arm汇编和c语言程序设计,ARM汇编程序设计之: ARM汇编程序设计举例-嵌入式系统-与非网...
10.5 ARM汇编程序设计举例
在本节中通过一些例子来说明ARM中伪操作及指令的基本用法。
10.5.1 条件跳转及循环
1.ALU状态标志
所有ARM指令都可以条件执行。大部分ARM指令集和Thumb-2指令集的数据处理指令都可以选择是否根据指令的执行结果设置ALU的状态标志位。
注意
较早的ARM体系结构中使用的Thumb指令不能选择是否更新ALU的标志位。当数据处理指令执行完后,处理器自动根据指令的执行结果更新状态标志。
较早的Thumb-2指令只有跳转指令可以条件执行。新的体系结构中的Thumb-2指令可以IT(if-then)标识使程序条件执行。
更详细的介绍请参加本书的指令集部分。
2.ARM状态下的条件执行
在程序状态寄存器CPSR中保存着以下4个ALU状态标志。
· N:当指令的执行结果为负时,该位置1。
· Z:当指令的执行结果为零时,该位置1。
· C:当指令的执行结果有进位时,该位置1。
· V:当指令的执行结果溢出时,该位置1。
当加法操作的结果大于等于232或加法操作的结果为负时,进位标志C置位。
当加法、减法、比较操作结果大于等于231或小于-232时,溢出标志V置位。
在ARM指令后增加条件域可以使指令条件执行,各条件码的含义和助记符如表10.11所示。可条件执行的指令可以在其助记符的扩展域加上条件码助记符,从而在特定条件下执行。
表10.11 指令的条件码
条 件 码
助记符后缀
标 志
含 义
0000
EQ
Z置位
相等
0001
NE
Z清零
不相等
0010
CS
C置位
无符号数大于或等于
0011
CC
C清零
无符号数小于
0100
MI
N置位
负数
0101
PL
N清零
正数或零
0110
VS
V置位
溢出
0111
VC
V清零
未溢出
1000
HI
C置位Z清零
无符号数大于
1001
LS
C清零Z置位
无符号数小于或等于
1010
GE
N等于V
带符号数大于或等于
1011
LT
N不等于V
带符号数小于
1100
GT
Z清零且(N等于V)
带符号数大于
1101
LE
Z置位或(N不等于V)
带符号数小于或等于
1110
AL
忽略
无条件执行
默认情况下,ARM指令并不会更新ARM寄存器cpsr中的N、Z、C、V标志。对大多数指令,若要更新这些标志需要对指令助记符加后缀S。但CMP指令不需要S后缀就更新这些标志位。
下面的一段程序,说明了指令的S后缀和条件执行的过程。
ADD r0, r1, r2 ;r0 = r1 + r2,不更新标志位
ADDS r0, r1, r2 ;r0 = r1 + r2,并且更新标志位
ADDSCS r0, r1, r2 ;如果进位标志位C=1,r0 = r1 + r2,并且更新标志位
CMP r0, r1 ;根据 r0-r1的结果更新标志位
从上面的例子可以看出,无论更新标志位标志“S”是否设置,CMP指令自动更新标志位。
3.条件执行的例子
通过组合使用条件执行和条件标志设置,可是简单地实现分支语句,不需要任何分支指令。这样可以改善性能,因为分支指令会占用较多的周期数;同时这样做也可以减小代码尺寸,提高代码密度。
下面是一段C语言程序,该程序实现了著名的Euclid最大公约数算法。
int gcd(int a, int b)
{
while (a != b)
{
if (a > b)
a = a - b;
else
b = b - a;
}
return a;
}
用ARM汇编语言重写来重写这个例子,如下所示。
【程序1】
gcd CMP r0, r1
BEQ end
BLT less
SUB r0, r0, r1
B gcd
less
SUB r1, r1, r0
B gcd
End
充分地利用条件执行修改上面的例子,得到【程序2】。
【程序2】
gcd
CMP r0, r1
SUBGT r0, r0, r1
SUBLT r1, r1, r0
BNE gcd
【程序1】仅使用了分支指令,【程序2】充分利用了ARM指令条件执行的特点,仅使用了4条指令就完成了全部算法。这对提供程序的代码密度和执行速度十分有帮助。
事实上,分支指令十分影响处理器的速度。每次执行分支指令,处理器都会排空流水线,重新装载指令。
注意
新的ARM处理器如ARM10和StrongARM都有分支预测硬件。只有当分支预测硬件失败时,处理器才排空流水线,重新装载指令。
表10.12和10.13分别总结了【程序1】和【程序2】在ARM7上的执行过程(假设r0=1、r1=2)。
表10.12 程序1执行过程
r0:a
R1:b
指 令
执行周期(ARM7)
1
2
CMP r0, r1
1
1
2
BEQ end
1 (未执行)
1
2
BLT less
3
1
2
SUB r1, r1, r0
1
1
2
B gcd
3
1
1
CMP r0, r1
1
1
1
BEQ end
3
Total = 13
