分布式系统故障容灾治理总结
最近刚好得闲来整理一下自己这几年工作的经验,这篇文章将会整理总结对于分布式系统的容灾配置的经验与思考。
思路
设想现在有一个系统处于整个链路的中游,上游对该系统有依赖,且该系统对下游也有依赖
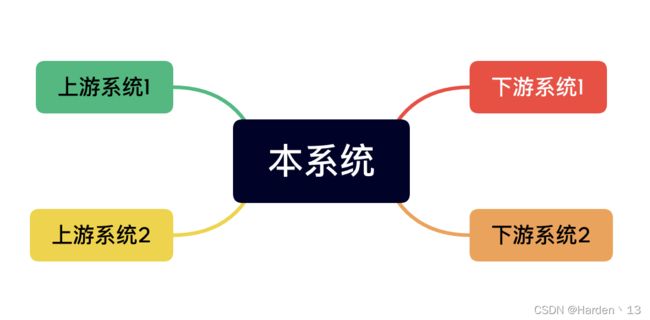
我们的目的是为了保障链路的可靠性,所以此时我们应该从以下几点去思考:
1.如果上游系统突然有海量请求袭来,我们应该怎么处理?
2.如果下游系统崩了或者接口耗时突增,我们应该怎么处理?
Tips:下游系统可能不仅是其他API服务,也可能是Redis、Kafka等中间件系统。
核心思想
我们做分布式系统故障容灾治理的核心思想是当我们系统统的上下游发生故障时,要最大程度的保证我们系统的可用性,保证系统不发生崩溃。
故障场景
上下游系统出故障/预期外容灾时其实可以分为以下几种情况:
1.上游突然发起海量请求
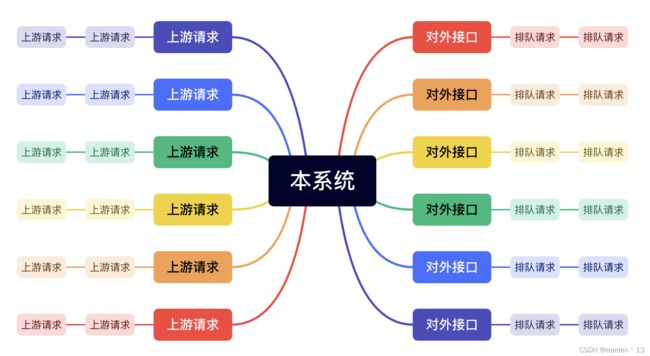

这个时候我们的系统会收到超过平时N倍的请求,此时会对系统的网络连接池、数据库连接池及其他中间件连接的线程池发起挑战。遇到这种情况我们可以设想最坏的场景:即我们接口的响应速度比请求产生的速度慢,那么请求会越来越多,产生挤压,甚至产生雪崩效应,导致下游系统也被拖垮。所以我们要采用“快速失败”的策略:
a.设置合理的连接超时时间
b.将等待超时的连接丢弃(等待时间过久的连接可能已经失效)
c.设置合理的网络连接池、数据库连接池及其他中间件连接池最大连接数
d.如果可以的话,对每一个对外暴露的接口或者控制器设置最大连接数
e.将接口降级,即只保留核心逻辑,比如下单接口此时只执行核心下单逻辑,其他非必要逻辑暂时不执行
f.将接口熔断,如果接口非核心接口,则可以将接口暂时禁用
2.下游系统崩溃/响应速度变慢


这个时候我们调用下游的请求耗时就会增大,甚至可能每次请求都会耗时最大Timeout,此时我们系统的接口耗时也可能因此增大,设想最坏的场景:下游每次请求都耗时max_timeout,而上游对我们设置的max_timeout可能也是此时接口的耗时,那么上游有可能会多次重试,甚至导致出现场景一“上游突然发起海量请求”的情况。为了保证我们系统的可用性,我们依然需要采用“快速失败”的策略:
a.对下游接口返回设置合理的最大超时时间
b.设置合理的重试次数,不采用无限重试策略,尽量在业务代码中实现重试逻辑
c.设置合理的网络连接池、数据库连接池及其他中间件连接池最大连接数
d.在下游接口返回失败时,如果非核心数据,可以采用降级策略,将这部分数据忽略
e.如果在某段时间内该下游接口失败或超时次数超过了限制,则跳过调用该接口一段时间
方法总结
其实从上面可以看出来当上游系统请求突增时可能会导致下游系统崩溃/响应速度变慢,当下游系统崩溃/响应速度变慢时也可能会导致上游系统请求增多,所以对分布式系统进行故障容灾处理的策略可以认为是相同的:
a.合理设置系统对外的服务和调用下游的连接最大超时时间
b.将等待超时的连接从连接池中丢弃
c.设置合理的重试次数,不采用无限重试策略,尽量在业务代码中实现重试逻辑
d.设置合理的网络连接池、数据库连接池及其他中间件连接池最大连接数
e.如果可以的话,对每一个对外暴露的接口或者控制器设置最大连接数
f.采用降级和熔断策略,最大化保证核心流程可用
以上就是对于分布式系统故障容灾处理的总结,不仅是在治理的时候,我们在平时设置各种参数的时候也需要考虑到这些问题,保证系统的可用性及稳定性。