C++ 入门基础(一) 详解命名空间和缺省参数
文章目录
- 前言
- 1. C++关键字(C++98)
- 2. 命名空间
-
- 2.1 C语言中的命名冲突问题
- 2.2 域作用限定符
- 2.3 命名空间的嵌套
- 2.4 命名空间的释放
- 2.5 用C++打印hello world的几种方式
-
- 2.5.1 释放std命名空间
- 2.5.2 不释放命名空间
- 2.5.3 释放常用的函数
- 3. C++输入与输出
- 4. 缺省参数
-
- 4.1 全缺省参数
- 4.2 半缺省参数
- 4.3 缺省参数应用实例
前言
C++入门基础篇的内容为C++的基本特性,只有在掌握C++的基本特性后,是进入后面类和对象学习的基础。
基本内容如下
1. C++关键字
2. 命名空间
3. C++输入/输出
4. 缺省函数
5. 函数重载
6. 引用
7. 内联函数
8. auto关键字(C++11)
9. 基础范围的for循环(C++11)
10. 指针空值—nullptr(C++11)
本篇博客将对1.C++关键字、2.命名空间、3.C++输入/输出、4.缺省参数进行详细介绍
1. C++关键字(C++98)
C++98中有63个关键字,其中有32个是C语言关键字(红色标注)
对于以下这些关键字,只需认识一下即可。在后续会学习中会慢慢接触到。
| asm | do | if | return | try | continue |
| auto | double | inline | short | typedef | for |
| bool | dynamic_cast | int | signed | typeid | public |
| break | else | long | sizeof | typename | throw |
| case | enum | mutable | static | union | wchar_t |
| catch | explicit | namespace | static_cast | unsigned | default |
| char | export | new | struct | using | friend |
| class | extern | operator | switch | virtual | register |
| const | false | private | template | void | true |
| const_cast | float | protected | this | volatile | while |
| delete | goto | reinterpret_cast |
2. 命名空间
看过c++的代码的都会发现只要是c++代码就会写下下面这句代码:
#include 这个头文件就类似于
using namespace std;
这就是我们今天接触的第一个关键字namespace,用来解决c语言中的不足
2.1 C语言中的命名冲突问题
首先我们知道C语言中的变量定义需要遵循命名规则,并且不能以C语言的关键字名称来命名变量。但除了这种情况,还有命名冲突的情况
为大家举个例子:
strlen并不是C语言中的关键字,将变量名定义为
strlen时,运行结果是没有问题的,但是在包含了strlen函数所在的头文件后,就无法编译,这就是C语言中的命名冲突问题
#include 于是为了解决这个问题,C++引入namespace这个关键字。
关键字namespace的使用:
#include 再次运行代码

我们发现这次不再存在上面的问题,而是打印出了strlen函数的地址,这就是namespace的功劳。
关键字namespace的作用是将int strlen = 0;这句代码隔离起来,而home就是“隔离间”的名称。
ps:命名空间不会改变strlen的生命周期,只是将它隔离开,strlen依旧是全局变量:>
C/C++中其实并不是不能命名同一个变量,命名冲突是发生在同一个作用域上的,当包含入int strlen这个变量和头文件中定义的strlen()函数的名字相冲突,而用namespace来处理,就相当于在作用域中建立了一个“隔离间”,从而解决了命名冲突的问题。再举一个例子

2.2 域作用限定符
默认情况下,当我们访问一个函数或者变量的时候,会先在该作用域内寻找函数或变量,如果该作用域内没有,便会在全局作用域内寻找函数或变量

要想访问全局域中的变量f,就要使用域作用限定符::,在域作用限定符前啥也不加就是访问全局域里的变量f

如果想要访问某一作用域中的变量f,只要像下面这样做

所以说,有了namespace这个关键字,你和同事小A的冲突也就迎刃而解了,两个人就算定义的变量或者函数命名冲突,也不用某一方委曲求全去改变他的函数名/变量名。小A可以创建一个名字为’A’的命名空间,而你可以创建一个名字为’home’的命名空间
namespace A
{
struct LTNode
{
int val;
struct LTNode* next;
};
}
namespace home
{
struct LTNode
{
int val;
struct LTNode* next;
};
}
int main()
{
A::LTNode* n1;
home::LTNode* n2;
return 0;
}
ps:main()函数中的
A::LTNode*类型是按照C++的方式来写的,样例中博主都是这么写的,要按照C的要求来写需要将其写为struct A::LTNode*
2.3 命名空间的嵌套
假如你和小A都在一个大厂上班,你们俩在维护一个项目时,都神使鬼差地将命名空间的名字设置成你们的公司名"byte",会怎么样呢?
小A作为项目A小组的成员,在项目中创建了一个头文件Queue.h,用来定义他要写的结构体类型
而你作为项目B小组的成员,在项目中创建了一个头文件List.h,用来定义你要写的结构体类型

