MAE论文笔记+Pytroch实现
Masked Autoencoders Are Scalable Vision Learners, 2021
近期在梳理Transformer在CV领域的相关论文,落脚点在于如何去使用Pytroch实现如ViT和MAE等。通过阅读源码,发现不少论文的源码都直接调用timm来实现ViT。故在此需要简单介绍一下timm这个库中ViT相关部分。此外小破站上的李沐大神讲的贼棒,这里也顺带记录一下相关笔记。
文章目录
- Masked Autoencoders Are Scalable Vision Learners, 2021
-
- 一、timm库
- 二、论文介绍
-
- 1.动机
- 2.方法
- 3.实验
- 三、Pytroch整体代码
一、timm库
可以参考这篇知乎文章视觉 Transformer 优秀开源工作:timm 库 vision transformer 代码解读,写的挺全的。
二、论文介绍
本篇论文提出了一个非对称自编码器架构(这里的非对称指的是Encoder和Decoder看到的东西即输入时不一样的),用来得到一个泛化能力比较强的特征提取器。进行自监督学习可以用来进行迁移学习。自编码器简单的说就是一个模型包含两个部分Encoder和Decoder,其中Encoder用来进行特征提取,Decoder用来进行还原图像。自编码器的任务是输入噪声或有损图片,输出重构好的图片,就是还原图片。通过训练,得到的特征提取器Encoder就有较强的特征提取能力,可以用来进行自监督学习。
什么叫自监督学习呢?简单的说就是构造一个pretext task,用来提高模型的特征提取能力。然后把得到的特征提取器迁移到下游任务。如自编码器的pretext task就是重构图像,如果输入和输出图像的差异越大,并且重构效果较好,往往得到的特征提取器性能也较好。我们可以把学习到的Encoder单独拿出来,后面根据特定的下游任务添加head。常见的使用方式为微调。微调往往能够加快收敛速度,甚至提高模型性能。
好了,介绍了这么多,接下来我们看一下本篇论文的动机+方法。
1.动机
在NLP领域,BERT(完成的任务类似于完形填空)等已经尝试使用masked autoencoding来产生具有较强泛化性能的大参数模型。但是目前CV领域相关工作较少。为了在CV领域使用masked autoencoding,作者从三个角度出发,分析了视觉和语言之间的区别:
- 结构问题,CV领域主要使用CNN,这使得mask token和position embedding难以使用。但目前ViT的出现,弥补了这一差距。
- 语言和视觉的信息密度不同。语言是人类产生的信号,具有高度的语义性和信息密集性。当训练一个模型来预测一个句子中只有几个缺失的单词时,这个任务似乎可以诱导复杂的语言理解。就是“完形填空”是一个比较复杂的任务,可以迫使神经网络学习到好的特征。相反,图像是具有严重空间冗余的自然信号,例如,一个丢失的块可以从对部分、对象和场景的高层理解很少的相邻块中恢复。为了克服这种差异并鼓励学习有用的特征,我们证明了一个简单的策略在计算机视觉中很好地工作:掩蔽很高比例的随机块。该策略在很大程度上减少了冗余,并创建了一个具有挑战性的自我监督任务,需要超越低级图像统计的整体理解。
- 自动编码器的解码器将潜在的表示映射回输入,在重建文本和图像之间发挥着不同的作用。在视觉中,解码器重建像素,因此其输出的语义级别低于常见的识别任务。这与语言相反,解码器预测包含丰富语义信息的缺失单词。而在BERT中,解码器可以是一个MLP ,我们发现对于图像,解码器的设计在决定学习到的潜在表示的语义水平方面起着关键作用。
基于上述三个发现,作者提出了本文的模型(细节方面作者通过大量的实验获得)。
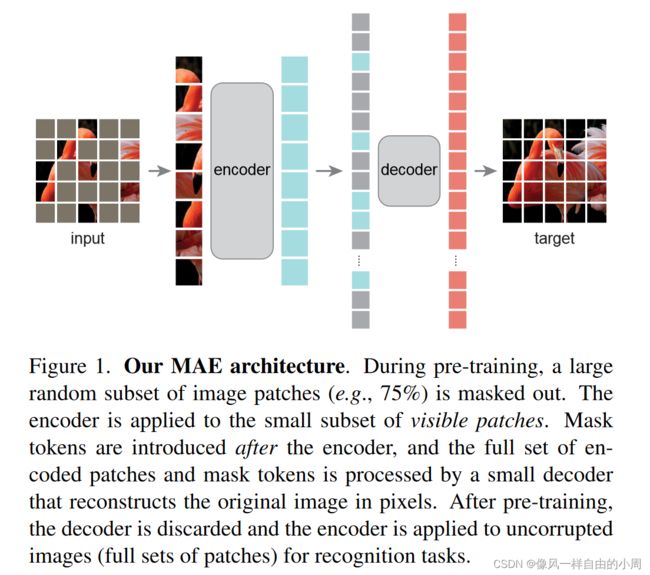
2.方法
框架如上图所示,下面具体来说一下细节。
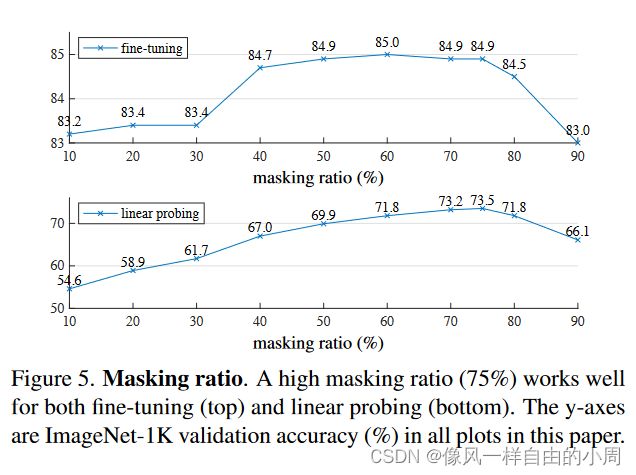
- Masking: 我个人觉得Masking的主要目的是为了让模型能够学习到更强的特征,故输入的图像要和原图像相差很大,而且上面作者说了图像具有冗余性,故遮盖比例应该挺大的,如果遮盖比例比较小的话可能不需要进行训练直接插值就可能出来,且可能按规律裁剪效果不行。作者做了一些消融实验。这里的实验中的ft表示微调,lin表示linear probing即只调整线性层(类似于冻结网络)。


