darknet-19与darknet53
Darknet是最经典的一个深层网络,结合Resnet的特点在保证对特征进行超强表达的同时又避免了网络过深带来的梯度问题,主要有Darknet19和Darknet53。
引言,为什么学这个
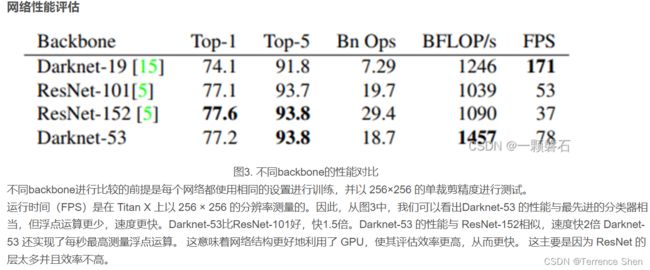
yolo v3用于提取特征的backbone是Darknet-53,他借鉴了yolo v2中的网络(Darknet-19)结构,在名字上我们也可以窥出端倪。不同于Darknet-19的是,Darknet-53引入了大量的残差结构,并且使用步长为2,卷积核大小为3×3卷积层Conv2D代替池化层Maxpooling2D。通过在ImageNet上的分类表现,Darknet-53经过以上改造在保证准确率的同时极大地提升了网络的运行速度,证明了Darknet-53在特征提取能力上的有效性。

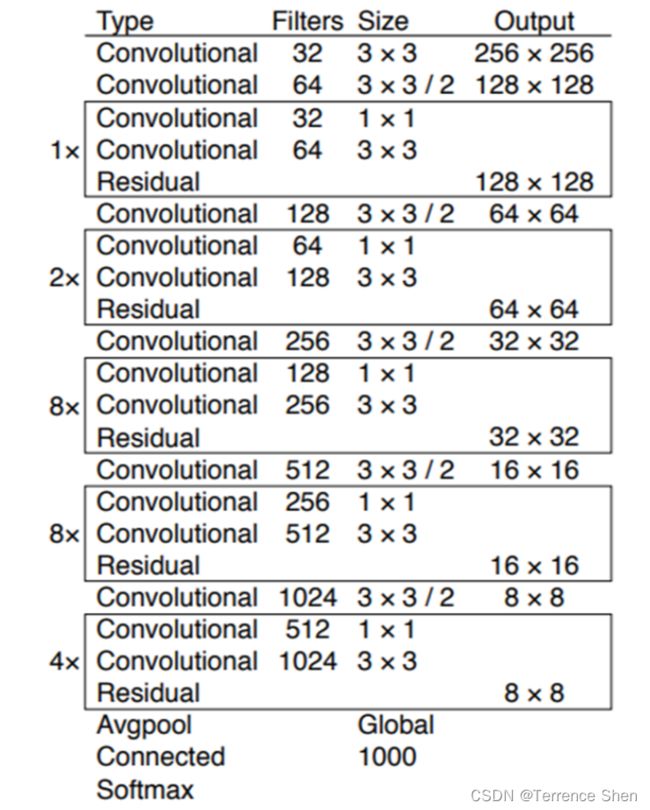
从图中可以看出,网络中堆叠了大量的残差结构Residual,而且每两个残差结构之间插着一个步长为2,卷积核大小为3×3卷积层,用于完成下采样的操作。在源码中,Darknet-53网络的输入尺寸是416416,最后卷积层输出的特征图尺寸为1313,通道数为1024。如果是分类任务,最后一个残差结构之后接入全局池化层Global Avgpool,1000个神经元的全连接层Connected,以及一个激活函数层Softmax。但是,在YOLO v3中,Darknet-53只用于提取特征,所以没有最后的这三层(去掉最后的部分,接上neck和head,充当backbone的作用),只是输出了三种不同尺寸的特征图(13 * 13、26 * 26、52 * 52)。
Darknet-53中残差单元的网络结构

基本介绍
The Darknet-53 network structure is a deep convolutional neural network that is commonly used in object detection, image recognition, and other computer vision tasks. This network is designed to handle the challenges of detecting objects and patterns in images that are taken in low light or low contrast environments, where traditional image recognition networks struggle. The Darknet-53 network has over 53 layers of neural network structures, which allows it to learn and identify image features at different scales and abstract levels. Its unique architecture allows it to process images quickly and accurately, making it a powerful tool for a wide range of image and video analysis applications. The Darknet-53 network structure has gained popularity in recent years due to its superior accuracy, efficiency, and versatility.
