JVM系统优化实践(16):线上GC案例(一)
您好,我是湘王,这是我的CSDN博客,欢迎您来,欢迎您再来~
列举几个实际使用案例说一下GC的问题。一个高峰期每秒10万QPS的社交APP,个人主页模块是流量最大的那个,而一次个人主页的查询,大概会加载5M的数据。
由于并发量太高,导致高峰期年轻代的Eden区被迅速填满,且频繁触发Young GC,每次Young GC后存活对象较多,Survivor中放不下。大量的对象快速进入老年代,由于老年代满而频繁触发Full GC。
优化JVM参数为:
-XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=5
CMS会导致大量的内存碎片,可以在5次GC之后,做一次Compaction压缩操作。
所以,在Full GC频率升高时,需要将如上参数调整为:
-XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=0
避免越来越频繁的GC。
一般新手工程师在部署生产环境时基本不会对JVM进行设置,基本跟上也都是使用JVM的默认设置,这是一个很大的隐患。例如,如果不设置-Xmx或者-Xms的话,可能初始的年轻代和老年代就几百M大小。Full GC一般在正常情况下,都是按天为单位来发生的,比如每天一次,或几天一次Full GC。
下面是一个公司级别的JVM模板:

Full GC不仅会因为老年代占满而触发,也会因为Metaspace区域被占满而触发。Java中的反射会将产生的类放在Metaspace中,而SoftReference软引用对象的回收公式是:
1、clock - timestamp ≤ freespace * SoftRefLRUPolicyMSPerMB;
2、clock – timestamp:表示软引用对象多久没被访问过;
3、freespace:JVM的空闲内存空间;
4、SoftRefLRUPolicyMSPerMB:每一MB空闲空间允许SoftReference对象存活多久。
5、如果freespace=3000MB,SoftReference=1000毫秒,则软引用对象可以存活freespace * SoftReference = 3000秒 = 50分钟。
如果-XX:SoftRefLRUPolicyMSPerMB=0,会导致可能刚创建出来的反射类迅速被Young GC回收掉。程序执行会继续执行反射以弥补不足,如此反复循环,造成Metaspace被占满。一般可将SoftRefLRUPolicyMSPerMB设为1000~5000毫秒,让JVM创建的软引用不会被立即回收,Metaspace的占用是比较稳定的,不会大幅波动,因为没有必要专门设置SoftRefLRUPolicyMSPerMB这个值。
通常,一个比较良好的JVM性能,应该是Full GC几天才触发一次,或者最多一天几次而已。未优化前的JVM参数:
-Xms1536M -Xmx1536M -Xmn512M -Xss256K -XX:SurvivorRatio=5 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=68 -XX:+CMSParallelRemarkEnabled -XX:+UseCMSInitiatingOccupancyOnly -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC
导致的结果是:
1、6天内,Young GC总次数2.6万次,总耗时1400秒
2、6天内,Full GC总次数250次,总耗时70秒
可以看出:
1、老年代1024M,年轻代512M,且Eden:S0:S1 = 5:1:1
2、-XX:CMSInitiatingOccupancyFraction=68,即老年代空间达到680M时触发Full GC
可由上述GC日志倒推JVM的内存模型:
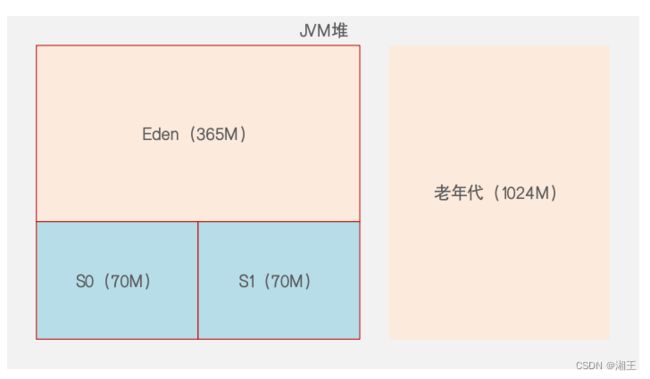
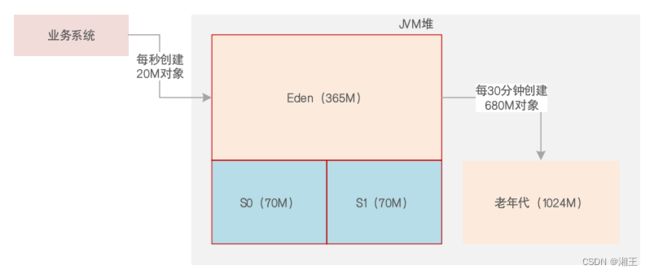
每分钟3次Young GC,说明每20秒会让Eden满,则每秒产生365/20 ≈ 15~20M对象:

每30分钟1次Full GC,说明每30分钟可能产生680M对象,或者每次Young GC后存活对象太多,老年代放不下年轻代转过来的对象:
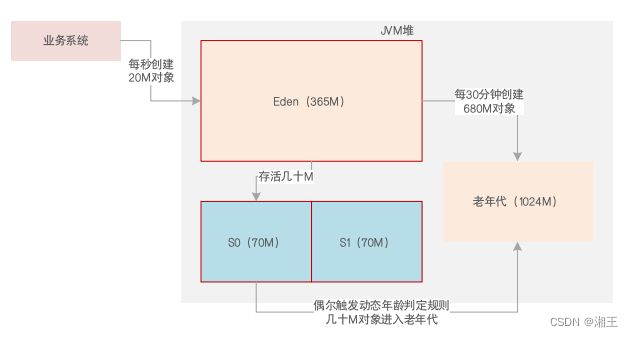
通过jstat得知:每次Young GC后,升入老年代的对象很少,因为S0/S1太小,经常触发动态年龄判定规则:
再次通过jstat得知:老年代总会突然有几百M对象占据着:
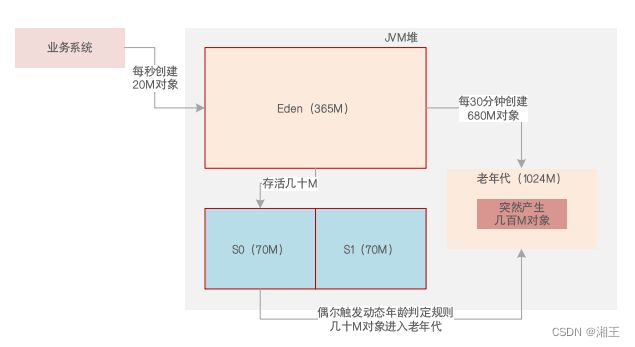
因此,答案很明显:大对象。一定是系统运行时,突然产生几百M大对象,而年轻代放不下这些大对象,它们就直接进入老年代,频繁触发Full GC:

然后再定位产生大对象的原因:
1、通过jmap,导出一份dump内存快照,接着用jhat或者Visual VM之类的工具分析dump文件;
2、通过分析dump,得知那个几百M的大对象,是从数据库中查出的数据,存放在Map中;
3、进一步排查出问题SQL语句。
故障解决和优化:
1、首先要解决代码中的bug;
2、年轻代明显太小,S0/S1区太小,因此需要调整JVM参数为:
-Xms1536M -Xmx1536M -Xmn1024M -Xss256K -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M -XX:SurvivorRatio=5 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=92 -XX:+CMSParallelRemarkEnabled -XX:+UseCMSInitiatingOccupancyOnly -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC
通过查看jstat,发现每秒都有Full GC,每次几百毫秒,年轻代增长不快,老年代才使用10%空间,元空间也才20%。怀疑人为原因:代码中写了System.gc()!
System.gc()不能随便写,它让JVM执行一次全空间的Full GC!
在系统负载量低时,这段代码可能没什么问题,但当系统负载量很高时,这段代码会频繁触发Full GC,导致系统直接卡死!为预防此类问题,可以通过加入-XX:+DisableExplicitGC避免显示触发GC。
感谢您的大驾光临!咨询技术、产品、运营和管理相关问题,请关注后留言。欢迎骚扰,不胜荣幸~