每日学术速递4.19
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
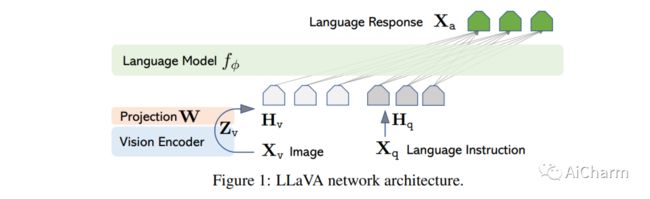
1.Visual Instruction Tuning

标题:可视化指令调优
作者:Haotian Liu, Chunyuan Li, Qingyang Wu, Yong Jae Lee
文章链接:https://arxiv.org/abs/2304.08485
项目代码:https://llava-vl.github.io/


摘要:
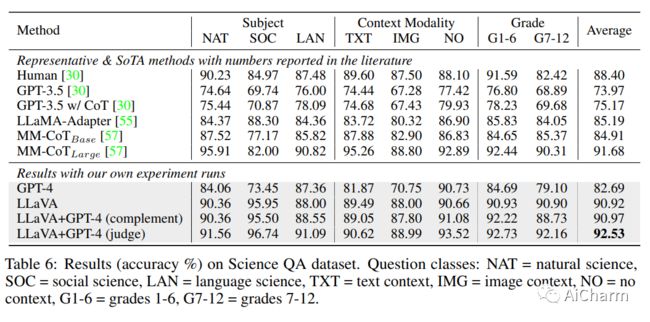
使用机器生成的指令跟踪数据对大型语言模型 (LLM) 进行指令调优提高了新任务的零样本能力,但这一想法在多模式领域的探索较少。在本文中,我们首次尝试使用纯语言 GPT-4 生成多模态语言图像指令跟踪数据。通过对此类生成的数据进行指令调整,我们介绍了 LLaVA:大型语言和视觉助手,这是一种端到端训练的大型多模态模型,连接视觉编码器和 LLM 以实现通用视觉和语言理解。我们的早期实验表明,LLaVA展示了令人印象深刻的多模型聊天能力,有时在看不见的图像/指令上表现出多模态 GPT-4 的行为,并且与合成多模态指令跟随数据集上的 GPT-4 相比,产生了 85.1% 的相对分数。当在 Science QA 上进行微调时,LLaVA 和 GPT-4 的协同作用达到了 92.53% 的新的最先进的准确率。我们公开了 GPT-4 生成的视觉指令调整数据、我们的模型和代码库。
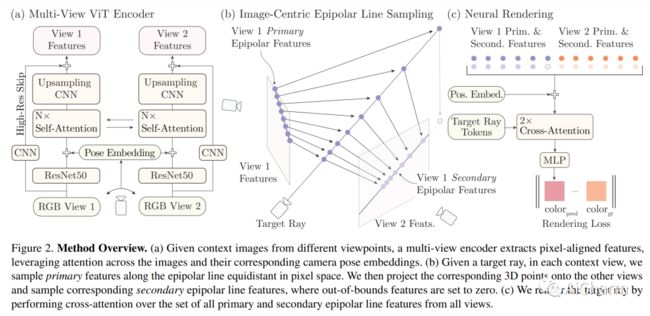
2.Learning to Render Novel Views from Wide-Baseline Stereo Pairs(CVPR 2023 )

标题:学习从宽基线立体对中渲染新颖的视图
作者:Yilun Du, Cameron Smith, Ayush Tewari, Vincent Sitzmann
文章链接:https://arxiv.org/abs/2304.08463
项目代码:https://yilundu.github.io/wide_baseline/
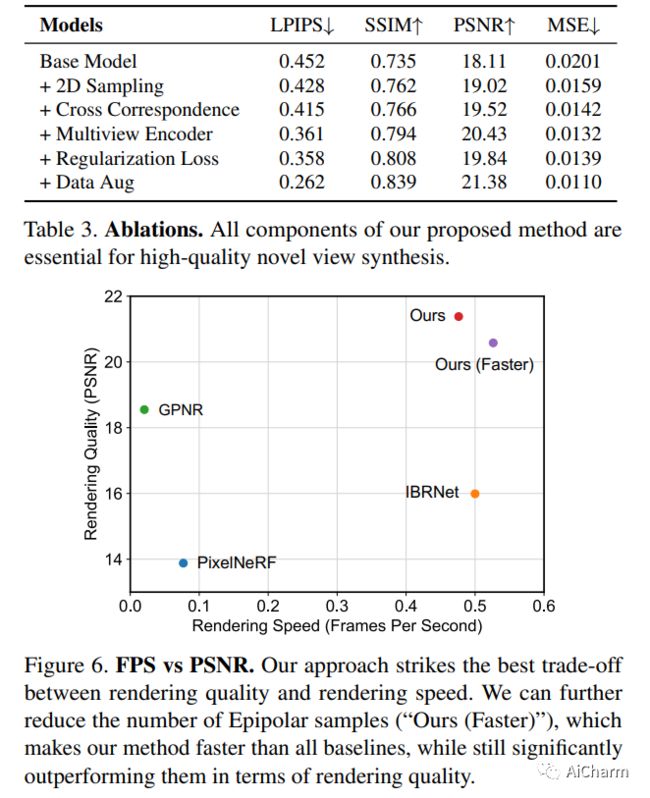

