搜索实现之lucene
一 搜索技术
1.1 搜索分类
搜索引擎按照功能分类,通常分为垂直搜索和综合搜索。
- 垂直搜索:指的是专门针对某一类信息进行搜索。例如:会搜网,主要是做商务搜索的,并提供商务信息。
- 综合搜索:指的是对众多系你行进行综合性搜索。例如:百度,谷歌,搜狗等。
1.2 倒排索引
倒排索引又叫反向索引,如下图。搜索字或词在文档中出现的位置。

在实际的运用中,我们可以对数据库中原始的数据结构(左图),在业务空闲时事先根据左图内容,创建新的倒排索引结构的数据区域(右图)。
用户有查询需求时,先访问倒排索引数据区域(右图),得出文档id后,通过文档id即可快速,准确的通过左图找到具体的文档内容。
这一过程,可以通过我们自己写程序来实现,也可以借用已经抽象出来的通用开源技术来实现。
二 lucene概述
2.1 lucene是什么
- Lucene是一套用于全文检索和搜寻的开源程序库,由Apache软件基金会支持和提供
- Lucene提供了一个简单却强大的应用程序接口(API),能够做全文索引和搜寻,在Java开发环境里Lucene是一个成熟的免费开放源代码工
- Lucene并不是现成的搜索引擎产品,但可以用来制作搜索引擎产品。
- 官网:http://lucene.apache.org/
2.2 全文检索
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
全文检索的方法主要分为按字检索和按词检索两种。按字检索是指对于文章中的每一个字都建立索引,检索时将词分解为字的组合。对于各种不同的语言而言,字有不同的含义,比如英文中字与词实际上是合一的,而中文中字与词有很大分别。按词检索指对文章中的词,即语义单位建立索引,检索时按词检索,并且可以处理同义项等。英文等西方文字由于按照空白切分词,因此实现上与按字处理类似,添加同义处理也很容易。中文等东方文字则需要切分字词,以达到按词索引的目的,关于这方面的问题,是当前全文检索技术尤其是中文全文检索技术中的难点,在此不做详述/、。
lucene全文检索就是对文档的全部内容进行分词,然后对所有的单词建立倒排索引的过程。
2.3 lucene的下载
官网:
目前最新的版本是7.x系列,但是在企业中还是用4.x比较多,所以我们学习4.x的版本。老版本下载地址:http://archive.apache.org/dist/lucene/java/
2.4 lucene,solr,ElasticSearch关系
-
Lucene:底层的API,工具包
-
Solr:基于Lucene开发的企业级的搜索引擎产品
-
Elasticsearch:基于Lucene开发的企业级的搜索引擎产品
三 lucene基本使用
使用Lucene的API来实现对索引的增(创建索引)、删(删除索引)、改(修改索引)、查(搜索数据)。
3.1 基本概念了解
3.1.1 索引创建流程

- 文档document: 文档对象,数据库中一条具体的记录
- 字段Field: 数据库中的每个字段。
- 目录对象Directory: 物理存储的位置。
- 写出器配置对象:需要分词器和lucene的版本去配置。
3.1.2 添加依赖

