WAF绕过信息收集
WAF绕过-信息收集之反爬虫延时代理池技术
思维导图
WAF拦截会出现在安全测试的各个层面,掌握各个层面的分析和绕过技术最为关键。

webpathbrute工具
一个Web目录扫描暴力探测工具
WebPathBrute-Web路径暴力探测工具下载:https://github.com/7kbstorm/7kbscan-WebPathBrute
网站部署waf时,采用进程抓包工具抓取webpathbrute数据包分析,一般有2种结果:
- 1.直接误报或者无结果
- 2.扫描一段时间后突然误报
扫描探针机制
- 数据包拦截
- 速度过快拦截
使用WebPathBrute扫描网站目录,当网站服务器分别部署了以下waf时,对拦截机制进行测试分析,结果如下:
演示案例:
Safedog-默认拦截机制分析绕过-未开 CC
一、什么是CC攻击?
CC攻击可以归为DDoS攻击的一种,其原理就是攻击者控制某些主机不停地发大量数据包给对方服务器造成服务器资源耗尽,一直到宕机崩溃。
CC攻击主要模拟多个用户不停地进行访问那些需要大量数据操作的页面,造成服务器资源的浪费,使CPU长时间处于100%,永远都有处理不完的连接直至网络拥塞,令正常的访问被中止。
同时,CC攻击的IP都是真实、分散的,并且都是正常的数据包,全都是有效且无法拒绝的请求。
另外,因为CC攻击的目标是网页,所以服务器什么的都可以连接,ping也没问题,但是网页就是无法访问。
二、实践过程
safedog ——CC攻击防护默认是关闭的,我们直接开启实验:

1.用铸剑目录扫描工具扫描目录模拟cc攻击
该工具是通过网站的状态码判断是否成功

发现扫描出来的状态码都是200,登录发现目标是不存在的。
这表示扫描出来的目录都是假的。
- 扫描结果:出现误报,全部200状态码
2.抓包分析
我们抓取正常访问的数据包和工具扫描·的数据包进行对比。
工具WSExolorer:工具可以抓取指定软件流量包
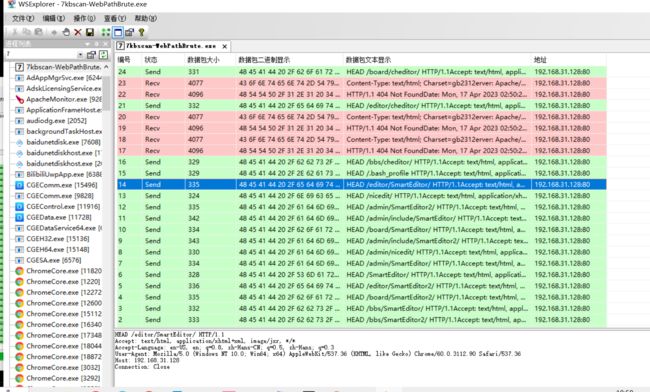
结果:

可以很明显的看出不同,在请求方法上就不同。可以修改为Get方式。
- 原因:浏览器采用get方法,工具扫描采用head方法。
[
没有误报了。

Safedog-开启CC
一、正常思路
防护规则:
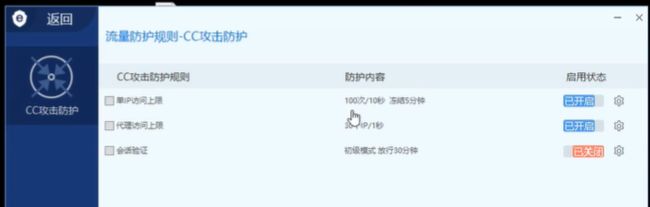
开启CC之后,再次使用扫描工具,并且访问网站。
- 扫描结果:误报

