16图的定义和术语,图的存储结构及其代码实现
文章目录
- 图的定义和术语
-
- 图的定义和术语
- 案例引入和类型定义
-
- 案例:六度空间理论
- 图的类型定义
- 图的存储结构
-
- 邻接矩阵(数组)表示法
- 无向图的邻接矩阵
-
- 无向图邻接矩阵的特点
- 代码实现
- 有向图的邻接矩阵
-
- 有向图邻接矩阵的特点
- 代码实现
- 有权图的邻接矩阵
-
- 代码实现
- 采用邻接矩阵创建无向网
-
- 邻接矩阵的优缺点
- 邻接表(链式)
-
- 无向图邻接表
- 无向图邻接表的代码实现
-
- 带权值的代码实现
- 有向图的邻接表
- 有向图的邻接矩阵的代码实现
- 逆邻接表
- 拓展:用双向链表解决有向图找入度难的问题
- 邻接表表示法的优缺点
- 邻接矩阵和邻接表的联系和区别
- 邻接矩阵和邻接表总结
- 十字链表
-
- 代码实现
- 邻接多重表
-
- 代码实现
图的定义和术语
- 在线性结构中,结点之间的关系属于一个对一个;数据元素之间有着线性关系,每个数据元素只有一个直接前趋和一个直接后继,
- 在树形结构中,结点之间的关系属于一个对多个。数据元素之间有着明显的层次关系,并且每一层中的数据元素可能和下一层中的多个元素(即其孩子结点)相关,但只能和上一层中一个元素(即其双亲结点)相关;
- 而在图结构中,结点之间的关系属于多个对多个。结点之间的关系可以是任意的,图中任意两个数据元素之间都可能相关。
图(Graph)是一种非线性数据结构,由顶点(Vertex)和连接这些顶点的边(Edge)组成。
图的定义和术语
-
**图:**G(V,e)——Graph = (Vertex , Edge )
- V:图中的每个实体称为顶点。顶点也可以表示为节点(Node)。
- E:顶点之间的连接关系称为边。边可以有方向(有向图)或无方向(无向图)。
-
无向图(Undirected Graph):如果图中的边没有方向,则称为无向图。在无向图中,边表示顶点之间的双向关系。
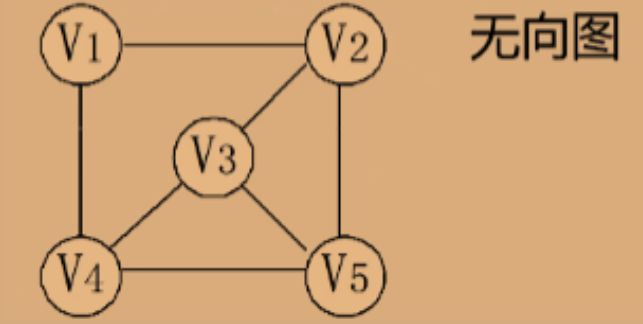
-
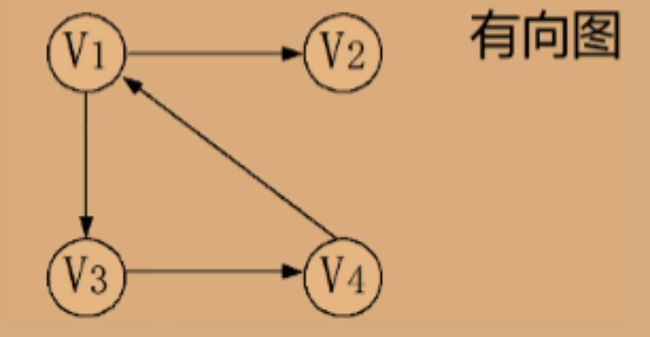
有向图(Directed Graph):如果图中的边具有方向,则称为有向图。在有向图中,边从一个顶点出发并指向另一个顶点。
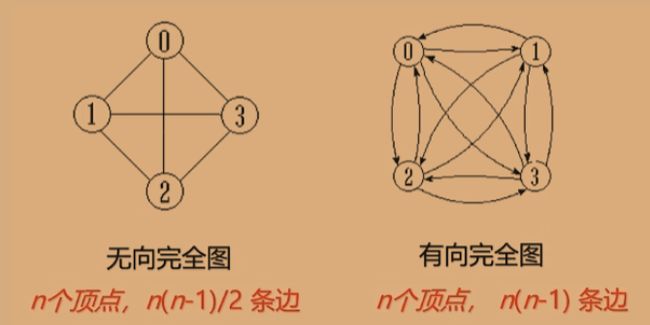
- 完全图(Complete Graph):完全图是一种特殊的图,其中任意两个顶点之间都有一条边。在有向完全图中,每对顶点之间都有两条相反方向的边。
-
稀疏图与稠密图(Sparse and Dense Graph):稀疏图是具有相对较少边的图,而稠密图是具有相对较多边的图。对于具有n个顶点的无向图,边数的上限是n(n-1)/2,而对于有向图,边数的上限是n(n-1)。
-
网:边 / 弧 带权的图
- 给 边 / 弧 加的这个有特殊意义的值就为权 。
-
邻接(Adjacent):如果两个顶点之间存在一条边,则称这两个顶点是相邻的。
- 存在无向图 (Vi,Vj),则称 Vi 和 Vj 互为邻接点。(Vi,Vj)表示 Vi 到 Vj 之间有一条边。
- 存在有向图
,则称 Vi 邻接到 Vj,Vj 邻接于 Vi。 表示在有向图中存在一条从 VI 到 Vj 的弧。
-
关联(依附):边 / 弧 与顶点之间的关系。
- 存在 (Vi,Vj) /
- 存在 (Vi,Vj) /
-
度(Degree):一个顶点的度是与其相邻的边的数量。在有向图中,我们还有入度(In-degree,指向该顶点的边数)和出度(Out-degree,从该顶点出发的边数)。

问:当有向图中仅一个顶点的入度为 0,其余顶点的入度均为 1,此时是何形状?
答:是树!而且是一棵有向树!