表10.13 程序2执行过程
r0:a
R1:b
指 令
执行周期(ARM7)
1
2
CMP r0, r1
1
1
2
SUBGT r0,r0,r1
1 (未执行)
1
1
SUBLT r1,r1,r0
1
1
1
BNE gcd
3
1
1
CMP r0,r1
1
1
1
SUBGT r0,r0,r1
1 (未执行)
1
1
SUBLT r1,r1,r0
1 (未执行)
1
1
BNE gcd
1 (未执行)
Total = 10
从上面的例子可以看出,利用条件执行执行可以实现大部分条件语句,比使用条件分支指令效率高很多。
10.5.2 传送指令程序设计
1.加载立即数
通常,使用MOV和MVN指令向寄存器加载常量,但由于单条MOV或MVN指令只能包含8位立即数,向寄存器加载立即数需要一些特殊的操作。
注意
在ARMv6T2体系结构及以上版本中,可以使用MOV32伪操作将一个32位立即数加载到寄存器。
下面分别介绍加载立即数的不同方法。
(1)使用MOV和MVN指令
在ARM或Thumb-2状态下,可以使用MOV和MVN指令将符合一定规则的常数加载到寄存器。在16位的Thumb指令下,可以将0~255的任意常数加载到寄存器。表10.14列出了在ARM状态下可直接加载到寄存器的立即数。
表10.14 ARM状态合法立即数
二 进 制
十 进 制
步骤
十六进制
MVN指令值
注释
000000000000000000000000abcdefgh
0~255
1
0~0xFF
-1~-256
0000000000000000000000abcdefgh00
0~1020
4
0~0x3FC
-4~-1024
00000000000000000000abcdefgh0000
0~4080
16
0~0xFF0
-16~-4096
000000000000000000abcdefgh000000
0~16320
64
0~0x3FC0
-64~-16384
...
...
...
...
abcdefgh000000000000000000000000
0~255×224
224
0~0xFF000000
1~256ד-224”
cdefgh000000000000000000000000ab
(bit pattern)
—
—
(bit pattern)
②
efgh000000000000000000000000abcd
(bit pattern)
—
—
(bit pattern)
②
gh000000000000000000000000abcdef
(bit pattern)
—
—
(bit pattern)
②
00000000000000000000abcdefghijkl
0~4095
1
0~0xFFF
—
③
注释
① 在ARM数据操作指令中,除MVN外,其他指令不能直接操作MVN的值,即MVN列所列出的立即数在其他数据操作指令中可能为非法操作数。
② 表中所列数据为ARM状态合法数据,对Thumb-2状态不一定适用。
③ 这些值只能在ARMv6T2体系结构及其以上版本中适用。
ARM状态下立即数的使用要符合以下规则。
① 每个立即数由一个8位的常数循环右移偶数位得到。
注意
这样得到的立即数对任何数据处理指令都是合法的。
② MVN指令向寄存器加载一个合法立即数的“按位反”,即-(n+1)。其中n为MOV指令可以加载的合法立即数。
③ ARMv6T2体系结构及其以上版本,可以加载12位的立即数,但MVN指令不能加载此12位立即数的“按位反”。
在ARMv6T2体系结构及其以上版本的Thumb状态下,可以加载的合法立即数有以下规则。
① 32位的MOV指令可以加载的立即数符合以下规则。
· 任意8位立即数(范围0x0~0xff)。
· 任意8位立即数向左移任意位。
· 任意8位立即数重复4次填充32位寄存器。
· 使用任意8位立即数填充一个32位寄存器的第0和第2字节,其余两个字节填充0。
· 使用任意8位立即数填充一个32位寄存器的第1和第3字节,其余两个字节填充0。
注意
通过上述方法得到的立即数,在其他数据操作指令中同样合法。
② MVN指令向寄存器加载一个合法立即数的“按位反”,即-(n+1)。其中n为MOV指令可以的加载的合法立即数。
③ 可以加载任意12位的立即数,但MVN指令不能加载此12位立即数的“按位反”。
表10.15列出了在Thumb-2状态下可直接加载到寄存器的立即数。
表10.15 Thumb状态合法立即数
二 进 制
十进制
步骤
十 六 进 制
MVN指令值
注释
000000000000000000000000abcdefgh
0~255
1
0~0xFF
-1 to -256
00000000000000000000000abcdefgh0
0~510
2
0~0x1FE
-2 to -512
0000000000000000000000abcdefgh00
0~1020
4
0~0x3FC
-4 to -1024
...
...
...
...