<properties>
<lunece.version>4.10.2</lunece.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<!-- lucene核心库 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>${lunece.version}</version>
</dependency>
<!-- Lucene的查询解析器 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>${lunece.version}</version>
</dependency>
<!-- lucene的默认分词器库 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>${lunece.version}</version>
</dependency>
<!-- lucene的高亮显示 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-highlighter</artifactId>
<version>${lunece.version}</version>
</dependency>
</dependencies>
3.2 创建索引
3.2.1 代码实现
步骤:
1 创建文档对象
2 创建存储目录
3 创建分词器
4 创建索引写入器的配置对象
5 创建索引写入器对象
6 将文档交给索引写入器
7 提交
8 关闭
示例:
// 创建索引
@Test
public void testCreate() throws Exception{
//1 创建文档对象
Document document = new Document();
// 创建并添加字段信息。参数:字段的名称、字段的值、是否存储,这里选Store.YES代表存储到文档列表。Store.NO代表不存储
document.add(new StringField("id", "1", Field.Store.YES));
// 这里我们title字段需要用TextField,即创建索引又会被分词。
document.add(new TextField("title", "谷歌地图之父跳槽facebook", Field.Store.YES));
//2 索引目录类,指定索引在硬盘中的位置
Directory directory = FSDirectory.open(new File("d:\\indexDir"));
//3 创建分词器对象
Analyzer analyzer = new StandardAnalyzer();
//4 索引写出工具的配置对象
IndexWriterConfig conf = new IndexWriterConfig(Version.LATEST, analyzer);
//5 创建索引的写出工具类。参数:索引的目录和配置信息
IndexWriter indexWriter = new IndexWriter(directory, conf);
//6 把文档交给IndexWriter
indexWriter.addDocument(document);
//7 提交
indexWriter.commit();
//8 关闭
indexWriter.close();
}
查看本地磁盘:
3.2.2 Api详解
1,Document文档类
Document:文档对象,是一条原始的数据

2,Field类
一个Document中可以有很多个不同的字段,每一个字段都是一个Field类的对象。其中字段其类型是不确定的,因此Field类就提供了各种不同的子类,来对应这些不同类型的字段。

- DoubleField、FloatField、IntField、LongField、StringField这些子类一定会被创建索引,但是不会被分词,而且不一定会被存储到文档列表。要通过构造函数中的参数Store来指定:如果Store.YES代表存储,Store.NO代表不存储。

- TextField即创建索引,又会被分词。StringField会创建索引,但是不会被分词。如果不分词,会造成整个字段作为一个词条,除非用户完全匹配,否则搜索不到
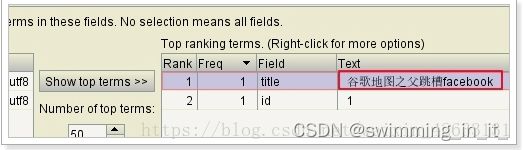 我们一般,需要搜索的字段,都会做分词:
我们一般,需要搜索的字段,都会做分词:

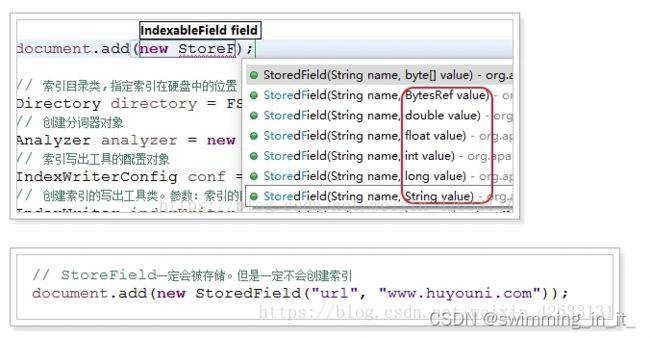
- StoreField一定会被存储,但是一定不创建索引。StoredField可以创建各种数据类型的字段:
问题1:如何确定一个字段是否需要存储?
如果一个字段要显示到最终的结果中,那么一定要存储,否则就不存储
问题2:如何确定一个字段是否需要创建索引?
如果要根据这个字段进行搜索,那么这个字段就必须创建索引。
问题3:如何确定一个字段是否需要分词?
前提是这个字段首先要创建索引。然后如果这个字段的值是不可分割的,那么就不需要分词。例如:ID
3,目录类(directory)
指定索引要存储的位置
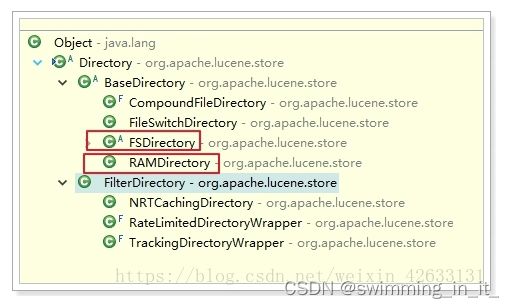
- FSDirectory:文件系统目录,会把索引库指向本地磁盘。速度略慢,但是比较安全
- RAMDirectory:内存目录,会把索引库保存在内存。速度快但是不安全。
4,Analyzer(分词器类)
提供分词算法,可以把文档中的数据按照算法分词
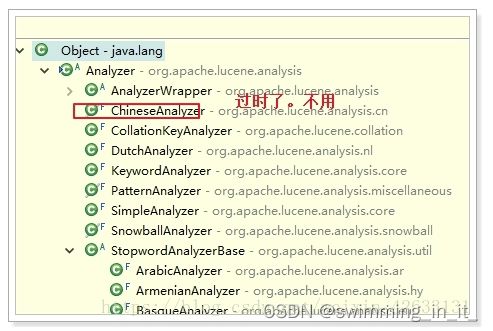 这些分词器,并没有合适的中文分词器,因此一般我们会用第三方提供的分词器:一般我们用IK分词器。
这些分词器,并没有合适的中文分词器,因此一般我们会用第三方提供的分词器:一般我们用IK分词器。
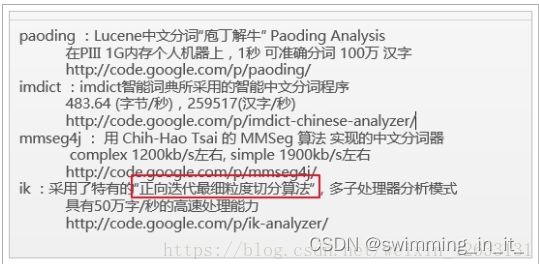
IK分词器:
IK分词器官方版本是不支持Lucene4.X的,有人基于IK的源码做了改造,支持了Lucene4.X:
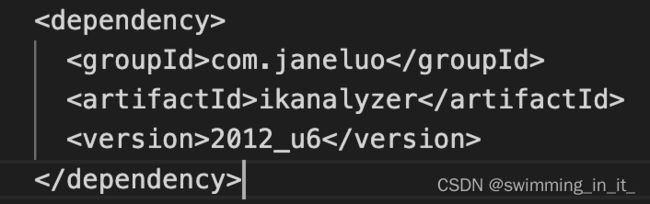
引入IK分词器:
IK分词器的词库有限,新增加的词条可以通过配置文件添加到IK的词库中,也可以把一些不用的词条去除。