pytroch代码如下:
def random_masking(self, x, mask_ratio):
"""
Perform per-sample random masking by per-sample shuffling.
Per-sample shuffling is done by argsort random noise.
x: [N, L, D], sequence
这里的x不是原始图像块,而是通过线性映射后的x,即embedding结果。batchsize=N,维度=D
"""
N, L, D = x.shape # batch, length, dim
len_keep = int(L * (1 - mask_ratio))
noise = torch.rand(N, L, device=x.device) # noise in [0, 1]
# sort noise for each sample
ids_shuffle = torch.argsort(noise, dim=1) # ascend: small is keep, large is remove
ids_restore = torch.argsort(ids_shuffle, dim=1) # 可以根据这个还原出排序过后的序列
# keep the first subset
ids_keep = ids_shuffle[:, :len_keep]
x_masked = torch.gather(x, dim=1, index=ids_keep.unsqueeze(-1).repeat(1, 1, D)) # 这个函数是按照索引取值
# generate the binary mask: 0 is keep, 1 is remove
mask = torch.ones([N, L], device=x.device)
mask[:, :len_keep] = 0
# unshuffle to get the binary mask
mask = torch.gather(mask, dim=1, index=ids_restore)
return x_masked, mask, ids_restore
- MAE encoder: 这里的Encoder输入仅包含没有被mask掉的patch(这里作者也做了消融实验,发现只输入没有被mask掉的patch块较好)。如果训练好了,拿来做迁移学习,这个时候就没有mask操作了,输入的就是整张图片的patch块。网络结构采用的是ViT。对图像的输入处理和ViT类似,将图像块通过线性投影加位置编码输入到Encoder中。
代码如下,这里因为使用的是ViT,故需要添加class token:
from timm.models.vision_transformer import PatchEmbed, Block
from util.pos_embed import get_2d_sincos_pos_embed
def __init__(self, img_size=224, patch_size=16, in_chans=3,
embed_dim=1024, depth=24, num_heads=16,
decoder_embed_dim=512, decoder_depth=8, decoder_num_heads=16,
mlp_ratio=4., norm_layer=nn.LayerNorm, norm_pix_loss=False):
super().__init__()
# --------------------------------------------------------------------------
# MAE encoder specifics
self.patch_embed = PatchEmbed(img_size, patch_size, in_chans, embed_dim)
num_patches = self.patch_embed.num_patches
