cifar-10数据集+ResNet50
CIFAR-10-ObjectRecognition
作为一个古老年代的数据集,用ResNet来练一下手也是不错的。
比赛链接:CIFAR-10 - Object Recognition in Images | Kaggle
1. 预设置处理
创建各类超参数,其中如果是在Kaggle上训练的话batch_size是可以达到4096的。
同时对于CIFAR-10数据集中含有10个类别,通过字典与反字典生成相应映射。
'''
**************************************************
@File :kaggle -> ResNet
@IDE :PyCharm
@Author :TheOnlyMan
@Date :2023/4/14 23:06
**************************************************
'''
seed = 998244353
torch.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)
torch.cuda.manual_seed_all(seed)
# torch.autograd.set_detect_anomaly(True) 检测梯度计算失败位置
class ArgParse:
def __init__(self) -> None:
self.batch_size = 16
self.lr = 0.001
self.epochs = 10
self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
args = ArgParse()
dic = {"airplane": 0, "automobile": 1, "bird": 2, "cat": 3, "deer": 4,
"dog": 5, "frog": 6, "horse": 7, "ship": 8, "truck": 9}
rev_dic = {0: "airplane", 1: "automobile", 2: "bird", 3: "cat", 4: "deer",
5: "dog", 6: "frog", 7: "horse", 8: "ship", 9: "truck"}
2. 创建Dataset
对于CIFAR-10数据集而言,图片的大小为(3,32,32),若是采用ResNet的话也不必要重新插值生成(224,224)尺寸的图像, 目前觉得好像(32,32)会更好点,而且模型体量更小点。
由于数据集是比较大的,可以不采用一次性读入内存的形式,在需要时在读取。
最后对于正确标签而言,采用onehot编码的形式,将正确标签概率设置为1,因此模型的输出只需要判断概率问题即可,较为经典的多分类问题。
class DataSet(Dataset):
def __init__(self, flag='train') -> None:
self.flag = flag
self.trans = transforms.Compose([
# trans.Resize((224, 224)),
transforms.RandomHorizontalFlip(p=0.5),
trans.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
assert flag in ['train', 'test'], 'not implement'
if self.flag == 'train':
self.path = "dataset/cifar-10/train"
self.dtf = pd.read_csv("dataset/cifar-10/trainLabels.csv")
else:
self.path = "dataset/cifar-10/test"
self.dtf = None
self.len = len(os.listdir(self.path))
def __getitem__(self, item):
image = Image.open(os.path.join(self.path, f"{item + 1}.png"))
if self.flag == 'train':
label = [0 for _ in range(10)]
label[dic.get(self.dtf.iloc[item, 1], -1)] = 1
return self.trans(image), torch.tensor(label, dtype=torch.float)
else:
return self.trans(image), torch.tensor(item, dtype=torch.int32)
def __len__(self):
return self.len
3. 模型
CNN
采取类似VGG架构,卷积核均为3,通道数在卷积层由3>8>16>32>64>128,在全连接层则是由一层512节点数构成,最后的输出层10采用Softmax函数进行多分类处理。(注:nn.Softmax()中dim需要设定为1)
训练轮数只有5-10轮,提交上去后有百分之73的准确率,对于一个较为少层的神经网络来说效果还是不错的,轻量级,同时如果训练轮数在多点应该也可以到达较高的准确率。
相比ResNet50而言,在训练10轮之后可以很快达到60%多的准确率。

10-20轮次CNN趋于稳定,验证集准确率不再上升。
