JVM探究
目录
前言:
内存区域划分
类加载
双亲委派模型
垃圾回收机制GC
GC的STW问题
GC实际工作过程
判定垃圾
如何清理垃圾
小结:
前言:
Java作为跨平台语言,正是由于JVM的存在使得Java程序可以一次编译,处处运行。不同的环境只要安装了虚拟机(Java Virtual Machine,简称 JVM)就可以运行Java程序。
内存区域划分
JVM在启动的时候会向操作系统申请一大块内存,JVM就会对这块内存区域进行划分。
1)本地方法栈
Native就表示JVM内部的c++代码,给调用Native方法(JVM内部方法)准备的栈空间。
2)虚拟机栈
给Java代码准备的栈空间。存储的是方法之间的调用关系。整个栈空间内部,可以认为包含很多元素,每个元素称为一个“栈帧”。这一个栈帧里,会包含这个方法的入口地址,方法的参数都是什么,返回地址是啥,局部变量等等一些关于函数调用的参数。
栈上的空间是跟着方法走的。调用一个方法就会创建栈帧,方法执行结束了栈帧也就销毁了。(栈的空间是连续使用的)。即栈的空间使用是忽上忽下的,根据方法的生命周期决定这个方法的栈帧是否销毁(还给操作系统)。
线程是独立的执行流,每个线程都有自己栈空间。如果有多个线程就会有多个栈,每一个栈都对应这一个方法。
3)堆区
JVM中最大的区域。实例出来的对象都在堆区,那么对应的类成员变量也就在堆区。
一个JVM分配的内存区域属于一个Java进程。有两个Java进程就有两个JVM内存区域。JVM的生命周期起点是当一个java应用main函数启动时虚拟机也同时被启动,而只有当在虚拟机实例中的所有前台线程结束,java虚拟机实例才结束生命。
堆是一个进程有一份,一个进程中的线程共享一块堆内存。
4)元数据区(方法区)
类对象,常量池,静态成员变量。元数据区是一个进程有一份,一个进程中的线程共享一块元数据区内存。
5)程序计数器
记录当前线程执行到哪个指令。很小的一块内存存一个地址,每个线程有一份。
注意:
局部变量在栈上,普通类成员变量在堆上,静态成员变量在方法区。
类加载
类加载就是把.java文件使用javac编译为.class文件,从文件(硬盘)被加载到内存中(元数据区)。类最终加载完成是要得到类对象的。
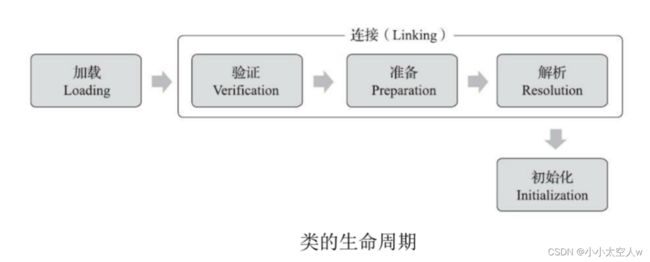
1)加载
把编译好的.class文件找到。打开文件,读文件,把文件内容读到内存中。(元数据区)
2)验证
检验.class文件格式对不对。.class文件是二进制文件,这里的格式有严格说明的,哪几个字节表示什么,java官方文档都有明确规定。
下图是官方文档给出的class文件中每个字节表示的含义,其中u4就代表4个字节。class文件采用的的是类似于结构体的方式来存储数据。

3)准备
给类对象分配内存空间(先在元数据区占个位置),也会使静态成员变量设成0值(内存初始化为全0)。
4)解析
初始化字符串常量,把符号引用转为直接引用。
字符串常量得有一块内存空间,存这个字符串的实际内容,还得有一个引用保存这个内存空间的起始地址。
在类加载之前,字符串常量存在于.class文件中。此时这个引用记录的并非真正的地址,而是文件中的偏移量指向这个字符串。(符号引用)
类加载之后,才会真正将这个字符串常量加载到内存中,这个人时候引用才真正指向内存中的地址。(直接引用)
5)初始化
调用构造方法(真正进行类对象里面的内容进行初始化),进行成员初始化,执行代码块,静态代码块,加载父类...
提出问题:一个类啥时候会被加载呢?
不是java程序一运行就把所有类都加载了,而是真正用到哪个类才加载哪个类。一旦加载过后后续使用就不必加载了。
- 构造类的实例
- 调用这个类的静态方法/静态实例
- 加载子类首先会加载父类
双亲委派模型
双亲委派模型就描述了找.class文件的过程。下面的类存在“父子关系”,但不是父类和子类的继承关系,单纯的就是指向的是自己的父类或者子类。

