Day 3 初始C语言 12.13
对于之前部分自学和自我理解的知识进行一个笔记的总结。可能会有点杂就是了。
目录
数据类型
声明数组
setw()函数
for循环结构
输出控制符
if else语句
分享一个自己在C Primer Plus上看到的知识点。
数据类型
char //字符数据
short //短整形
int //整形
long //长整形
long long //长长整形
float //单精度浮点数
double //双精度浮点数
printf (“%d\n”,sizeof(char)); //1 单位为字节。
printf (“%d\n”,sizeof(short)); //2
printf (“%d\n”,sizeof(int)); //4
printf (“%d\n”,sizeof(long)); //4
printf (“%d\n”,sizeof(long long)); //8
printf (“%d\n”,sizeof(float)); //4
printf (“%d\n”,sizeof(double)); //8声明数组
double balance [10] = {1,2,3,4,5,6,7,8,9,10};
//double为数据类型 balance为数组名 10为元素个数
balance [4] = 4;
//拔balance组的第5个元素命令为4
double salary = balance[9];
//把数组第九个元素的值赋给salary变量注意:如果要使用scanf()函数,需要在开头加上:
#define_CRT_SECURE_NO_WARNINGS 1setw()函数
用于设置字符的宽度,格式为:
setw(n)
//其中n为宽度,用数字表示。注意:setw()函数只对紧接着输出产生作用。
cout << setw(4) << "runoob" << endl;
//开头宽度设置为4,而后面的“runoob”长度大于4,所以setw函数不起作用。
cout << setw(14) << "runoob" << endl;
//开头宽度设置为14,而后面的“runoob”长度小于14,所以setw函数补充14-6也就是8格。有以上等式,setw函数中的数减去字符串长度就是前面留空的长度。
cout << setfill('*') << setw(14) << "runoob" << endl;可以使用setfill()函数配合其他字符填充,如上输出即为:
********runoob
也可以直接用cout来实现输出。
#include
using namespace std;
int main()
{
cout << "Hello,world";
return 0;
} 补充:
在C语言中,有以下要求:
#include
using namespace std;
//库函数末尾有h的为以前的头文件,没有.h的头文件为标准库函数,后者需要加上using namespace std; #include
using std::setw
//std为命名空间,对头文件iomainip进行限制,避免与其他的文件全局命名冲突。这样艰苦有直接用string,而不需要打出原本的std::string了。 for循环结构
语法:
for(init;condition;increment)
{
statement(s);
}
//init为初始值,condition为条件,statement(s)为代码块,increment为增量。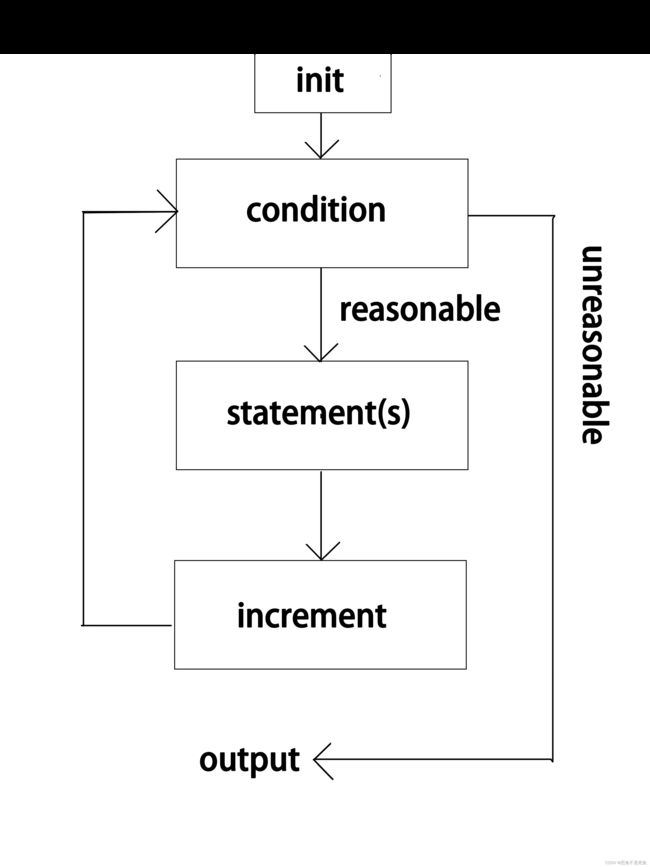
for函数还有以下知识点:简单范围迭代。
int main()
{
int mercy[5] = {1,2,3,4,5};
for(int &x = mercy)
{
x* = 2; //x乘上2。
cout << x << endl;
}
for(auto&x:mercy)
{
x* = 2;
cout << x << endl:
}
}auto可以检测上面mercy数据的变化 也就是2,4,6,8,10。并将新的值赋给x。
这就是for是简单范围迭代。
输出控制符
%d
//十进制整形数据输出。
%ld
//长整型数据输出。
%md
//m为指定的输出字段宽度,数位m,安实际位数输出。同setw。
%c
//输出字符。
%f
//输出实数(单精度,双精度)【超过六位小数则四舍五入】。
%.mf
//输出实数时小数点保留m位(注意m前面有一个.)。
%o
//八进制输出。
%x %X %#x %#X
//都为十六进制输出。 int i = 47;
printf("%x/n",i); //输出2f。
printf("%X/n",i); //输出2F。
printf("%#x/n",i); //输出0x2f。
printf("%#X/n",i); //输出0x2F。
//后两者较为标准。补充:如果要输出%d,\,双引号。
%d -- %%d
\ -- \\
"" -- \"\"
//如上替换就可以输出。if else语句
结构为:
if(判断条件)
{
语句块1
else
{
语句块2
}
}分享一个自己在C Primer Plus上看到的知识点。
浮点数常量可以用一个有符号的数字(包括小数点)后面紧跟e或E,最后一个有符号的数字是10的指数。例如:
-1.56E+12
2.87e-3
正号可以省略,不能同时省略小数点和指数部分(可以省略一个)也不能同时省略小数部分和整数部分(可以省略一个)。
默认情况,编译器假定浮点型常量是double类型的精度。在浮点数后面加上f或者F可以覆盖默认设置。同理加上字母l或者L可以把数字成为long double类型。
C99新增了一个浮点型常量格式,用十六进制表示浮点型常量,即在十六进制数前加上十六进制前缀(0X或0x),用p和P分别代替e和E,用2的幂代替10的幂。也就是p计数法。例如
0xa.1fp10
十六进制中a等于十进制的10,
1f是1/16加上15/256 (十六进制f等于十进制的15),
p10是2的十次方。因此整个值为:
(10+1/16+15/256)x1024。
但并不是每个编译器都支持C99这一特性。
其中的0xa.1fp10 = (10+1/16+15/256)x 1024是这么来的。
十六进制中的a,b,c,d,e,f(大小写均可)对应十进制的10,11,12,13,14,15。而十六进制中只用数字1~9。
因此我们看0x后面的部分。.1fp表示的是一个小数。由上面可得,a表示的就是10。1/16是由本体1作为分子,16的负一次方作为分母得来的。同理,15/256是由f对应的十进制的值作为分子,16的负二次方作为分母得来的。然后两者相加。最后是10即是2的10次方。