线性表详解
目录
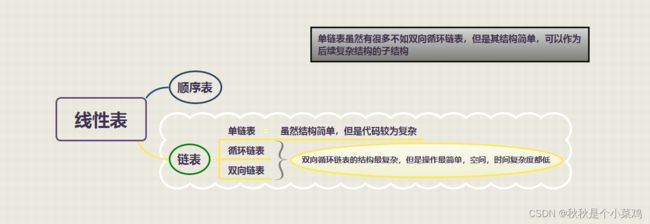
1.线性表的定义和特点
2.案例
2.1一元多项式的计算
可以通过下面这个题目简单练习一下
2.2稀疏多项式的计算
2.3图书信息管理系统
3.线性表的类型定义
4.线性表的顺序表示和实现
4.1线性表的顺序储存表示
4.2顺序表中基本操作的实现
5.线性表的链式表现和实现
5.1单链表的定义和实现
5.2单链表的基本操作实现
5.3循环链表
5.4双向链表
6.顺序表和链表的比较
6.1空间性能
6.2时间性能
7.线性表的应用
7.1线性表的合并
7.2有序表的合并
8.小结
1.线性表的定义和特点
定义:由n(n≥0)个数据特性相同的元素构成的有限序列称为线性表。
线性表中的元素个数n定义为线性表的长度。n=0时为空链。
特点:
(1)存在唯一的一个被称为“第一个”的数据元素
(2)存在唯一的一个被称为“最后一个”的数据元素
(3)除第一个以外,结构中的每个数据元素均只有一个前驱;
(4)除最后一个以外,结构中的每个数据元素均只有一个后继;
2.案例
2.1一元多项式的计算
用两个线性表来储存系数,这样就转化为两个链表对应元素相操作的问题了
可以通过下面这个题目简单练习一下
剑指 Offer II 025. 链表中的两数相加 - 力扣(Leetcode)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
//方法: 把所有数字压入栈中,再依次取出相加
stack s1, s2;
while (l1) {
//1.把l1中所有数字压入栈s1中
s1.push(l1 -> val);
l1 = l1 -> next;
}
while (l2) {
//2.把把l2中所有数字压入栈s2中
s2.push(l2 -> val);
l2 = l2 -> next;
}
int carry = 0;
ListNode* ans = nullptr;//用于储存最后返回的值
while (!s1.empty() or !s2.empty() or carry != 0) {
int a = s1.empty() ? 0 : s1.top();
int b = s2.empty() ? 0 : s2.top();
if (!s1.empty()) s1.pop();
if (!s2.empty()) s2.pop();
int cur = a + b + carry;
carry = cur / 10;
cur %= 10;
auto curnode = new ListNode(cur);
curnode -> next = ans;
ans = curnode;
}
return ans;
}
};
2.2稀疏多项式的计算
稀疏多项式的次幂跳度往往很大,这时如果再按照每个次幂来记录对应系数会有大量的0,比较浪费空间。这时我们采用(系数,指数)来记录多项式。
用一个长度为m且每个元素由两个数据线(系数项和指数项)的线性表。和多项式的计算其实差不多,不过原来简单多项式的线性表元素是单个数,稀疏多项式用的是(m,n)这样的数对。
具体的代码在后面介绍(c++中有个很好的结构叫做(pair)键值对,在树的对应章节会介绍)
2.3图书信息管理系统
出版社有一些图书数据保存在一个文本文件 book . txt 中,为简单起见,在此假设每种图书只包括三部分信息: ISBN (书号)、书名和价格,文件中的部分数据如图2.1所示。现要求实现一个图书信息管理系统,包括以下6个具体功能。
(1)查找:根据指定的 ISBN 或书名查找相应图书的有关信息,并返回该图书在表中的位置序号。(2)插人:插入一种新的图书信息。
(3)删除:删除一种图书信息。
(4)修改:根据指定的 ISBN ,修改该图书的价格。
(5)排序:将图书按照价格由低到高进行排序。
(6)计数:统计图书表中的图书数量。
要实现上述功能,与以上案例中的多项式一样,我们首先根据图书表的特点将其抽象成一个线性表,每本图书作为线性表中一个元素,然后可以采用适当的存储结构来表示该线性表,在此基础上设计完成有关的功能算法。具体采取哪种存储结构,可以根据两种不同存储结构的优缺点,视实际情况而定。
具体代码实现会在后面单独的一篇博文给出
3.线性表的类型定义
说明:
(1)出翔数据类型进士一个模型的定义,不涉及模型的具体实现(不是某种语言的代码实现),下面描述的所涉及参数不考虑具体数据类型;
(2)下面抽象数据类型中给出的操作只是基本的操作。
ADT List{
数据对象:D={ai|ai∈ElemSet,i=1,2,...n,n≥0}
数据操作关系:R={,ai∈D,i=2,...,n}
基本操作;
InitList(&L)
操作结果:构造一个空的线性表L(初始化)
DestoryList(&L)
初始条件:线性表L已经存在
操作结果:销毁线性表L
ClearList(&L)
初始条件:线性表L已经存在
操作结果:将线性表L重置为空表
ListEmpty(L)
初始条件:线性表L已经存在
操作结果:若线性表L为空表,返回true,若不是,返回false
ListLength(L)
初始条件:线性表L已经存在
操作结果:返回线性表L中数据元素个数
GetElem(L,i,&e)