0abcdefgh00000000000000000000000
0~0x7F800000
abcdefgh000000000000000000000000
0~0xFF000000
abcdefghabcdefghabcdefghabcdefgh
(bit pattern)
-
0xXYXYXYXY
-
00000000abcdefgh00000000abcdefgh
(bit pattern)
-
0x00XY00XY
0xFFXYFFXY
abcdefgh00000000abcdefgh00000000
(bit pattern)
-
0xXY00XY00
0xXYFFXYFF
00000000000000000000abcdefghijkl
0~4095
1
0~0xFFF
-
①
(2)使用MOV32伪操作
ARMv6T2体系结构中,ARM和Thumb-2指令集包括下面两条数据传送指令。
· MOV指令:可以加载任意8位立即数到32位寄存器。
· MOVT指令:可以加载任意16位立即数(0x0~0xffff)到32寄存器的高16位或低16位,而不改变余下的位。
可以使用组合的MOV和MOVT指令加载任意32位立即数到寄存器,也可以使用伪操作MOV32实现上述两条指令的组合功能。汇编器在扫描源代码时,自动将伪操作MOV32编译成MOV加MOVT指令的组合。
(3)使用LDR伪操作
LDR Rd,=const伪操作可以将任意32位立即数加载到寄存器。可以使用此伪操作将超出MOV和MVN指令操作范围的立即数加载到寄存器。LDR的效率很高,如果立即数可以由指令中的表示,则汇编器生成相应的MOV或MVN指令;如果立即数不能由直接表示,则汇编器将该立即数放到一个缓冲池(literal pool),并生成一条将该缓冲池内容加载到目标寄存器的LDR指令。例如,
LDR rn, [pc, #offset to literal pool]
该指令从地址[pc, #offset to literal pool]向Rn寄存器加载一个字。因此,必须确保在该LDR指令的访问范围内,存在一个可用的缓冲池。汇编器会在每个段后面添加一个缓冲池。对于ARM指令集,计数器PC的偏移量必须小于4KB,对于Thumb指令,PC的偏移量必须小于1KB。通常,汇编器会在LDR伪操作后寻找可用的缓冲池,但是,如果LDR指令与默认缓冲池距离太远,则汇编器将会报错。此时必须在LDR指令上下4KB(Thumb为1KB)之间用LTORG伪操作显式地在代码段中添加缓冲池,而且由于缓冲池在代码段中,必须确保它不会被处理器作为指令而加以执行。通常将其紧跟在无条件跳转指令后面。
下面是使用LDR伪操作加载立即数的例子。
AREA Loadcon, CODE, READONLY
ENTRY ;函数入口
start BL func1 ;跳转到func1
BL func2 ;跳转到func2
stop MOV r0, #0x18 ;angel_SWIreason_ReportException为SWI调用准备参数
LDR r1, =0x20026 ;调用SWI的ADP_Stopped_ApplicationExit功能
SWI 0x123456 ;调用ARM semihosting SWI
func1
LDR r0, =42 ;将立即数42存入
LDR r1, =0x55555555
;将立即数0x55555555存入r1,该指令被编译为LDR R1,[PC,#offset]
LDR r2, =0xFFFFFFFF ;将0xFFFFFFFF存入r2
BX lr
LTORG ;缓存池 1 contains
;该缓存池中包含立即数Ox55555555
func2
LDR r3, =0x55555555
;将立即数存入r3,该伪操作被编译为LDR R3,[PC,#offset]
; LDR r4, =0x66666666 ;将立即数0x66666666存入r4
BX lr
LargeTable
SPACE 4200 ;申请4200字节的内存空间并初始化为零
END ;Literal Pool 2 is empty
(4)加载浮点常数
ARM体系结构中,允许加载单精度和双精度的浮点数。详细信息请参见FLD伪操作。
2.加载程序地址
通常在编写程序时需要加载程序地址。这些地址包括变量地址、字符串地址或程序跳转表的入口地址。这些地址通常是基于程序计数器PC或某个基址寄存器的偏移量。
下面分别介绍加载程序地址的不同方法。
(1)使用ADR和ADRL伪操作
使用ADR和ADRL伪操作可以直接向寄存器加载程序地址。ADR和ADRL伪操作的操作数可以是程序相关表达式,汇编器在编译时,将此表达式转换成相对PC或寄存器的偏移量加载到目标寄存器。
注意
ADR和ADRL伪操作所加载的地址是有一定限制的。加载的标号地址必须和当前指令在同一代码段内。如果加载的程序标号和当前指令不在同一代码段,汇编器将报错并中止汇编。另外在Thumb状态下,ADR伪操作只能产生字对齐的地址加载指令。
ADRL伪操作只能在ARM状态下使用。
ADR和ADRL伪操作(ADR rn,label或ADRL rn,label)所能加载的地址范围依赖使用的指令集。
下面列出了在不同指令集下,ADR伪操作所能加载的地址范围。
· ARM:在字节或半字节对齐的内存使用模式下,范围为±255字节。在字对齐的内存使用模式下,范围为±1020字节。
· 16位Thumb指令集:0~1020字节。Label必须是字对齐地址标号,可以和伪操作ALIGN配合使用。
