论文翻译《Object-Level Ranking: Bringing Order to Web Objects》
Object-Level Ranking: Bringing Order to Web Objects
Zaiqing Nie Yuanzhi Zhang Jirong Wen Weiying Ma
摘要:
现在的网络搜索方法实际上是做文档级排名和检索,与之相对比,我们在探索一种新的聚合体以实现在对象级的网络检索。我们搜集与某一特定领域有关的对象的网络信息,并按照应答用户查询的相关性和流行度对这些对象进行排名。由于不同对象间不均匀性的存在,传统的PageRank模型在计算对象的popularity时不再有效。这篇论文介绍了PopRank,一种对一个特殊域的对象排名的域独立、对象级链接分析模型。我们明确的对每一类对象关系分配一个流行度传播因子(PPF),研究不同种类关系的不同PPF怎样影响popularity rangking。建议一种自动决定这些系数的途径。我们的实验使用一百万篇CS论文,试验结果表明,在对象图上使用PopRank可以获得比PageRank更好的排名结果。
类别和主题描述
H.3.3 [Information Storage and Retrieval]: Information Search and Retrieval; G.2.2 [Discrete Mathematics]: Graph Theory; H.3.5 [Information Storage and Retrieval]: Online Information Services—Web based services
信息存储和检索:信息搜索和检索
离散数学:图论
信息存储和检索:在线信息服务——基于网络的服务
关键词
Web information retrieval,Web objects, PageRank, PopRank, Link analysis
网络信息检索,网络对象,网页排名,流行度排级,链接分析
1. 介绍
现存的网络搜索引擎把整个网页当作检索和消费的单元。但是,存在不同种类的对象嵌入在静态网页或网络数据库中。典型的对象是产品、人、论文、组织等等。我们可以想象如果这些对象可以从网络中抽取和集成,强大的对象级搜索引擎可以被建立以更精确的满足用户的信息需求,特别是一些特殊领域。这样的看法在研究社区产生了重要的兴趣,近年来,研发出了相关的技术,例如wrapper deduction、网络数据库模式匹配、网络对象鉴定等。这些技术使我们可以提取和集成同一个对象的相关网络信息成为一个信息单元。我们称这些网络信息单元为网络对象。现在,检索和排名相关网络对象以回答用户查询的工作做的较少。
就像网页相互链接被称为网页图一样,不同种类的对象通过它们之间的相互联系形成了对象图。在网页图中,根据内连接,不同的页面有不同的流行度。像PageRank和HITS等技术已经被成功的应用于通过分析网页图的链接结构区别不同网页的流行度。显然,在对象图中,对象的流行度也不相同。拿研究领域当例子。只有在一个领域的几个顶级会议可以吸引高质量的论文,他们的论文更可能被阅读。为了帮助用户快速的定位感兴趣的对象,我们应该计算所收集对象的流行度。显然对象越流行,用户可能对它越感兴趣。所以自然产生一个问题:怎样应用链接分析技术有效地计算网络对象的流行度。这篇论文的目标是解决这个问题。我们对这个问题的回答是肯定的,但是需要不同的技术,因为对象图有其独有的特征。