当你想要将小A写的文件和你写的文件包含入test.cpp文件中时,你会发现

出现错误的原因是:当作用域命名相同的时候,编译器会合并两个作用域。也就是说此时struct
Node这个结构体类型在一个作用域中定义了两次,所以说编译失败也是理所当然的。
此时,你和小A就可以使用命名嵌套的方式来处理这种情况:
小A在byte命名空间内嵌套一个名为'A'的命名空间,表示是小组A的定义;
而你就可以在byte命名空间内嵌套一个名为'home'的命名空间,表示是你的定义

此时再运行程序,就不会报错啦,你也可以自由的应用你和小A定义的结构体变量了
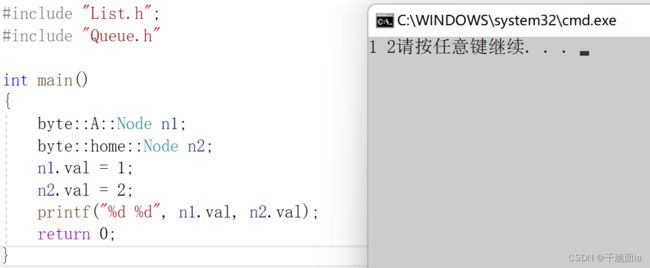
命名空间的小总结:
- 可以用命名空间来定义变量、函数、和类型
- 只能在全局定义命名空间
- 同名的命名空间是可以同时存在的,编译器编译时会合并
- 命名空间可以嵌套
2.4 命名空间的释放
如果将代码都像前面所说的方式来写→byte::A:: / byte::home::未免显得过于繁琐,接下来就将讲到命名空间的释放的几种情形,在理解完命名空间的释放后,我们在开头提到的疑问就能顺理成章地解决了。
写下这样一段代码:
using namespace byte;
再运行我们就发现,不需要再写下byte这个命名空间了
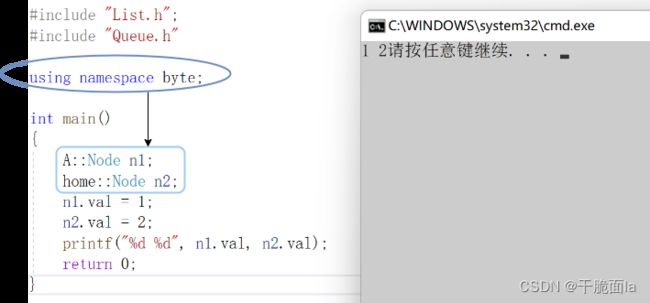
这是因为using namespace byte这段代码就相当于把空间名为byte的命名空间释放出来,也就是说此时的命名空间home和A就不再是byte内的空间,而是变为位于全局域中的命名空间

同样的道理,还可以在释放byte之后,再释放byte内的命名空间A。
ps:只有再释放byte后才能释放A,否则将会找不到命名空间A

如果不想释放byte空间,只想释放byte内的A空间,则可以这样写:
using namespace byte::A
此时也就相当于命名空间A里所定义的内容,被释放到全局域中

此时代码就该这样书写:
using namespace byte::A;
int main()
{
Node n1;
byte::home::Node n2;
n1.val = 1;
n2.val = 2;
printf("%d %d", n1.val, n2.val);
return 0;
}
如果要释放的不是命名空间,而是命名空间的函数或者变量,那么就不需要加namespace,比如单独释放命名空间A里定义的变量a
using byte::A::a;