- 路径(Path):路径是顶点和边的序列,其中相邻顶点之间存在边。路径可以是简单路径(没有重复的顶点和边)或回路(首尾顶点相同的路径)。
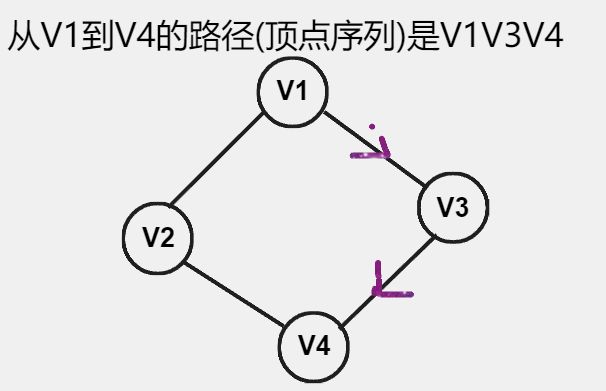
- 路径长度:路径上 边或弧 的数目或权值之和

-
回路(Circuit):是一种特殊的路径,其起点和终点相同。换句话说,在回路中,路径的第一个顶点和最后一个顶点是同一个顶点。需要注意的是,回路并不要求所有顶点都是唯一的。这意味着在回路中,某些顶点可能出现多次。
例如,对于顶点 A、B、C 和 D,一个回路可以表示为:(A, B, C, B, D, A)。在这个例子中,起点 A 和终点 A 相同,而其他顶点(如 B)可以在路径中出现多次。
-
简单路径(Simple Path):简单路径是一条路径,其中所有的顶点都不重复。换句话说,简单路径的顶点是唯一的,不会出现第二次。例如,对于顶点A、B、C和D,简单路径可以表示为:(A,B,C,D).
-
简单环(Simple Cycle):简单环是一条路径,其中除了起点和终点相同外,其他顶点都不重复。简单环是一种特殊的简单路径,它的起点和终点是同一个顶点。例如,对于顶点A、B、C和D,简单环可以表示为{A,B,C,D,A}.
简单路径有助于在分析和处理图时避免顶点重复的问题。例如,在寻找最短路径或最长路径时,通常要求找到的是简单路径,以避免无限循环或重复访问相同的顶点。
-
连通图(Connected Graph): 是一种无向图,其中任意两个顶点之间都存在至少一条路径。换句话说,在连通图中,从任意一个顶点出发,我们都可以到达其他所有顶点。连通图强调了顶点之间的连通性。
- 连通分量(Connected Component):连通分量是一个无向图中的最大连通子图。换句话说,一个连通分量是一个子图,其中任意两个顶点之间都存在至少一条路径,且不存在与子图外的其他顶点之间的路径。一个无向图可以由一个或多个连通分量组成。
- 强连通图(Strongly Connected Graph):强连通图是一种有向图,其中任意两个顶点之间都存在一条从一个顶点到另一个顶点的有向路径。强连通图要求从一个顶点到另一个顶点的路径是有向的,并且在这些路径上的边的方向是一致的。
- 弱连通图(Weakly Connected Graph):弱连通图是一种有向图,如果我们忽略边的方向,图变成了一个连通图。换句话说,在弱连通图中,如果我们将所有边视为无向边,那么任意两个顶点之间都存在至少一条路径。
-
权(Weight)与 网(Network)
- 权是与图中边相关联的一个数值,用于表示两个顶点之间的关系强度、距离、成本或其他度量。
- 网是一种特殊的加权图,用于表示实际系统中的网络结构,如通信网络、交通网络、电力网等。
-
子图(Subgraph):是一个图的部分,它包括原图中的一部分顶点和边。换句话说,子图是从原图中选择一部分顶点和边所形成的图。子图的顶点集和边集都是原图的子集。
例如,考虑一个包含顶点 A、B、C、D 和边 (A, B)、(B, C)、(C, D) 的原图 G。我们可以从 G 中选取顶点 B、C 和边 (B, C) 来形成一个子图 H。在这个例子中,子图 H 的顶点集为 {B, C},边集为 {(B, C)}。
- 连通分量(Connected Component):是无向图中的一个概念,指的是图中的一个最大连通子图。换句话说,连通分量是一个子图,其中任意两个顶点之间都存在至少一条路径,且没有与子图之外的其他顶点存在路径。在连通分量内的所有顶点都是连通的,而与连通分量之外的顶点是不连通的。
需要注意的是,对于有向图,我们使用类似的概念,称为强连通分量(Strongly Connected Component),它表示一个最大子图,其中任意两个顶点之间都存在一条从一个顶点到另一个顶点的有向路径。强连通分量和连通分量在很多方面具有相似的应用。
-
极大联通子图(Maximal Connected Subgraph)和极小联通子图(Minimal Connected Subgraph):是无向图中连通性相关的概念。它们分别表示具有最大顶点数和最小顶点数的连通子图。
- 极大联通子图:极大联通子图是一个连通子图,其中任意两个顶点之间存在至少一条路径,且无法通过添加原图中的任何其他顶点或边来增加其连通性。换句话说,极大联通子图是包含尽可能多顶点和边的连通子图。需要注意的是,连通分量(Connected Component)就是极大联通子图。
- 极小联通子图:极小联通子图是一个连通子图,其中任意两个顶点之间存在至少一条路径,且无法通过删除子图中的任何顶点或边来保持其连通性。换句话说,极小联通子图是包含尽可能少顶点和边的连通子图。极小联通子图通常是用来描述图的某种核心结构,例如生成树(Spanning Tree)就是一种极小联通子图,它包含了原图中所有顶点,但只有足够的边来保持连通性,不包含任何环**。**
-
生成树(Spanning Tree)和生成森林(Spanning Forest):是图论中描述无向图连接结构的两个概念。它们主要应用于优化问题,如网络设计、最小成本连接等。
-
生成树:生成树是一个无向图的连通子图,它包含原图中的所有顶点,并且是无环的。换句话说,生成树是一棵树,它覆盖(或连接)原图中的所有顶点。
生成树的边数等于顶点数减一(即,
|E| = |V| - 1)。需要注意的是,生成树只适用于连通图。在实际应用中,最小生成树(Minimum Spanning Tree)是一个重要概念,它是一棵生成树,使得所有边的权重之和最小。 -
生成森林:生成森林是一个无向图的子图,它包含原图中的所有顶点,并且是无环的。生成森林可以看作是若干棵生成树的集合,这些生成树分别覆盖原图中的连通分量。换句话说,生成森林是一个无环图,它连接原图中的所有顶点,但不一定是连通的。生成森林适用于非连通图。
与生成树类似,最小生成森林(Minimum Spanning Forest)是一个重要概念,它是一个生成森林,使得所有边的权重之和最小。
-
案例引入和类型定义
案例:六度空间理论
六度空间理论(Six Degrees of Separation)是一种社会网络理论,它认为任何两个人之间的关系距离可以用六步以内的联系来连接。也就是说,在这个世界上,任何两个陌生人之间最多只需五个中间人,就可以建立联系。这里以图的方式来解释一下这个理论:
- 首先,想象一个由不同颜色的圆形节点组成的网络图,每个节点代表一个人,不同颜色代表不同的社会群体。
- 然后,在这些节点之间用线条连接,表示人与人之间的关系。线条越多,表示这两个人的关系越紧密。
- 从图中任意选择一个节点(代表一个人),标记为A。接下来,我们将寻找另一个与A无直接联系的节点B。
- 现在,尝试找到一条最短路径,将A和B连接在一起。首先,寻找与A直接相连的节点,这些节点距离A为1度。然后,在这些1度节点中,寻找与它们直接相连的节点,这些节点距离A为2度,以此类推。
- 通常情况下,你会发现A和B之间的最短路径长度不会超过6,也就是说,A和B之间最多只隔了5个中间人。
- 这个网络图说明了六度空间理论,即在这个复杂的社会网络中,任何两个人之间的关系距离都可以用六步以内的联系来连接。
图的类型定义