为了做链接分析,对象图最独特的是链接的不均匀性,换言之,对象间通过不同的关系类型相互联系。例如,一个论文对象可能被一个其他论文对象的集合引用,被一个作者对象集合撰写,被一个会议/期刊对象出版(如图1)。
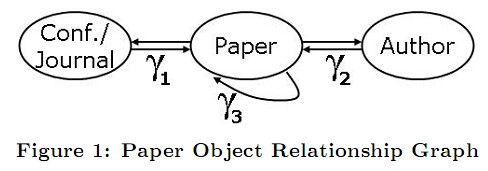
所以有三种不同的链接:cited-by, authored-by and published-by。它们有不同的语义。传统的链接分析方法(包括PageRank、HITS)假定这些链接具有相同的“endorsement”语义,并且同等重要,直接应用这些方法会导致不合理的流行度排名。例如,一片论文的流行度不应该被作者的数量影响太大,被引用的数量对流行度有较大影响。在这篇论文中,我们提出了PopRank,一种同时考虑一个网络对象的流行度和对象间的关系来计算其流行度分数的方法。
PopRank对PageRank模型进行扩展,对每个链接指向的对象增加一个流行度传播因子(PPF,popularity propagation factor),对不同的关系类型使用不同的PPF。例如,对指向论文对象的链接,对三种不同的关系cited-by, authored-by and published-by,我们需要三个PPF(图1中的γ1,γ2,γ3)。但是,手工分配这些因子以使流行度排名合理是一个极大的挑战。对一个巨大的链接图,我们很难指出什么样的链接类型更重要,更难确定他们准确的重要性。幸运的是,一直以来我们从领域专家收集一些对象的部分排名比较容易。例如,作为一个研究员,我们知道我们领域的顶级会议或期刊的顺序,我们可能知道什么样的论文更流行。我们提出一个基于学习的途径,使用领域专家提供的部分对象排名来自动学习不同类型链接PPF。模拟退火算法用来探测所有PPF可能组合的搜索空间,迭代的缩小域专家的部分排名和我们的学习模式排名之间的差异。
我们的学习途径面临的主要问题是我们获得合理的PPF分配需要尝试太多的可行因子组合,代价太高。由于计算对象的PopRank来测试最优的PPF因子分配需要花费大量的时间。为了使学习时间便于管理,我们建议在学习过程中使用整个链接图的子图。因为我们一旦有了大多数相关对象和他们包围训练对象的链接,我们就可能计算这些训练对象的较精确的PopRank值。因为我们感兴趣的不是获得精确的排名得分而是训练对象的相关排名,较小的减少精确度不会对最优分配造成较大影响。但是在对象链接图过大的情形下,可能需要牺牲优化性来获得效率。
前面描述和激发的PopRank链接分析模型已经被完全实现,并在一个被称为Libra的研究原型的内容里被评估,Libra索引了一百万计算机科学方面的论文。在本文中,我们描述了PopRank模型的细节,并应用到Libra。我们的模型稍作修改之后也可以应用到多其他的垂直搜索引擎领域,包括产品搜索、图像搜索、音乐搜索和人物搜索。我们在Libra的试验结果显示,与PageRank相比,在对象图应用PopRank可以显著的获得更好的排名结果。
本文剩余部分如下组织。下一节,我们给出PopRank链接分析模型的数学描述,提供直觉的证明。第3节描述我们的链接重要性学习途径的细节。3.2节描述我们怎样选择整个对象链接图的子图。第4节我们简要介绍我们的Libra论文搜索。第5节描述了我们使用PopRank和Libra来评估我们提出的途径的有效性的实验。第6节讨论相关工作,第7节展示我们的结论和未来的工作。