· 32位Thumb-2指令集:±4095字节(无论标号label是字、半字还是字节对齐)。
下面列出了在不同指令集下,ADRL伪操作所能加载的地址范围。
· ARM:在字节或半字节对齐的内存使用模式下,范围为±64KB。在字对齐的内存使用模式下,范围为:±256KB。
· 16位Thumb指令集:ADRL伪指令不可用。
· 32位Thumb-2指令集:±1M字节(无论标号label是字、半字还是字节对齐)。
汇编过程中,汇编器将伪指令ADR编译成一条ADD或SUB指令,如果一条指令不能完成伪操作的功能,编译器将报错。ADRL伪操作被编译器编译成两条数据处理指令,详细信息参见ARM伪操作一节。
下面的程序使用ADR伪操作加载了跳转表的入口地址,成功地实现了程序跳转。
AREA Jump, CODE, READONLY ;将该子程序命名为Name
CODE32 ;下面的代码为ARM代码
num EQU 2 ;要查找的跳转表入口号
ENTRY ;程序入口
start ;程序指令开始
MOV r0, #0 ;为程序跳转加载3个参数
MOV r1, #3
MOV r2, #2
BL arithfunc ;调用函数arithfunc
stop MOV r0, #0x18 ;为SWI调用准备参数
LDR r1, =0x20026 ;调用ADP_Stopped_ApplicationExit功能
SWI 0x123456 ;ARM semihosting SWI
arithfunc ;arithfunc函数入口
CMP r0, #num ;r0中数值和num做比较
integer
BXHS lr ;如果r0≥num,函数返回
ADR r3, JumpTable ;加载跳转表地址
LDR pc, [r3,r0,LSL#2] ;跳转到相应的函数入口
JumpTable
DCD DoAdd
DCD DoSub
DoAdd ADD r0, r1, r2 ;r1和r2相加,结果放入r0
BX lr ;子函数返回
DoSub SUB r0, r1, r2 ;r1和r2相减,结果放入r0
BX lr ;子函数返回
END ;程序结束
上面的程序段中,函数arithfunc带有3个参数(使用r0、r1和r2传参),函数的返回值通过r0返回。参数1决定该函数的功能。
· 参数1=0,结果=参数1+参数2;
· 参数1=1,结果=参数1-参数2。
程序中伪操作LDR pc,[r3,r0,LSL#2]向PC寄存器加载了跳转表中的正确的子函数入口地址。
(2)使用LDR Rd, = label伪指令
使用LDR Rd, = label可以将32位的常数加载到寄存器。详见ARM伪指令一节。
ARM汇编器首先将label地址存入数据缓冲池,在使用LDR rn [pc, #offset to literal pool]指令将该label地址加载到寄存器。
使用LDR Rd, = label可以加载本段以外的标号label地址值(与ADR不同)。如果LDR Rd, = label加载的地址标号label和指令不在同一段,汇编器将在目标码中放置重定位伪操作指示连接器在连接时替换成合适地址值。
下面的例子使用LDR Rd, = label加载了本段之外的标号。
AREA LDRlabel, CODE,READONLY
ENTRY ;程序入口
start
BL func1 ;跳转到func1
BL func2 ;跳转到func2
stop MOV r0, #0x18 ;为SWI调用准备参数
LDR r1, =0x20026 ;准备调用SWI的ADP_Stopped_ApplicationExit功能
SWI 0x123456 ;semihosting软中断调用
func1
LDR r0, =start ;加载标号地址
LDR r1, =Darea + 12 ;该伪操作被编译为指令LDR R1,[PC,#offset into
;Literal Pool 1]
LDR r2, =Darea + 6000 ;该伪操作被编译为指令LDR R2, [PC, #offset into
;Literal Pool 1]
MOV pc,lr ;程序返回
LTORG ;内存池1入口
func2
LDR r3, =Darea + 6000 ;编译为指令LDR r3, [PC, #offset into
;Literal Pool 1]
;(共享内存池)
; LDR r4, =Darea + 6004 ;从内存池2中加载新的数据,因为内存池2超出范围,
;所以指令失败
BX lr ;返回
Darea SPACE 8000 ;申请8000字节的内存空间并初始化为0
END ;程序结束,内存池2超出了LDR指令的数据加载范围
3.使用LDM和STM指令实现堆栈操作
无论ARM、Thumb-2还是16位Thumb指令集,都有相同的加载多个寄存器的指令(LDM和STM指令)。多寄存器数据传输指令为寄存器和内存的多数据交换提供了有效方法。这些指令通常用于块拷贝或堆栈操作。使用多寄存器数据传输指令代替多条单寄存器传输指令的组合,有下面几点优势。
① 产生的代码量小,代码密度高。
② 在没有Cache的ARM处理器上使用多寄存器传输指令传输数据时,除第一个被传送的数据外,其余数据均是在连续的指令周期完成的(第一个被传送的数据使用非连续的内存周期),提高了指令的执行速度。
多寄存器的LDM和STM指令会增加中断的延时,因为ARM通常不会打断正在执行的指令去相应中断,而必须等到指令执行完。编译器会提供一个开关来控制Load/Store指令可以传送的最大寄存器数目以限制最大的中断延迟。
