ClickHouse分区表的正面与侧面
当我们处理连续数据并需要基于移动窗口(如,仅使用过去三个月数据)计算时使用分区功能非常有用,因为分区无需删除数据,就能高效避过不使用的(或过期)数据。本文介绍分区表原理,对比查询、插入性能,了解分区的优势于劣势,从而理解在恰当的应用场景使用分区功能。
分区表原理
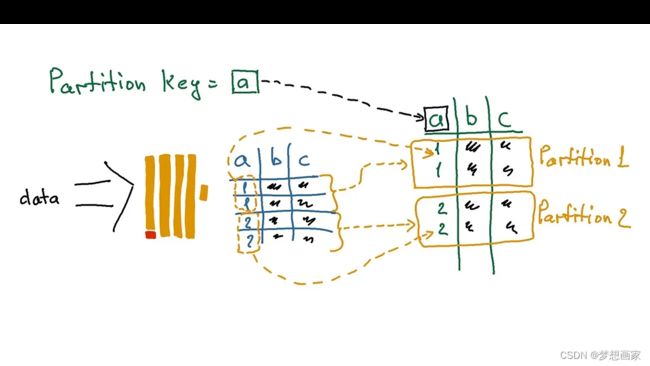
ClickHouse分区表把表分成多个块,从而后续可以高效地处理这些块(如,删除或移动),要定义分区表,需要使用PARTITION BY表达式指定分区键,示例如下:
CREATE TABLE test (
`Days` Date,
`Name` String,
`Event` String
) engine=MergeTree()
PARTITION BY (Days) ORDER BY (Name);
通过下面语句查看元信息:
select table ,engine,partition_key,sorting_key,primary_key
from system.tables where table = 'test';
返回表主要字段信息:
┌─table─┬─engine────┬─partition_key─┬─sorting_key─┬─primary_key─┐
│ test │ MergeTree │ Days │ Name │ Name │
└───────┴───────────┴───────────────┴─────────────┴─────────────┘
当定义了分区键,ClickHouse自动路由存入数据至对应块(分区):
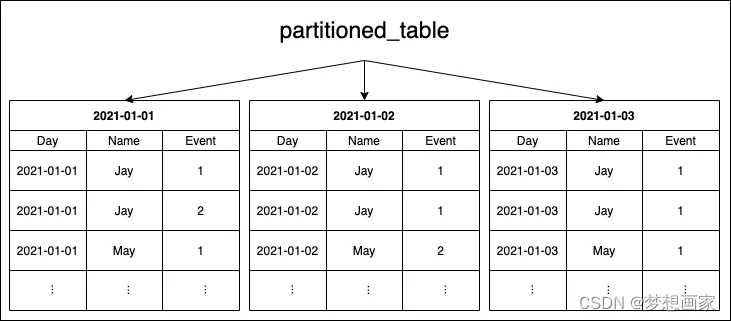
用户看到的仍为单个表,与非分区表一样。但内部表数据被存储在多个分区,下面详细说明。
分区表测试
下面针对相同场景分别定义分区表和非分区表,然后对比读写性能。
非分区表
假设场景需要存储时间序列数据,我们仅需要过去7天数据,每天自动清除过期数据。创建表如下:
CREATE TABLE unpartitioned
(`t` Date, `label` UInt8, `value` UInt32 )
ENGINE = MergeTree ORDER BY (label, t);
通常需要基于t和label 或仅label进行过滤:
SELECT AVG(value) FROM unpartitioned WHERE t = today() AND label = 10
现在填充1亿行测试数据:
INSERT INTO unpartitioned
SELECT today() - rand32() % 10, rand32() % 10000, rand32()
FROM numbers(100000000);
分区表
下面创建分区表:
CREATE TABLE partitioned
(`t` Date, `label` UInt8, `value` UInt32)
ENGINE = MergeTree PARTITION BY t ORDER BY label;
INSERT INTO partitioned SELECT * FROM unpartitioned;
因为使用了t自动作为分区键,则排序字段中就不再需要。下面查看分区的分区情况:
SELECT partition, formatReadableSize(sum(bytes))
FROM system.parts
WHERE table = 'partitioned'
GROUP BY partition
返回结果:
SELECT
partition,
formatReadableSize(sum(bytes))
FROM system.parts
WHERE table = 'partitioned'
GROUP BY partition
Query id: 52db4a34-0640-4fa7-b7a7-49085606ca62
┌─partition──┬─formatReadableSize(sum(bytes_on_disk))─┐
│ 2023-04-12 │ 115.13 MiB │
│ 2023-04-19 │ 115.12 MiB │
│ 2023-04-17 │ 115.09 MiB │
│ 2023-04-14 │ 115.16 MiB │
│ 2023-04-11 │ 115.26 MiB │
│ 2023-04-15 │ 115.16 MiB │
│ 2023-04-10 │ 115.07 MiB │
│ 2023-04-18 │ 115.14 MiB │
│ 2023-04-13 │ 115.25 MiB │
│ 2023-04-16 │ 115.09 MiB │
└────────────┴────────────────────────────────────────┘
我们看到了10个分区(与期望一致),即每天创建了不同分区。
查询性能
针对分区表,ClickHouse会检查分区决定使用哪些分区或跳过哪些分区,性能优劣取决于使用了多少分区。
- 使用单个分区
假设查询下面查询语句:
SELECT avg(value) FROM unpartitioned WHERE t = today() AND label = 10
返回结果:
SELECT avg(value)
FROM unpartitioned
WHERE (t = today()) AND (label = 10)
Query id: f36c9e74-5f6b-4a17-aee6-98ce65867a84