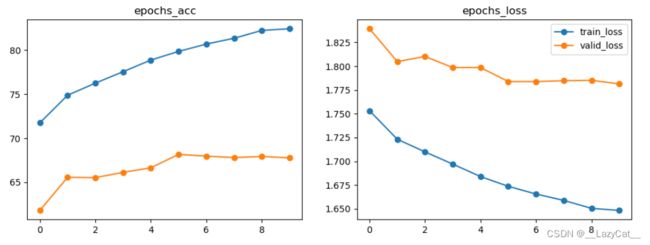
可能是设置的参数与第一次设置的不同,从20-50轮次的训练中,CNN的效果也并没有什么起色,应该是已经达到了该网络的上限。已经无法稳定地突破70%的准确率。
![]()
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(
in_channels=3, out_channels=8, kernel_size=3, stride=1, padding=1
),
nn.BatchNorm2d(8), nn.ReLU(), nn.MaxPool2d(2),
nn.Conv2d(
in_channels=8, out_channels=16, kernel_size=3, stride=1, padding=1
),
nn.BatchNorm2d(16), nn.ReLU(), nn.MaxPool2d(2),
nn.Conv2d(
in_channels=16, out_channels=32, kernel_size=3, stride=1, padding=1
),
nn.BatchNorm2d(32), nn.ReLU(),
nn.Conv2d(
in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=1
),
nn.BatchNorm2d(64), nn.ReLU(), nn.MaxPool2d(2),
nn.Conv2d(
in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1
),
nn.BatchNorm2d(128), nn.ReLU(),
)
self.layer = nn.Sequential(
nn.Linear(4 * 4 * 128, 512),
nn.BatchNorm1d(512),
nn.ReLU(),
nn.Linear(512, 10),
nn.Softmax(dim=1)
)
def forward(self, x):
x = self.conv(x)
x = x.view(x.size(0), -1)
x = self.layer(x)
return x
ResNet50
采用由torchvision中包含的resnet50模型进行训练,同时去除掉resnet50的全连接层直接由卷积层连向输出层。
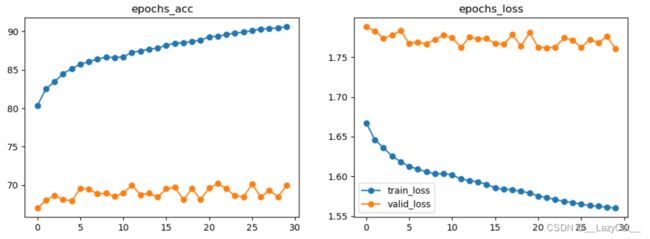
训练50轮次后可以达到82.7%的准确率。应该是轮次不足,或是仅仅使用原ResNet网络模型的效果无法达到90%以上等。其中采用20层初始预训练,经过微调后继续30层训练。感觉是还有上升的余地的,把训练轮数再翻倍应该可以达到85%以上准确率。
![]()
class ResNet50(nn.Module):
def __init__(self):
super(ResNet50, self).__init__()
self.model = torchvision.models.resnet50(pretrained=True)
in_channel = self.model.fc.in_features
self.model.fc = nn.Linear(in_channel, 10)
self.layer = nn.Sequential(
nn.Softmax(dim=1)
)
def forward(self, x):
x = self.model(x)
return self.layer(x)
MyResNet50
参考另一篇博客:ResNet残差网络
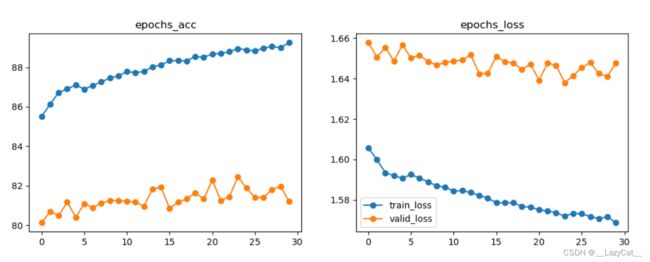
对于该模型而言,训练其50轮。
在20轮时的并没有20轮的CNN效果好。不过CNN本身参数虽然少,但是其效果之直逼ResNet50。

当对MyResNet50训练到第50轮时,其准确率并没有达到ResNet源码的效果,只在72%附近徘徊(比CNN略好一点,上限略高一点),因为MyResNet只是个简化的版本。这就使得网络比较浅的CNN效果和深层网络ResNet效果类似。
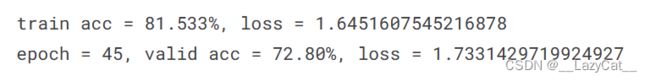
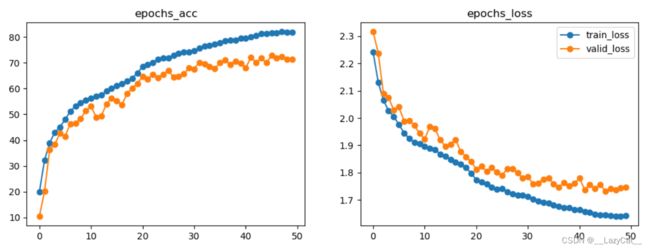
尝试再此基础上再次进行50轮次训练,并将学习率减少为原来的一半。此时验证集准确率已经到达极限,无法上升。

4. train
模型的创建或者加载由以上三个模型进行确定。
def train(pretrain=None):
dataset = DataSet('train')
train_size = int(len(dataset) * 0.95)
valid_size = len(dataset) - train_size
train_dataset, valid_dataset = random_split(dataset, [train_size, valid_size])
train_loader = DataLoader(dataset=train_dataset, batch_size=args.batch_size, shuffle=True)
valid_loader = DataLoader(dataset=valid_dataset, batch_size=args.batch_size, shuffle=True)
model = ResNet(Bottleneck, [3, 4, 6, 3], 10).to(args.device)