相互配合流程
BootstrapClassLoader负责加载标准库中的类;ExtensionClassLoader负责加载JVM扩展库中的类;ApplicationClassLoader负责加载用户提供的第三方库/用户项目中的类;CustomClassLoader用户自定义的类加载器。
首先类加载是从ApplicationClassLoader加载器开始的。但是它会把加载任务交给自己的父亲,当ExtensionClassLoader要执行加载任务时,也会把加载任务交给自己的父亲。当BootstrapClassLoader执行加载任务时,也会寻找自己的父亲,但是它没有父亲/父亲加载完了,没找到类,才自己加载。
此时BootstrapClassLoader就会执行加载任务,如果找到就加载,如果没找到就由子类执行加载任务。ExtensionClassLoader执行加载任务,如果找到就加载,如果没找到就让子类执行加载任务。ApplicationClassLoader执行加载任务,如果找到就加载,如果没找到就会抛类找不到异常(没有子类了)。
注意:
上述加载过程会由顶层先加载,然后子类加载器才执行加载任务(JVM中源码类加载器的配合是按照递归的方式写的)。
如果用户写了一些和标准库中一样的类,这样的类加载机制首先会加载标准库中的类,就不会加载到用户自己创建的类,就保证了JVM代码不会出现混乱。
用户也也可以自定义类加载器,加入到上述的加载流程,和现有的类加载器配合使用。
用户自定义的类加载器可以遵守上述流程,也可以不遵守。那么就可以破坏双亲委派模型。
垃圾回收机制GC
在堆区开辟的内存需要释放,当一块内存不在使用的时候,就可以被释放了(还给操作系统),这个时候这块内存就是垃圾。(GC主要争对堆区内存进行释放)。
GC是以 “对象” 为单位进行释放的 ,只有当整个对象都不使用的时候,才可以使用GC进行释放。
GC的STW问题
STW:stop the world。如果有时候,内存中的垃圾已经很多了,这个时候触发一次GC就会消耗大量系统资源,其他程序可能就无法正常执行了。GC可能会涉及一些锁操作,就可能导致业务代码无法正常执行。极端情况下可会卡顿几十毫秒甚至上百毫秒。
当JVM触发GC时,首先会让所有的用户线程到达安全点SafePoint时阻塞,也就是STW。然后枚举根节点,即找到所有的GC Roots,然后就可以从这些GC Roots向下搜寻,可达的对象就保留,不可达的对象就回收。
GC实际工作过程
判定垃圾
判定哪个对象以后不会在使用了。主要思路就是判断:是否还有 “引用” 指向这个对象。Java中使用对象只有 “引用” 这么一个办法。
一、引用计数(不是Java的做法,python/php)
给每个对象分配了一个计数器(整数),每次这个对象创建引用这个计数器就 + 1,销毁一个引用这个计数器就 - 1。那么就可以判断这个计数器是否为0,来确定这个对象是否还使用。

注意:
上述这段伪代码,当new出Test对象时有一个引用t指向了这个对象,那么计数器就 + 1。当t2等于t时,t2也指向了这个对象,那么t3也就指向这个对象,即这个对象的计数器就是3了。
当出这个大括号。这三个局部变量也就出作用域了,此时的Test对象的引用就是0了,就可以认为是垃圾。
缺点:
1)内存空间利用率低
需要给每个对象分配一个计数器,如果按照4个字节存储。当这个对象内存空间占用比较小的时候,这4个字节相对于就比较大了。
2)存在循环引用的问题