更多的关于LDM和STM指令的信息请参加ARM指令一节。
使用ARM汇编语言实现堆栈操作时,下面4条指令常被用到。
· LDM:加载多寄存器指令;
· STM:存储多寄存器指令;
· PUSH:将多个寄存器的值存储到堆栈并更新堆栈指针;
· POS:从堆栈中装载多个寄存器的值并更新堆栈指针。
下面分别介绍操作这些指令时的一些限制。
对于LDM/STM指令,可操作的寄存器要满足以下要求。
① ARM状态下,r0~r15中的任意寄存器或寄存器的组合。
② 在32位的Thumb-2指令集中,可以是r0~r12中的任意寄存器或寄存器的组合或有选择性的使用r14或r15。
③ 在16位的Thumb指令集中,可以使用r0~r7中的任意寄存器或寄存器的组合。
对于LDM/STM指令,内存地址要满足以下要求。
① 数据传送后增长。
② 数据传送前增长(仅在ARM指令集中)。
③ 数据传送后减少(仅在ARM指令集中)。
④ 数据传送前减少(仅在ARM和32位Thumb指令集中)。
任何当前寄存器组的子集都可以使用多寄存器LDM/STM指令与寄存器进行数据交换。基址寄存器Rn决定目标或源地址,可以通过选择使用Rn后缀字符“!”来确定Rn的值是否随着传送而改变,就像使用回写前变址寻址的单寄存器传送指令一样。
对于PUSH和POS,要满足以下要求。
① 使用堆栈指针寄存器r13作为基址寄存器,并在操作后更新该寄存器的值。
② 在每一个POP指令后,基址寄存器地址自动增加;在每一个PUSH指令后,基址寄存器地址自动减少。
③ 对指令操作的寄存器的限制同LDM/STM指令。
在ARM的37个寄存器中,R13通常用作堆栈指针。堆栈寻址是隐含的,堆栈指针所指定的存储单元就是堆栈的栈顶,堆栈寻址通常有两种方式:向上生长(ascending)和向下生长(descending)。ARM处理器有ARM和Thumb两种指令集。每种指令集都有丰富的指令可以对堆栈进行操作。堆栈指针指向最后压入堆栈的有效数据,称为满堆栈(full stack);堆栈指针指向下一个数据项放入的空位置,称为空堆栈(empty stack)。根据堆栈的生长方向不同,可以生成4种类型的堆栈,即满递增、空递增、满递减和空递减。
注意
这种递增和递减的多寄存器传送指令不仅可以对堆栈进行操作,而且也可以用于正向或反向访问数组。
为方便堆栈的操作,ARM指令增加了专门对堆栈操作的指令后缀。表10.16列出了对堆栈操作的数据传输指令。
表10.16 对堆栈操作的数据传送指令
堆 栈 类 型
Push
Pop
满递减
STMFD(STMDB,Decrement Before)
LDMFD (LDM , Icrement Ater)
满递增
STMFA (STMIB, Increment Before)
LDMFA (LDMDA , Decrement After)
空递减
STMED (STMDA, Decrement After)
LDMED (LDMIB, Increment Before)
空递增
STMEA (STM , increment after)
LDMEA (LDMDB, Decrement Before)
下面的例子显示了数据传送指令对堆栈的操作。
STMFD r13!, {r0-r5} ;r0~r5入栈,该堆栈为满递减堆栈
LDMFD r13!, {r0-r5} ;数据出栈,放入寄存器r0~r5,该堆栈为满递减堆栈
注意
ARM过程调用标准AAPCS定义使用满递减堆栈。使用PUSH和POP指令操作堆栈,堆栈类型默认为满递减堆栈,自动使用地址回写。
堆栈操作经常用于子程序调用的现场保护和子程序返回的现场恢复。另外,子程序的返回地址也常常被压栈保护。
下面的例子显示如何在子程序中进行现场保护和现场恢复。
subroutine PUSH {r5-r7,lr} ;将工作寄存器和返回地址lr压栈
; code
BL somewhere_else
; code
POP {r5-r7,pc} ;保存的寄存器数据和返回地址出栈
如果系统中存在ARM和Thumb的交互工作,以上代码只能用于ARMv5架构及其以上版本。在ARMv4架构中,直接将返回地址送PC,不能引起处理器状态的切换。
下面的例子显示在符合AAPCS标准的满递减堆栈上,使用STMFD指令完成的PUSH操作(见图10.1)。STMFD指令把寄存器内容压栈,SP指针指向栈顶。
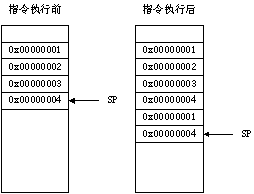
图10.1 满递减堆栈的STMFD操作
MOV r1,0x01
MOV r4,0x04
STMFD SP!,{r1,r4}
若要检查一个堆栈,必须关注堆栈的3个属性:堆栈基址、堆栈指针及堆栈限制。堆栈基址是堆栈在存储器中的起始地址;堆栈指针初始时指向堆栈基址单元,随着数据压栈,堆栈指针连续移动并始终指向栈顶;如果堆栈指针超过了堆栈限制,就会发生堆栈溢出错误。下面代码用于检测递减式堆栈的溢出错误。
SUB SP,SP,#size
CPM SP,r10
BLLO _stack_overflow ;条件
AAPCS把寄存器r10定义为堆栈限制或sl(stack limit)寄存器。这是一个可选的操作,因为,堆栈检查只有在堆栈检查使能的时候才可以使用。BLL0指令是一个附加了条件助记符L0的带链接的分支指令。如果在执行一个push操作后,SP的值小于r10的值,就发生了堆栈溢出错误。如果堆栈指针在执行pop操作后,超出了堆栈基址,那么就产生了堆栈下溢(stack underflow)错误。