if pretrain:
model.load_state_dict(torch.load(pretrain))
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=args.lr)
train_epochs_loss = []
valid_epochs_loss = []
train_acc = []
valid_acc = []
for epoch in tqdm(range(args.epochs)):
model.train()
train_epoch_loss = []
acct, numst = 0, 0
for inputs, labels in tqdm(train_loader):
inputs = inputs.to(args.device)
labels = labels.to(args.device)
outputs = model(inputs)
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_epoch_loss.append(loss.item())
acct += sum(outputs.max(axis=1)[1] == labels.max(axis=1)[1]).cpu()
numst += labels.size()[0]
train_epochs_loss.append(np.average(train_epoch_loss))
train_acc.append(100 * acct / numst)
with torch.no_grad():
model.eval()
val_epoch_loss = []
acc, nums = 0, 0
for inputs, labels in tqdm(valid_loader):
inputs = inputs.to(args.device)
labels = labels.to(args.device)
outputs = model(inputs)
loss = criterion(outputs, labels)
val_epoch_loss.append(loss.item())
acc += sum(outputs.max(axis=1)[1] == labels.max(axis=1)[1]).cpu()
nums += labels.size()[0]
valid_epochs_loss.append(np.average(val_epoch_loss))
valid_acc.append(100 * acc / nums)
print("train acc = {:.3f}%, loss = {}".format(100 * acct / numst, np.average(train_epoch_loss)))
print("epoch = {}, valid acc = {:.2f}%, loss = {}".format(epoch, 100 * acc / nums,
np.average(val_epoch_loss)))
plt.figure(figsize=(12, 4))
plt.subplot(121)
plt.plot(train_acc, '-o', label="train_acc")
plt.plot(valid_acc, '-o', label="valid_acc")
plt.title("epochs_acc")
plt.subplot(122)
plt.plot(train_epochs_loss, '-o', label="train_loss")
plt.plot(valid_epochs_loss, '-o', label="valid_loss")
plt.title("epochs_loss")
plt.legend()
plt.show()
torch.save(model.state_dict(), 'model.pth')
5. predict
最后预测将其生成指定submission.csv文件即可进行提交。
def pred():
model = ResNet50().to(args.device)
model.load_state_dict(torch.load('model.pth'))
model.eval()
test_data = DataSet('test')
test_loader = DataLoader(dataset=test_data, batch_size=args.batch_size, shuffle=False)
data = []
for inputs, labels in tqdm(test_loader):
ans = model(inputs.to(args.device)).cpu()
ans = ans.max(axis=1)[1].numpy()
for number, res in zip(labels, ans):
data.append([number + 1, rev_dic.get(res)])
dtf = pd.DataFrame(data, columns=['id', 'label'])
dtf['id'] = dtf['id'].astype(np.int64)
dtf.sort_values(by='id', ascending=True)
print(dtf.info())
dtf.to_csv('submission.csv', index=False)