Darknet-53 网络结构是一种深度卷积神经网络,常用于目标检测、图像识别和其他计算机视觉任务。 该网络旨在应对检测在低光或低对比度环境中拍摄的图像中的对象和模式的挑战,传统图像识别网络在这些环境中难以应对。 Darknet-53 网络拥有超过 53 层的神经网络结构,使其能够学习和识别不同尺度和抽象层次的图像特征。 其独特的架构使其能够快速准确地处理图像,使其成为广泛的图像和视频分析应用程序的强大工具。 Darknet-53 网络结构近年来因其卓越的准确性、效率和通用性而受到欢迎。
网络设计
网络结构设计理念
Darknet-53在Darknet-19的基础上增加了大量的残差结构Residual,并且使用步长为2,卷积核大小为3×3卷积层Conv2D代替池化层Maxpooling2D。作者为什么要做这两点改进呢?
残差结构
首先,加入残差结构Residual的目的是为了增加网络的深度,用于支持网络提取更高级别的语义特征,同时残差的结构可以帮助我们避免梯度的消失或爆炸。因为残差的物理结构,反映到反向梯度传播中,可以使得梯度传递到前面很远的网络层中,削弱反向求导的链式反应。
其次,我们看到残差结构单元里边输入首先会经过一个1×1的卷积层将输入通道降低一半,然后再进行3×3的卷积,这在相当程度上帮助网络减少了计算量,使得网络的运行速度更快,效率更高。
步长为2的卷积替换池化层
从作用上来说,步长为2的卷积替换池化层都可以完成下采样的工作,但其实现在的神经网络中,池化层已经比较少了,大家都开始尝试其他的下采样方法,比如步长为2的卷积。那么为什么要这样替换呢?参考CNN为什么不需要池化层下采样了?.
对于池化层和步长为2的卷积层来说,个人的理解是这样的,池化层是一种先验的下采样方式,即人为的确定好下采样的规则(选取覆盖范围内最大的那个值,默认最大值包含的信息是最多的);而对于步长为2的卷积层来说,其参数是通过学习得到的,采样的规则是不确定的,这种不确定性会增加网络的学习能力。
代码实现
class Conv_BN_LeakyReLU(nn.Module):
def __init__(self, in_channels, out_channels, ksize, padding=0, dilation=1):
super(Conv_BN_LeakyReLU, self).__init__()
self.convs = nn.Sequential(
nn.Conv2d(in_channels, out_channels, ksize, padding=padding, dilation=dilation),
nn.BatchNorm2d(out_channels),
nn.LeakyReLU(0.1, inplace=True)
)
def forward(self, x):
return self.convs(x)
class DarkNet_19(nn.Module):
def __init__(self, num_classes=1000):
print("Initializing the darknet19 network ......")
super(DarkNet_19, self).__init__()
# backbone network : DarkNet-19
# output : stride = 2, c = 32
self.conv_1 = nn.Sequential(
Conv_BN_LeakyReLU(3, 32, 3, 1),
nn.MaxPool2d((2,2), 2),
)
# output : stride = 4, c = 64
self.conv_2 = nn.Sequential(
Conv_BN_LeakyReLU(32, 64, 3, 1),
nn.MaxPool2d((2,2), 2)
)
# output : stride = 8, c = 128
self.conv_3 = nn.Sequential(
Conv_BN_LeakyReLU(64, 128, 3, 1),
Conv_BN_LeakyReLU(128, 64, 1),
Conv_BN_LeakyReLU(64, 128, 3, 1),
nn.MaxPool2d((2,2), 2)
)
# output : stride = 16, c = 256
self.conv_4 = nn.Sequential(
Conv_BN_LeakyReLU(128, 256, 3, 1),
Conv_BN_LeakyReLU(256, 128, 1),
Conv_BN_LeakyReLU(128, 256, 3, 1),
nn.MaxPool2d((2,2), 2)
)
# output : stride = 32, c = 512
self.conv_5 = nn.Sequential(
Conv_BN_LeakyReLU(256, 512, 3, 1),
Conv_BN_LeakyReLU(512, 256, 1),
Conv_BN_LeakyReLU(256, 512, 3, 1),
Conv_BN_LeakyReLU(512, 256, 1),
Conv_BN_LeakyReLU(256, 512, 3, 1),
nn.MaxPool2d((2,2), 2)
)
# output : stride = 32, c = 1024
self.conv_6 = nn.Sequential(
Conv_BN_LeakyReLU(512, 1024, 3, 1),
Conv_BN_LeakyReLU(1024, 512, 1),
Conv_BN_LeakyReLU(512, 1024, 3, 1),
Conv_BN_LeakyReLU(1024, 512, 1),
Conv_BN_LeakyReLU(512, 1024, 3, 1)
)
self.conv_7 = nn.Conv2d(1024, 1000, 1)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
def forward(self, x):
x = self.conv_1(x)
x = self.conv_2(x)
x = self.conv_3(x)
x = self.conv_4(x)
x = self.conv_5(x)
x = self.conv_6(x)
x = self.conv_7(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
return x
darknet53的代码:
class Conv_BN_LeakyReLU(nn.Module):#图里名为DBL的模块
def __init__(self, in_channels, out_channels, ksize, padding=0, stride=1, dilation=1):
super(Conv_BN_LeakyReLU, self).__init__()
self.convs = nn.Sequential(
nn.Conv2d(in_channels, out_channels, ksize, padding=padding, stride=stride, dilation=dilation),
nn.BatchNorm2d(out_channels),
nn.LeakyReLU(0.1, inplace=True)
)
def forward(self, x):
return self.convs(x)
class resblock(nn.Module): #图里名为Res_unit的模块
def __init__(self, ch, nblocks=1):
super().__init__()
self.module_list = nn.ModuleList()
for _ in range(nblocks):
resblock_one = nn.Sequential(
Conv_BN_LeakyReLU(ch, ch//2, 1),
Conv_BN_LeakyReLU(ch//2, ch, 3, padding=1)
)
self.module_list.append(resblock_one)
def forward(self, x):