登录发现以及被拦截无法访问网站了

原因:频繁访问(访问频率过快,被安全狗拦截判断为工具),触发安全狗防护机制,被拦截
二、绕过方法
方法1:可以设置延迟扫描。
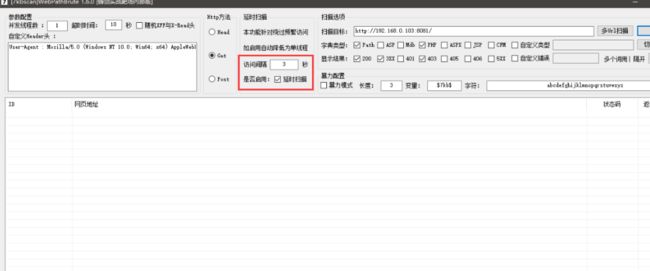
- 特定:开启延时扫描,慢速扫描,缺点是速度过慢。
方法2:可以使用安全狗开启的爬虫白名单机制绕过
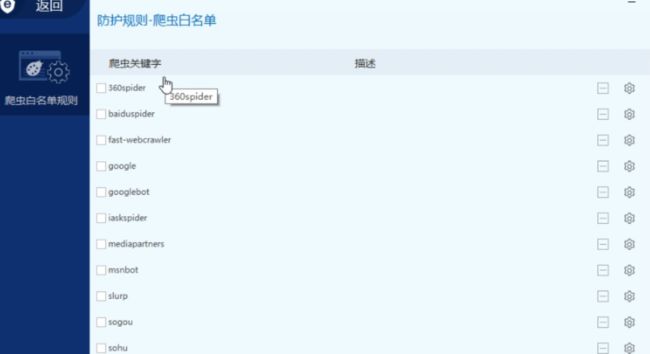
可以使用工具模拟搜索引擎请求头User-Agent
- 模拟搜索引擎请求头User-Agent进行扫描
- 各大搜索引擎的User-Agent:https://www.cnblogs.com/iack/p/3557371.html
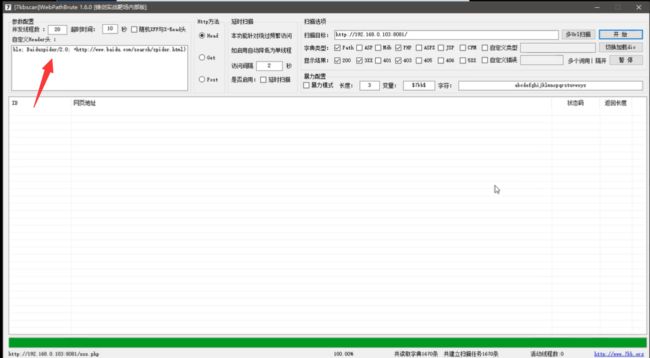
但是扫描没有结果!
原因是软件只修改了头部,但是发送的数据包还是不完整,被拦截了。
因此我们编写爬虫脚本:添加完整的数据包
模拟用户正常来访问
import requests
import time
headers = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie': 'PHPSESSID=4d6f9bc8de5e7456fd24d60d2dfd5e5a',
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Microsoft Edge";v="92"',
'sec-ch-ua-mobile': '?0',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (compatible; Baiduspider-render/2.0; +http://www.baidu.com/search/spider.html)'
}
for paths in open('php_b.txt', encoding='utf-8'):
url = "http://127.0.0.1/pikachu"
paths = paths.replace('\n', '')
urls = url + paths
proxy = {
'http': '127.0.0.1:7777'
}
try:
code = requests.get(urls, headers=headers, proxies=proxy).status_code
# time.sleep(3)
print(urls + '|' + str(code))
except Exception as err:
print('connect error')
time.sleep(3)
//这里php_b.txt是爆破的目录字典
//head里面放入正常的数据包头部信息
开启测试 -抓包分析:
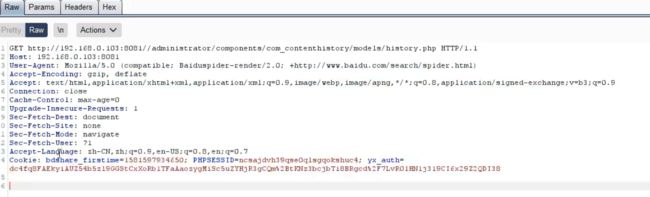

结果正常。在脚本headrs中使用爬虫引擎的UA,就能正常扫描。

如果未使用自定义数据包:结果
被服务器识别出是python脚本
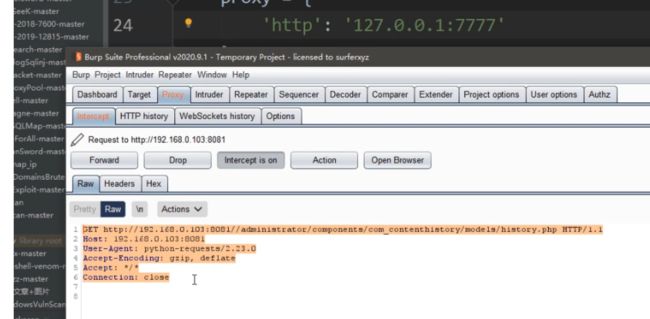
未使用爬虫的UA,因为开启了CC,访问过快,扫描会被拦截,产生误报!