了解了using的使用,我们再回头看前面所说的代码
#include 在C++中,实际上是将库函数全部放在名为std的命名空间中,包含了头文件后,预编译使iostream里的库函数展开,但此时这些库函数还被名为std的命名空间所隔离using namespace std实际上就是将这些库函数释放出来。
前期学习C++的过程中,我们通常直接将std里所有的库函数都释放出来,也就是说有命名冲突的风险。但在项目中,通常将std中常用的库函数释放出来,接下来我将用打印hello world的几种方式为大家讲解。
2.5 用C++打印hello world的几种方式
2.5.1 释放std命名空间
放出来,虽然方便使用了,但是存在冲突的风险。
#include 2.5.2 不释放命名空间
不释放命名空间,可以以指定命名空间的方式来编写,但是频繁使用的时候用起来实在是过于繁杂。
#include 2.5.3 释放常用的函数
释放部分常用的函数,是一种较好的方式。
#include 3. C++输入与输出
其实它们涉及的内容很多,目前只需要先记住它们的用法。
对比C和C++的输入与输出,它们达到的效果是一样的
#include 我们发现:使用C++输入输出更方便,不需增加数据格式控制,比如:整形–%d,字符–%c
其实C++的输入和输出是很好理解的:
cin和cout里的’c’其实是控制台的缩写, in是输入,out是输出
“>>”——流提取运算符,"<<"流插入运算符
cin >> a;就相当于从标准输入(键盘)中输入的元素提取到变量a中
cout << a;就相当于把变量a的元素插入到标准输出(控制台)中以输出
连续使用流提取(>>) / 流插入(<<)运算符就相当于一行输入 / 输出多个元素;而endl就相当于是换行,和’\n’是一样的。
#include 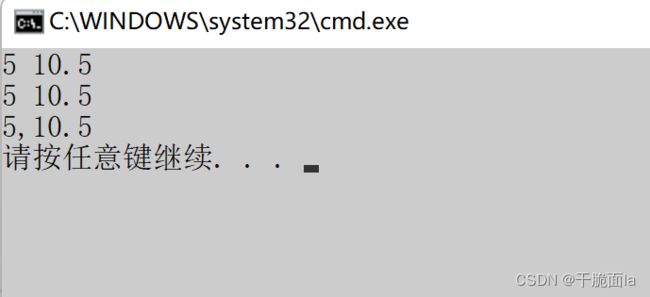
4. 缺省参数
缺省参数是声明或定义函数时为函数的参数指定一个默认值。在调用该函数时,如果没有指定实参则采用该默认值,否则使用指定的实参。
在我看来缺省参数就像是一个备胎,没有指定参数的时候才派上用场。
4.1 全缺省参数
全缺省函数就是:你所定义的函数有几个参数,就将其所有参数都设置上默认值
- 有一个参数的函数

- 有多个参数的函数
void TestFunc(int a = 10, int b = 20, int c = 30)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl << endl;
}
int main()
{
TestFunc(); // 没有传参时,使用参数的默认值
TestFunc(1); // 传参时,使用指定的实参
TestFunc(1,2);
TestFunc(1,2,3);
}
运行结果如下

ps:对于多个参数的函数,定义了它的全缺省参数后;
在调用函数的时候,要想指定实参,必须从左往右按顺序传。
比如想要跳过第一个参数指定第二个参数时,TestFunc(,2)的写法是错误的
4.2 半缺省参数
半缺省参数也就是说定义一个函数时有部分参数没有设置上默认值,如下
(注意!! 半缺省参数必须从右往左依次来给出,不能间隔着给)
如void TestFunc(int a = 10, int b, int c = 30)
和void TestFunc(int a = 10, int b = 20, int c)的方式都是错误的
void TestFunc(int a, int b = 20, int c = 30)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl << endl;
}
int main()
{
TestFunc(1); // 传参时,使用指定的实参
TestFunc(1,2);
TestFunc(1,2,3);
}
还需要注意的一点是:语法要求当分装函数声明和定义时缺省参数不能在函数声明和定义中同时出现。
原因是:怕我们在声明和定义函数时,缺省参数出现两个值不一样的情况。
因此我们可以在声明时写缺省参数,在定义中不写。
如果在声明时不写缺省函数,在定义时写缺省参数,同样会报错
原因是:函数声明会在编译的时候展开,而链接的时候才会找到函数的定义
4.3 缺省参数应用实例
我们定义一个栈,在对其进行初始化的时候,需要为其数据存放开辟一块空间,可以为需要开辟空间的大小设置一个默认值为4。
如果不使用缺省函数,初始化栈时开辟的空间只能写死为一个固定值,后续扩容时会耗费一定的资源
对于使用栈的人来说,在他明确知道自己存放的数据需要开辟多大的空间的情况下,便可以传一个自己需要的实参,为后续扩容带来一定程度的便利。
实现方式如下
struct Stack
{
int* a;
int size;
int capacity;
};
//定义半缺省参数
void StackInit(struct Stack* pst, int n = 4)
{
assert(pst);
pst->a = (int*)malloc(sizeof(int) * n);
pst->size = 0;
pst->capacity = n;
}
int main()
{
Stack st;
//为了避免扩容,直接传实参100
StackInit(&st, 100);
}