4.使用LDM和STM指令实现块复制
当程序中有大量数据需要复制或搬移时,常用到LDM和STM指令。虽然使用单寄存器数据传送指令LDR和STR也能实现同样的功能,但代码密度和执行效率要低于使用多寄存器传送指令。
下面通过两个例子说明了使用单寄存器数据传送指令和使用多寄存器数据传送指令的区别。
AREA Word, CODE, READONLY ;给代码段起名为Word
num EQU 20 ;num=20将要拷贝的字的个数
ENTRY ;程序入口
call
start
LDR r0, =src ;r0 = 源操作块起始地址
LDR r1, =dst ;r1 = 目的操作块起始地址
MOV r2, #num ;r2 = 将要拷贝的字的个数
wordcopy LDR r3, [r0], #4 ;从源操作块装载一个字
STR r3, [r1], #4 ;存储到目的操作块
SUBS r2, r2, #1 ;指针移到下一个要拷贝的字单元
BNE wordcopy ;循环拷贝
stop MOV r0, #0x18 ;angel_SWIreason_ReportException为软中断调用准备参数
LDR r1, =0x20026 ;调用Semihosting的ADP_Stopped_ApplicationExit功能
SWI 0x123456 ;ARM semihosting SWI调用
AREA BlockData, DATA, READWRITE
src DCD 1,2,3,4,5,6,7,8,1,2,3,4,5,6,7,8,1,2,3,4
dst DCD 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
END
下面是使用多寄存器数据拷贝命令LDM和STM重写的代码。
AREA Block, CODE, READONLY ;给代码段起名为Block
num EQU 20 ;num=20将要拷贝的字的个数
ENTRY ;程序入口
call
start
LDR r0, =src ;r0 = 源操作块起始地址
LDR r1, =dst ;r1 = 目的操作块起始地址
MOV r2, #num ;r2 = 将要拷贝的字的个数
MOV sp, #0x400 ;设置堆栈指针 (r13)
blockcopy MOVS r3,r2, LSR #3 ;判断要移动的字的个数是8的几倍
BEQ copywords ;如果移动的字的个数小于8则跳转到copywords子函数
PUSH {r4-r11} ;将用到的工作寄存器压栈保存
octcopy LDM r0!, {r4-r11} ;从源地址拷贝8个字
STM r1!, {r4-r11} ;存到目的地址
SUBS r3, r3, #1 ;计数器减1
BNE octcopy ;如果计数器不等于零,继续拷贝
POP {r4-r11} ;如果计数器等于零,恢复工作寄存器
copywords ANDS r2, r2, #7 ;判断要拷贝的剩余字个数
BEQ stop ;判断剩余字数是否为零
wordcopy LDR r3, [r0], #4 ;从源地址加载一个字
STR r3, [r1], #4 ;到目的地址
SUBS r2, r2, #1 ;计算器减1
BNE wordcopy ;如果计数器不等于零,继续拷贝
stop MOV r0, #0x18 ;为软中断调用准备参数
LDR r1, =0x20026 ;调用Semihosting的ADP_Stopped_ApplicationExit功能
SWI 0x123456 ;调用Semihosting软中断
AREA BlockData, DATA, READWRITE
src DCD 1,2,3,4,5,6,7,8,1,2,3,4,5,6,7,8,1,2,3,4
dst DCD 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
END
为了增加数据拷贝的效率,程序中使用了“MOVS r3,r2, LSR #3”指令。该指令将为下面以8个字节为单位进行数据拷贝做准备。将数据以8个字为单位拷贝,是因为ARM体系结构中所能使用的寄存器为8个,即:r4~r11(根据AAPCS标准,r0~r3在子程序调用过程中将被使用)。
10.5.3 宏的使用
使用伪操作MACRO和MEND可以将一段代码定义为宏。程序运行时,使用宏名调用宏。程序中使用宏的优势在于。
① 提高代码的可读性,使用更能代表程序功能的名称代替特定的代码段。
② 避免同一代码段在程序中重复多次。
1.宏在分支程序中的应用
在ARMv6T2之前的ARM体系结构中,一个“测试-分支”操作需要至少两条ARM指令完成。可以使用宏定义这种“分支-测试”结构。
MACRO
$label TestAndBranch $dest, $reg, $cc
$label CMP $reg, #0
B$cc $dest
MEND
上面的程序段定义了一个叫做TestAndBranch的宏,并且为该宏定义了4个参数($label、$dest、$reg和$cc),在程序中使用该宏时,必须为参数赋值。下面的程序段显示了如何调用TestAndBranch宏。
test TestAndBranch NonZero, r0, NE
...
...
NonZero
After substitution this becomes:
test CMP r0, #0
BNE NonZero
...
