KNN 实现数据分类
KNN算法:
邻近算法,或者说K最邻近(KNN,K-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是K个最近的邻居的意思,说的是每个样本都可以用它最接近的K个邻近值来代表。近邻算法就是将数据集合中每一个记录进行分类的方法。
算法思想:
给定已知的数据和标签,给定k值。给定新数据,那么怎么判断新数据为哪一类呢?
那就把新数据和已知的数据进行距离计算吧,这里要注意必须刻画成可计算的数值进行计算,通常采用欧氏距离,也就是我们初中学过的两点之间计算距离的方法。
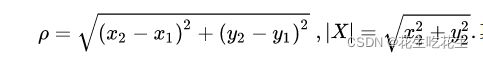
计算完的距离就是会有大有小吧,那么再根据大小进行排序。
再根据给定的K值,K值也就是取的次数了,换句话说,就是取距离新数据的最近的K个单位。
哪个种类在这K个单位中占比大,那么就将新数据分类为哪个种类。由此可知,这个K值会影响排序结果。
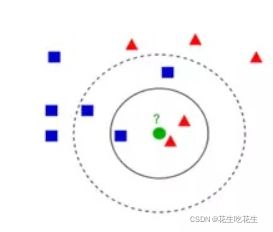
举例:若K取3,那么待分类数据(绿色)就属于三角形,因为三角行在就近的3个中占比大为2/3,
但是若K取5,那么待分类数据(绿色)就属于正方形了。
Python实现简单数据分类
import numpy as np
import matplotlib.pyplot as plt
import operator
def createDateSet():
# 数据集
group = np.array([
[1.0, 1.1],
[1.0, 1.0],
[0, 0],
[0, 0.1]
])
# 贴标签
labels = ['A', 'A', 'B', 'B']
return group, labels
# inX输入的数据,dataSet数据集,balels,标签,K:K值
def classify(inX, dataSet, labels, k):
# np.shape[0] 为第二维度的长度,第一维度为行,第二维度为列
# 拿到列数也就是4
# dataSetSize = 4
dataSetSize = dataSet.shape[0]
# np.tile()沿着x轴/或者y轴复制,或者x轴和y轴都复制,默认复制x轴。当有两个参数时,第一个为y轴复制倍数
# diffMat 即为两个矩阵之间的差矩阵
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet
# print('diffMat', diffMat)
sqDiffMat = diffMat ** 2
# print('sqDiffMat', sqDiffMat)
# axis为0的时候即每一列相加。axis = 1,的时候为每一行相加,再成为一个新的行
sqDistance = sqDiffMat.sum(axis=1)
distance = sqDistance ** 0.5
# 将元素从小到大排序,再取出索引
sortedDistanceIndex = distance.argsort()
# print('sortDistanceIndex', sortedDistanceIndex)
# 存放最终投票结果
classCount = {}
for i in range(k):
# 拿出对应索引对应的标签值
voteIlabel = labels[sortedDistanceIndex[i]]
# 统计标签出现的次数
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
# 将字典按照值进行排序,使用operator.itemgetter(1)取出字典的第一个域,字典两个域,一个0就是key,1就是value
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
# 返回标签
return sortedClassCount[0][0]
def show_data(group, labels):
labels = np.array(labels)
# 如果值为true 返回索引
# 拿到A和B的索引
index_a = np.where(labels == 'A')
# print(index_a)
index_b = np.where(labels == 'B')
# print(index_b)
for i in labels:
if i == 'A':
plt.scatter(group[index_a][:, :1], group[index_a][:, 1:2], c='red')
elif i == 'B':
plt.scatter(group[index_b][:, :1], group[index_b][:, 1:2], c='green')
plt.show()
if __name__ == '__main__':
# 导入数据
dataSet, labels = createDateSet()
# 新数据
inX = [0.6, 0.2]
# 分类
classify(inX, dataSet, labels, 3)
# 拿到分类结果标签
className = classify(inX, dataSet, labels, 3)
print("该数据属于{}类".format(className))
# 合并数据,纵向堆叠
dataSet = np.vstack((dataSet, inX))
# 添加标签
labels.append(className)
# print(dataSet, labels)
# 画图
show_data(dataSet, labels)
结果:
B类(绿色)
inX = [0.6,0.2]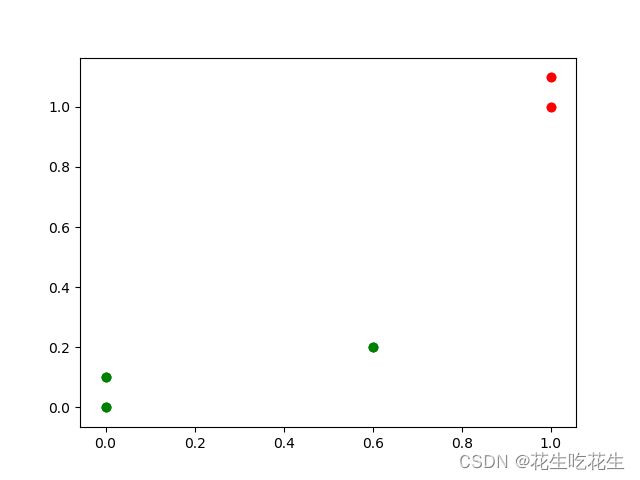
A类(红色)
inX = [1, 0.2] 
参考:KNN算法介绍 - 知乎