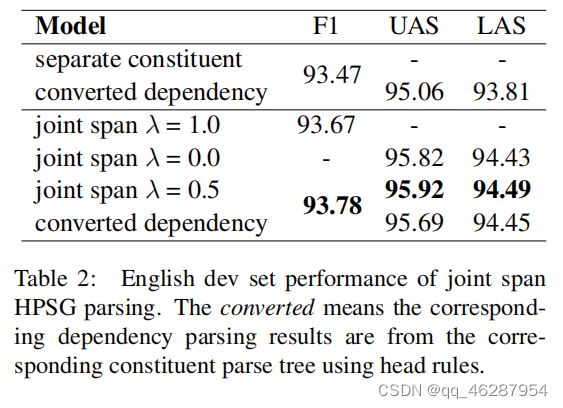
| link | https://www.aclweb.org/anthology/P19-1230.pdf-table_2 |
|---|---|
| gold | table 2 shows that even in such a work mode, our hpsg parser still outperforms the separate constituent parser in terms of either constituent and dependency parsing performance.as lambda is set to 0.5, our hpsg parser will give constituent and dependency structures at the same time, which are shown better than the work alone mode of either constituent or dependency parsing.besides, the comparison also shows that the directly predicted dependencies from our model are slightly better than those converted from the predicted constituent parse trees |
| 1 | table 2 shows the results for english dev set. we can see that hpsg parser converted dependency parsers using head rules can outperform the two baselines. although the results are slightly lower in accuracy than those using separate constituent parsers, the precision reaches almost 87% and is thus raised to a new level, corresponding to a 20% absolute improvement in recall |
| 2 | table 2 compares the performance of our parser with the corresponding constituent parse trees using head rules in the hansard parser, as discussed in section 5. our hpsg parser joint span outperforms the separate constituent parser by 0.05 and 0.08 in terms of f1-score, respectively. as we can see from the table, the converted parser effectively uses the head rules to improve the performance |
case 37-116
| link | https://www.aclweb.org/anthology/P19-1309.pdf-table_3 |
|---|---|
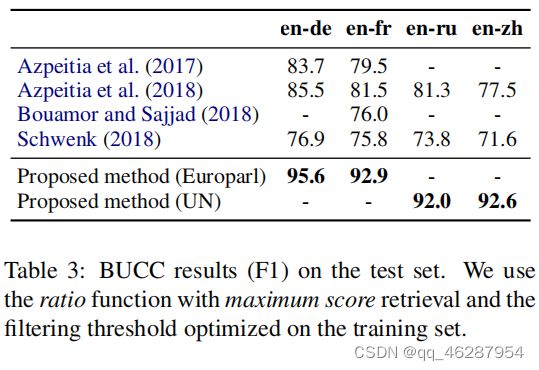
| gold | table 3 reports the results on the test set for both the europarl and the un model in comparison to previous work.9 .our proposed system outperforms all previous methods by a large margin, obtaining improvements of 10-15 f1 points and showing very consistent performance across different languages, including distant ones |
| 1 | table 3 reports the results using the bucc evaluation metric. again, we see that the proposed method with maximum score retrieval achieves the best performance with a small standard deviation, which corresponds to a rrie of 5% |
| 2 | table 3 shows the results. the proposed method with maximum score retrieval outperforms all previous systems, including those with minimum score retrieval and filtering thresholds. Huang et al. (2018) achieves the best result with an absolute improvement of 5.9% f1 on the training set. we also outperform the schwenk system by a large margin, which is based on a wide range of lexical, syntactic and semantic features |
case 38-118

| link | https://www.aclweb.org/anthology/P19-1332.pdf-table_8 |
|---|---|
| gold | mtl+copy, dnpg and adapted dnpg as well as the reference.table 8 shows the mean rank and inter-annotator agreement (cohen’s kappa) of each model.adapted dnpg again significantly outperforms mtl+copy by a large margin (p-value < 0.01).the performance of the original dnpg and mtl+copy has no significant difference (p-value = 0.18).all of the interannotator agreement is regarded as fair or above |
| 1 | table 8 shows the human evaluation results. the results show that our proposed adaptation layer improves the mean rank of mtl+copy by 3.24% and the bleu-recall by 1.79% on the wikianswers dataset, respectively |
| 2 | table 8 shows the human evaluation results of our model and the baseline models in wikianswers→quora. we compare our model with the state-of-the-art dnpg model (augenstein et al., 2017) which uses a graph-based attention mechanism for improved performance, and the mtl model which uses two stack lstm encoder-decoders (mtl+copy) for improved agreement. our model outperforms both models according t |
case 39-130
| link | https://www.aclweb.org/anthology/P19-1565.pdf-table_4 |
|---|---|
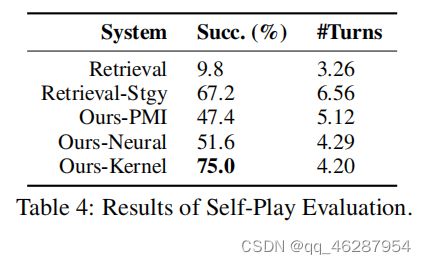
| gold | table 4 shows the results of 500 simulations for each of the comparison systems.our system with kernel transition obtains the highest success rate, significantly improving over other approaches.the success rate of the base retrieval agent is lower than 10%, which proves that a chitchat agent without a target-guided strategy can hardly accomplish our task.the retrieval-stgy agent has a relatively high success rate, while taking more turns (6.56) to accomplish this |
| 1 | table 4 shows the results of self-play evaluation. our system with kernel transition module outperforms all other systems in terms of all metrics on both two tasks, expect for rte system with pmi transition. the kernel approach can predict the next keywords more precisely. in the task of response selection, our systems that are augmented with predicted keywords significantly outperform the base retrieval approach, showing predicted keywords are helpful for better retrieving responses by capturing coarsegrained information of the next utterances |
| 2 | table 4 shows the results of self-play evaluation. our system with kernel transition module outperforms all other systems in terms of all metrics, and the improvements are statistically significant (t-test with p-value < 0.05). similar improvements are also observed in the neural network setting, where the retrieval-stgy approach outperforms the neural-based approach by 3.26% and yields 3.39% improvement on success rate |
case 40-132

| link | https://www.aclweb.org/anthology/P19-1581.pdf-table_2 |
|---|---|
| gold | accuracies of 1-best and 5-best translations in table 2 show comparable word translation quality to previous work, although we do not employ any task specific steps in contrast to braune et al. (2018) |
| 1 | table 2 shows the results. the bilingual lexicon induction results show that our proposed method significantly outperforms the best previous method (braune et al., 2018) by 17.5% (19.3% relative) for 1-best vs. 5-best translation results. it also shows that the proposed method can obtain comparable performance with the state-of-the-art (28.8% vs. 28.8%) |
| 2 | table 2 shows the results. the bwe based dictionaries achieve 1-best and 5-best translations, which demonstrates the high quality of the bwes. compared with the state-of-the-art, the improvements are statistically significant (with p-value< 0.05). we also compare our models with the existing models, e.g., (braune et al., 2018) which uses a multi-task learning approach to improve the performance of training the |