图的存储结构
邻接矩阵(数组)表示法
建立一个顶点表(记录各个顶点的信息)和一个邻接矩阵(表示各个顶点之间的关系)
- 假设图A= (V,E)有n个顶点,则:

- 图的邻接矩阵是一个二维数组
A.arcs[n][n],定义为:

无向图的邻接矩阵
图中有n个顶点,这个邻接矩阵就用n × n 来表示
因为要描述任意两个顶点之间的关系,任意两个顶点都需要描述他们两个之间有没有边。
下图有五个顶点,那么就需要一个5 × 5的方阵。
- 如果两个顶点之间存在邻接(有边)关系,那么邻接矩阵的值就是 1,反之为 0。

- 先观察 V1,V1到V2、V4有边记为1,其余顶点没有边记为0。

- 观察 V2,V2 到 V1、V3、V5 都有边记为1,其余记为0。

- 观察 V2,V2 到 V1、V3、V5 都有边记为1,其余记为0。

无向图邻接矩阵的特点
- **对称矩阵:**对于无向图,其邻接矩阵是对称的。换句话说,邻接矩阵的转置等于它本身。这意味着
matrix[i][j] = matrix[j][i],其中 matrix 是邻接矩阵,i 和 j 分别表示图中的顶点。因为无向图中的边没有方向,所以如果顶点 i 与顶点 j 相邻,那么顶点 j 也与顶点 i 相邻。 - **矩阵对角线元素:**在无向图的邻接矩阵中,对角线元素(即
matrix[i][i])表示顶点 i 是否与自身相连。对于大多数图,对角线元素的值为0,表示没有自环。如果对角线元素的值为1,那么表示该顶点存在自环。 - **空间复杂度:**邻接矩阵表示法的空间复杂度为 O(n^2),其中 n 是顶点的数量。对于稀疏图(边数远小于顶点数的平方),邻接矩阵表示法可能会浪费大量空间。在这种情况下,邻接表表示法可能是更好的选择。
- **时间复杂度:**邻接矩阵表示法在某些操作上具有较好的时间复杂度。例如,检查两个顶点之间是否存在边只需要 O(1) 的时间。然而,在添加或删除顶点时,可能需要重新分配并拷贝整个邻接矩阵,时间复杂度较高。
- **易于处理带权图:**邻接矩阵表示法可以方便地处理带权图。在这种情况下,矩阵中的元素值表示相应边的权重,而不仅仅是0和1。对于没有边的顶点对,可以使用一个特殊值(如
INT_MAX或0)表示它们之间没有连接。
总之,无向图的邻接矩阵表示法具有对称性、易于处理带权图的优点,但在空间复杂度方面可能不如邻接表表示法。在实际应用中,可以根据具体需求和数据特点选择适当的图表示方法。
代码实现
例如,考虑以下无向图:
1 —— 3
| |
2 —— 4
其对应的邻接矩阵为:
0 1 1 0
1 0 0 1
1 0 0 1
0 1 1 0
- 首先,我们定义一个名为
Graph的结构体,用于表示图。结构体包含两个成员:一个表示顶点数量的整数num_vertices和一个表示邻接矩阵的指针adjacency_matrix。
typedef struct Graph {
int num_vertices;
int **adjacency_matrix;
} Graph;
- 创建图的函数:根据顶点数量分配内存空间,初始化邻接矩阵。
Graph *create_graph(int num_vertices) {
Graph *graph = (Graph *)malloc(sizeof(Graph));
graph->num_vertices = num_vertices;
// 为邻接矩阵分配内存
graph->adjacency_matrix = (int **)malloc(num_vertices * sizeof(int *));
for (int i = 0; i < num_vertices; i++) {
graph->adjacency_matrix[i] = (int *)calloc(num_vertices, sizeof(int));
}
return graph;
}
- 添加边的函数:将邻接矩阵中对应的元素值设为1。注意无向图的邻接矩阵是对称的,所以我们要同时更新
matrix[vertex1][vertex2]和matrix[vertex2][vertex1]。
void add_edge(Graph *graph, int vertex1, int vertex2) {
graph->adjacency_matrix[vertex1][vertex2] = 1;
graph->adjacency_matrix[vertex2][vertex1] = 1;
}
- 删除边的函数:将邻接矩阵中对应的元素值设为0。注意无向图的邻接矩阵是对称的,所以我们要同时更新
matrix[vertex1][vertex2]和matrix[vertex2][vertex1]。
void remove_edge(Graph *graph, int vertex1, int vertex2) {
graph->adjacency_matrix[vertex1][vertex2] = 0;
graph->adjacency_matrix[vertex2][vertex1] = 0;
}
- 打印图的邻接矩阵:通过两个嵌套的循环,我们遍历并打印邻接矩阵中的每个元素。
void print_graph(Graph *graph) {
for (int i = 0; i < graph->num_vertices; i++) {
for (int j = 0; j < graph->num_vertices; j++) {
printf("%d ", graph->adjacency_matrix[i][j]);
}
printf("\n");
}
}
- 示例使用这些函数创建、修改和打印图:
int main() {
int num_vertices = 4;
Graph *graph = create_graph(num_vertices);
// 添加边
add_edge(graph, 0, 1);
add_edge(graph, 0, 2);
add_edge(graph, 1, 3);
add_edge(graph, 2, 3);
// 打印邻接矩阵
print_graph(graph);
// 删除边
remove_edge(graph, 1, 3);
printf("\n");
// 打印更新后的邻接矩阵
print_graph(graph);
// 释放内存
for (int i = 0; i < num_vertices; i++) {
free(graph->adjacency_matrix[i]);
}
free(graph->adjacency_matrix);
free(graph);
return 0;
}
总结
#include
#include
// 邻接矩阵表示的无向图结构体
typedef struct {
int** matrix; // 二维数组表示邻接矩阵
int num_vertices; // 顶点数
} Graph;
// 创建一个新图
Graph* create_graph(int num_vertices) {
Graph* graph = (Graph*)malloc(sizeof(Graph));
graph->num_vertices = num_vertices;
// 动态分配邻接矩阵所需的二维数组内存
graph->matrix = (int**)malloc(num_vertices * sizeof(int*));
for (int i = 0; i < num_vertices; ++i) {
graph->matrix[i] = (int*)calloc(num_vertices, sizeof(int));
}
return graph;
}
// 添加一条边
void add_edge(Graph* graph, int vertex1, int vertex2) {
graph->matrix[vertex1][vertex2] = 1;
graph->matrix[vertex2][vertex1] = 1;
}
// 删除一条边
void remove_edge(Graph* graph, int vertex1, int vertex2) {
graph->matrix[vertex1][vertex2] = 0;
graph->matrix[vertex2][vertex1] = 0;
}
// 打印图的邻接矩阵
void print_graph(Graph* graph) {
for (int i = 0; i < graph->num_vertices; ++i) {
for (int j = 0; j < graph->num_vertices; ++j) {
printf("%d ", graph->matrix[i][j]);
}
printf("\n");
}
}
// 释放图的内存
void destroy_graph(Graph* graph) {
for (int i = 0; i < graph->num_vertices; ++i) {
free(graph->matrix[i]);
}
free(graph->matrix);
free(graph);
}
// 主函数
int main() {
// 创建一个包含4个顶点的新图
Graph* graph = create_graph(4);
// 添加4条边
add_edge(graph, 0, 1);
add_edge(graph, 0, 2);
add_edge(graph, 1, 3);
add_edge(graph, 2, 3);
// 打印邻接矩阵
printf("The adjacency matrix of the graph:\n");
print_graph(graph);
// 删除一条边
remove_edge(graph, 1, 3);
// 打印更新后的邻接矩阵
printf("\nThe updated adjacency matrix of the graph:\n");
print_graph(graph);
// 释放图的内存
destroy_graph(graph);
return 0;
}
有向图的邻接矩阵
- 首先,矩阵有几行几列任然取决于顶点的个数。
- 在有向图中两个顶点之间的关系是有向的,顶点之间的边称作弧。

