前言
多线程下载,顾名思义就是对一个文件进行切片访问,等待所有的文件下载完成后在本地进行拼接成一个整体文件的过程。
因此可以利用 golang 的多协程对每个分片同步下载,之后再合并且进行md5校验或者总长度校验。
请求资源
下载文件的本质就是从服务器获取数据,更笼统地说就是向服务器发送 GET请求。
http1.1协议
HTTP1.1 协议(RFC2616)开始支持获取文件的部分内容,这为并行下载以及断点续传提供了技术支持:Range\Content-Range。Range参数是本地发往服务器的http头参数;Content-Range是远程服务器发往本地http头参数。
Range\Content-Range
range: (unit=first byte pos)-[last byte pos] : 指定第一个字节位置和最后一个字节位置。
例子说明:
- range: bytes=0-1300 : 表示第0-1300字节范围的内容发往远程服务器。
- range: bytes=1301-23041: 表示第1201-23041字节范围的内容发往远程服务器。
Content-Range: bytes (unit first byte pos) - [last byte pos]/[entity legth]
例子说明:
- content-Range: bytes 0-797/1024000 : 表示0-797字节范围内容从服务器响应到客户端,1024000是文件总大小。
完成http响应后,http状态码返回:206 表示使用断掉续传方式,而一般200表示不使用断掉续传方式。
比如:
(base) luliang@shenjian ~ % curl --location --head ‘https://download.jetbrains.com/go/goland-2020.2.2.exe’
HTTP/2 302
date: Sat, 06 May 2023 11:52:42 GMT
content-type: text/html
content-length: 138
location: https://download.jetbrains.com.cn/go/goland-2020.2.2.exe
server: nginx
strict-transport-security: max-age=31536000; includeSubdomains;
x-frame-options: DENY
x-content-type-options: nosniff
x-xss-protection: 1; mode=block;
x-geocountry: China
x-geocode: CN
x-geocity: Taiyigong
HTTP/2 200
content-type: binary/octet-stream
content-length: 338589968
date: Sat, 06 May 2023 11:51:35 GMT
last-modified: Tue, 30 Mar 2021 14:16:56 GMT
etag: “548422fa12ec990979c847cfda85a068-65”
accept-ranges: bytes
server: AmazonS3
x-cache: Hit from cloudfront
via: 1.1 f7c361bc042484d244950f166c4f320c.cloudfront.net (CloudFront)
x-amz-cf-pop: PVG52-E1
x-amz-cf-id: xkbWvLoSgdyhCV-gXgANy7pq_P4ndAHEBCznYtxiOIAuvEm5ew9Qlw==
age: 72
如果在响应的Header中存在Accept-Ranges首部(并且它的值不为 “none”),那么表示该服务器支持范围请求(支持断点续传)。
可以使用 curl 发送一个 HEADER 请求来进行检测:
(base) luliang@shenjian ~ % curl -I https://download.jetbrains.com.cn/go/goland-2020.2.2.exe
HTTP/2 200
content-type: binary/octet-stream
content-length: 338589968
date: Sat, 06 May 2023 11:55:58 GMT
last-modified: Tue, 30 Mar 2021 14:16:56 GMT
etag: “548422fa12ec990979c847cfda85a068-65”
accept-ranges: bytes
server: AmazonS3
x-cache: Miss from cloudfront
via: 1.1 cf7a8587fc03d8367e313c3f45e5b454.cloudfront.net (CloudFront)
x-amz-cf-pop: BJS9-E1
x-amz-cf-id: UDJvsOsiddSrXUF9CzkUKucO9ClpNrFrj2m-M9S4LYJADs34pMn8wA==
在上面的响应中, Accept-Ranges: bytes 表示界定范围的单位是 bytes,这里 Content-Length 也是很有用的信息,因为它提供了要检索的图片的完整大小!
如果站点返回的Header中不包括Accept-Ranges,那么它有可能不支持范围请求。一些站点会明确将其值设置为 “none”,以此来表明不支持。在这种情况下,某些应用的下载管理器可能会将暂停按钮禁用!
