SQL Server如何在变长列上存储索引
原文:
SQL Server如何在变长列上存储索引
这篇文章我想谈下SQL Server如何在变长列上存储索引。首先我们创建一个包含变长列的表,在上面定义主键,即在上面定义了聚集索引,然后往里面插入80000条记录:
1 -- Create a new table 2 CREATE TABLE Customers 3 ( 4 CustomerName VARCHAR(255) NOT NULL PRIMARY KEY, 5 Filler CHAR(138) NOT NULL 6 ) 7 GO 8 9 -- Insert 80.000 records 10 DECLARE @i INT = 1 11 WHILE (@i <= 80000) 12 BEGIN 13 INSERT INTO Customers VALUES 14 ( 15 'CustomerName' + CAST(@i AS VARCHAR), 16 'Filler' + CAST(@i AS VARCHAR) 17 ) 18 19 SET @i += 1 20 END 21 GO
从代码里我们可以看到,我在VARCHAR(255)列上建立了主键约束,SQL Server会强制这列为唯一聚集索引。接下来我们通过DMV sys.dm_db_index_physical_stats来获取聚集索引的相关物理信息:
1 -- Retrieve physical information about the clustered index 2 SELECT * FROM sys.dm_db_index_physical_stats 3 ( 4 DB_ID('ALLOCATIONDB'), 5 OBJECT_ID('Customers'), 6 NULL, 7 NULL, 8 'DETAILED' 9 ) 10 GO

从输出结果可以看出,在索引页里,min_record_size_in_bytes列的值是7,max_record_size_in_bytes列的值是28。我们据此可以得出结论:在索引记录内部,聚集键是以变长列保存的。我们建立一个帮助表来存储DBCC IND的输出信息来做进一步分析。
1 -- Create a helper table 2 CREATE TABLE HelperTable 3 ( 4 PageFID TINYINT, 5 PagePID INT, 6 IAMFID TINYINT, 7 IAMPID INT, 8 ObjectID INT, 9 IndexID TINYINT, 10 PartitionNumber TINYINT, 11 PartitionID BIGINT, 12 iam_chain_type VARCHAR(30), 13 PageType TINYINT, 14 IndexLevel TINYINT, 15 NextPageFID TINYINT, 16 NextPagePID INT, 17 PrevPageFID INT, 18 PrevPagePID INT, 19 PRIMARY KEY (PageFID, PagePID) 20 ) 21 GO 22 23 -- Write everything in a table for further analysis 24 INSERT INTO HelperTable EXEC('DBCC IND(ALLOCATIONDB, Customers, 1)') 25 GO 26 27 -- Retrieve the root index page (1 page) 28 SELECT * FROM HelperTable 29 WHERE IndexLevel = 2 30 GO

我这里的根页是15058,我们使用DBCC PAGE命令查看下这个根页(记得先执行 DBCC TRACEON(3604))。
1 DBCC TRACEON (3604) 2 GO 3 --Dump out the root index page 4 DBCC PAGE(ALLOCATIONDB, 1, 15058, 1) 5 GO
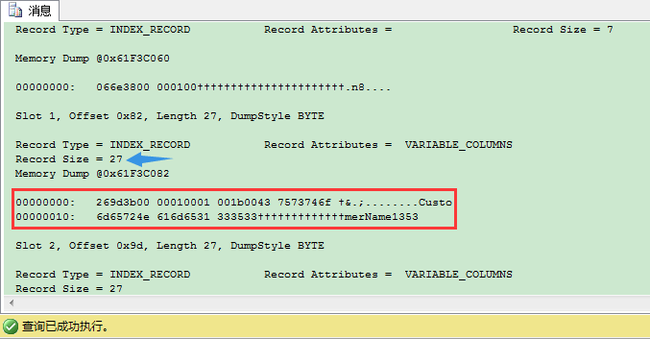
即如下所示的数字:
00000000: 269d3b00 00010001 001b0043 7573746f †&.;........Custo 00000010: 6d65724e 616d6531 333533†††††††††††††merName1353
我们来分析下这些16进制值:
26 95020000 0100 0100 1b00 43757374 6f6d6572 4e616d65 31333533
- 26 第1个字节代表状态位
- 95020000 这4个字节代表索引记录指向的子页id(child-page-id)
- 0100 这2个字节代表索引记录指向的子文件id(child-file-id)
- 0100 这2个字节代表变长列数
- 1b00 这2个字节代表每个变长列结束为止的偏移量。每个变长列需要2字节。这个和在数据页里存储变长列一致。这里我们有1个变长列,因此SQL Server需要1个 2 byte的偏移量——27 byte的偏移量。这就是说下一个字节一直到27 byte的偏移量都是我们变长列(聚集键)的组成部分。
- 43757374 6f6d6572 4e616d65 31333533 聚集键的16进制值,即CustomerName列。
从上面的解释,我们可以看出SQL Server存储变长索引列格式和数据页里存储变长列格式是一样的。但你要知道有一点额外开销,因为你需要额外2 bytes 来存储变长列个数,对于每个变长列在变长列偏移数组里需要2 bytes。在设计索引和计算一个索引页存放多少索引记录时,要留意这些存储开销。