17.网络爬虫—Scrapy入门与实战
这里写目录标题
- Scrapy基础
- Scrapy运行流程原理
-
- Scrapy的工作流程
- Scrapy的优点
- Scrapy基本使用(豆瓣网为例)
-
-
- 创建项目
- 创建爬虫
- 配置爬虫
- 运行爬虫
- 如何用python执行cmd命令
- 数据解析
- 打包数据
- 打开管道
-
- pipeline使用注意点
-
- 后记
前言:
️️个人简介:以山河作礼。
️️:Python领域新星创作者,CSDN实力新星认证
第一篇文章《1.认识网络爬虫》获得全站热榜第一,python领域热榜第一。
第四篇文章《4.网络爬虫—Post请求(实战演示)》全站热榜第八。
第八篇文章《8.网络爬虫—正则表达式RE实战》全站热榜第十二。
第十篇文章《10.网络爬虫—MongoDB详讲与实战》全站热榜第八,领域热榜第二
第十三篇文章《13.网络爬虫—多进程详讲(实战演示)》全站热榜第十二。
第十四篇文章《14.网络爬虫—selenium详讲》测试领域热榜第二十。
第十六篇文章《网络爬虫—字体反爬(实战演示)》全站热榜第二十五。
《Python网络爬虫》专栏累计发表十六篇文章,上榜七篇。欢迎免费订阅!欢迎大家一起学习,一起成长!!
悲索之人烈焰加身,堕落者不可饶恕。永恒燃烧的羽翼,带我脱离凡间的沉沦。
Scrapy基础
Scrapy是一个用于爬取网站数据和提取结构化数据的Python应用程序框架。Scrapy的设计是用于Web爬虫,也可以用于提取数据和自动化测试。
Scrapy提供了一个内置的HTTP请求处理器,可以通过编写自定义的中间件来扩展其功能。Scrapy使用Twisted事件驱动框架,可以同时处理数千个并发请求。
Scrapy的主要组件包括:
ScrapyEngine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到Responses交还给ScrapyEngine(引擎),由引擎交给Spider来处理。Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。Downloader Middlewares(下载中间件):一个可以自定义扩展下载功能的组件。Spider Middlewares(Spider中间件):一个可以自定扩展和操作引擎和Spider中间通信的功能组件。
Scrapy运行流程原理
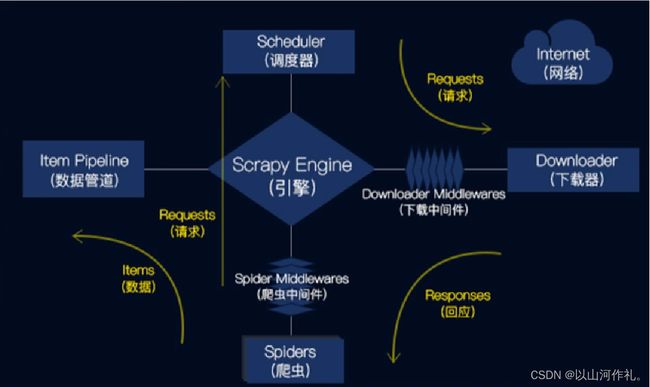
Scrapy的工作流程