...
NonZero
2.宏在除法中的应用
下面的例子程序定义的宏实现了无符号整数的除法,调用该宏需要为以下4个参数赋值。
· $Bot:保存除法除数的寄存器。
· $Top:指令执行前保存被除数,指令执行后保存除数。
· $Div:保存除法运算的商,如果除法只要求余数,该寄存器的值为0。
· $Temp:临时寄存器。
MACRO
$Lab DivMod $Div,$Top,$Bot,$Temp
ASSERT $Top <> $Bot ;如果使用的寄存器不全相等,产生错误信息
ASSERT $Top <> $Temp
ASSERT $Bot <> $Temp
IF "$Div" <> ""
ASSERT $Div <> $Top ;如果$Div不为空,产生三个提示信息
ASSERT $Div <> $Bot
ASSERT $Div <> $Temp
ENDIF
$Lab
MOV $Temp, $Bot ;将除数放入$Temp
CMP $Temp, $Top, LSR #1 ;$Temp乘以2,直到2*$Temp>$Top
90 MOVLS $Temp, $Temp, LSL #1
CMP $Temp, $Top, LSR #1
BLS %b90 ;b表示向后搜索
IF "$Div" <> "" ;如果$Div为空,忽略下一条指令
MOV $Div, #0 ;将$Div初始化
ENDIF
91 CMP $Top, $Temp ;Can we subtract $Temp?$Top大于$Temp?
SUBCS $Top, $Top,$Temp ;如果大于,$Top减去$Temp,结果放入$Top
IF "$Div" <> "" ;如果$Div为空,忽略下一条指令
ADC $Div, $Div, $Div ;将$Div乘以2
ENDIF
MOV $Temp, $Temp, LSR #1 ;将$Temp除2
CMP $Temp, $Bot ;循环,直到$Temp小于除数
BHS %b91
MEND
下面是该除法宏被引用时的结果。
ASSERT r5 <> r4 ;如果寄存器全不相等,显示提示信息
ASSERT r5 <> r2
ASSERT r4 <> r2
ASSERT r0 <> r5 ;如果$Div不为空,产生三个提示信息
ASSERT r0 <> r4
ASSERT r0 <> r2
ratio
MOV r2, r4 ;将除数放在r2中
CMP r2, r5, LSR #1 ;r2乘以2,直到2*r2>r5
90 MOVLS r2, r2, LSL #1
CMP r2, r5, LSR #1
BLS %b90 ;b表示向后搜索
MOV r0, #0 ;初始化r0
91 CMP r5, r2 ;判断r5是否大于r2
SUBCS r5, r5, r2 ;如果大于,r5减去r2,结果放入r5
ADC r0, r0, r0 ;r0乘以2
MOV r2, r2, LSR #1 ;r2除以2
CMP r2, r4 ;循环,直到r2
BHS %b91
10.5.4 使用MAP和FIELD命令描述数据结构
可以使用MAP和FIELD伪操作来描述数据结构。这两个伪操作一般是一起使用的。
使用MAP和FIELD伪操作定义数据结构有以下好处。
· 容易维护。
· 可以方便地实现相同数据结构的重复定义。
· 可以更高效地存取数据。
MAP伪操作指定数据结构的基址。
FIELD伪操作指定一个数据项所需的存储器数量,并为该数据项指定一个标号。对结构中的每个数据项重复该命令。
注意
使用MAP和FIELD伪操作当定义一个数据结构时,不分配存储器空间。使用定义常数的命令(如 DCD)来分配存储器空间。
1.相对映射
MAP/FIELD伪操作和使用寄存器相对寻址的LOAD/STORE指令配合使用,访问事先定义好的结构体是MAP/FIELD伪操作的基本用法。
下面是一个使用寄存器相对寻址的LOAD指令访问结构体的例子。
MAP 0
consta FIELD 4 ;consta占用4字节,偏移量为0
constb FIELD 4 ;constb占用4字节,偏移量为4
x FIELD 8 ;x占用8字节,偏移量为8
y FIELD 8 ;y占用8字节,偏移量为16
string FIELD 256 ;string占用256,偏移量为24
上面定义的数据结构,可以使用下列指令来访问:
MOV r9,#4096
LDR r4,[r9,#constb]
标号是相对于数据结构的开始位置的。用于存放映射的起始地址的寄存器(此例中为 r9)称为基址寄存器。
数据结构的位置是由运行时装载到基址寄存器的值确定的。MAP/FIELD伪操作不实际分配内存地址。
同一映射可以用于描述数据结构的多个实例。它们可以位于存储器中的任何位置。
备注
r9是“ARM-Thumb 程序调用标准”中的静态基址寄存器 (sb)。详细信息请参阅本书附录。
2.基于寄存器的映射
一般情况下,每次访问一个数据结构时可以使用相同的寄存器作为基址寄存器。可以在使用MAP定义映射的基址时指定该寄存器的名称。
下面的例子显示了一个基于寄存器的映射。
MAP 0,r9
consta FIELD 4 ;consta变量占用4个字节,地址偏移量为0(相对于r9中的地址)
constb FIELD 4 ;constb变量占用4个字节,地址偏移量为4
x FIELD 8 ;x占用8个字节,地址偏移量为8
y FIELD 8 ;y占用8个字节,地址偏移量为16