Last-Modified\If-Modified-Since
利用HTTP协议头Last-Modified\If-Modified-Since参数存储文件最后修改日期,每次通信文件要判断与上一次文件最后修改日期是否相同,如果不同就从0开始重新接收文件,相同则继续。Last-Modified 是由服务器往客户端发送的 HTTP 头,而If-Modified-Since 则是由客户端往服务器发送的头。
例如:
- Last-Modified: Fri, 22 Feb 2023 03:45:06 GMT : 服务器端返回客户端HTTP头信息。
- If-Modified-Since: Fri, 22 Feb 2013 03:45:02 GMT : 客户端通过 If-Modified-Since HTTP头将上一次服务器端发过来的 Last-Modified 时间戳发送回服务器端进行比较验证。
NewRequest()
该NewRequest()函数的定义为:
func NewRequest(method string, url string, body io.Reader) (*Request, error)
返回一个*Request,该结构体定义为:
type Request struct {
Method string
URL *url.URL
Proto string // "HTTP/1.0"
ProtoMajor int // 1
ProtoMinor int // 0
Header Header
Body io.ReadCloser
GetBody func() (io.ReadCloser, error)
ContentLength int64
TransferEncoding []string
Close bool
Host string
Form url.Values
PostForm url.Values
MultipartForm *multipart.Form
Trailer Header
RemoteAddr string
RequestURI string
TLS *tls.ConnectionState
Cancel <-chan struct{}
Response *Response
ctx context.Context
}
http.DefaultClient.Do()
该函数定义为:
func (c *Client) Do(req *Request) (*Response, error) {
return c.do(req)
}
而函数 do()也返回一个 *Response,Response的结构体定义如下:
type Response struct {
Status string // e.g. "200 OK"
StatusCode int // e.g. 200
Proto string // e.g. "HTTP/1.0"
ProtoMajor int // e.g. 1
ProtoMinor int // e.g. 0
Header Header
Body io.ReadCloser
ContentLength int64
TransferEncoding []string
Close bool
Uncompressed bool
Trailer Header
Request *Request
TLS *tls.ConnectionState
}
可以看到,Response 中有StatusCode 、Header 、Body等我们想要的信息。
因此可以打一套组合拳将Response得到:
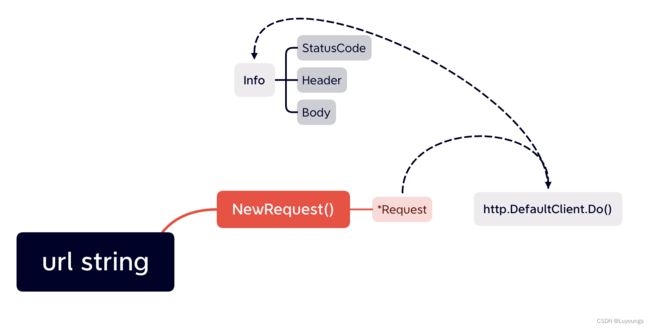
用函数实现就是:
func (d *FileDownloader) getHeaderInfo() (int, error) {
headers := map[string]string{
"User_Agent": userAgent,
}
req, err := getNewRequest(d.url, "HEADER", headers) // 得到一个 request
resp, err := http.DefaultClient.Do(req) // 利用 req 发送请求,获得一个请求
if err != nil {
return 0, err
}
fmt.Println(req)
fmt.Println(resp)
fmt.Println(resp.StatusCode)
// 对响应做出相应的处理
//信息响应 (100–199)
//成功响应 (200–299)
//重定向消息 (300–399)
//客户端错误响应 (400–499)
//服务端错误响应 (500–599)
if resp.StatusCode > 299 {
// 如果出错就直接返回
return 0, errors.New(fmt.Sprintf("Can't process, response is %v", resp.StatusCode))
}
// 检查是否支持断点续传
if resp.Header.Get("Accept-Ranges") != "bytes" {
return 0, errors.New("服务器不支持文件断点续传")
}
// 支持断点传送时,获取相应的信息
//获取文件名
outputFileName, err := parseFileInfo(resp)
if err != nil {
return 0, errors.New(fmt.Sprintf("get file info err: %v", err))
}
// 返回文件名
if d.outputFileName == "" {
d.outputFileName = outputFileName
}
// 返回文件的长度
return strconv.Atoi(resp.Header.Get("Content-Length"))
}
// 返回一个 Request
func getNewRequest(url, method string, headers map[string]string) (*http.Request, error) {
r, err := http.NewRequest(
method,
url,
nil,
)
if err != nil {
return nil, err
}
// 设置头部信息,即 UserAgent 信息
for k, v := range headers {
r.Header.Set(k, v)
}
return r, err
}
获取文件名
我们先看看 Hear 上定义的方法:
A Header represents the key-value pairs in an HTTP header. The keys should be in canonical form, as returned by CanonicalHeaderKey. Methods on (Header): Add(key string, value string) Set(key string, value string) Get(key string) string Values(key string) []string get(key string) string has(key string) bool Del(key string) Write(w io.Writer) error write(w io.Writer, trace *httptrace.ClientTrace) error Clone() http.Header sortedKeyValues(exclude map[string]bool) (kvs []http.keyValues, hs *http.headerSorter) WriteSubset(w io.Writer, exclude map[string]bool) error writeSubset(w io.Writer, exclude map[string]bool, trace *httptrace.ClientTrace) error `Header` on pkg.go.dev