1.引擎从爬虫的起始URL开始,发送请求至调度器。
2.调度器将请求放入队列中,并等待下载器处理。
3.下载器将请求发送给网站服务器,并下载网页内容。
4.下载器将下载的网页内容返回给引擎。
5.引擎将下载的网页内容发送给爬虫进行解析。
6.爬虫解析网页内容,并提取需要的数据。
7.管道将爬虫提取的数据进行处理,并保存到本地文件或数据库中。
Scrapy的优点
1.高效:Scrapy使用Twisted事件驱动框架,可以同时处理数千个并发请求。
2.可扩展:Scrapy提供了丰富的扩展接口,可以通过编写自定义的中间件来扩展其功能。
3.灵活:Scrapy支持多种数据格式的爬取和处理,包括HTML、XML、JSON等。
4.易于使用:Scrapy提供了丰富的文档和示例,可以快速入门。
Scrapy基本使用(豆瓣网为例)
安装scrapy模块:
pip install Scrapy
创建项目
选择需要创建项目的位置
进入cmd命令窗口(win+r),或者pycharm中打开终端也可以。
第一种方式:
第二种方式:
进入到需要创建文件的盘符,在命令窗口使用命令(C:/D:/E:/F:)进入对应的盘符

进入需要创建的路径:cd 路径
cd D:\新建文件夹\pythonProject1\测试\scrapy入门
![]()
当输入命令的前面部分出现对应的路径,代表进入成功

检测scrapy是否成功,直接输入scrapy按确认,
注意:如果没有成功(需要配置pip的环境变量,检测scrapy是否下载成功,是否安装到了其他的解释器中)
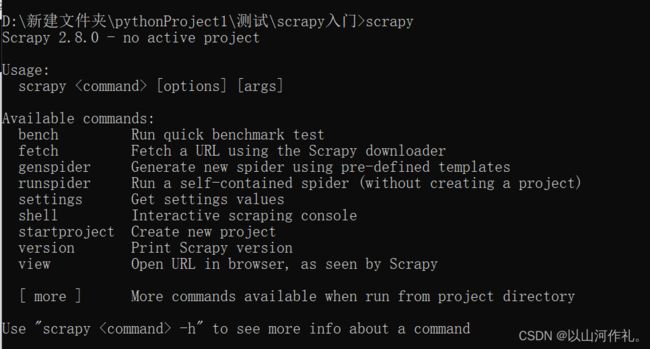
创建项目,使用命令在命令窗口输入:
scrapy startproject douban # douban是项目的名称
确认输入的命令后,会在当前路径下创建一个项目,以下为成功案例:

New Scrapy project 'douban', using template directory 'D:\Python3.10\Lib\site-packages\scrapy\templates\project', created in:
D:\新建文件夹\pythonProject1\测试\scrapy入门\douban
You can start your first spider with:
cd douban
scrapy genspider example example.com
创建完成后,如果没有出现文件,进行刷新即可

