CV学习第五课——SVM、决策树、KNN以及K-Means等其他机器学习工具
1.SVM(支持向量机)
以下内容转载文章:[SVM支持向量机入门及数学原理]https://blog.csdn.net/Datawhale/article/details/94598943
1.1简介
SVM名字由来:
在支持向量机中,距离超平面最近的且满足一定条件的几个训练样本点被称为支持向量。
图中有红色和蓝色两类样本点。黑色的实线就是最大间隔超平面。在这个例子中,A,B,C 三个点到该超平面的距离相等。
注意,这些点非常特别,这是因为超平面的参数完全由这三个点确定。该超平面和任何其他的点无关。如果改变其他点的位置,只要其他点不落入虚线上或者虚线内,那么超平面的参数都不会改变。A,B,C 这三个点被称为支持向量(support vectors)。
而“机”主要是machine这个词翻译的有点唬人,如果翻译为“算法”就舒服多了。

支持向量机(support vector machines)是一种二分类模型,它的目的是寻找一个超平面来对样本进行分割,分割的原则是间隔最大化,最终转化为一个凸二次规划问题来求解。由简至繁的模型包括:
- 当训练样本线性可分时,通过硬间隔最大化,学习一个线性可分支持向量机;
- 当训练样本近似线性可分时,通过软间隔最大化,学习一个线性支持向量机;
- 当训练样本线性不可分时,通过核技巧和软间隔最大化,学习一个非线性支持向量机;
1.2线性可分支持向量机
给定训练样本集 D = ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x m , y m ) D = ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x m , y m ) D=(x1,y1),(x2,y2),⋯,(xm,ym)D=(x1,y1),(x2,y2),⋯,(xm,ym) D=(x1,y1),(x2,y2),⋯,(xm,ym)D=(x1,y1),(x2,y2),⋯,(xm,ym),其中 y i ∈ ( − 1 , + 1 ) , y i ∈ ( − 1 , + 1 ) y_i∈({−1,+1}),y_i∈({−1,+1}) yi∈(−1,+1),yi∈(−1,+1),分类学习最基本的想法就是基于训练集 D D D在样本空间中找到一个划分超平面,将不同类别的样本分开。
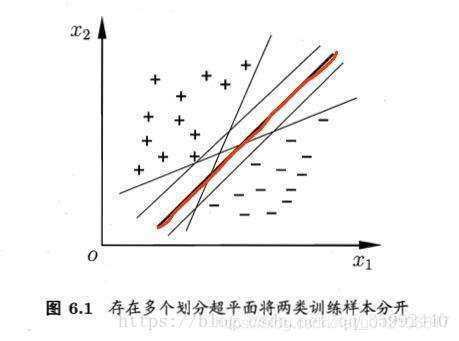
直观看上去,能将训练样本分开的划分超平面有很多,但应该去找位于两类训练样本“正中间”的划分超平面,即图6.1中红色的那条,因为该划分超平面对训练样本局部扰动的“容忍”性最好,例如,由于训练集的局限性或者噪声的因素,训练集外的样本可能比图6.1中的训练样本更接近两个类的分隔界,这将使许多划分超平面出现错误。而红色超平面的影响最小,简言之,这个划分超平面所产生的结果是鲁棒性的。
那什么是线性可分呢?
如果一个线性函数能够将样本分开,称这些数据样本是线性可分的。那么什么是线性函数呢?其实很简单,在二维空间中就是一条直线,在三维空间中就是一个平面,以此类推,如果不考虑空间维数,这样的线性函数统称为超平面。我们看一个简单的二维空间的例子,O代表正类,X代表负类,样本是线性可分的,但是很显然不只有这一条直线可以将样本分开,而是有无数条,我们所说的线性可分支持向量机就对应着能将数据正确划分并且间隔最大的直线。

