OpenCV 图像处理学习手册:1~5
原文:Learning Image Processing with OpenCV
协议:CC BY-NC-SA 4.0
译者:飞龙
本文来自【ApacheCN 计算机视觉 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。
当别人说你没有底线的时候,你最好真的没有;当别人说你做过某些事的时候,你也最好真的做过。
一、处理图像和视频文件
本章旨在与 OpenCV,其安装和第一个基本程序进行首次接触。 我们将涵盖以下主题:
- 面向新手的 OpenCV 简介,然后是简单的分步安装库指南
- 在用户本地磁盘中安装后快速浏览 OpenCV 的结构
- 使用带有一些常见编程框架的库创建项目的快速秘籍
- 如何使用函数读取和写入图像和视频
- 最后,我们描述了用于向软件项目添加丰富的用户界面的库函数,包括鼠标交互,绘图基元和 Qt 支持
OpenCV 简介
OpenCV(开源计算机视觉)最初是由英特尔开发的,它是一个免费跨平台库,用于实时图像处理,实际上已经成为用于与计算机视觉相关的所有事物的标准工具。 第一个版本于 2000 年以 BSD 许可证发行,此后,其功能得到了科学界的极大丰富。 2012 年,非营利组织 OpenCV.org 承担了为开发人员和用户维护支持网站的任务。
注意
在撰写本书时,OpenCV 的新主要版本(版本 3.0)可用,但仍处于 beta 状态。 在整本书中,我们将介绍此新版本带来的最相关的更改。
OpenCV 适用于最流行的操作系统,例如 GNU/Linux,OSX,Windows,Android,iOS 等。 第一个实现是在C编程语言中实现的; 但是,随着版本 2.0 的 C++ 实现,它的受欢迎程度随之增加。 新功能使用 C++ 编程。 但是,如今,该库具有其他编程语言(例如 Java,Python 和 MATLAB/Octave)的完整接口。 另外,还开发了用于其他语言(例如 C#,Ruby 和 Perl)的包装程序,以鼓励程序员采用。
为了最大程度地提高计算密集型视觉任务的性能,OpenCV 包括对以下内容的支持:
- 使用线程构建模块(TBB)在多核计算机上进行多线程处理-由 Intel 开发的模板库。
- 英特尔处理器上的集成性能基元(IPP)的子集,以提高性能。 多亏了 Intel,这些原语可从 3.0 beta 版开始免费获得。
- 使用计算统一设备架构(CUDA)和开放计算语言(OpenCL)。
OpenCV 的应用涵盖以下领域:分段和识别,2D 和 3D 功能工具包,对象识别,人脸识别,运动跟踪,手势识别,图像拼接,高动态范围(HDR)成像,增强现实等等。 此外,为了支持某些先前的应用领域,还包括具有统计机器学习功能的模块。
下载并安装 OpenCV
OpenCV 可从这里免费下载。 该站点提供了发行的最新版本(当前为 3.0 beta)和较旧的版本。
注意
如果下载的版本是不稳定版本,例如当前的 3.0 beta 版本,则应格外小心,以免出现错误。
在这个页面上,可以找到适用于每个平台的 OpenCV 版本。 可以根据最终目的从不同的存储库中获取代码和库信息:
-
主存储库(位于这个页面),专用于最终用户。 它包含库的二进制版本和目标平台的可编译源。
-
测试数据存储库(位于这个页面),其中包含用于测试某些库模块目的的数据集。
-
贡献者仓库位于这个页面)带有源代码,与贡献者提供的额外功能和最先进的功能相对应。 与主干相比,此代码更容易出错,并且测试较少。
提示
在最新版本的 OpenCV 3.0 beta 中,额外的贡献模块未包含在主包中。 它们应单独下载,并通过适当的选项明确包含在编译过程中。 如果包括其中一些贡献的模块,请务必谨慎,因为其中一些模块依赖于 OpenCV 不附带的第三方软件。
-
每个模块的文档站点(位于这个页面),包括提供的模块。
-
开发库(位于这个页面),带有库的当前开发版本。 它适用于库主要功能的开发人员以及希望在发布最新版本之前仍使用最新更新的“急躁”用户。
而不是 GNU/Linux 和 OSX,其中 OpenCV 仅作为源代码分发,在 Windows 发行版中,可以找到预编译的(使用 Microsoft Visual C++ v10,v11 和 v12)的版本。 每个预编译的版本都可以与 Microsoft 编译器一起使用。 但是,如果主要目的是使用不同的编译器框架开发项目,则需要为该特定编译器(例如 GNU GCC)编译库。
提示
使用 OpenCV 最快的方法是使用发行版随附的预编译版本之一。 然后,更好的选择是使用用于软件开发的本地平台的最佳设置来构建库的微调版本。 本章提供在 Windows 上构建和安装 OpenCV 的信息。 在这个页面和这个页面上可以找到在 Linux 上设置库的更多信息。
获取编译器并设置 CMake
使用 OpenCV 开发跨平台的一个不错的选择是使用 GNU 工具包(包括 gmake,g++ 和 gdb)。 对于大多数流行的操作系统,可以轻松获得 GNU 工具包。 对于开发环境,我们的首选选择包括 GNU 工具包和跨平台 Qt 框架,其中包括 Qt 库和 Qt Creator 集成开发环境(IDE)。 Qt 框架可从这个页面免费获得。
注意
在 Windows 上安装编译器之后,请记住正确设置Path环境变量,为编译器的可执行文件添加路径,例如 Qt 框架随附的 GNU /编译器的C:\Qt\Qt5.2.1\5.2.1\mingw48_32\bin。 在 Windows 上,免费的快速环境编辑器工具(可从这个页面获得)提供了一种方便的方式来更改Path和其他环境变量 。
要以与编译器无关的方式管理 OpenCV 库的生成过程,推荐使用 CMake 工具。 CMake 是可从这个页面上获得的免费且开源的跨平台工具。
使用 CMake 配置 OpenCV
将库的源代码下载到本地磁盘后,需要为该库的编译过程配置 Makefile。 CMake 是轻松配置 OpenCV 安装过程的关键工具。 它可以从命令行使用,也可以通过图形用户界面(GUI)版本以更加用户友好的方式使用。
使用 CMake 配置 OpenCV 的步骤总结如下:
- 选择源目录(在下面将其命名为
OPENCV_SRC)和目标目录[OPENCV_BUILD)。 目标目录是编译后的二进制文件所在的位置。 - 选中分组和高级复选框,然后单击配置按钮。
- 选择所需的编译器(例如,GNU 默认编译器,MSVC 等)。
- 设置首选选项,然后取消设置不需要的选项。
- 单击配置按钮并重复步骤 4 和 5,直到没有错误为止。
- 单击生成按钮并关闭 CMake。
以下屏幕截图显示了 CMake 的主窗口,其中包含源目录和目标目录以及将所有可用选项分组的复选框:

预先配置步骤后的 CMake 主窗口
注意
为简便起见,本文中使用OPENCV_BUILD和OPENCV_SRC分别表示 OpenCV 本地设置的目标目录和源目录。 请记住,所有目录都应与您当前的本地配置相匹配。
在预配置过程中,CMake 会检测到存在的编译器和许多其他本地属性,以设置 OpenCV 的生成过程。 上一个屏幕截图显示了预配置过程后的 CMake 主窗口,并以红色显示了分组的选项。
可以保留默认选项不变,然后继续配置过程。 但是,可以设置一些方便的选项:
BUILD_EXAMPLES:设置为使用 OpenCV 构建一些示例。BUILD_opencv_:设置为在构建过程中包括模块(module_name)。OPENCV_EXTRA_MODULES_PATH:当您需要一些额外的模块时使用; 在此处设置附加模块的源代码的路径(例如C:/opencv_contrib-master/modules)。WITH_QT:启用此功能可将 Qt 功能包括在库中。WITH_IPP:此选项默认为打开。 当前的 OpenCV 3.0 版本包括英特尔集成性能基元(IPP)的子集,这些子集可加快库的执行时间。
提示
如果编译新的 OpenCV 3.0(测试版),请小心,因为已报告一些与 IPP 包含有关的意外错误(即,使用此选项的默认值)。 我们建议您取消设置WITH_IPP选项。
如果配置与 CMake 一起执行(循环执行步骤 4 和 5)没有产生任何其他错误,则可以为构建过程生成最终的 Makefile。 以下屏幕截图显示了生成步骤后没有错误的 CMake 主窗口:

编译和安装库
使用 CMake 生成 Makefile 的过程之后的下一步是使用适当的make工具进行的编译。 通常在目标目录(在 CMake 配置步骤中设置的目录)的命令行(控制台)上执行此工具。 例如,在 Windows 中,应从命令行启动编译,如下所示:
OPENCV_BUILD>mingw32-make
此命令使用 CMake 生成的 Makefile 启动构建过程。 整个编译通常需要几分钟。 如果编译没有错误结束,则安装将继续执行以下命令:
OPENCV_BUILD>mingw32-make install
此命令将 OpenCV 二进制文件复制到OPENCV_BUILD\install目录。
如果在编译过程中出现问题,我们应该再次运行 CMake 来更改在配置过程中选择的选项。 然后,我们应该重新生成 Makefile。
通过将库二进制文件的位置(例如,在 Windows 中,生成的 DLL 文件位于OPENCV_BUILD\install\x64\mingw\bin)添加到Path,安装环境变量的末尾。 如果Path字段中没有此目录,则每个 OpenCV 可执行文件的执行都会出错,因为找不到库二进制文件。
要检查安装过程是否成功,可以运行随库一起编译的一些示例(如果使用 CMake 设置了BUILD_EXAMPLES选项)。 代码示例(用 C++ 编写)可以在OPENCV_BUILD\install\x64\mingw\samples\cpp找到。
注意
安装 OpenCV 的简短说明适用于 Windows。 可以在这个页面上阅读有关 Linux 前提条件的详细说明。 尽管本教程适用于 OpenCV 2.0,但几乎所有信息对于版本 3.0 仍然有效。
OpenCV 的结构
一旦安装 OpenCV ,OPENCV_BUILD\install目录将填充三种类型的文件:
- 头文件:它们位于
OPENCV_BUILD\install\include子目录中的,用于通过 OpenCV 开发新项目。 - 库二进制文件:这些是静态或动态库(取决于 CMake 选择的选项),具有每个 OpenCV 模块的功能。 它们位于
bin子目录中(例如,当使用 GNU 编译器时,为x64\mingw\bin)。 - 示例二进制文件:这些是可执行文件,并带有使用库的示例。 这些样本的来源可以在源包中找到(例如
OPENCV_SRC\sources\samples)。
OpenCV 具有模块化的结构,这意味着该包为每个模块都包含一个静态或动态(DLL)库。 每个模块的正式文档可以在这个页面中找到。 包中包含的主要模块是:
-
core:这定义了所有其他模块使用的基本功能以及包括重要多维数组Mat在内的基本数据结构。 -
highgui:这提供了简单的用户界面(UI)功能。 使用 Qt 支持(WITH_QTCMake 选项)构建库可以使 UI 与此类框架兼容。 -
imgproc:这些是图像处理功能,包括滤波(线性和非线性),几何变换,颜色空间转换,直方图等。 -
imgcodecs: 这是一个易于使用的界面,用于读取和写入图像。注意
自从 OpenCV 3.0 以来,请注意模块中的更改,因为某些功能已移至新模块(例如,读取和写入图像功能已从
highgui移至imgcodecs)。 -
photo:这包括计算摄影,包括修补,去噪,High动态范围(HDR)成像等。 -
stitching:用于图像拼接。 -
videoio:这是一个易于使用的界面,用于视频捕获和视频编解码器。 -
video:它为提供视频分析功能(运动估计,背景提取和对象跟踪)。 -
features2d:这些是功能,用于特征检测(角和平面对象),特征描述,特征匹配等。 -
objdetect:这些是功能,用于对象检测和预定义检测器实例(例如脸部,眼睛,微笑,人,汽车等)。
其他一些模块是calib3d(相机校准),flann(聚类和搜索),ml(机器学习),shape(形状距离和匹配),superres(超分辨率),video (视频分析)和videostab(视频稳定)。
注意
从 3.0 beta 版开始,新的贡献模块以单独的包(opencv_contrib-master.zip)分发,可以从这个页面下载。 这些模块提供了的附加功能,在使用它们之前,应充分了解它们。 有关新版 OpenCV(版本 3.0)中新功能的快速概述,请参考位于这个页面的文档。
使用 OpenCV 创建用户项目
在本书中,我们假定 C++ 是用于编程图像处理应用的主要语言,尽管实际上提供了其他编程语言的接口和包装器(例如 Python,Java,MATLAB/Octave 等)。
在本节中,我们将说明如何使用易于使用的跨平台框架使用 OpenCV 的 C++ API 开发应用。
库的一般用法
要使用 C++ 开发 OpenCV 应用,我们需要我们的代码:
- 包括带有定义的 OpenCV 头文件
- 链接 OpenCV 库(二进制文件)以获取最终的可执行文件
OpenCV 标头文件位于OPENCV_BUILD\install\include\opencv2目录中,每个模块都有一个文件(*.hpp)。 头文件的包含是通过#include伪指令完成的,如下所示:
#include 使用此伪指令,可以包含用户程序所需的每个头文件。 另一方面,如果包含opencv.hpp头文件,则将自动包括所有头文件,如下所示:
#include 注意
请记住,本地安装的所有模块都在OPENCV_BUILD\install\include\opencv2\opencv_modules.hpp头文件中定义,该头文件在 OpenCV 的构建过程中自动生成。
#include指令的使用并不总是保证正确包含头文件,因为有必要告诉编译器在哪里可以找到包含文件。 这可以通过在文件的位置传递一个特殊的参数来实现(例如,对于 GNU 编译器为I\)。
链接过程要求您为链接器提供库(动态或静态),可以在其中找到所需的 OpenCV 功能。 通常使用链接器的两种类型的参数来完成:库的位置(例如,对于 GNU 编译器为‑L)和库的名称(例如-l)。
注意
您可以在这个页面和这个页面中找到 GNU GCC 和make可用在线文档的完整列表。
开发新项目的工具
开发我们自己的 OpenCV C++ 应用的主要先决条件是:
- OpenCV 头文件和库二进制文件:当然,我们需要编译 OpenCV,辅助库是进行此类编译的前提条件。 该包应使用与生成用户应用相同的编译器进行编译。
- C++ 编译器:一些辅助工具可以方便地用作代码编辑器,调试器,项目管理器和流程管理器(例如 CMake),版本控制系统(例如 Git,Mercurial,SVN 等)以及类检查器等。 通常,这些工具一起部署在所谓的集成开发环境(IDE)中。
- 任何其他辅助库:可选地,将需要对最终应用进行编程的任何其他辅助库,例如图形,统计等。
用于编程 OpenCV C++ 应用的最受欢迎的编译器套件是:
- Microsoft Visual C(MSVC):Windows 仅支持,它与 IDE Visual Studio 集成得很好,尽管它也可以与其他跨平台 IDE(例如 Qt Creator 或 Eclipse)集成。 当前与最新的 OpenCV 版本兼容的 MSVC 版本是 VC 10,VC 11 和 VC 12(Visual Studio 2010、2012 和 2013)。
- GNU 编译器集合 GNU GCC:这是由 GNU 项目开发的跨平台编译器系统。 对于 Windows,此套件称为 MinGW(最小 GNU GCC)。 与当前 OpenCV 发行版兼容的版本是 GNU GCC 4.8。 该套件可与多个 IDE 一起使用,例如 Qt Creator,Code :: Blocks,Eclipse 等。
对于本书介绍的示例,我们使用了 Windows 的 MinGW 4.8 编译器套件以及 Qt 5.2.1 库和 Qt Creator IDE(3.0.1)。 跨平台 Qt 库需要使用此类库提供的新 UI 功能来编译 OpenCV。
注意
对于 Windows,可以从这个页面下载 Qt 捆绑包(包括 Qt 库,Qt Creator 和 MinGW 套件)。 捆绑包约为 700 MB。
Qt Creator 是用于 C++ 的跨平台 IDE,它集成了我们编码应用所需的工具。 在 Windows 中,它可以与 MinGW 或 MSVC 一起使用。 以下屏幕截图显示了 Qt Creator 主窗口,其中包含 OpenCV C++ 项目的不同面板和视图:

Qt Creator 的主窗口带有 OpenCV C++ 项目的一些视图
使用 Qt Creator 创建 OpenCV C++ 程序
接下来,我们说明如何使用 Qt Creator IDE 创建代码项目。 特别是,我们将此描述应用于 OpenCV 示例。
我们可以通过导航到文件 | Qt Creator | 新文件或文件 | 项目…,然后导航到非 Qt 项目 | 普通 C++ 项目为任何 OpenCV 应用创建一个项目。 然后,我们必须选择一个项目名称及其存储位置。 下一步是为项目(在我们的情况下为 Desktop Qt 5.2.1 MinGW 32 位)选择一个工具包(即编译器),并确定生成二进制文件的位置。 通常,使用两种可能的构建配置(配置文件):debug和release。 这些配置文件设置适当的标志来构建和运行二进制文件。
使用 Qt Creator 创建项目时,将生成两个特殊文件(扩展名为.pro和.pro.user)来配置生成和运行过程。 构建过程由在项目创建期间选择的工具包确定。 使用 Desktop Qt 5.2.1 MinGW 32 位套件,此过程依赖于qmake和 mingw32make 工具。 使用*.pro文件作为输入,qmake生成用于驱动每个配置文件(即release和debug)构建过程的 Makefile。 Qt Creator IDE 使用qmake工具作为 CMake 的替代品,以简化软件项目的构建过程。 它可以自动从几行信息中生成 Makefile。
以下各行代表*.pro文件(例如showImage.pro)的示例:
TARGET: showImage
TEMPLATE = app
CONFIG += console
CONFIG -= app_bundle
CONFIG -= qt
SOURCES += \
showImage.cpp
INCLUDEPATH += C:/opencv300-buildQt/install/include
LIBS += -LC:/opencv300-buildQt/install/x64/mingw/lib \
-lopencv_core300.dll \
-lopencv_imgcodecs300.dll\
-lopencv_highgui300.dll\
-lopencv_imgproc300.dll
上一个文件说明了qmake生成适当的 Makefile 来构建项目二进制文件所需的选项。 每行以一个标记(表示TARGET,CONFIG,SOURCES,INCLUDEPATH和LIBS)的标签开头,后跟一个标记以添加(+=)或删除(-=)可选值。 在此示例项目中,我们使用非 Qt 控制台应用。 可执行文件为showImage.exe(TARGET),源文件为showImage.cpp(SOURCES)。 由于此项目是基于 OpenCV 的应用,因此最后两个标签指示此特定项目(core,imgcodecs,highgui和imgproc)。 注意,在行末尾的反斜杠表示在下一行继续。
注意
有关在 Qt 项目中开发的工具(包括 Qt Creator 和qmake)的详细说明,请访问这个页面。
读写图像文件
图像处理依赖于获得图像(例如照片或视频名望)并通过在其上应用信号处理技术来“播放”图像以获得所需的结果。 在本节中,我们向您展示如何使用 OpenCV 提供的功能从文件读取图像。
基本 API 概念
Mat类是在 OpenCV 中存储和处理图像的主要数据结构。 此类在core模块中定义。 OpenCV 已实现了为这些数据结构自动分配和释放内存的机制。 但是,当数据结构共享相同的缓冲存储器时,程序员仍应格外小心。 例如,赋值运算符不将内存内容从对象(Mat A)复制到另一个对象(Mat B); 它仅复制引用(内容的内存地址)。 然后,一个对象(A或B)的更改会影响两个对象。 要复制Mat对象的内存内容,应使用Mat::clone()成员函数。
注意
OpenCV 中的许多函数通常使用Mat类来处理密集的单通道或多通道数组。 但是,在某些情况下,可以使用其他数据类型,例如std::vector<>,Matx<>,Vec<>或Scalar。 为此,OpenCV 提供了代理类InputArray和OutputArray,它们允许将任何先前的类型用作函数的参数。
Mat类用于密集的 n 维单通道或多通道数组。 它实际上可以存储实数或复数值向量和矩阵,彩色或灰度图像,直方图,点云等。
创建Mat对象的方法有很多,最流行的是构造器,其中指定数组的大小和类型如下:
Mat(nrows, ncols, type, fillValue)
数组元素的初始值可以由Scalar类设置为典型的四元素向量(针对数组中存储的图像的每个 RGB 和透明度分量)。 接下来,我们向您展示Mat的用法示例,如下所示:
Mat img_A(4, 4, CV_8U, Scalar(255));
// White image:
// 4 x 4 single-channel array with 8 bits of unsigned integers
// (up to 255 values, valid for a grayscale image, for example,
// 255=white)
DataType类定义了 OpenCV 的原始数据类型。 基本数据类型可以是bool,unsigned char,signed char,unsigned short,signed short,int,float,double或这些原始类型之一的值的元组。 任何原始类型都可以由标识符以以下形式定义:
CV_<bit depth>{U|S|F}C(<number of channels>)
在前面的代码U中,S和F分别代表unsigned,signed和float。 对于单通道数组,将应用以下枚举,以描述数据类型:
enum {CV_8U=0, CV_8S=1, CV_16U=2, CV_16S=3,CV_32S=4, CV_32F=5, CV_64F=6};
注意
在此,应注意,这三个声明是等效的:CV_8U,CV_8UC1和CV_8UC(1)。 单通道声明非常适合用于灰度图像的整数数组,而数组的三通道声明更适合具有三个分量(例如 RGB,BRG,HSV 等)的图像。 对于线性代数运算,可以使用float(F)类型的数组。
我们可以为多通道数组(最多 512 个通道)定义所有上述数据类型。 以下屏幕截图说明了一个通道(CV_8U,grayscale)的图像内部表示以及三个通道(CV_8UC3,RGB)表示的同一图像。 这些屏幕截图是通过放大 OpenCV 可执行文件窗口中显示的图像(showImage示例)而获得的:
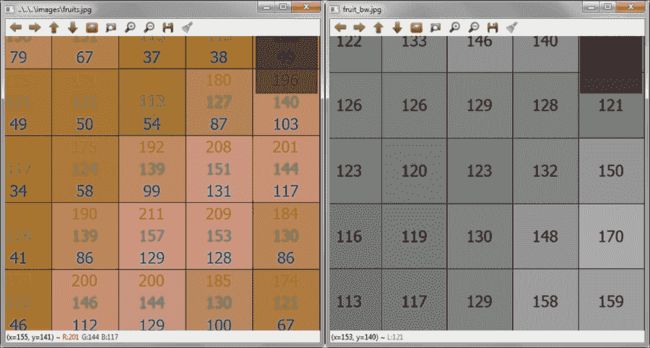
RGB 颜色和灰度的图像的 8 位表示
注意
的注意很重要,要使用 OpenCV 功能正确保存 RGB 图像,必须将图像存储在内存中,其通道按 BGR 顺序排列。 以相同的方式,当从文件中读取 RGB 图像时,它以 BGR 顺序以其通道存储在内存中。 而且,它需要一个辅助的第四通道(alpha)来操作具有 RGB 和透明性三个通道的图像。 对于 RGB 图像,较大的整数值表示 alpha 通道的像素更亮或更透明。
所有 OpenCV 类和函数都在cv命名空间中,因此,我们在源代码中将具有以下两个选项:
- 包括头文件之后,添加
using namespace cv声明(这是本书所有代码示例中使用的选项)。 - 将
cv::前缀附加到我们使用的所有 OpenCV 类,函数和数据结构。 如果 OpenCV 提供的外部名称与常用的标准模板库(STL)或其他库冲突,则建议使用此选项。
图像文件支持的格式
OpenCV 支持最常见的图像格式。 但是,其中一些需要(免费提供)第三方库。 OpenCV 支持的主要格式为:
- Windows 位图(
*.bmp和*dib) - 便携式图像格式(
*.pbm,*.pgm,*.ppm) - 太阳栅格(
*.sr,*.ras)
需要辅助库的格式为:
- JPEG(
*.jpeg,*.jpg,*.jpe) - JPEG 2000(
*.jp2) - 便携式网络图形(
*.png) - TIFF(
*.tiff,*.tif) - WebP(
*.webp)。
除上述列出的格式外,对于 OpenCV 3.0 版本,它还包括支持以下格式的驱动程序(NITF,DTED,SRTM 等) 由地理数据抽象库(GDAL)设置,并带有 CMake 选项WITH_GDAL。 请注意,尚未在 Windows 操作系统上对 GDAL 支持进行广泛的测试。 在 Windows 和 OSX 中,默认情况下使用 OpenCV 附带的编解码器(libjpeg,libjasper,libpng和libtiff)。 然后,在这些 OS 中,可以读取 JPEG,PNG 和 TIFF 格式。 Linux(和其他类似 Unix 的开源操作系统)正在寻找系统中安装的编解码器。 可以在 OpenCV 之前安装编解码器,也可以通过在 CMake 中设置适当的选项(例如BUILD_JASPER,BUILD_JPEG,BUILD_PNG和BUILD_TIFF)从 OpenCV 包中构建库。
示例代码
为了说明如何使用 OpenCV 读取和写入图像文件,我们现在将描述showImage示例。 从命令行使用相应的输出窗口执行示例,如下所示:
<bin_dir>\showImage.exe fruits.jpg fruits_bw.jpg

showImage示例的输出窗口
在此示例中,给出了两个文件名作为参数。 第一个是要读取的输入图像文件。 第二个是要与输入图像的灰度副本一起写入的图像文件。 接下来,我们向您显示源代码及其说明:
#include
// Read original image
in_image = imread(argv[1], IMREAD_UNCHANGED);
if (in_image.empty()) {
// Check whether the image is read or not
cout << "Error! Input image cannot be read...\n";
return -1;
}
// Creates two windows with the names of the images
namedWindow(argv[1], WINDOW_AUTOSIZE);
namedWindow(argv[2], WINDOW_AUTOSIZE);
// Shows the image into the previously created window
imshow(argv[1], in_image);
cvtColor(in_image, out_image, COLOR_BGR2GRAY);
imshow(argv[2], in_image);
cout << "Press any key to exit...\n";
waitKey(); // Wait for key press
// Writing image
imwrite(argv[2], in_image);
return 0;
}
在这里,我们将#include指令与opencv.hpp头文件一起使用,该头文件实际上包括所有 OpenCV 头文件。 通过包含此单个文件,无需再包含其他文件。 声明使用cv命名空间后,此命名空间内的所有变量和函数都不需要cv::前缀。 在main函数中要做的第一件事是检查在命令行中传递的参数数量。 然后,如果发生错误,将显示帮助消息。
读取图像文件
如果参数数量正确,则使用imread(argv[1], IMREAD_UNCHANGED)函数将图像文件读入Mat in_image对象,其中第一个参数是在命令行中传递的第一个参数(argv[1]) 参数是一个标志(IMREAD_UNCHANGED),这意味着存储在内存对象中的图像应保持不变。 imread函数根据文件内容而不是文件扩展名确定图像(编解码器)的类型。
imread函数的原型如下:
Mat imread(const String& filename,
int flags = IMREAD_COLOR )
该标志指定所读取图像的颜色,它们由imgcodecs.hpp头文件中的以下枚举定义和解释:
enum { IMREAD_UNCHANGED = -1, // 8bit, color or not
IMREAD_GRAYSCALE = 0, // 8bit, gray
IMREAD_COLOR = 1, // unchanged depth, color
IMREAD_ANYDEPTH = 2, // any depth, unchanged color
IMREAD_ANYCOLOR = 4, // unchanged depth, any color
IMREAD_LOAD_GDAL = 8 // Use gdal driver
};
注意
从 OpenCV 3.0 版开始,imread函数在imgcodecs模块中,而不在highgui中,就像在 OpenCV 2.x 中一样。
提示
随着几个函数和声明移入 OpenCV 3.0,由于链接器未找到一个或多个声明(符号和/或函数),可能会出现一些编译错误。 为了弄清楚符号的定义位置(*.hpp)和要链接的库,我们建议使用 Qt Creator IDE 进行以下技巧:
将#include 声明添加到代码中。 用鼠标光标在符号或函数上按F2功能键; 这将打开*.hpp文件,在其中声明了符号或函数。
读取输入图像文件后,请检查操作是否成功。 此检查是通过in_image.empty()成员函数完成的。 如果读取图像文件时没有错误,则会创建两个窗口分别显示输入和输出图像。 使用以下函数执行窗口的创建:
void namedWindow(const String& winname,int flags = WINDOW_AUTOSIZE )
OpenCV 窗口在程序中由明确的名称标识。 标志的定义及其说明由highgui.hpp头文件中的以下枚举给出:
enum { WINDOW_NORMAL = 0x00000000,
// the user can resize the window (no constraint)
// also use to switch a fullscreen window to a normal size
WINDOW_AUTOSIZE = 0x00000001,
// the user cannot resize the window,
// the size is constrained by the image displayed
WINDOW_OPENGL = 0x00001000, // window with opengl support
WINDOW_FULLSCREEN = 1,
WINDOW_FREERATIO = 0x00000100,
// the image expends as much as it can (no ratio constraint)
WINDOW_KEEPRATIO = 0x00000000
// the ratio of the image is respected
};
窗口的创建不会在屏幕上显示任何内容。 在窗口中显示图像的函数(属于highgui模块)是:
void imshow(const String& winname, InputArray mat)
如果使用WINDOW_AUTOSIZE标志创建了窗口(winname),则图像(mat)将以其原始尺寸显示为。
在showImage示例中,第二个窗口显示了输入图像的灰度副本。 要将彩色图像转换为灰度图像,请使用imgproc模块中的cvtColor函数。 该函数实际上可以用于更改图像颜色空间。
程序中创建的任何窗口均可调整大小并从其默认设置移动。 当不再需要任何窗口时,应将其销毁以释放其资源。 像示例中一样,这种资源释放是在程序结束时隐式完成的。
进入固有循环的事件处理
如果我们在窗口上显示图像后没有做任何其他事情,令人惊讶的是,该图像将根本不会显示。 在窗口上显示图像后,我们应该开始循环以获取和处理与用户与窗口交互有关的事件。 该任务由以下函数(从highgui模块中)执行:
int waitKey(int delay=0)
此函数会等待一个毫秒数的按键(delay > 0),以返回按键的代码;如果延迟在没有按键的情况下结束,则将返回-1。 如果delay为0或负数,则该函数将一直等待直到按下某个键。
注意
请记住,waitKey函数仅在至少存在一个已创建且处于活动状态的窗口时才起作用。
写入图像文件
imgcodecs模块中的另一个重要函数是:
bool imwrite(const String& filename, InputArray img, const vector<int>& params=vector<int>())
此函数将图像(img)保存到文件(filename)中,作为第三个可选参数,它是指定编解码器参数的属性值对的向量(将其保留为空以使用默认值)。 编解码器由文件扩展名确定。
注意
有关编解码器属性的详细列表,请查看这个页面上的imgcodecs.hpp头文件和 OpenCV API 参考。
读写视频文件
视频处理的不是运动图像,而是静止图像。 视频源可以是专用摄像机,网络摄像机,视频文件或图像文件序列。 在 OpenCV 中,VideoCapture和VideoWriter类提供了易于使用的 C++ API,用于捕获和记录视频处理中涉及的任务。
示例代码
recVideo示例是一小段代码,您可以在其中看到如何使用默认相机作为捕获设备来抓取帧,对其进行边缘检测并将其保存为新的帧。 文件。 此外,还创建了两个窗口,以同时显示原始帧和已处理的帧。 示例代码为:
#include 在此示例中,以下函数值得快速回顾:
-
double VideoCapture::get(int propId):这将返回VideoCapture对象的指定属性的值。videoio.hpp头文件包含基于 DC1394(IEEE 1394 数码相机规格)的属性的完整列表。 -
static int VideoWriter::fourcc(char c1, char c2, char c3, char c4):这会将四个字符连接到一个 fourcc 代码。 在示例中,MSVC 代表 Microsoft Video(仅适用于 Windows)。 有效的 fourcc 代码列表发布在这个页面上。 -
bool VideoWriter::isOpened():如果用于写入视频的对象已成功初始化,则返回true。 例如,使用不正确的编解码器会产生错误。提示
要小心; 系统中有效的 fourcc 代码取决于本地安装的编解码器。 要了解本地系统中已安装的 fourcc 编解码器,我们建议使用开源工具 MediaInfo,该工具可在这个页面上的许多平台上使用。
-
VideoCapture& VideoCapture::operator>>(Mat& image):抓取,解码并返回下一帧。 此方法具有等效的bool VideoCapture::read(OutputArray image)函数。 可以使用它而不是使用VideoCapture::grab()函数,然后使用VideoCapture::retrieve()。 -
VideoWriter& VideoWriter::operator<<(const Mat& image):这将写入下一帧。 这种方法等效void VideoWriter::write(const Mat& image)函数。在此示例中,存在一个读取/写入循环,其中窗口事件也被获取和处理。
waitKey(1000/fps)函数调用负责此工作; 但是,在这种情况下,1000/fps表示返回外部循环之前要等待的毫秒数。 尽管不精确,但可以为记录的视频获得每秒帧的近似量度。 -
void VideoCapture::release():这会释放视频文件或捕获设备。 尽管在此示例中不是明确必需的,但我们将其包括在内以说明其用法。
用户交互工具
在前面的部分中,我们解释了如何创建(namedWindow)窗口以显示(imshow)图像和获取/处理事件(waitKey)。 我们提供的示例向您展示了一种非常简单的方法,用于用户通过键盘与 OpenCV 应用进行交互。 waitKey函数返回在超时之前按下的键的代码。
幸运的是,OpenCV 提供了更灵活的用户交互方式,例如轨迹栏和鼠标交互,可以与某些绘图函数结合使用,以提供更丰富的用户体验。 而且,如果 OpenCV 是在 Qt 支持下(CMake 的WITH_QT选项)在本地编译的,则可以使用一组新功能来编写更好的 UI。
在本节中,我们将快速回顾在具有 Qt 支持的 OpenCV 项目中对用户界面进行编程的可用功能。 我们使用下一个名为showUI的示例来说明有关 OpenCV UI 支持的内容。
该示例在窗口中向您显示了彩色图像,说明了如何使用一些基本元素来丰富用户交互。 以下屏幕快照显示了在示例中创建的 UI 元素:
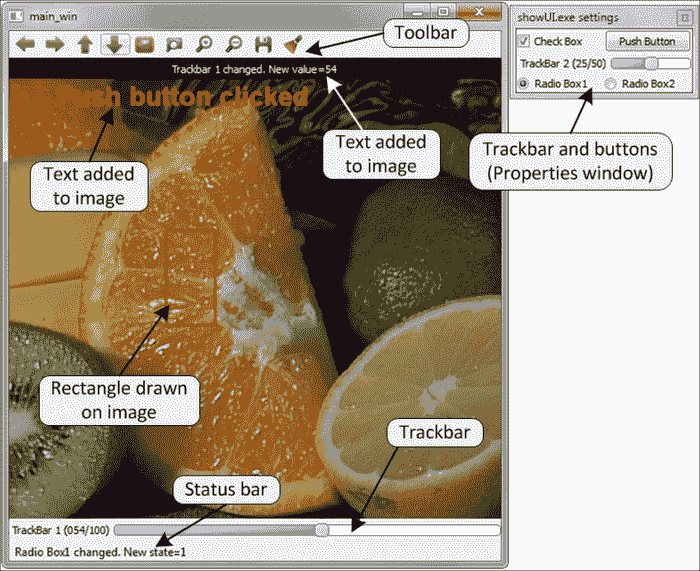
showUI示例的输出窗口
showUI示例的源代码(没有回调函数)如下:
#include 使用 Qt 支持构建 OpenCV 时,每个通过highgui模块创建的窗口都会显示默认的工具栏(参见上图),并具有(从左到右)用于平移,缩放,保存, 并打开属性窗口。
除了上述工具栏(仅 Qt 可用)之外,在接下来的小节中,我们将注释示例中创建的不同 UI 元素以及实现它们的代码。
轨迹栏
轨迹栏是在指定窗口(winname)中使用createTrackbar(const String& trackbarname, const String& winname, int* value, int count, TrackbarCallback onChange=0, void* userdata=0)函数创建的,具有链接的整数值(value),最大值(count)和可选值的滑块更改时将调用回调函数(onChange),以及回调函数的参数(userdata)。 回调函数本身有两个参数:value(由滑块选择)和一个指向userdata的指针(可选)。在 Qt 支持下,如果未指定窗口,则是属性窗口。 在showUI示例中,我们创建了两个跟踪栏:第一个在主窗口中,第二个在属性窗口中。 跟踪栏回调的代码为:
void tb1_Callback(int value, void *) {
sprintf(msg, "Trackbar 1 changed. New value=%d", value);
displayOverlay(main_win, msg);
return;
}
void tb2_Callback(int value, void *) {
sprintf(msg, "Trackbar 2 changed. New value=%d", value);
displayStatusBar(main_win, msg, 1000);
return;
}
鼠标交互
始终会生成鼠标事件,因此,用户会与进行鼠标交互(移动和单击)。 通过设置适当的处理器或回调函数,可以实现诸如选择,拖放等操作。 回调函数(onMouse)通过指定窗口(winname)和可选参数(userdata)中的setMouseCallback(const String& winname, MouseCallback onMouse, void* userdata=0 )函数启用。
处理鼠标事件的回调函数的源代码为:
void cbMouse(int event, int x, int y, int flags, void*) {
// Static vars hold values between calls
static Point p1, p2;
static bool p2set = false;
// Left mouse button pressed
if (event == EVENT_LBUTTONDOWN) {
p1 = Point(x, y); // Set orig. point
p2set = false;
} else if (event == EVENT_MOUSEMOVE &&
flags == EVENT_FLAG_LBUTTON) {
// Check moving mouse and left button down
// Check out bounds
if (x > orig_img.size().width)
x = orig_img.size().width;
else if (x < 0)
x = 0;
// Check out bounds
if (y > orig_img.size().height)
y = orig_img.size().height;
else if (y < 0)
y = 0;
p2 = Point(x, y); // Set final point
p2set = true;
// Copy orig. to temp. image
orig_img.copyTo(tmp_img);
// Draws rectangle
rectangle(tmp_img, p1, p2, Scalar(0, 0 ,255));
// Draw temporal image with rect.
imshow(main_win, tmp_img);
} else if (event == EVENT_LBUTTONUP
&& p2set) {
// Check if left button is released
// and selected an area
// Set subarray on orig. image
// with selected rectangle
Mat submat = orig_img(Rect(p1, p2));
// Here some processing for the submatrix
//...
// Mark the boundaries of selected rectangle
rectangle(orig_img, p1, p2, Scalar(0, 0, 255), 2);
imshow("main_win", orig_img);
}
return;
}
在showUI示例中,鼠标事件用于通过回调函数(cbMouse)进行控制,即通过在矩形区域周围绘制矩形来选择矩形区域。 在示例中,此函数声明为void cbMouse(int event, int x, int y, int flags, void*),参数是事件发生的指针的位置(x,y),事件发生的条件(flags),并且可选地, userdata。
注意
可用的事件,标志及其相应的定义符号可以在highgui.hpp头文件中找到。
按钮
OpenCV(仅具有 Qt 支持)允许创建三种类型的按钮:复选框(QT_CHECKBOX),单选框(QT_RADIOBOX)和按钮(QT_PUSH_BUTTON)。 这些类型的按钮可分别用于设置选项,设置排他选项以及在按下按钮时执行操作。 这三个属性是通过createButton(const String& button_name, ButtonCallback on_change, void* userdata=0, int type=QT_PUSH_BUTTON, bool init_state=false )函数在此窗口中最后一个跟踪栏之后的按钮栏中排列的属性窗口中创建的。 按钮的参数是其名称(button_name),在状态更改时调用的回调函数(on_change),还可以是回调的参数(userdate),按钮的类型(type )以及按钮的初始状态(init_state)。
接下来,我们向您展示示例中与按钮对应的回调函数的源代码:
void checkboxCallBack(int state, void *) {
sprintf(msg, "Check box changed. New state=%d", state);
displayStatusBar(main_win, msg);
return;
}
void radioboxCallBack(int state, void *id) {
// Id of the radio box passed to the callBack
sprintf(msg, "%s changed. New state=%d",
(char *)id, state);
displayStatusBar(main_win, msg);
return;
}
void pushbuttonCallBack(int, void *font) {
// Add text to the image
addText(orig_img, "Push button clicked",
Point(50,50), *((QtFont *)font));
imshow(main_win, orig_img); // Shows original image
return;
}
按钮的回调函数获得两个参数:其状态和(可选)指向用户数据的指针。 在showUI示例中,我们向您展示如何传递一个整数(radioboxCallBack(int state, void *id))来标识按钮和一个更复杂的对象(pushbuttonCallBack(int, void *font))。
绘制和显示文本
将某些图像处理的结果传达给用户的一种非常有效的方法是通过在正在处理的图形上绘制形状或/和显示文本。 通过imgproc模块,OpenCV 提供了一些便捷的功能来完成诸如放置文本,绘图线,圆,椭圆,矩形,多边形等任务。showUI示例说明了如何在图像上选择矩形区域并绘制矩形以标记所选区域。 以下函数在图像上绘制(img),该图像由两个点(p1,p2)定义,并带有指定的颜色和其他可选参数作为厚度(对于填充形状为负)和线型:
void rectangle(InputOutputArray img, Point pt1, Point pt2,const Scalar& color, int thickness=1,int lineType=LINE_8, int shift=0 )
除了形状的图形支持之外,imgproc模块还提供了一个函数,可以使用以下函数在图像上放置文本:
void putText(InputOutputArray img, const String& text, Point org, int fontFace, double fontScale, Scalar color, int thickness=1, int lineType=LINE_8, bool bottomLeftOrigin=false )
注意
可以在core.hpp头文件中检查文本的可用字体。
在highgui模块中,对 Qt 的支持增加了一些其他方法来在 OpenCV 应用的主窗口上显示文本:
- 图像上方的文本:我们使用
addText(const Mat& img, const String& text, Point org, const QtFont& font)函数获得此结果。 此函数允许您使用先前用fontQt(const String& nameFont, int pointSize=-1, Scalar color=Scalar::all(0), int weight=QT_FONT_NORMAL, int style=QT_STYLE_NORMAL, int spacing=0)函数创建的字体为显示的文本选择起点。 在showUI示例中,此函数用于在单击按钮时在图像上放置文本,从而在回调函数中调用addText函数。 - 状态栏上的文本:使用
displayStatusBar(const String& winname, const String& text, int delayms=0 )函数,在状态栏上中显示由最后一个参数(delayms)给出的毫秒的文本。 在showUI示例中,当属性窗口的按钮和轨迹栏更改其状态时,此函数(在回调函数中)用于显示内容丰富的文本。 - 覆盖在图像上的文本:使用
displayOverlay(const String& winname, const String& text, int delayms=0)函数,将显示在图像上的文本显示最后一个参数给出的毫秒数。 在showUI示例中,当主窗口跟踪栏更改其值时,此函数(在回调函数中)用于显示内容丰富的文本。
总结
在本章中,您快速了解了 OpenCV 库及其模块的主要用途。 您了解了如何在本地系统中编译,安装和使用该库来开发具有 Qt 支持的 C++ OpenCV 应用的基础。 为了开发自己的软件,我们解释了如何从免费的 Qt Creator IDE 和 GNU 编译器工具包开始。
首先,本章提供了完整的代码示例。 这些示例向您展示了如何读写图像和视频。 最后,本章为您提供了一个示例,该示例在 OpenCV 程序中显示一些易于实现的用户界面功能,例如轨迹栏,按钮,在图像上放置文本,绘制形状等。
下一章将致力于建立主要的图像处理工具和任务,这些工具和任务将为其余各章奠定基础。
二、建立图像处理工具
本章介绍将在后续章节中使用的主要数据结构和基本过程:
- 图片类型
- 像素存取
- 图像的基本操作
- 直方图
这些是我们必须对图像执行的一些最常见的操作。 此处介绍的大多数功能都在库的核心模块中。
基本数据类型
OpenCV 中的基本数据类型为Mat,因为它用于存储图像。 基本上,图像存储为标题和包含像素数据的存储区。 图像具有多个通道。 灰度图像具有单个通道,而彩色图像通常具有三个用于红色,绿色和蓝色分量的通道(尽管 OpenCV 以相反的顺序存储它们,即蓝色,绿色和红色)。 也可以使用第四个透明度(alpha)通道。 可以使用img.channels()检索img图像的通道数。
图像中的每个像素都使用许多位存储。 这称为图像深度。 对于灰度图像,像素通常以 8 位存储,因此允许 256 个灰度级(整数值 0 到 255)。 对于彩色图像,每个像素存储在三个字节中,每个彩色通道存储一个字节。 在某些操作中,有必要以浮点格式存储像素。 可以使用img.depth()获得图像深度,并且返回的值为:
CV_8U,8 位无符号整数(0..255)CV_8S,8 位有符号整数(-128..127)CV_16U,16 位无符号整数(0..65,535)CV_16S,16 位有符号整数(-32,768..32,767)CV_32S,32 位有符号整数(-2,147,483,648..2,147,483,647)CV_32F,32 位浮点数CV_64F,64 位浮点数
请注意,对于灰度图像和彩色图像,最常见的图像深度均为CV_8U。 可以使用convertTo方法从一种深度转换为另一种深度:
Mat img = imread("lena.png", IMREAD_GRAYSCALE);
Mat fp;
img.convertTo(fp,CV_32F);
在浮点图像上执行运算是很常见的(也就是说,像素值是数学运算的结果)。 如果使用imshow()显示该图像,则将看不到任何有意义的内容。 在这种情况下,我们必须将像素转换为0..255的整数范围。 convertTo函数实现了线性变换,并具有两个附加参数alpha和beta,分别代表比例因子和要添加的增量值。 这意味着每个像素p都将转换为:
newp = alpha * p + beta
这可用于正确显示浮点图像。 假设img图像具有m和M最小值和最大值(请参阅下面的代码,以了解如何获得这些值),我们将使用此值:
Mat m1 = Mat(100, 100, CV_32FC1);
randu(m1, 0, 1e6); // random values between 0 and 1e6
imshow("original", m1);
double minRange,MaxRange;
Point mLoc,MLoc;
minMaxLoc(m1,&minRange,&MaxRange,&mLoc,&MLoc);
Mat img1;
m1.convertTo(img1,CV_8U,255.0/(MaxRange-minRange),-255.0/minRange);
imshow("result", img1);
This code maps the range of the result image values to the range 0-255. The following image shows you the result of running the code:

convertTo的结果(请注意,左侧图像显示为白色)
图像大小可以通过row和cols属性获得。 还有一个size属性可以检索这两个属性:
MatSize s = img.size;
int r=l[0];
int c=l[1];
除了图像本身外,其他数据类型也很常见。 请参考下表:
| 类型 | 类型关键字 | 示例 |
|---|---|---|
| (小)向量 | VecAB,其中A可以是 2、3、4、5 或 6,B可以是b,s,i,f或d |
Vec3b rgb; rgb[0]=255; |
| (最多 4 个)标量 | Scalar |
Scalar a; a[0]=0; a[1]=0; |
| 点 | PointAB,其中A可以是2或3,而B可以是i,f或d |
Point3d p; p.x=0; p.y=0; p.z=0; |
| 尺寸 | Size |
Size s; s.width=30; s.height=40; |
| 长方形 | Rect |
Rect r; r.x=r.y=0; r.width=r.height=100; |
其中一些类型具有其他操作。 例如,我们可以检查一个点是否位于矩形内:
p.inside(r)
p和r自变量分别是(二维)点和矩形。 请注意,在任何情况下,上表都不是完整的。 OpenCV 提供了更多支持结构以及相关方法。
像素级访问
要处理图像,我们必须知道如何独立访问每个像素。 OpenCV 提供了许多方法来执行此操作。 在本节中,我们介绍两种方法; 第一个对于程序员来说很容易,而第二个效率更高。
第一种方法使用at<>模板函数。 为了使用它,我们必须指定矩阵像元的类型,例如下面的简短示例:
Mat src1 = imread("lena.jpg", IMREAD_GRAYSCALE);
uchar pixel1=src1.at<uchar>(0,0);
cout << "Value of pixel (0,0): " << (unsigned int)pixel1 << endl;
Mat src2 = imread("lena.jpg", IMREAD_COLOR);
Vec3b pixel2 = src2.at<Vec3b>(0,0);
cout << "B component of pixel (0,0):" << (unsigned int)pixel2[0] << endl;
该示例读取灰度和彩色图像,并访问(0, 0)处的第一个像素。 在第一种情况下,像素类型为unsigned char(即uchar)。 在第二种情况下,当以全色读取图像时,我们必须使用Vec3b类型,它是指未签名字符的三元组。 当然,at<>函数也可以出现在分配的左侧,即更改像素的值。
以下是另一个简短示例,其中使用此方法将浮点矩阵初始化为 Pi 值:
Mat M(200, 200, CV_64F);
for(int i = 0; i < M.rows; i++)
for(int j = 0; j < M.cols; j++)
M.at<double>(i,j)=CV_PI;
请注意,at<>方法不是很有效,因为它必须从像素行和列中计算出确切的存储位置。 当我们逐像素处理整个图像时,这可能会非常耗时。 第二种方法使用ptr函数,该函数返回指向特定图像行的指针。 以下代码段获取彩色图像中每个像素的像素值:
uchar R, G, B;
for (int i = 0; i < src2.rows; i++)
{
Vec3b* pixrow = src2.ptr<Vec3b>(i);
for (int j = 0; j < src2.cols; j++)
{
B = pixrow[j][0];
G = pixrow[j][1];
R = pixrow[j][2];
}
}
在上面的示例中,ptr是,用于获取指向每一行中第一个像素的指针。 使用此指针,我们现在可以访问最内层循环中的每一列。
测量时间
处理图像需要花费时间(比处理 1D 数据要花费的时间要多得多)。 通常,处理时间是决定解决方案是否可行的关键因素。 OpenCV 提供了两个测量经过时间的函数:getTickCount()和getTickFrequency()。 您将像这样使用它们:
double t0 = (double)getTickCount();
// your stuff here ...
elapsed = ((double)getTickCount() – t0)/getTickFrequency();
在这里,elapsed以秒为单位。
图像的常用操作
下表总结了最典型的图像操作:
设定矩阵值:
img.setTo(0); // for 1-channel img
img.setTo(Scalar(B,G,R); // 3-channel img
MATLAB 样式的矩阵初始化:
Mat m1 = Mat::eye(100, 100, CV_64F);
Mat m3 = Mat::zeros(100, 100, CV_8UC1);
Mat m2 = Mat::ones(100, 100, CV_8UC1)*255;
随机初始化:
Mat m1 = Mat(100, 100, CV_8UC1);
randu(m1, 0, 255);
创建矩阵的副本:
Mat img1 = img.clone();
创建矩阵的副本(使用遮罩):
img.copy(img1, mask);
引用子矩阵(不复制数据):
Mat img1 = img (Range(r1,r2),Range(c1,c2));
图像裁剪:
Rect roi(r1,c2, width, height);
Mat img1 = img(roi).clone(); // data copied
调整图片大小:
resize(img, imag1, Size(), 0.5, 0.5); // decimate by a factor of 2
翻转图片:
flip(imgsrc, imgdst, code);
// code=0 => vertical flipping
// code>0 => horizontal flipping
// code<0 => vertical & horizontal flipping
分割通道:
Mat channel[3];
split(img, channel);
imshow("B", channel[0]); // show blue
合并通道:
merge(channel,img);
计算非零像素:
int nz = countNonZero(img);
最小和最大:
double m,M;
Point mLoc,MLoc; minMaxLoc(img,&m,&M,&mLoc,&MLoc);
平均像素值:
Scalar m, stdd;
meanStdDev(img, m, stdd);
uint mean_pxl = mean.val[0];
检查图像数据是否为空:
If (img.empty())
cout << "couldn't load image";
算术运算
算术运算符已重载。 这意味着我们可以像在此示例中一样对Mat图像进行操作:
imgblend = 0.2*img1 + 0.8*img2;
在 OpenCV 中,运算的结果值受所谓的饱和算法的影响。 这意味着最终值实际上是0..255范围内最接近的整数。
使用掩码时,按位运算bitwise_and(),bitwise_or(),bitwise_xor()和bitwise_not()可能非常有用。 遮罩是二进制图像,指示要在其中执行操作的像素(而不是整个图像)。 以下bitwise_and示例向您展示了如何使用 AND 运算来裁剪图像的一部分:
#include 阅读并显示输入的图像后,我们通过绘制一个填充的白色圆圈来创建遮罩。 在 AND 操作中,使用此掩码。 逻辑运算仅适用于掩码值不为零的像素; 其他像素不受影响。 最后,在此示例中,我们用白色填充结果图像的外部(即,圆的外部)。 使用前面说明的像素访问方法之一完成此操作。 在以下屏幕截图中查看生成的图像:

bitwise_and示例的结果
接下来,显示另一个很酷的示例,其中我们估计 Pi 的值。 让我们考虑一个正方形及其封闭的圆:

它们的面积由下式给出:
![]()
![]()
由此,我们有:

假设我们的边长未知的正方形图像和一个封闭的圆。 我们可以通过在图像中的随机位置绘制许多像素并计算落入封闭圆内的像素来估计封闭圆的面积。 另一方面,正方形的面积估计为绘制的像素总数。 这样一来,您可以使用前面的公式估计 Pi 的值。
以下算法对此进行了模拟:
- 在黑色正方形图像上,绘制一个实心白色封闭的圆圈。
- 在另一个黑色正方形图像(相同尺寸)上,在随机位置上绘制大量像素。
- 在两个图像之间执行“与”运算,并计算结果图像中的非零像素。
- 使用等式估计 Pi。
以下是EstimatePi示例的代码:
#include 程序完全遵循上述算法。 请注意,我们使用countNonZero函数对非零(在这种情况下为白色)像素进行计数。 对于npixels=8000,估计为 3.125。 npixels的值越大,估计越好。