2. PopRank模型
假设在应用域,我们有n种不同类型的网络对象模型X1,X2,……,Xn。例如,在科学学术领域,我们有四种类型的对象:论文、作者、会议、期刊。这些对象之间通过不同的方式相互联系:一篇论文引用其他论文,一个作者写作一片论文,一个会议出版一篇论文,等等。在这一节,我们给出我们的PopRank模型的细节,用于计算网络对象流行度。
2.1 网页和对象关系图
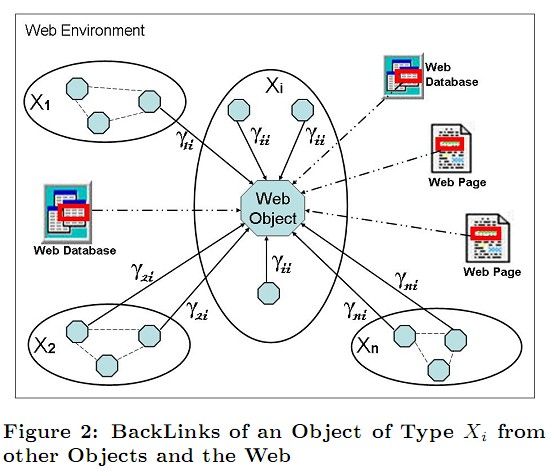
在图2,我们展示了类型Xi的对象背后的链接。在这张图中,实线箭头表示同一类型对象和其他类型对象之间的背后链接,虚线箭头表示对象包含于网页或网页数据库。
由于网络对象包含于网页或网络数据库,所以这些网页和数据库的流行度也会影响他们所包含对象的流行度。如果一个网页是流行的,它的对象信息被阅读的可能性更大。我们用网络流行度(web popularity)来表示网络用户阅读关于某一对象信息的可能性。发现对象信息有两种途径,随机冲浪(换言之,一直点击网页之间的链接),通过一些网页搜索引擎(或一些组合)。由于关于一个对象的信息通常表示为一个网页的一块,网络流行度计算可以考虑包含这个对象的网页的PageRank得分和网页块的重要性。我们假设网络数据库想它的对象一致的传播它的流行度,所以这些源的网络流行度可以很容易的计算。
一个域中的对象关系图也是可以用来计算流行度排级的重要源。例如,一个读者想要进入一个新的研究领域并阅读相关论文。开始,他可能先用Google或CiteSeer来找几个种子对象,可能是一些相关论文、作者、会议、期刊。之后他很可能对象关系链接来定位更多的论文。他可能想要阅读被他读过的论文引用的论文,或者阅读他喜欢的作者、会议、期刊的论文。显然,一篇被众多流行论文引用的论文是流行的,一篇在最近的重要会议上发表的论文即使被应用较少也是流行的。
2.2 PopRank
我们介绍一个“随机对象探测器”模型来解释读者的习惯。这个“随机对象探测器”一直随机地连续点击网页链接,网页到其他对象的链接,对象关系链接。基本上,他开始他在网页上的随机行走,当他找到第一个网络对象后他会开始沿着对象关系链接,不停的点击“后退”直到厌倦,然后重新开始他在网页上的随机行走来寻找另一个种子对象。
我们使用向量REX表示对象X的网络流行度,随机对象探测器单纯通过网页链接图找到对象X的可能性。使用向量RX表示他通过网页链接图和对象关系图找到对象X的可能性。
为了计算一个对象的流行度得分,PopRank模型同时考虑一个对象的网络流行度和它与其它对象的关系。我们使用下面的公式计算类型X的对象的Poprank得分Rx。
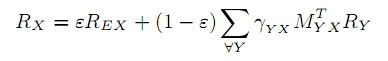
公式中
l X={ x1, x2, ……, xn }, Y={ y1,y2, ……,yn }, X、Y为对象类型
l Rx、Ry:对象类型X、Y的流行度得分向量
l MYX:邻接矩阵
![]() ,如果从对象y到对象x有关系链接,Num(x,y)表示从对象y到任何类型X的对象的链接数。如果从对象y到对象x没有关系链接,myx=0.
,如果从对象y到对象x有关系链接,Num(x,y)表示从对象y到任何类型X的对象的链接数。如果从对象y到对象x没有关系链接,myx=0.