初始条件:线性表L已经存在,且1≤i≤ListLength(L)
操作结果:用e返回L中第i个数据元素的值
LocateElem(L,e)
初始条件:线性表L已经存在
操作结果:用e返回L中第1个和e相同的元素在L中的位置。若这样的值不存在,则返回值为空值
ProirElem(L,cur_e,&pre_e)
初始条件:线性表L已经存在
操作结果:若cur_e是L的数据元素,且不是第一个,则用pre_e返回其前驱,否则操作失败,pre_e无定义
NextElem(L,cur_e,&next_e)
初始条件:线性表L已经存在
操作结果:若cur_e是L的数据元素,且不是最后一个,则用next_e返回其前驱,否则操作失败,next_e无定义
ListInsert(&L,i,e)
初始条件:线性表L已经存在且1≤i≤ListLength(L)
操作结果:在L中的第i个位置之前按插入新的元素e,L的长度+1.
ListDelete(&L,i)
初始条件:线性表L已经存在且非空,且1≤i≤ListLength(L)
操作结果:删除L中的第i个位置的元素,L的长度-1.
TraverseList(L)
初始条件:线性表L已经存在
操作结果:对线性表L进行遍历,在遍历过程中对L的每个元素访问一次。
4.线性表的顺序表示和实现
4.1线性表的顺序储存表示
定义:用一组地址连续的存储单元一次存储线性表的数据元素,这种表示方法也称作顺序储存结构或顺序映像。通常,称这种存储结构的线性表为顺序表
特点:逻辑上相邻的元素,物理位置上也相邻。
在c语言中可以用动态分配的一维数组来表示线性表,描述如下
#define N 200
typedef int SLDataType;
struct SeqList
{
SLDataType *elem; //存储空间的基地址
int length; //当前长度
}SqList; //顺序表的结构类型为SqList
4.2顺序表中基本操作的实现
//顺序表中基本操作的实现
//初始化
bool InitList(SeqList& L)
{
L.elem = new SLDataType[N];
if (!L.elem) exit(-1);
L.length = 0;
return true;
}
//取值
bool GetElem(SeqList L, int i, SLDataType& e) {
if (i<1 || i>L.length) return false;
e = L.elem[i - 1];
return true;
}
//查找
int LocateElem(SeqList L,SLDataType e)
{
for (int i = 0;i < L.length;i++)
{
if (L.elem[i] == e)
return i + 1;
}
return 0;
}
//插入
bool ListInsert(SeqList& L, int i, SLDataType e)
{
if ((i < 1) || (i > L.length + 1))return false;
if (L.length == N) return false;
for (int j = L.length - 1;j >= i - 1;j++)
{
L.elem[j + 1] = L.elem[j];
L.elem[i - 1] = e;
L.length++;
return true;
}
}
//删除
bool ListDelete(SeqList& L, int i)
{
if ((i < 1) || (i > L.length)) return false;
for (int j = i;j <= L.length - 1;j++)
{
L.elem[j - 1] = L.elem[j];
L.length--;
}
return true;
}5.线性表的链式表现和实现
静态顺序表存在一个问题:N太小,可能不够用,N太大,可能浪费空间,所以很多时候链式线性表更为常用。
5.1单链表的定义和实现
特点:用一组任意的春初单元存储线性表的数据元素
定义:
//1.定义
typedef int SLDataType;
typedef struct LNode {
SLDataType data; /*数据域*/
struct LNode* next; /*指针域*/
}LNode,*LinkList;5.2单链表的基本操作实现
//2.初始化
bool InitList(LinkList& L)
{
L = new LNode;
L->next = NULL;
return true;
}
//3.取值
bool GetElem(LinkList L,int i, SLDataType& e)
{
LNode *p = L->next;
int j = 1;
while (p && j < i)
{
p = p->next;
j++;
}
if (!p || j > i)
return false;
e = p->data;
return true;
}
//4.查找
LNode* LocateElem(LinkList L, SLDataType e)
{
LNode* p = L->next;
while (p && p->data != e)
{
p = p->next;
