| 探讨Hash表中的一些原理/概念,及根据这些原理/概念,自己设计一个用来存放/查找数据的Hash表,并且与JDK中的HashMap类进行比较。 我们分一下七个步骤来进行。
一。 Hash表概念
二 . Hash构造函数的方法,及适用范围
三. Hash处理冲突方法,各自特征
四. Hash查找过程
五. 实现一个使用Hash存数据的场景--Hash查找算法,插入算法
六. JDK中HashMap的实现
七. Hash表与HashMap的对比,性能分析
一。 Hash表概念
在Hash表中,记录在表中的位置和其关键字之间存在着一种确定的关系。这样 我们就能预先知道所查关键字在表中的位置,从而直接通过下标找到记录。
|
|
1) 哈希(Hash)函数是一个映象,即: 将关键字的集合映射到某个地址集合上,它的设置很灵活,
只要这个地址集合的大小不超出允许范围即可; 2) 由于哈希函数是一个压缩映象,因此,在一般情况下,很容易产生“冲突”现象,
即: key1!=key2,而 f (key1) = f(key2)。 3). 只能尽量减少冲突而不能完全避免冲突,这是因为通常关键字集合比较大,其元素包括所有可能的关键字,
而地址集合的元素仅为哈希表中的地址值.在构造这种特殊的“查找表” 时,除了需要选择一个“好”(尽可能少产生冲突)
的哈希函数之外;还需要找到一 种“处理冲突” 的方法。 二 . Hash构造函数的方法,及适用范围 直接定址法
数字分析法
平方取中法
折叠法
除留余数法
随机数法
(1)直接定址法: 哈希函数为关键字的线性函数,H(key) = key 或者 H(key) = a * key + b (2)数字分析法:
假设关键字集合中的每个关键字都是由 s 位数字组成 (u1, u2, …, us),分析关键字集中的全体,
并从中提取分布均匀的若干位或它们的组合作为地址。 此法适于:能预先估计出全体关键字的每一位上各种数字出现的频度。 (3)平方取中法:
以关键字的平方值的中间几位作为存储地址。求“关键字的平方值” 的目的是“扩大差别” ,
同 时平方值的中间各位又能受到整个关键字中各位的影响。 (4)折叠法:
将关键字分割成若干部分,然后取它们的叠加和为哈希地址。两种叠加处理的方法:移位叠加:
将分割后的几部分低位对齐相加;间界叠加:从一端沿分割界来回折叠,然后对齐相加。 此法适于:关键字的数字位数特别多。 (5)除留余数法: 设定哈希函数为:H(key) = key MOD p ( p≤m ),其中, m为表长,p 为不大于 m 的素数,或 是不含 20 以下的质因子 (6)随机数法: 设定哈希函数为:H(key) = Random(key)其中,Random 为伪随机函数 实际造表时,采用何种构造哈希函数的方法取决于建表的关键字集合的情况(包括关键字的范围和形态),
以及哈希表长度(哈希地址范围),总的原则是使产生冲突的可能性降到尽可能地小。 三. Hash处理冲突方法,各自特征 “处理冲突” 的实际含义是:为产生冲突的关键字寻找下一个哈希地址。 开放定址法
再哈希法
链地址法 (1)开放定址法:
为产生冲突的关键字地址 H(key) 求得一个地址序列: H0, H1, H2, …, Hs 1≤s≤m-1,Hi = ( H(key) +di ) MOD m,
其中: i=1, 2, …, s,H(key)为哈希函数;m为哈希表长; (2)链地址法: 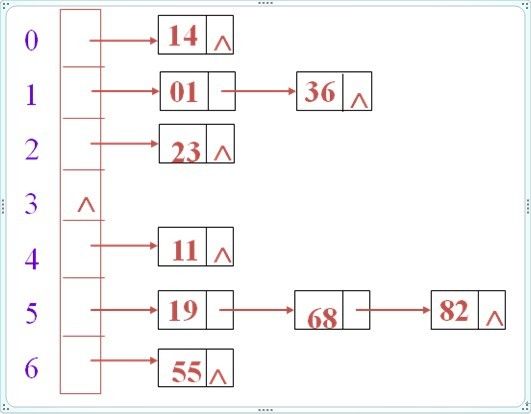
将所有哈希地址相同的记录都链接在同一链表中。
(3)再哈希法:
方法:构造若干个哈希函数,当发生冲突时,根据另一个哈希函数计算下一个哈希地址,直到冲突不再发 生。
即:Hi=Rhi(key) i=1,2,……k,其中:Rhi——不同的哈希函数,特点:计算时间增加 四. Hash查找过程 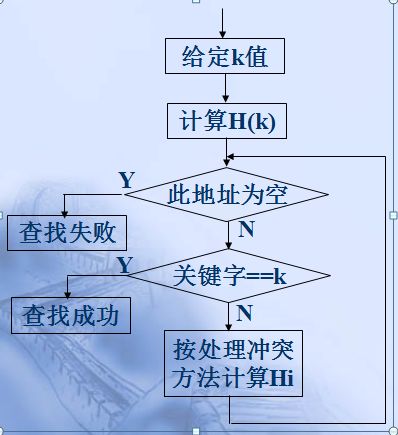
对于给定值 K,计算哈希地址 i = H(K),若 r[i] = NULL 则查找不成功,若 r[i].key = K 则查找成功,
否则 “求 下一地址 Hi” ,直至r[Hi] = NULL (查找不成功) 或r[Hi].key = K (查找成功) 为止。 五. 实现一个使用Hash存数据的场景-------Hash查找算法,插入算法 假设我们要设计的是一个用来保存中南大学所有在校学生个人信息的数据表。因为在校学生数量也不是特别巨大(8W),
每个学生的学号是唯一的,因此,我们可以简单的应用直接定址法,声明一个10W大小的数组,每个学生的学号作为主键。
然后每次要添加或者查找学生,只需要根据需要去操作即可。 但是,显然这样做是很脑残的。这样做系统的可拓展性和复用性就非常差了,比如有一天人数超过10W了?
