python 文件处理(二):Excel相关的操作汇总 之 数据查询
Excel简介
要讲Excel的相关操作,首先我们要对Excel文件有个基本的了解。我们打开Excel进行编辑时会发现一个Excel文件下面会有很多个sheet供我们选择,如图所示:
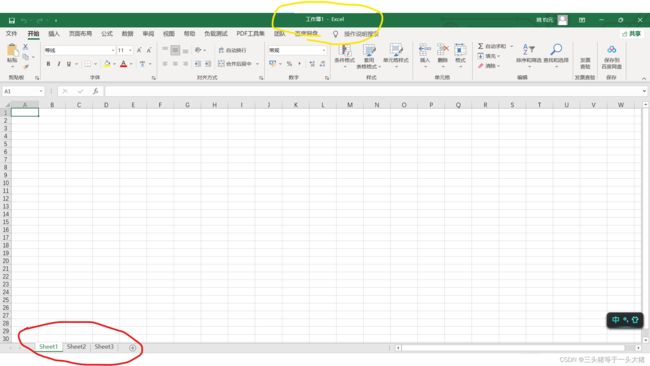
红色圈起来的地方就是我们实际数据输入的地方,叫做worksheet(工作表),而我们可以看到黄色圈起来的地方,也就是Excel文件的文件名是工作簿(workbook)。由此我们可以总结:一个workbook是由一个或多个worksheet组成的,因此在后面对Excel文件进行操作的时候,需要格外注意操作的对象是workbook还是worksheet。workbook和worksheet以及后面会讲到的单元格等等都是以对象的形式出现的。当我们获取了workbook,worksheet的时候,我们只需要将他们想象成一个个实例化的对象,会好理解一些。
注意,python对Excel进行操作时,要引用一个名为openpyxl的包,请提前下载哦(在cmd窗口输入 pip install openpyxl,如果不行的话百度一下,网上讲的很详细的)。
一、打开Excel工作簿和工作表
了解了Excel的基本结构之后,我们就要开始操作了。首先,打开工作簿:
openpyxl.load_workbook(file_path)
(file_path假如和工作目录一样则直接写文件名,假如不一样,则写文件名的绝对路径,或将工作目录改为和文件相同)【注意,此函数读取的是工作簿,不是工作表!!】
当单元格中含有公式的时候,要加上data_only = True, 就像这样:openpyxl.load_workbook(file_path,data_only = True). 具体原因往下看,讲 二、单元格操作 的时候会讲到。
读取了workbook之后,我们需要知道workbook中含有哪些worksheet。workbook对象有一个名叫sheetnames的属性,使用sheetnames这个属性就可以获得workbook中的所有worksheet的名字,输出的是一个数组列表。需要注意的是,sheetnames不是函数,是属性名,所以调用它的时候不要像调用函数那样加括号!!
打开了工作簿,下一步就是获取具体的工作表:
wb[worksheet_name]
此处用wb表示上一步获取的workbook。
如果难理解的话,看了下面的例子就懂了
import os
import shutil
import openpyxl
os.chdir("D:\Python Code\阿巴阿巴") #改变工作目录到文件所在地址
wb = openpyxl.load_workbook("游戏.xlsx") #获取名为游戏的workbook
ws_name = wb.sheetnames
print(ws_name)
ws_HPJY = wb["和平精英"] #获取名为和平精英的worksheet
print("worksheet和平精英已获取")
输出结果:

二、单元格的查询
2.1对单个单元格的查询
获取了具体的worksheet,下一步就是对单元格的操作了。每个单元格对象其实也可以看做是worksheet自己的一个数据成员,只不过这个成员本身也是一个对象。因此, 我们获取到的一个单元格包含了两个重要的成员:key 和 value,也就是常说的 键——值 的格式。
单元格的key(键)就是正常使用表格时常数的几行几列的形式,如“C5”(C列5行),"E8"(E列8行)这样的字符串。那么怎么通过key值找到value呢,看下面这个例子就行。(同时,里面也提到了在上面讲获取workbook有时候要加data_only = True的原因。)
获取的表格如下,其中C6的2是使用公式A6+B6算出来的:
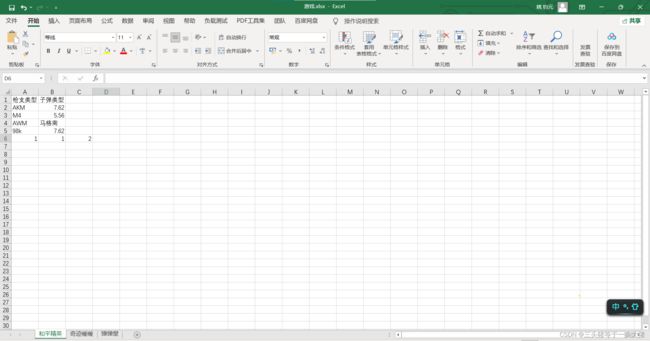
import os
import openpyxl
os.chdir("D:\Python Code\阿巴阿巴")
wb = openpyxl.load_workbook("游戏.xlsx")
ws_name = wb.sheetnames
print(ws_name)
ws_HPJY = wb["和平精英"]
bulletAKM_cell = ws_HPJY["B2"]
bulletAKM = ws_HPJY["B2"].value
value_1 = ws_HPJY["C6"].value
print(bulletAKM_cell) ############输出 |
print(bulletAKM) #################输出7.62
print(value_1) ###################输出 =A6+B6
wb = openpyxl.load_workbook("游戏.xlsx", data_only=True)
ws_HPJY = wb["和平精英"]
value_2 = ws_HPJY["C6"].value
print(value_2) ##################输出 2 | 注意:可以看到,在不添加data_only=True 的时候,直接输出含有公式的单元格的value只会输出公式。只有添加了data_only=True的时候才能正确输出想要的值。
2.2对单元格按行查询
worksheet对象本身还带有raws这个成员,ws.rows可以获得worksheet所有的行(ws代指worksheet),每一行为一个元组。
具体操作方式参考下面这个例子。值得注意的是,在获取每行第一个单元格的内容的时候,我们用的是raw[0].value 语句,而不是 raw['A'].value。为什么呢? 上面提过,由于for循环获得的每个raw其实是元组形式,所以获取元组里的信息当然是用数字啦。不过我们在实际操作中,表格不会只有这么一点点,往往会有很多列。观察表格会发现,第一行, A1-Z1结束后,接下来是AA1,BB1...,直接判断列号比较难,所以会用到
openpyxl.utils.cell.column_index_from_string()函数,
作用就是将表格中的列号ABCD转换为对应的数字1,2,3,4,不过元组的索引号是从0开始的,因此实际应用数据时我们要减一。
import os
import openpyxl
os.chdir("D:\Python Code\阿巴阿巴")
wb = openpyxl.load_workbook("游戏.xlsx", data_only=True)
ws_HPJY = wb["和平精英"]
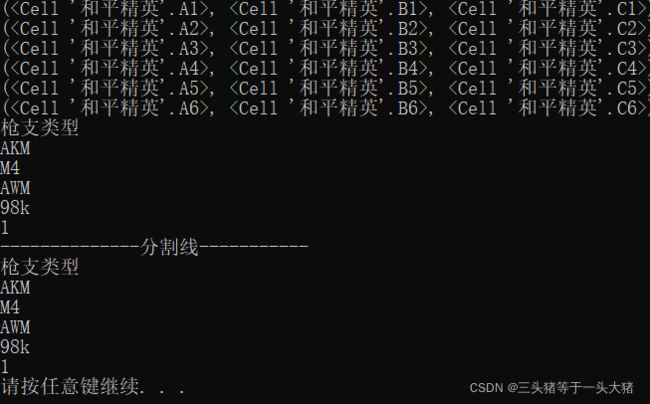
for raw in ws_HPJY.rows:
print(raw) ##########输出每一行的行对象
for raw in ws_HPJY.rows:
print(raw[0].value) ####获取每一行的第一个单元格的内容(也就是第一列 A列 的内容)
#########别忘了value哦!!!!!!!!!
print("--------------分割线-----------")
for raw in ws_HPJY.rows: ###########记得减一!!!
print(raw[openpyxl.utils.cell.column_index_from_string('A')-1].value)
##########列值的转换,输出结果其实是一样的。
输出结果:
OK,今天的Excel的数据查询就讲到这里,下一节我们会讲如何创建一个新的workbook,以及将数据录入其中。