l yXY:表示从类型为Y的对象到类型为X的对象的关系链接的PPF,且![]()
l REX:类型X的对象的网络流行度得分向量
l ![]() :一个衰减系数, random object finder厌烦跟随对象关系图的链接,并开始通过网页图寻找另一个对象的概率
:一个衰减系数, random object finder厌烦跟随对象关系图的链接,并开始通过网页图寻找另一个对象的概率
PopRank可以使用简单的迭代算法计算。
3. 自动分配PPF
就像我们之前提到的,为了计算对象的流行度,我们需要知道相关对象的关系链接的流行度传播因子(PPF)。因为不同类型的关系影响相关对象流行度的方式不同。但是手工决定这些因子是不现实的。因为不同关系类型的数量可能很大,一个系统设计者很难精确的指出一个相关对象能够多大程度的影响另一个对象的流行度。但是一个系统设计者可以比较容易的从领域专家一些关于对象子集的流行度顺序信息,被称为部分排名列表(partial ranking lists)。在这一节,我们提出一个新奇的途径,通过用户给出的部分排名列表来自动学习一个较好的流行度传播因子。
基本上,我们想要查找一个流行度传播因子的集合,用于我们的PopRank模型来产生与领域专家给出的部分排名列表相似的对象排名。这变成了一个参数估计问题。自动分配流行度传播因子(PPF)开始挑战。由于对象关系图可以很大,我们需要等待几个小时(或几天)才能知道一个分配的质量。我们尝试成千上万的分配来寻找一个好的分配不切实际。为了使学习成本便于控制,我们需要一个好的搜索策略,通过探测搜索空间的一小部分来找到一个好的分配。同时。我们需要降低评估每个流行度传播因子(PPF)因子分配质量的代价。在下面的两个子节,我们介绍我们怎样在PPF估计问题中应用现有的搜索算法,怎样通过考虑整个对象关系图的子图来降低每个评估的代价。
3.1 搜索策略
PPF估计问题是一个典型的参数优化问题。有一个基于搜索算法的数字启发教育法可以被改造用于这个问题。在图3中我们展示了SAFA(Simulated Annealing for Factor Assignment)算法,SAFA算法是对Simulated Annealing算法[9] 的改造,用于自动分配流行度传播因子(PPF)。

算法的基本思想是一直检查目前最好的(或选择的)PPF因子组合的邻居,如果有一个邻居更好,那么它就被选为最好的组合。偶尔地,我们可能故意的选择一个较坏的组合以避免陷入一个局部最优区域。
我们这样寻找目前PPF因子组合的邻居:在一个时间周期只改变一个PPF因子,并保持其它因子固定。一个因子的邻居Neighbor(γYX)被试验性的设置为
![]() ,费用函数
,费用函数![]() 用来估计新因子
用来估计新因子![]() 的质量。通过替换当前PPF因子组合里的
的质量。通过替换当前PPF因子组合里的![]() ,应用新的PPF因子组合到对象关系图,来计算训练对象的PopRank score. 排名结果间的距离和域专家给出的排名是费用
,应用新的PPF因子组合到对象关系图,来计算训练对象的PopRank score. 排名结果间的距离和域专家给出的排名是费用![]() 。(请看第5.2节关于测量两个排名距离的细节讨论)
。(请看第5.2节关于测量两个排名距离的细节讨论)
3.2 子图选择
就像我们前面提到的,对较大的对象关系图,估计一个新的PPF因子![]() 的质量可能花费几个小时(或几天)。因为一个搜索算法要尝试许多PPF因子组合来找到一个好的分配,自动学习这些因子可能过于昂贵。幸运的是由于我们只需要知道训练对象的排名来评估PPF因子组合的质量,在PopRank计算中我们不需要知道整个图。
的质量可能花费几个小时(或几天)。因为一个搜索算法要尝试许多PPF因子组合来找到一个好的分配,自动学习这些因子可能过于昂贵。幸运的是由于我们只需要知道训练对象的排名来评估PPF因子组合的质量,在PopRank计算中我们不需要知道整个图。