如果是用来保存别的数据呢?或者我只需要保存20条记录呢?声明大小为10W的数组显然是太浪费了的。 如果我们是用来保存大数据量(比如银行的用户数,4大的用户数都应该有3-5亿了吧?),这时候我们计算出来的
HashCode就很可能会有冲突了, 我们的系统应该有“处理冲突”的能力,此处我们通过挂链法“处理冲突”。 如果我们的数据量非常巨大,并且还持续在增加,如果我们仅仅只是通过挂链法来处理冲突,可能我们的链上挂了
上万个数据后,这个时候再通过静态搜索来查找链表,显然性能也是非常低的。所以我们的系统应该还能实现自动扩容,
当容量达到某比例后,即自动扩容,使装载因子保存在一个固定的水平上。 综上所述,我们对这个Hash容器的基本要求应该有如下几点: 满足Hash表的查找要求(废话)
能支持从小数据量到大数据量的自动转变(自动扩容)
使用挂链法解决冲突 好了,既然都分析到这一步了,咱就闲话少叙,直接开始上代码吧。 public class MyMap< K, V> {
private int size;// 当前容量
private static int INIT_CAPACITY = 16;// 默认容量
private Entry< K, V>[] container;// 实际存储数据的数组对象
private static float LOAD_FACTOR = 0.75f;// 装载因子
private int max;// 能存的最大的数=capacity*factor
// 自己设置容量和装载因子的构造器
public MyMap(int init_Capaticy, float load_factor) {
if (init_Capaticy < 0)
throw new IllegalArgumentException("Illegal initial capacity: "
+ init_Capaticy);
if (load_factor <= 0 || Float.isNaN(load_factor))
throw new IllegalArgumentException("Illegal load factor: " + load_factor);
this.LOAD_FACTOR = load_factor;
max = (int) (init_Capaticy * load_factor);
container = new Entry[init_Capaticy];
}
// 使用默认参数的构造器
public MyMap() {
this(INIT_CAPACITY, LOAD_FACTOR);
}
/**
* 存
*
* @param k
* @param v
* @return
*/
public boolean put(K k, V v) {
// 1.计算K的hash值
// 因为自己很难写出对不同的类型都适用的Hash算法,故调用JDK给出的hashCode()方法来计算hash值
int hash = k.hashCode();
//将所有信息封装为一个Entry
Entry< K,V> temp=new Entry(k,v,hash);
if(setEntry(temp, container)){
// 大小加一
size++;
return true;
}
return false;
}
/**
* 扩容的方法
*
* @param newSize
* 新的容器大小
*/
private void reSize(int newSize) {
// 1.声明新数组
Entry< K, V>[] newTable = new Entry[newSize];
max = (int) (newSize * LOAD_FACTOR);
// 2.复制已有元素,即遍历所有元素,每个元素再存一遍
for (int j = 0; j < container.length; j++) {
Entry< K, V> entry = container[j];
//因为每个数组元素其实为链表,所以…………
while (null != entry) {
setEntry(entry, newTable);
entry = entry.next;
}
}
// 3.改变指向
container = newTable;
}
/**
*将指定的结点temp添加到指定的hash表table当中
* 添加时判断该结点是否已经存在
* 如果已经存在,返回false
* 添加成功返回true
* @param temp
* @param table
* @return
*/
private boolean setEntry(Entry< K,V> temp,Entry[] table){
// 根据hash值找到下标
int index = indexFor(temp.hash, table.length);
//根据下标找到对应元素
Entry< K, V> entry = table[index];
// 3.若存在
if (null != entry) {
// 3.1遍历整个链表,判断是否相等
while (null != entry) {
//判断相等的条件时应该注意,除了比较地址相同外,引用传递的相等用equals()方法比较
//相等则不存,返回false
if ((temp.key == entry.key||temp.key.equals(entry.key)) &&
temp.hash == entry.hash&&(temp.value==entry.value||temp.value.equals(entry.value))) {
return false;
}
else if(temp.key == entry.key && temp.value != entry.value) {
entry.value = temp.value;
return true;
}
//不相等则比较下一个元素
else if (temp.key != entry.key) {