方法3:使用代理池
代理ip的应用范围非常广泛,它的主要应用场景有:
**突破访问限制:**部分网站会根据用户的IP地址进行访问限制,使用代理ip可以绕过这些限制。
**爬虫数据采集:**在批量数据采集中,爬虫程序需要使用到代理ip来防止被目标网站封禁或限制访问。
**提高网络安全性:**通过使用代理IP隐藏真实IP地址,可以防止黑客攻击和网络钓鱼等安全威胁。

爬虫代理设置:
通常购买代理后平台会提供IP地址、端口号、账号、密码,在代码中设置代理时,代理数据类型通常为字典类型。格式如下:
proxy = { 'https://': 'http://%(ip)s:%(port)s' % {"ip":ip,"port":port},
'http://': 'http://%(ip)s:%(port)s' % {"ip":ip,"port":port} }
例如:
在requests中设置代理非常简单,Request对象中提供了一个参数来设置代理。
import requests
proxy = {
'https': 'http://112.74.202.247:16816',
'http': 'http://112.74.202.247:16816'
}
url = 'http://httpbin.org/get'
response = requests.get(url,proxies=proxy)
print(response.json())
#proxies的格式是一个字典,爬虫借助该函数设置代理
检测ip代理,一般是CC防护,但是使用代理,扫描目录,大概率是可行的。
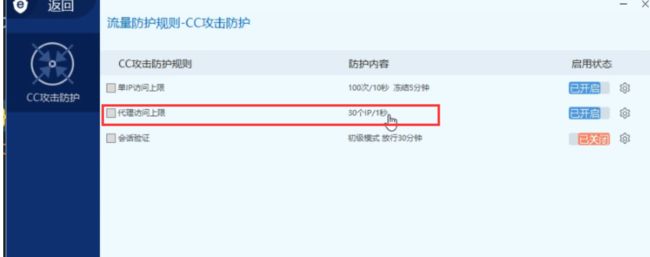
阿里云-默认拦截机制分析绕过-简要界面
扫描结果:对部署在阿里云上的网站进行目录扫描时,扫着扫着网站就打不开了,大约1个小时后才能重新打开,重启服务器也不能使网站重新打开,只能等一个小时,猜测这是因为阿里云自己有一套防护体系。
即:
阿里云-无法模拟搜索引擎爬虫绕过,只能采用代理池或者延时。
阿里云+宝塔+安全狗付费安全服务
在三个都开启的情况下,取共同绕过点

宝塔付费页面:

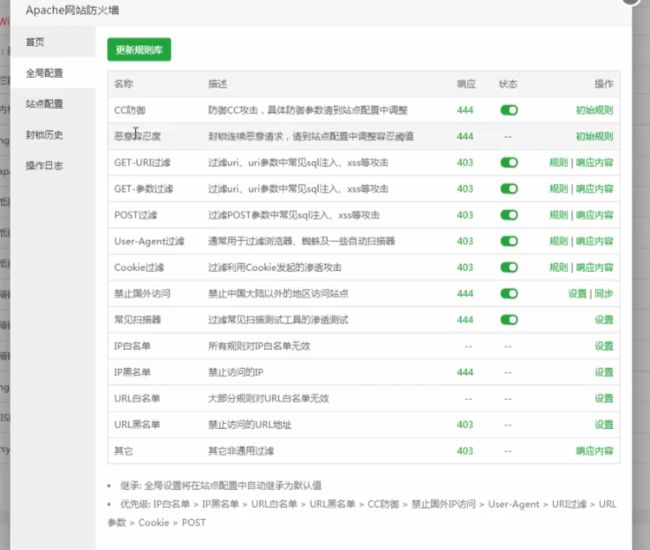
使用代理池开启扫描:
扫描3个后发现无法正常显示了,不是alliyun拦截的,而是BT的防火墙拦截的。
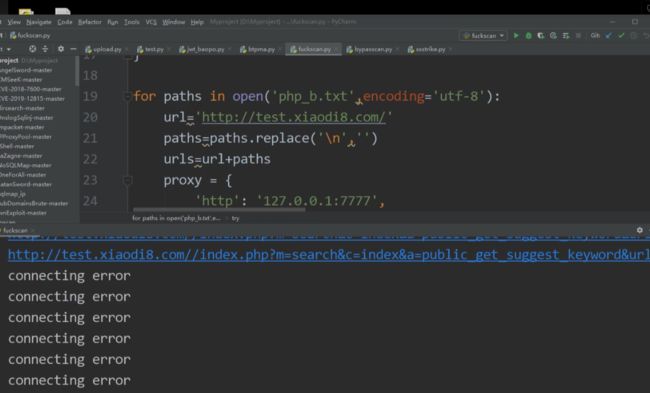

宝塔里的日志还是会显示:
宝塔会通过判断是不是在频繁扫描后缀特殊特殊的目录,来进行拦截
如:bak,zip等等

绕过方法:
1.重新编写字典,将字典拆开使用 ,绕过他的恶意容忍机制60秒内6次
2.通过添加上延时来搞:
3.将字典改为:
ode.php.bak 可以优化成code.php.bak .访问的还是原来的。
类似于文件上传绕过的规则。
总结:
python编写绕过脚本,进行目录扫描
- 自定义headers头部,模拟用户
- 休眠3秒,模拟延时(测试发现,阿里云至少休眠3秒,否则拦截)
- 添加proxy,从网上爬取代理池,按需添加,比如一个代理发10个请求,接着换另一个代理。
- 脚本如下
![]() 绕过waf脚本-单线程
绕过waf脚本-单线程