string FIELD 256 ;字符串占用256字节,起始地址偏移量为24
利用示例中的映射,可以访问数据结构(不管它在内存中什么位置):
ADR r9,datastart
LDR r4,constb ; => LDR r4,[r9,#4] ;该伪操作被编译为LDR r4,[r9,#4]
constb包含从数据结构开始位置算起的数据项的偏移量,也包含基址寄存器。在此例中,基址寄存器是在MAP命令中定义的r9。
3.相对于程序的映射
可以使用程序计数器 (r15) 作为一个映射的基址寄存器。当使用r15做为基址寄存器时,被使用LOAD/STORE指令寻址的数据结构偏移量不能超出4KB范围。这是因为使用PC寄存器为基址的LOAD/STORE指令,最大寻址能力为4KB。
下面的例子显示了使用r15作为基址寄存器的程序段。其中包含一个为数据结构分配存储器空间的SPACE伪操作。
datastruc SPACE 280 ;保留280个字节来定义数据结构
MAP datastruc
consta FIELD 4
constb FIELD 4
x FIELD 8
y FIELD 8
string FIELD 256
使用下面的指令读取constb域所包含的内容。
LDR r2,constb ; => LDR r2,[pc,offset] 该伪操作被编译为LDR r2,[pc,offset]
在此例中,不需要在装载数据之前装载基址寄存器,此时使用程序计数器PC作为默认寄存器。
注意
由于处理器里面的流水线,r15寄存器值和 LDR 指令的实际地址并不相同。但是,汇编器将修正此问题。
4.定义结构体的结束
可以使用带有0操作数的FIELD伪操作来标记结构内的一个位置。标记位置后位置计数器并未增加(即偏移量offset不增加)。
下面的例子使用事先定义好的常量MaxStrLen和ArrayLen定义了字符串和数组的大小。为了防止MaxStrLen和ArrayLen值过大,使结构体超出所能使用的内存范围,使用了“FIELD 0”伪操作来标识结构体的结束。
StartOfData EQU 0x1000
EndOfData EQU 0x2000
MAP StartOfData
Integer FIELD 4
Integer2 FIELD 4
String FIELD MaxStrLen
Array FIELD ArrayLen*8
BitMask FIELD 4
EndOfUsedData FIELD 0
ASSERT EndOfUsedData <= EndOfData
该例中使用了:
· 一个EQU命令定义可使用的最大内存空间;
· 一个带有0操作数的FIELD伪操作来标记数据结构的结束位置;
· 一个ASSERT伪操作确认数据结构的结束位置并未超出可用内存。
5.强制内存对齐
如果在定义数据结构时,使用了一些字符变量(或其他非4字节的变量),就可能造成内存访问的对齐问题。
下面例子中显示了一个数据结构的定义。该定义方式使整数访问不能保证在字边界对齐。
StartOfData EQU 0x1000
EndOfData EQU 0x2000
MAP StartOfData
Char FIELD 1
Char2 FIELD 1
Char3 FIELD 1
Integer FIELD 4 ; 非字边界对齐
Integer2 FIELD 4
String FIELD MaxStrLen
Array FIELD ArrayLen*8
BitMask FIELD 4
EndOfUsedData FIELD 0
ASSERT EndOfUsedData <= EndOfData
这里,不能使用ALIGN伪操作来修正该边界对齐问题,因为ALIGN伪操作只对齐存储器内的当前位置。而MAP和FIELD伪操作不为其定义的结构分配任何存储空间。
解决的方法是,在Char3 FIELD 1后插入一个虚拟的FIELD 1。但是,如果改变了字符变量的数目,就会造成维护困难。每次必须重新计算正确的填充数。
下面的例子说明了一个更好的调整填充的方法。该示例使用一个带有0操作数的FIELD伪操作来标记字符数据的结束位置。第二个FIELD命令根据标号的值插入正确的填充数。使用“:AND:”运算符来计算正确的值。
StartOfData EQU 0x1000
EndOfData EQU 0x2000
MAP StartOfData
Char FIELD 1
Char2 FIELD 1
Char3 FIELD 1
EndOfChars FIELD 0
Padding FIELD (-EndOfChars):AND:3
Integer FIELD 4
Integer2 FIELD 4
String FIELD MaxStrLen
Array FIELD ArrayLen*8
BitMask FIELD 4
EndOfUsedData FIELD 0
ASSERT EndOfUsedData <= EndOfData
“(-EndOfChars):AND:3”表达式计算正确的填充数:
· 如果EndOfChars是0 mod 4,则填充数是0;
· 如果EndOfChars是1 mod 4,则填充数是3;
· 如果EndOfChars是2 mod 4,则填充数是2;
· 如果EndOfChars是3 mod 4,则填充数是1。
无论何时添加或删除字符变量,它会自动调整填充数。