矩阵表示
如果存在着由当前顶点发出的弧,就在邻接矩阵当中记录一个1。没有发出弧的顶点在邻接矩阵中的值全为0。
- 从 V1 顶点出发,发出了两条弧,一条弧到 V2,一条弧到 V3,那么就在 V1 行的 V2 列和 V3 列记录一个1,其余记为 0。

- V2 顶点没有发出任何弧,那么从 V2 顶点到其他所有顶点的邻接矩阵的值都为0。

- 剩下的 V3 只发出来一条到 V4 的弧,V4 只发出了一条到 V1 的弧。
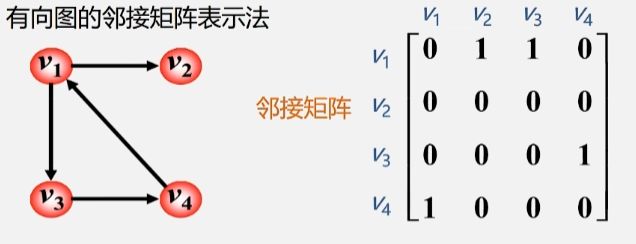
注:在有向图的邻接矩阵中
- 第 i 行含义:以结点为 Vi 为尾的弧(即出度边)。
- 第 i 列含义:以结点 Vi 为头的弧(即入度边)。
有向图邻接矩阵的特点
- 有向图的邻接矩阵可能是不对称的。
- 顶点的出度 = 第 i 行元素之和。顶点的入度 = 第 i 列元素之和。
- V1 的出度就是看矩阵的第一行有多少1。
- V1 的入度就是看矩阵的第一列有多少1。
- 顶点 i 的度 = 第 i 行元素之和 + 第 i 列元素之和。
- 例如V1的度就是V1所在行的两个1加上V1所在列的一个1相加为,V1的度就是3。
代码实现
有向图的邻接矩阵表示法与无向图的邻接矩阵表示法类似,不同之处在于邻接矩阵的元素表示的是有向边的关系,而不再是无向边的关系。具体来说,对于有向图的邻接矩阵,第 i 行第 j 列的元素 matrix[i][j] 表示顶点 i 是否指向顶点 j。如果顶点 i 指向顶点 j,那么 matrix[i][j] 就为 1,否则为 0。
下面是一个用邻接矩阵表示的有向图的例子:
0 --> 1 --> 2
^ ^ |
| | |
+-----------+
这个有向图有三个顶点和四条有向边,其中顶点 0 指向顶点 1,顶点 1 指向顶点 2,顶点 2 指向顶点 0,以及顶点 2 指向顶点 1。
它的邻接矩阵可以表示为一个 3x3 的矩阵:
0 1 2
0 0 1 0
1 0 0 1
2 1 1 0
- 首先,定义了一个结构体
DirectedGraph,包含一个二维数组matrix表示邻接矩阵,以及顶点数num_vertices。
#include
#include
// 有向图的邻接矩阵结构体
typedef struct {
int** matrix; // 二维数组表示邻接矩阵
int num_vertices; // 顶点数
} DirectedGraph;
-
函数
create_graph接受一个参数num_vertices,表示有向图的顶点数,返回一个指向DirectedGraph结构体的指针。首先动态分配
DirectedGraph结构体的内存,并将num_vertices存入num_vertices中。然后,动态分配
matrix的内存。它是一个二维数组,每一行都指向一个长度为num_vertices的整型数组。为了保证内存的清零,我们使用calloc函数来分配内存。最后,返回指向
DirectedGraph结构体的指针。
// 创建一个新的有向图
DirectedGraph* create_graph(int num_vertices) {
DirectedGraph* graph = (DirectedGraph*)malloc(sizeof(DirectedGraph));
graph->num_vertices = num_vertices;
// 动态分配二维数组内存
graph->matrix = (int**)malloc(num_vertices * sizeof(int*));
for (int i = 0; i < num_vertices; ++i) {
graph->matrix[i] = (int*)calloc(num_vertices, sizeof(int));
}
return graph;
}
- 函数
add_edge接受三个参数:指向有向图的指针graph,表示边的起点的顶点编号from_vertex,以及表示边的终点的顶点编号to_vertex。它将邻接矩阵中从顶点from_vertex到顶点to_vertex的元素设置为1,表示存在一条从顶点from_vertex指向顶点to_vertex的有向边。
// 添加一条有向边
void add_edge(DirectedGraph* graph, int from_vertex, int to_vertex) {
graph->matrix[from_vertex][to_vertex] = 1;
}
- 函数
remove_edge接受三个参数:指向有向图的指针graph,表示边的起点的顶点编号from_vertex,以及表示边的终点的顶点编号to_vertex。它将邻接矩阵中从顶点from_vertex到顶点to_vertex的元素设置为0,表示删除从顶点from_vertex到顶点to_vertex的有向边。
// 删除一条有向边
void remove_edge(DirectedGraph* graph, int from_vertex, int to_vertex) {
graph->matrix[from_vertex][to_vertex] = 0;
}
- 函数
print_graph接受一个指向有向图的指针graph,它打印出有向图的邻接矩阵。
// 打印有向图的邻接矩阵
void print_graph(DirectedGraph* graph) {
printf("Adjacency matrix of the directed graph:\n");
for (int i = 0; i < graph->num_vertices; ++i) {
for (int j = 0; j < graph->num_vertices; ++j) {
printf("%d ", graph->matrix[i][j]);
}
printf("\n");
}
}
- 函数
destroy_graph接受一个指向有向图的指针graph,它释放掉动态分配的所有内存。
// 释放有向图的内存
void destroy_graph(DirectedGraph* graph) {
for (int i = 0; i < graph->num_vertices; ++i) {
free(graph->matrix[i]);
}
free(graph->matrix);
free(graph);
}
- 主函数中的代码展示了如何创建一个包含4个顶点的有向图,如何添加5条有向边,如何打印邻接矩阵,如何删除一条边,如何打印更新后的邻接矩阵,并最后释放动态分配的内存。
// 主函数
int main() {
// 创建一个包含4个顶点的有向图
DirectedGraph* graph = create_graph(4);
// 添加5条有向边
add_edge(graph, 0, 1);
add_edge(graph, 1, 2);
add_edge(graph, 2, 3);
add_edge(graph, 3, 1);
add_edge(graph, 3, 0);
// 打印邻接矩阵
print_graph(graph);
// 删除一条边
remove_edge(graph, 2, 3);
// 打印更新后的邻接矩阵
print_graph(graph);
// 释放图的内存
destroy_graph(graph);
return 0;
}
代码总结
#include 有权图的邻接矩阵
将网的邻接矩阵的值定义为:

- 如果两个顶点之间存在着 边/弧,就在矩阵当中记录这两个顶点之间的边的权值。
- 如果两个顶点之间不存在 边/弧,就在矩阵当中记录 ∞。

代码实现
#include 采用邻接矩阵创建无向网
#include 需要注意的是,邻接矩阵表示法的有权图在实现时需要考虑边不存在的情况,这里使用 INT_MAX 来表示边不存在。此外,邻接矩阵只适合表示边稠密的图,因为其空间复杂度为 O(V^2),其中 V 为顶点数。如果是边稀疏的图,建议使用邻接表等数据结构来存储。
邻接矩阵的优缺点
优点
- 直观、简单、好理解。
- 便于判断啊两个顶点之间是否有边,即根据 A[i][j] = 0 或 1来判断。
- 方便找任一顶点的所有 邻接点(有边直接相连的的顶点)。
- 便于计算各个顶点的度。
- 无向图:对于行(或列)非 0 元素的个数;
- 有向图:对应非 0 元素的个数是“出度”;对应列 非 0 元素的个数为“入度”(行出列入)。
缺点
- 不便于增加和删除顶点。
- 不便于统计边的数目,需要扫描邻接矩阵所有元素才能统计完毕,时间复杂度为 O(n2)。
- 空间复杂度高。
- 如果是有向图:n 个邻接矩阵需要 n2 个单元存储边。
- 如果是无向图:因其邻接矩阵时对称的,所以对规模较大的邻接矩阵可以采用压缩存储的方式,仅存储下三角(或上三角)的元素,这样需要 n(n-1)/2个单元即可。
邻接表(链式)
-
邻接表是图的一种链式存储结构。
- 在邻接表中,对图中的每一个顶点Vi建立一个单链表,把与Vi相邻接的顶点放在这个链表中
- 邻接表中每个单链表的第一个结点存放有关顶点的信息,把这一个结点看成链表的表头,其余结点存放有关边的信息,这样邻接表便由两部分组成:表头节点和边表。
无向图邻接表
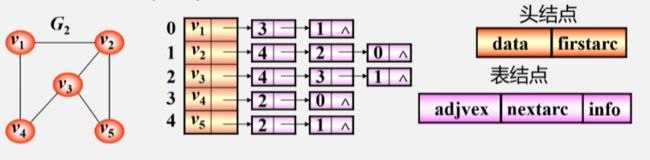
- 图 G 中有 5 个顶点,一维数组就开辟五个空间存储这些顶点。
- 每个元素空间还有一个指针,用来指向与该顶点邻接的第一个邻接点。
- 因为 下标 3 的 V4 是 V1 的邻接点,下标为 1 的 V2 也是 V1 的邻接点,所以 3、1 的位置是可以互换的。
表头结点表
由顶点构成的一维数组称为表头结点表
- 表头结点包括数据域 (data) 和 链域(firstarc)。

- 数据域用来存储顶点 Vi 的名称或其他有关信息。
- 链域是用来指向链表中的第一个结点(即与顶点 Vi 邻接的顶点)。
边表
由表示图中顶点间关系的 2n 个边链表组成
- 边链表中包含邻接点域 (adjvex) 和 链域 (nextarc)。

