[目标识别-论文笔记]Object Detection in Videos by Short and Long Range Object Linking
文章标题:2018_Cite=13_Tang——Object Detection in Videos by Short and Long Range Object Linking
这篇论文也被叫做“2019_Cite=91_TPAMI_Tang——Object Detection in Videos by High Quality Object Linking”
如果这篇博客对你有帮助,希望你 点赞、收藏、关注、评论,您的认可将是我创作下去最大的动力。也欢迎您将这篇文章转发给您的朋友,也许他也对对目标识别领域感兴趣呢?
术语Term解释
proposal
候选区域
tubelet
指目标移动的大致路径,目标在移动过程中,这些时刻的box的位置的集合
![[目标识别-论文笔记]Object Detection in Videos by Short and Long Range Object Linking_第1张图片](http://img.e-com-net.com/image/info8/aaf95de99c6c41c784326d2dfff88942.jpg)
non-maximum suppression
什么是NMS?
有什么用?用来解决什么问题?——aims to remove overlapping object detection boxes
tracklet
一般翻译为“跟踪小片段”,在做物体跟踪时会用到数据关联(data association),整个连续的跟踪过程其实是由很多tracklet构成的。
region proposal network (RPN)
是一个单独的网络吗?有介绍吗?
Faster R-CNN
我知道是用来做目标识别的,请问它是怎么做的,它这个思路是不是后面有的模型延续继续使用?或者模仿了它的设计思想?。好像region proposal network是Faster R-CNN网络的一部分
ROI (region of interest)
感兴趣区域,与bbox概念类似,定义图像中我们感兴趣的部分,只把这一部分交给模型进行学习。换言之,这块区域以外的部分,就不input给后序的模型。
目标检测主要解决两个问题(1)目标的位置,也就是bbox四个点的位置(2)确定这个方框中object的类别。这里这个Region Of Interest,就是服务于第一个目的。你要确定这个方框四个顶点的位置,你你怎么去找这四个点?如果是一个滑窗在图片上滑动的话,那candidate bbox就太多了,计算量明显太大。那怎么办,你划一片区域,说这篇区域你感兴趣,因此得名 region of interest,只对这个区域input进模型进行识别,大大减少了candidate bbox
![[目标识别-论文笔记]Object Detection in Videos by Short and Long Range Object Linking_第2张图片](http://img.e-com-net.com/image/info8/420b8da8c1c8412caf747e8243c2e12b.jpg)
objectness
顾名思义,这个词的意思是,(这片候选区域 region of interst),存在object的一种可能性(概率的度量)。
这个东西的用处是:允许我们快速地删除不包含任何物体的图像窗口。
如果一幅图像具有较高的Objectness,我们期望它具有:
- 在整个图像中具有唯一性。(如果你这个东西,和其他区域很类似,没有独特性,你这个region of interest不就是千篇一律的background的一部分吗?)
- 物体周围有严格的边界。(一般来说只有object,比如下面绿色框里这个羊,和背景绿草地有明显的边界,颜色和纹理不同,一个白色,一个绿色。如果和方框以外没有明显的边界,说明你的图案和背景很类似,那你大概率也是背景)
-
与周围环境的外观不同。(同上)
![[目标识别-论文笔记]Object Detection in Videos by Short and Long Range Object Linking_第3张图片](http://img.e-com-net.com/image/info8/28e6d9897d504336b2e558397c91b3c6.jpg)
如何度量objectness?