里面有一个 get方法,它传入一个 key,返回一个值。我们可以传入一个想要的键从而得到想要的信息。
如果我们可以传入一个"Content-Disposition",得到 fileName。Content-Disposition就是当用户想把请求所得的内容存为一个文件的时候提供一个默认的文件名。
// 或得 filename
func parseFileInfo(resp *http.Response) (string, error) {
contentDisposition := resp.Header.Get("Content-Disposition")
if contentDisposition != "" {
_, params, err := mime.ParseMediaType(contentDisposition)
if err != nil {
return "", err
}
return params["filename"], nil
}
filename := filepath.Base(resp.Request.URL.Path)
return filename, nil
}
下载文件
两个重要的结构体:
// FileDownloader 定义下载器
type FileDownloader struct {
// 待下载文件大小
fileSize int
// 目标源连接
url string
// 下载文件存储名
outputFileName string
// 文件切片的总数
totalPart int
// 文件存储目录
outputDir string
// 已完成文件切片
doneFilePart []filePart
// 文件校验
md5 string
}
// 文件分片
type filePart struct {
// 文件分片序号
Index int
// 开始下载 byte 起点
From int
// 结束byte
To int
// 下载得到的内容
Data []byte
}
其中一个是定义的下载器,这个下载器定义了源地址、总文件大小、文件名、文件存储地址、md5 校验等;另一个定义了一个分片,这个分片定义了分片的身份(编号),文件开始点、结束点以及一个存储数据的Data。
接下来就可以初始化下载器了,填充一些基本的信息:
// NewFileDownloader 创建下载器(初始化)
func NewFileDownloader(url, outputFileName, outputDir string, totalPart int, md5 string) *FileDownloader {
if outputDir == "" {
// 如果为空,就获取当前目录
wd, err := os.Getwd()
if err != nil {
log.Println(err)
}
outputDir = wd
}
return &FileDownloader{
fileSize: 0,
url: url,
outputFileName: outputFileName,
totalPart: totalPart,
doneFilePart: make([]filePart, totalPart),
md5: md5,
outputDir: outputDir,
}
}
下载分片
func (d *FileDownloader) downloadPart(c filePart) error {
headers := map[string]string{
"User-Agent": userAgent,
"Range": fmt.Sprintf("bytes=%v-%v", c.From, c.To),
}
// 或得一个 request
r, err := getNewRequest(d.url, "GET", headers)
if err != nil {
return err
}
// 打印要下载的分片信息
log.Printf("开始[%d]下载from:%d to:%d\n", c.Index, c.From, c.To)
resp, err := http.DefaultClient.Do(r)
if resp.StatusCode > 299 {
return errors.New(fmt.Sprintf("服务器错误状态码: %v", resp.StatusCode))
}
// 最后关闭文件
defer func(Body io.ReadCloser) {
err := Body.Close()
if err != nil {
}
}(resp.Body)
// 读取 Body 的响应数据
bs, err := io.ReadAll(resp.Body)
if err != nil {
return err
}
if len(bs) != (c.To - c.From + 1) {
return errors.New("下载文件分片长度错误")
}
c.Data = bs
// c完成了后就加入到下载器中
d.doneFilePart[c.Index] = c
return nil
}
这个思路就是就把 Body 存储起来,那就是有效数据。之后就可以把所有的 数据合成成一个完整文件。
合成文件
// 合并要下载的文件
func (d *FileDownloader) mergeFileParts() error {
path := filepath.Join(d.outputDir, d.outputFileName)
log.Println("开始合并文件")
// 创建文件
mergedFile, err := os.Create(path)
if err != nil {
return err
}
// 最后关闭文件
defer func(mergedFile *os.File) {
err := mergedFile.Close()
if err != nil {
}
}(mergedFile)
// sha256是一种密码散列函数,说白了它就是一个哈希函数。
//对于任意长度的消息,SHA256都会产生一个256bit长度的散列值,
//称为消息摘要,可以用一个长度为64的十六进制字符串表示。
fileMd5 := sha256.New()
totalSize := 0
// 合并的工作
for _, s := range d.doneFilePart {
_, err := mergedFile.Write(s.Data)
if err != nil {
fmt.Printf("error when merge file: %v\n", err)
}
fileMd5.Write(s.Data) // 更新哈希值
totalSize += len(s.Data) // 更新长度
}
// 校验文件完整性
if totalSize != d.fileSize {
return errors.New("文件不完整")
}
// 检验 MD5
if d.md5 == "" {
// 将整个文件进行了 Sum 运算, 该函数返回一个 16 进制串,转成字符串之后,
// 和 d.md5比较,起到了一个校验的效果
if hex.EncodeToString(fileMd5.Sum(nil)) != d.md5 {
return errors.New("文件损坏")
} else {
log.Println("文件SHA-256校验成功")
}
}
return nil
}
该函数合成了新文件还对文件完整性、MD5 做了校验。
多线程下载
func (d *FileDownloader) Run() error {
// 获取文件大小
fileTotalSize, err := d.getHeaderInfo()
if err != nil {
fmt.Printf("hello!!")
