python pandas 行转列_pandas行转列、列转行、以及一行生成多行
楔子
笔者曾经碰到过两种格式的数据,当时确实把我难住了,最后虽然解决了,但是方法不够优雅,而且效率也不高,如果想高效率,那么就必须使用pandas提供的方法。而pandas作为很强的一个库,一定可以优雅地解决。当时用自己的方法解决之后,就没有之后了。但是最近又碰到了当时的情况,于是决定要优雅地解决,最后经过努力总算找到了解决的办法,下面先来看看当时难住笔者的两种格式的数据、以及需求吧。
需求一:
有以下格式的数据:
姓名 科目 成绩
小红 语文 90
小红 数学 90
小红 英语 90
小胖 语文 91
小胖 数学 91
小胖 英语 91
小花 语文 92
小花 数学 92
小花 英语 92
我们要变成以下的样子
姓名 语文 数学 英语
小红 90 90 90
小胖 91 91 91
小花 92 92 92
需求二:
姓名 年龄 爱好
小红 18 跳舞,唱歌,钢琴
小胖 20 唱,跳,rap,篮球
小花 19 古筝,翻译
我们要变成以下的样子
姓名 年龄 爱好
小红 18 跳舞
小红 18 唱歌
小红 18 钢琴
小胖 20 唱
小胖 20 跳
小胖 20 rap
小胖 20 篮球
小花 19 古筝
小花 19 翻译
解决需求一
unstack
print(df)
"""
姓名 科目 分数
0 小红 语文 90
1 小红 数学 90
2 小红 英语 90
3 小胖 语文 91
4 小胖 数学 91
5 小胖 英语 91
6 小花 语文 92
7 小花 数学 92
8 小花 英语 92
"""
# 将姓名和科目设置索引,然后只取出"分数",得到对应的二级索引Series对象
df = df.set_index(["姓名", "科目"])
two_level_index_series = df["分数"]
# 此时得到的是一个具有二级索引的series
print(two_level_index_series)
"""
姓名 科目
小红 语文 90
数学 90
英语 90
小胖 语文 91
数学 91
英语 91
小花 语文 92
数学 92
英语 92
Name: 分数, dtype: int64
"""
# 调用二级索引的unstack方法,会得到一个DataFrame
# 并且会自动把一级索引变成DataFrame的索引,二级索引变成DataFrame的列
new_df = two_level_index_series.unstack()
print(new_df)
"""
科目 数学 英语 语文
姓名
小红 90 90 90
小胖 91 91 91
小花 92 92 92
"""
# 怎么样是不是改回来了呢?但是还有不完美的地方
# 那就是这个new_df的index和columns都有名字
# index的名字就是"姓名",columns的名字就是"科目",因为原来的series的两个索引就叫"姓名"和"分数"
# rename_axis表示给坐标轴重命名
# 这里先把columns的名字变为空,至于index不为空的原因继续看
new_df = new_df.rename_axis(columns=None)
print(new_df)
"""
数学 英语 语文
姓名
小红 90 90 90
小胖 91 91 91
小花 92 92 92
"""
new_df = new_df.reset_index()
print(new_df)
"""
姓名 数学 英语 语文
0 小红 90 90 90
1 小胖 91 91 91
2 小花 92 92 92
"""
# 大功告成,如果index变为空的话,那么在reset_index之后,列名会变成index
# 但是如果原来索引有名字,reset_index,列名就是原来的索引名
pivot
pivot相当于是我们上面方法的一个化简,我们是把姓名作为索引、科目作为列、分数作为值
print(df)
"""
姓名 科目 分数
0 小红 语文 90
1 小红 数学 90
2 小红 英语 90
3 小胖 语文 91
4 小胖 数学 91
5 小胖 英语 91
6 小花 语文 92
7 小花 数学 92
8 小花 英语 92
"""
df = pd.pivot(df, index="姓名", columns="科目", values="分数")
print(df)
"""
科目 数学 英语 语文
姓名
小红 90 90 90
小胖 91 91 91
小花 92 92 92
"""
# 可以看到上面这一步,就直接相当于df.set_index(["姓名", "科目"])["分数"].unstack()
df = df.rename_axis(columns=None).reset_index()
print(df)
"""
姓名 数学 英语 语文
0 小红 90 90 90
1 小胖 91 91 91
2 小花 92 92 92
"""
解决需求二:
print(df)
"""
姓名 年龄 爱好
小红 18 跳舞,唱歌,钢琴
小胖 20 唱,跳,rap,篮球
小花 19 古筝,翻译
"""
df = df.set_index(["姓名", "年龄"])["爱好"].str.split(",", expand=True).stack().reset_index(drop=True, level=-1).reset_index().rename(columns={0: "爱好"})
print(df)
"""
姓名 年龄 爱好
0 小红 18 跳舞
1 小红 18 唱歌
2 小红 18 钢琴
3 小胖 20 唱
4 小胖 20 跳
5 小胖 20 rap