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim), requires_grad=False) # fixed sin-cos embedding,这是不可学习参数,下面还有一个赋值函数,太长了,没有列,最后会给一个总的代码。
self.blocks = nn.ModuleList([
Block(embed_dim, num_heads, mlp_ratio, qkv_bias=True, qk_scale=None, norm_layer=norm_layer)
for i in range(depth)]) # Transformer block
self.norm = norm_layer(embed_dim)
# --------------------------------------------------------------------------
def forward_encoder(self, x, mask_ratio):
# embed patches
x = self.patch_embed(x)
# add pos embed w/o cls token
x = x + self.pos_embed[:, 1:, :]
# masking: length -> length * mask_ratio
x, mask, ids_restore = self.random_masking(x, mask_ratio)
# append cls token
cls_token = self.cls_token + self.pos_embed[:, :1, :]
cls_tokens = cls_token.expand(x.shape[0], -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
# apply Transformer blocks
for blk in self.blocks:
x = blk(x)
x = self.norm(x)
return x, mask, ids_restore
- MAE decoder: Decoder的输入包含Encoder的输出特征,以及之前的mask tokens,这里的mask tokens是共享可学习的参数。作者在这里给所有的输入添加了位置编码(positional embedding),结构依旧使用的是Transformer block。
self.decoder_embed = nn.Linear(embed_dim, decoder_embed_dim, bias=True)
self.mask_token = nn.Parameter(torch.zeros(1, 1, decoder_embed_dim))
self.decoder_pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, decoder_embed_dim), requires_grad=False) # fixed sin-cos embedding
self.decoder_blocks = nn.ModuleList([
Block(decoder_embed_dim, decoder_num_heads, mlp_ratio, qkv_bias=True, qk_scale=None, norm_layer=norm_layer)
for i in range(decoder_depth)])
self.decoder_norm = norm_layer(decoder_embed_dim)
self.decoder_pred = nn.Linear(decoder_embed_dim, patch_size**2 * in_chans, bias=True) # decoder to patch
def forward_decoder(self, x, ids_restore):
# embed tokens
x = self.decoder_embed(x) # 添加了一个线性层用来进行过渡