-
多尺度显著性:这本质上是对图像窗口的外观独特性的度量。与整个图像相比,框中唯一性像素的密度越高,该值就越高。
-
颜色对比度:框内像素与建议图像窗口与周围区域的颜色对比度越大,该值越大。
-
边缘密度:我们定义边缘为物体的边界,这个值是图像窗口边界附近的边缘的度量值。一个有趣的算法可以找到这些边缘:https://cv-tricks.com/opencv-dnn/edge-detection-hed/。
-
超像素跨越:我们定义超像素是几乎相同颜色的像素团。如果该值很高,则框内的所有超像素只包含在其边界内。
RoI = Region of Interest
CoI = Cuboids of Interest
RoI Pooling
ROI Pooling 的过程就是将一个个大小不同的 box 矩形框,都映射成大小为 w ∗ h的矩形框
详细的要看这篇文章深度学习之 ROI Pooling_奔跑的大西吉的博客-CSDN博客。有时间,看完总结完。
response map:
对原始图像,进行一种操作后所形成的输出图像,可以称之为这种操作的响应图。
解决什么问题?:
你已经识别出来这个是一个object,已经打了方框了,但是你不知道这个object的类别。也就是说你此时应该做分类,并提供你这个分类结果的置信度。
但是这种分类,有时候是会分错的。比如(a)这一列,第三和第四张图都是把松鼠错分类成了猴子。(b)和(c)用了一些技术,最后分类就不出现错误了。本文提出的这个算法就是致力于纠正这种分类错误的。
但是我的毕业论文这个,并不是分类错误哦,是直接就识别不出来走过来的人。但虽然不满足我的需求,但是把这种方法加进YOLOv8里面,说不动会启发设计出独特的结构,说不定这样一改就涨点呢?,或者不掉点,那也是可以拿来作为创新点的。——提高分类的置信度,也是一种创新。
如果识别人和非人,这个意义不大。如果人里面分很多个类别,就有意义看。
![[目标识别-论文笔记]Object Detection in Videos by Short and Long Range Object Linking_第4张图片](http://img.e-com-net.com/image/info8/3c579c9288e542508a7c5c8600e49533.jpg)
本文背景
视频目标追踪因为视频的下列特点所以效果不太理想
(1)motion blurs and
(2)图片质量差degraded image qualities
这两个因素会导致分视频中同一个object的分类类表现的不稳定(比如这几帧,这个object被分类成了人,那几帧就分类成了猴子)esult in unstable classification for the same object across video.
为了解决上面这个问题,学术界过去有人这样做过
- 下面这些做法主要是为了捕捉时间情景信息Various attempts have been made to explore
- temporal contexts
- 光流法为基础的特征信息传播optical-flow based feature propagation [38] and
- 聚合aggregation [37],
- 借助tubelets来实现跨帧的目标关联object association across frames by tubelets [16, 17, 18], and
- 通过追踪的方法来完成识别track to detect [4].
注意,本文提出的这个算法也是和上面这些方法一个思路,就是去捕捉时间情景信息to explore temporal contexts
算法
模型的名字:时间-空间 立方体 推荐区域 网络spatio-temporal cuboid proposal network
(1) link objects in the short ranges and long ranges 。object association across frame不同帧之间object的联系(2)aggregating the classification scores from the linked objects 。跨帧去关联目标exploit objects association across frames in the video
一共four stages, 三个关于three about short range object linking and ,一个关于one about long range object linking
(Step 1)cubic proposal for short segment
如何拿到short range linking呢?
建立时空立方体候选区域spatio-temporal cuboid proposals。针对短的视频片段short video segment.生成一系列的候选的spatio-temporal cuboids时空立方体。前面说的那种link如何体现呢?这种link体现在,在这个立方体里面,跨不同帧的object被看做同一个objectThe objects across frames lying in a cuboid are regarded as the same object.So the objects in a video
segment are naturally linked by the cuboid.
这一步的意义在于提出一系列的立方体,这些立方体可以跨过不同帧的图片,把图像上相同的object,全部包裹起来,就像下图的这个红色实线和虚线组成的这个立方体。This step aims to propose a set of cuboids (containers) which bound the sameobject across frames。
下面这张图是如何绘制的,我来介绍一下。你看绿的框在红色框中的相对位置,你可以有下面这些发现。第一张图到第二张图,横向上这个小孩向左边移动了一点点。第二到第三张图,这个小孩除了向左移动到红色框框的左边界,他向上移动到了上端的边界。——由此我们推断出,,红色的框是在画完绿色框以后,找一个最大的红色框,能够使得三个绿色的框都能囊括在里面的那个红色的框。
红色的这个立方体是“cubic proposal for a short segment”这一步,也就是第一步的要完成的任务The red cuboid, bounding the movement of the object, is the target of the cuboid proposal stage.
绿色的这个立方体,也就是tubelet,是“object tubelet detection for a short segment”这一步,也就是第二步,要完成的任务The tubelet, composed of the green object boxes in the video segment, is the target of the object tubelet objection stage.
