C语言多线程爬虫代码示例
使用C语言编写多线程爬虫能够同时处理多条数据,提高了爬虫的并发度和效率。在编写多线程爬虫时仍需要注意线程安全性和错误处理机制,并根据系统资源和目标网站的特点调整线程数和优化并发策略,以提高程序效率和稳定性。
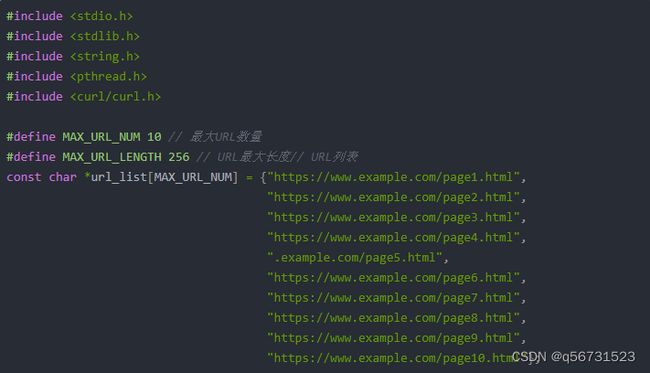
以下是一个使用C语言多线程编写的简单爬虫示例,实现了并发爬取多个页面的功能:
#include 在以上示例中,我们使用了libcurl库来发起HTTP请求和接收响应。为了方便演示,我们直接预定义了10个URL,并启动10个线程并行执行爬虫任务。实际项目中,可以通过读取配置文件或从命令行参数中获取URL列表,并根据系统资源、网络质量等因素自适应地调整并发度。
在实现过程中,需要注意线程安全性和错误处理机制,避免出现死锁、内存泄漏等问题。