# append mask tokens to sequence
mask_tokens = self.mask_token.repeat(x.shape[0], ids_restore.shape[1] + 1 - x.shape[1], 1)
x_ = torch.cat([x[:, 1:, :], mask_tokens], dim=1) # no cls token
x_ = torch.gather(x_, dim=1, index=ids_restore.unsqueeze(-1).repeat(1, 1, x.shape[2])) # unshuffle
x = torch.cat([x[:, :1, :], x_], dim=1) # append cls token
# add pos embed
x = x + self.decoder_pos_embed
# apply Transformer blocks
for blk in self.decoder_blocks:
x = blk(x)
x = self.decoder_norm(x)
# predictor projection
x = self.decoder_pred(x)
# remove cls token
x = x[:, 1:, :]
return x
- Reconstruction target: 为了重构出像素,解码器Decoder的最后一层是一个线性层。如果输入patch大小是16×16,那么线形层输出就是256维向量,通过reshape就可以还原了。损失函数使用的是MSE,这里的MSE只在mask掉的patch上做。
3.实验
作者先在ImageNet-1K上做自监督预训练,然后再在ImageNet-1K上做监督训练,监督训练方式有微调和linear probing(只允许改最后一层的线性输出层,类似冻结网络参数)。
这里ViT一开始未作改动是需要大规模数据去进行训练的,但后来有人发现添加强正则化会可以使得在相对较小的数据集上也可以训练出来。

- 消融实验: 这里我比较感兴趣的就是数据增强这一部分,作者解释MAE对数据增强方法不是很敏感,但常见的对比学习方法却比较依赖于数据增强。


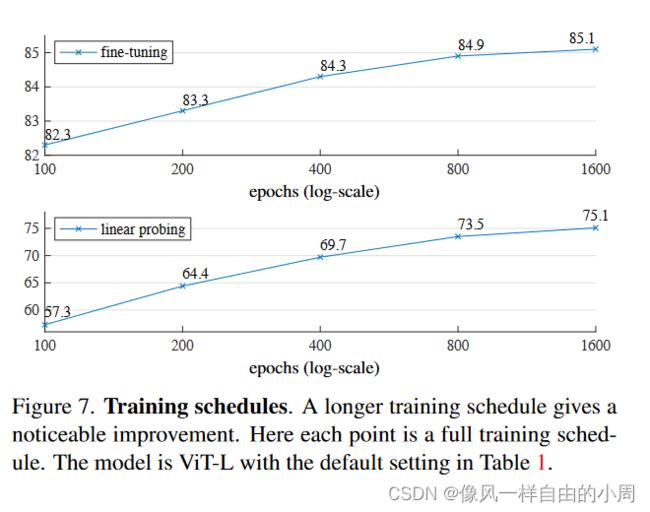
上图的实验表示的是预训练的epoch数量对于结果的影响,可以看到当epochs=1600时效果还能不断提升。
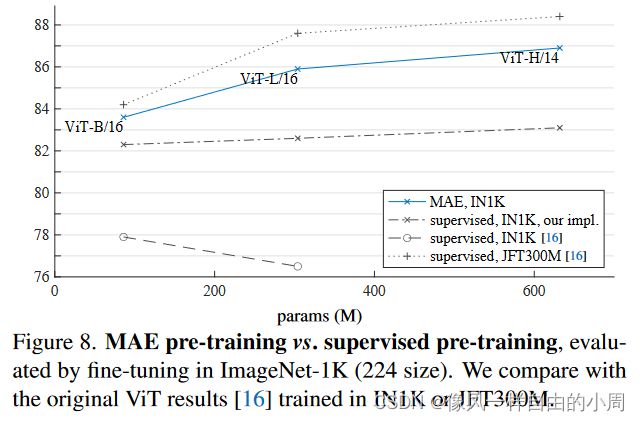
- 对比实验
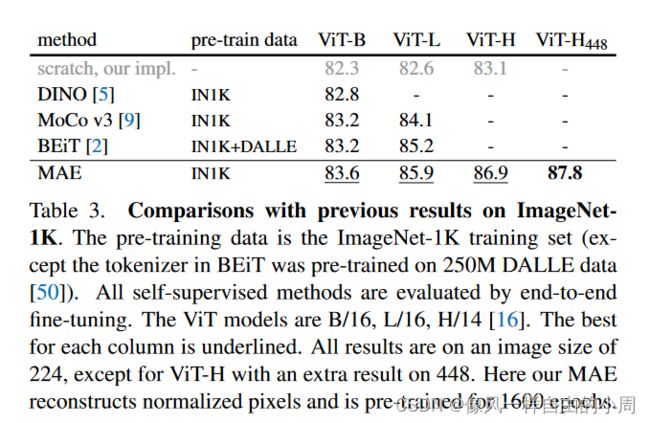
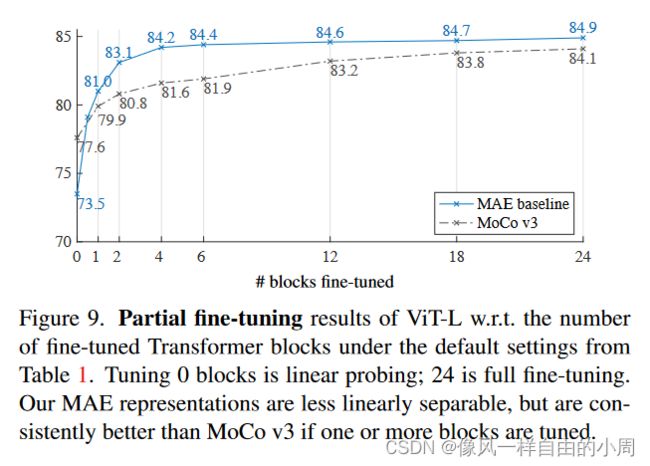
- 部分微调
这里作者想要知道到底微调多少层比较好。
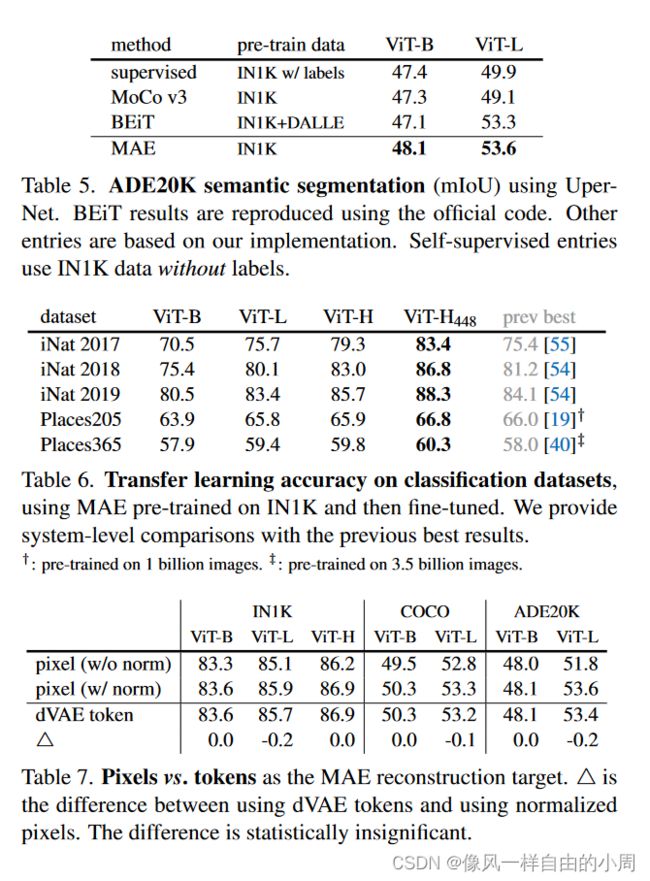
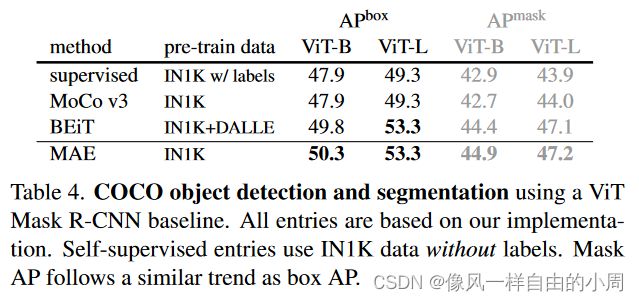
- 不同的下游任务性能
三、Pytroch整体代码
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
# --------------------------------------------------------
# References:
# timm: https://github.com/rwightman/pytorch-image-models/tree/master/timm
# DeiT: https://github.com/facebookresearch/deit
# --------------------------------------------------------
from functools import partial
import torch
import torch.nn as nn
from timm.models.vision_transformer import PatchEmbed, Block
from util.pos_embed import get_2d_sincos_pos_embed
