论文精读1:(网格特征)In Defense of Grid Features for Visual Question Answering(CVPR2020)

- 马萨诸塞州立大学阿默斯特分校
- Facebook 人工智能研究
目录
-
- 1. Introduction
- 2. Related Work
-
- Visual features for vision and language tasks
- Pre-training for VQA
- Regions vs. grids.
- 3. From Regions to Grids
-
- 3.1. Bottom-Up Attention with Regions
-
- Region selection
- Region feature computation
- 3.2. Grid Features from the Same Layer
- 3.3. 1×1 RoIPool for Improved Grid Features
- 4. Experiment
-
- 4.1 Main Results
- 4.2 Number of Regions
- 4.3 Test Accuracy and Inference Time
- 4.4 Qualitative Comparison
- 5. Why do Our Grid Features Work?
-
- 5.1. Factor 1: Input Image Size
- 5.2 Factor 2: Pre-Training Task
- 6. Generalization of Grid Features
- 7. Conclusion
1. Introduction
多模态视觉与语言研究中的一些重要发展,包括深度学习和注意力机制的引入以及“自下而上”的注意力机制的发现。相比传统的“自上而下”的语言输入来聚焦于视觉输入的特定部分,自下而上的注意力机制使用预训练的物体检测器仅基于视觉输入本身来识别显著区域。因此,图像通过基于边界框或区域的特征表示,这些特征已经在多项任务中占据主导地位,尤其是视觉问答任务。

该段文字探讨了区域特征在多模态视觉与语言研究中成功的原因。作者提出了两种可能的原因:一是更好地定位单个物体,由于区域是直接从检测器输出的边界框结果;二是若干个重叠的区域可以轻松捕捉图像中的粗略信息和细节。然而,这些潜在的优势能否证明区域特征优于网格特征呢?
一项重要的研究发现,当前广泛使用的自下而上的区域特征并没有比传统的网格特征具有明显的优势。作者提出,区域特征在相关任务中表现卓越的关键原因在于对大规模的物体和属性注释的利用,以及高分辨率输入图像所提供的空间信息。

作者认为,将特征表示从区域特征切换到网格特征可以带来显著的推理速度提升,并且能够省略现有VQA流程中所有与区域特征提取的相关步骤。例如,在使用ResNet-50作为网络骨干的情况下,整个处理单张图像的时间从0.89秒降至0.02秒,速度提升40倍以上,且准确率略有提高。实际上,提取区域特征的时间消耗如此之高,以至于大多数最先进的模型都直接在缓存的视觉特征上训练和评估。这种做法不仅对模型设计施加了不必要的限制,而且限制了现有视觉语言系统的潜在应用。

该段文字介绍了利用网格特征进行端到端训练的一些优势。与使用区域特征相比,直接用网格特征进行端到端训练更加容易,因为它们不需要额外的 grounding 标注,可以直接针对最终目标(如正确回答问题)进行优化。通过使用网格特征,作者还探索了更有效的VQA模型设计,并发现即使在没有显式区域注释的情况下,网络也可以实现强大的VQA准确性,这进一步证明了网格特征在VQA中的优越性。作者希望这一发现能够为视觉和语言研究开辟新的机遇。
2. Related Work
Visual features for vision and language tasks


该段文字介绍了特征在视觉和语言任务中的重要作用。深度学习特征在图像字幕生成等领域的应用取得了显著的进展。虽然本文不涉及所有用于视觉和语言任务的视觉特征,但作者指出现代VQA模型的准确性取决于所使用的底层视觉特征,包括VGG和ResNet网格特征以及后来占据主导地位的自下而上的区域特征。现今大多数最先进的VQA模型都是基于区域特征构建的,并且采用了各种融合策略;而本文对网格特征进行了重新审视,表明它们同样有效,并能够带来显著的速度提升,常常超过一个数量级!
总之,该段文字强调了特征在视觉和语言任务中的关键作用,并介绍了现代VQA模型所依赖的底层视觉特征类型。本文的研究发现为我们重新审视了传统网格特征的潜力,并展示了其同样有效且速度更快的优势。
Pre-training for VQA

该段文字讨论了视觉问答任务中的预训练方法。传统的VQA方法通常使用两个分别预训练的模型:在ImageNet和VG数据集上进行预训练的视觉模型以及用于语言特征的词嵌入。然而,这些单独训练的特征可能并不是联合视觉和语言理解的最优选择,因此近年来研究人员开始探索联合预训练模型。这些方法通常将区域和单词视为各自领域的“token”,并预训练BERT的变体进行“masked” token prediction。与此方向互补的是,本文着重探讨了视觉token的“格式”问题,并可以与这些方法相结合,实现速度和准确性的平衡。
Regions vs. grids.

