【编译原理】LR(1)分析方法(c++实现)
前文回顾
【编译原理】LR(0)分析方法(c++实现)
【编译原理】SLR(1)分析方法(c++实现)
算法
来自龙书第二版


代码
和SLR的区别其实只是DFA中多了一个搜索符,构建分析表的时候规约项的列是相应的搜索符而已
代码基本上就在SLR的代码上修修补补,但是写的有点乱,以后有时间再整理一下吧
Item类
#include LR(1)分析方法
#include first<<"\t"<second<
}
//填终结符
void addT()
{
string temp="";
for(string left:NT)
{
for(string right:production[left])
{
right+="#";
for(int i=0; i<right.size(); i++)
{
if(right[i]=='|'||right[i]==' '||right[i]=='#')
{
//不是非终结,且不是空,则加入终结符号
if((find(NT.begin(),NT.end(),temp)==NT.end())&&temp!="@")
{
T.push_back(temp);
}
temp="";
}
else
{
temp+=right[i];
}
}
}
}//end left
//终结符去重
sort(T.begin(),T.end());
T.erase(unique(T.begin(), T.end()), T.end());
}
//判断是否是非终极符号
bool isNT(string token)
{
if(find(NT.begin(),NT.end(),token)!=NT.end())
return true;
return false;
}
//判断temp在不在集合c中
bool isIn(Item temp,set<Item>c)
{
for(Item i:c)
{
if(i.getItem()==temp.getItem()&&i.getSymbol()==temp.getSymbol())
return true;
}
return false;
}
//判断是否应该规约
string tableReduce(int num)
{
for(State s:States)
{
//目标状态
if(s.id==num)
{
//遍历项目集
for(Item i:s.items)
{
//还有下一个点,肯定不是规约项目
if(i.hasNextDot())
return "";
//是规约项目
else
return i.getLeft();//返回左部NT
}
}
}
return "";
}
//找到item规约到的产生式,返回其编号
int findReduce(int num)
{
for(State s:States)
{
if(s.id==num)
{
for(Item i:s.items)
{
string temp=i.getItem();
temp.erase(temp.find("."));
temp.pop_back();
return numPro.find(temp)->second;
}
}
}
return -1;
}
//根据项目找规约的产生式编号
int findReduce(Item item)
{
string temp=item.getItem();
temp.erase(temp.find("."));
temp.pop_back();
if(numPro.find(temp)!=numPro.end())
return numPro.find(temp)->second;
return -1;
}
//找到产生式序号为pro的产生式右部数量
int rightCount(string &left,int pro)
{
for(auto it=numPro.begin(); it!=numPro.end(); it++)
{
if(it->second==pro)
{
cout<<it->first<<endl;
string target=it->first;
left=target.substr(0,target.find("->"));
string right=target.substr(target.find("->")+2);
vector<string>temp=split(right," ");
return temp.size();
}
}
return 0;
}
public:
//构造函数,读入所需的四元组
LR1(string fileName)
{
readGrammar(fileName);
Extension();//拓广文法
}
//拓广文法
void Extension()
{
string newS=S;
newS+="'";
NT.insert(NT.begin(),newS);
production[newS].push_back(S);
S=newS;
}
//状态集是否已经包含该状态
int hasState(set<Item>J)
{
for(State s:States)
{
if(s.items.size()!=J.size())
continue;
if(s.items==J)
return s.id;
else
continue;
}
return -1;
}
//获得FIRST集合
void getFirst()
{
FIRST.clear();
//终结符号或@
FIRST["@"].insert("@");
for(string X:T)
{
FIRST[X].insert(X);
}
//非终结符号
int j=0;
while(j<4)
{
for(int i=0; i<NT.size(); i++)
{
string A=NT[i];
//遍历A的每个产生式
for(int k=0; k<production[A].size(); k++)
{
int Continue=1;//是否添加@
string right=production[A][k];
//X是每条产生式第一个token
string X;
if(right.find(" ")==string::npos)
X=right;
else
X=right.substr(0,right.find(" "));
//cout<
//FIRST[A]=FIRST[X]-@
if(!FIRST[X].empty())
{
for(string firstX:FIRST[X])
{
if(firstX=="@")
continue;
else
{
FIRST[A].insert(firstX);
Continue=0;
}
}
if(Continue)
FIRST[A].insert("@");
}
}
}
j++;
}
}
//获得FOLLOW集合
void getFollow()
{
getFirst();
//将界符加入开始符号的follow集
FOLLOW[S].insert("$");
int j=0;
while(j<4)
{
//遍历非终结符号
for(string A:NT)
{
for(string right:production[A])
{
for(string B:NT)
{
//A->Bb
if(right.find(B)!=string::npos)
{
/*找B后的字符b*/
string b;
int flag=0;
//识别到E'
if(right[right.find(B)+B.size()]!=' '&&right[right.find(B)+B.size()]!='\0')
{
string s=right.substr(right.find(B));//E'b