class MaskedAutoencoderViT(nn.Module):
""" Masked Autoencoder with VisionTransformer backbone
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3,
embed_dim=1024, depth=24, num_heads=16,
decoder_embed_dim=512, decoder_depth=8, decoder_num_heads=16,
mlp_ratio=4., norm_layer=nn.LayerNorm, norm_pix_loss=False):
super().__init__()
# --------------------------------------------------------------------------
# MAE encoder specifics
self.patch_embed = PatchEmbed(img_size, patch_size, in_chans, embed_dim)
num_patches = self.patch_embed.num_patches
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim), requires_grad=False) # fixed sin-cos embedding
self.blocks = nn.ModuleList([
Block(embed_dim, num_heads, mlp_ratio, qkv_bias=True, qk_scale=None, norm_layer=norm_layer)
for i in range(depth)])
self.norm = norm_layer(embed_dim)
# --------------------------------------------------------------------------
# --------------------------------------------------------------------------
# MAE decoder specifics
self.decoder_embed = nn.Linear(embed_dim, decoder_embed_dim, bias=True)
self.mask_token = nn.Parameter(torch.zeros(1, 1, decoder_embed_dim))
self.decoder_pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, decoder_embed_dim), requires_grad=False) # fixed sin-cos embedding
self.decoder_blocks = nn.ModuleList([
Block(decoder_embed_dim, decoder_num_heads, mlp_ratio, qkv_bias=True, qk_scale=None, norm_layer=norm_layer)
for i in range(decoder_depth)])
self.decoder_norm = norm_layer(decoder_embed_dim)
self.decoder_pred = nn.Linear(decoder_embed_dim, patch_size**2 * in_chans, bias=True) # decoder to patch
# --------------------------------------------------------------------------
self.norm_pix_loss = norm_pix_loss
self.initialize_weights()
def initialize_weights(self):
