MySQL索引最左匹配原则
MySQL索引最左匹配原则
- 一、案例一
-
- 1、表与索引创建
- 2、查询语句举例
- 3、那么究竟用到了哪些索引呢?
- 4、原因
- 二、案例二
-
- 1、表与索引创建
- 2、查询语句举例
- 3、原因
- 4、最左匹配原则
- 三、案例三
-
- 1、表与索引创建
- 2、查询语句举例
- 3、原因以及补充资料
一、案例一
1、表与索引创建
DROP TABLE IF EXISTS med_computer_info;
CREATE TABLE med_computer_info (
ID BIGINT NOT NULL AUTO_INCREMENT COMMENT '电脑id',
HOST_NAME VARCHAR ( 64 ) NOT NULL COMMENT '电脑id地址',
PORT VARCHAR ( 64 ) NOT NULL COMMENT '电脑端口',
TYPE INT NOT NULL COMMENT '电脑类型',
LAUNCH_DATE DATE NOT NULL COMMENT '电脑发布日期',
MODIFIED TIMESTAMP NOT NULL COMMENT '记录修改时间',
CREATED TIMESTAMP NOT NULL COMMENT '记录创建时间',
PRIMARY KEY ( ID ),
UNIQUE KEY INDEX_WORKER_NODE ( HOST_NAME, PORT, LAUNCH_DATE, TYPE )
) COMMENT = 'DB WorkerID Assigner for UID Generator',
ENGINE = INNODB;
2、查询语句举例
select * from med_computer_info where PORT=3306 and Type=1 ;
select * from med_computer_info where PORT=3307 and HOST_NAME='172.21.1.1' ;
select * from med_computer_info where PORT=3308 AND HOST_NAME='172.21.1.2' AND TYPE=2 ;
3、那么究竟用到了哪些索引呢?
第一句:没用到索引,在聚集索引上从左至右依次扫描过滤;
第二句:用到了辅助索引INDEX_WORKER_NODE;
第三句:用到了辅助索引INDEX_WORKER_NODE,但是只有HOST_NAME和PORT条件是通过索引完成的,条件TYPE是依次扫描过滤完成的;
4、原因
因为辅助索引是B+树实现的,虽然可以指定多个列,但是每个列的比较优先级不一样,写在前面的优先比较。一旦出现遗漏,在B+树上就无法继续搜索了(通过补齐等措施解决的除外),因此是按照最左连续匹配来的。既然是在B+树上搜索,对于条件的比较自然是要求精确匹配(即"=“和"IN”)。不过顺序倒是可以颠倒,因为查询优化器重排序一下就好了。
第一句,由于缺少HOST_NAME,只能在聚集索引的叶节点上,从左至右的扫描,挨个比对;
第二句,可以直接在辅助索引上查找,被找到的子树的所有叶节点就是命中的记录;
第三句,缺少LAUNCH_DATE条件,所以只能先依据HOST_NAME和PROT在辅助索引上查找,找到的主键值作为候选记录,然后到聚集索引上读取对应记录,再比较TYPE条件是否满足。
二、案例二
1、表与索引创建
DROP TABLE IF EXISTS student;
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`cid` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `name_cid_INX` (`name`,`cid`),
KEY `name_INX` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8
2、查询语句举例
依据mysql索引最左匹配原则,两个索引都匹配上了,这个没有问题
EXPLAIN SELECT * FROM student WHERE name='小红';