![[目标识别-论文笔记]Object Detection in Videos by Short and Long Range Object Linking_第5张图片](http://img.e-com-net.com/image/info8/45771fa5e8ca4c51b5930c4432eba228.jpg)
在一个视频片段中(in a short segment), ground truth的目标(object)立方体(cuboid),是由K帧图像组成的,每张照片用Image的首字母 "I"表示。这些帧照片是从一个一个视频片段中提取出来的,很自然的,每张照片代表了一个时刻,所以在下面这个数学表示右上角显示的是,t时刻到 t+K-1时刻,一共K张照片。
ground truth cuboid of objects是一个集合,这个集合可以用右边这个式子表示 ![]()
tubelet如何表示呢?
什么是tubelet? K帧图片里面所有ground truth的 box方框,就是那些绿色的真实的bounding box。a series of all ground truth boxes in the K frames,
你将上面的I 换成"b上面带个波浪线",表示时间的右上标保留。给这个集合起个名字,就是左边这个“歪歪扭扭的T,上面带个波浪线”来表示tubelets
![]()
这里备注一下 "b上面带个波浪线,右上角带个时间",它具体指的是什么?换句话说你可以从从哪些维度来提供数据,进而成功表示一个bounding box?可以用后面这个公式可以表示 
上面这个括号里面每一个b,都是由四个元素组成的,识别框中心的横坐标和纵坐标,识别框的宽度和高度。这四个元素右上角的那个“怪怪的T”表示这是哪个时刻下,这一帧的识别框的信息。
然后,如何拿到红色最外围的那个bounding box呢?
你自然是将所有的这些每一帧上每一个绿色的这些 box都放在一起,然后取上下左右最靠边的那四条。这个红色的方框叫做 cubic proposal,就是下面这个式子里的“b上面带个波浪线”。如何得到它?就是在上面这个式子外面,加个bounding box,取取到最靠边的那四条了。
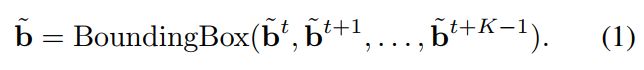
这样就得到了一个红色的框
bounding cuboid怎么得来?
(是K(帧数)个红的框最后形成了这个bounding cuboid?——还是,每一个帧上都有一个绿色的tubelet框,这些绿色的框,最后形成了一个红色的框?
我倾向于前者。形成bounding cuboid的方法是收集K个,"b上面带着一个波浪线"(K个(帧数个)红框)The bounding cuboid in our approach is just a collection of![]()
尽管这K个红框,他们的时间(所在的帧位置)是不一样的,但是为了简便,我们都写成b上带一个波浪线,然后他们组成的这个集合被命名为“c上面一个波浪线”![]()
我们修改了Faster R-CNN网络里面的region proposal network,用cuboid proposl network来替代了RPN计算cuboid proposal。传统的RPN是一张图一张图的输入,我们的给cuboid proposal network是一次性输入进去K帧张图片进去
输进去K帧图片以后,输出是一个立方体,这个立方体里面装的是candidate cubiods of interest,也就是你觉得感兴趣的候选的立方体区域。后面模型只会使用你感兴趣的这些区域来进行后面的识别的运算,你感兴趣以外的立方体区域,一律不会被后面的模型进行识别。
这个CoI(candidate cuboids of interest)被和一个w×h的空间网格做了回归(这是啥操作啊?你能跟我说,具体是怎么做吗?). The output is a set of whk candidate cuboids
of interest (CoI), regressed from a w × h spatial grid
前面那个CoI具备下面两个特点
(1)在每一帧图片的相同的位置,都有k个reference boxes,因为这记录了在这个位置下面k个时间点下画出的k个方框。
(2)每一个CoI(candidate cuboids of interrest)这个数值,都是和objectness score紧密相关的。
补充:
类似于二维平面的candidate region of interest,这里是个立方体,我们就称呼它为candidate cubiods of interest。
这个立方体的维度是w×h×k, w代表bbox的width,h代表bbox的height, k代表我们跨越了多少帧。然后我们去和
(Step 2)Object tubelet detction for short segment
通过上一步分操作,你拿到了红色的那个cuboid proposals。这一步对tubelets做回归和分类,regress and classify,最终拿到绿的的方框实线和虚线
在这个步骤里,我们用了立方体候选区域cuboid proposal 的2D形式(2D form),作为每一帧的(each frame)的2D 方框候选区域的区域推荐。每一帧图片上,每一个2D候选区域,都被做了分类(识别候选区域里面是什么object,是人还是汽车?),通过也做了一些优化refine
——We use the 2D form of the cuboid proposal as the 2D box (region) proposal for each frame in this segment, which is classified and refined for each frame separately.