该段文字探讨了区域特征和网格特征之间的关系,并将其与目标检测任务联系起来。传统的基于区域(R-CNN)的目标检测方法表明,采用区域级别的计算有助于提高目标检测的性能。但是,一些新型的单阶段检测器则不需要显式的区域级别计算,而是使用网格特征来完成检测任务,并且在某些情况下也能取得竞争性的性能。本文的工作也使用了网格特征,以获得更快的推理速度。为了尽可能减少与自下而上的注意力模型[2]的改变,作者选择使用Faster R-CNN进行预训练,但在推理过程中只使用网格卷积特征,从而对网格特征进行了更加有力的证明。同时,作者还指出,虽然区域特征在VQA和COCO字幕等基准测试中非常有效,但是在一些需要模型进行推理的视觉问答基准测试(如CLEVR),基于网格的简单方法已经展现出了强大的性能。
3. From Regions to Grids

该段文字介绍了实现与区域特征同样有效的网格特征的方法。为了满足这一要求,网格特征必须使用与区域特征相同的任务进行预训练。在7节中,作者还展示了通过端到端训练可以消除“相同预训练”约束并且网格特征仍然可以缩小与区域特征之间的差距。该段先简要回顾了自下而上的注意力[2]所用的区域特征。
总之,该段文字指出了实现同样有效的网格特征的方法,并介绍了该方法需要使用与区域特征相同的任务进行预训练才能实现。同时,作者也提到了在后续章节中将会阐述如何通过端到端训练来消除这一限制。
3.1. Bottom-Up Attention with Regions

该段文字简要介绍了自下而上的注意力方法[2]所用的基础模型和数据集。该方法使用了Faster RCNN检测模型[31],并在Visual Genome [21]数据集的清洗版本上进行训练。Visual Genome数据集包含数千个物体类别和数百个带有边界框(即区域)注释的属性标注信息。
总之,该段文字介绍了自下而上的注意力方法[2]中所用到的基础模型和数据集,并为接下来的内容提供了背景知识。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LrRuv9mx-1681220771878)(/imgs/2023-04-02/IOugjn5Qif36G3pi.png#pic_center =100%x100%)]](http://img.e-com-net.com/image/info8/f76cd0e1ec134f39a7fa0f895a22f0f4.jpg)
为了获得用于视觉问答等任务的自下而上的注意力特征,需要完成两个与区域相关的步骤。
Region selection

由于Faster R-CNN是一种两阶段检测器,在处理过程中需要进行两次区域选择。第一步是通过Region proposal network[31],将候选“锚点”形变并选择出最突出的感兴趣区域(ROI)。另一个选择是在后期以每类别为单位聚合前N个边界框时完成的。在这两个步骤中,都采用了非极大值抑制(NMS)技术,该技术保留具有最高分类分数的区域,并删除局部邻域内的其他相似区域。
总之,该段文字介绍了Faster R-CNN作为一种两阶段检测器,在区域选择方面的两个步骤,并解释了其中使用的非极大值抑制(NMS)技术的作用。
Region feature computation

-
首先使用Region proposal network提取感兴趣的区域ROI(可能高达数千个)。
-
然后通过RoIPool操作[31]从这些区域中提取初始的区域级特征initial region-level features。接着,额外的网络层分别计算每个区域的输出表示。
-
最后,经过两轮选择后幸存下来的区域特征被整合在一起,作为表示图像的自下而上特征。
-
值得注意的是,由于Visual Genome数据集的复杂性(例如包含数千个类别)和所使用的Faster R-CNN检测器[2]的特殊性质,这两个步骤的计算成本非常高。相比之下,直接使用网格特征可以跳过或加速这些步骤,并且具有潜在的显著加速优势。
总之,该段文字介绍了自下而上的注意力方法中进行区域特征计算的流程,并强调了其计算成本较高的问题。作者还指出,直接使用网格特征可以优化计算速度,提高效率。
3.2. Grid Features from the Same Layer

将区域特征转换为网格的最简单方法是查看是否可以直接计算同一网络层的输出,但是要采用共享的、完全卷积的方式。为此,作者对原始的自下而上的注意力[2]中使用的具体Faster R-CNN架构进行了更详细的研究。
总之,该段文字重点介绍了将区域特征转化为网格特征的一种简单方法,并着眼于分析了原始的自下而上的注意力方法所使用的具体Faster R-CNN架构。

该段文字介绍了Faster R-CNN的具体架构及其与ResNet模型[15]之间的关系,以及如何将其转化为网格特征。Faster R-CNN是c4模型[15]的一种变体,在属性分类方面增加了一个额外的分支。它将ResNet[15]的权重分成两个独立的集合:

-
给定输入图像,首先使用ResNet的较低块计算特征映射,直到C4块,这个特征图被所有区域共享。举例:当给定一个输入图像(假设大小为224×224×3)时,首先使用ResNet的较低块对图像进行卷积操作和池化操作,直到C4块。这样就生成了一个7×7×1024的特征图,其中包含了输入图像的高级语义信息。
-
然后,针对每个区域单独进行特征计算,将C5块应用于14×14 RoIPool操作后的特征上。
-
C5的输出然后被AvgPool平均池化成每个区域的最终向量作为自下而上的特征[2]。
-
由于所有最终的区域特征均来自C5,因此可以将检测器重新转换回ResNet分类器,并将同一层C5作为我们的输出网格特征。具体如图2左所示:

总之,该段文字详细介绍了Faster R-CNN的具体架构及其与ResNet模型之间的关系,并指出如何将其转化为网格特征的方法。

实验旨在研究如何在使用 Faster RCNN 模型进行目标检测任务时,使用转换后的 C5 特征图是否会影响模型的性能。实验结果表明,直接使用转换后的 C5 特征图已经取得了出乎意料的良好效果,但如果需要进一步提高模型的性能,则可能需要进行一些细微的调整,以优化特征提取,从而改善 Faster RCNN 在基于网格的目标检测任务中的性能。此外,作者也指出,Faster RCNN 模型虽然在区域检测方面高度优化,但对于基于网格的检测任务的性能优化可能不是特别强。
3.3. 1×1 RoIPool for Improved Grid Features
基于Faster R-CNN改进后的目标检测模型中1×1 RoIPool的使用。在传统的Faster R-CNN中,每个RoI(Region of Interest)都被表示为一个三维张量,即高度、宽度和通道数。而在改进后的模型中,使用1×1 RoIPool将每个RoI表示为一个单一的向量,这样可以减少计算量,同时强制每个网格特征向量独立地表示每个空间区域的所有信息。虽然这种做法看起来有些不合理,因为2D中的两个额外的空间维度(高度和宽度)对于确定物体不同的部分非常有用,但如果强制每个向量仅覆盖空间区域的所有信息,可以得到更强的网格特征,从而提高目标检测的性能。但需要注意的是,在VG数据集上,这种修改对目标检测的性能有负面影响。

直接将1×1 RoIPool应用于原始模型中存在问题,主要是因为C5由多个ImageNet预训练的卷积层组成,这些卷积层对特定空间维度的输入效果最佳。因此,为了解决这个问题,借鉴目标检测领域的最新进展,在共享特征计算方面使用整个ResNet直到C5作为骨干网络,并在区域级别的计算部分顶部放置两个1024D的全连接层(FC层),默认情况下接收向量作为输入。这样做可以解决直接应用1×1 RoIPool所导致的问题,并保证目标检测的性能。

为了减少使用C5池化特征来训练检测器时low resolutions的影响(因为C5的stride为32,而C4的stride为16),作者采取了一些策略:将stride为2的层替换为stride为1的层,并将其余层dilated两倍[54]以提高检测器的性能。在提取网格特征时,取消这种扩张并将其转换回普通的ResNet以保持原始模型的特性。这样做的目的是为了提高模型的性能和准确度,以便更好地识别和定位目标物体。

图2(右)总结了我们所做的改进网格的变化。需要注意的是,与原始模型(左)相比,我们只对与区域相关的组件在训练期间进行必要的修改。由于特征提取期间删除了所有此类计算,因此我们的网格特征提取器在推理期间保持不变。这意味着,我们使用改进的网格来训练模型,但在使用训练完成的模型进行推理时,我们仍然使用未经修改的原始网格特征提取器。这种方法可以有效地提高训练效率和模型性能,并且在实际应用中具有一定的可行性。
4. Experiment
4.1 Main Results

首先,与广泛使用的自下而上区域特征(第 1 行)相比,使用相同模型(第 3 行)直接从 C5 中提取输出效果出奇地好(64.29 : 63.64 准确度)。相比之下,在 ImageNet [6] 上预训练的标准 ResNet-50 模型显示出更差的性能——准确率为 60.76,与自底向上特征的差距超过 3%(网格特征的好处)。
4.2 Number of Regions
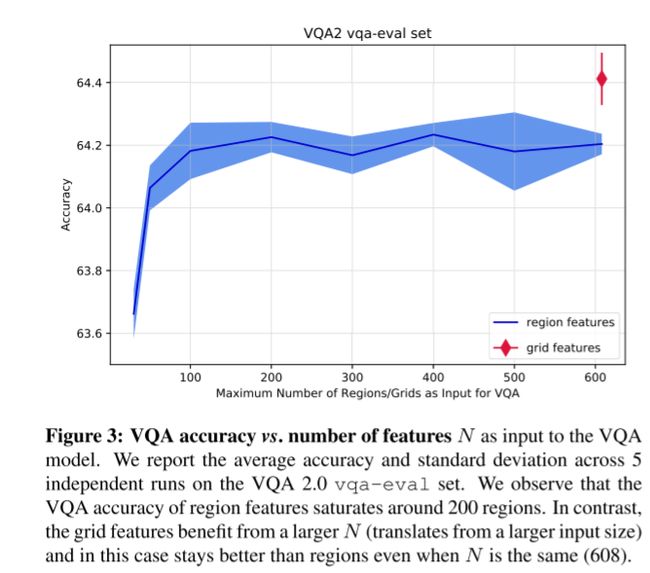
为了了解这些不同数量的区域特征如何影响精度,我们使用不同数量的特征N进行实验,结果如图3所示。对于区域特征,我们观察到,当区域数量从30个增加到200个时,精度有所提高,超过这个数字,精度达到饱和。有趣的是,即使与数量最多的区域相比,我们的网格特征也更好。
4.3 Test Accuracy and Inference Time