string temp=right.substr(right.find(B)+B.size());//' b
//A->E'
if(temp.find(" ")==string::npos)
{
B=s;//B:E->E'
FOLLOW[B].insert(FOLLOW[A].begin(),FOLLOW[A].end());//左部的FOLLOW赋给B
flag=1;
}
//A->E'b
else
{
B=s.substr(0,s.find(" "));
temp=temp.substr(temp.find(" ")+1);//b
//b后无字符
if(temp.find(" ")==string::npos)
b=temp;
//b后有字符
else
b=temp.substr(0,temp.find(" "));
}
}
//A->aEb
else if(right[right.find(B)+B.size()]==' ')
{
string temp=right.substr(right.find(B)+B.size()+1);//B后的子串
//b后无字符
if(temp.find(" ")==string::npos)
b=temp;
//b后有字符
else
b=temp.substr(0,temp.find(" "));
}
//A->aE
else
{
FOLLOW[B].insert(FOLLOW[A].begin(),FOLLOW[A].end());
flag=1;
}
//FOLLOW[B]还没求到
if(flag==0)
{
//FIRST[b]中不包含@
if(FIRST[b].find("@")==FIRST[b].end())
{
FOLLOW[B].insert(FIRST[b].begin(),FIRST[b].end());
}
else
{
for(string follow:FIRST[b])
{
if(follow=="@")
continue;
else
FOLLOW[B].insert(follow);
}
FOLLOW[B].insert(FOLLOW[A].begin(),FOLLOW[A].end());
}
}
}
}
}
}
j++;
}
printFIRST();
printFOLLOW();
}
//项目闭包
set<Item> closure(Item item)
{
set<Item>C;//项目闭包
C.insert(item);
queue<Item>bfs;//bfs求所有闭包项
bfs.push(item);
//cout<
while(!bfs.empty())
{
Item now=bfs.front();
bfs.pop();
//cout<
vector<string>buffer=split(now.getRight(),".");
if(buffer.size()>1)
{
string first=firstWord(buffer[1].erase(0,1));
set<string>fst;
vector<string>candidate=split(now.getRight(),first);
//如果first后面有符号,则first后面符号的FIRST作为新的向前搜索符号
if(candidate.size()>1)
{
candidate[1].erase(0,1);
for(string f:FIRST[firstWord(candidate[1])])
fst.insert(f);
}
//如果first后面没有符号,则向前搜索符号为新的向前搜索符号
else
fst.insert(now.getSymbol());
if(isNT(first))//如果"."后面第一个字符是NT
{
for(auto it2=production[first].begin(); it2!=production[first].end(); it2++)
{
Item temp(first,*it2);
if(!isIn(temp,C))
{
for(string f:fst)
{
temp.setSymbol(f);
C.insert(temp);
bfs.push(temp);
}
}
}
}
}
}
return C;
}
//构造DFA
void dfa()
{
State s0;//初始项目集
s0.id=number++;//状态序号
//初始项目集
string firstRight=*(production[S].begin());
Item start(S,firstRight);
s0.items=closure(start);//加到状态中
States.insert(s0);
//构建DFA
State temp;
for(State s:States)
{
map<string,int>Paths;//路径
for(Item now:s.items)
{
now.getItem();
if(now.hasNextDot())
{
string path=now.getPath();//path
Item nextD(now.getLeft(),now.nextDot(),now.getSymbol());//新状态核心项,向前搜索符继承
set<Item>next=closure(nextD);//to
//该状态已经有这条路径了,则将新产生的闭包添加到原有目的状态中
int oldDes;
if(Paths.find(path)!=Paths.end())
{
oldDes=Paths.find(path)->second;
// cout<
for(State dest:States)
{
if(dest.id==oldDes)
{
dest.items.insert(next.begin(),next.end());
next=dest.items;
//更新状态集中状态
//set不允许重复插入,因此只能删除再插
States.erase(dest);
States.insert(dest);
int tID=hasState(next);
if(tID!=-1)
{
//temp=dest;
for(int i=0; i<GO.size(); i++)
{
if(GO[i].to==oldDes)
{
GO[i].to=tID;
// cout<
}
}
}
}
}
}
//如果该目的状态在状态集里没有出现过,就加入状态集
int tID=hasState(next);
if(tID==-1)
{
State t;
t.id=number++;
t.items=next;
States.insert(t);
Paths.insert(pair<string,int>(path,t.id));
GO.push_back(GOTO(s.id,path,t.id));
}
//该目的状态已经在状态集中了
else
{
Paths.insert(pair<string,int>(path,tID));
GO.push_back(GOTO(s.id,path,tID));
}
}
}
}
//删除重复GOTO
sort(GO.begin(),GO.end());
GO.erase(unique(GO.begin(), GO.end()), GO.end());
//处理重复状态
for(State s1:States)
{
for(State s2:States)
{
//发现重复状态集
if(s2.id>s1.id&&s1.items==s2.items)
{
int erase_id=s2.id;
States.erase(s2);
//重复状态后面的所有状态序号-1
for(State s:States)
{
if(s.id>erase_id)
{
//原地修改set!