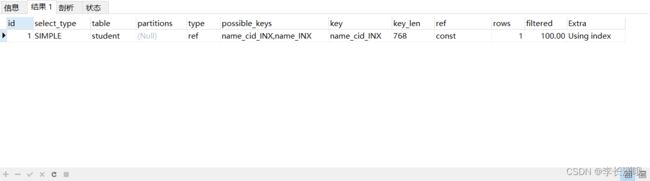
判断条件是cid=1,而cid是(name,cid)复合索引的一部分,没有问题,可以进行index类型的索引扫描方式。explain显示结果使用到了索引,是index类型的方式。
EXPLAIN SELECT * FROM student WHERE cid=1;
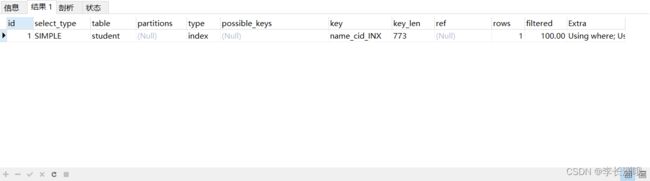
cid字段的索引数据也是有序的情况下才能使用,什么时候才是有序的呢?观察可知,当然是在name字段是等值匹配的情况下,cid才是有序的。
EXPLAIN SELECT * FROM student WHERE cid=1 AND name='小红';
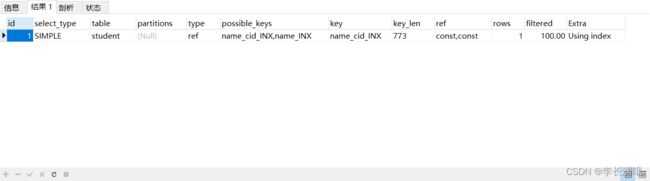
3、原因
index:这种类型表示是mysql会对整个该索引进行扫描。要想用到这种类型的索引,对这个索引并无特别要求,只要是索引,或者某个复合索引的一部分,mysql都可能会采用index类型的方式扫描。但是呢,缺点是效率不高,mysql会从索引中的第一个数据一个个的查找到最后一个数据,直到找到符合判断条件的某个索引。
ref:这种类型表示mysql会根据特定的算法快速查找到某个符合条件的索引,而不是会对索引中每一个数据都进行一 一的扫描判断,也就是所谓你平常理解的使用索引查询会更快的取出数据。而要想实现这种查找,索引却是有要求的,要实现这种能快速查找的算法,索引就要满足特定的数据结构。简单说,也就是索引字段的数据必须是有序的,才能实现这种类型的查找,才能利用到索引。
4、最左匹配原则
以该表的(name,cid)复合索引为例,它内部结构简单说就是下面这样排列的:
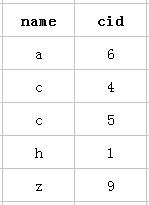
Mysql创建复合索引的规则是首先会对复合索引的最左边的,也就是第一个name字段的数据进行排序,在第一个字段的排序基础上,然后再对后面第二个的cid字段进行排序。其实就相当于实现了类似 order by name cid这样一种排序规则。
所以:第一个name字段是绝对有序的,而第二字段就是无序的了。所以通常情况下,直接使用第二个cid字段进行条件判断是用不到索引的,当然,可能会出现上面的使用index类型的索引。这就是所谓的mysql为什么要强调最左前缀原则的原因。
那么什么时候才能用到呢?
当然是cid字段的索引数据也是有序的情况下才能使用
三、案例三
1、表与索引创建
DROP TABLE IF EXISTS student;
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`cid` int(11) DEFAULT NULL,
`home` VARCHAR(255) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `name_cid_INX` (`name`,`cid`),
KEY `name_INX` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8
2、查询语句举例
EXPLAIN SELECT * FROM student WHERE cid=1;
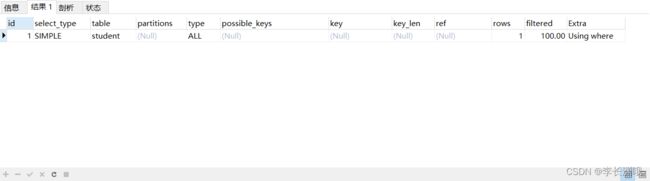
3、原因以及补充资料
比案例二多了一个home字段,由于辅助索引包含聚集索引,所以案例二的辅助索引为全部字段。
辅助索引包含了主键id用于回表操作,同时利用覆盖索引扫描可以更好的优化SQL。
索引可以加快数据的检索,减少IO开销,会占用磁盘空间,是一种用空间换时间的优化手段,同时更新操作会导致索引频繁的合并分裂,影响索引性能,在实际的业务开发中,如何根据业务场景去设计合适的索引是非常重要的
mysql查询优化器会判断纠正这条sql语句该以什么样的顺序执行效率最高,最后才生成真正的执行计划。所以,当然是我们能尽量的利用到索引时的查询顺序效率最高咯,所以mysql查询优化器会最终以这种顺序进行查询执行。