4,IndexWriterConfig(索引写出器配置类)
- 设置配置信息:Lucene的版本和分词器类型

- 设置是否清空索引库中的数据。

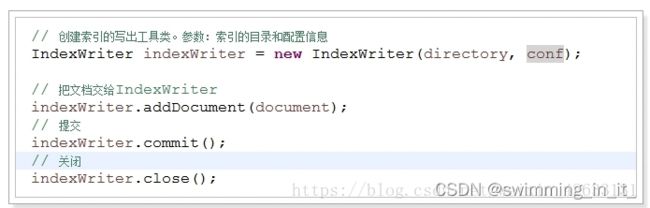
5,IndexWriter(索引写出器类)
索引写出工具,作用就是 实现对索引的增(创建索引)、删(删除索引)、改(修改索引)
可以一次创建一个,也可以批量创建索引:
// 批量创建索引
@Test
public void testCreate2() throws Exception{
// 创建文档的集合
Collection<Document> docs = new ArrayList<>();
// 创建文档对象
Document document1 = new Document();
document1.add(new StringField("id", "1", Field.Store.YES));
document1.add(new TextField("title", "谷歌地图之父跳槽facebook", Field.Store.YES));
docs.add(document1);
// 创建文档对象
Document document2 = new Document();
document2.add(new StringField("id", "2", Field.Store.YES));
document2.add(new TextField("title", "谷歌地图之父加盟FaceBook", Field.Store.YES));
docs.add(document2);
// 创建文档对象
Document document3 = new Document();
document3.add(new StringField("id", "3", Field.Store.YES));
document3.add(new TextField("title", "谷歌地图创始人拉斯离开谷歌加盟Facebook", Field.Store.YES));
docs.add(document3);
// 创建文档对象
Document document4 = new Document();
document4.add(new StringField("id", "4", Field.Store.YES));
document4.add(new TextField("title", "谷歌地图之父跳槽Facebook与Wave项目取消有关", Field.Store.YES));
docs.add(document4);
// 创建文档对象
Document document5 = new Document();
document5.add(new StringField("id", "5", Field.Store.YES));
document5.add(new TextField("title", "谷歌地图之父拉斯加盟社交网站Facebook", Field.Store.YES));
docs.add(document5);
// 索引目录类,指定索引在硬盘中的位置
Directory directory = FSDirectory.open(new File("d:\\indexDir"));
// 引入IK分词器
Analyzer analyzer = new IKAnalyzer();
// 索引写出工具的配置对象
IndexWriterConfig conf = new IndexWriterConfig(Version.LATEST, analyzer);
// 设置打开方式:OpenMode.APPEND 会在索引库的基础上追加新索引。OpenMode.CREATE会先清空原来数据,再提交新的索引
conf.setOpenMode(IndexWriterConfig.OpenMode.CREATE);
// 创建索引的写出工具类。参数:索引的目录和配置信息
IndexWriter indexWriter = new IndexWriter(directory, conf);
// 把文档集合交给IndexWriter
indexWriter.addDocuments(docs);
// 提交
indexWriter.commit();
// 关闭
indexWriter.close();
}
3.3 查询索引
3.3.1 代码实现
步骤:
1 创建读取目录对象
2 创建索引读取工具
3 创建索引搜索工具
4 创建查询解析器
5 创建查询对象
6 搜索数据
7 各种操作
代码实现:
@Test
public void testSearch() throws Exception {
// 索引目录对象
Directory directory = FSDirectory.open(new File("d:\\indexDir"));
// 索引读取工具
IndexReader reader = DirectoryReader.open(directory);
// 索引搜索工具
IndexSearcher searcher = new IndexSearcher(reader);
// 创建查询解析器,两个参数:默认要查询的字段的名称,分词器
QueryParser parser = new QueryParser("title", new IKAnalyzer());
// 创建查询对象
Query query = parser.parse("谷歌");
// 搜索数据,两个参数:查询条件对象要查询的最大结果条数
// 返回的结果是 按照匹配度排名得分前N名的文档信息(包含查询到的总条数信息、所有符合条件的文档的编号信息)。
TopDocs topDocs = searcher.search(query, 10);
// 获取总条数
System.out.println("本次搜索共找到" + topDocs.totalHits + "条数据");
// 获取得分文档对象(ScoreDoc)数组.SocreDoc中包含:文档的编号、文档的得分
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
// 取出文档编号
int docID = scoreDoc.doc;
// 根据编号去找文档
Document doc = reader.document(docID);
System.out.println("id: " + doc.get("id"));
System.out.println("title: " + doc.get("title"));
// 取出文档得分
System.out.println("得分: " + scoreDoc.score);
}
}
3.3.2 Api详解
1,QueryParser(查询解析器)
- QueryParser:单一字段查询解析器。

- MultiFieldQueryParser:多字段查询解析器。

2,Query(查询对象)
- 通过QueryParser解析关键字,得到查询对象

- 自定义查询对象(高级查询):通过Query的子类创建查询对象实现高级查询,后面详述。
3,IndexSearch(索引搜索对象,执行搜索功能)
IndexSearch可以帮助我们实现:快速搜索、排序、打分等功能。IndexSearch需要依赖IndexReader类

查询后得到的结果,就是打分排序后的前N名结果。N可以通过第2个参数来指定:

4,TopDocs(查询结果对象)
通过IndexSearcher对象,我们可以搜索,获取结果,TopDocs对象,包含两部分信息:
- int totalHits:查询到的总条数
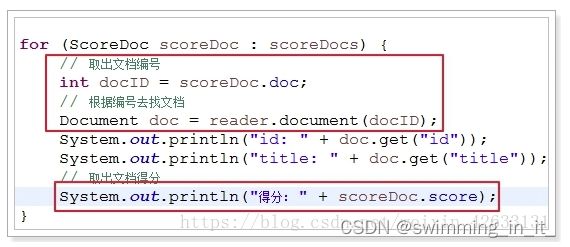
- ScoreDoc[] scoreDocs:查询到的文档对象数组。

ScoreDoc是得分文档对象,包含两部分数据,拿到编号后,我们还需要根据编号来获取真正的文档信息。
- int doc:文档编号,lucene内文档的唯一编号
- float score: 文档的得分信息。
5,特殊查询
1)抽取公用的搜索方法
public void search(Query query) throws Exception {
// 索引目录对象
Directory directory = FSDirectory.open(new File("indexDir"));
// 索引读取工具
IndexReader reader = DirectoryReader.open(directory);
// 索引搜索工具
IndexSearcher searcher = new IndexSearcher(reader);
// 搜索数据,两个参数:查询条件对象要查询的最大结果条数
// 返回的结果是 按照匹配度排名得分前N名的文档信息(包含查询到的总条数信息、所有符合条件的文档的编号信息)。
TopDocs topDocs = searcher.search(query, 10);
// 获取总条数
System.out.println("本次搜索共找到" + topDocs.totalHits + "条数据");
// 获取得分文档对象(ScoreDoc)数组.SocreDoc中包含:文档的编号、文档的得分
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
// 取出文档编号
int docID = scoreDoc.doc;
// 根据编号去找文档
Document doc = reader.document(docID);
System.out.println("id: " + doc.get("id"));
System.out.println("title: " + doc.get("title"));
// 取出文档得分
System.out.println("得分: " + scoreDoc.score);
}
}
2) TermQuery(词条查询)
/*
* 测试普通词条查询
* 注意:Term(词条)是搜索的最小单位,不可再分词。值必须是字符串!
*/
@Test
public void testTermQuery() throws Exception {
// 创建词条查询对象
Query query = new TermQuery(new Term("title", "谷歌地图"));
search(query);
}