考虑到在这一部分里有 "帧“![]() 这个东西Considering a frame Iτ in this segment(为啥有帧这个东西,你选择了后面这样做?你究竟考虑到了啥?),我们使用了FastR-CNNl来计算分类的分数and refine the box,对这个识别框进行精细化的调整。
这个东西Considering a frame Iτ in this segment(为啥有帧这个东西,你选择了后面这样做?你究竟考虑到了啥?),我们使用了FastR-CNNl来计算分类的分数and refine the box,对这个识别框进行精细化的调整。
RoI Pooling:我们以一个RoI(Region of Interest)的pooling运算为开始(RoI pooling是什么,我还不懂,有时间看上面那个链接)。这个pooling运算的输入是一个2D的region proposal,b, 然后经过一个CNN运算,得到一个处理过以后的feature map ![]() ,这个也被称作response map响应图。
,这个也被称作response map响应图。
分类:然后上面这个RoI pooling这个运算的结果被喂进了一个分类层,输出一个C+1维的分类分数向量![]() 。这里这个C表示什么,这里解释一下,C表示识别分类的类别数量,多出来的加一是指的把background这一类也算进类别里面。
。这里这个C表示什么,这里解释一下,C表示识别分类的类别数量,多出来的加一是指的把background这一类也算进类别里面。
回归:上面这个RoI pooling运算的结果,同时也会被喂进一个回归层。借助这个回归层,我们可以实现对于box的一个refine。然后做一个回归,回归的自变量和因变量中的一个是,在每一帧图像上方框的精确位置the precise box locations in each frame 。另一个有点复杂,听我细细道来。cuboid proposal(也可以被叫做tubelet是吗?),这个tubelet里面有很多的帧,这个东西里面能被放进这个tubelet的都是被当做同一个object的object。然后把这个tubelet里面,每一帧的分类的分数score。然后通过某种方式的aggregate,得到一个分数。—— It then regresses the precise box locations in each frame over each cuboid proposal, yielding a tubelet with a single classification score which is aggregated from the scores of the boxes
in the tubelet.————we regress the precise box locations and classification scores for each frame separately, forming a tubelet representing the linked object boxes in the short video segment.We obtain the classification score of the tubelet, by aggregating the classification
scores of the boxes across frames.
Refine:导致结果的K(导致什么结果?多少帧?)精细化调整了方框。这种调整是为了K帧,这K帧组成了tubelet(绿色线)在这一步骤的识别结果(整句话不知道啥意思)。The resulting K refined boxes for the K frames form the tubelet detection result over this segment. 这表示它分裂出来的的,在每一帧上的bounding box吧?
![]()
![]()
这些tubelet上,所有帧,分类的分数,通过某种方式聚合得到一个分数。
![]()
聚合aggregate的方式多种多样,可以求mean均值,也可以用下面这个公式做聚合
![]()
(上面这三步具体是做的什么,我真的是不太懂)
前面 aggregating the classification scores的好处是,提高识别正类的分类分数( boosting the classification scores for positive detections),进而提高整体的分类分数 improve the classification quality
(Step 3)Tubelet non-maximum suppression
NMS本来设计出来是为了用来干什么的?移除那些重叠的识别框,使得识别框之间尽量不重叠。the non-maximum suppression (NMS) algorithm aims to remove overlapping object detection boxes。这个方法以scores为基础对于所有的detected boxes进行排序。分数最高的那个识别框会被选中。对于那些分数大于预先定义的阈值的其他识别框,如果他们也有显著的overlap,它们会被抑制suppress(如何抑制?说说你采取什么行动抑制了这个分数)。对于剩余的boxes,整个过程会递归的执行。
最直接的解决方案是去执行一个帧级别的NMS,也就是独立-无关联地,在每一帧,移除重叠的2D识别框。这样会有这样一种倾向,这样做可能导致一整个tubelet被打碎成若,被分成不同类别的目标的,干个小的tubelets。会导致这样的结果的原因是,objects在tubelet里面的,关于相同的object点是没有被充分利用。上面这种倾向,已经被实证实验证明