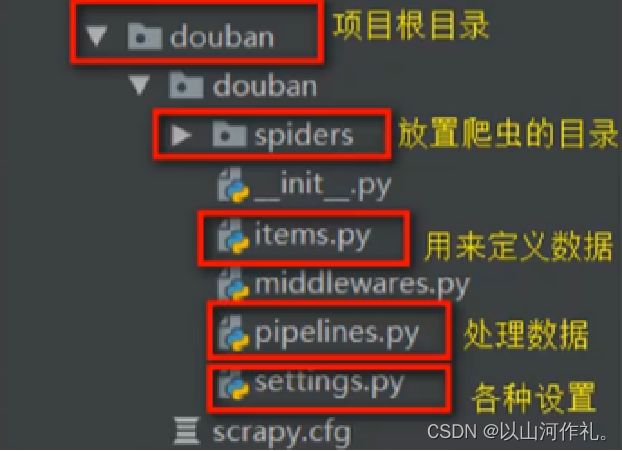
创建爬虫
进入到spiders文件下创建创建爬虫文件
cd 到spiders文件下
例如:
cd douban\douban\spiders
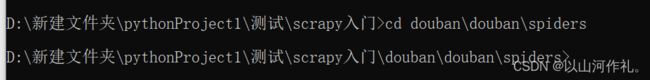
创建爬虫 命令:
[scrapy genspider 爬虫的名称 爬虫网站]
爬虫的名称不能和项目名称一样
爬虫的网站是主网站即可
成功后返回如下
Created spider 'douban_data' using template 'basic' in module:
{spiders_module.__name__}.{module}
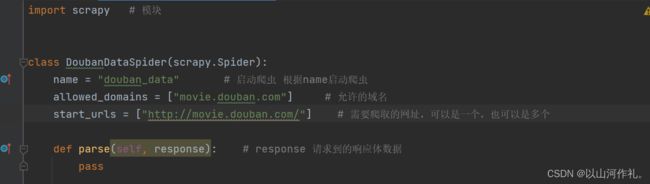
配置爬虫
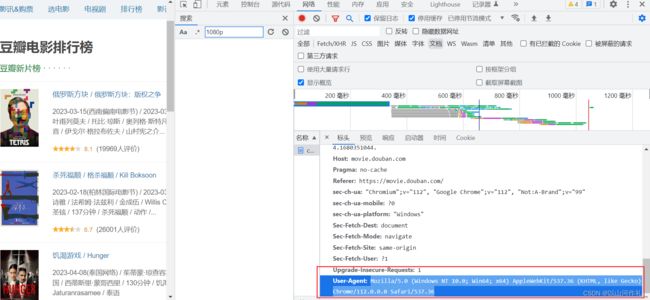
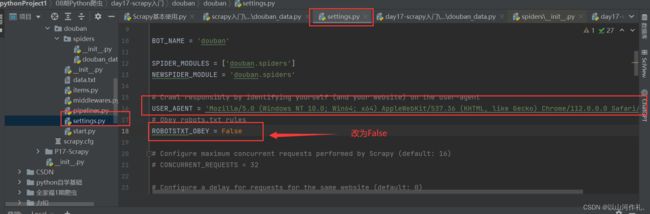
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
运行爬虫
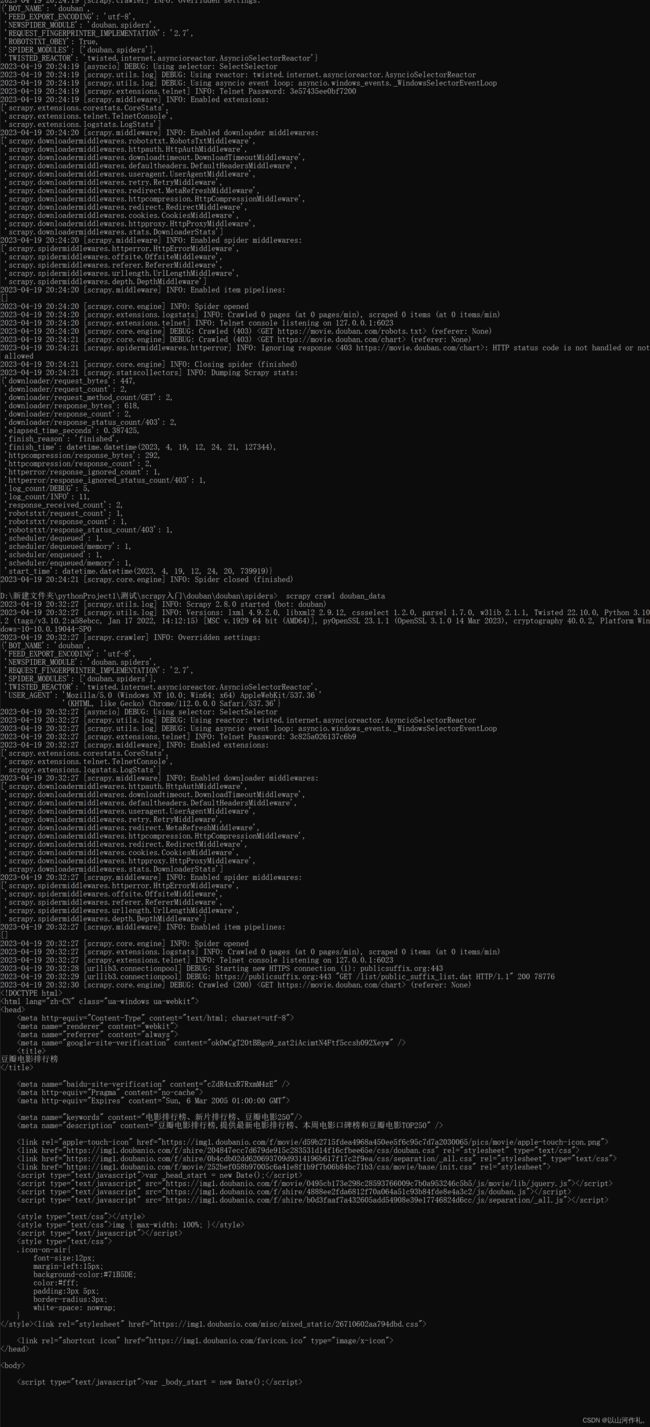
启动爬虫文件 scarpy crawl 爬虫名称
例如
scrapy crawl douban_data
运行结果:
如何用python执行cmd命令
终端获取的数据无法进行搜索,所以我们使用python的模块来运行cmd命令,获取相同的数据,方便我们数据的搜索和筛选。
我们创建一个start的py文件,帮助我们运行程序:
方法/步骤:
- 打开编辑器,导入python的os模块
- 使用os模块中的system方法可以调用底层的cmd,其参数
os.system(cmd) - sublime编辑器执行快捷键Ctrl+B执行代码,此时cmd命令执行
代码如下:
# 'scrapy crawl douban_data'
import os
os.system('scrapy crawl douban_data')
运行结果(展示部分内容):
红色不是报错,是日志文件,日志输出也是红色。

数据解析
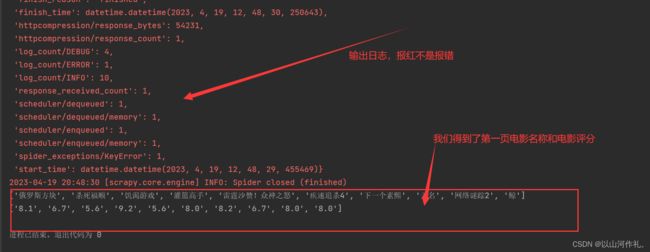
我们需要对全部数据进行分析,拿到我们想到的数据,电影名称和电影评分:
title = re.findall('', response.text)
print(title)
nums = re.findall('', response.text)