EstimatePi示例的输出
数据持久化
在 OpenCV 中,除了读取和写入图像和视频的特定功能外,还有一种更通用的保存/加载数据的方法。 这称为数据持久性:可以将程序中对象和变量的值记录(序列化)在磁盘上。 这对于保存结果和加载配置数据非常有用。 主类的名称恰当地命名为FileStorage,它表示磁盘上的文件。 数据实际上以 XML 或 YAML 格式存储。
这些是写入数据时涉及的步骤:
- 调用
FileStorage构造器,并传递文件名和带有FileStorage::WRITE值的标志。 数据格式由文件扩展名定义(即.xml,.yml或.yaml)。 - 使用
<<操作符将数据写入文件。 数据通常写为字符串值对。 - 使用
release方法关闭文件。
读取数据要求您执行以下步骤:
- 调用
FileStorage构造器,并传递文件名和带有FileStorage::READ值的标志。 - 使用
[]或>>操作符从文件中读取数据。 - 使用
release方法关闭文件。
以下示例使用数据持久性来保存和加载跟踪栏值。
#include 提示
使用 Qt 支持编译 OpenCV 后,可以使用saveWindowParameters()函数保存窗口属性,包括轨迹栏值。
一旦跟踪栏用于控制整数值,就可以将其简单地添加到原始图像中,使其更明亮。 程序启动时读取该值(该值首次为 0),并在程序正常退出时保存。 注意,显示了两种等效的方法来读取tb1_值变量的值。 config.xml文件的内容是:
<?xml version="1.0"?>
<opencv_storage>
<tb1_value>112</tb1_value>
</opencv_storage>
直方图
一旦使用数据类型定义了图像,并且我们能够访问其灰度值(即像素),我们可能希望获得不同灰度的概率密度函数,称为直方图 。 图像直方图表示图像中各种灰度等级的出现频率。 可以对直方图进行建模,以便图像可以更改其对比度级别。 这被称为直方图均衡。 直方图建模是一种通过对比度变化来增强图像的强大技术。 均衡允许较低对比度的图像区域获得较高的对比度。 下图显示了均衡图像及其直方图的示例:
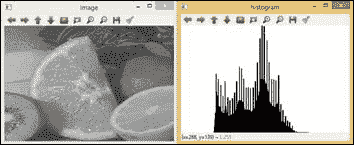
均衡图像直方图的示例
在 OpenCV 中,可以通过void calcHist函数计算图像直方图,并通过void equalizeHist函数进行直方图均衡。
图像直方图计算由十个参数定义:void calcHist(const Mat* images,int nimages,const int* channels,InputArray mask,OutputArray hist,int dims,const int* histSize,const float** ranges,bool uniform=true和bool accumulate=false) 。
const Mat* images:第一个参数是来自集合的第一个图像的地址。 这可用于处理一批图像。int nimages:第二个参数是源图像的数量。const int* channels:第三个输入参数是用于计算直方图的通道列表。 通道数从 0 到 2。InputArray mask:这是一个可选的遮罩,用于指示直方图中计数的图像像素。OutputArray hist:第五个参数是输出直方图。int dims:此参数允许您指示直方图的尺寸。const int* histSize:此参数是每个维度中直方图大小的数组。const float** ranges:此参数是每个维度中直方图箱子边界的维度数组。bool uniform=true:默认情况下,布尔值为true。 它表示直方图是均匀的。bool accumulate=false:默认情况下,布尔值为false。 它表明直方图是非累积的。
直方图均衡化仅需要两个参数void equalizeHist(InputArray src, OutputArray dst)。 第一个参数是输入图像,第二个参数是直方图均等的输出图像。
可以计算多个输入图像的直方图。 这使您可以比较图像直方图并计算多个图像的联合直方图。 可以使用void compareHist(InputArray histImage1, InputArray histImage2, method)函数对histImage1和histImage2这两个图像直方图进行比较。 Method度量用于计算两个直方图之间的匹配。 OpenCV 中实现了四个度量,即相关性(CV_COMP_CORREL),卡方(CV_COMP_CHISQR),交点或最小距离(CV_COMP_INTERSECT)和 Bhattacharyya 距离(CV_COMP_BHATTACHARYYA)。
可以计算同一彩色图像的一个以上通道的直方图。 这要归功于第三个参数。
以下各节向您展示和用于颜色直方图计算的两个示例代码(ColourImageEqualizeHist)和比较ColourImageComparison。 在ColourImageComparison示例中,在ColourImageEqualizeHist中,还显示了如何计算两个通道的直方图均衡以及 2D 直方图,即色调(H)和饱和度(S)。
示例代码
以下ColourImageEqualizeHist示例向您展示如何均衡彩色图像并同时显示每个通道的直方图。 RGB 图像中每个颜色通道的直方图计算均使用histogramcalculation(InputArray Imagesrc, OutputArray histoImage)函数完成。 为此,将彩色图像分为通道:R,G 和 B。直方图均衡化也应用于每个通道,然后合并以形成均衡的彩色图像:
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include 示例创建四个带有以下内容的窗口:
- 源图像:这是下图中左上角显示的。
- 均匀彩色图像:这是下图中右上角显示的。
- 三个通道的直方图:对于源图像,此处 R 为红色,G 为绿色,B 为蓝色。 下图的左下角显示了该内容。
- 均衡图像的 RGB 通道的直方图:在下图右下角中显示。 该图显示了由于均衡过程如何延长了 R,G 和 B 的最频繁强度值。
下图显示了该算法的结果:
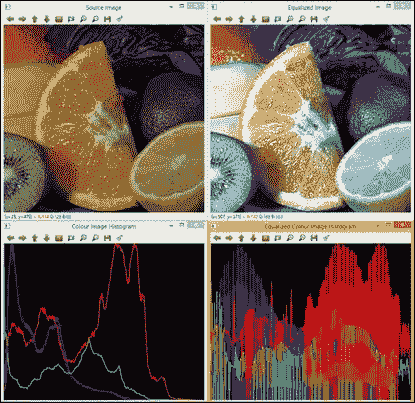
示例代码
以下ColourImageComparison示例显示了如何从同一彩色图像计算由两个通道组成的 2D 直方图。 示例代码还通过直方图匹配在原始图像和均衡图像之间执行比较。 用于匹配的度量是前面已经提到的四个度量,即“相关”,“卡方”,“最小距离”和“Bhattacharyya 距离”。 H 和 S 颜色通道的 2D 直方图计算是通过histogram2Dcalculation(InputArray Imagesrc, OutputArray histo2D)函数完成的。 为了执行直方图比较,已经为 RGB 图像计算了标准化的 1D 直方图。 为了比较直方图,已将归一化。 这是在histogramRGcalculation(InputArray Imagesrc, OutputArray histo)中完成的:
void histogram2Dcalculation(const Mat &src, Mat &histo2D)
{
Mat hsv;
cvtColor(src, hsv, CV_BGR2HSV);
// Quantize the hue to 30 -255 levels
// and the saturation to 32 - 255 levels
int hbins = 255, sbins = 255;
int histSize[] = {hbins, sbins};
// hue varies from 0 to 179, see cvtColor
float hranges[] = { 0, 180 };
// saturation varies from 0 (black-gray-white) to
// 255 (pure spectrum color)
float sranges[] = { 0, 256 };
const float* ranges[] = { hranges, sranges };
MatND hist, hist2;
// we compute the histogram from the 0-th and 1-st channels
int channels[] = {0, 1};
calcHist( &hsv, 1, channels, Mat(), hist, 1, histSize, ranges, true, false );
double maxVal=0;
minMaxLoc(hist, 0, &maxVal, 0, 0);
int scale = 1;
Mat histImg = Mat::zeros(sbins*scale, hbins*scale, CV_8UC3);
for( int h = 0; h < hbins; h++ )
for( int s = 0; s < sbins; s++ )
{
float binVal = hist.at<float>(h, s);
int intensity = cvRound(binVal*255/maxVal);
rectangle( histImg, Point(h*scale, s*scale),
Point( (h+1)*scale - 1, (s+1)*scale - 1),
Scalar::all(intensity),
CV_FILLED );
}
histo2D=histImg;
}
void histogramRGcalculation(const Mat &src, Mat &histoRG)
{
// Using 50 bins for red and 60 for green
int r_bins = 50; int g_bins = 60;
int histSize[] = { r_bins, g_bins };
// red varies from 0 to 255, green from 0 to 255
float r_ranges[] = { 0, 255 };
float g_ranges[] = { 0, 255 };
const float* ranges[] = { r_ranges, g_ranges };
// Use the o-th and 1-st channels
int channels[] = { 0, 1 };
// Histograms
MatND hist_base;
// Calculate the histograms for the HSV images
calcHist( &src, 1, channels, Mat(), hist_base, 2, histSize, ranges, true, false );
normalize( hist_base, hist_base, 0, 1, NORM_MINMAX, -1, Mat() );
histoRG=hist_base;
}
int main( int argc, char *argv[])
{
Mat src, imageq;
Mat histImg, histImgeq;
Mat histHSorg, histHSeq;
// Read original image
src = imread( "fruits.jpg");
if(! src.data )
{ printf("Error imagen\n"); exit(1); }
// Separate the image in 3 places ( B, G and R )
vector<Mat> bgr_planes;
split( src, bgr_planes );
// Display results
namedWindow("Source image", 0 );
imshow( "Source image", src );
// Calculate the histogram of the source image
histogram2Dcalculation(src, histImg);
// Display the histogram for each colour channel
imshow("H-S Histogram", histImg );
// Equalized Image
// Apply Histogram Equalization to each channel
equalizeHist(bgr_planes[0], bgr_planes[0] );
equalizeHist(bgr_planes[1], bgr_planes[1] );
equalizeHist(bgr_planes[2], bgr_planes[2] );
// Merge the equalized image channels into the equalized image
merge(bgr_planes, imageq );
// Display Equalized Image
namedWindow("Equalized Image", 0 );
imshow("Equalized Image", imageq );
// Calculate the 2D histogram for H and S channels
histogram2Dcalculation(imageq, histImgeq);
// Display the 2D Histogram
imshow( "H-S Histogram Equalized", histImgeq );
histogramRGcalculation(src, histHSorg);
histogramRGcalculation(imageq, histHSeq);
/// Apply the histogram comparison methods
for( int i = 0; i < 4; i++ )
{
int compare_method = i;
double orig_orig = compareHist( histHSorg, histHSorg, compare_method );
double orig_equ = compareHist( histHSorg, histHSeq, compare_method );
printf( " Method [%d] Original-Original, Original-Equalized : %f, %f \n", i, orig_orig, orig_equ );
}
printf( "Done \n" );
waitKey();
}
示例使用源图像,均等的彩色图像以及 2 个原始图像和均化图像的 H 和 S 通道的 2D 直方图创建四个窗口。 该算法还显示从原始 RGB 图像直方图与其自身以及与均衡后的 RGB 图像进行比较所获得的四个数值匹配参数。 对于相关和相交方法,度量越高,匹配越精确。 对于卡方距离和 Bhattacharyya 距离,结果越少,匹配越好。 下图显示了ColourImageComparison算法的输出:

最后,您可以参考第 3 章,“校正和增强图像”以及其中的示例,以涵盖此广泛主题的基本方面,例如通过直方图建模来增强图像。
注意
有关更多信息,请参阅OpenCV Essentials, Deniz O., Fernández M.M., Vállez N., Bueno G., Serrano I., Patón .A., Salido J. by Packt Publishing。
总结
本章涵盖并建立了应用计算机视觉中使用的图像处理方法的基础。 图像处理通常是进一步实现计算机视觉应用的第一步,因此,这里已涉及到:基本数据类型,像素级访问,图像的常规操作,算术运算,数据持久性和直方图。
您还可以参考 Packt Publishing 的《OpenCV Essentials》的第 3 章,“校正和增强图像”,以涵盖该广泛主题的其他重要方面,例如图像增强,通过滤波的图像恢复以及几何校正。
下一章将介绍通过平滑,锐化,图像分辨率分析,形态和几何变换,修复和去噪来校正和增强图像的图像处理的其他方面。
三、校正和增强图像
本章介绍了图像增强和校正的方法。 有时,有必要减少图像中的噪点或强调或抑制图像中的某些细节。 这些过程通常是通过修改像素值,对它们或它们的本地邻居执行一些操作来执行的。 根据定义,图像增强操作用于改善重要的图像细节。 增强操作包括降噪,平滑和边缘增强。 另一方面,图像校正尝试恢复损坏的图像。 在 OpenCV 中,imgproc模块包含图像处理功能。
在本章中,我们将介绍:
- 图像过滤。 这包括图像平滑,图像锐化以及使用图像金字塔。
- 应用形态学操作,例如扩张,腐蚀,打开或关闭。
- 几何变换(仿射和透视变换)。
- 修复,用于重建图像的受损部分。
- 去噪,这对于减少图像捕获设备产生的图像噪声是必需的。
图像过滤
图像过滤是修改或增强图像的过程。 强调某些特征或去除图像中的其他特征是图像过滤的示例。 过滤是一种邻居操作。 邻域是所选像素周围的一组像素。 图像滤波通过对附近像素的像素值执行某些操作来确定位于位置(x, y)的特定像素的输出值。
OpenCV 为常见的图像处理操作(例如平滑或锐化)提供几种过滤功能。
平滑
平滑,也称为“模糊”的,是一种图像处理操作,除其他用途外,通常用于减少噪声。 通过对图像应用线性过滤器来执行平滑操作。 然后,将位置(x[i], y[j])处的输出的像素值计算为位置(x[i], y[j])处的输入像素值及其附近的加权和。 线性运算中像素的权重通常存储在称为核的矩阵中。 因此,过滤器可以表示为系数的滑动窗口。

像素邻域的表示
假设K为核,I和O分别为输入图像和输出图像。 然后,在(i, j)处的每个输出像素值计算如下:
![]()
中值,高斯和双边是最常用的 OpenCV 平滑过滤器。 中值滤波非常适合消除椒盐或斑点噪声,而高斯滤波则是边缘检测的更好的预处理步骤。 另一方面,双边滤波是一种在尊重强边缘的同时平滑图像的好技术。
为此,OpenCV 中包含的函数是:
-
void boxFilter(InputArray src, OutputArray dst, int ddepth, Size ksize, Point anchor = Point(-1,-1), bool normalize = true, int borderType = BORDER_DEFAULT):这是一个盒子过滤器,其核系数相等。 使用normalize=true时,每个输出像素值都是其核邻居的平均值,所有系数均等于1 / n,其中n为元素数。 使用normalize=false时,所有系数都等于 1。src参数是输入图像,而滤波后的图像存储在dst中。ddepth参数指示输出图像深度为 -1,以使用与输入图像相同的深度。 核大小在ksize中指示。anchor点指示所谓的锚点像素的位置。 默认值(-1, -1)表示锚点位于核的中心。 最后,在borderType参数中指示边界类型的处理。 -
void GaussianBlur(InputArray src, OutputArray dst, Size ksize, double sigmaX, double sigmaY = 0, int borderType=BORDER_DEFAULT): This is done by convolving each point in thesrcinput array with a Gaussian kernel to produce thedstoutput. ThesigmaXandsigmaYparameters indicate the Gaussian kernel standard deviation in X and Y directions. IfsigmaYis zero, it is set to be equal tosigmaX, and if both are equal to zero, they are computed using the width and height given inksize.注意
卷积定义为两个函数乘积的积分,其中两个函数之一先前已被反转和移位。
-
void medianBlur(InputArray src, OutputArray dst, int ksize):这遍历图像的每个元素,并将每个像素替换为其相邻像素的中间值。 -
void bilateralFilter(InputArray src, OutputArray dst, int d, double sigmaColor, double sigmaSpace, int borderType=BORDER_DEFAULT):这类似于高斯过滤器,其中考虑了相邻像素,每个像素都分配有权重,但每个权重上都有两个分量,这与高斯过滤器使用的分量相同,而另一个考虑了相邻像素和评估像素之间的强度。 此函数需要像素邻域的直径作为参数d和sigmaColorsigmaSpace值。sigmaSpace参数的较大值表示像素邻域内的其他颜色将混合在一起,从而生成较大的半均等颜色区域,而sigmaSpace参数的较大值表示较远像素将彼此影响。 只要它们的颜色足够接近。 -
void blur(InputArray src, OutputArray dst, Size ksize, Point anchor=Point(-1,-1), int borderType=BORDER_DEFAULT): This blurs an image using the normalized box filter. It is equivalent to usingboxFilterwithnormalize = true. The kernel used in this function is:
注意
getGaussianKernel和getGaborKernel函数可以在 OpenCV 中使用以生成自定义核,然后可以将其传递给filter2D。
在所有情况下,都必须外推图像边界外不存在的像素的值。 OpenCV 允许在大多数过滤器函数中指定外推方法。 这些方法是:
BORDER_REPLICATE:此操作重复上一个已知的像素值:aaaaaa | abcdefgh | hhhhhhhBORDER_REFLECT:这反映了图像边框:fedcba | abcdefgh | hgfedcbBORDER_REFLECT_101:这将反映图像边框,而不复制边框的最后一个像素:gfedcb | abcdefgh | gfedcbaBORDER_WRAP:这将追加相对边框的值:cdefgh | abcdefgh | abcdefgBORDER_CONSTANT:这将在新边界上建立一个常数:kkkkkk | abcdefgh | kkkkkk
示例代码
平滑示例之后的向您展示了如何通过GaussianBlur和medianBlur函数加载图像并对其应用高斯和中值模糊:
#include "opencv2/opencv.hpp"
using namespace cv;
int main( int argc, char** argv )
{
// Read the source file
Mat src;
src = imread(argv[1]);
// Apply the filters
Mat dst, dst2;
GaussianBlur( src, dst, Size( 9, 9 ), 0, 0);
medianBlur( src, dst2, 9);
// Show the results
namedWindow( " ORIGINAL ", WINDOW_AUTOSIZE );
imshow( " ORIGINAL ", src );
namedWindow( " GAUSSIAN BLUR ", WINDOW_AUTOSIZE );
imshow( " GAUSSIAN BLUR ", dst );
namedWindow( " MEDIAN BLUR ", WINDOW_AUTOSIZE );
imshow( " MEDIAN BLUR ", dst2 );
waitKey();
return 0;
}
下图显示了代码的输出:

来自高斯和中值模糊变换的原始和模糊图像
锐化
锐化过滤器用于突出显示图像中的边框和其他精细细节。 它们基于一阶和二阶导数。 图像的一阶导数计算图像强度梯度的近似值,而二阶导数定义为该梯度的散度。 由于数字图像处理处理离散量(像素值),因此将一阶和二阶导数的离散版本用于锐化。
一阶导数产生较厚的图像边缘,并广泛用于边缘提取。 但是,由于二阶导数对精细细节的响应更好,因此可用于图像增强。 用于获得导数的两种流行的运算符是 Sobel 和 Laplacian。
Sobel 运算符通过以下方式计算图像I的一阶图像导数:
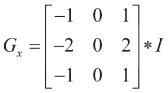

可以通过组合两个方向上的梯度近似值来获得 Sobel 梯度幅度,如下所示:
![]()
另一方面,可以将图像的离散拉普拉斯算子与以下核进行卷积:

为此,OpenCV 中包含的函数是:
void Sobel(InputArray src, OutputArray dst, int ddepth, int dx, int dy, int ksize = 3, double scale = 1, double delta = 0, int borderType = BORDER_DEFAULT):这将根据src中的图像使用 Sobel 运算符计算一阶,二阶,三阶或混合图像导数。ddepth参数指示输出图像深度,即 -1 至使用与输入图像相同的深度。 籽粒大小在ksize中指示,所需的导数阶数在dx和dy中指示。 可以使用scale建立计算得出的微分值的比例因子。 最后,在borderType参数中指示边界类型处理,并且可以在将结果存储在dst中之前将delta值添加到结果中。void Scharr(InputArray src, OutputArray dst, int ddepth, int dx, int dy, double scale = 1, double delta = 0, int borderType = BORDER_DEFAULT ):这为大小为3 x 3的核计算了一个更准确的导数。Scharr(src, dst, ddepth, dx, dy, scale, delta, borderType)等效于Sobel(src, dst, ddepth, dx, dy, CV_SCHARR, scale, delta, borderType)。void Laplacian(InputArray src, OutputArray dst, int ddepth, int ksize = 1, double scale = 1, double delta = 0, int borderType = BORDER_DEFAULT):这将计算图像的拉普拉斯算子。 除了ksize以外,所有参数均与Sobel和Scharr函数中的参数相同。 当ksize>为 1 时,它通过将使用Sobel计算的第二x和y导数相加来计算src中图像的拉普拉斯算子。 当ksize = 1时,通过用3 x 3核对图像进行滤波来计算拉普拉斯算子,该核包含 -4 为中心,0 为角,其余为 1。
注意
getDerivKernels可以在 OpenCV 中使用以生成自定义的派生核,然后可以将其传递给sepFilter2D。
示例代码
锐化示例之后的展示了如何通过Sobel和Laplacian函数从图像计算 Sobel 和 Laplacian 导数。 示例代码为:
#include "opencv2/opencv.hpp"
using namespace cv;
int main( int argc, char** argv )
{
// Read the source file
Mat src;
src = imread(argv[1]);
// Apply Sobel and Laplacian
Mat dst, dst2;
Sobel(src, dst, -1, 1, 1 );
Laplacian(src, dst2, -1 );
// Show the results
namedWindow( " ORIGINAL ", WINDOW_AUTOSIZE );
imshow( " ORIGINAL ", src );
namedWindow( " SOBEL ", WINDOW_AUTOSIZE );
imshow( " SOBEL ", dst );
namedWindow( " LAPLACIAN ", WINDOW_AUTOSIZE );
imshow( " LAPLACIAN ", dst2 );
waitKey();
return 0;
}
下图显示了代码的输出:

通过 Sobel 和 Laplacian 派生获得的轮廓
使用图像金字塔
在某些场合下,无法使用固定的图像尺寸进行操作,并且我们将需要具有不同分辨率的原始图像。 例如,在对象检测问题中,检查整个图像以尝试查找对象会花费太多时间。 在这种情况下,以较小的分辨率开始搜索对象会更有效。 这种图像集称为金字塔或 mipmap,因为如果图像从底部到顶部按从大到小的顺序排列,则与金字塔结构类型相似 。