我们为非极大值抑制算法增加了下面这个功能,we extend the non-maximum suppression algorithm to,那就是在短的视频切片上移除空间上重叠的tubelets(box框的移动轨迹) remove spatially-overlapping tubelets in the short segment, 这样可以避免帧级别的NMS的过程中,tubelet的broken(坏掉)avoiding tubelets broken by the framewise NMS。这个过程里我们引入离开一种评估指标,用于评估tubelets的重叠的多少,with the introduction of an overlap measure for tubelets。这个过程被命名为 tubelet NMS algorithm(T-NMS)
唯一的难点在如何评估两个tublets的overlap。对于overlap的定义是建立在相同帧的图不同识别框的重叠这一概念基础之上建立的。实际就是通过IoU来实现的
![[目标识别-论文笔记]Object Detection in Videos by Short and Long Range Object Linking_第6张图片](http://img.e-com-net.com/image/info8/0412fc6399394bfe9c4fdc1edc618a3f.jpg)
(Step 4)Classification score refinement via temporally-overlapping tubelets
我们对于数据的处理是这样的
将视频拆分成一些短的视频片段,整个视频片段的长度为K,取完这个视频片段,下一步割开K-1长度以后再切,也就是步长为K-1。这样保证连续的两段视频片段之间是有最少1秒的重叠时刻。
![[目标识别-论文笔记]Object Detection in Videos by Short and Long Range Object Linking_第7张图片](http://img.e-com-net.com/image/info8/a9652552117c4dcc800a1e3603257492.jpg)
考虑到两个时间上重叠的(中间重叠的一秒)tubelets,,来自第m个片段的,第i个tubelet是来自于第(m+1)个片段(啥意思?)
如果两个视频片段中间的这个是重叠的,也就是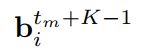
和 ![]() 之间的重叠到达了阈值,重叠的十分显著,我们就把他们link起来。
之间的重叠到达了阈值,重叠的十分显著,我们就把他们link起来。
我们在执行过程中使用的是贪心算法,具体说是a greedy tubelet linking algorithm。一开始,我们把所有短的视频片段的ubelets都放进一个池子里面,并且我们记录每一个tubelet对应的片段。对于那些分类分数最高的tubelet,我们首先把这些pop out出来。对于那些在T时刻重叠的帧,我们去check识别框的IoU。如果IoU大于阈值,比如0.4,我们将会合并这两个tubelets变成一个tubelet。对于重叠的帧,移除那些分数分数比较低的识别框。
用Equation(2)对于那些已经合并的tubelet,更新分类的分数。尤其是那些两段视频片段合并成一个视频的,你要记录下来合并后的对应的视频片段。然后把合并后的tubelet放进池子里。重复做上面这个步骤,知道没有tubelets需要被合并。
留在池子里的这些tubelets形成了视频目标识别的结果。tubelet的分数被分配给tubelet中每一个识别框了。来自所有的tubelets得识别框和某一帧的关联性特别强会被视作最终识别的识别框。对于对于对应帧。
我们如何拿到long range object linking呢?
我们先将整个视频切成一个个小的片段 dividing the whole video sequence into short video segments。对于整个视频中,横跨多个“”时间上有的重叠的"视频片段,如果显著重叠了,那么我就将对应的tubelets关联起来.we link the tubelets with significant overlap across temporally-overlapping short video segments 。这样就形成了long range object link 长距离目标关联?还是长时间段的目标关联。
(我现在怀疑这个long range和short range在这篇文章中,的意思不是远距离,近距离,而是指的,长时间间隔和短时间间隔)
何种情况下,两个tubelets会被关联在一起并且合并成同一个tubelets呢?
(1)两个方框boxes,在空间上足够重叠(2)两个方框boxes来自于在时间上足够重叠的临近的两个tubelets的两帧 (3)两个tubelets要是邻近的
——If two boxes, (2)which are from the temporally-overlapping frame of (3)two neighboring tubelets, (1)have sufficient spatial overlap, the tubelets are linked together and merged.