}
return p;
}
//5.插入
bool ListInsert(LinkList L,int i,SLDataType e)
{
LNode* p = L;int j = 0;
while (p && (j < i - 1))
{
p = p->next;
j++;
}
if (!p || j > i - 1)
return false;
LNode* s = new LNode;
s->data = e;
s->next = p->next;
p->next = s;
return true;
}
//6.删除
bool ListDelete(LinkList& L, int i)
{
LNode* p = L;
int j = 0;
while ((p->next) && j < i - 1)
{
p = p->next;j++;
}
if (!p || j > i - 1)
return false;
}
//前插法创建单链表
void CreateList_H(LinkList& L, int n)
{
L = new LNode;
L->next = NULL;
for (int i = 0;i < n;i++)
{
LNode* p = new LNode;
cin >> p->data;
p->next = L->next;
L->next = p;
}
}
//后插法创建新链表
void CreateList_R(LinkList& L, int n)
{
LNode* L = new LNode;
LinkList r = L;
for (int i = 0;i < n;++i)
{
LNode *p = new LNode;
cin >> p->data;
p->next = NULL;r->next = p;
r = p;
}
}
5.3循环链表
特点:表中最后一个节点的指针域指向头结点
操作与单链表基本类似。
区别:遍历链表的判别条件不同,为 p!=NULL或者p->next!=NULL;
5.4双向链表
✍双向链表几乎和单向列表一样。唯一的不同是每一个节点都要两个指针。与单向列表相同的是他的继承点都指向下一个节点(如果存在)。但是每个节点有一个额外的指针指向前面的一个节点(如果存在)。
使用这个额外的指针能够让我们从链表的末尾开始向前迭代,但是这样会使用两倍的内存。但是他的好处是我们会很容易的搜索,插入或者 删除比较靠后的节点,其时间复杂度是O(1)。如果用单向列表做那么时间复杂度为O(n)。
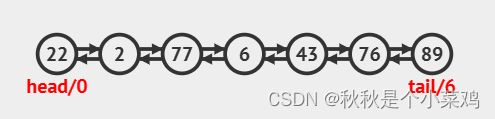
不带头结点的单链表是链表的最简单的一种结构,最复杂的一种结构是带有头结点的双向循环链表。
#pragma once
#include
#include
#include
#include
typedef int LTDataType;
typedef struct ListNode
{
struct ListNode* next; //指向直接前驱
struct ListNode* prev; //指向直接后继
LTDataType data; //数据域
}LTNode;
LTNode* BuyListNode(LTDataType x)
{
LTNode* node = (LTNode*)malloc(sizeof(LTNode));
if (node == NULL)
{
perror("malloc fail");
exit(-1);
}
node->data = x;
node->next = NULL;
node->prev = NULL;
return node;
}
//void ListInit(LTNode** pphead)
//{
// *pphead = BuyListNode(-1);
// (*pphead)->next = *pphead;
// (*pphead)->prev = *pphead;
//}
LTNode* ListInit()
{
LTNode* phead = BuyListNode(-1);
phead->next = phead;
phead->prev = phead;
return phead;
}
void ListPrint(LTNode* phead)
{
assert(phead);
LTNode* cur = phead->next;
while (cur != phead)
{
printf("%d ", cur->data);
cur = cur->next;
}
printf("\n");
}
void ListPushBack(LTNode* phead, LTDataType x)
{
assert(phead);
/*LTNode* newnode = BuyListNode(x);
LTNode* tail = phead->prev;
tail->next = newnode;
newnode->prev = tail;
newnode->next = phead;
phead->prev = newnode;*/
ListInsert(phead, x);
}
void ListPushFront(LTNode* phead, LTDataType x)
{