# initialization
# initialize (and freeze) pos_embed by sin-cos embedding
pos_embed = get_2d_sincos_pos_embed(self.pos_embed.shape[-1], int(self.patch_embed.num_patches**.5), cls_token=True)
self.pos_embed.data.copy_(torch.from_numpy(pos_embed).float().unsqueeze(0))
decoder_pos_embed = get_2d_sincos_pos_embed(self.decoder_pos_embed.shape[-1], int(self.patch_embed.num_patches**.5), cls_token=True)
self.decoder_pos_embed.data.copy_(torch.from_numpy(decoder_pos_embed).float().unsqueeze(0))
# initialize patch_embed like nn.Linear (instead of nn.Conv2d)
w = self.patch_embed.proj.weight.data
torch.nn.init.xavier_uniform_(w.view([w.shape[0], -1]))
# timm's trunc_normal_(std=.02) is effectively normal_(std=0.02) as cutoff is too big (2.)
torch.nn.init.normal_(self.cls_token, std=.02)
torch.nn.init.normal_(self.mask_token, std=.02)
# initialize nn.Linear and nn.LayerNorm
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
# we use xavier_uniform following official JAX ViT:
torch.nn.init.xavier_uniform_(m.weight)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def patchify(self, imgs):
"""
imgs: (N, 3, H, W)
x: (N, L, patch_size**2 *3)
"""
p = self.patch_embed.patch_size[0]
assert imgs.shape[2] == imgs.shape[3] and imgs.shape[2] % p == 0
h = w = imgs.shape[2] // p
x = imgs.reshape(shape=(imgs.shape[0], 3, h, p, w, p))
x = torch.einsum('nchpwq->nhwpqc', x)
x = x.reshape(shape=(imgs.shape[0], h * w, p**2 * 3))
return x
def unpatchify(self, x):
"""
x: (N, L, patch_size**2 *3)
imgs: (N, 3, H, W)
"""
p = self.patch_embed.patch_size[0]
h = w = int(x.shape[1]**.5)
assert h * w == x.shape[1]
x = x.reshape(shape=(x.shape[0], h, w, p, p, 3))
x = torch.einsum('nhwpqc->nchpwq', x)
imgs = x.reshape(shape=(x.shape[0], 3, h * p, h * p))
return imgs
def random_masking(self, x, mask_ratio):
"""
Perform per-sample random masking by per-sample shuffling.