实验数据集:ImageNet VID dataset
https://image-net.org/challenges/LSVRC/2015/index
它是一种流行的大型视频目标检测基准,有30个类别,都包含在ImageNet DET内。对训练集的3862个视频片段和验证集的555个视频片段进行模型训练和评估。2015年ImageNet大规模视觉识别挑战赛(ILSVRC2015)引入了一项名为“从视频对象检测”(VID)的任务,其中包含一个新的数据集。
别人看了这篇文章以后的解读
https://github.com/ocean1100/Reading/blob/5b1b4846045105fda9b8b9ac6dc276f7b1924ba9/VideoDetection/Object_Detection_in_Videos_by_Short_and_Long_Range_Object_Linking.md)
-
Cuboid proposal for a short segment propose 一个立方体
-
Tubelet detection for a short segment
-
对这个立方体回归、分类,得分是所有bbox得分的聚合
-
聚合方式:$0.5(mean+max)$
-
-
Tubelet non-maximum suppression
-
2D NMS 易导致tubelet中断
-
tubelets 的IOU:先计算对应帧的bbox的IOU,取其中最小的
-
-
Classification refinement through temporally-overlapping tubelets.
-
M个 short segments(包含1K帧,K2K-1帧 ...), 都有Cuboid proposal
-
K帧bbox重叠较大的两个bbox所在的tubelets看做是同一个
-
按照2的方法融合两段tubelets的得分
-
https://htx1998.cn/2021/03/19/3-19/
摘要
此前的方法大都在相邻帧关联目标,本文首次提出在同一帧内关联目标。与其他方法不同,作者在相同帧连接目标,并且跨帧传播box分数,而非传播特征。
本文创新点:
-
提出了一个cuboid proposal network(CPN,立方体 候选框 网络),提取约束物体运动的时空候选长方体。
-
提出了一个短的tubelet(小管子) detection网络,在短视频中监测short tuubelets。
-
提出了一个短的tubelet连接算法,连接有时间重叠的short tubelets来形成长的tubelets。
Related Work
不使用Object Linking进行特征传播
FGFA STSN STMN MANet:当前帧的特征通过聚合来自其他相邻帧的特征进行增强,FGFA和MANet使用光流来对齐不同帧的特征,进而聚合。STSN使用变形卷积网络跨时空传播特征。STMN采用Conv-GRU来从相邻帧传播特征。此外,DFF也利用特征传播来加速目标检测。作者提出用非常深的高代价网络来计算关键帧的特征,从而将其通过shallow计算出的光流传播到非关键帧。以上这些方法都没有使用Object Linking。
使用Object Linking进行特征传播
Tubelet Proposal Network首先生成静态的目标proposals,进而预测之后帧的相对位移。tubelets中box的特征通过使用CNN-LSTM网络传播到每个box用于分类。MANet为当前真的每个proposal预测相邻帧的相对位移,相邻帧box的特征通过平均池化被传播到当前帧对应box。与这些方法不同,作者在相同帧连接目标,并且跨帧传播box分数,而非传播特征。此外,作者的方法直接为视频片段生成时空cuboid proposals,而非像Tubelet Proposal Network和MANet一样生成逐帧proposal。
使用Object Linking进行分数传播
Object detection from video tubelets with convolutional neural networks.(Object Linking) T-CNN:Tubelets with convolutional neural networks for object from videos(Object Linking)
以上两篇文章提出了两种Object Linking方法。第一种跟踪当前帧检测到的box到其相邻帧来用更高的召回率增强其原始的检测结果。分数也被传播来提升分类精度。这种连接是基于box内的平均光流向量。第二种使用跟踪算法连接目标和long tubelet,之后采用分类器来聚合tubelets中的检测分数。
Seq-NMS方法通过选择相邻帧box的空间重叠小来连接目标,不考虑运动信息,之后聚合所连接目标的分数作为最终的分数。Detect to track and track to detect中的方法同时预测两帧的目标位置,以及从前一帧到后一帧的目标位移。之后使用位移来连接检测到的目标和tubelets。相同tubelet的检测分数通过一些方式重新加权。
方法
视频目标检测的任务是:推断出视频每一帧目标的位置和类别。为了得到高质量的目标连接,作者提出在相同的帧连接目标,这可以提升分类精度。
给出被分割成具有时间重叠的视频片段作为输入,作者的方法由3步组成:
-
为一个片段生成立方体proposal。这一步旨在生成一组立方体(容器)来约束不同帧的相同目标。(不懂)
-
为一个小片段执行Short tubelet detection。对于每个立方体proposal,回归和分类产生short tubelet(是边界框的序列,每个边界框定位一帧的目标位置)空间重叠的short tubelet通过tublet非极大值抑制移除(不懂)。short tubelet是在视频片段中不同帧连接过的目标的一种表示。(不懂)
-
对整个视频进行short tubelet linking。这一步将具有时间重叠的片段的目标连接起来,并且优化连接过的tubelets的分类分数。
其中,前两步cuboid proposal generation和short tubelet detection生成时间重叠的short tubelets,从而确保可以在short tubelet linking 这一步进行连接。
1.Cuboid Proposal Generation
Tubelet:一组ground turth box的集合。
Cuboid:我的理解是一组相同的bbox的集合,用来约束目标的位移。在cuboid中的不同帧的目标被看成相同的目标。
作者那个Faster R-CNN的 Region Proposal Network修改为 Cuboid Proposal Network。RPN的输入是单张图像,CPN的输入是K帧图像。输出whk个cuboid proposals,其中有wxh个空间网格,其中每个位置有k个参考boxes。每个cuboid proposal都与一个客观评分关联。
2.Short Tubelet Detection
作者采用Cuboid Proposal的二维形式,作为视频片段每一帧的2Dbox(区域)proposal,对每一帧分别进行分类和细化。(就是说,类似RPN生成的proposal是对目标位置的一个粗略回归,这里选择二维的CPN输出作为每一帧的粗略proposal)
对于视频片段某一帧,作者采用与Fast R-CNN相同的方法来精炼边界框并且计算其分类分数。输入是一个二维的Region Proposal b、通过CNN获得的响应图I,之后执行ROI池化操作,ROI池化的结果喂给分类层和回归层,分别产生(C+1)维的分类分数向量、形成精炼后的边界框。
最终,对K帧分别生成K个精炼过的边界框,即为Short tubelet detection result。
为了移除冗余的short tubelets,作者将标准的非极大值抑制方法(NMS)扩展为Tubelet-NMS(T-NMS)来移除位置重叠的short tubelets。(与单张图像类似,若没有NMS会有许多重叠的冗余框,作者将标准NMS扩展到Tubelet)这种策略通过助阵NMS独立的为每一帧移除2D框,保证tubelets不被破坏(如果逐帧进行NMS,会打破现有Tubelet)。
作者依据相同帧的边界框IOU来度量两个tubelets的空间重叠度。(此处可能是因为一个视频片段可能产生了多个tubelets,就需要一种方式来度量两个Tubelets的相似性,也就是说只要有一堆边界框没有完全重合,那么这两个tubelets就不相同)
3.Short Tubelet Linking
作者将一段视频分为一系列长度为K帧的具有重叠帧的小片段(步长为K-1),每个小片段分别生成一个tubelet(小管子),当不同tubelet的重叠帧(相同帧)的空间重合度高于一个预定义的阈值时,将其连接在一起。
作者采用了一种贪婪地连接算法:开始时将所有视频片段的short tubelets放到一个池中,并且记录每个tubelet对应的视频片段。然后算法首先从池中选出分类得分最高的short tubelet,计算其重叠帧与其他tubelet的IOU,当IOU大于0.4时,将这两个short tubelets合并为一个长的tubelet,并且移除两个Tubelet的重叠帧中较低的分数,根据等式(2)Aggregation(⋅)=12(mean(⋅)+max(⋅))�����������(·)=12(����(·)+���(·))计算出新的分类分数。重复以上过程,直到没有tubelet可以合并。
最终,池中剩余的tubelets形成了视频目标检测的结果。tubelet的分数被分给每一个box。
总结
本篇论文提出的cuboid proposal network(CPN)让人眼前一亮,其主要思路是将一个长的视频片段分割成一个个短的片段,每个短的片段之间都有一帧重合。之后通过对不同tubelet之间重叠帧进行相似性度量,将多个tubelet连接在一起,并且优化连接过的tubelets的分类分数。
这种方法与此前的聚合方法有很大不同,此前方法大都集中在选择关键帧与非关键帧,而本文的方法是将长的视频片段分割成小片段。这种思路以后可以借鉴。
存在的问题:
-
分割片段的长度如何选择?2
-
图(b)中出现错误的分类,如何度量其相似性?
-
如果某个tubelet与其他的tubelet的IOU都很低怎么办?允许broken links