assert(phead);
//LTNode* newnode = BuyListNode(x);
//LTNode* next = phead->next;
phead newnode next
//phead->next = newnode;
//newnode->prev = phead;
//newnode->next = next;
//next->prev = newnode;
ListInsert(phead->next, x);
}
//void ListPushFront(LTNode* phead, LTDataType x)
//{
// assert(phead);
//
// LTNode* newnode = BuyListNode(x);
//
// phead->next->prev = newnode;
// newnode->next = phead->next;
//
// phead->next = newnode;
// newnode->prev = phead;
//}
void ListPopBack(LTNode* phead)
{
assert(phead);
assert(phead->next != phead);
//assert(!ListEmpty(phead));
/*LTNode* tail = phead->prev;
LTNode* tailPrev = tail->prev;
free(tail);
tailPrev->next = phead;
phead->prev = tailPrev;*/
ListErase(phead->prev);
}
void ListPopFront(LTNode* phead)
{
assert(phead);
assert(phead->next != phead);
ListErase(phead->next);
}
bool ListEmpty(LTNode* phead)
{
assert(phead);
return phead->next == phead;
}
// 在pos位置之前插入x
void ListInsert(LTNode* pos, LTDataType x)
{
assert(pos);
LTNode* prev = pos->prev;
LTNode* newnode = BuyListNode(x);
// prve newnode pos
prev->next = newnode;
newnode->prev = prev;
newnode->next = pos;
pos->prev = newnode;
}
// 删除pos位置的节点
void ListErase(LTNode* pos)
{
assert(pos);
LTNode* prev = pos->prev;
LTNode* next = pos->next;
prev->next = next;
next->prev = prev;
free(pos);
} 6.顺序表和链表的比较
6.1空间性能
(1)储存空间的比较
顺序表的存储空间必须预先分配,元素个数扩充受到一定限制,易造成存储空间的浪费或者空间一处现象。链表则不需要预先分配空间,对空间的利用更充分。
(2)存储密度的大小
存储密度=数据元素本身所占存储量/节点结构占用的存储量。如果不考虑
6.2时间性能
(1)存取性能的比较
顺序表---O(1) 链表---O(n)
(2)删除和插入
顺序表---O(n) 链表---O(1)
7.线性表的应用
7.1线性表的合并
可以参考这个题目的练习
1669. 合并两个链表 - 力扣(Leetcode)
class Solution {
public:
ListNode* mergeInBetween(ListNode* list1, int a, int b, ListNode* list2) {
ListNode* preA = list1;
for (int i = 0; i < a - 1; i++) {
preA = preA->next;
}
ListNode* preB = preA;
for (int i = 0; i < b - a + 2; i++) {
preB = preB->next;
}
preA->next = list2;
while (list2->next != nullptr) {
list2 = list2->next;
}
list2->next = preB;
return list1;
}
};
7.2有序表的合并
21. 合并两个有序链表 - 力扣(Leetcode)
class Solution {
public:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
if (l1 == NULL) {
return l2;
}
if (l2 == NULL) {
return l1;
}
if (l1->val <= l2->val) {
l1->next = mergeTwoLists(l1->next, l2);
return l1;
}
l2->next = mergeTwoLists(l1, l2->next);
return l2;
}
};8.小结