高斯金字塔
有两种图像金字塔:高斯金字塔和拉普拉斯金字塔。
高斯金字塔
高斯金字塔是通过交替除去较低级别的行和列,然后通过使用来自底层级别的邻域应用高斯过滤器来获得较高级别像素的值来创建的。 在每个金字塔步骤之后,图像将其宽度和高度减小一半,并且其面积是上一级图像面积的四分之一。 在 OpenCV 中,可以使用pyrDown,pyrUp和buildPyramid函数来计算高斯金字塔:
void pyrDown(InputArray src, OutputArray dst, const Size& dstsize = Size(), int borderType = BORDER_DEFAULT):此子采样会模糊src图像,并将结果保存在dst中。 如果未使用dstsize参数设置输出图像的大小,则将其计算为Size((src.cols+1)/2, (src.rows+1)/2)。void pyrUp(InputArray src, OutputArray dst, const Size& dstsize = Size(), int borderType = BORDER_DEFAULT):计算pyrDown的相反过程。void buildPyramid(InputArray src, OutputArrayOfArrays dst, int maxlevel, int borderType = BORDER_DEFAULT):这将为src中存储的图像构建高斯金字塔,获取maxlevel新图像,然后将它们存储在dst[0]中原始图像之后的dst数组中。 因此,dst结果存储了maxlevel + 1图像。
金字塔也用于分割。 OpenCV 提供了一个基于均值漂移分割算法第一步来计算均值漂移金字塔的函数:
-
void pyrMeanShiftFiltering(InputArray src, OutputArray dst, double sp, double sr, int maxLevel = 1, TermCriteria termcrit = TermCriteria (TermCriteria::MAX_ITER + TermCriteria::EPS, 5, 1)): This implements the filtering stage of the mean-shift segmentation, obtaining an image,dst, with color gradients and fine-grain texture flattened. Thespandsrparameters indicate the spatial window and the color window radii.注意
可以在这个页面中找到有关均值漂移分割的更多信息。
拉普拉斯金字塔
拉普拉斯金字塔在 OpenCV 中没有特定的函数实现,但它们是由高斯金字塔形成的。 拉普拉斯金字塔可视为边界图像,其中大部分元素为零。 拉普拉斯金字塔中的第i个级别是高斯金字塔中第i个级别与第i + 1个级别的扩展版本之间的差。 高斯金字塔。
示例代码
金字塔示例之后的向您展示了如何通过pyrDown函数从高斯金字塔中获取两个级别,以及如何通过pyrUp从相反的操作中获取两个级别。 请注意,使用pyrUp后无法获得原始图像:
#include "opencv2/opencv.hpp"
using namespace cv;
int main( int argc, char** argv )
{
// Read the source file
Mat src;
src = imread(argv[1]);
// Apply two times pyrDown
Mat dst, dst2;
pyrDown(src, dst);
pyrDown(dst, dst2);
// Show the results
namedWindow( " ORIGINAL ", WINDOW_AUTOSIZE );
imshow( " ORIGINAL ", src );
namedWindow( " 1st PYRDOWN ", WINDOW_AUTOSIZE );
imshow( " 1st PYRDOWN ", dst );
namedWindow( " 2st PYRDOWN ", WINDOW_AUTOSIZE );
imshow( " 2st PYRDOWN ", dst2 );
// Apply two times pyrUp
pyrUp(dst2, dst);
pyrUp(dst, src);
// Show the results
namedWindow( " NEW ORIGINAL ", WINDOW_AUTOSIZE );
imshow( " NEW ORIGINAL ", dst2 );
namedWindow( " 1st PYRUP ", WINDOW_AUTOSIZE );
imshow( " 1st PYRUP ", dst );
namedWindow( " 2st PYRUP ", WINDOW_AUTOSIZE );
imshow( " 2st PYRUP ", src );
waitKey();
return 0;
}
下图显示了代码的输出:
高斯金字塔的原始层和两个层
形态操作
形态学操作根据形状处理图像。 他们将定义的“结构元素”应用于图像,从而获得新图像,其中通过比较位置上的输入像素值来计算位置(x[i], y[j])上的像素(x[i], y[j])及其附近地区。 根据所选的结构元素,形态操作对一种特定形状或其他形状更敏感。
两种基本的形态学操作是膨胀和侵蚀。 膨胀将像素从背景添加到图像中对象的边界,而侵蚀则将像素去除。 这是在其中考虑结构元素以选择要添加或删除的像素的地方。 在扩张中,输出像素的值是附近所有像素的最大值。 使用腐蚀,输出像素的值是附近所有像素的最小值。

膨胀和腐蚀的例子
其他图像处理操作可以通过组合扩张和腐蚀来定义,例如打开和关闭操作以及形态梯度。 打开操作的定义是腐蚀,然后是膨胀,而关闭是相反的操作-膨胀,然后是腐蚀。 因此,打开时会从图像中移除小物体,同时保留较大的物体,而闭合用于移除小孔,而同时保留较大物体,其方式类似于打开。 形态梯度定义为图像的膨胀与腐蚀之间的差异。 此外,还使用打开和关闭定义了另外两个操作:高帽操作和黑帽操作。 在大礼帽的情况下,它们被定义为源图像与其打开之间的差异;在黑帽的情况下,它们被定义为图像的关闭与源图像之间的差异。 所有操作都使用相同的结构元素。
在 OpenCV 中,可以通过以下函数应用膨胀,腐蚀,打开和关闭:
void dilate(InputArray src, OutputArray dst, InputArray kernel, Point anchor = Point(-1,-1), int iterations = 1, int borderType = BORDER_CONSTANT, const Scalar& borderValue = morphologyDefaultBorderValue()):这会使用特定的结构化元素扩大src中存储的图像,并将结果保存在dst中。kernel参数是所使用的结构元素。anchor点指示锚点像素的位置。(-1, -1)值表示锚点位于中心。 使用iterations可以多次应用该操作。 边界类型的处理在borderType参数中指示,与前面部分中的其他过滤器相同。 最后,如果使用BORDER_CONSTANT边界类型,则在borderValue中指示常量。void erode(InputArray src, OutputArray dst, InputArray kernel, Point anchor = Point(-1,-1), int iterations = 1, int borderType = BORDER_CONSTANT, const Scalar& borderValue = morphologyDefaultBorderValue()):这会使用特定的结构元素腐蚀图像。 其参数与dilate中的参数相同。void morphologyEx(InputArray src, OutputArray dst, int op, InputArray kernel, Point anchor = Point(-1,-1), int iterations = 1, int borderType = BORDER_CONSTANT, const Scalar& borderValue = morphologyDefaultBorderValue()):这执行使用op参数定义的高级形态学操作。 可能的op值为MORPH_OPEN,MORPH_CLOSE,MORPH_GRADIENT,MORPH_TOPHAT和MORPH_BLACKHAT。Mat getStructuringElement(int shape, Size ksize, Point anchor = Point(-1,-1)):这将返回指定大小和形状的结构元素,以进行形态学操作。 支持的类型为MORPH_RECT,MORPH_ELLIPSE和MORPH_CROSS。
示例代码
以下形态学示例向您展示了如何在棋盘格中分割红色棋子,如何应用二进制阈值(inRange函数),然后通过膨胀和腐蚀操作(通过dilate和erode函数)完善结果。 使用的结构是15 x 15像素的圆圈。 示例代码为:
#include "opencv2/opencv.hpp"
using namespace cv;
using namespace std;
int main( int argc, char** argv )
{
// Read the source file
Mat src;
src = imread(argv[1]);
// Apply the filters
Mat dst, dst2, dst3;
inRange(src, Scalar(0, 0, 100), Scalar(40, 30, 255), dst);
Mat element = getStructuringElement(MORPH_ELLIPSE,Size(15,15));
dilate(dst, dst2, element);
erode(dst2, dst3, element);
// Show the results
namedWindow( " ORIGINAL ", WINDOW_AUTOSIZE );
imshow( " ORIGINAL ", src );
namedWindow( " SEGMENTED ", WINDOW_AUTOSIZE );
imshow( " SEGMENTED ", dst );
namedWindow( " DILATION ", WINDOW_AUTOSIZE );
imshow( " DILATION ", dst2 );
namedWindow( " EROSION ", WINDOW_AUTOSIZE );
imshow( " EROSION ", dst3 );
waitKey();
return 0;
}
下图显示了代码的输出:

原始的红色分割,膨胀和腐蚀
LUT
查找表(LUT)在自定义过滤器中非常常见,在自定义过滤器中,中两个具有相同值的像素在输入中也包含相同的值。 LUT 变换根据表给出的值为输入图像中的每个像素分配一个新的像素值。 在该表中,索引表示输入强度值,并且由索引给出的单元格的内容表示相应的输出值。 由于实际上是针对每个可能的强度值计算变换的,因此这减少了在图像上应用变换所需的时间(图像通常具有比强度值的数量更多的像素)。
LUT(InputArray src, InputArray lut, OutputArray dst, int interpolation = 0) OpenCV 函数对 8 位有符号或src无符号图像应用查找表转换。 因此,lut参数中给出的表包含 256 个元素。 lut中的通道数为 1 或src.channels。 如果src具有多个通道,但lut具有单个通道,则将同一lut通道应用于所有图像通道。
示例代码
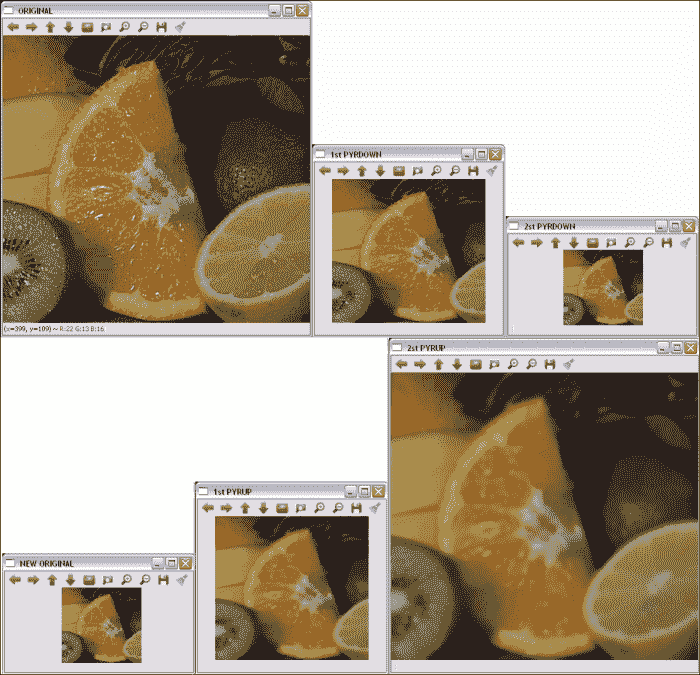
下面的 LUT 示例向您展示了如何使用查找表将图像的像素强度除以 2。 在将 LUT 与以下代码结合使用之前,需要对其进行初始化:
uchar * M = (uchar*)malloc(256*sizeof(uchar));
for(int i=0; i<256; i++){
M[i] = i*0.5; //The result is rounded to an integer value
}
Mat lut(1, 256, CV_8UC1, M);
将创建一个Mat对象,其中每个单元格都包含新值。 示例代码为:
#include "opencv2/opencv.hpp"
using namespace cv;
int main( int argc, char** argv )
{
// Read the source file
Mat src;
src = imread(argv[1]);
// Create the LUT
uchar * M = (uchar*)malloc(256*sizeof(uchar));
for(int i=0; i<256; i++){
M[i] = i*0.5;
}
Mat lut(1, 256, CV_8UC1, M);
// Apply the LUT
Mat dst;
LUT(src,lut,dst);
// Show the results
namedWindow( " ORIGINAL ", WINDOW_AUTOSIZE );
imshow( " ORIGINAL ", src );
namedWindow( " LUT ", WINDOW_AUTOSIZE );
imshow( " LUT ", dst );
waitKey();
return 0;
}
下图显示了代码的输出:
原始和 LUT 转换的图像
几何变换
几何变换不会更改图像内容,而是会通过使它们的网格变形来使图像变形。 在这种情况下,输出图像像素值的计算方法是:首先通过应用相应的映射函数获得相应输入像素的坐标,然后将原始像素值从获得的位置复制到新位置:
![]()
这种类型的操作有两个问题:
- 外推:
f[x](x, y)和f[y](x, y)可获得表示图像外部边界像素的值。 几何变换中使用的外推方法与图像过滤中使用的外推方法相同,外加另一种称为BORDER_TRANSPARENT的方法。 - 插值:
f[x](x, y)和f[y](x, y)通常是浮点数。 在 OpenCV 中,可以在最近邻和多项式插值方法之间进行选择。 最近邻插值包括将浮点坐标舍入到最接近的整数。 支持的插值方法是:INTER_NEAREST:这是前面解释的最近邻插值。INTER_LINEAR:这是一种双线性插值方法。 默认情况下使用。INTER_AREA:使用像素面积关系重新采样。INTER_CUBIC:这是在4 x 4像素邻域上的双三次插值方法。INTER_LANCZOS4:这是在8 x 8像素邻域上的 Lanczos 插值方法。
OpenCV 支持的几何变换包括仿射(缩放,平移,旋转等)和透视变换。
仿射变换
仿射变换是几何变换,在应用后保留了直线上初始线的所有点。 此外,还保留了从这些点中的每一个到线的末端的距离比。 另一方面,仿射变换不一定会保留角度和长度。
缩放,平移,旋转,倾斜和反射等几何变换都是仿射变换。
缩放
缩放图像可通过缩小或缩放来调整其大小。 为此,OpenCV 中的函数为void resize(InputArray src, OutputArray dst, Size dsize, double fx = 0, double fy = 0, int interpolation = INTER_LINEAR)。 除了输入图像和输出图像src和dst外,它还具有一些参数来指定图像要缩放到的尺寸。 如果通过将dsize设置为不同于 0 的值来指定新图像尺寸,则缩放因子参数fx和fy均为 0,并且从dsize和fx计算fx和fy。 输入图像的原始大小。 如果fx和fy不同于 0,并且dsize等于 0,则根据其他参数计算dsize。 缩放操作可以通过其转换矩阵表示:

此处,s[x]和s[y]是 x 和 y 轴上的比例因子。
示例代码
以下缩放示例显示了如何通过resize函数缩放图像。 示例代码为:
#include "opencv2/opencv.hpp"
using namespace cv;
int main( int argc, char** argv )
{
// Read the source file
Mat src;
src = imread(argv[1]);
// Apply the scale
Mat dst;
resize(src, dst, Size(0,0), 0.5, 0.5);
// Show the results
namedWindow( " ORIGINAL ", WINDOW_AUTOSIZE );
imshow( " ORIGINAL ", src );
namedWindow( " SCALED ", WINDOW_AUTOSIZE );
imshow( " SCALED ", dst );
waitKey();
return 0;
}
下图显示了代码的输出:

原始和缩放图像; fx和fy均为 0.5
平移
平移只是沿着特定的方向和距离移动图像。 因此,平移可以通过向量(t[x], t[y])或其转换矩阵表示:

在 OpenCV 中,可以使用void warpAffine( InputArray src, OutputArray dst, InputArray M, Size dsize, int flags = INTER_LINEAR, int borderMode = BORDER_CONSTANT, const Scalar& borderValue = Scalar())函数应用平移。 M参数是将src转换为dst的转换矩阵。 使用flags参数指定插值方法,该参数也支持WARP_INVERSE_MAP值,这意味着M是逆变换。 borderMode参数是外推方法,当borderMode为BORDER_CONSTANT时,borderValue为。
示例代码
平移示例向您展示如何使用warpAffine函数平移图像。 示例代码为:
#include "opencv2/opencv.hpp"
using namespace cv;
int main( int argc, char** argv )
{
// Read the source file
Mat src;
src = imread(argv[1]);
// Apply translation
Mat dst;
Mat M = (Mat_<double>(2,3) << 1, 0, 200, 0, 1, 150);
warpAffine(src,dst,M,src.size());
// Show the results
namedWindow( " ORIGINAL ", WINDOW_AUTOSIZE );
imshow( " ORIGINAL ", src );
namedWindow( " TRANSLATED ", WINDOW_AUTOSIZE );
imshow( " TRANSLATED ", dst );
waitKey();
return 0;
}
下图显示了代码的输出:

原始图像和置换图像。 水平位移为 200,垂直位移为 150。
图像旋转
图像旋转涉及特定角度θ。 OpenCV 使用定义如下的转换矩阵在特定位置支持缩放旋转:

此处,x和y是旋转点的坐标, sf 是比例因子。
旋转通过warpAffine函数像平移一样应用,但使用Mat getRotationMatrix2D(Point2f center, double angle, double scale)函数创建旋转变换矩阵。 M参数是将src转换为dst的转换矩阵。 如参数名称所示,center是旋转的中心点,angle是旋转角度(沿逆时针方向),scale是比例因子。
示例代码
以下旋转示例显示了如何使用warpAffine函数旋转图像。 首先通过getRotationMatrix2D( Point2f( src.cols/2, src.rows/2 ), 45, 1 )获得 45 度中心旋转矩阵。 示例代码为:
#include "opencv2/opencv.hpp"
using namespace cv;
int main( int argc, char** argv )
{
// Read the source file
Mat src;
src = imread(argv[1]);
// Apply the rotation
Mat dst;
Mat M = getRotationMatrix2D(Point2f(src.cols/2,src.rows/2),45,1);
warpAffine(src,dst,M,src.size());
// Show the results
namedWindow( " ORIGINAL ", WINDOW_AUTOSIZE );
imshow( " ORIGINAL ", src );
namedWindow( " ROTATED ", WINDOW_AUTOSIZE );
imshow( " ROTATED ", dst );
waitKey();
return 0;
}
下图显示了代码的输出:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oxqcgxHx-1681871326909)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-imgproc-opencv/img/7659OT_03_11.jpg)]
应用原始图像和中心旋转 45 度后的图像
倾斜
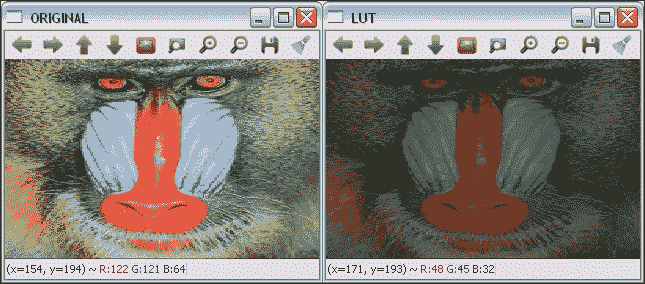
倾斜变换将每个点在固定方向上移动的距离与与平行于方向的线的其有符号距离成比例。 因此,它通常会扭曲几何图形的形状,例如,将正方形变成非正方形的平行四边形,将圆形变成椭圆。 但是,倾斜会保留几何图形的面积,共线点的对齐方式和相对距离。 倾斜映射是直立和倾斜(或斜体)字母样式之间的主要区别。
偏斜也可以通过其角度θ来定义。
原稿及其与中心图像旋转 45 度
使用偏斜角度,水平和垂直偏斜的转换矩阵为:

由于与先前转换的相似性,用于应用倾斜的函数为warpAffine。
提示
在大多数情况下,有必要为输出图像添加一些大小和/或应用平移(更改剪切变换矩阵上的最后一列),以便完整且集中地显示输出图像。
示例代码
偏斜示例之后的向您展示了如何使用warpAffine函数使图像中的θ = π/ 3水平偏斜。 示例代码为:
#include "opencv2/opencv.hpp"
#include 下图显示了代码的输出:

原始图像和水平倾斜时的图像
反射
由于默认情况下会在x和y轴上进行反射,因此必须应用平移(变换矩阵的最后一列)。 然后,反射矩阵为:

在此,t[x]是图像列数,t[y]是图像行数。
与以前的转换一样,用于施加反射的函数为warpAffine。
注意
其他仿射变换可以使用warpAffine函数及其对应的变换矩阵来应用。
示例代码
以下反射示例显示了使用warpAffine函数对图像进行水平,垂直和组合反射的示例。 示例代码为:
#include "opencv2/opencv.hpp"
using namespace cv;
int main( int argc, char** argv )
{
// Read the source file
Mat src;
src = imread(argv[1]);
// Apply the reflections
Mat dsth, dstv, dst;
Mat Mh = (Mat_<double>(2,3) << -1, 0, src.cols, 0, 1, 0
Mat Mv = (Mat_<double>(2,3) << 1, 0, 0, 0, -1, src.rows);
Mat M = (Mat_<double>(2,3) << -1, 0, src.cols, 0, -1, src.rows);
warpAffine(src,dsth,Mh,src.size());
warpAffine(src,dstv,Mv,src.size());
warpAffine(src,dst,M,src.size());
// Show the results
namedWindow( " ORIGINAL ", WINDOW_AUTOSIZE );
imshow( " ORIGINAL ", src );
namedWindow( " H-REFLECTION ", WINDOW_AUTOSIZE );
imshow( " H-REFLECTION ", dsth );
namedWindow( " V-REFLECTION ", WINDOW_AUTOSIZE );
imshow( " V-REFLECTION ", dstv );
namedWindow( " REFLECTION ", WINDOW_AUTOSIZE );
imshow( " REFLECTION ", dst );
waitKey();
return 0;
}
下图显示了代码的输出:

X,Y 和两个轴上的原始图像和旋转图像
透视变换
对于透视变换,虽然需要对二维图像执行,但仍需要3 x 3变换矩阵。 直线在输出图像中保持直线,但是在这种情况下,比例会改变。 与仿射变换相比,查找变换矩阵要复杂得多。 使用透视图时,将使用输入图像矩阵的四个点的坐标及其在输出图像矩阵上的相应坐标来执行此操作。
通过这些点和getPerspectiveTransform OpenCV 函数,可以找到透视变换矩阵。 在获得矩阵之后,应用warpPerspective获得透视变换的输出。 这两个函数在这里详细说明:
Mat getPerspectiveTransform(InputArray src, InputArray dst)和Mat getPerspectiveTransform(const Point2f src[], const Point2f dst[]):这将返回根据src和dst计算的透视变换矩阵。void warpPerspective(InputArray src, OutputArray dst, InputArray M, Size dsize, int flags=INTER_LINEAR, int borderMode=BORDER_CONSTANT, const Scalar& borderValue=Scalar()):这会将M仿射变换应用于src图像,从而获得新的dst图像。 其余参数与讨论的其他几何变换相同。
示例代码
以下透视图示例向您展示了如何使用warpPerspective函数更改图像的透视图的示例。 在这种情况下,需要指示从第一张图像开始的四个点的坐标,并从输出指示另外四个点的坐标,以通过getPerspectiveTransform计算透视变换矩阵。 选择的点是:
Point2f src_verts[4];
src_verts[2] = Point(195, 140);
src_verts[3] = Point(410, 120);
src_verts[1] = Point(220, 750);
src_verts[0] = Point(400, 750);
Point2f dst_verts[4];
dst_verts[2] = Point(160, 100);
dst_verts[3] = Point(530, 120);
dst_verts[1] = Point(220, 750);
dst_verts[0] = Point(400, 750);
示例代码为:
#include "opencv2/opencv.hpp"
using namespace cv;
int main( int argc, char** argv )
{
// Read the source file
Mat src;
src = imread(argv[1]);
Mat dst;
Point2f src_verts[4];
src_verts[2] = Point(195, 140);
src_verts[3] = Point(410, 120);
src_verts[1] = Point(220, 750);
src_verts[0] = Point(400, 750);
Point2f dst_verts[4];
dst_verts[2] = Point(160, 100);
dst_verts[3] = Point(530, 120);
dst_verts[1] = Point(220, 750);
dst_verts[0] = Point(400, 750);
// Obtain and Apply the perspective transformation
Mat M = getPerspectiveTransform(src_verts,dst_verts);
warpPerspective(src,dst,M,src.size());
// Show the results
namedWindow( " ORIGINAL ", WINDOW_AUTOSIZE );
imshow( " ORIGINAL ", src );
namedWindow( " PERSPECTIVE ", WINDOW_AUTOSIZE );
imshow( " PERSPECTIVE ", dst );
waitKey();
return 0;
}
下图显示了代码的输出:

透视结果带有原始图像中标记的点
修复
修复是重建图像和视频的受损部分的过程。 此过程也称为,称为图像或视频插值。 基本思想是模拟古董修复者完成的过程。 如今,随着数码相机的广泛使用,修补已成为一种自动过程,不仅可以通过删除划痕来进行图像恢复,还可以用于其他任务,例如去除物体或文本。
OpenCV 从版本 2.4 开始支持修复算法。 用于此目的的函数是:
void inpaint(InputArray src, InputArray inpaintMask, OutputArray dst, double inpaintRadius, int flags):这将恢复源(src)图像中inpaintMask参数用非零值指示的区域。inpaintRadius参数指示flags指定的算法要使用的邻域。 OpenCV 中可以使用两种方法:INPAINT_NS:这是基于 Navier-Stokes 的方法INPAINT_TELEA:这是 Alexandru Telea 提出的方法
最后,恢复的图像存储在dst中。
注意
有关 OpenCV 中使用的修复算法的更多详细信息,请参见这个页面。
提示
对于视频修复,请将视频视为图像序列,然后将算法应用于所有图像。
示例代码
修复示例之后的显示了如何使用inpaint函数修复在图像遮罩中指定的图像区域。
示例代码为:
#include "opencv2/opencv.hpp"
using namespace cv;
int main( int argc, char** argv )
{
// Read the source file
Mat src;
src = imread(argv[1]);
// Read the mask file
Mat mask;
mask = imread(argv[2]);
cvtColor(mask, mask, COLOR_RGB2GRAY);
// Apply the inpainting algorithms
Mat dst, dst2;
inpaint(src, mask, dst, 10, INPAINT_TELEA);
inpaint(src, mask, dst2, 10, INPAINT_NS);
// Show the results
namedWindow( " ORIGINAL ", WINDOW_AUTOSIZE );
imshow( " ORIGINAL ", src );
namedWindow( " MASK ", WINDOW_AUTOSIZE );
imshow( " MASK ", mask );
namedWindow(" INPAINT_TELEA ", WINDOW_AUTOSIZE );
imshow( " INPAINT_TELEA ", dst );
namedWindow(" INPAINT_NS ", WINDOW_AUTOSIZE );
imshow( " INPAINT_NS ", dst2 );
waitKey();
return 0;
}
下图显示了代码的输出:

应用修补的结果
注意
第一行包含原始图像和使用的遮罩。 第二行在左侧包含 Telea 提出的修复结果,在右侧包含基于 Navier-Stokes 的方法的结果。
要获得修复遮罩并非易事。 inpainting2示例代码向您展示了一个示例,该示例说明如何使用通过threshold(mask, mask, 235, 255, THRESH_BINARY)的二进制阈值从源图像中获取遮罩:
#include "opencv2/opencv.hpp"
using namespace cv;
int main( int argc, char** argv )
{
// Read the source file
Mat src;
src = imread(argv[1]);
// Create the mask
Mat mask;
cvtColor(src, mask, COLOR_RGB2GRAY);
threshold(mask, mask, 235, 255, THRESH_BINARY);
// Apply the inpainting algorithms
Mat dst, dst2;
inpaint(src, mask, dst, 10, INPAINT_TELEA);
inpaint(src, mask, dst2, 10, INPAINT_NS);
// Show the results
namedWindow( " ORIGINAL ", WINDOW_AUTOSIZE );
imshow( " ORIGINAL ", src );
namedWindow( " MASK ", WINDOW_AUTOSIZE );
imshow( " MASK ", mask );
namedWindow(" INPAINT_TELEA ", WINDOW_AUTOSIZE );
imshow( " INPAINT_TELEA ", dst );
namedWindow(" INPAINT_NS ", WINDOW_AUTOSIZE );
imshow( " INPAINT_NS ", dst2 );
waitKey();
return 0;
}
下图显示了代码的输出:

在不知道遮罩的情况下应用修复算法的结果
注意
第一行包含原始图像和提取的遮罩。 第二行在左侧包含 Telea 提出的修复结果,在右侧包含基于 Navier-Stokes 的方法的结果。
此示例的结果表明,并非总是可能获得完美的遮罩。 有时会包括图像的其他一些部分,例如背景或噪点。 但是,修复结果仍然可以接受,因为生成的图像接近于在其他情况下获得的图像。
降噪
降噪或降噪是从模拟或数字设备获得的信号中去除噪声的过程。 本节将重点放在减少数字图像和视频的噪声上。
尽管平滑和中值滤波是对图像进行降噪的不错选择,但 OpenCV 提供了其他算法来执行此任务。 这些是非本地均值和 TVL1(总变异 L1)算法。 非局部均值算法的基本思想是用来自多个图像子窗口的平均颜色替换像素的颜色,这些子窗口与包含像素邻域的子窗口相似。 另一方面,使用原始对偶优化算法实现的 TVL1 变分降噪模型将图像降噪过程视为一个变分问题。
注意
有关非局部均值和 TVL1 去噪算法的更多信息,请访问这个页面和这个页面。
OpenCV 提供了四种使用非局部均值方法对彩色和灰度图像进行降噪的函数。 对于 TVL1 模型,提供了一种函数。 这些函数为:
void fastNlMeansDenoising(InputArray src, OutputArray dst, float h = 3, int templateWindowSize = 7, int searchWindowSize = 21):这会将src中加载的单个灰度图像降噪。templateWindowSize和searchWindowSize参数是用于计算权重的模板补丁的像素大小,以及用于计算给定像素的加权平均值的窗口大小。 这些应该是奇数,建议值分别为 7 和 21 像素。h参数调节算法的效果。 较大的h值可消除更多的噪点缺陷,但具有消除更多图像细节的缺点。 输出存储在dst中。void fastNlMeansDenoisingColored(InputArray src, OutputArray dst, float h = 3, float hForColorComponents = 3, int templateWindowSize = 7, int searchWindowSize = 21):这是对彩色图像先前函数的修改。 它将src图像转换为 CIELAB 色彩空间,然后使用fastNlMeansDenoising函数分别对 L 和 AB 分量进行降噪。void fastNlMeansDenoisingMulti(InputArrayOfArrays srcImgs, OutputArray dst, int imgToDenoiseIndex, int temporalWindowSize, float h = 3, int templateWindowSize = 7, int searchWindowSize = 21):这使用图像序列获得去噪的图像。 在这种情况下,还需要两个参数:imgToDenoiseIndex和temporalWindowSize。imgToDenoiseIndex的值是srcImgs中要去噪的目标图像索引。 最后,temporalWindowSize用于确定要用于降噪的周围图像的数量。 这应该很奇怪。void fastNlMeansDenoisingColoredMulti(InputArrayOfArrays srcImgs, OutputArray dst, int imgToDenoiseIndex, int temporalWindowSize, float h = 3, float hForColorComponents = 3, int templateWindowSize = 7, int searchWindowSize = 21):基于fastNlMeansDenoisingColored和fastNlMeansDenoisingMulti函数。 这些参数将在其余函数中说明。void denoise_TVL1(const std::vector:这从& observations, Mat& result, double lambda, int niters) observations中存储的一个或多个噪声图像获得result中的去噪图像。lambda和niters参数控制算法的强度和迭代次数。
示例代码
去噪示例后的向您展示了如何使用其中一种降噪函数对彩色图像(fastNlMeansDenoisingColored))进行降噪。由于该示例使用的是无噪声图像,因此需要添加一些内容。 为此,使用以下代码行:
Mat noisy = src.clone();
Mat noise(src.size(), src.type());
randn(noise, 0, 50);
noisy += noise;
创建的Mat元素具有与原始图像相同的大小和类型,以在其上存储由randn函数产生的产生的噪声。 最后,将噪声添加到克隆图像中以获得噪声图像。
示例代码为:
#include "opencv2/opencv.hpp"
using namespace cv;
int main( int argc, char** argv )
{
// Read the source file
Mat src;
src = imread(argv[1]);
// Add some noise
Mat noisy = src.clone();
Mat noise(src.size(), src.type());
randn(noise, 0, 50);
noisy += noise;
// Apply the denoising algorithm
Mat dst;
fastNlMeansDenoisingColored(noisy, dst,30,30,7,21);
// Show the results
namedWindow( " ORIGINAL ", WINDOW_AUTOSIZE );
imshow( " ORIGINAL ", src );
namedWindow( " ORIGINAL WITH NOISE ", WINDOW_AUTOSIZE );
imshow( " ORIGINAL WITH NOISE ", noisy );
namedWindow(" DENOISED ", WINDOW_AUTOSIZE );
imshow( " DENOISED ", dst );
waitKey();
return 0;
}
下图显示了执行前一代码后产生的噪点和去噪图像:

应用去噪的结果
总结
在本章中,我们介绍了用于图像增强和校正的方法,包括降噪,边缘增强,形态运算,几何变换以及受损图像的恢复。 在每种情况下都提供了不同的选项,以向读者提供可以在 OpenCV 中使用的所有选项。
下一章将介绍色彩空间以及如何转换色彩空间。 另外,将说明基于色彩空间的分割和色彩转移方法。
四、处理色彩
颜色是响应于我们的视觉系统的激发而产生的感知结果,入射光是在光谱的可见光区域中入射到视网膜上的。 图像的颜色可能包含大量信息,这些信息可用于简化图像分析,对象识别和基于颜色的提取。 通常在考虑定义其的色彩空间中的像素值的情况下执行这些过程。 本章将讨论以下主题:
- OpenCV 中使用的色彩空间以及如何将图像从一种色彩模型转换为另一种色彩模型
- 考虑定义图片色彩空间的方式如何对图片进行分割的示例
- 如何使用颜色转移方法将图像的外观转移到另一个
色彩空间
人类的视觉系统能够分辨出数十万种颜色。 为了获得此信息,人类视网膜具有三种类型的彩色感光锥体细胞,它们对入射辐射作出响应。 因此,可以使用称为原色的三个数字分量生成大多数人的颜色感知。
为了根据三个或更多个特定特性来指定颜色,存在许多称为颜色空间或颜色模型的方法。 在它们之间代表图像进行选择取决于要执行的操作,因为根据所需的应用,某些操作更合适。 例如,在某些颜色空间(例如 RGB)中,亮度会影响三个通道,这对于某些图像处理操作可能是不利的。 下一节将说明 OpenCV 中使用的色彩空间,以及如何将图片从一种色彩模型转换为另一种色彩模型。
颜色空间之间的转换(cvtColor)
OpenCV 中有 150 多种颜色空间转换方法。 OpenCV 在imgproc模块中提供的函数是void cvtColor(InputArray src, OutputArray dst, int code, int dstCn=0)。 该函数的参数为:
src:这是 8 位无符号,16 位无符号(CV_16UC)或单精度浮点的输入图像。dst:此是与src相同大小和深度的输出图像。code:此是色彩空间转换代码。 该参数的结构为COLOR_SPACEsrc2SPACEdst。 一些示例值是COLOR_BGR2GRAY和COLOR_YCrCb2BGR。dstCn:这是目标图像中的通道数。 如果此参数为 0 或省略,则通道数自动从src和code派生。
此函数的示例将在接下来的部分中进行介绍。
提示
cvtColor函数只能从 RGB 转换为另一个颜色空间,或从另一个颜色空间转换为 RGB,因此,如果读者想在 RGB 以外的两个颜色空间之间转换,则必须先进行到 RGB 的转换。
OpenCV 中的各种色彩空间将在接下来的部分中进行讨论。
RGB
RGB 是可加模型,其中图像由三个独立图像平面或通道组成:红色,绿色和蓝色(以及可选的透明度的第四个通道,有时称为 alpha 通道)。 为了指定特定的颜色,每个值指示每个像素上存在的每种成分的数量,较高的值对应于较亮的像素。 由于该色彩空间对应于人眼的三个感光器,因此被广泛使用。
注意
OpenCV 中的默认颜色格式通常称为 RGB,但实际上将其存储为 BGR (通道相反)。
示例代码
以下BGRsplit示例向您展示了如何加载 RGB 图像,如何以灰色和彩色分割并显示每个特定通道。 代码的第一部分用于加载和显示图片:
#include 代码的下一部分将图片分成每个通道并显示:
vector<Mat> channels;
split( image, channels );
//show channels in gray scale
namedWindow("Blue channel (gray)", WINDOW_AUTOSIZE );
imshow("Blue channel (gray)",channels[0]);
namedWindow("Green channel (gray)", WINDOW_AUTOSIZE );
imshow("Green channel (gray)",channels[1]);
namedWindow("Red channel (gray)", WINDOW_AUTOSIZE );
imshow("Red channel (gray)",channels[2]);
//show channels in BGR
vector<Mat> separatedChannels=showSeparatedChannels(channels);
namedWindow("Blue channel", WINDOW_AUTOSIZE );
imshow("Blue channel",separatedChannels[0]);
namedWindow("Green channel", WINDOW_AUTOSIZE );
imshow("Green channel",separatedChannels[1]);
namedWindow("Red channel", WINDOW_AUTOSIZE );
imshow("Red channel",separatedChannels[2]);
waitKey(0);
return 0;
}
值得注意使用void split(InputArray m, OutputArrayOfArrays mv) OpenCV 函数将图像m分成三个通道,并将其保存在称为mv的向量中。 相反,void merge( InputArrayOfArrays mv, OutputArray dst)函数用于将所有mv通道合并到一个dst图像中。 此外,命名为showSeparatedChannels的函数用于创建代表每个通道的三个彩色图像。 对于每个通道,该函数都会生成vector,该vector由通道本身和两个辅助通道组成,它们的所有值均设置为 0,表示颜色模型的其他两个通道。 最后,辅助图片被合并,生成仅满足一个通道的图像。 该函数代码将在本章的其他示例中使用,如下所示:
vector<Mat> showSeparatedChannels(vector<Mat> channels){
vector<Mat> separatedChannels;
//create each image for each channel
for ( int i = 0 ; i < 3 ; i++){
Mat zer=Mat::zeros( channels[0].rows, channels[0].cols, channels[0].type());
vector<Mat> aux;
for (int j=0; j < 3 ; j++){
if(j==i)
aux.push_back(channels[i]);
else
aux.push_back(zer);
}
Mat chann;
merge(aux,chann);
separatedChannels.push_back(chann);
}
return separatedChannels;
}
下图显示了示例的输出:

原始 RGB 图像和通道分割
灰度
在灰度中,每个像素的值表示为仅包含强度信息的单个值,它构成了一个由不同灰度组成的图像。 使用cvtColor在 OpenCV 中在 RGB 和灰度(Y)之间转换的颜色空间转换代码是COLOR_BGR2GRAY,COLOR_RGB2GRAY,COLOR_GRAY2BGR和COLOR_GRAY2RGB。 这些转换的内部计算如下:
注意
![]()
![]()
请注意,根据上式中的,不可能直接从灰度图像中检索颜色。
示例代码
Gray示例之后的显示了如何将 RGB 图像转换为灰度,并显示了两张图片。 示例代码为:
#include 下图显示了代码的输出:

原始 RGB 图像和灰度转换
注意
从 RGB 转换为灰度的方法的缺点是失去了原始图像的对比度。 本书的第 6 章,“计算摄影”描述了脱色过程,该过程在克服此问题的同时进行了相同的转换。
CIE XYZ
CIE XYZ 系统使用亮度分量 Y 来描述颜色,该亮度分量与人眼的亮度灵敏度有关,并且由国际照明委员会(CIE)使用来自几个人类观察者的实验统计数据,标准化了另外两个通道 X 和 Z。 此颜色空间用于报告测量仪器(例如比色计或分光光度计)的颜色,当需要跨不同设备进行一致的颜色表示时,该颜色空间将非常有用。 这种颜色空间的主要问题是颜色以不均匀的方式缩放。 这一事实导致 CIE 采用 CIE Lab 和 CIE Luv 颜色模型。
使用cvtColor在 OpenCV 中在 RGB 和 CIE XYZ 之间转换的色彩空间转换代码是COLOR_BGR2XYZ,COLOR_RGB2XYZ, COLOR_XYZ2BGR和COLOR_XYZ2RGB。 这些转换的计算如下:


示例代码
CIExyz示例之后的显示了如何将 RGB 图像转换为 CIE XYZ 颜色空间,并分别以灰色和彩色显示并显示每个特定通道。 代码的第一部分用于加载和转换图片:
#include 代码的下一部分在每个 CIE XYZ 通道中拆分图片并显示它们:
vector<Mat> channels;
split( image, channels );
//show channels in gray scale
namedWindow("X channel (gray)", WINDOW_AUTOSIZE );
imshow("X channel (gray)",channels[0]);
namedWindow("Y channel (gray)", WINDOW_AUTOSIZE );
imshow("Y channel (gray)",channels[1]);
namedWindow("Z channel (gray)", WINDOW_AUTOSIZE );
imshow("Z channel (gray)",channels[2]);
//show channels in BGR
vector<Mat> separatedChannels=showSeparatedChannels(channels);
for (int i=0;i<3;i++){ cvtColor(separatedChannels[i],separatedChannels[i],COLOR_XYZ2BGR);
}
namedWindow("X channel", WINDOW_AUTOSIZE );
imshow("X channel",separatedChannels[0]);
namedWindow("Y channel", WINDOW_AUTOSIZE );
imshow("Y channel",separatedChannels[1]);
namedWindow("Z channel", WINDOW_AUTOSIZE );
imshow("Z channel",separatedChannels[2]);
waitKey(0);
return 0;
}
下图显示了代码的输出:

原始 RGB 图像和 CIE XYZ 通道分割
YCrCb
此色彩空间广泛用于视频和图像压缩方案,它不是绝对的色彩空间,因为它是对 RGB 色彩空间进行编码的一种方式。 Y 通道表示亮度,而 Cr 和 Cb 表示红色差异(RGB 色彩空间中的 R 通道与 Y 之间的差异)和蓝色差异(RGB 色彩空间中的 B 通道与 Y 之间的差异)色度分量。 它广泛用于视频和图像压缩方案,例如 MPEG 和 JPEG。
使用cvtColor在 OpenCV 中在 RGB 和 YCrCb 之间进行转换的颜色空间转换代码是COLOR_BGR2YCrCb,COLOR_RGB2YCrCb,COLOR_YCrCb2BGR和COLOR_YCrCb2RGB。 这些转换的计算如下:
![]()
![]()
![]()
![]()
![]()
![]()
然后,以和来看以下内容:

示例代码
下面的 YCrCb 颜色示例向您展示如何将 RGB 图像转换为 YCrCb 颜色空间,并以灰色和一种颜色拆分并显示每个特定的通道。 代码的第一部分用于加载和转换图片:
#include 代码的下一部分将图片分成每个 YCrCb 通道,并显示它们:
vector<Mat> channels;
split( image, channels );
//show channels in gray scale
namedWindow("Y channel (gray)", WINDOW_AUTOSIZE );
imshow("Y channel (gray)",channels[0]);
namedWindow("Cr channel (gray)", WINDOW_AUTOSIZE );
imshow("Cr channel (gray)",channels[1]);
namedWindow("Cb channel (gray)", WINDOW_AUTOSIZE );
imshow("Cb channel (gray)",channels[2]);
//show channels in BGR
vector<Mat> separatedChannels=showSeparatedChannels(channels);
for (int i=0;i<3;i++){
cvtColor(separatedChannels[i],separatedChannels[i],COLOR_YCrCb2BGR);
}
namedWindow("Y channel", WINDOW_AUTOSIZE );
imshow("Y channel",separatedChannels[0]);
namedWindow("Cr channel", WINDOW_AUTOSIZE );
imshow("Cr channel",separatedChannels[1]);
namedWindow("Cb channel", WINDOW_AUTOSIZE );
imshow("Cb channel",separatedChannels[2]);
waitKey(0);
return 0;
}
下图显示了代码的输出:

原始 RGB 图像和 YCrCb 通道分割
HSV
HSV 颜色空间属于所谓的面向色相的颜色坐标系。 这种颜色模型与人类颜色感知模型非常相似。 在其他颜色模型(如 RGB)中,图像被视为三种基色的相加结果,而 HSV 的三个通道代表色相(H 给出了颜色的光谱组成的一个度量),饱和度(S 表示主波长的纯光比例,它表示颜色与相等亮度的灰色有多远)和值(V 给出相对于类似照亮的白色颜色的亮度的亮度),对应于色调,阴影和色调的直观吸引力。 HSV 被广泛用于进行颜色比较,因为 H 几乎是独立的光线变化。 下图显示了此颜色模型,该颜色模型将每个通道表示为圆柱体的一部分:

用于使用cvtColor在 OpenCV 中的 RGB 和 HSV 之间进行转换的颜色空间转换代码是COLOR_BGR2HSV,COLOR_RGB2HSV,COLOR_HSV2BGR和COLOR_HSV2RGB。 在这种情况下,值得注意的是,如果src图像格式为 8 位或 16 位,则cvtColor首先将其转换为浮点格式,并在 0 和 1 之间缩放值。 转换计算如下:
![]()
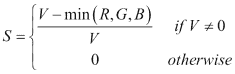

如果H < 0,则H = H + 360。 最后,值将转换为目标数据类型。
示例代码
下面的HSVcolor示例向您展示如何将 RGB 图像转换为 HSV 色彩空间,并以灰度和 HSV 图像拆分和显示每个特定通道。 示例代码为:
#include 下图显示了代码的输出:

原始 RGB 图像,HSV 转换和通道分割
注意
OpenCV 的imshow函数假定要显示的图像颜色是 RGB,因此显示不正确。 如果您在其他颜色空间中有图像,并且想要正确显示,则首先必须将其转换回 RGB。
HLS
HLS 颜色空间属于面向色相的颜色坐标系统,例如先前说明的 HSV 颜色模型。 开发该模型以指定每个通道中的色相,亮度和颜色饱和度的值。 HSV 颜色模型的区别在于,HLS 定义的纯色的亮度等于中等灰色的亮度,而 HSV 定义的纯色的亮度等于白色的亮度。
使用cvtColor在 OpenCV 中在 RGB 和 HLS 之间进行转换的颜色空间转换代码为COLOR_BGR2HLS,COLOR_RGB2HLS,COLOR_HLS2BGR和COLOR_HLS2RGB。 在这种情况下,与 HSV 一样,如果src图像格式为 8 位或 16 位,则cvtColor首先将其转换为浮点格式,将值缩放到 0 到 1 之间。然后,转换计算如下:
![]()
![]()
![]()

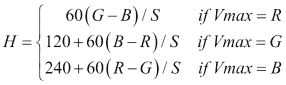
如果H < 0,则H = H + 360。 最后,将值重新转换为目标数据类型。
示例代码
以下HLScolor示例向您展示如何将 RGB 图像转换为 HLS 色彩空间,如何拆分和显示灰度中的每个特定通道以及 HLS 图像。 示例代码为:
#include 下图显示了代码的输出:

原始 RGB 图像,HLS 转换和通道分割
CIE Lab
CIE Lab 颜色空间是在 CIE Luv 之后由 CIE 标准化的第二个均匀颜色空间,它是基于 CIE XYZ 空间和白色参考点得出的。 实际上,它是 CIE 指定的最完整的色彩空间,其创建是与设备无关的,例如 CYE XYZ 模型,并用作参考。 它能够描述人眼可见的颜色。 这三个通道代表颜色的亮度(L),品红色和绿色之间的位置(a),以及黄色和蓝色之间的位置(b)。
使用cvtColor在 OpenCV 中在 RGB 和 CIE Lab 之间进行转换的色彩空间转换代码是COLOR_BGR2Lab,COLOR_RGB2Lab,COLOR_Lab2BGR和COLOR_Lab2RGB。 在这个页面中解释了用于计算这些转换的过程。
示例代码
CIElab示例之后的显示了如何将 RGB 图像转换为 CIE Lab 色彩空间,以灰度和 CIE Lab 分割并显示图片的每个特定通道。 示例代码为:
#include 下图显示了代码的输出:

原始 RGB 图像,CIE Lab 转换和通道分割
CIE Luv
CIE Luv 颜色空间是 CIE 标准化的第一个统一颜色空间。 它是 CIE XYZ 空间和白色参考点的简单计算转换,尝试进行感知均匀性。 类似于 CIE Lab 颜色空间,它的创建与设备无关。 三个通道代表颜色的亮度(L)及其在绿色和红色之间的位置(u),最后一个通道主要代表蓝色和紫色类型的颜色(v)。 该颜色模型具有线性加和特性,因此可用于灯光的添加剂混合物。
使用cvtColor在 OpenCV 中在 RGB 和 CIE Luv 之间进行转换的颜色空间转换代码是COLOR_BGR2Luv,COLOR_RGB2Luv,COLOR_Luv2BGR和COLOR_Luv2RGB。 可以在这个页面上看到用于计算这些转换的过程。
示例代码
CIELuvcolor示例之后的显示了如何将 RGB 图像转换为 CIE Luv 色彩空间,以灰度和 CIE Luv 分割并显示图片的每个特定通道。 示例代码为:
#include 下图显示了代码的输出:

原始 RGB 图像,CIE Luv 转换和通道分割
拜耳
拜耳像素空间合成被广泛用于带有仅一个图像传感器的数码相机。 与具有三个传感器的相机(每个 RGB 通道一个传感器,可以获取特定组件的所有信息)不同,在一台传感器相机中,每个像素都被一个不同的滤色镜覆盖,因此每个像素仅以此颜色进行测量。 使用拜耳方法从其邻居中推断出丢失的颜色信息。 它使您可以从一个像素交错的单一平面中获取完整的彩色图片,如下所示:

拜耳模式示例
注意
请注意,拜耳图案由比 R 和 B 多的 G 像素表示,因为人眼对绿色频率更敏感。
通过将图案在任何方向上移动一个像素,可以获得对所示图案的几种修改。 在 OpenCV 中将 Bayer 转换为 RGB 的色彩空间转换代码是将第二行的第二列和第三列(分别为X和Y)的组件定义为COLOR_BayerXY2BGR的。 例如,前一张图片的图案具有“BG”类型,因此其转换代码为COLOR_BayerBG2BGR。
示例代码
以下Bayer示例向您展示如何将由从图像传感器获得的 RG Bayer 模式定义的图片转换为 RGB 图像。 示例代码为:
#include 下图显示了代码的输出:

拜耳图案图像和 RGB 转换
基于颜色空间的分割
每个颜色空间代表一个图像,该图像指示每个像素上每个通道测得的特定特性的数值。 考虑到这些特性,可以使用线性边界(例如,三维空间中的平面和每个通道一个空间)对颜色空间进行分区,从而可以根据其所在的分区对每个像素进行分类,因此可以选择一组具有预定义特性的像素。 这个想法可以用来分割我们感兴趣的图像对象。
OpenCV 提供void inRange(InputArray src, InputArray lowerb, InputArray upperb, OutputArray dst)函数来检查元素数组是否位于其他两个数组的元素之间。 对于基于色彩空间的分割,此函数可让您获得src图像的像素集,其通道值位于lowerb下边界和upperb上边界之间,从而获得dst图片。
注意
lowerb和upperb边界通常定义为Scalar(x, y, z),其中x,y,和z是定义为上下边界的每个通道的数值。
以下示例向您展示如何检测可以被认为是皮肤的像素。 已经观察到,肤色的强度比色度的差异更大,因此通常在皮肤检测中不考虑亮度成分。 由于该色彩空间对亮度的依赖性,这一事实使得难以检测以 RGB 表示的图像中的皮肤,因此使用 HSV 和 YCrCb 颜色模型。 值得注意的是,对于这种类型的分段,必须知道或获得每个通道的边界值。
HSV 分割
如先前所述,HSV 被广泛用于进行颜色比较,因为 H 几乎与光的变化无关,因此在皮肤检测中很有用。 在该示例中,选择下边界(0, 10, 60)和上边界(20, 150, 255)以检测每个像素中的皮肤。 示例代码为:
#include 下图显示代码的输出:

使用 HSV 颜色空间进行皮肤检测
YCrCb 分割
YCrCb 颜色空间减少了 RGB 颜色通道的冗余,并以独立的组件表示颜色。 考虑到亮度和色度分量是分开的,此空间是皮肤检测的不错选择。
以下示例将 YCrCb 颜色空间用于皮肤检测,并使用每个像素中的下边界(0, 33, 77)和上边界(255, 173, 177)。 示例代码为:
#include 下图显示代码的输出:
使用 YCrCb 颜色空间进行皮肤检测
注意
有关的更多图像分割方法,请参阅 Packt Publishing 的《OpenCV Essentials》的第 4 章。
颜色转移
图像处理中通常执行的另一项任务是修改图像的颜色,特别是在需要去除主要或不希望有的偏色的情况下。 这些方法中的一种称为颜色转移,该方法执行一组借用一个源图像的颜色特征的颜色校正,并将源图像的外观转移到目标图像。
示例代码
以下colorTransfer示例显示了如何将颜色从源图像传输到目标图像。 此方法首先将图像色彩空间转换为 CIE Lab。 接下来,它为源图像和目标图像分割通道。 之后,使用均值和标准差拟合从一个图像到另一个图像的通道分布。 最后,通道合并回一起并转换为 RGB。
注意
有关示例中使用的转换的完整理论详细信息,请参见《图像之间的颜色转换》 。
代码的第一部分将图像转换为 CIE Lab 颜色空间,同时还将图像类型更改为CV_32FC1:
#include 代码的接下来的部分执行颜色转移,如前所述:
//Find mean and std of each channel for each image
Mat mean_src, mean_tar, stdd_src, stdd_tar;
meanStdDev(src_lab, mean_src, stdd_src);
meanStdDev(tar_lab, mean_tar, stdd_src);
// Split into individual channels
vector<Mat> src_chan, tar_chan;
split( src_lab, src_chan );
split( tar_lab, tar_chan );
// For each channel calculate the color distribution
for( int i = 0; i < 3; i++ ) {
tar_chan[i] -= mean_tar.at<double>(i);
tar_chan[i] *= (stdd_src.at<double>(i) / stdd_src.at<double>(i));
tar_chan[i] += mean_src.at<double>(i);
}
//Merge the channels, convert to CV_8UC1 each channel and convert to BGR
Mat output;
merge(tar_chan, output);
output.convertTo(output,CV_8UC1);
cvtColor(output, output, COLOR_Lab2BGR );
//show pictures
namedWindow("Source image", WINDOW_AUTOSIZE );
imshow("Source image",src);
namedWindow("Target image", WINDOW_AUTOSIZE );
imshow("Target image",tar);
namedWindow("Result image", WINDOW_AUTOSIZE );
imshow("Result image",output);
waitKey(0);
return 0;
}
下图显示了代码的输出:
夜间外观颜色转移示例
总结
在本章中,我们对 OpenCV 中使用的色彩空间进行了更深入的介绍,并向您展示了如何使用cvtColor函数在色彩空间之间进行转换。 此外,强调了使用不同颜色模型进行图像处理的可能性以及考虑到我们需要进行的操作选择正确的颜色空间的重要性。 为此,实现了基于颜色空间的分割和颜色转移方法。
下一章将介绍用于视频或一系列图像的图像处理技术。 我们将看到如何使用 OpenCV 实现视频稳定,超分辨率和拼接算法。
五、视频图像处理
本章介绍与视频图像处理有关的各种技术。 尽管大多数经典图像处理都是处理静态图像,但基于视频的处理正变得越来越流行且价格合理。
本章涵盖以下主题:
- 视频稳定
- 视频超分辨率过程
- 图像拼接
在本章中,我们将直接与视频序列或实时摄像机一起使用。 图像处理的输出可以是一组修改的图像或有用的高级信息。 大多数图像处理技术将图像视为二维数字信号,并对其应用不同的技术。 在本章中,将使用视频或实时摄像机的图像序列来使用不同的高级技术来制作或改进新的增强序列。 因此,获得了更多有用的信息,即,结合了第三时间维度。
视频稳定
视频稳定是指用于减少与摄像机运动相关的模糊的一系列方法。 换句话说,它补偿了任何角度移动,等效于摄像机的偏航,俯仰,横滚以及 x 和 y 平移。 最早的图像稳定器出现在 60 年代初期。 这些系统能够略微补偿相机抖动和非自愿移动。 它们由陀螺仪和加速计控制,其机制是通过改变镜头的位置来抵消或减少不必要的运动。 当前,这些方法广泛用于双筒望远镜,摄像机和望远镜。
有多种用于图像或视频稳定的方法,本章重点介绍最广泛的方法系列:
- 机械稳定系统:这些系统在摄像机镜头上使用机械系统,因此在移动摄像机时,加速度计和陀螺仪会检测到运动,并且系统会在运动时产生运动。 镜片。 这些系统将不在此处考虑。
- 数字稳定系统:这些通常是视频中使用的,它们直接作用于从摄像机获得的图像。 在这些系统中,稳定图像的表面略小于源图像的表面。 移动相机时,拍摄的图像也会移动以补偿该移动。 尽管这些技术通过减小运动传感器的可用面积有效地消除了运动,但是却牺牲了分辨率和图像清晰度。
视频稳定算法通常包括以下步骤:

视频稳定算法的一般步骤
本章将放在 OpenCV 3.0 Alpha 中的videostab模块上,该模块包含一组可用于解决视频稳定问题的函数和类。
让我们更详细地探讨一般过程。 视频稳定是通过使用 RANSAC 方法对连续帧之间的帧间运动进行第一估计来实现的。 在此步骤结束时,将获得3 x 3矩阵的数组,并且每个矩阵都描述了两对连续帧的运动。 全局运动估计对于此步骤非常重要,它会影响稳定的最终序列的准确率。
注意
您可以在这个页面上找到有关 RANSAC 方法的更多详细信息。
第二步基于估计的运动生成新的帧序列。 执行其他处理,例如平滑,去模糊,边界外推等,以提高稳定的质量。
第三步消除烦人的不规则扰动,请参见下图。 有一些方法假设了摄像机运动模型,当可以对摄像机的实际运动做出一些假设时,这些方法会很好地起作用。