3) WildcardQuery(通配符查询)
/*
* 测试通配符查询
* ? 可以代表任意一个字符
* * 可以任意多个任意字符
*/
@Test
public void testWildCardQuery() throws Exception {
// 创建查询对象
Query query = new WildcardQuery(new Term("title", "*歌*"));
search(query);
}
4) FuzzyQuery(模糊查询)
/*
* 测试模糊查询
*/
@Test
public void testFuzzyQuery() throws Exception {
// 创建模糊查询对象:允许用户输错。但是要求错误的最大编辑距离不能超过2
// 编辑距离:一个单词到另一个单词最少要修改的次数 facebool --> facebook 需要编辑1次,编辑距离就是1
// Query query = new FuzzyQuery(new Term("title","fscevool"));
// 可以手动指定编辑距离,但是参数必须在0~2之间
Query query = new FuzzyQuery(new Term("title","facevool"),1);
search(query);
}
5) NumericRangeQuery(数值范围查询)
/*
* 测试:数值范围查询
* 注意:数值范围查询,可以用来对非String类型的ID进行精确的查找
*/
@Test
public void testNumericRangeQuery() throws Exception{
// 数值范围查询对象,参数:字段名称,最小值、最大值、是否包含最小值、是否包含最大值
Query query = NumericRangeQuery.newLongRange("id", 2L, 2L, true, true);
search(query);
}
6)BooleanQuery(组合查询)
/*
* 布尔查询:
* 布尔查询本身没有查询条件,可以把其它查询通过逻辑运算进行组合!
* 交集:Occur.MUST + Occur.MUST
* 并集:Occur.SHOULD + Occur.SHOULD
* 非:Occur.MUST_NOT
*/
@Test
public void testBooleanQuery() throws Exception{
Query query1 = NumericRangeQuery.newLongRange("id", 1L, 3L, true, true);
Query query2 = NumericRangeQuery.newLongRange("id", 2L, 4L, true, true);
// 创建布尔查询的对象
BooleanQuery query = new BooleanQuery();
// 组合其它查询
query.add(query1, BooleanClause.Occur.MUST_NOT);
query.add(query2, BooleanClause.Occur.SHOULD);
search(query);
}
3.4 修改索引
步骤:
1 创建文档存储目录
2 创建索引写入器配置对象
3 创建索引写入器
4 创建文档数据
5 修改
6 提交
7 关闭
/* 测试:修改索引
* 注意:
* A:Lucene修改功能底层会先删除,再把新的文档添加。
* B:修改功能会根据Term进行匹配,所有匹配到的都会被删除。这样不好
* C:因此,一般我们修改时,都会根据一个唯一不重复字段进行匹配修改。例如ID
* D:但是词条搜索,要求ID必须是字符串。如果不是,这个方法就不能用。
* 如果ID是数值类型,我们不能直接去修改。可以先手动删除deleteDocuments(数值范围查询锁定ID),再添加。
*/
@Test
public void testUpdate() throws Exception{
// 创建目录对象
Directory directory = FSDirectory.open(new File("indexDir"));
// 创建配置对象
IndexWriterConfig conf = new IndexWriterConfig(Version.LATEST, new IKAnalyzer());
// 创建索引写出工具
IndexWriter writer = new IndexWriter(directory, conf);
// 创建新的文档数据
Document doc = new Document();
doc.add(new StringField("id","1",Store.YES));
doc.add(new TextField("title","谷歌地图之父跳槽facebook ",Store.YES));
/* 修改索引。参数:
* 词条:根据这个词条匹配到的所有文档都会被修改
* 文档信息:要修改的新的文档数据
*/
writer.updateDocument(new Term("id","1"), doc);
// 提交
writer.commit();
// 关闭
writer.close();
}
3.5 删除索引
步骤:
1 创建文档对象目录
2 创建索引写入器配置对象
3 创建索引写入器
4 删除
5 提交
6 关闭
/*
* 演示:删除索引
* 注意:
* 一般,为了进行精确删除,我们会根据唯一字段来删除。比如ID
* 如果是用Term删除,要求ID也必须是字符串类型!
*/
@Test
public void testDelete() throws Exception {
// 创建目录对象
Directory directory = FSDirectory.open(new File("indexDir"));
// 创建配置对象
IndexWriterConfig conf = new IndexWriterConfig(Version.LATEST, new IKAnalyzer());
// 创建索引写出工具
IndexWriter writer = new IndexWriter(directory, conf);
// 根据词条进行删除
// writer.deleteDocuments(new Term("id", "1"));
// 根据query对象删除,如果ID是数值类型,那么我们可以用数值范围查询锁定一个具体的ID
// Query query = NumericRangeQuery.newLongRange("id", 2L, 2L, true, true);
// writer.deleteDocuments(query);
// 删除所有
writer.deleteAll();
// 提交
writer.commit();
// 关闭
writer.close();
}
四 lucene的高级使用
4.1 lucene的高亮显示
原理:
- 给所有的关键字加上一个HTML标签
- 给特殊标签设置css样式
实现步骤:
1 创建目录 对象
2 创建索引读取工具
3 创建索引搜索工具
4 创建查询解析器
5 创建查询对象
6 创建格式化器
7 创建查询分数工具