print(nums)
打包数据
# 打包数据 /在items中定义传输数据的结构(结构可以定义,或者不进行定义)
item = DoubanItem()
# 需要将一条数据存入到字典中
for title, nums in zip(title, nums):
item['title'] = title
item['nums'] = nums
yield item
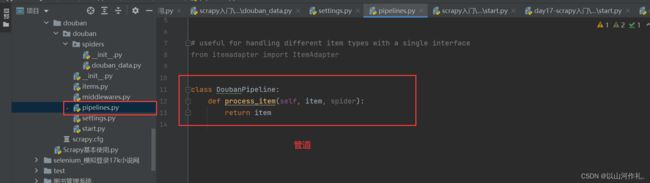
打开管道
解除注释,打开管道

pipeline使用注意点
1. 使用之前需要在settings中开启
2. pipeline在setting中键表示位置(即pipeline在项目中的位置可以自定义),值表示距离引擎的远近,越近数据会越先经过:权重值小的优先执行
3. 有多个pipeline的时候,process_item的方法必须return item,否则后一个pipeline取到的数据为None值
4. pipeline中process_item的方法必须有,否则item没有办法接受和处理
5. process_item方法接受item和spider,其中spider表示当前传递item过来的spider
6. open_spider(self, spider) :能够在爬虫开启的时候执行一次
7. close_spider(self, spider) :能够在爬虫关闭的时候执行一次
8. 上述俩个方法经常用于爬虫和数据库的交互,在爬虫开启的时候建立和数据库的连接,在爬虫关闭的时候断开和数据库的连接
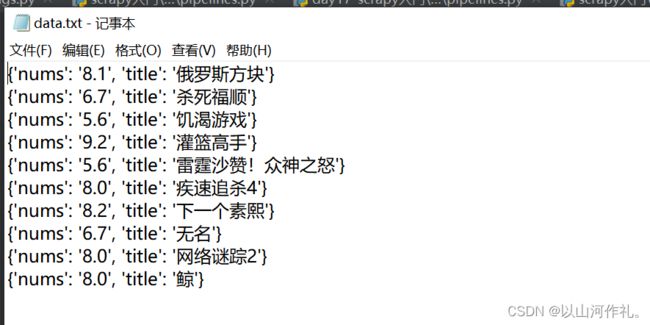
打开管道将数据写入txt文件中
class DoubanPipeline:
def __init__(self):
self.f = open('data.txt', 'w+', encoding='utf-8')
def process_item(self, item, spider):
self.f.write(f'{item}\n')
return item
def close_spider(self, spider):
self.f.close()
print('文件写入完成')
运行结果:
后记
本专栏所有文章是博主学习笔记,仅供学习使用,爬虫只是一种技术,希望学习过的人能正确使用它。
博主也会定时一周三更爬虫相关技术更大家系统学习,如有问题,可以私信我,没有回,那我可能在上课或者睡觉,写作不易,感谢大家的支持!!