我们建议使用整个对象关系图的子图来减少排名低于某个PPF因子分配组合的训练对象时间。子图包括一个同心圆集合,训练对象是圆心。这些圆包括对象和它们与其它子图中对象的关系链接。我们用k直径子图(k-diameter subgraph)来表示k个包含所有对象和对象间链接的同心圆子图,这些对象与至少一个核心对象的距离少于k个链接。我们不需要考虑离核心较远的对象,因为衰减因子和它们对核心对象的影响随着距离的增加越来越小。现在问题变成怎样寻找一个好的子图,这个子图不会过多的影响PPF因子评价。

我们介绍DiameterEstimator算法(如图四)来决定一个优化的直径。我们首先使用整个图和统一的PPF因子来计算所有训练对象的排名。然后我们使用k直径子图计算所有训练对象的排名。如果新的排名和使用整个图的排名之间的不同小于停止阈值,我们考虑这个k直径子图足够大了。由于子图外面的对象对评估核心对象(换言之,训练对象)的PopRank得分影响较小,它们的影响可以通过调整停止阈值来忽略。
4. 案例研究
基于PopRank模型,我们开发出了Libra,一个对象级网络搜索原型,帮助科学家和学生找出研究资料。Libra收集所有类型的研究著作里的对象,包括论文,作者,会议和期刊。
对象信息提取自网络数据库,网页,PDF/PS文件。所有关于同一对象的信息集成到一起作为一个基本信息单元。目前,一篇论文被题目、作者名(last name)、和年份信息唯一标识,作者被他/她的全名唯一标识,会议和期刊被他们的短名称标识(如果没有可用的短名称,则使用全名)。对象被按照它们与查询的关系和它们的流行度检索和排序。对象的相关性使用所有收集的关于这个对象的信息计算,关于每个独立的属性进行存储。例如,论文信息存储到w.r.t. 下面的属性:题目,作者,年份,会议,摘要,全文。用这种方法,我们也可以很好的处理结构化查询,同时,给出在计算不同属性的相关性分数时的采样[4] 不同的属性权重。对象相关性分数计算的细节超出了本文的范围。
与传统论文搜索引擎相比,包括在文档级搜索论文信息的CiteSeer[1] 在内,Libra可以关于用户询问进行对象检索和排序,这些对象如作者、论文、会议、期刊。这将使初级研究员和学生获益,他们有兴趣寻找他们研究领域的流行科学家,论文,会议,期刊。甚至是最近出版的较少被引用的论文,如果它们在较好的会议上出版或者被有名的研究员撰写,PopRank会给它们分配合适的流行度。
5. 实验
本文提出的PopRank模型和PPF评估算法被在Libra的内容中完整的实现和评估。实验的研究目的是:(i)比较PopRank模型和PageRank模型的性能,(ii)不同等级的子图近似怎样影响分配PPF因子的质量和效率,(iii)理解搜索空间的形状和估计因子分配算法SAFA的性能。我们现在描述我们实验性评估的数据集和指标。
5.1 数据集
![]()
![]()
![]() Libra现在包含收集到的网络对象间的7百万对象关系链接,这些对象包括1百万篇论文,650 000 位作者,1700个会议,和480种期刊。在图1中,我们展示了这些对象的对象关系图。就像我们看到的,有三种不同的对象链接指向论文对象:会议/期刊 论文,作者 论文,论文 论文。由于另两种对象,会议/期刊对象,作者对象,只有一种类型的关系链接指向它们,这些类型的PPF因子是1。我们只需要分配指向论文对象的关系链接的PPF因子。
Libra现在包含收集到的网络对象间的7百万对象关系链接,这些对象包括1百万篇论文,650 000 位作者,1700个会议,和480种期刊。在图1中,我们展示了这些对象的对象关系图。就像我们看到的,有三种不同的对象链接指向论文对象:会议/期刊 论文,作者 论文,论文 论文。由于另两种对象,会议/期刊对象,作者对象,只有一种类型的关系链接指向它们,这些类型的PPF因子是1。我们只需要分配指向论文对象的关系链接的PPF因子。
我们收集了14个部分排名列表,包括对67个对象信息的排名。8个部分排名列表(论文的3个,作者的2个,会议的2个,期刊的1个)包含被选作训练对象的45个对象的部分排名,6个部分排名列表(论文的3个,作者的1个,会议的1个,期刊的1个)包含被选作测试对象的22个对象的部分排名。这些部分排名列表由微软研究实验室的研究员提供,他们是不同领域的,包括信息检索、机器学习、数据库、计算机视觉等。这里我们展示关于排好名的会议和数据库社区的部分排名列表:1. SIGMOD,2. VLDB,3 ICDE, 4. EDBT, 5. ICDT,6. ER,7. DEXA,8. WIDM。我们确保每种对象类型有至少两个对象排名列表。一个好的排名列表应该确保排名的正确性,同时,排名列表中邻近的对象的流行度不应该有较大的间隔。
5.2 评估指标
为了测量排名结果的质量,我们计算同一对象集的两个排名列表间的距离。我们需要有评估指标,不但测量这两个列表不匹配的数量,而且考虑这些不匹配的位置。例如,如果一个排名列表交换第一个对象和第二个对象的排名,这个列表和测试列表的距离应该比只交互最后一个对象和第二个对象的列表和测试列表的距离要大。因为用户通常只浏览结果列表里顶部的几个对象。
我们提出下面的距离指标来测量两个排名列表R、R’的距离。
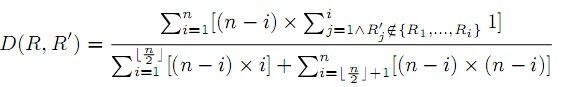
其中,n是排名列表中对象的总数,Ri表示排名列表R中的第i个对象。注意公式的分子用来测量两个排名列表的实际距离,分母用来将实际距离一般化到0和1之间。我们可以看到,我们对排名较高的对象的不匹配分配较大的罚款。例如,最好的对象的排名是错的,错误的权重是n-1,第二好的对象的排名是错的,错误的权重是n-2。
5.3 实验结果
我们现在展示实验结果。
理解搜索空间的形状:在图5,我们展示会议-论文关系PPF因子被设置为0.3时的论文-论文关系PPF因子搜索空间,。数据点收集时,统一采样间隔在[0,0.65],论文-论文关系PPF因子步长0.005。我们可以看出论文-论文PPF因子搜索空间形状在我们固定其它因子时事可以预言的,在小的间隔内没有戏剧性的变化。图6展示论文-论文关系PPF因子被设置为0.3时的会议-论文PPF因子搜索空间。尽管搜索空间的形状不可预测,在一个小的间隔内只有很少的失效。显然基于搜索算法的启发式教育法适合探测这种类型的搜索空间。
停止阈值 :使用 DiameterEstimator 算法,我们自动选择停止阈值为 δ 的 PPF 因子分配子图的直径。在图 8 和图 7 ,我们展示了 PPF 因子估计学习时间和使用不同阈值 δ 学习 PPF 因子的结果质量。我们可以看出,停止阈值 δ越小,开始的质量越好,学习的时间也越长。但是排名结果的质量在阈值小于0.01时不再改进,但是PPF因子学习时间随着阈值减小而保持增长。我们清楚的看到对我们的数据集来说0.01是一个好的停止阈值。
基于前面的实验结果,我们设置停止阈值δ=0.01。使用45个训练对象的不同半径大小的PPF学习时间如图10。从这个图我们可以看出,我们降低子图大小时,学习时间大幅下降。
我们得到不同直径大小的学习PPF因子组合后,我们把它们应用到整个图来计算所有对象的流行度排名。我们比较测试对象的排名结果和域专家的排名。它们的 排名距离在图11中展示。我们可以从图中看到,当我们把直径大小增加到大于4时,排名距离保持相同,尽管PPF因子学习时间继续增加。
模拟退火法(simulated annealing):图12展示在使用45个训练对象时,我们的SAFA算法的性能。我们发现这个算法尝试300到400次迭代来找出优化的PPF分配。它可能是局部最优解,但是我们尝试的另外1100次迭代没有找到改进。