Per-sample shuffling is done by argsort random noise.
x: [N, L, D], sequence
"""
N, L, D = x.shape # batch, length, dim
len_keep = int(L * (1 - mask_ratio))
noise = torch.rand(N, L, device=x.device) # noise in [0, 1]
# sort noise for each sample
ids_shuffle = torch.argsort(noise, dim=1) # ascend: small is keep, large is remove
ids_restore = torch.argsort(ids_shuffle, dim=1)
# keep the first subset
ids_keep = ids_shuffle[:, :len_keep]
x_masked = torch.gather(x, dim=1, index=ids_keep.unsqueeze(-1).repeat(1, 1, D))
# generate the binary mask: 0 is keep, 1 is remove
mask = torch.ones([N, L], device=x.device)
mask[:, :len_keep] = 0
# unshuffle to get the binary mask
mask = torch.gather(mask, dim=1, index=ids_restore)
return x_masked, mask, ids_restore
def forward_encoder(self, x, mask_ratio):
# embed patches
x = self.patch_embed(x)
# add pos embed w/o cls token
x = x + self.pos_embed[:, 1:, :]
# masking: length -> length * mask_ratio
x, mask, ids_restore = self.random_masking(x, mask_ratio)
# append cls token
cls_token = self.cls_token + self.pos_embed[:, :1, :]
cls_tokens = cls_token.expand(x.shape[0], -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
# apply Transformer blocks
for blk in self.blocks:
x = blk(x)
x = self.norm(x)
return x, mask, ids_restore
def forward_decoder(self, x, ids_restore):
# embed tokens
x = self.decoder_embed(x)
# append mask tokens to sequence
mask_tokens = self.mask_token.repeat(x.shape[0], ids_restore.shape[1] + 1 - x.shape[1], 1)
x_ = torch.cat([x[:, 1:, :], mask_tokens], dim=1) # no cls token
x_ = torch.gather(x_, dim=1, index=ids_restore.unsqueeze(-1).repeat(1, 1, x.shape[2])) # unshuffle
x = torch.cat([x[:, :1, :], x_], dim=1) # append cls token
# add pos embed
x = x + self.decoder_pos_embed
# apply Transformer blocks
for blk in self.decoder_blocks:
x = blk(x)
x = self.decoder_norm(x)
# predictor projection
x = self.decoder_pred(x)
# remove cls token
x = x[:, 1:, :]
return x
def forward_loss(self, imgs, pred, mask):
"""
imgs: [N, 3, H, W]
pred: [N, L, p*p*3]
mask: [N, L], 0 is keep, 1 is remove,
"""
target = self.patchify(imgs)
if self.norm_pix_loss:
mean = target.mean(dim=-1, keepdim=True)
var = target.var(dim=-1, keepdim=True)
target = (target - mean) / (var + 1.e-6)**.5
loss = (pred - target) ** 2
loss = loss.mean(dim=-1) # [N, L], mean loss per patch
loss = (loss * mask).sum() / mask.sum() # mean loss on removed patches
return loss
def forward(self, imgs, mask_ratio=0.75):
latent, mask, ids_restore = self.forward_encoder(imgs, mask_ratio)
pred = self.forward_decoder(latent, ids_restore) # [N, L, p*p*3]
loss = self.forward_loss(imgs, pred, mask)
return loss, pred, mask
def mae_vit_base_patch16_dec512d8b(**kwargs):
model = MaskedAutoencoderViT(
patch_size=16, embed_dim=768, depth=12, num_heads=12,
decoder_embed_dim=512, decoder_depth=8, decoder_num_heads=16,
mlp_ratio=4, norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
return model
def mae_vit_large_patch16_dec512d8b(**kwargs):
model = MaskedAutoencoderViT(
patch_size=16, embed_dim=1024, depth=24, num_heads=16,
decoder_embed_dim=512, decoder_depth=8, decoder_num_heads=16,
mlp_ratio=4, norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
return model
def mae_vit_huge_patch14_dec512d8b(**kwargs):
model = MaskedAutoencoderViT(
patch_size=14, embed_dim=1280, depth=32, num_heads=16,
decoder_embed_dim=512, decoder_depth=8, decoder_num_heads=16,
mlp_ratio=4, norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
return model
# set recommended archs
mae_vit_base_patch16 = mae_vit_base_patch16_dec512d8b # decoder: 512 dim, 8 blocks
mae_vit_large_patch16 = mae_vit_large_patch16_dec512d8b # decoder: 512 dim, 8 blocks
mae_vit_huge_patch14 = mae_vit_huge_patch14_dec512d8b # decoder: 512 dim, 8 blocks