for module in self.module_list:
x = module(x) + x
return x
# darknet-53 code
class DarkNet_53(nn.Module):
def __init__(self, num_classes=1000):
super(DarkNet_53, self).__init__()
# stride = 2
self.layer_1 = nn.Sequential(
Conv_BN_LeakyReLU(3, 32, 3, padding=1),
Conv_BN_LeakyReLU(32, 64, 3, padding=1, stride=2),
resblock(64, nblocks=1)
)
# stride = 4
self.layer_2 = nn.Sequential(
Conv_BN_LeakyReLU(64, 128, 3, padding=1, stride=2),
resblock(128, nblocks=2)
)
# stride = 8
self.layer_3 = nn.Sequential(
Conv_BN_LeakyReLU(128, 256, 3, padding=1, stride=2),
resblock(256, nblocks=8)
)
# stride = 16
self.layer_4 = nn.Sequential(
Conv_BN_LeakyReLU(256, 512, 3, padding=1, stride=2),
resblock(512, nblocks=8)
)
# stride = 32
self.layer_5 = nn.Sequential(
Conv_BN_LeakyReLU(512, 1024, 3, padding=1, stride=2),
resblock(1024, nblocks=4)
)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(1024, num_classes)
def forward(self, x, targets=None):
x = self.layer_1(x)
x = self.layer_2(x)
x = self.layer_3(x)
x = self.layer_4(x)
x = self.layer_5(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
该结构的pytorch实现
引用于该帖子
import math
from collections import OrderedDict
import torch.nn as nn
#---------------------------------------------------------------------#
# 残差结构
# 利用一个1x1卷积下降通道数,然后利用一个3x3卷积提取特征并且上升通道数
# 最后接上一个残差边
#---------------------------------------------------------------------#
class BasicBlock(nn.Module):
def __init__(self, inplanes, planes):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes[0], kernel_size=1, stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(planes[0])
self.relu1 = nn.LeakyReLU(0.1)
self.conv2 = nn.Conv2d(planes[0], planes[1], kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes[1])
self.relu2 = nn.LeakyReLU(0.1)
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu1(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu2(out)
out += residual
return out
class DarkNet(nn.Module):
def __init__(self, layers):
super(DarkNet, self).__init__()
self.inplanes = 32
# 416,416,3 -> 416,416,32
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(self.inplanes)
self.relu1 = nn.LeakyReLU(0.1)
# 416,416,32 -> 208,208,64
self.layer1 = self._make_layer([32, 64], layers[0])
# 208,208,64 -> 104,104,128
self.layer2 = self._make_layer([64, 128], layers[1])
# 104,104,128 -> 52,52,256
self.layer3 = self._make_layer([128, 256], layers[2])
# 52,52,256 -> 26,26,512
self.layer4 = self._make_layer([256, 512], layers[3])
# 26,26,512 -> 13,13,1024
self.layer5 = self._make_layer([512, 1024], layers[4])
self.layers_out_filters = [64, 128, 256, 512, 1024]
# 进行权值初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
#---------------------------------------------------------------------#
# 在每一个layer里面,首先利用一个步长为2的3x3卷积进行下采样
# 然后进行残差结构的堆叠
#---------------------------------------------------------------------#
def _make_layer(self, planes, blocks):
layers = []
# 下采样,步长为2,卷积核大小为3
layers.append(("ds_conv", nn.Conv2d(self.inplanes, planes[1], kernel_size=3, stride=2, padding=1, bias=False)))
layers.append(("ds_bn", nn.BatchNorm2d(planes[1])))
layers.append(("ds_relu", nn.LeakyReLU(0.1)))
# 加入残差结构
self.inplanes = planes[1]
for i in range(0, blocks):
layers.append(("residual_{}".format(i), BasicBlock(self.inplanes, planes)))
return nn.Sequential(OrderedDict(layers))
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.layer1(x)
x = self.layer2(x)
out3 = self.layer3(x)
out4 = self.layer4(out3)
out5 = self.layer5(out4)
return out3, out4, out5
def darknet53():
model = DarkNet([1, 2, 8, 8, 4])
return model