8 准备高亮工具
9 搜索
10 获取结果
11 用高亮工具处理普通的查询结果
实现代码:
// 高亮显示
@Test
public void testHighlighter() throws Exception {
// 目录对象
Directory directory = FSDirectory.open(new File("indexDir"));
// 创建读取工具
IndexReader reader = DirectoryReader.open(directory);
// 创建搜索工具
IndexSearcher searcher = new IndexSearcher(reader);
QueryParser parser = new QueryParser("title", new IKAnalyzer());
Query query = parser.parse("谷歌地图");
// 格式化器
Formatter formatter = new SimpleHTMLFormatter("", "");
QueryScorer scorer = new QueryScorer(query);
// 准备高亮工具
Highlighter highlighter = new Highlighter(formatter, scorer);
// 搜索
TopDocs topDocs = searcher.search(query, 10);
System.out.println("本次搜索共" + topDocs.totalHits + "条数据");
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
// 获取文档编号
int docID = scoreDoc.doc;
Document doc = reader.document(docID);
System.out.println("id: " + doc.get("id"));
String title = doc.get("title");
// 用高亮工具处理普通的查询结果,参数:分词器,要高亮的字段的名称,高亮字段的原始值
String hTitle = highlighter.getBestFragment(new IKAnalyzer(), "title", title);
System.out.println("title: " + hTitle);
// 获取文档的得分
System.out.println("得分:" + scoreDoc.score);
}
}
4.2 排序
// 排序
@Test
public void testSortQuery() throws Exception {
// 目录对象
Directory directory = FSDirectory.open(new File("indexDir"));
// 创建读取工具
IndexReader reader = DirectoryReader.open(directory);
// 创建搜索工具
IndexSearcher searcher = new IndexSearcher(reader);
QueryParser parser = new QueryParser("title", new IKAnalyzer());
Query query = parser.parse("谷歌地图");
// 创建排序对象,需要排序字段SortField,参数:字段的名称、字段的类型、是否反转如果是false,升序。true降序
Sort sort = new Sort(new SortField("id", SortField.Type.LONG, true));
// 搜索
TopDocs topDocs = searcher.search(query, 10,sort);
System.out.println("本次搜索共" + topDocs.totalHits + "条数据");
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
// 获取文档编号
int docID = scoreDoc.doc;
Document doc = reader.document(docID);
System.out.println("id: " + doc.get("id"));
System.out.println("title: " + doc.get("title"));
}
}
4.3 分页
// 分页
@Test
public void testPageQuery() throws Exception {
// 实际上Lucene本身不支持分页。因此我们需要自己进行逻辑分页。我们要准备分页参数:
int pageSize = 2;// 每页条数
int pageNum = 3;// 当前页码
int start = (pageNum - 1) * pageSize;// 当前页的起始条数
int end = start + pageSize;// 当前页的结束条数(不能包含)
// 目录对象
Directory directory = FSDirectory.open(new File("indexDir"));
// 创建读取工具
IndexReader reader = DirectoryReader.open(directory);
// 创建搜索工具
IndexSearcher searcher = new IndexSearcher(reader);
QueryParser parser = new QueryParser("title", new IKAnalyzer());
Query query = parser.parse("谷歌地图");
// 创建排序对象,需要排序字段SortField,参数:字段的名称、字段的类型、是否反转如果是false,升序。true降序
Sort sort = new Sort(new SortField("id", Type.LONG, false));
// 搜索数据,查询0~end条
TopDocs topDocs = searcher.search(query, end,sort);
System.out.println("本次搜索共" + topDocs.totalHits + "条数据");
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (int i = start; i < end; i++) {
ScoreDoc scoreDoc = scoreDocs[i];
// 获取文档编号
int docID = scoreDoc.doc;
Document doc = reader.document(docID);
System.out.println("id: " + doc.get("id"));
System.out.println("title: " + doc.get("title"));
}
}
4.4 得分算法
Lucene会对搜索结果打分,用来表示文档数据与词条关联性的强弱,得分越高,表示查询的匹配度就越高,排名就越靠前!其算法公式是:

