perl学习笔记——输入与输出
读取标准输入
用<STDIN>进行标准输入:chomp($line=<STDIN>);
如果读到文件尾,行输入操作符就会返回undef。便可利用这一性质跳出循环。
while(defined ($line=<STDIN>)){
print "I saw $line";
}
简写为:
while(<STDIN>){
print "I saw $_ .";
}
注意:这个简写只在最早的写法中才能正常运行,如果将行输入操作符放在其他的任何地方(特别是自成一行),他并不会读取行输入并自动保存入默认变量$_。唯独在while循环中条件表达式里只有行输入操作符的前提下这个简写才起作用。
同样foreach也有这样的用法:
foreach (<STDIN>){
print "I saw $_";
}
不同之处在于:while每读入一行就处理一行,foreach需要一次性读完再处理。
#!/usr/bin/perl use strict; use warnings; while (<STDIN>) { print "I saw $_ \n"; } foreach (<STDIN>) { print "I saw $_ \n"; }
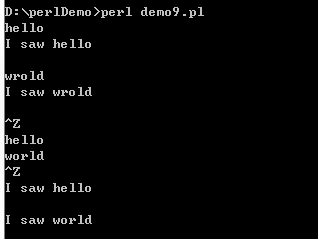
来自钻石操作符(<>)的输入
可以用钻石操作符编写类似cat、sed、awk、sort、grep、lpr等工具程序。
程序调用参数:$./my_program fred barney betty
如果比提供任何调用参数的话,程序会从标准输入流中采集数据。此外:如果用连字符(-)当作参数,则表示要从标准输入中读入数据。所以假如调用参数fred - betty,那么程序应该先处理文件fred,然后处理标准输入流提供的的数据,最后是betty。
钻石操作符就是行输入操作符的特例。不过他并不是从键盘中读取输入,而是从用户指定的位置读取:
while(defined($line =<>)){
chomp($line);
print "It was $line that I saw!\n";
}
如果现在输入的是调用参数是fred、barney、betty那么,输出结果就会是"It was [从文件中读取的一行内容] line that I saw!"等,直到遇到文件尾结束。注意:<>在读完一个文件后会接着读新的文件,然后在逐行输出内容。应为使用钻石操作符时已经报这些文件合并成一个很大的文件一样,钻石操作符只有碰到所有的输入的结尾时才会返回undef然后跳出while循环。
上面代码简写:
while (<>){
chomp;
print "It was $_ that I saw!\n";
}
注意:钻石操作符一般会处理所有的输入,所以在程序中如果看到多个钻石操作符那么通常是错误的。
#!/usr/bin/perl while (<>){ chomp; print "$_ \n"; }
//注意代码中下面执行指令中添加了-,并从grep的输出管道中读入
如果需要的不是在执行程序时由用户来指定输入数据的文档,而是直接在程序中写死了输入的数据的是哪一些文档则可以用下面的方式:
1. 调用参数@ARGV;
2. 文件句柄;
调用参数
钻石操作符的输入文件也可以来自于数组@ARGV,这个数组是Perl解释器事先建立起来的特殊数组,其内容就是命令行参数组成的列表。
钻石操作符会首先检查数组@ARGV是否为空,如果为空则改用标准输入流;four则就会使用@ARGV里的文件列表。
如:
@ARGV= qw / larry moe curely/;
while(<>){
chomp;
print "$_";
}
注意:在while中使用$ARGV 可以知道现在正在打开输入的是哪一个文件。
如:
@ARGV= qw / larry moe curely/;
while(<>){
say "$ARGV";
chomp;
print "$_";
}
例题:

第五题代码如下:
#!/usr/bin/env perl
use 5.010;
foreach (@ARGV){
$hash{$_}=1;
}
while(<>){
say "$ARGV";
if(/\A##Copyright/){
delete $hash{$ARGV};
}
}
@ARGV=keys %hash;
$^I='.bak';
$date=`date`;
while(<>){
if(/\A#!.+/)
{
s/$&/$&\n\#\#Copyright (C) $date/;
}
print;
}
输出到标准输出
print用于标准输出。
如:print "3+4=",3+4,".\n";
@array=qw / hello world /;
print @array;==>结果:helloworld
print "@array";==>结果:hello world
print <>;==>相当于Unix下的cat命令
print sort <>;==>相当于Unix下的sort命令
注意命令:
print (2+3)*4 其实等效于(print (2+3))*4
如果实在要实现(2+3)*4的结果的话,可以使用:printf "%d",(2+3)*4;或者 print ((2+3)*4);
使用printf格式化输出
如:printf "Hello,%s; your passsword expires in %d days!\n",$user,$day_to_die;
使用和C下面的差不多,这里就不多讲了。
数组和printf
举例说明吧!!!