摘要:
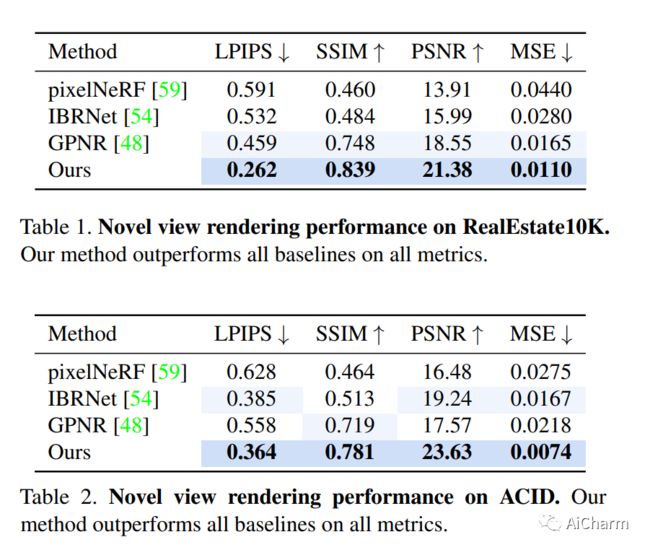
我们介绍了一种仅给定单个宽基线立体图像对的新颖视图合成方法。在这个具有挑战性的制度中,3D 场景点仅定期观察一次,需要基于先验的场景几何和外观重建。我们发现,由于恢复不正确的 3D 几何形状,以及由于可微分渲染的高成本阻碍了它们扩展到大规模训练,现有的从稀疏观察合成新视图的方法失败了。我们朝着解决这些缺点迈出了一步,制定了多视图变换器编码器,提出了一种高效的图像空间极线采样方案来为目标射线组装图像特征,以及一种基于交叉注意力的轻量级渲染器。我们的贡献使我们的方法能够在室内和室外场景的大规模真实世界数据集上进行训练。我们证明了我们的方法在减少渲染时间的同时学习了强大的多视图几何先验。我们对两个真实世界数据集的保留测试场景进行了广泛的比较,显着优于先前从稀疏图像观察到新视图合成的工作,并实现了多视图一致的新视图合成。
3.DETRs Beat YOLOs on Real-time Object Detection