State &newS=const_cast<State&>(*States.find(s));
newS.id--;
}
}
//状态转移函数
for(int i=0; i<GO.size(); i++)
{
if(GO[i].from==erase_id||GO[i].to==erase_id)
GO.erase(find(GO.begin(),GO.end(),GO[i]));
if(GO[i].from>erase_id)
GO[i].from--;
if(GO[i].to>erase_id)
GO[i].to--;
}
}
}
}
printS();
printGO();
}
//构造LR(1)分析表
void getTable()
{
addNumP();
string s=S;
s=s.erase(s.find("'"));
pair<int,string>title(1,"$");
actionTable[title]="acc";
for(GOTO go:GO)
{
//目的地是NT
if(isNT(go.path))
{
pair<int,string>title(go.from,go.path);
gotoTable[title]=go.to;
}
//加入action表
else
{
//shift
pair<int,string>title(go.from,go.path);
actionTable[title]="s"+to_string(go.to);
}
//reduce,行为状态号,列为向前搜索符
string rNT=tableReduce(go.to);
if(rNT!="")
{
if(go.path!=s)
{
//找该状态的项目集
State temp;
temp.id=go.to;
temp=*(States.find(temp));
set<Item>itm(temp.items.begin(),temp.items.end());
//向前搜索符下的规约项规约到对应产生式
for(Item i:itm)
{
pair<int,string>title(go.to,i.getSymbol());
int nReduce=findReduce(i);
if(nReduce!=-1)
actionTable[title]="r"+to_string(nReduce);
else
actionTable[title]="error";
}
}
}
}
printTable();
}
//语法分析过程
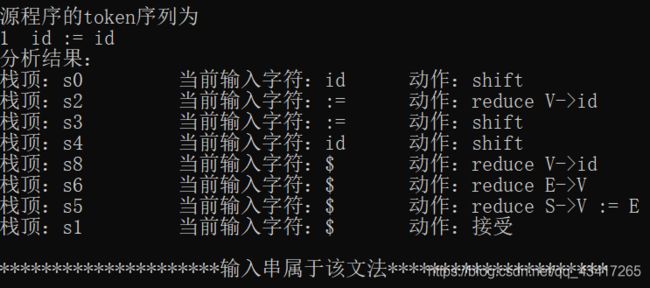
int parsing(string input)
{
stack<string>Analysis;
input+=" $";
//0状态入栈
Analysis.push("$");
Analysis.push("0");
vector<string>w=split(input," ");//将输入串分成一个个词
int ip=0;//输入串的指针
while(true)
{
pair<int,string>title(stoi(Analysis.top()),w[ip]);//stoi函数用于string to int
string res=actionTable[title];
cout<<"栈顶:s"<<setw(10)<<Analysis.top()<<"当前输入字符:"<<setw(8)<<w[ip];
//shift
if(res[0]=='s')
{
cout<<"动作:shift"<<endl;
int state=stoi(res.substr(1));
Analysis.push(w[ip]);
Analysis.push(to_string(state));
ip++;
}
//reduce
else if(res[0]=='r')
{
cout<<"动作:reduce ";
int pro=stoi(res.substr(1));
string left;//产生式左部
int b=2*rightCount(left,pro);//2倍的产生式右部符号数量
while(b>0)
{
Analysis.pop();
b--;
}
int s1=stoi(Analysis.top());
Analysis.push(left);
pair<int,string>t(s1,left);
Analysis.push(to_string(gotoTable[t]));
}
else if(res[0]=='a')
{
cout<<"动作:接受"<<endl;
return 1;
}
else
{
cout<<"文法错误"<<endl;
return 0;
}
}
}
void parser(string fileName)
{
ifstream input(fileName);
if(!input)
{
cout<<fileName<<" Failed"<<endl;
return;
}
getFollow();
dfa();
getTable();
//读取token
char c;
string program="";
int line=1;
cout<<"源程序的token序列为"<<endl;
cout<<line<<" ";
while((c=input.get())!=EOF)
{
cout<<c;
if(c=='\n')
{
cout<<++line<<" ";
program+=" ";
}
else
program+=c;
}
cout<<endl;
cout<<"分析结果:"<<endl;
if(parsing(program))
cout<<endl<<"*********************输入串属于该文法*********************"<<endl;
else
cout<<endl<<"********************输入串不属于该文法********************"<<endl;;
}
/*=====================打印===========================*/
//打印NT和T
void printV()
{
cout<<"非终结符号集合:"<<endl;
for(int i=0; i<NT.size(); i++)
{
cout<<NT[i]<<" ";
}
cout<<endl;
cout<<"终结符号集合:"<<endl;
for(int i=0; i<T.size(); i++)
{
cout<<T[i]<<" ";
}
cout<<endl;
}
//打印FIRST集
void printFIRST()
{
cout<<"FIRST集合为"<<endl;
cout.setf(ios::left);
for(string non_terminal:NT)
{
cout<<setw(20)<<non_terminal;
for(string first:FIRST[non_terminal])
cout<<first<<" ";
cout<<endl;
}
cout<<endl;
}
//打印FOLLOW集
void printFOLLOW()
{
cout<<"FOLLOW集合为"<<endl;
cout.setf(ios::left);
for(string non_terminal:NT)
{
cout<<setw(20)<<non_terminal;
for(string follow:FOLLOW[non_terminal])
cout<<follow<<" ";
cout<<endl;
}
cout<<endl;
}
//打印分析表
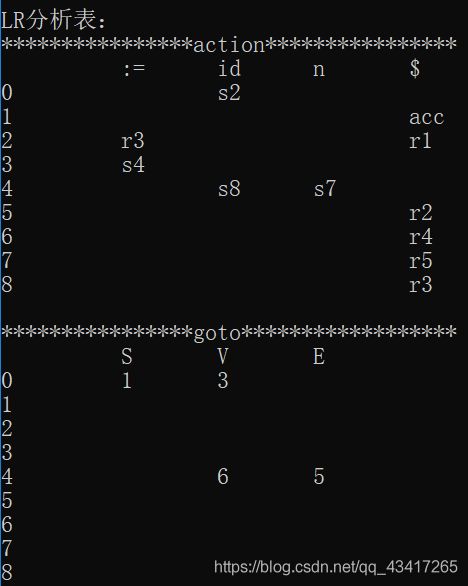
void printTable()
{
cout<<"LR分析表:"<<endl;
vector<string>x=T;//含界符的终结符号集合
x.push_back("$");
//输出表格横轴
cout<<"****************action****************"<<endl;
cout.setf(ios::left);
for (auto it1 = x.begin(); it1 != x.end(); it1++)
{
if (it1==x.begin())
cout<<setw(10)<<" ";
cout<<setw(8)<<*it1;
}
cout<<endl;
for(int i=0; i<States.size(); i++)
{
cout<<setw(10)<<i;
for(string t:x)
{
//cout<
if(!actionTable.empty())
{
pair<int,string>title(i,t);
cout<<setw(8)<<actionTable[title];
}
else
cout<<setw(8);
}
cout<<endl;
}
cout<<endl;
/*打印GOTO表*/
vector<string>y=NT;//不含S’的非终结符号集合
y.erase(y.begin());
cout<<"****************goto******************"<<endl;
cout.setf(ios::left);
for (auto it1 = y.begin(); it1 != y.end(); it1++)
{
if(it1==y.begin())
cout<<setw(10)<<"";
cout<<setw(8)<<*it1;
}
cout<<endl;
for(int i=0; i<States.size(); i++)
{
cout<<setw(10)<<i;
for(string t:y)
{
pair<int,string>title(i,t);
if(gotoTable[title]!=0)
{
cout<<setw(8)<<gotoTable[title];
}
else
cout<<setw(8)<<"";
}
cout<<endl;
}
cout<<endl<<"LR分析表构建完成"<<endl<<endl;
}
//打印产生式
void printP()
{
cout<<"语法的产生式为"<<endl;
for(string left:NT)
{
cout<<left<<"->";
for(auto it=production[left].begin(); it!=production[left].end(); it++)
{
if(it!=production[left].end()-1)
cout<<*it<<"|";
else
cout<<*it<<endl;
}
}
cout<<endl;
}
//打印状态表
void printS()
{
cout<<"**********状态集合为**********"<<endl;
for(State s:States)
{
cout<<"状态编号:"<<s.id<<endl;
printI(s.items);
}
cout<<endl;
}
//打印状态转移函数
void printGO()
{
cout<<"**********状态转移函数为**********"<<endl;
for(GOTO go:GO)
{
cout<<go.from<<"---"<<go.path<<"-->"<<go.to<<endl;
}
cout<<endl;
}
//打印项目集
void printI(set<Item>I)
{
cout<<"LR的项目集为"<<endl;
for(Item i:I)
{
cout<<i.getItem()<<","<<i.getSymbol()<<endl;
}
cout<<endl;
}
};
int main()
{
string filename="grammar-input.txt";
LR1 grammar(filename);
grammar.printP();//输出产生式
grammar.parser("Tokens.txt");
return 0;
}
/*
测试文法:
S->id|V := E
V->id
E->V|n
*/
测试结果