【设计原则】依赖倒置原则--高层代码和底层代码到底谁该依赖谁?
文章目录
- 前言
- 一、谁依赖谁
- 二、依赖于抽象
- 总结
前言
依赖这个词,程序员们都好理解,意思就是,我这段代码用到了谁,我就依赖了谁。依赖容易有,但能不能把依赖弄对,就需要动点脑子了。
如果依赖关系没有处理好,就会导致一个小改动影响一大片,而把依赖方向搞反,就是最典型的错误。
那什么叫依赖方向搞反呢?
我们就来讨论关于依赖的设计原则:依赖倒置原则。
一、谁依赖谁
依赖倒置原则(Dependency inversion principle,简称 DIP)是这样表述的:
高层模块不应依赖于低层模块,二者应依赖于抽象。
抽象不应依赖于细节,细节应依赖于抽象。
学习这个原则,最重要的是要理解“倒置”,而要理解什么是“倒置”,就要先理解所谓的“正常依赖”是什么样的。
我们很自然地就会写出类似下面的这种代码:
class CriticalFeature {
private Step1 step1;
private Step2 step2;
...
void run() {
// 执行第一步
step1.execute();
// 执行第二步
step2.execute();
...
}
}
但是,这种未经审视的结构天然就有一个问题:高层模块会依赖于低层模块。
在上面这段代码里,CriticalFeature 类就是高层类,Step1 和 Step2 就是低层模块,而且 Step1 和 Step2 通常都是具体类。
虽然这是一种自然而然的写法,但是这种写法确实是有问题的。
在实际的项目中,代码经常会直接耦合在具体的实现上。比如,我们用 Kafka 做消息传递,我们就在代码里直接创建了一个 KafkaProducer 去发送消息。我们就可能会写出这样的代码:
class Handler {
private KafkaProducer producer;
void send() {
...
Message message = ...;
producer.send(new KafkaRecord<>("topic", message);
...
}
}
也许你会问,我就是用了 Kafka 发消息,创建一个 KafkaProducer,这有什么问题吗?
其实,我们需要站在长期的角度去看,什么东西是变的、什么东西是不变的。Kafka 虽然很好,但它并不是系统最核心的部分,我们在未来是可能把它换掉的。
你可能会想,这可是我实现的一个关键组件,我怎么可能会换掉它呢?软件设计需要关注长期、放眼长期,所有那些不在自己掌控之内的东西,都是有可能被替换的。其实,替换一个中间件是经常发生的。
所以,依赖于一个可能会变的东西,从设计的角度看,并不是一个好的做法。那我们应该怎么做呢?这就轮到倒置登场了。
所谓倒置,就是把这种习惯性的做法倒过来,让高层模块不再依赖于低层模块。那要是这样的话,我们的功能又该如何完成呢?计算机行业中一句名言告诉了我们答案:
计算机科学中的所有问题都可以通过引入一个间接层得到解决。
是的,引入一个间接层。这个间接层指的就是 DIP 里所说的抽象。也就是说,这段代码里面缺少了一个模型,而这个模型就是这个低层模块在这个过程中所承担的角色。
既然这个模块扮演的就是消息发送者的角色,那我们就可以引入一个消息发送者(MessageSender)的模型:
interface MessageSender {
void send(Message message);
}
class Handler {
void send(MessageSender sender) {
...
sender.send(message);
...
}
}
有了消息发送者这个模型,那我们又该如何把 Kafka 和这个模型结合起来呢?那就要实现一个 Kafka 的消息发送者:
class KafkaMessageSender implements MessageSender {
private KafkaProducer producer;
public void send(final Message message) {
this.producer.send(new KafkaRecord<>("topic", message));
}
}
消费者可以这样消费消息:
Handler handler = new Handler();
handler.send(new KafkaMessageSender());
这样一来,高层模块就不像原来一样直接依赖低层模块,而是将依赖关系“倒置”过来,让低层模块去依赖由高层定义好的接口。这样做的好处就在于,将高层模块与低层实现解耦开来。
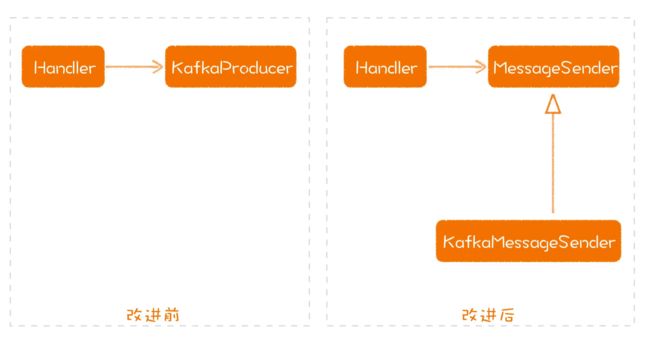
如果未来我们要用RabbitMQ替换掉 Kafka,只要重写一个 MessageSender 就好了,其他部分并不需要改变。这样一来,我们就可以让高层模块保持相对稳定,不会随着低层代码的改变而改变。
class RabbitmqMessageSend implements MessageSender {
private RabbitTemplate rabbitTemplate;
public void send(final Message message) {
rabbitTemplate.setExchange(exchangeKey);
rabbitTemplate.setRoutingKey(routingKey);
CorrelationData correlationId = new CorrelationData(UUID.randomUUID().toString());
this.rabbitTemplate.convertAndSend(exchangeKey,routingKey,message,correlationId);
}
}
消费者可以这样消费消息:
Handler handler = new Handler();
handler.send(new RabbitmqMessageSend());
二、依赖于抽象
抽象不应依赖于细节,细节应依赖于抽象。
其实,这个可以更简单地理解为一点:依赖于抽象,从这点出发,我们可以推导出一些更具体的指导编码的规则:
- 任何变量都不应该指向一个具体类;
- 任何类都不应继承自具体类;
- 任何方法都不应该改写父类中已经实现的方法。
举个List 声明的例子,其实背后遵循的就是这里的第一条规则:
List<String> list = new ArrayList<>();
在实际的项目中,这些编码规则有时候也并不是绝对的。如果一个类特别稳定,我们也是可以直接用的,比如字符串类。但是,请注意,这种情况非常少。因为大多数人写的代码稳定度并没有那么高。所以,上面几条编码规则可以成为覆盖大部分情况的规则,出现例外时,我们就需要特别关注一下。
总结
- 如果说实现开闭原则的关键事抽象化,是面向对象设计的目标的话,依赖倒置原则就是这个面向对象设计的主要机制。
- 依赖倒置原则的目的是通过要面向接口的编程来降低类间的耦合性,所以我们在实际编程中只要遵循以下4点,就能在项目中满足这个规则:
- 每个类尽量提供接口或抽象类,或者两者都具备。
- 变量的声明类型尽量是接口或者是抽象类。
- 任何类都不应该从具体类派生。
- 使用继承时尽量遵循里氏替换原则。