优化查询语句的性能是 MySQL 数据库管理中的一个重要方面。在优化查询性能时,选择正确的索引对于减少查询的响应时间和提高系统性能至关重要。但是,如何确定 MySQL 的索引选择策略?MySQL 的优化器是如何选择索引的?
在这篇《索引失效了?看看这几个常见的情况!》文章中,我们介绍了索引区分度不高可能会导致索引失效,而这里的“不高”并没有具体量化,实际上 MySQL 会对执行计划进行成本估算,选择成本最低的方案来执行。具体我们还是通过一个案例来说明。
案例
还是以人物表为例,我们来看一下优化器是怎么选择索引的。
建表语句如下:
CREATE TABLE `person` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(64) NOT NULL,
`score` int(11) NOT NULL,
`age` int(11) NOT NULL,
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `idx_name_score` (`name`,`score`) USING BTREE,
KEY `idx_age` (`age`) USING BTREE,
KEY `idx_create_time` (`create_time`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4;然后插入 10 万条数据:
create PROCEDURE `insert_person`()
begin
declare c_id integer default 3;
while c_id <= 100000 do
insert into person values(c_id, concat('name',c_id), c_id + 100, c_id + 10, date_sub(NOW(), interval c_id second));
-- 需要注意,因为使用的是now(),所以对于后续的例子,使用文中的SQL你需要自己调整条件,否则可能看不到文中的效果
set c_id = c_id + 1;
end while;
end;
CALL insert_person();可以看到,最早的 create_time 是 2023-04-14 13:03:44。
我们通过下面的SQL语句对person表进行查询:
explain select * from person where NAME>'name84059' and create_time>'2023-04-15 13:00:00'
通过执行计划,我们可以看到 type=All,表示这是一次全表扫描。接着,我们将 create_time 条件中的 13 点改为 15 点,再次执行查询:
explain select * from person where NAME>'name84059' and create_time>'2023-04-15 15:00:00'
这次执行计划显示 type=range,key=create_time,表示 MySQL 优化器选择了 create_time 索引来执行这个查询,而不是使用 name_score 联合索引。
也许你会对此感到奇怪,接下来,我们一起来分析一下背后的原因。
OPTIMIZER_TRACE 工具介绍
为了更好地理解 MySQL 优化器的工作原理,我们可以使用一个强大的调试工具:OPTIMIZER_TRACE。它是在 MySQL 5.6 及之后的版本中提供的,可以查看详细的查询执行计划,包括查询优化器的决策、选择使用的索引、连接顺序和优化器估算的行数等信息。
当开启 OPTIMIZER_TRACE 时,MySQL 将会记录查询的执行计划,并生成一份详细的报告。这个报告可以提供给开发人员或数据库管理员进行分析,以了解 MySQL 是如何决定执行查询的,进而进行性能优化。
在 MySQL 中,开启 OPTIMIZER_TRACE 需要在查询中使用特定的语句,如下所示:
SET optimizer_trace='enabled=on';
SELECT * FROM mytable WHERE id=1;
SET optimizer_trace='enabled=off';当执行查询后,MySQL将会生成一个 JSON 格式的执行计划报告。
需要注意的是,开启 OPTIMIZER_TRACE 会增加查询的执行时间和资源消耗,因此只应该在需要调试和优化查询性能时使用。
官方文档在这里:https://dev.mysql.com/doc/dev/mysql-server/latest/PAGE_OPT_TR...