┌─────────avg(value)─┐
│ 2148085697.0056076 │
└────────────────────┘
1 rows in set. Elapsed: 0.031 sec. Processed 122.88 thousand rows, 860.16 KB (3.91 million rows/s., 27.36 MB/s.)
处理了122.88k行,下面查询分区表:
SELECT avg(value)
FROM partitioned
WHERE (t = today()) AND (label = 10)
Query id: 0f4b4a30-c565-4370-b7bc-05c135a35fb7
┌─────────avg(value)─┐
│ 2148085697.0056076 │
└────────────────────┘
1 rows in set. Elapsed: 0.038 sec. Processed 114.69 thousand rows, 802.82 KB (2.98 million rows/s., 20.89 MB/s.)
分区表需要扫描的行数较少,下面分析查询语句进行说明:
EXPLAIN ESTIMATE
SELECT avg(value)
FROM partitioned
WHERE (t = today()) AND (label = 10)
Query id: 23dff40c-b795-46a7-94bf-39018ff06976
┌─database─┬─table───────┬─parts─┬───rows─┬─marks─┐
│ default │ partitioned │ 4 │ 114688 │ 14 │
└──────────┴─────────────┴───────┴────────┴───────┘
1 rows in set. Elapsed: 0.003 sec.
EXPLAIN ESTIMATE
SELECT avg(value)
FROM unpartitioned
WHERE (t = today()) AND (label = 10)
Query id: 4dd38904-52a3-4bed-999a-efe987fe172b
┌─database─┬─table─────────┬─parts─┬───rows─┬─marks─┐
│ default │ unpartitioned │ 5 │ 122880 │ 15 │
└──────────┴───────────────┴───────┴────────┴───────┘
分区表选择4个分区,分区表仅有一个排序键label字段,ClickHouse首先发现目标分区,然后根据label字段进行过滤。查询条件中日期对应的分区一共有5个:
SELECT
partition,
name,
part_type,
formatReadableSize(sum(bytes))
FROM system.parts
WHERE (table = 'partitioned') AND (partition = '2023-04-19')
GROUP BY
partition,
name,
part_type
Query id: 23d89ac3-ff43-4513-a7d0-bd03195b5144
┌─partition──┬─name───────────────┬─part_type─┬─formatReadableSize(sum(bytes_on_disk))─┐
│ 2023-04-19 │ 20230419_510_670_2 │ Wide │ 6.80 MiB │
│ 2023-04-19 │ 20230419_5_496_3 │ Wide │ 20.25 MiB │
│ 2023-04-19 │ 20230419_674_831_2 │ Wide │ 6.89 MiB │
│ 2023-04-19 │ 20230419_905_954_1 │ Compact │ 2.17 MiB │
│ 2023-04-19 │ 20230419_845_899_1 │ Compact │ 2.43 MiB │
└────────────┴────────────────────┴───────────┴────────────────────────────────────────┘
在非分区表,ClickHouse基于排序键(label + t)载入所有可能的部分。
下面换个条件进行对比,跳过分区键:
EXPLAIN ESTIMATE
SELECT avg(value)
FROM partitioned
WHERE label = 10
Query id: eeea741c-e1f7-417b-8dc5-4df029831d49
┌─database─┬─table───────┬─parts─┬───rows─┬─marks─┐
│ default │ partitioned │ 38 │ 720896 │ 88 │
└──────────┴─────────────┴───────┴────────┴───────┘
EXPLAIN ESTIMATE
SELECT avg(value)
FROM unpartitioned
WHERE label = 10
Query id: 2ac544a0-2880-44db-889b-3985fb17f61e
┌─database─┬─table─────────┬─parts─┬───rows─┬─marks─┐