6 小胖 20 篮球
7 小花 19 古筝
8 小花 19 翻译
"""
估计有人会懵逼,别急我们来一步一步拆解,不过在此之前我们先来介绍一下unstack和stack
unstack和stack
首先Series只有unstack,DataFrame既有unstack又有stack。对于Series来说,我们刚才说了,unstack是把该Series变成一个DataFrame,并且会把当前的一级索引变成DataFrame的对应索引、二级索引变成DataFrame的对应列,但如果不止二级呢?假设这个Series有8级索引呢?其实不管有多少级,假设n级,unstack不加参数的话,那么默认是把最后一级索引变成DataFrame的列,前面的n-1个索引则依旧会变成DataFrame的索引,当然也是n-1个。
为了和DataFrame做对比,我们就假设为2级索引。对于Series来说,unstack是把1级索引变成对应DataFrame的索引,2级索引是变成对应DataFrame的列。如果对DataFrame调用unstack,那么会把这个DataFrame转成一个具有二级索引的Series(如果这个DataFrame的索引只有一级的话),对应的索引变成具有二级索引的Series的二级索引,对应的列变成具有二级索引Series的一级索引。如果是stack的话,那么和Series正好是相反的,DataFrame的索引变成具有二级索引Series的一级索引,列变成具有二级索引Series的二级索引。
文字不好懂的话,看一张图
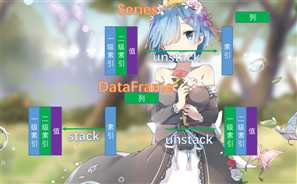
下面我们就来分析一下上面的那一长串
print(df)
"""
姓名 年龄 爱好
小红 18 跳舞,唱歌,钢琴
小胖 20 唱,跳,rap,篮球
小花 19 古筝,翻译
"""
# 我们是对"爱好"这个字段进行分解
# 那么将除了"爱好"之外的其它字段设置为索引
df = df.set_index(["姓名", "年龄"])
print(df)
"""
爱好
姓名 年龄
小红 18 跳舞,唱歌,钢琴
小胖 20 唱,跳,rap,篮球
小花 19 古筝,翻译
"""
# 筛选出"爱好"这个字段,此时得到的是一个具有二级索引的Series
# 索引的名字叫 "姓名"和"年龄"
s = df["爱好"]
print(s)
"""
姓名 年龄
小红 18 跳舞,唱歌,钢琴
小胖 20 唱,跳,rap,篮球
小花 19 古筝,翻译
Name: 爱好, dtype: object
"""
# 那么下面就对期望的字段进行分解
# 我们这个例子都是以逗号为分隔符,至于具体是什么则以实际数据为准
# 显然这里得到一个具有二级索引的DataFrame
df = s.str.split(",", expand=True)
print(df)
"""
0 1 2 3
姓名 年龄
小红 18 跳舞 唱歌 钢琴 None
小胖 20 唱 跳 rap 篮球
小花 19 古筝 翻译 None None
"""
# 调用stack,按照前面说的,会变成一个Series,索引就是DataFrame的索引再加上这个列变成的索引,显然列变成的索引就是三级索引了
# 可以看成是把DataFrame的索引看成一个整体作为对应Series的一级索引了
s = df.stack()
# 此时的数据已经像那么回事了
print(s)
"""
姓名 年龄
小红 18 0 跳舞
1 唱歌
2 钢琴
小胖 20 0 唱
1 跳
2 rap
3 篮球
小花 19 0 古筝
1 翻译
dtype: object
"""
# 然后调用reset_index,但是我们发现索引有三级,那么这样做就会导致,0 1 2 0 1 2..这些也变成了一列,当然可以之后drop掉
# 但是我们也可以直接删掉
# 于是我们可以加上一个drop=True,但是这样又把所有的index都删掉了,于是我们可以指定一个level
# 由于三级索引,那么最后一级就是2,当然可以直接指定为-1,表示最后一级,表示把最后一级索引删掉
s = s.reset_index(drop=True, level=-1)
print(s)
"""
姓名 年龄
小红 18 跳舞
18 唱歌
18 钢琴
小胖 20 唱
20 跳
20 rap
20 篮球
小花 19 古筝
19 翻译
dtype: object
"""
# 但是我们发现,上面的reset_index(drop=True, level=-1)并没有把前面的索引变成列
# 这是因为我们指定了level,如果不指定level,那么drop=True会把所有的索引都删掉
# 但指定了level只会删除对应级别的索引,而不会同时对前面的索引进行reset,于是需要再调用一次reset_index,此时就什么也不需要指定了
df = s.reset_index()
# 会自动进行笛卡尔乘积
print(df)
"""
姓名 年龄 0
0 小红 18 跳舞
1 小红 18 唱歌
2 小红 18 钢琴
3 小胖 20 唱
4 小胖 20 跳
5 小胖 20 rap
6 小胖 20 篮球
7 小花 19 古筝
8 小花 19 翻译
"""
# 但是我们发现列名,是自动生成的0,于是再进行rename
df = df.rename(columns={0: "爱好"})
print(df)
"""
姓名 年龄 爱好
0 小红 18 跳舞
1 小红 18 唱歌
2 小红 18 钢琴
3 小胖 20 唱
4 小胖 20 跳
5 小胖 20 rap
6 小胖 20 篮球
7 小花 19 古筝
8 小花 19 翻译
"""
# 此时就大功告成啦