#!/usr/bin/perl use warnings; my @items = qw / wilma dino pebbles/; my @format= "The items are :\n".("%10s\n" x @items); printf @format,@items;

说明:x操作符表示赋值指定的字符串,复制的次数和@items(此处@items是在标量上下文中的使用,所以返回的是元素个数3)的元素个数相同。所以上面的表达式其实是:The items are:\n%10s\n%10s\n%10s 。
文件句柄
文件句柄就是程序与外界之间的I/O联系的名称。Perl5.6以前叫裸字(全大写),从Perl5.6开始,我们可以把文件句柄保存在常规的标量变量中。
例如:./your_program <dino >wilma 程序输入来自于问及那dino,输出送到文件wilma。
特殊的文件句柄:STDOUT STDIN STDERR DATA ARGV ARGVOUT
打开文件句柄
使用open操作符
open CONFIG,'dino';//默认模式是从文件中读取数据,即以读模式打开
open CONFIG,'<dino';//指定文件为输入文件
open BEDROCK,'>fred';
open LOG,'>>logfile';
使用一个标量来代替文件说明符,指定输入和输出方向:
my $selected_output='my_output';
open LOG,">$selected_output";
三参数的形式写法:
open CONFIG '<','dino';
open BEDROCK,'>',$file_name;
open LOG,'>>',&logfilename();
除此之外,三参数还有另外一个好处——可以指定编码方式。
open CONFIG,'<:encoding(UTF-8)','dino';<==>open CONFIG,'<:utf8','dino'(可能会有些问题)
open BEDROCK,'>:encoding(UTF-8)',$file_name;
open LOG,'>>:encoding(UTF-8)',&logfile_name();
当然可以执行其他的编码方式:
open BEDROCK,'>:encoding(UTF-16LE)',$file_name;
注意可以用下面的命令查看所有perl能理解和处理的字符编码清单:
perl -MEncoding -le "print for Encode->encoding(':all')"
以二进制方式读写文件句柄(暂时不知道有啥用)
略。
有问题的文件句柄
和其他语言一样,Perl自身是无法打开系统中的文件的,只能要求操作系统代劳。所以,操作系统也有可能因为全县不足、文件名错误等原因拒绝打开。
如果试着从有问题的文件句柄读取数据便会立刻读到文件末尾,文件末尾在标量上下文中是undef,在列表中则是空列表。如果试图向有问题的文件句柄中写入数据,这些数据也会被丢弃。为了避免以上问题,有两种方法:
1.一开始便使用-w或者warning编译指令来启动警告功能;
2.或者使用下面方法;
my $success=open LOG,'>>','logfile';
if ( !$success){
失败时的操作...
}
关闭文件句柄(这是非常重要的,有打开就有关闭)
close <文件句柄名>;
用die处理致命错误
die函数会输出指定的信息到转为这类信息准备的标准错误流中,并且让你的程序立刻终止并返回不为0的退出码。同时die会做一件事,他会将perl程序名和出错行附加在信息的后面。
如:if(!open LOG,'>>','logfile'){
die "Cannot create logile: $!";
}
说明:当系统拒绝我们的请求服务时,$!一般会给我们一个说明,如 permission denied 或者 file not found。注意提示出错的行号和程序名称可不是$!的功能。
再比如:
if (@ARGV < 2){
die "Not enough arguments\n";
}
自动检测致命错误
use autodie;
上面的那些if 语句就不用在写了。
使用文件句柄
读入:
if (!open PASSWD ."/etc/passwd"){
die "how did you get logged in?($!)";
}
while (<PASSWD>){
chomp;
...
}
输出:
print LOG "this is a logfile";
printf STDERR "%d",100;
改变默认的文件输出句柄(注意只能改变默认的输出句柄,没有改变输入句柄)
select <文件句柄名>;
如 :
select BEDROCK;
print "I hope Mr.Slate doesn't find out about this.\n";
print "Wilma!\n";
一旦选择了文件句柄,程序就会一直往里面输入数据。这不是很友好,解决方法:
select LOG;
$|=1;#不要将LOG的内容保留在缓冲区
select STDOUT;
说明:只要将特殊变量$|设置为1,就会使当前的(也就是修改变量时所指定)的默认文件句柄在每次进行输出操作后立刻刷新缓冲区。
重新打开标准的文件句柄
如:if (! open STDERR,">>/home/barney/.error_log"){
die "Can't open error log for append;$!";
}
用say来输出
say和print相比,say会在输出时会自动加上一个换行符。
use 5.010;
print "HELLO!\n";
print "HELLO","\n";
say "HELLO";
上面三个命令输出结果相同。
标量变量中的文件句柄
如:my $rocks_fh;
open $rocks_fh,'<','rocks.txt'
or die "could not open rocks.txt:$!";
while(<$rocks_fh>){
chomp;
....
}