│ default │ unpartitioned │ 5 │ 442368 │ 54 │
└──────────┴───────────────┴───────┴────────┴───────┘
我们看到未分区表仍使用排序键进行过滤,而分区表首先查询相关分区,然后再过滤每个分区,性能显然不如非分区表。
这给我们关于分区表性能的重要启示:
- 如果需要让大多数查询命中单个分区,通常会提高查询性能
- 相反如果查询访问多个分区,则可能导致性能下降
分区会影响读性能,同样排序键也会影响性能。
写性能
使用分区也影响数据的写入方式。当数据到达分区表,ClickHouse首先为数据寻找相应的分区,然后填充(创建并填充)新数据。相比于非分区表这是额外的工作:
INSERT INTO partitioned SELECT
today() - (rand32() % 100),
rand32() % 100,
rand32()
FROM numbers(250000000)
Query id: 8034ae4f-3542-4135-b3ab-714d6fbe17d7
Ok.
0 rows in set. Elapsed: 91.676 sec. Processed 250.60 million rows, 2.00 GB (2.73 million rows/s., 21.87 MB/s.)
INSERT INTO unpartitioned SELECT
today() - (rand32() % 100),
rand32() % 100,
rand32()
FROM numbers(250000000)
Query id: 6922f79e-a920-4567-a47f-e432819f58d2
Ok.
0 rows in set. Elapsed: 47.080 sec. Processed 250.60 million rows, 2.00 GB (5.32 million rows/s., 42.58 MB/s.)
我们可以看到数据插入到分区表和非分区表(label作为排序键)的差异,分区表插入时间为91.676 sec,非分区表为47.080 sec。另外单个查询中插入分区数有一定限制,缺省为100,尝试插入太多分区会产生错误,这里测试SQL一次性包括1000个分区:
INSERT INTO partitioned SELECT
today() - (rand32() % 1000),
rand32() % 100,
rand32()
FROM numbers(250000000)
Query id: 518892e3-9a45-486a-84a7-f05f35dce1d7
0 rows in set. Elapsed: 0.191 sec.
Received exception from server (version 22.2.2):
Code: 252. DB::Exception: Received from localhost:9000. DB::Exception: Too many partitions for single INSERT block (more than 100). The limit is controlled by 'max_partitions_per_insert_block' setting. Large number of partitions is a common misconception. It will lead to severe negative performance impact, including slow server startup, slow INSERT queries and slow SELECT queries. Recommended total number of partitions for a table is under 1000..10000. Please note, that partitioning is not intended to speed up SELECT queries (ORDER BY key is sufficient to make range queries fast). Partitions are intended for data manipulation (DROP PARTITION, etc).. (TOO_MANY_PARTS)
如果需要插入很多分区,不得不分割数据为多个批次,从而减少分区数量。考虑到这一点,当我们插入序列数据(例如时间序列)时,特别适合使用分区表,这样插入批次通常会涉及单个分区或少量分区。
删除分区数据
因为我们仅需要最近7天数据,对于未分区表,需要每天进行删除:
ALTER TABLE unpartitioned DELETE WHERE t < (today() - 7)
该语句属于修改语句,数据行不能被立刻删除,仅被ClickHouse标记。ClickHouse后端程序会在恰当的时间进行永久删除。对于分区表,可以通过删除分区立刻删除数据:
ALTER TABLE partitioned DROP PARTITION '2023-04-17'
分区名(如2023-04-17)可以在system.parts表中找到。该操作属于轻量级操作(仅文件夹在磁盘上被删除),服务端几乎没有性能影响,也能立刻看到表占用空间大小减少。
总结
在Clickhouse中分区功能实现透明地将表拆分为多个块,并能够独立管理这些块(例如删除它们)。分区键应该始终为低基数表达式(如有几十个值)。不要仅为了提高查询性能而考虑分区,同时也要注意到分区表数据写入性能可能会降低。