return err
}
d.fileSize = fileTotalSize
jobs := make([]filePart, d.totalPart)
// 这里进行均分
eachSize := fileTotalSize / d.totalPart
for i := range jobs {
jobs[i].Index = i
// 计算 form
if i == 0 {
jobs[i].From = 0
} else {
jobs[i].From = jobs[i-1].To + 1
}
// 计算 to
if i < d.totalPart-1 {
jobs[i].To = jobs[i].From + eachSize
} else {
// 最后一个filePart
jobs[i].To = fileTotalSize - 1
}
}
// 多线程下载
var wg sync.WaitGroup
for _, j := range jobs {
wg.Add(1)
go func(job filePart) {
defer wg.Done()
err := d.downloadPart(job)
if err != nil {
log.Println("下载文件失败:", err, job)
}
}(j)
}
wg.Wait()
return d.mergeFileParts()
}
该函数将文件总长度信息获取之后,进行了等分的分片,然后开启协程进行并发请求。
之后,我们在 main()函数中填上目标链接以及 md5值就可以下载了。
func main() {
startTime := time.Now()
url := "https://speed.hetzner.de/100MB.bin"
md5 := "2f282b84e7e608d5852449ed940bfc51"
downloader := NewFileDownloader(url, "", "", 8, md5)
if err := downloader.Run(); err != nil {
log.Fatal(err)
}
fmt.Printf("\n 文件下载完成耗时: %f second\n", time.Now().Sub(startTime).Seconds())
}
运行效果:
2023/05/07 19:56:48 开始[7]下载from:365989316 to:418273495
2023/05/07 19:56:48 开始[0]下载from:0 to:52284187
2023/05/07 19:56:48 开始[5]下载from:261420940 to:313705127
2023/05/07 19:56:48 开始[4]下载from:209136752 to:261420939
2023/05/07 19:56:48 开始[3]下载from:156852564 to:209136751
2023/05/07 19:56:48 开始[1]下载from:52284188 to:104568375
2023/05/07 19:56:48 开始[6]下载from:313705128 to:365989315
2023/05/07 19:56:48 开始[2]下载from:104568376 to:156852563
…………
总结
该程序的流程简单,和爬虫相比,更简单,毕竟不用使用各种选择器+正则表达式来获取特定元素。本质上来说,就是在获取 GET 请求,只是绕的弯比较多。
另外这里有一个获取某个文件 md5 值的方法:
func getFileMd5(filename string) string {
// 文件全路径名
path := fmt.Sprintf("./%s", filename)
pFile, err := os.Open(path)
if err != nil {
log.Println("打开文件失败!")
return ""
}
defer func(pFile *os.File) {
err := pFile.Close()
if err != nil {
}
}(pFile)
md5h := md5.New()
io.Copy(md5h, pFile)
return hex.EncodeToString(md5h.Sum(nil))
}
func main() {
// 当前目录的csv配置文件为例
fileName1 := "Tasks/Downloader/100MB.bin"
fileName2 := "goland-2020.2.2.dmg"
md5Val := getFileMd5(fileName2)
md5Val1 := getFileMd5(fileName1)
fmt.Println("配置文件的md5值:", md5Val, md5Val1)
// 配置文件的md5值: 8c2e8bcad8f0612fb62c8d5bd21efb8f 2f282b84e7e608d5852449ed940bfc51
}
到此这篇关于Golang多线程下载器实现高效快速地下载大文件的文章就介绍到这了,更多相关Golang多线程下载器内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!