//到达队尾,中断循环
if(null==entry.next){
break;
}
// 没有到达队尾,继续遍历下一个元素
entry = entry.next;
}
}
// 3.2当遍历到了队尾,如果都没有相同的元素,则将该元素挂在队尾
addEntry2Last(entry,temp);
return true;
}
// 4.若不存在,直接设置初始化元素
setFirstEntry(temp,index,table);
return true;
}
private void addEntry2Last(Entry< K, V> entry, Entry< K, V> temp) {
if (size > max) {
reSize(container.length * 4);
}
entry.next=temp;
}
/**
* 将指定结点temp,添加到指定的hash表table的指定下标index中
* @param temp
* @param index
* @param table
*/
private void setFirstEntry(Entry< K, V> temp, int index, Entry[] table) {
// 1.判断当前容量是否超标,如果超标,调用扩容方法
if (size > max) {
reSize(table.length * 4);
}
// 2.不超标,或者扩容以后,设置元素
table[index] = temp;
//!!!!!!!!!!!!!!!
//因为每次设置后都是新的链表,需要将其后接的结点都去掉
//NND,少这一行代码卡了哥哥7个小时(代码重构)
temp.next=null;
}
/**
* 取
*
* @param k
* @return
*/
public V get(K k) {
Entry< K, V> entry = null;
// 1.计算K的hash值
int hash = k.hashCode();
// 2.根据hash值找到下标
int index = indexFor(hash, container.length);
// 3。根据index找到链表
entry = container[index];
// 3。若链表为空,返回null
if (null == entry) {
return null;
}
// 4。若不为空,遍历链表,比较k是否相等,如果k相等,则返回该value
while (null != entry) {
if (k == entry.key||entry.key.equals(k)) {
return entry.value;
}
entry = entry.next;
}
// 如果遍历完了不相等,则返回空
return null;
}
/**
* 根据hash码,容器数组的长度,计算该哈希码在容器数组中的下标值
*
* @param hashcode
* @param containerLength
* @return
*/
public int indexFor(int hashcode, int containerLength) {
return hashcode & (containerLength - 1);
}
/**
* 用来实际保存数据的内部类,因为采用挂链法解决冲突,此内部类设计为链表形式
*
* @param < K>key
* @param < V>
* value
*/
class Entry< K, V> {
Entry< K, V> next;// 下一个结点
K key;// key
V value;// value
int hash;// 这个key对应的hash码,作为一个成员变量,当下次需要用的时候可以不用重新计算
// 构造方法
Entry(K k, V v, int hash) {
this.key = k;
this.value = v;
this.hash = hash;
}
//相应的getter()方法
}
}
第一次初始化加的时候,因为每个元素的next都是空的,而扩充容量resize()时,
因为冲突处理是链式结构的,当将他们重新hash添加的时候,重复的这些鸟元素的next是有元素的,一定要设置为null。
七.性能分析:
1.因为冲突的存在,其查找长度不可能达到O(1) 2哈希表的平均查找长度是装载因子a 的函数,而不是 n 的函数。 3.用哈希表构造查找表时,可以选择一个适当的装填因子 ,使得平均查找长度限定在某个范围内。 最后给出我们这个HashMap的性能 测试代码 public class Test {
public static void main(String[] args) {
MyMap< String, String> mm = new MyMap< String, String>();
Long aBeginTime=System.currentTimeMillis();//记录BeginTime
for(int i=0;i< 1000000;i++){
mm.put(""+i, ""+i*100);
}
Long aEndTime=System.currentTimeMillis();//记录EndTime
System.out.println("insert time-->"+(aEndTime-aBeginTime));
Long lBeginTime=System.currentTimeMillis();//记录BeginTime
mm.get(""+100000);
Long lEndTime=System.currentTimeMillis();//记录EndTime
System.out.println("seach time--->"+(lEndTime-lBeginTime));
}
}
100W个数据时,全部存储时间为1S多一点,而搜寻时间为0
insert time-->1536
seach time--->0 |
|