那么我们考虑第一个问题,为什么要间隔最大呢?一般来说,一个点距离分离超平面的远近可以表示分类预测的确信度,如图中的A B两个样本点,B点被预测为正类的确信度要大于A点,所以SVM的目标是寻找一个超平面,使得离超平面较近的异类点之间能有更大的间隔,即不必考虑所有样本点,只需让求得的超平面使得离它近的点间隔最大。
接下来考虑第二个问题,怎么计算间隔?只有计算出了间隔,才能使得间隔最大化。在样本空间中,划分超平面可通过如下线性方程来描述:
W T x + b = 0 WTx+b=0 WTx+b=0
其中 w w w为法向量,决定了超平面的方向, b b b为位移量,决定了超平面与原点的距离。假设超平面能将训练样本正确地分类,即对于训练样本 ( x i , y i ) (xi,yi) (xi,yi),满足以下公式:
{ W T x i + b ≥ + 1 , y i = + 1 W T x i + b ≤ − 1 , y i = − 1 \left\{ \begin{matrix} \ W^Tx_i+b≥+1,y_i=+1 \\ \ W^Tx_i+b≤−1,y_i=-1 \end{matrix} \right. { WTxi+b≥+1,yi=+1 WTxi+b≤−1,yi=−1
该公式被称为最大间隔假设, y i = + 1 y_i=+1 yi=+1表示样本为正样本, y i = − 1 yi=−1 yi=−1表示样本为负样本,式子前面选择大于等于+1,小于等于-1只是为了计算方便,原则上可以是任意常数,但无论是多少,都可以通过对 w w w的变换使其为 +1 和 -1 。实际上该公式等价于; y i ( W T x i + b ) ≥ + 1 y_i(W^Tx_i+b)≥+1 yi(WTxi+b)≥+1
如图6.2所示,距离超平面最近的这几个样本点满足 y i ( W T x i + b ) = 1 y_i(W^Tx_i+b)=1 yi(WTxi+b)=1,它们被称为“支持向量”。虚线称为边界,两条虚线间的距离称为间隔(margin)。

关于间隔的计算:它就等于两个异类支持向量的差在 W方向上的投影 ,W方向是指图6.2所示实线的法线方向。
即:

进而可以推出:

故有:
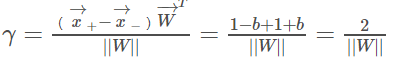
至此,我们求得了间隔,SVM的思想是使得间隔最大化,也就是:

显然,最大化 2/||w|| 相当于最小化 ||w||,为了计算方便,将公式转化成如下公式,它即为支持向量机的基本型:
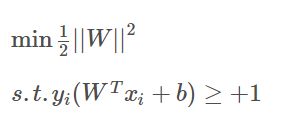
该基本型是一个凸二次规划问题,可以采用拉格朗日乘子法对其对偶问题求解求解,拉格朗日函数:

后续的拉格朗日乘子和KTT条件计算看参考的文章。
2.决策树
参考文章如下:
1.决策树的基本概率
2.机器学习之-常见决策树算法(ID3、C4.5、CART)
3.KNN算法
参考文章如下:
1.机器学习笔记:K-近邻算法(KNN)
2.什么是KNN算法?
4.K-means算法
参考文章如下:
1.K-Means聚类算法
2.K-Means算法
5.交叉熵和softmax函数
参考文章如下:
1.一文搞懂交叉熵在机器学习中的使用,透彻理解交叉熵背后的直觉
2.一文搞懂交叉熵损失
3.一分钟理解softmax函数(超简单)
4.softmax函数详解
5.Softmax 函数及其作用(含推导)
6.过拟合和欠拟合
参考文章如下:
1.过拟合和欠拟合
2.欠拟合、过拟合总结
3.过拟合与欠拟合及方差偏差
7.梯度消失和梯度爆炸
参考文章如下:
1.梯度消失和梯度爆炸问题详解
2.梯度消失与梯度爆炸的原因及解决方法
3.梯度消失、梯度爆炸产生的原因