Ubuntu18.04下配置hadoop完全分布式集群
集群配置信息:

目录
1准备工作
1.1克隆三台虚拟机
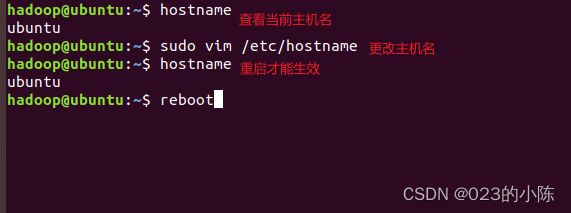
1.1.1更改主机名
1.1.2配置静态ip
1.1.3更改主机映射
1.1.4配置ssh
1.2安装jdk和hadoop并配置环境变量
2配置集群信息
2.1修改core-site.xml
2.2HDFS的配置文件:
2.3 配置YARN文件
2.4 配置MapReduce文件
2.5 配置slaves文件
3集群启动
1准备工作
1.1克隆三台虚拟机
更改每台虚拟机的主机名,映射,用户名,配置静态ip,配置ssh(三台节点用户名都是hadoop,主机名分别是hadoop200、201、202)
1.1.1更改主机名
![]()
1.1.2配置静态ip
ubuntu18.04开始不采用在/etc/network/interfaces里固定IP的配置
而是改成netplan方式网卡配置文件路径在:/etc/netplan/01-network-manager-all.yaml
# Let NetworkManager manage all devices on this system
network:
version: 2
renderer: NetworkManager
ethernets:
ens33: #配置的网卡名称,使用ifconfig -a查看得到
dhcp4: no #dhcp4关闭
addresses: [192.168.74.200/24] #设置本机IP及掩码,这里的24一定要加,IP地址在该网段下可以ping一下想要设置的ip看是否被使用
gateway4: 192.168.74.2 #设置网关,可以用route -n查看,这里一定要写对,不然·ping不通外网
nameservers:
addresses: [8.8.8.8, 114.114.114.114] #设置DNS,dns可以自己找常用的
之后重启就配置好了
1.1.3更改主机映射
sudo vim /etc/hosts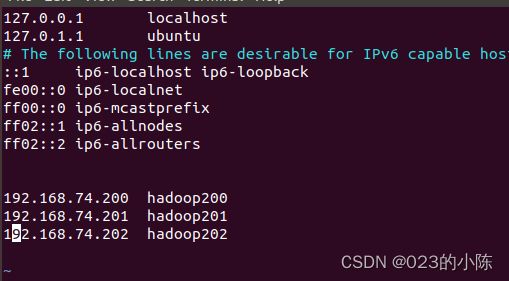
之后可以通过ping 各个主机名看是否配置好:如下图
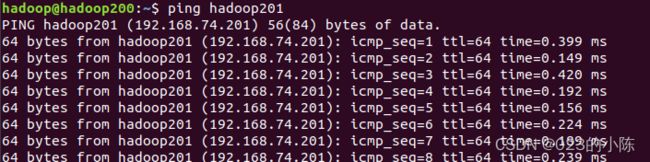
如果失败了可以关闭防火墙试试
1.1.4配置ssh
说明一下:有NameNode和ResourceManager的节点都要配置ssh,并把公匙分发给其他节点,并且还需要把公匙分给自己。
准备前提:每台节点上先安装:
sudo apt-get install openssh-server在hadoop200上ssh:
ssh-keygen -t rsa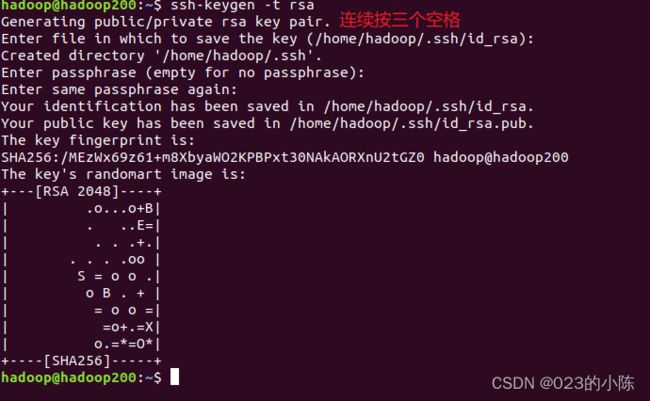
把公匙放在自己上:
ssh-copy-id hadoop200把公匙放在其他节点上:
ssh-copy-id hadoop201
ssh-copy-id hadoop202之后检查是否成功配置免密码登录其他主机:
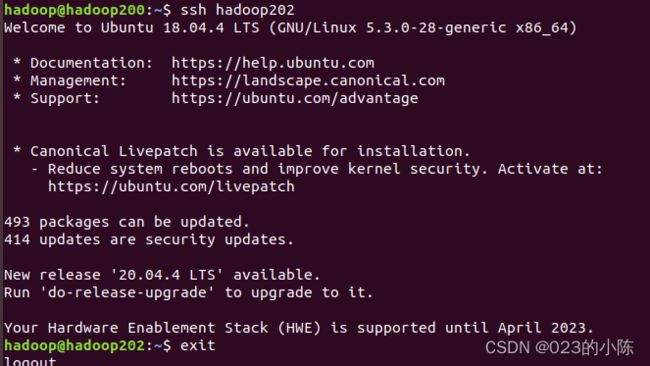
在有ResourceManager节点(hadoop201)也同样操作一遍
这样就实现了有NameNode和ResourceManager的节点的主机可以免密码登录其他主机了
1.2安装jdk和hadoop并配置环境变量
在hadoop200上:
首先把jdk和hadoop解压到/usr/local
然后配置环境变量:
sudo vim ~/.bashrc
#配置jdk环境变量
export JAVA_HOME=/usr/local/jdk
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=$PATH:${JAVA_HOME}/bin
#配置hadoop环境变量
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
然后记得source ~/.bashrc时环境变量生效
然后jdk和hadoop解压后的文件通过rsync命令同步到其他节点上