- 邻接点域(adjvex): 存放与 Vi 邻接的顶点在标表头数组中的下标。
- 链域(nextarc):链域指示与顶点 Vi 邻接的下一条边的结点。
无向图邻接表的特点
- 邻接表不唯一(与某个顶点连接的边的顺序是可变的)。
- 若无向图中有 n个顶点,e 条边。
- 则其邻接表需要 n 个头结点和 2e 个表结点。
- 所以无向图邻接表需要 O(n + 2e) 的存储空间,适合存储稀疏图。
- 无向图中顶点 Vi 的度为 第 i 个单链表中的结点数。
- 每个顶点有多少个表结点,则和这个顶点关联的边就有几个。
- 如:V1 有 2 个表结点,所以和V1 关联的边有两条,V1 的度为2
无向图邻接表的代码实现
#include 带权值的代码实现
#include
#include
// 顶点结构体
struct Vertex {
int value; // 顶点的值
struct AdjListNode* adjListHead; // 指向下一个邻接表节点的指针
};
// 邻接表节点结构体
struct AdjListNode {
int dest; // 目标顶点的编号
int weight; // 边的权值
struct AdjListNode* next; // 指向下一个邻接表节点的指针
};
// 图结构体
struct Graph {
int numVertices; // 图的顶点数
int numEdges; // 图当前的弧数
struct Vertex* vertices; // 顶点数组
};
// 创建新的邻接表节点
struct AdjListNode* newAdjListNode(int dest, int weight) {
struct AdjListNode* newNode = (struct AdjListNode*)malloc(sizeof(struct AdjListNode));
newNode->dest = dest;
newNode->weight = weight;
newNode->next = NULL;
return newNode;
}
// 创建一个图
struct Graph* createGraph(int numVertices) {
struct Graph* graph = (struct Graph*)malloc(sizeof(struct Graph));
graph->numVertices = numVertices;
graph->numEdges = 0;
graph->vertices = (struct Vertex*)malloc(numVertices * sizeof(struct Vertex));
for (int i = 0; i < numVertices; ++i) {
graph->vertices[i].value = 0; // 初始化顶点的值为0(或其他默认值)
graph->vertices[i].adjListHead = NULL; // 初始化邻接表头指针为NULL
}
return graph;
}
// 添加边到图中
void addEdge(struct Graph* graph, int src, int dest, int weight) {
struct AdjListNode* newNode = newAdjListNode(dest, weight);
newNode->next = graph->vertices[src].adjListHead;
graph->vertices[src].adjListHead = newNode;
newNode = newAdjListNode(src, weight);
newNode->next = graph->vertices[dest].adjListHead;
graph->vertices[dest].adjListHead = newNode;
graph->numEdges++; // 更新弧数
}
// 打印图的邻接表表示
void printGraph(struct Graph* graph) {
for (int i = 0; i < graph->numVertices; ++i) {
struct AdjListNode* temp = graph->vertices[i].adjListHead;
printf("顶点 %d 的邻接列表: ", i);
while (temp) {
printf("%d (权值: %d) -> ", temp->dest, temp->weight);
temp = temp->next;
}
printf("NULL\n");
}
}
int main() {
struct Graph *graph = createGraph(5);
addEdge(graph, 0, 1, 10);
addEdge(graph, 0, 4, 20);
addEdge(graph, 1, 2, 30);
addEdge(graph, 1, 3, 40);
addEdge(graph, 1, 4, 50);
addEdge(graph, 2, 3, 60);
addEdge(graph, 3, 4, 70);
// 打印邻接表
printGraph(graph);
return 0;
}
有向图的邻接表

- 在有向图中,只需要保存以当前顶点为弧尾的这一条边(每条弧只保存一次,只保存发出的弧)。
- 没有发出弧的顶点的头结点表的链域就置为NULL。
有向图邻接表的特点
- 顶点 Vi 的 出度为第 i 个单链表中的结点个数。
- 顶点 Vi 的入度为整个单链表中邻接点域值是i-1的结点个数。
- 如:想求V1的入度,就得去找邻接点域是1-1=0的结点有多少个。‘
有向图的邻接矩阵的代码实现
#include
#include
// 邻接表节点结构体
struct AdjListNode {
int dest; // 目标顶点的编号
struct AdjListNode* next; // 指向下一个邻接表节点的指针
};
// 邻接表结构体
struct AdjList {
struct AdjListNode* head; // 指向邻接表的第一个节点的指针
};
// 图结构体
struct Graph {
int numVertices; // 图的顶点数
struct AdjList* array; // 指向邻接表的指针数组
};
// 创建新的邻接表节点
struct AdjListNode* newAdjListNode(int dest) {
// 分配一个新的邻接表节点
struct AdjListNode* newNode = (struct AdjListNode*)malloc(sizeof(struct AdjListNode));
newNode->dest = dest; // 设置目标顶点的编号
newNode->next = NULL; // 初始化下一个节点的指针为NULL
return newNode; // 返回新节点的指针
}
// 创建一个图
struct Graph* createGraph(int numVertices) {
// 分配一个新的图
struct Graph* graph = (struct Graph*)malloc(sizeof(struct Graph));
graph->numVertices = numVertices; // 设置图的顶点数
// 创建邻接表数组
graph->array = (struct AdjList*)malloc(numVertices * sizeof(struct AdjList));
// 初始化每个邻接表为空
for (int i = 0; i < numVertices; ++i) {
graph->array[i].head = NULL;
}
return graph; // 返回新图的指针
}
// 添加边到图中
void addEdge(struct Graph* graph, int src, int dest) {
// 添加从src到dest的边
// 创建一个新的邻接表节点,并将目标顶点的编号设置为dest
struct AdjListNode* newNode = newAdjListNode(dest);
// 将新节点添加到src的邻接表的开头
newNode->next = graph->array[src].head;
graph->array[src].head = newNode;
}
// 打印邻接表
void printGraph(struct Graph* graph) {
for (int i = 0; i < graph->numVertices; ++i) {
struct AdjListNode* temp = graph->array[i].head; // 获取当前顶点的邻接表
printf("顶点 %d 的邻接列表: ", i);
// 遍历当前顶点的邻接表,并打印每个邻接点的编号
while (temp) {
printf("%d -> ", temp->dest);
temp = temp->next;
}
printf("NULL\n");
}
}
int main() {
// 创建一个具有5个顶点的图
struct Graph* graph = createGraph(5);
// 添加边
addEdge(graph, 0, 1);
addEdge(graph, 1, 2);
addEdge(graph, 2, 0);
addEdge(graph, 2, 3);
addEdge(graph, 3, 4);
// 打印邻接表
printGraph(graph);
return 0;
}
逆邻接表
- 既然可以用每个结点来存储顶点的出度边,那么当然也能反过来存入度边。
- 在逆邻接表中,单链表当中的结点是入度边

有向图逆邻接表的特点
- 顶点 Vi 的入度为第 i 个单链表中的结点个数。
- 顶点 Vi 的出度为整个单链表中邻接点域是是 i-1 的结点个数。
拓展:用双向链表解决有向图找入度难的问题
如果需要频繁计算每个顶点的入度,但是邻接表又不适合这种情况,可以考虑采用双向链表来改善这个问题。
双向链表是一种链表,每个节点都有两个指针,一个指向前一个节点,一个指向后一个节点。在有向图中,如果我们为每个节点维护一个指向它的入边列表,就可以快速查找每个节点的入度。
具体而言,可以将每个邻接表节点扩展为一个包含指向前一个节点和后一个节点的指针的节点,然后使用一个指向第一个节点和最后一个节点的指针来构建一个双向链表。
这种方法的缺点是需要使用更多的空间来存储额外的指针,而且在添加或删除节点时需要更新前向和后向指针,因此可能会导致一些开销。但是,如果需要频繁地查找每个节点的入度,则这种方法可能比遍历整个邻接表更有效。
#include
#include
// 双向链表节点结构体
struct DoubleListNode {
int val; // 目标顶点的编号
struct DoubleListNode* prev; // 指向前一个节点的指针
struct DoubleListNode* next; // 指向后一个节点的指针
};
// 邻接表节点结构体
struct AdjListNode {
int src; // 当前顶点的编号
struct DoubleListNode* inEdges; // 指向所有入边节点的指针
struct DoubleListNode* outEdges; // 指向所有出边节点的指针
};
// 邻接表结构体
struct AdjList {
struct AdjListNode* node; // 指向邻接表节点的指针
};
// 图结构体
struct Graph {
int numVertices; // 图的顶点数
struct AdjList* array; // 指向邻接表的指针数组
};
// 创建新的双向链表节点
struct DoubleListNode* newDoubleListNode(int val) {
// 分配一个新的双向链表节点
struct DoubleListNode* newNode = (struct DoubleListNode*)malloc(sizeof(struct DoubleListNode));
newNode->val = val; // 设置节点的值
newNode->prev = NULL; // 初始化前向指针为NULL
newNode->next = NULL; // 初始化后向指针为NULL
return newNode; // 返回新节点的指针
}
// 创建新的邻接表节点
struct AdjListNode* newAdjListNode(int src) {
// 分配一个新的邻接表节点
struct AdjListNode* newNode = (struct AdjListNode*)malloc(sizeof(struct AdjListNode));
newNode->src = src; // 设置当前顶点的编号
newNode->inEdges = NULL; // 初始化所有入边节点的指针为NULL
newNode->outEdges = NULL; // 初始化所有出边节点的指针为NULL
return newNode; // 返回新节点的指针
}
// 创建一个图
struct Graph* createGraph(int numVertices) {
// 分配一个新的图
struct Graph* graph = (struct Graph*)malloc(sizeof(struct Graph));
graph->numVertices = numVertices; // 设置图的顶点数
// 创建邻接表数组
graph->array = (struct AdjList*)malloc(numVertices * sizeof(struct AdjList));
// 初始化每个邻接表为空
for (int i = 0; i < numVertices; ++i) {
graph->array[i].node = newAdjListNode(i);
}
return graph; // 返回新图的指针
}
// 添加边到图中
void addEdge(struct Graph* graph, int src, int dest) {
// 添加从src到dest的边
// 创建一个新的双向链表节点,并将值设置为src
struct DoubleListNode* newNode = newDoubleListNode(src);
// 将新节点添加到dest的入边列表的开头
newNode->next = graph->array[dest].node->inEdges;
if (graph->array[dest].node->inEdges != NULL) {
graph->array[dest].node->inEdges->prev = newNode;
}
graph->array[dest].node->inEdges = newNode;
// 创建一个新的双向链表节点,并将值设置为dest
newNode = newDoubleListNode(dest);
// 将新节点添加到src的出边列表的开头
newNode->next = graph->array[src].node->outEdges;
if (graph->array[src].node->outEdges != NULL) {
graph->array[src].node->outEdges->prev = newNode;
}
graph->array[src].node->outEdges = newNode;
}
// 打印邻接表
void printGraph(struct Graph* graph) {
for (int i = 0; i < graph->numVertices; ++i) {
struct DoubleListNode* temp = graph->array[i].node->outEdges; // 获取当前顶点的出边链表
printf("顶点 %d 的邻接列表: ", i);
// 遍历当前顶点的出边链表,并打印每个邻接点的编号
while (temp) {
printf("%d -> ", temp->val);
temp = temp->next;
}
printf("NULL\n");
}
}
// 计算每个节点的入度
void printInDegrees(struct Graph* graph) {
int inDegrees[graph->numVertices]; // 存储每个节点的入度
// 初始化所有节点的入度为0
for (int i = 0; i < graph->numVertices; ++i) {
inDegrees[i] = 0;
}
// 遍历每个节点的邻接表,并更新每个节点的入度
for (int i = 0; i < graph->numVertices; ++i) {
struct DoubleListNode* temp = graph->array[i].node->inEdges;
while (temp) {
++inDegrees[i];
temp = temp->next;
}
}
// 打印每个节点的入度
printf("每个节点的入度:\n");
for (int i = 0; i < graph->numVertices; ++i) {
printf("节点 %d 的入度为 %d\n", i, inDegrees[i]);
}
}
int main() {
// 创建一个具有5个顶点的图
struct Graph* graph = createGraph(5);
// 添加边
addEdge(graph, 0, 1);
addEdge(graph, 1, 2);
addEdge(graph, 2, 0);
addEdge(graph, 2, 3);
addEdge(graph, 3, 4);
// 打印邻接表
printf("邻接表:\n");
printGraph(graph);
// 打印每个节点的入度
printInDegrees(graph);
return 0;
}
邻接表表示法的优缺点
在表示图的数据结构中,邻接表和邻接矩阵都是常用的表示方法。它们各自具有一定的优缺点,并在某些方面之间存在关联。下面我们来详细了解一下这些方面。
邻接表表示法的优点:
- 空间利用率高:邻接表仅表示存在的边,因此对于稀疏图(边的数量远小于顶点数量的平方)来说,邻接表的空间利用率更高。
- 遍历邻接顶点高效:邻接表允许我们直接访问与某个顶点相邻的所有顶点,因此在图遍历算法(如BFS和DFS)中效率较高。
邻接表表示法的缺点:
- 查找边的存在性较慢:与邻接矩阵相比,邻接表在判断两个顶点之间是否存在边时需要遍历其中一个顶点的邻接顶点列表,效率较低。
- 需要更复杂的数据结构:邻接表需要维护一个顶点的列表以及每个顶点的邻接顶点列表,相对邻接矩阵来说,数据结构更加复杂。
邻接矩阵和邻接表的联系和区别
-
存储结构: 邻接矩阵使用一个二维数组来表示图。设图有n个顶点,则使用一个n×n的矩阵A来表示图。如果顶点i和顶点j之间存在一条边,则A[i][j]为1(无权图)或边的权重(带权图);如果顶点i和顶点j之间没有边,则A[i][j]为0(无权图)或特殊值(如无穷大,表示顶点之间不可达)。
邻接表使用一个一维数组与链表来表示图。一维数组的每个元素表示一个顶点,对应一个链表。链表中的节点表示与该顶点相邻的顶点。通常,链表节点包括相邻顶点的编号和指向下一个节点的指针,对于带权图,链表节点还包括边的权重。
-
空间复杂度: 邻接矩阵的空间复杂度是O(n^2),其中n是顶点的数量。这意味着邻接矩阵在存储稀疏图(边数相对较少)时会浪费大量空间。
邻接表的空间复杂度是O(n + m),其中n是顶点的数量,m是边的数量。邻接表更适合存储稀疏图,因为它只需要存储存在的边。
-
时间复杂度: 邻接矩阵查询两个顶点之间是否存在边的时间复杂度为O(1),因为可以直接通过矩阵元素进行查询。但是,遍历图的所有边需要O(n^2)的时间。
邻接表查询两个顶点之间是否存在边的时间复杂度为O(deg(v)),其中deg(v)表示顶点v的度(与顶点v相邻的顶点数)。遍历图的所有边需要O(n + m)的时间,因为每个顶点的邻接表中的每个节点都表示一条边。
-
修改操作: 在邻接矩阵中添加或删除边的操作相对简单,只需修改对应的矩阵元素即可。
在邻接表中添加或删除边涉及到链表的操作,可能稍微复杂一些。
邻接矩阵多用于稠密图;而邻接表多用于稀疏图(边比较少)。
邻接矩阵和邻接表总结
邻接矩阵:
- 存储结构:使用一个二维数组表示图。如果顶点 i 和顶点 j 之间存在一条边,则矩阵元素 A[i][j] 表示边的存在或权重;如果顶点 i 和顶点 j 之间没有边,则 A[i][j] 表示边的不存在或不可达。
- 空间复杂度:O(n^2),其中 n 为顶点数。可能导致稀疏图的存储空间浪费。
- 时间复杂度:
- 查询两个顶点之间是否存在边:O(1)
- 遍历所有边:O(n^2)
- 添加或删除边:O(1)
- 对称性:无向图的邻接矩阵是对称的,即 A[i][j] = A[j][i]。
- 适用场景:稠密图(边数较多)或需要频繁查询边的存在性的场景。
- 扩展性:扩展邻接矩阵以存储额外信息较为困难。
邻接表:
- 存储结构:使用一个一维数组(顶点数组)与链表(邻接表)表示图。一维数组的每个元素表示一个顶点,对应一个链表。链表中的节点表示与该顶点相邻的顶点。链表节点通常包括相邻顶点的编号、边的权重(如果是带权图),以及指向下一个节点的指针。
- 空间复杂度:O(n + m),其中 n 为顶点数,m 为边数。更适合存储稀疏图,因为只需要存储存在的边。
- 时间复杂度:
- 查询两个顶点之间是否存在边:O(deg(v)),其中 deg(v) 表示顶点 v 的度(与顶点 v 相邻的顶点数)
- 遍历所有边:O(n + m)
- 添加或删除边:O(deg(v))
- 适用场景:稀疏图(边数较少)或需要更高效地遍历边和节省存储空间的场景。
- 扩展性:邻接表支持方便地存储额外信息,如顶点权值、边权值等。
邻接矩阵在查询操作方面更快,但空间需求较大;邻接表在存储空间和遍历操作方面更高效,但查询操作较慢。
十字链表
邻接表:
- 有向图——缺点:求结点的度困难——解决办法:十字链表
- 无向图——缺点:每条边都要存储两遍——解决办法:邻接多重表
十字链表是有向图的另一种链式存储结构。可以看成是将有向图的邻接表以及逆邻接表结合起来得到的新的链表。
-
同时有向图中的每个结点在十字链表中对应有一个结点,叫做顶点结点,用来存放原来的第一个出、入度边。
- data域:数据域
- fristin域:第一个入度边
- firstout域:第一个出度边
-
有向图中的每一条弧对应十字链表中的一个弧结点。同时弧结点包括四个域
- tailvex 域:表示弧尾顶点在顶点数组中的下标。弧尾顶点是有向弧起始的顶点。
- headvex 域:表示弧头顶点在顶点数组中的下标。弧头顶点是有向弧指向的顶点。
- hlink 域:表示指向具有相同弧头顶点的下一个弧结点的指针。通过这个指针,可以找到所有以同一个顶点为弧头的弧。
- tlink 域:表示指向具有相同弧尾顶点的下一个弧结点的指针。通过这个指针,可以找到所有以同一个顶点为弧尾的弧。