全表扫描的总成本
MySQL 在查询数据之前,首先会根据可能的执行方案生成执行计划,然后依据成本决定走哪个执行计划。这里的成本,包括 IO 成本和 CPU 成本:
- IO 成本,是从磁盘把数据加载到内存的成本。默认情况下,读取数据页的 IO 成本常数是 1(也就是读取 1 个页成本是 1)。
- CPU 成本,是检测数据是否满足条件和排序等 CPU 操作的成本。默认情况下,检测记录的成本是 0.2。
MySQL 维护了表的统计信息,可以使用下面的命令查看:
SHOW TABLE STATUS LIKE 'person'该命令将返回包括表的行数、数据长度、索引大小等信息。这些信息可以帮助 MySQL 优化器做出更好的决策,选择更优的执行计划。我们使用上述命令查看 person 表的统计信息。
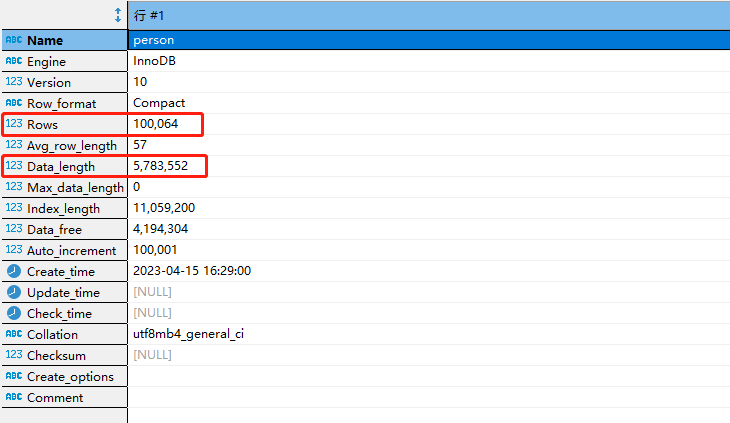
图中总行数为 100064 行(由于 MySQL 的统计信息是一个估算,多出 64 行是正常的),CPU 成本是 100064 * 0.2 = 20012.8 左右。
数据长度是 5783552 字节。对于 InnoDB 存储引擎来说,5783552 就是聚簇索引占用的空间,等于聚簇索引的页数量 * 每个页面的大小。InnoDB 每个页面的大小是 16KB,因此我们可以算出页的数量是 353,因此 IO 成本是 353 左右。
所以,全表扫描的总成本是 20365.8 左右。
追踪 MySQL 选择索引的过程
select * from person where NAME>'name84059' and create_time>'2023-04-15 13:00:00'上面这条语句可能执行的策略有:
- 使用 name_score 索引;
- 使用 create_time 索引;
- 全表扫描;
接着我们开启 OPTIMIZER_TRACE 追踪:
SET OPTIMIZER_TRACE="enabled=on",END_MARKERS_IN_JSON=on;
SET optimizer_trace_offset=-30, optimizer_trace_limit=30;依次执行下面的语句。
select * from person where NAME >'name84059';
select * from person where create_time>'2023-04-15 13:00:00';
select * from person;然后查看追踪结果:
select * from information_schema.OPTIMIZER_TRACE;
SET optimizer_trace="enabled=off";我从 OPTIMIZER_TRACE 的执行结果中,摘出了几个重要片段来重点分析:
1、使用 name_score 对 name84059 30435 是查询二级索引的 IO 成本和 CPU 成本之和,再加上回表查询聚簇索引的 IO 成本和 CPU 成本之和。 2、使用 create_time 进行索引扫描需要扫描 27566 行,成本是 33080。 3、全表扫描 100064 条记录的成本是 20366。 所以 MySQL 最终选择了全表扫描方式作为执行计划。 把 SQL 中的 create_time 条件从 13:00 改为 15:00,再次分析 OPTIMIZER_TRACE 可以看到: 因为是查询更晚时间的数据,走 create_time 索引需要扫描的行数从 33080 减少到了 7919.8。这次走这个索引的成本 7919.8 小于全表扫描的 20366,更小于走 name_score 索引的 31705。 所以这次执行计划选择的是走 create_time 索引。 优化器有时会因为统计信息的不准确或成本估算的问题,实际开销会和 MySQL 统计出来的差距较大,导致 MySQL 选择错误的索引或是直接选择走全表扫描,这个时候就需要人工干预,使用强制索引了。 比如,像这样强制走 name_score 索引:{
"index": "idx_name_score",
"ranges": [
"name84059 < name"
] /* ranges */,
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 26420,
"cost": 31705,
"chosen": true
}{
"index": "idx_create_time",
"ranges": [
"2023-04-15 13:00:00 < create_time"
] /* ranges */,
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 27566,
"cost": 33080,
"chosen": true
}{
"considered_execution_plans": [
{
"plan_prefix": [
] /* plan_prefix */,
"table": "`person`",
"best_access_path": {
"considered_access_paths": [
{
"access_type": "scan",
"rows": 100064,
"cost": 20366,
"chosen": true
}
] /* considered_access_paths */
} /* best_access_path */,
"cost_for_plan": 20366,
"rows_for_plan": 100064,
"chosen": true
}
] /* considered_execution_plans */
}{
"index": "idx_create_time",
"ranges": [
"2023-04-15 15:00:00 < create_time"
] /* ranges */,
"index_dives_for_eq_ranges": true,
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 6599,
"cost": 7919.8,
"chosen": true
}人工干预
explain select * from person FORCE INDEX(name_score) where NAME >'name84059' and create_time>'2023-04-15 13:00:00'