如果a和b引用销毁,这个时候一号对象和二号对象的引用计数是1。但实际上这个两个对象已经获取不到了,那么对象就无法及时得到释放(引用计数不为0)。
python/php使用引用计数,需要搭配一些其他机制来避免循环引用。
二、可达性分析
整个Java中的对象会使用 链式/树形 结构把所有对象串起来。(一个对象的属性又指向另一个对象)
可达性分析,就是把所有这些对象被组织的结构视为是树。就从树根节点出发,遍历树,所有能被访问到的对象,标记成 ”可达“(不能访问到的对象就是不可达)。不可达就是垃圾,就可以进行回收了。
这是一颗树,如果一个节点不可达,那么可能就有一串对象都不可达。
可达性分析不需要一直执行,只需要隔一段时间执行一次寻找不可达对象,确定垃圾就可以了。
可达性分析的起点称为:GCroots(就是一个Java对象)。一个代码中有很多这样的起点,把每个起点都遍历一遍就完成了一次扫描。
提出问题:什么样的对象可以做为GCroots呢?(很难被回收的对象)
1、方法区静态属性引用的对象
全局对象的一种,Class对象本身很难被回收,回收的条件非常苛刻,只要Class对象不被回收,静态成员就不能被回收。
2、方法区常量池引用的对象
也属于全局对象,例如字符串常量池,常量本身初始化后不会再改变,因此作为GC Roots也是合理的。
3、方法栈中栈帧本地变量表引用的对象
属于执行上下文中的对象,线程在执行方法时,会将方法打包成一个栈帧入栈执行,方法里用到的局部变量会存放到栈帧的本地变量表中。只要方法还在运行,还没出栈,就意味这本地变量表的对象还会被访问,GC就不应该回收,所以这一类对象也可作为GC Roots。
4、JNI本地方法栈中引用的对象
和上一条本质相同,无非是一个是Java方法栈中的变量引用,一个是native方法(C、C++)方法栈中的变量引用。
5、被同步锁持有的对象
被synchronized锁住的对象也是绝对不能回收的,当前有线程持有对象锁呢,GC如果回收了对象,锁不就失效了嘛。
如何清理垃圾
1)标记清除

注意:
经过可达性分析后就可以确定垃圾对象,把所标记的垃圾对象直接进行回收。
缺点:
内存碎片化,被释放的对象是零散的(不连续的)。
2)复制算法

注意:
复制算法解决了内存碎片化问题。把内存分为两半,用一半丢一半。
复制算法就是把不是垃圾的复制到内存中的另一半中,然后回收整个内存空间(1,2复制到右侧,回收左侧空间)。每次触发复制算法,都是向另一侧进行复制,内存中的数据拷贝过去。
缺点:
空间利用率低。
如果垃圾少,有效对象多,那么复制开销就会比较大。
3)标记整理
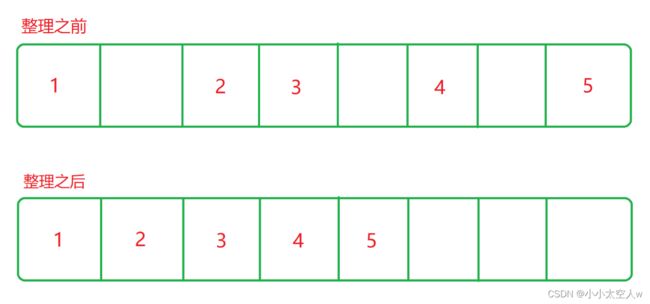
注意:
解决复制算法的缺点,类似于顺序表删除操作,会有元素搬运操作。
保证了空间利用率,同时也解决了内存碎片化问题。
缺点:
如果搬运的数据比较多,系统开销也会比较大。
4)分代回收(Java基于上述做法的结合)
把垃圾回收分为不同场景,不同的场景下使用不同的算法,尽可能的减少每个算法的缺点。
如何进行分代?
基于一个经验规律,如果一个东西存在时间长了,那么接下来大概率也会存在(要没有早就没有了)。
Java中的对象也适用这种规律,根据对象生命周期的长短使用不同的算法。给对象引入一个概念:年龄。(年龄是熬过GC的轮次)。年龄越大这个对象存在的时间就越久。
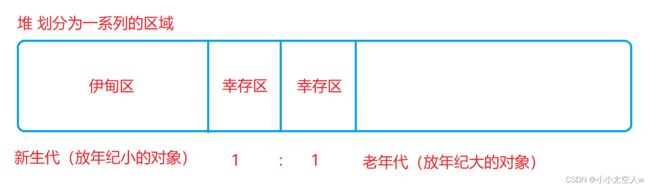
注意:
1)刚new出来的对象,也就是年纪为0的对象放在伊甸区。熬过一轮GC的对象就转移到了幸存区(复制算法)。
2)当对象处在幸存区之后,也需要经历GC的扫描。如果是垃圾就会被释放,如果不是垃圾则拷贝到幸存区的另一半幸存区(两个幸存区只用一个),在两者之间来回拷贝(复制算法)。由于幸存区空间不大,这样也不会浪费太多空间。当在幸存区熬过一定GC轮次之后,年龄也就增长了,此时就会被转移到老年代。
3)老年代都是年纪大的对象,生命周期一般都比较长。针对老年代也会进行GC的扫描,只不过是频率更短了。如果老年代对象是垃圾了使用标记整理的算法进行释放。
小结:
JVM这篇文章只是一小部分知识,需要了解更多关于JVM相关知,那就得查阅更多的相关文档,以及查看JVM源码。