消除不规则的扰动
在 OpenCV 示例([opencv_source_code]/samples/cpp/videostab.cpp)中,可以找到视频稳定程序示例。 对于以下videoStabilizer示例,videoStabilizer.pro项目需要以下库:lopencv_core300,lopencv_highgui300,lopencv_features2d300,lopencv_videoio300和lopencv_videostab300。
使用 OpenCV 3.0 Alpha 的videostab模块创建了以下videoStabilizer示例:
#include 本示例接受输入视频文件的名称作为默认视频文件名(.\cube4.avi)。 将显示结果视频,然后将其另存为.\cube4_stabilized.avi。 请注意如何包含videostab.hpp标头和使用cv::videostab名称空间。 该示例采取了四个重要步骤。 第一步准备输入视频路径,此示例使用标准命令行输入参数(inputPath = argv[1])选择视频文件。 如果没有输入视频文件,则使用默认视频文件(.\cube4.avi)。
第二步建立运动估计器。 使用 OpenCV(Ptr)的智能指针(Ptr)为运动估计器创建了基于 RANSAC 的鲁棒全局 2D 方法。 有不同的运动模型可以稳定视频:
MM_TRANSLATION = 0MM_TRANSLATION_AND_SCALE = 1MM_ROTATIO = 2MM_RIGID = 3MM_SIMILARITY = 4MM_AFFINE = 5MM_HOMOGRAPHY = 6MM_UNKNOWN = 7
在稳定视频的精度和计算时间之间需要权衡。 基本运动模型越不准确,计算时间就越长。 但是,更复杂的模型具有更好的准确率和更差的计算时间。
现在创建 RANSAC 对象(RansacParams ransac = est-> ransacParams()),并设置它们的参数(ransac.size,ransac.thresh和ransac.eps)。 还需要一个特征检测器来估计稳定器将使用的每个连续帧之间的运动。 本示例使用GoodFeaturesToTrackDetector方法来检测(nkps = 1000)每帧中的显着特征。 然后,它使用鲁棒的 RANSAC 和特征检测器方法使用Ptr类创建运动估计器,并使用motionEstBuilder->setDetector (feature_detector)设置特征检测器。
| RANSAC 参数 |
|---|
size |
eps |
thresh |
prob |
第三步,创建需要先前运动估计器的稳定器。 您可以选择(isTwoPass = 1)一或两遍稳定器。 如果使用两遍稳定器(TwoPassStabilizer *twoPassStabilizer = new TwoPassStabilizer()),结果通常会更好。 但是,在此示例中,这在计算上较慢。 如果使用其他选项单程稳定器(OnePassStabilizer *onePassStabilizer = new OnePassStabilizer()),结果会更糟,但响应速度会更快。 稳定器需要设置其他选项才能正常工作,例如源视频文件(stabilizer->setFrameSource(source))和运动估计器(stabilizer->setMotionEstimator(motionEstBuilder))。 它还需要将稳定器转换为简单的帧源视频以读取稳定的帧(stabilizedFrames.reset(dynamic_cast)。
最后一步使用创建的稳定器稳定视频。 创建processing(Ptr函数来处理和稳定每个帧。 此函数需要引入一条路径来保存生成的视频(string outputPath = ".//stabilizedVideo.avi")和设置播放速度(double outputFps = 25)。 此后,此函数将计算每个稳定的帧,直到不再有帧(stabilizedFrame = stabilizedFrames-> nextFrame().empty())。 在内部,稳定器首先估计每个帧的运动。 此函数创建一个视频编写器(writer.open(outputPath,VideoWriter::fourcc('X','V','I','D'), outputFps, stabilizedFrame.size())),以 XVID 格式存储每个帧。 最后,它保存并显示每个稳定的帧,直到用户按下Esc键。
为了演示如何使用 OpenCV 稳定视频,使用了先前的videoStabilizer示例。 该示例从命令行执行,如下所示:
<bin_dir>\videoStabilizer.exe .\cube4.avi .\cube4_stabilized.avi
注意
该cube4.avi视频可在 OpenCV 示例文件夹中找到。 它还具有大量的相机移动,这对于此示例来说是完美的。
为了显示稳定结果,首先,请参见下图中的cube4.avi的四个帧。 这些帧之后的图显示了cube4.avi和cube4_stabilized.avi的前 10 个帧,没有(图的左侧)和(图的右侧)稳定叠加。

cube4.avi视频的四个连续帧是摄像机的移动

cube4.avi和cube4_stabilizated视频的 10 个叠加帧
通过右图查看上图,您可以看到由于稳定,减少了摄像机运动产生的振动。
超分辨率
超分辨率是指是指通常用于从较低分辨率的图像序列中提高图像或视频空间分辨率的技术或算法。 它与传统的图像缩放技术不同,传统的图像缩放技术使用单个图像来提高分辨率,同时保持锐利的边缘。 相反,超分辨率合并了来自同一场景的多个图像的信息,以表示最初在原始图像中未捕获的细节。
从真实场景捕获图像或视频的过程需要以下步骤:
- 采样:这是连续系统从理想离散系统场景开始的变换,没有混叠
- 几何变换:此是指根据摄像机的位置和镜头系统应用一组变换(例如平移或旋转)来理想地推断到达每个传感器的场景细节
- 模糊:这是由于镜头系统或积分期间场景中的现有运动造成的
- 二次采样:传感器仅对可使用的像素数(照片)进行积分
您可以在下图中看到此图像捕获过程:
从真实场景捕获图像的过程
在此捕获过程中,场景的细节由不同的传感器集成,因此每次捕获中的每个像素都包含不同的信息。 因此,超分辨率基于试图找到获得场景不同细节的不同捕获之间的关系,以便创建具有更多信息的新图像。 因此,超分辨率用于再生具有更高分辨率的离散场景。
可以通过各种技术来获得超分辨率,从空间领域中最直观的技术到基于频谱分析的技术。 技术基本上分为光学技术(使用镜头,变焦等)或基于图像处理的技术。 本章重点介绍基于图像处理的超分辨率。 这些方法使用低分辨率图像或其他无关图像的其他部分来推断高分辨率图像的外观。 这些算法也可以分为频域或空间域。 最初,超分辨率方法仅适用于灰度图像,但是已经开发出新方法来使它们适应彩色图像。
通常,由于低分辨率和高分辨率图像的尺寸很大,并且可能需要数百秒才能生成图像,因此在空间和时间上都需要超分辨率。 为了尝试减少计算时间,当前将预处理器用于负责使这些功能最小化的优化器。 另一种选择是使用 GPU 处理来改善计算时间,因为超分辨率过程固有地可并行化。
本章重点介绍 OpenCV 3.0 Alpha 中的superres模块,其中包含一组可用于解决分辨率增强问题的函数和类。 该模块实现了多种基于图像处理超分辨率的方法。 本章重点介绍已实现的双边总变异 L1(BTVL1)超分辨率方法。 超分辨率过程的主要困难是估计扭曲函数以建立超分辨率图像。 双总变异 L1 使用光流来估计翘曲函数。
注意
您可以在这个页面和这个页面找到双边 TV-L 方法的更多详细信息。
在 OpenCV 示例([opencv_source_code]/samples/gpu/super_resolution.cpp)中,可以找到超分辨率的基本示例。
注意
您还可以从这个页面的 OpenCV GitHub 存储库中下载此示例。
对于以下超分辨率示例项目,superresolution.pro项目文件应包括以下库:lopencv_core300,lopencv_imgproc300,lopencv_highgui300,lopencv_features2d300,lopencv_videoio300和lopencv_superres300才能正常工作:
#include 本示例创建一个程序(超分辨率)以获取具有超分辨率的视频。 它采用输入视频的路径或使用默认视频路径(.\tree.avi)。 显示所得的视频并将其另存为.\tree_superresolution.avi。 首先,包含superres.hpp和superres/optical_flow.hpp标头,并使用cv::superres命名空间。 该示例遵循四个重要步骤。
第一步设置初始参数。 输入视频路径使用标准输入(inputVideoName = argv[1])选择视频文件,如果没有输入视频文件,则使用默认视频文件。 输出视频路径还使用输入标准(outputVideoName = argv[2])选择输出视频文件,如果它没有输出视频文件,则使用默认输出视频文件(.\tree_superresolution)同时也设置输出回放速度(double outputFps = 25.0)。 superresolution方法的其他重要参数是比例因子(const int scale = 4),迭代count(const int iterations = 100,时间搜索区域的半径(const int temporalAreaRadius = 4)和光流算法(string optFlow = "farneback")。 。
第二步创建光流方法以检测显着特征并针对每个视频帧跟踪它们。 已经创建了一种新方法(static Ptr),以便在不同的光流方法之间进行选择。 您可以在 Farneback,TVL1,Brox 和 Pyrlk 光流方法之间进行选择。 编写了新的方法(static Ptr),以创建光学流动方法来跟踪特征。 两个最重要的方法是 Farneback(createOptFlow_Farneback())和 TV-L1(createOptFlow_DualTVL1())。 第一种方法基于 Gunner Farneback 的算法,该算法计算帧中所有点的光流。 第二种方法基于电视能量的双重公式计算两个图像帧之间的光流,并采用有效的逐点阈值化步骤。 此第二种方法在计算上更有效。
| 不同光流方法之间的比较 | ||
|---|---|---|
| 方法 | 复杂度 | 可并行化 |
| Farneback | 二次 | 否 |
| TVL1 | 线性 | 是 |
| Brox | 线性 | 是 |
| Pyrlk | 线性 | 否 |
注意
您还可以在此处了解有关 Farneback 光流方法的更多信息。
第三步创建并设置superresolution方法。 创建此方法的一个实例(Ptr),该实例使用双边总变异 L1 算法(superRes = createSuperResolution_BTVL1())。 对于算法,此方法具有以下参数:
scale:这是比例因子iterations:这是迭代计数tau:这是最速下降法的渐近值lambda:这是权重参数,用于平衡数据项和平滑度项alpha:这是双边电视中空间分布的参数btvKernelSize:这是双边电视过滤器的核大小blurKernelSize:这是高斯模糊核大小blurSigma:这是高斯模糊西格玛temporalAreaRadius:这是时间搜索区域的半径opticalFlow:这是一种密集光流算法
这些参数设置如下:
superRes->set("parameter", value);
仅设置以下参数; 其他参数使用其默认值:
superRes->set("opticalFlow", optical_flow);
superRes->set("scale", scale);
superRes->set("iterations", iterations);
superRes->set("temporalAreaRadius", temporalAreaRadius);
之后,选择输入视频帧(superRes->setInput(frameSource))。
最后一步处理输入视频以计算超分辨率。 对于每个视频帧,计算超分辨率(superRes->nextFrame(result)); 这种计算在计算上非常慢,因此估计处理时间可以显示进度。 最后,显示每个结果帧(imshow("Super Resolution", result))并保存(writer << result)。
为了显示超分辨率的结果,比较了tree.avi和tree_superresolution.avi视频的第一帧的一小部分是否有超分辨率:

tree.avi和tree_superresolution.avi视频的第一帧的一部分,不包括超分辨率处理
在上图的右侧部分,由于超分辨率过程,您可以在树的叶子和树枝中观察到更多细节。
拼接
图像拼接或照片拼接可以发现具有一定程度重叠的图像之间的对应关系。 此过程将一组图像与重叠的视场组合在一起,以生成全景图像或高分辨率图像。 大多数用于图像拼接的技术需要在图像之间几乎完全重叠以产生无缝结果。 一些数码相机可以在内部拼接一组图像以构建全景图像。 下图显示了一个示例:

通过拼接创建的全景图像
注意
可以在这个页面上找到前面的图像示例和有关图像拼接的更多信息。
拼接通常可以分为三个重要步骤:
- 配准(图像)表示一组图像中的匹配特征以搜索使重叠像素之间差异的绝对值之和最小的位移。 直接比对方法可用于获得更好的结果。 用户还可以添加全景图的粗略模型以帮助特征匹配阶段,在这种情况下,结果通常更准确且计算速度更快。
- 校准(图像)将重点放在最小化理想模型和相机镜头系统之间的差异:不同的相机位置和光学缺陷,例如失真,曝光,色差等。
- 合成(图像)使用上一步校准的结果,并将图像重新映射到输出投影。 图像之间的颜色也会进行调整,以补偿曝光差异。 将图像融合在一起,并进行接缝线调整以最小化图像之间接缝的可见性。
当从空间的同一点拍摄了图像片段时,可以使用各种地图投影之一进行拼接。 最重要的地图投影如下所示:
- 直线投影:在这里,在与全景球在一个点相交的二维平面上查看拼接图像。 无论图像上的方向如何,现实中笔直的线都显示类似。 当视野开阔(大约 120 度)时,图像在边框附近会变形。
- 圆柱投影:此处,拼接图像显示 360 度水平视场和有限的垂直视场。 该投影旨在被视为好像图像被包裹在圆柱体中并从内部观看。 在 2D 平面上查看时,水平线看起来是弯曲的,而垂直线则保持笔直。
- 球形投影:在这里,拼接图像显示了 360 度水平视野和 180 度垂直视野,即整个球体。 具有这种投影的全景图像旨在像被包裹在一个球体中并从内部观看一样被观看。 在 2D 平面上查看时,水平线看起来像圆柱投影一样弯曲,而垂直线则保持垂直。
- 立体投影或鱼眼投影:通过将虚拟摄像机指向下方并将视场设置为足够大以显示整个地面及其上方的某些区域,可以将其用于形成一个小行星全景。 将虚拟摄像机指向上方会产生隧道效果。
- 帕尼尼投影:这具有专业投影,可能比常规制图投影在美学上更具优势。 此投影将同一图像中的不同投影组合在一起,以微调输出全景图像的最终外观。
本章重点介绍 OpenCV 3.0 Alpha 中的stitching模块和detail子模块,其中包含实现拼接器的一组函数和类。 使用这些模块,可以配置或跳过某些步骤。 实现的缝合示例具有以下常规示意图:

在 OpenCV 示例中,有两个基本的缝合示例,可以在([opencv_source_code]/samples/cpp/stitching.cpp])和([opencv_source_code]/samples/cpp/stitching_detailed.cpp])处找到。
对于以下,更高级的拼接示例,stitchingAdvanced.pro项目文件必须包含以下库才能正常工作:lopencv_core300,lopencv_imgproc300,lopencv_highgui300,lopencv_features2d300,lopencv_videoio300, lopencv_imgcodecs300和lopencv_stitching300:
#include 此示例创建一个程序,以使用 OpenCV 步骤拼接图像。 它采用输入路径来选择不同的输入图像或使用默认的输入图像(.\panorama_image1.jpg和panorama_image2.jpg),这些将在后面显示。 最后,显示所得图像并将其另存为.\panorama_result.jpg。 首先,包含stitching.hpp和detail标头,并使用cv::detail命名空间。 还设置了更重要的参数,您可以使用这些参数配置针迹处理。 如果您需要使用自定义配置,则了解拼接过程的总体图(上图)非常有用。 这个高级示例包含 11 个重要步骤。 第一步读取并检查输入图像。 本示例需要两个或更多图像才能工作。
第二步使用double scale = 1参数调整输入图像的大小,并在每个图像上找到特征; 您可以使用string features_type = "orb"参数在 Surf(finder = makePtr)或 Orb(finder = makePtr)特征查找器之间进行选择。 之后,此步骤将调整输入图像的大小(resize(full_img, img, Size(), scale, scale))并找到特征((*finder)(img, features[i]))。
注意
有关 SURF 和 ORB 描述符的更多信息,请参阅 Packt Publishing 的《OpenCV Essentials》的第 5 章。
第三步匹配先前找到的特征。 使用float match_conf = 0.3f参数创建一个匹配器(BestOf2NearestMatcher matcher(false, match_conf))。
第四步,选择图像并匹配子集以构建全景图。 然后,使用vector函数选择并匹配最佳特征。 通过这些特征,将创建一个新的子集以供使用。
第五步,使用包调整来全局调整的参数,以构建调整器(Ptr)。 给定一组从不同视点描绘多个 2D 或 3D 点的图像,可以将束调整定义为同时细化 2D 或 3D 坐标,描述场景几何形状,以及所部署的相机的相对运动和光学特性参数,根据涉及所有点的相应图像投影的最优性标准,来获取图像。 有两种计算束调整的方法,reproj(adjuster = makePtr)或ray(adjuster = makePtr),这些方法是通过string adjuster_method = "ray"参数选择的。 最后,将该束调整用作(*adjuster)(features, pairwise_matches, cameras)。
第六步是可选步骤(bool do_wave_correct = true),该步骤计算波形相关性以改善相机设置。 波相关的类型通过WaveCorrectKind wave_correct_type = WAVE_CORRECT_HORIZ参数选择,并计算为waveCorrect(rmats, wave_correct_type)。
第七步,创建需要地图投影的变形图像。 地图投影以前已经描述过,可以是直线,圆柱,球形,立体或帕尼尼。 实际上,OpenCV 中实现了更多的地图投影。 可以使用string warp_type = "spherical"参数选择地图投影。 此后,创建整形器(Ptr),并变形每个图像(warper->warp(masks[i], K, cameras[i].R, INTER_NEAREST, BORDER_CONSTANT, masks_warped[i]))。
第八步通过创建补偿器(Ptr)补偿曝光误差,并将其应用于每个变形图像(compensator->feed(corners, images_warped, masks_warped))。
第九步找到接缝口罩。 此过程将为每个全景图像搜索最佳的附件区域。 OpenCV 中实现了一些方法来执行此任务,并且本示例使用string seam_find_type = "gc_color"参数进行选择。 这些方法是NoSeamFinder(不使用此方法),VoronoiSeamFinder,GraphCutSeamFinderBase::COST_COLOR,GraphCutSeamFinderBase::COST_COLOR_GRAD,DpSeamFinder::COLOR和DpSeamFinder::COLOR_GRAD。
第十步,创建一个混合器,将每个图像合成全景图。 OpenCV 中实现了两种类型的搅拌器,即MultiBandBlender* mb = dynamic_cast和FeatherBlender* fb = dynamic_cast,可以使用int blend_type = Blender::MULTI_BAND参数进行选择。 最后,准备搅拌器(blender->prepare(corners, sizes))。
最后一步合成了最终的全景图。 该步骤需要前面的步骤来配置针脚。 执行四个子步骤以计算最终全景图。 首先,读取每个输入图像(full_img = imread(img_names[img_idx])),并在必要时调整其大小(resize(full_img, img, Size(), scale, scale))。 其次,将这些图像与创建的变形器(warper->warp(img, K, cameras[img_idx].R, INTER_LINEAR, BORDER_REFLECT, img_warped))变形。 第三,使用创建的补偿器(compensator->apply(img_idx, corners[img_idx], img_warped, mask_warped))补偿这些图像的曝光误差。 最后,使用创建的混合器混合这些图像。 现在,最终结果全景图已保存在string result_name = "panorama_result.jpg"文件中。
为了向您显示高级拼接结果,将两个输入图像进行拼接,结果全景图如下所示:

总结
在本章中,您学习了如何使用 OpenCV 的三个重要模块来处理视频中的图像处理。 这些模块是视频稳定,超分辨率和拼接。 每个模块还解释了一些理论基础。
在本章的每一节中,都将说明用 C++ 开发的完整示例。 还显示了每个模块的图像结果,显示了主要效果。
下一章介绍高动态范围图像,并向您展示如何使用 OpenCV 处理它们。 通常在现在称为计算摄影的范围内考虑高动态范围成像。 粗略地说,计算摄影是指允许您扩展数字摄影的典型功能的技术。 这可能包括硬件附加组件或修改,但主要指基于软件的技术。 这些技术可能会产生“传统”数码相机无法获得的输出图像。