标题:DETRs 在实时目标检测上击败 YOLOs
作者:Wenyu Lv, Shangliang Xu, Yian Zhao, Guanzhong Wang, Jinman Wei, Cheng Cui, Yuning Du, Qingqing Dang, Yi Liu
文章链接:https://arxiv.org/abs/2304.08069
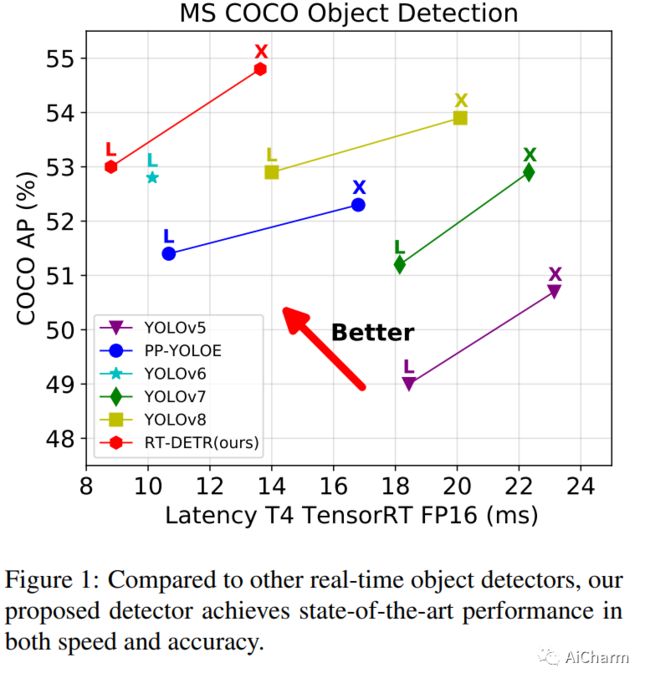
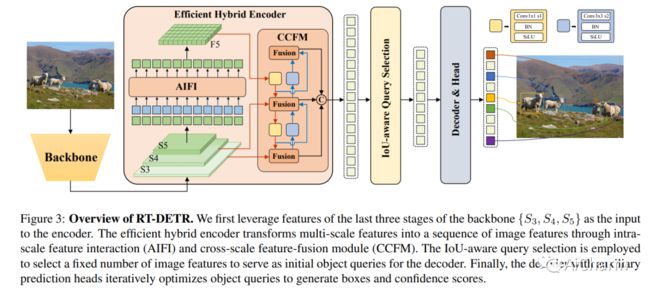
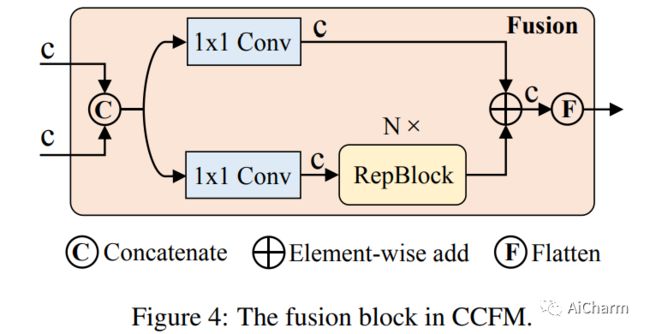
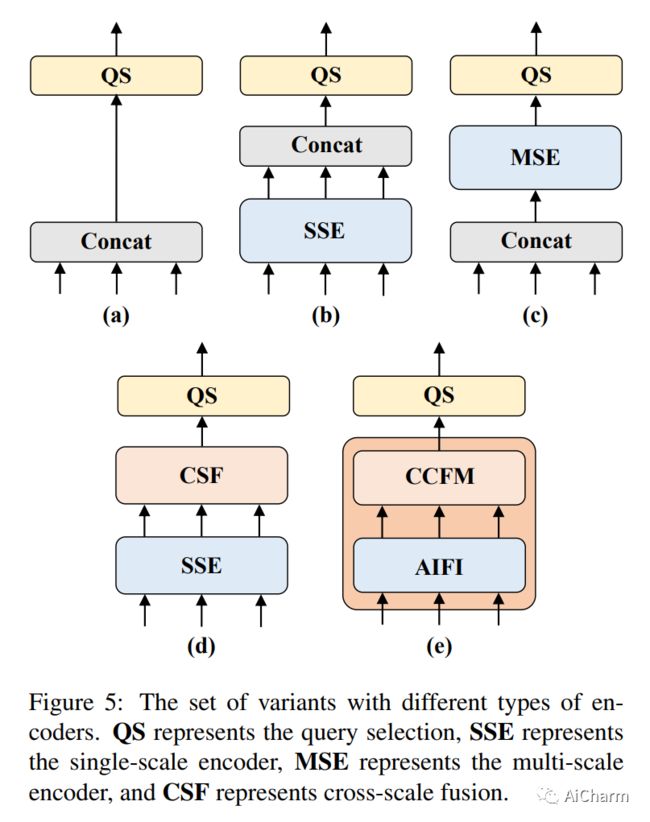
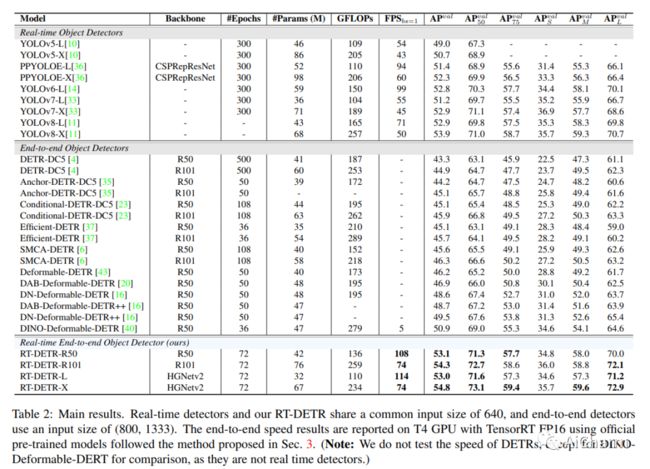
摘要:
最近,基于端到端变压器的检测器 (DETR) 取得了显着的性能。然而,DETRs 的高计算成本问题尚未得到有效解决,限制了它们的实际应用并阻止它们充分利用无后处理的好处,例如非最大抑制 (NMS)。在本文中,我们首先分析了现代实时目标检测器中 NMS 对推理速度的影响,并建立了端到端速度基准。为了避免 NMS 引起的推理延迟,我们提出了实时检测转换器 (RT-DETR),据我们所知,这是第一个实时端到端对象检测器。具体来说,我们设计了一种高效的混合编码器,通过解耦尺度内交互和跨尺度融合来高效处理多尺度特征,并提出 IoU 感知查询选择以改进对象查询的初始化。此外,我们提出的检测器支持通过使用不同的解码器层灵活调整推理速度而无需重新训练,这有助于实时目标检测器的实际应用。我们的 RT-DETR-L 在 COCO val2017 上实现了 53.0% 的 AP,在 T4 GPU 上实现了 114 FPS,而 RT-DETR-X 实现了 54.8% 的 AP 和 74 FPS,在速度和精度上都优于所有相同规模的 YOLO 检测器。此外,我们的 RT-DETR-R50 达到了 53.1% AP 和 108 FPS,准确率比 DINO-Deformable-DETR-R50 高出 2.2% AP,在 FPS 上高出约 21 倍。PaddleDetection 将提供源代码和预训练模型。
更多Ai资讯:公主号AiCharm