PopRank与PageRank对比:为了比较,我们实现了一个对所有链接分配统一的PPF因子的PageRank算法。图13展示了我们的PopRank算法和PageRank算法在几个数据集的比较。为了表明我们的PopRank模型在有较小训练对象数目时也能较好的工作,我们在这里使用前面的22个测试对象作为训练对象,从前面的45个训练对象中选出6个子集作为测试数据集。一个测试数据集的对象数量从45变成20。结果表明我们的PopRank算法在所有测试数据集都比PageRank算法要好。平均的,我们的排名准确度增加了50%,这显然说明在对象关系图仅应用PageRank实际上是不可行的。
训练对象的数量:在图14中,我们观察训练对象数量不同怎样影响排名结果的质量。我们可以看出,我们增加训练对象数量时,排名准确性随之改进。目前,我们只收集了67个对象做训练和测试。未来,我们计划包含更多的对象用于测试。希望准确性能有较大改进。
6. 相关工作
Brin和Page最早介绍PageRank技术[13] 来计算基于网页得分的网页重要性,一个网页的得分是通过指向该网页的链接得到的。因此,被许多高质量的网页指向的网页也变的重要。可选择的,网页重要性得分等价于一个随机冲浪者,从一个随机的网页开始,在一个特定时间内到达网页的可能性。由于PageRank模型考虑所有的链接有相同的权威传播因子,它不能直接应用到我们的对象级排名问题。
PageRank模型也被调整用于结构化数据库。Guo et al. [7] 介绍了XRANK来使用数据库链接结构排名XML元素。Balmin et al. 提出了ObjectRank系统[3] ,应用随机行走模型到数据库关键词搜索,成为标签图。一个与我们的PPF相似的称为权威转移率(authority transfer rates)的表示被介绍。在他们的相关反馈调查研究中,作者发现对不同的边类型使用不同的传播率是有效的。但是论文没有讨论这些权威转移率怎样分配。
Xi et al. [17] 提出一个统一的链接分析框架,称为“链接融合”(link fusion),同时考虑多类型内连接数据分析对象的内外类型链接结构。PageRank和HITS算法 [10] 被展示在统一链接分析框架的特殊情况中。尽管这篇论文提到一些与我们的PPF相似的表示,但是怎样分配这些因子被考虑为这篇论文今后研究的重要工作。此外,我们的PopRank模型本身也和link fusion framework不同,在我们的PopRank模型,我们同时考虑一个对象的网络流行度和从对象关系图得到的流行度。结合两种类型的流行度是重要的,特别是在对象广泛可用的网络数据库和网页这些应用域。例如,如果我们想要建立一个产品搜索引擎来对相关产品排名,这些对象的网络流行度在计算产品的流行度时很有用,只使用对象关系图会导致不合理的排名。
7. 结论和未来的工作
这篇论文研究了怎样基于网络流行度和对象关系图来计算网络对象的对象流行度得分。传统的PageRank模型不再有效,因为对象间不均匀性的存在。我们提出对每一种对象关系自动分配一个PPF因子。本文的特色贡献是:
i. 一个PopRank模型,同时考虑一个对象的网络流行度和对象关系图来计算网络对象的PopRank得分
ii. 一个使用来自域专家的局部排名列表为不同的对象关系自动分配网络流行度因子(PPF)的途径。我们提出使用整个对象关系图的子图来提高好的PPF的搜索效率
iii. 实验在Libra的内容里完成,一个索引了1百万篇论文的对象级网络搜索原型
本文的评估仅测试了这个模型的特殊案例,没有评估网页与语义对象混杂时排名模式的影响。我们当前工作以用更一般的方法和在其他领域评价这个模型。我们相信我们的途径在大多数垂直搜索领域是通用的。例如,在产品搜索域,有几种不同的对象,如产品、商标、电子商务网站和用户。也有多种不同类型的不均匀关系,例如产品-商标、产品-网站、产品-用户。
8. 参考文献