代码实现
#include 邻接多重表
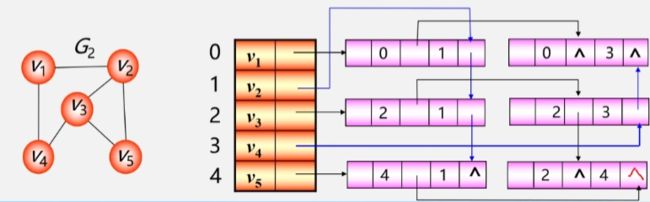
邻接多重表适用于表示无向图。
邻接多重表包含一个顶点数组和若干边结点。顶点数组中的每个元素都包含一个顶点数据和指向第一条依附该顶点的边的指针。边结点包含一个标记域(例如:用于标记边是否已经访问)、两个顶点的下标(ivex和jvex)、两个指向下一条依附相同顶点的边的指针(ilink和jlink),以及边的附加信息(如权重)。
插入边时,需要将新的边结点插入到对应的顶点的边链表中。这样做可以方便地遍历以某个顶点为端点的所有边。
时间复杂度:邻接多重表在查找某个顶点的度时具有较好的效率。对于稀疏图,邻接多重表的空间复杂度要优于邻接矩阵。
实现过程:
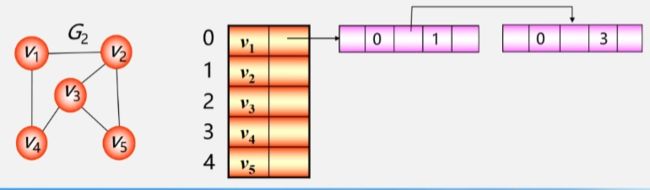
在邻接多重表中,每一条边用一个边结点表示。
- 这样一个边结点就存储了从 0 号位置的 V1 到 1号位置的 V2 之间的边。
- 下次就不用再记录从 V2 到 V1 之间的边了,直接使用这个边结点即可。

- 从 V1 到 V4 之间还有一条边,继续用一个边结点记录下来。这两条边都是从 0 号位置的 V1 开始的。
- 想找与 V1 相关的边就只需要找到第一条边就行了。
- 之后再找与 V2 相关联的边,V2 - V1 这条边已经有了,不需要再找一次了,直接拿来用,去找其余和 V2 有关联的边。
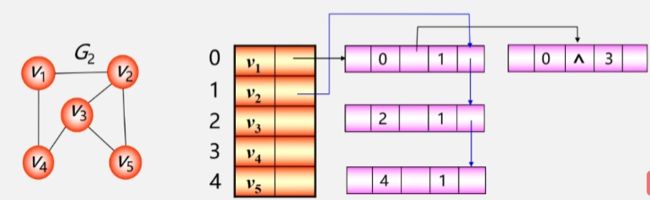
- 依次类推找到所有与其余顶点相关联的边。
代码实现
#include