使用不同特征(region和grid)进行VQA2.0测试,并且使用trainval+vqa-eval来进行训练,得到了表2中的结果。该实验表明,使用grid作为特征的模型的速度比使用bottom-up region features作为特征的模型的速度快48倍。这是因为region features需要进行区域选择和区域特征计算等额外操作,占据了总推理时间的98.3%。同时,在测试集中使用grid作为特征的模型获得了更高的VQA准确度。
4.4 Qualitative Comparison
图4中展示的使用top-down attention module 在COCO数据集上的attention maps效果。作者使用了region和grid两种特征,并将两个特征对应的attention value传播到相应的像素上,然后对每个像素的attention value取平均值并进行归一化处理,以得到attention maps。结果显示,这两种特征都能够捕捉输入图像中的相关概念。区域特征的attention maps往往覆盖类似物体的区域,而网格特征的attention maps并不一定覆盖支持的整个区域,但这两种特征都能够在VQA任务中表现得很好。尽管本文指出定位是很重要的,但是精准的个体物体检测对于回答VQA问题并不是关键。此外,作者还展示了region和grid特征在一些失败案例中的表现,发现通常情况下模型会注意到支持概念但仍然给出错误答案。对于那些无论使用region还是grid特征都表现不佳的情况,可能需要特定设计的模块(例如计数模块)才能正确回答问题。

5. Why do Our Grid Features Work?
这段文字总结了在第2节中提到的,与之前的研究相比,为什么本文的网格特征表现得如此出色。作者在表3中展示了不同设置下基于网格的方法(ResNet-50 C5特征)的性能,并发现有两个主要因素:1)输入图像大小;2)预训练任务。接下来,作者分别研究了这两个因素,并在vqa-eval数据集上报告了结果。

5.1. Factor 1: Input Image Size
输入图像大小对VQA 2.0 VQA -eval集的影响。网格特性受益于更大的输入图像尺寸。对于ImageNet预训练的模型,其精度在600×1000附近饱和,但VG模型更好地利用了更大的输入图像尺寸。

5.2 Factor 2: Pre-Training Task

作者在研究中通过引入不同的预训练模型,研究了ImageNet和VG两种不同预训练任务对VQA准确性的影响。作者在每个设置中都引入了一个额外的预训练模型来更好地理解这些差异。在分类预训练设置中,使用YFCC数据集(使用图像级标签进行训练)的模型表现比ImageNet模型更好,可能是因为它使用了数量级更大的数据进行训练。对于基于检测的预训练,VG模型(使用对象和属性进行训练)结果比COCO模型更好。VG具有比COCO更多的类别(1600 vs. 80)或额外的属性注释是提高性能的两个可能原因。接下来,作者研究了属性的影响。
6. Generalization of Grid Features

7. Conclusion
本文重新审视了作为视觉和语言任务中广泛使用的 bottom-up 区域特征[2]的替代选择 - 网格特征。作者展示了网格特征实际上能够在不同的VQA任务和模型以及生成字幕方面实现相当的准确性。我们看到了显著的加速 - 往往是超过一个数量级的现有依赖于区域的特征。作者的实验表明,特征的“格式”(区域 vs. 网格)不如特征所代表的语义内容对其效果更为关键。实验发现,可以通过在对象和属性数据集(例如VG)上进行预训练,或者更重要的是通过直接为端任务直接训练网格特征来实现有效的表示。需要注意的是,虽然使用网格特征容易进行端到端训练,但使用区域特征进行端到端训练并不是一件容易的事情。作者已经展示了,在更灵活的设计空间下,即使没有任何区域级别的注释,预训练的网格特征实际上也可以在VQA上获得强大的性能。尽管我们知道,在诸如指代表达式[19]这样的任务中,输出本身就是一个区域,但我们希望我们的网格特征潜在地可以为视觉和语言研究提供新的视角。