sudo rsync -rvl /usr/local/ hadoop@hadoop202:/usr/local之后要将~/.bashrc文件也要同步到其他节点上:
sudo rsync -rvl ~/.bashrc hadoop@hadoop201:~/.bashrc之后别忘了给其他节点上source ~/.basrc一下,使环境变量生效
2配置集群信息
需要修改这些配置文件:
在hadoop200上:
2.1修改core-site.xml
<--!配置NameNode位置-->
fs.defaultFS
hdfs://hadoop200:9000
<--!配置hadoop运行时产生文件的存储位置-->
hadoop.tmp.dir
file:/usr/local/hadoop/tmp
2.2HDFS的配置文件:
配置hadoop-env.sh
export JAVA_HOME=/usr/local/jdk配置hdfs-site.xml
dfs.namenode.secondary.http-address
hadoop202:50090
dfs.replication
3
dfs.namenode.name.dir
file:/usr/local/hadoop/tmp/dfs/name
dfs.datanode.data.dir
file:/usr/local/hadoop/tmp/dfs/data
2.3 配置YARN文件
配置yarn-env.sh
export JAVA_HOME=/usr/local/jdk配置yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop201
2.4 配置MapReduce文件
配置mapred-env.sh
export JAVA_HOME=/usr/local/jdk配置mapred-site.xml
mapreduce.framework.name
yarn
2.5 配置slaves文件
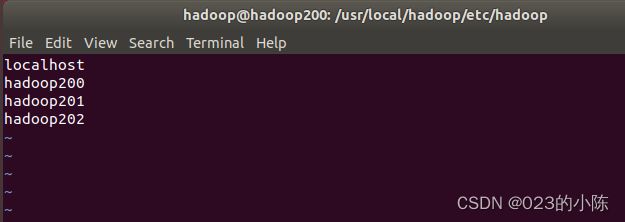
记住不要有多余的空格,不然会出错
只要配置有DataNode的节点都写进去
3集群启动
首先通过rsync将修改的配置文件同步到其他节点
rsync -rvl /usr/local/hadoop/etc/hadoop/ hadoop@hadoop201:/usr/local/hadoop/etc/hadoop
然后开启集群群起:
记住在格式化NameNode之前应该把每个节点上的/usr/local/hadoop下的logs文件和tmp(在core-site.xml自己定义的存储hadoop运行时产生的数据文件)文件删除掉,如果这两个文件存在时。
格式化namenode
![]()
然后启动怎个集群:
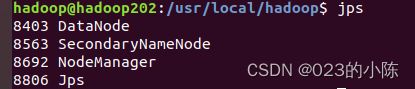
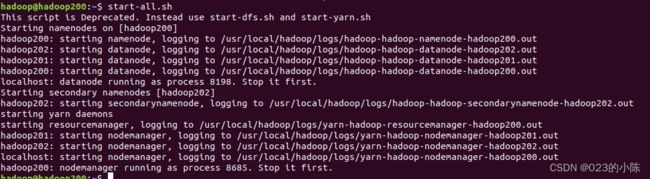 之后可以查看一下每个节点是否配置成功:
之后可以查看一下每个节点是否配置成功:
这里有个坑:
启动start-dfs.sh要在配置NameNode的节点上运行
启动start-yarn.sh要在配置ResourceManager的节点上运行
最开始我直接start-all.sh结果出错了,ResourceManager就是启动不起来
这个问题可以参考:https://blog.csdn.net/weixin_43950862/article/details/114481146?ops_request_misc=&request_id=&biz_id=102&utm_term=java.net.BindException:%20Port%20i&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-1-114481146.142^v33^pc_rank_34,185^v2^control&spm=1018.2226.3001.4187
hadoop200节点:
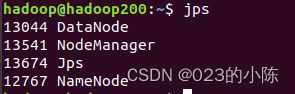
hadoop201:
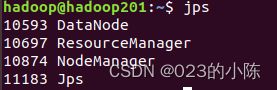
hadoop202: