qemu tcg系列-概览
Qemu是一个流行的模拟器软件,主要特点:
- 它支持各种流行的arch,x86, arm, mips, riscv等
- 它可以作为kvm/xen/hyper-v等虚拟化方式的管理端,当运行KVM模式下,目前作为底层构件被广泛用于各种云上,目前各家的虚拟化效率都基本达到了90+%
- Qemu可以作为纯粹的跨架构的模拟器,模拟不同的machine,也就是TCG模式下可以仅通过软件就可以模拟出在真实机器上的运行效果。无需真实的硬件资产就能部署开发验证环境
- 支持数量繁多的模拟设备,包括网卡,存储, USB控制器,显卡,串口等,并且集成了专为虚拟化设计的virtio系列设备仿真
这个系列主要是尝试分析qemu tcg方面的一些原理。
Qemu TCG
TCG是Tiny Code Generator的缩写,最早是用在gcc种,作为一种通用后端来使用的,在这里我们简单将它称为qemu TCG模式,因为目前的开发环境是在loongarch平台上,下面就以 x86<->loongarch 的翻译为例分析。
TCG又分为两种模式:只运行app和仿真整个系统,前者只有指令翻译(普通指令),通常称为linux-user,后者包括整个系统的仿真:特权态指令,中断控制器,桥片,MMU等,通常称为softmmu。
在TCG模式下可以跨平台运行不同指令集的程序或操作系统。例如典型的android模拟器,android镜像大多数是基于arm构建的,但是我们可以在x86上运行qemu模拟器运行android系统,在上面适配各种应用。
在TCG模式下我们通过target和host来区分宿主机和模拟的指令架构,target是要模拟的指令架构或者计算机,host是Qemu运行的环境。使用android模拟器情况下 target 是 arm, host 是 x86 。
TCG翻译执行
TCG以块为单位,将target的指令动态翻译成host指令,为了解耦不同arch上的关系,tcg设计成 target -> IR -> host , IR 也是一套虚拟的RISC 指令,target 只需要关注如何翻译到 IR ,host只需要关注如何翻译IR。前后端分离的架构对于新增某一种架构就相对比较简单,可以单独增加前端和后端的翻译。
target <-------------> IR <----------------> host
TCG 翻译过程中以Translation Block 为单位,即翻译块, 它对应一组target指令, 基本的操作就是扫描翻译target指令到 IR 直至以下几个条件:跳转指令, 系统调用,或者到达页的边缘,然后将tb的指令优化并翻译成host指令。一个tb中最多只有一个跳转指令。
- 为什么要分块管理?
程序可能很大,不可能全部翻译缓存,必须要分块,这样才能管理,所以出现了TB的概念。 - 为什么是这几个指标来分块呢?
跳转指令: TCG中只是模拟执行,最大的变化是寄存器, 从硬件变成了内存存储,”直接使用寄存器“ 变成了 “寄存器内存 加载-》 寄存器 -》回写 寄存器内存 ” ,原来的硬件流水线 “取指 -> 执行” 并没有本质的变化,只是中间加了一道环节变为了 “取指 -> 翻译 -> 执行”;
中间有一个特殊的情况:跳转,跳转的目标对象是target的PC而不是翻译后的host的PC, 所以通常是无法直接在host指令中跳转而是需要qemu帮助根据target pc找到对应的tb,再跳转。后面会有direct jump的优化,但是并不能掩盖跳转的目标依据是target pc的基本事实。 - 系统调用: 系统调用需要host帮助它实现具体的操作,其中target的syscall ABI和调用号不一定一致,直接翻译需要完成大量的汇编代码,不如直接回到qemu使用通用代码来完成。
- 到达页的边缘: 翻译指令的缓存不可能无限增加,当缓存数量较多时需要刷掉部分的缓存,而无效操作是以页为单位,跨页的tb比较麻烦。
为什么称TCG为JIT类型呢?
JIT是just in time的缩写,现代所有的高级语言运行环境中都有JIT实现,例如jvm,ebpf, python等,将类似于高级指令或者字节码的批量动态翻译成native的指令并且缓存起来,这样就能直接执行native指令来加速运行。TCG也是边翻译边执行,同时将翻译好的代码缓存起来,下次再次执行时能够加速,实现了JIT的概念。这里就要提一下android的AOT,将热点代码缓存到存储上以备下次使用,对于热点代码直接跳过翻译阶段,QEMU TCG产品化过程中是否也可以考虑一下这种方式呢。
在TCG模式下执行代码过程如下:
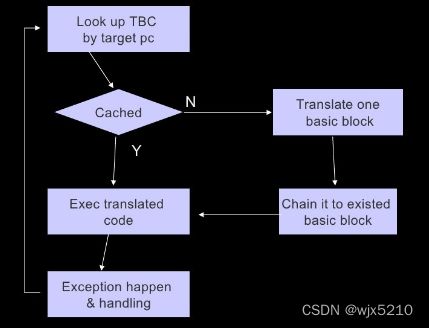
TCG执行过程如上图:
- 根据 pc 查找是否已经有缓存的TB,如果有则直接跳转过去执行
- 如果缓存中没有对应的翻译块,则开始翻译。翻译结束后尝试将上一个翻译块和当前翻译块进行一个链接,在direct link中会详细解释
- 执行缓存中的翻译块,直至异常发生,异常发生后调用 target 中的异常处理。在linux-user 模式下通常是系统调用,softmmu模式下就是计算机中的各种异常:异步异常(中断),同步异常(TLB类异常[load/store/读写执行],syscall,指令类异常[无效指令,指令特权态错误])。
关键的代码流程
cpu_exec
tb = tb_find(cpu, last_tb, tb_exit, cflags);
cpu_loop_exec_tb(cpu, tb, &last_tb, &tb_exit);
tb_find
tb = tb_lookup__cpu_state(cpu, &pc, &cs_base, &flags, cf_mask); //在cache中根据target PC 查找TB
if (tb == NULL) {
tb_gen_code(cpu, pc, cs_base, flags, cf_mask); //遍历target指令生成native code,中间先将target指令转换成IR,然后再将IR转换成native指令
}
if (last_tb) {
tb_add_jump(last_tb, tb_exit, tb);
}
tb_gen_code
tb = tb_alloc(pc);
gen_intermediate_code(cpu, tb);
gen_code_size = tcg_gen_code(tcg_ctx, tb);
tcg_tb_insert(tb);
我们先关注linux-user模式下也即是只翻译运行app的模式。
TCG执行时首先根据targe PC来找到对应TB,如果存在TB则说明它已经被翻译过并且缓存起来,直接执行就好。
如果没有在缓存中找到则开始翻译,翻译大体分为三步: target指令->IR, IR指令的优化, IR->host指令翻译。通常 target指令->IR 称为 frontend(前端翻译), IR->host指令 称为backend(后端翻译)。
在TCG翻译过程中,IR 存在几个概念:
- function: 对应着一个TB,通常一个TB通常以跳转指令结束
- basic block是比TB更小地单位,例如将一个寄存器的值rj加上一个立即数,存放到rd中,IR只有寄存器相加和寄存器赋值,所以它就需要分为两步,将立即数放到临时寄存器然后执行加法,那么首先就需要申请一个临时变量来存放临时变量,使用完释放。
- temporary:一个basic block中的临时变量,在前端翻译过程中需要显示地申请和释放。
- local temporary:它的生命周期是在一个TB中始终存在的。
- global:在整个程序运行过程中始终有效,它可以是一个内存地址,固定的寄存器类型。
temporary临时变量的翻译结果
loongarch原始指令:
addi.d $r30,$r24,8(0x8)
IR指令:
movi_i64 tmp2,$0x8
add_i64 s7,s1,tmp2
两条IR就是一个基本生命周期,用完就可以释放,在下面的basic block中可以重用。
tcg初始化
tcg前端初始化
这里还是先只讨论linux-user模式,它相对比较简单,softmmu需要初始化整个machine的状态而Linux-user没有machine的概念。
linux-user只支持模拟应用程序运行,入口在linux-user/main.c, 主要是支持ELF格式的可执行文件。在linux-user中不需要初始化前端的状态,它会解析需要翻译的可执行程序并找到入口点entry,从entry位置开始执行。
需要像内核一样加载程序并传给它一些变量,加载时包括以下几个方面:
1. 程序的加载
2. 程序的传参
3. 指令的翻译
- target程序加载和程序传参
target程序目前支持elf, elf头是跨体系结构的,从elf头可以解析section和segment的信息,可以获得入口地址,每个segment的范围,堆的地址等等。
qemu中加载elf和内核中是相同的,但是简化了很多,load_elf_binary 中根据segment 的地址将各个段映射到对应的位置,如果不幸和qemu中已有地址冲突了,直接退出了。
之后是程序参数和环境变量的处理,将qemu中的解析出的环境变量和参数放到对应的位置。
从这个角度看,这块需要模拟的不多,加载程序放到指定位置, 函数的入口地址放到 CPULOONGARCHState->active_tc.PC中,这样首次的tb_find就有了目标。
main() {
loader_exec(execfd, filename, target_argv, target_environ) //加载应用程序,除此之外还有环境变量,参数
tcg_prologue_init(tcg_ctx);
tcg_region_init();
cpu_loop(env);
}
loader_exec() {
bprm->fd = fdexec; //bprm和内核中相同,一个对象程序的所有信息都有了
bprm->filename = (char *)filename;
bprm->argc = count(argv);
bprm->argv = argv;
bprm->envc = count(envp);
bprm->envp = envp;
retval = prepare_binprm(bprm);
load_elf_binary(bprm, infop);
}
load_elf_binary() {
load_elf_image(bprm->filename, bprm->fd, info, &elf_interpreter, bprm->buf); //加载程序镜像
setup_arg_pages(bprm, info); //准备参数
bprm->p = copy_elf_strings(1, &bprm->filename, scratch, bprm->p, info->stack_limit);
info->file_string = bprm->p; //文件名
bprm->p = copy_elf_strings(bprm->envc, bprm->envp, scratch, bprm->p, info->stack_limit);
info->env_strings = bprm->p; //环境变量
bprm->p = copy_elf_strings(bprm->argc, bprm->argv, scratch, bprm->p, info->stack_limit);
info->arg_strings = bprm->p; //参数
}
load_elf_image() {
load_addr = target_mmap(loaddr, hiaddr - loaddr, PROT_NONE,
MAP_PRIVATE | MAP_ANON | MAP_NORESERVE, -1, 0);
info->entry = ehdr->e_entry + load_bias; //程序的入口
}
tcg后端初始化
后端和arch相关的主要集中在tcg_target_init。
tcg翻译target指令会遇到以下几种类型的指令:
TCG_TYPE_I32
TCG_TYPE_I64
TCG_TYPE_V64 //64位向量
TCG_TYPE_V128 //128位向量
TCG_TYPE_V256 //256位向量
翻译过程中需要保留一些特殊寄存器用来保存一些全局变量,是和arch ABI强相关的,例如SP,TP, ZERO等;
另外还需要定义在函数调用过程中哪些是callee-saved的寄存器,这些寄存器
定义了几个 GPR 的 bitmap :tcg_target_available_regs,tcg_target_call_clobber_regs,tcg_target_reg_alloc_order, tcg_target_call_iarg_regs, tcg_target_call_oarg_regs, s->reserved_regs
tcg_target_available_regs: 不同类型指令中可用的寄存器 bitmap
tcg_target_call_clobber_regs: 在函数调用过程中 caller 需要保存的寄存器
tcg_target_callee_save_regs: 在函数调用过程中 callee 需要保存的寄存器
tcg_target_call_iarg_regs: 在函数调用过程中寄存器传参的寄存器列表
tcg_target_call_oarg_regs:在函数调用过程中返回值寄存器列表
s->reserved_regs:在翻译 IR -> host 指令过程中不会使用的寄存器列表,类似于SP, TP, ZERO 和一些其他 reserved 的寄存器
在 qemu -> code cache 中它模拟的是函数调用过程,caller 对 caller clobbered寄存器进行保存,在prologue中 将callee saved 的寄存器都进行了入栈保存,其他不能使用的寄存器在 s->reserved_regs中进行标记,所以理论上在code cache 中可以使用除 s->reserved_regs 之外的所有寄存器。
定义了两个寄存器列表:tcg_target_reg_alloc_order 和 indirect_reg_alloc_order , 这两个的用途不同,前者主要是给 临时变量使用, 后者主要是给全局内存变量使用,通过定义不同的顺序可以减少变量使用寄存器的冲突概率。在寄存器使用冲突时需要保存原有寄存器内容到内存中,减少冲突就能减少指令。
tcg_target_reg_alloc_order: 翻译 IR -> host 申请使用 REG 的列表顺序,一般优先 callee saved寄存器,给临时变量使用。
indirect_reg_alloc_order:翻译 IR -> host, 一半是 callee saved寄存器逆序,给全局内存变量使用。
-
全局的TCGContext初始化
翻译代码时目前是单线程的,共享同一份的上下文,这样可以确保 同一份target 代码只会生成一份对应的 code cache, 在 tcg_context_init(&tcg_init_ctx); 初始化过程中,初始化 IR指令和helper指令和 TCGContext 的一些内部成员,为后续的指令翻译做准备。 -
prologue初始化
prologue 用来切换 qemu 代码和 code cache 的代码上下文,在 tcg_prologue_init(tcg_ctx) 调用 host 的 tcg_target_qemu_prologue 来组装这块代码。
在x86上组装出来的代码如下:
0x5644ca0ab000: push %rbp //函数调用过程中将callee saved的入栈保存,完成了callee本身需要做的事情,因此在执行tb代码时可以使用所有的寄存器,在tb执行过程中不遵循函数调用的接口规范了
0x5644ca0ab001: push %rbx
0x5644ca0ab002: push %r12
0x5644ca0ab004: push %r13
0x5644ca0ab006: push %r14
0x5644ca0ab008: push %r15
0x5644ca0ab00a: mov %rdi,%r14 //env到r14中,本身指向CPULOONGARCHState的对象,tb操作的对象都在
0x5644ca0ab00d: add $0xfffffffffffffb78,%rsp //
0x5644ca0ab014: jmpq *%rsi //跳转的tb的起始位置
0x5644ca0ab016: xor %eax,%eax //epilogue位置,返回值为0. 主要是为了goto_ptr使用
0x5644ca0ab018: add $0x488,%rsp //正常退出
0x5644ca0ab01f: emms
0x5644ca0ab022: pop %r15 //saved寄存器出栈
0x5644ca0ab024: pop %r14
0x5644ca0ab026: pop %r13
0x5644ca0ab028: pop %r12
0x5644ca0ab02a: pop %rbx
0x5644ca0ab02b: pop %rbp
0x5644ca0ab02c: retq //退出到qemu中
frontend的翻译
在target指令翻译过程TB以跳转指令结束,其他指令只需要根据语义翻译成IR指令就可以。其中比较特殊的是跳转指令,TB开始和TB结束时的一些特殊代码.
- TB开始位置:
gen_tb_start
ld_i32 tmp0,env,$0xffffffffffffffe4 //env指向CPULOONGARCHState,偏移是CPUState.icount_decr.u32相对于env的偏移;
movi_i32 tmp1,$0x0
brcond_i32 tmp0,tmp1,lt,$L0 //如果icount_decr.u32小于0则跳转到label 0处
参考文档: https://qemu.readthedocs.io/en/latest/devel/tcg-icount.html
icount只有在SOFTMMU中才有用,并且不能用在multi-threaded TCG 中,主要用于执行过程中指令的计数,后面详细再讲。
- TB结束:
gen_tb_end
set_label $L0 //生成一个label 0,给`br $label`或者`brcond_i32/i64 label`,`goto_tb`这些提供錨点
exit_tb $0x55f975f8bec3 //退出到tb_ret_addr
- 跳转指令:
- 有条件相对跳转
loongarch:
0x000000012001cae4: 40000d80 beqz $r12,12(0xc) # 0x2001caf0
IR:
---- 000000012001cae4 0000000000000000 0000000000000000
mov_i64 tmp2,t0 //目标寄存器
movi_i64 tmp3,$0x0 //zero
setcond_i64 bcond,tmp2,tmp3,eq //bcond是一个全局mem,if(tmp2 eq tmp3) bcond=true; else bcond = false;
movi_i64 tmp2,$0x0 //
brcond_i64 bcond,tmp2,ne,$L1 //if (tmp2 ne bcond) branch L1; L1是满足跳转条件的下一条指令
goto_tb $0x1 //第一次执行时是下一条指令,第二次执行时是next tb的第一条指令
movi_i64 PC,$0x12001cae8 //下一条指令
exit_tb $0x55f975f8bec1 //退出tb,返回值为tb和jump slot index 1的混合
set_label $L1
goto_tb $0x0
movi_i64 PC,$0x12001caf0 //跳转地址
exit_tb $0x55f975f8bec0 //退出tb,返回值为tb和jump slot index 0的混合
第一次执行时,goto_tb只是跳转到下一条指令,更新PC然后退出当前tb,此时是未优化的版本。
执行过程中qemu会根据pc寻找next tb,在执行next tb之前对上一个tb打补丁。
再次执行当前tb时,到了goto_tb跳转时,它已经被修改,会直接跳转到next tb的第一条指令而不需要返回到qemu中。
使用goto_tb + exit_tb,需要满足如下条件:
1. CPU state一定是常量,例如是否支持direct branch
2. direct branch不能进行跨页跳转。因为内存映射可能会随时被改变,目标地址可能无效或者更换了。
- 带返回跳转
loongarch:
0x0000000120000968: 55c0f000 bl 114928(0x1c0f0) # 0x2001ca58
IR:
movi_i64 ra,$0x120000968 //将返回值放回到ra中. ra,PC都是一个全局地址变量
goto_tb $0x0 //如果当前的tb链接到index的TB,则goto_tb退出当前的tb然后跳转到index的TB。否则执行下一条指令。
movi_i64 PC,$0x12001c018 //将跳转地址放到PC中
exit_tb $0x55f1cb190900 //退出tb,返回值为当前执行的tb地址和跳转的index
- 无条件相对跳转
loongarch:
0x000000012001c308: 53fdfbff b -520(0x3fffdf8) # 0x2001c100
IR:
goto_tb $0x0 //goto_tb只接受0或1的参数,一个tb中也最多只有两个label,一个是退出时的L0,还有一个是条件跳转时的L1。
movi_i64 PC,$0x12001c180 //跳转的PC
exit_tb $0x55f1cb191f40 //
- 带返回寄存器跳转
loongarch:
0x0000000120000710: 4c000021 jirl $r1,$r1,0(0x0)
IR:
mov_i64 btarget,ra //将ra保存到btarget
movi_i64 ra,$0x120000714
mov_i64 PC,btarget
call lookup_tb_ptr,$0x60,$1,tmp6,env //这个是找下一个tb的,见accel/tcg/tcg-runtime.c:void *HELPER(lookup_tb_ptr)(CPUArchState *env), 如果下一个pc对应的tb存在则返回起始地址。否则返回tcg_ctx->code_gen_epilogue,它增加了返回值赋0的动作。
goto_ptr tmp6 //根据找到的地址跳转。goto_ptr一般前面跟着call lookup_tb_ptr查找的结果
backend的翻译
backend的翻译也只看 IR 中比较特殊的指令,普通指令翻译就略过了。
- call
在REAME中call指令的形式是call, 不过通过ptr -d opdump出来的是如下形式:
call lookup_tb_ptr,$0x60,$1,tmp2,env
调用的函数名称:lookup_tb_ptr
返回值:tmp2
参数:env
flags:
0x60 = TCG_CALL_NO_WRITE_GLOBALS|TCG_CALL_NO_SIDE_EFFECTS
call作用是直接使用qemu中helper函数
实现方式和手动组装汇编相似,都是遵循函数调用的ABI来进行函数调用,需要解决几个问题:输入参数,输出参数,caller clobbered寄存器的保存。
在 tcg_target_init 架构实现中,需要指定初始化 tcg_target_available_regs,实际上就是 函数调用过程中传参顺序, arg0, arg1…放哪个寄存器, 如果传参超过了最大传参则将多余的参数压栈。
输入参数:
首先计算超出寄存器最大传参的,然后通过入栈,写入栈指针上的空间,这部分是在tcg_target_qemu_prologue初始化过程中预留好的,给call 过程中栈传参专用的,目前通常是128个 LONG型的空间。
寄存器传参填入: 根据tcg_target_call_iarg_regs 的顺序选择寄存器,如果该寄存器正在被使用则将它首先保存回内存寄存器文件。之后将参数加载到寄存器中
保存caller clobbered寄存器:
当前整个TB就是一个函数,它的入口是tcg_qemu_tb_exec,在TB整个范围内认为所有通用用途寄存器都可用。现在要调用其他函数,需要保存caller-clobbered寄存器tcg_target_call_clobber_regs,在x86上就是
生成call指令:
不同平台上会根据跳转距离生成不同的指令
返回值:
根据ABI来处理返回值,tcg_target_call_oarg_regs 定义了返回值列表寄存器,然后将返回值寄存器放回到输出参数的位置
-
dicard
丢弃该指令,很简单直接丢弃。 -
set_label
它并不会生成实际的汇编代码,而只是记录当前label的位置,如果之前有使用该label的,则进行一个重定位操作patch_reloc,如果没有则记录位置,后面使用label时再进行重定位,使用label的IR指令有br $label或者brcond_i32/i64 label,goto_tb。
在一个TB中最多有两个label,每个label表示一个basic block的结束,会将局部临时变量和全局变量进行保存。
basic block是比TB更小的单位,它从上一个basic block结束或者set_label的位置开始,遇到下面几条指令结束:branch指令,goto_tb, exit_tb, set_label, 在一个basic block结束的时候,标志着临时变量都被销毁,局部临时变量和全局变量需要保存到内存中。
所以在set_label标志着新的basic block的开始,也标志着当前block的结束,所以需要进行环境的清理。在实际实现中通过Livepass的分析,局部临时变量和全局变量应该已经和内存中保持一致了,在这个位置只是检查一致性。
-
其他通用指令的处理
其他指令分为参数的加载和IR指令->host指令的翻译转换。
参数分为输入参数和输出参数。输入参数:
有不同的类型:CONST常数, MEM中数据,REG。其中CONST常数如果能直接放到指令中那就不需要额外操作,如果不能则需要申请一个新的寄存器加载到寄存器中;MEM类型需要申请一个新的寄存器然后加载到寄存器中;REG只需要检查寄存器是否符合约束条件即可。输出参数:
选择合适的reg作为输出REG,但是并不会有加载数据到REG的操作,和输入参数不同的是,在生成指令后面会有对输出REG数据的操作
1. 对于TCGTemp要求 fixed_reg 但是REG != TCGTemp->reg的需要有 拷贝操作: mov TCGTemp->reg, REG
2. 检查是否需要SYNC,从REG中回写到内存
3. 检查是否DEAD,这部分并不会修改REG,而是标记该REG已经没有被使用,TCGTemp的val_type类型为DEAD
之后就是生成指令tcg_out_op,调用arch的接口生成host指令这里简单介绍一下TCGTemp中的几个成员,TCGTemp代表IR中的所有变量,包括temp,local temp, global:
val_type:DEAD, CONST, MEM, REG; DEAD标记已经不使用了,CONST标记这个临时变量是一个阐述,MEM:标记是一个内存中的数据,REG表示当前已经加载到REG中了。在TCG IR的设计过程中,它使用RISC模型,并不会直接操作内存,而是有专门的load/store来同步内存数据到寄存器中,数据也是在寄存器中进行运算;在使用过程中CONST可能直接被放到指令中,也可能需要加载到REG,而MEM需要加载到REG中。
temp_global:是否是全局变量
temp_local: 是否是局部临时变量
temp_allocated:是否已经
reg: 数据加载到哪个寄存器中了,此时它的val_type = REG
mem_coherent:如果是内存变量,当它加载到REG中之后可能会被修改,这样就出现数据不一致的现象,在basic block结束的时候或者标记SYNC时会将reg中同步回内存中
mem_base, mem_offset:在内存中的位置, load/store时使用
mem_allocated: 额外申请内存时,一般时global memory变量和call过程中需要通过栈传参时
val: CONST类型使用
fix_reg: 使用固定的寄存器
寄存器使用中的几个接口,内部通过bitmap来管理:
tcg_regset_test_reg:查看reg是否已经被使用
tcg_regset_set_reg:标记reg已经被使用
tcg_reg_alloc:申请使用reg
tcg_reg_free:释放reg, 会找到对应的TCGTemp并且同步回内存中
reg和TCGTemp的映射关系:
reg->TCGTemp: TCGContext->reg_to_temp[TCG_TARGET_NB_REGS]
TCGTemp->TCGReg: TCGTemp->reg -
goto_tb
goto_tb index退出当前的TB跳转到index TB位置,index只能是0和1。在i386下通过jmp类指令实现,在初次生成的指令中就是简单的跳转到下一条指令,在运行过程中会尝试进行direct jump的操作,这样就能直接跳转到其他TB的起始位置。
除了生成jmp指令外,还保存了当前jmp指令在TB中的偏移,这样在可以direct jump时修改该位置的跳转偏移到目标TB。 -
goto_ptr
这个就是寄存器跳转指令jmp,它现在的主要用途是和 call lookup_tb_ptr 搭配将相关的TB 链接起来。
call lookup_bt_ptr 会根据当前的 跳转目标的PC 寻找匹配的TB,如果存在目标TB则返回它的地址,否则返回JIT的 epilogue 地址,之后goto ptr 根据返回地址跳转到目标TB或者返回到qemu中。 -
exit_tb
exit_tb标记着从TB中返回到qemu,这里有个小优化,如果exit_tb 0则返回生成的epilogue位置,如果是exit_tb则返回tb_ret_addr。而epiogue是tb_ret_addr的上一条指令位置,将返回值强制赋为0,这样每个TB中就不必做这件事,相当于省了一条指令。
0x5592f355b016: xor %eax,%eax //epilogue,相当于强制返回0
0x5592f355b018: add $0x488,%rsp //tb_ret_addr,函数调用退出
指令翻译代码:
if (a0 == 0) {
tcg_out_jmp(s, s->code_gen_epilogue);
} else {
tcg_out_movi(s, TCG_TYPE_PTR, TCG_REG_EAX, a0);
tcg_out_jmp(s, tb_ret_addr);
}
- liveness pass
分析输入,输出参数是否已经无效或者需要同步。通过逆序分析TB 中所有的IR指令找到他们之间的关联性。
例如IR的输出参数在之后都没有被使用,则就可以标记为DEAD,如果它是一个内存类型,则还需要标记为SYNC。如果一条指令的输入和输出全部是DEAD,这条指令就可以删除。
系统调用的仿真
qemu执行模拟代码的基本过程如下:
int cpu_exec(CPUState *cpu) {
if (sigsetjmp(cpu->jmp_env, 0) != 0) { <<保存现场,异常发生时通过 siglongjmp 跳转回到这里
while (!cpu_handle_interrupt(cpu, &last_tb)) {
tb = tb_find(cpu, last_tb, tb_exit, cflags);
cpu_loop_exec_tb(cpu, tb, &last_tb, &tb_exit);
}
}
}
在计算机体系结构中,中断,系统调用都属于异常,只是前者是异步异常,后者是同步异常。
- 在 guest binary -> TCG IR 过程中,对于异常的翻译:当翻译到系统调用指令时,发出SYSCALL异常
static bool trans_syscall(DisasContext *ctx, arg_syscall *a)
{
generate_exception_end(ctx, EXCP_SYSCALL);
return true;
}
gen_helper_raise_exception_err(cpu_env, SYSCALL, terr)
-> call raise_exception_err
- 从 TCG IR -> host code 翻译过程中, target一般通过helper来实现复杂指令的翻译,raise_exception_err实际上调用 helper_raise_exception_err,跳出TB执行返回到qemu处理系统调用异常
target/loongarch/op_helper.c: helper_raise_exception_err
-> do_raise_exception_err
-> cpu_loop_exit_restore(cs, pc);
-> cpu_loop_exit
void cpu_loop_exit(CPUState *cpu) {
cpu->can_do_io = 1;
siglongjmp(cpu->jmp_env, 1); //跳转回当前的上下文
}
- 异常处理
void cpu_loop(CPULOONGARCHState *env)
{
trapnr = cpu_exec(cs); //返回EXCP_SYSCALL
switch (trapnr) {
case EXCP_SYSCALL:
env->active_tc.PC += 4; //PC执行结束
ret = do_syscall(env, env->active_tc.gpr[11], //使用通用的syscall来模拟系统调用
env->active_tc.gpr[4], env->active_tc.gpr[5],
env->active_tc.gpr[6], env->active_tc.gpr[7],
env->active_tc.gpr[8], env->active_tc.gpr[9],
-1, -1);
env->active_tc.gpr[4] = ret; //返回值
}
}
TB间跳转优化direct jump
如果没有direct jump的话,qemu 模拟执行代码的流程就是这样:
QEMU -> code cache -> QEMU -> code cache -> ...
执行完一个TB后需要回到qemu,根据PC查找下一个TB再进入,这样来回的切换就比较低效,所以加了 direct jump的优化。
基本的做法时将 TB 串起来形成,只要 TB执行完并且他的跳转目标也在code cache中,就将两个TB通过 jump指令串接起来。串接的方式有两种:direct jump和indirect jump,目前基本上都是 direct jump方式,直接修改 TB 中的指令码。
TB1 第一次执行时并不知道需要跳转到 TB2,需要返回qemu,根据跳转目标 PC 找到 TB2,之后对 TB1 的代码进行 patch 跳转到 TB2。再次执行 TB1 时就可以直接跳转到 TB2 而无需 返回 qemu。这对于热点代码非常友好。

int cpu_exec(CPUState *cpu) {
tb = tb_find(cpu, last_tb, tb_exit, cflags); //尝试根据 PC 找到对应的TB,见下面的tb_find
cpu_loop_exec_tb(cpu, tb, &last_tb, &tb_exit); //执行当前的tb可能它已经是串起来的tb,最后一个tb没有继续跳转的目标了返回到qemu,所以last_tb不一定是执行的tb。
}
TranslationBlock *tb_find(TranslationBlock *last_tb) {
tb = tb_lookup__cpu_state(cpu, &pc, &cs_base, &flags, cf_mask);
if (tb == NULL) {
tb = tb_gen_code(cpu, pc, cs_base, flags, cf_mask);
}
/* See if we can patch the calling TB. */
if (last_tb) {
// last_tb 是 TB的指针,而tb_eixt是jump slot index, 链接last_tb -> tb
tb_add_jump(last_tb, tb_exit, tb);
}
}
static inline void tb_add_jump(TranslationBlock *tb, int n, TranslationBlock *tb_next) {
//保存tb->jmp_dest[n] 指向 tb_next
old = atomic_cmpxchg(&tb->jmp_dest[n], (uintptr_t)NULL, (uintptr_t)tb_next);
/* patch the native jump address */ 修改jmp指令的地址部分
tb_set_jmp_target(tb, n, (uintptr_t)tb_next->tc.ptr);
/* add in TB jmp list */ 这两个是关联关系是为了unlink时使用
tb->jmp_list_next[n] = tb_next->jmp_list_head;
tb_next->jmp_list_head = (uintptr_t)tb | n;
}
void tb_set_jmp_target(TranslationBlock *tb, int n, uintptr_t addr)
{
//找到需要修改的指令位置在TB中的偏移
uintptr_t offset = tb->jmp_target_arg[n];
//前一个TB的起始位置
uintptr_t tc_ptr = (uintptr_t)tb->tc.ptr;
//arch定义的修改指令
tb_target_set_jmp_target(tc_ptr, tc_ptr + offset, addr);
}
static inline void tb_target_set_jmp_target(uintptr_t tc_ptr,
uintptr_t jmp_addr, uintptr_t addr)
{
//直接修改相对跳转地址
atomic_set((int32_t *)jmp_addr, addr - (jmp_addr + 4));
}
里面有几个问题:
1. tb offset -> tb_next 中的 offset 怎么得出来的
2. jump slot index代表什么
3. tb中的jmp_list_head 和 jmp_list_next 什么用途
- tb offset -> tb_next 中的 offset 怎么得出来的
offset 存放在tb->jmp_target_arg[n],在 IR -> host 指令翻译过程中, 翻译 goto_tb 指令时记录的offset
tcg_out_op {
case INDEX_op_goto_tb:
/* direct jump method */
int gap;
/* jump displacement must be aligned for atomic patching;
* see if we need to add extra nops before jump
*/ jump指令的地址部分必须是4字节对齐的,这样可以使用原子指令修改
gap = tcg_pcrel_diff(s, QEMU_ALIGN_PTR_UP(s->code_ptr + 1, 4));
if (gap != 1) {
tcg_out_nopn(s, gap - 1); //如果不满足则通过nop指令填充
}
tcg_out8(s, OPC_JMP_long); /* jmp im */ jmp指令码
//将当前tb的地址记录到tb_jmp_insn_offset, 此时s->tb_jmp_insn_offset是指向tb->jmp_target_arg的
s->tb_jmp_insn_offset[a0] = tcg_current_code_size(s);
tcg_out32(s, 0); //此时相对跳转地址为0,即下一条指令
//将offset保存在tb_jmp_reset_offset, 此时s->tb_jmp_reset_offset 指向tb->jmp_reset_offset
set_jmp_reset_offset(s, a0);
break;
}
- jump slot index代表什么
TB通常是以 跳转指令 结束的, 而跳转指令其实只有两种选择: 向坐或者向右, 两个 jump slot 代表两个跳转的目标, 也就是 goto_tb 0x0/0x1。
- tb中的jmp_list_head 和 jmp_list_next 什么用途
在上面连接 tb -> next tb时,并没有简单的形成 双向链表,而是又定义了两个成员,这些主要是为了unlink 场景下
static inline void tb_add_jump(TranslationBlock *tb, int n, TranslationBlock *tb_next) {
// tb_next->jmp_list_head 初值为自己,末兩位设为 10 (2)。
// 如果已有其它 TB,tb1,跳至 tb_next,則下面這條語句會使得
// tb->jmp_next 指向 tb1 (末兩位代表 tb1 跳至 tb_next 的方向)。
// tb_next->jmp_first 由原本指向 tb1 改指向 tb。
tb->jmp_list_next[n] = tb_next->jmp_list_head;
// tb_next 的 jmp_list_head 指回 tb,末兩位代表由 tb 哪一个条件 分支跳至 tb_next。
tb_next->jmp_list_head = (uintptr_t)tb | n;
}
有些特殊用法中会进行代码自修改,例如插入软件断点,内核中根据CPU特性选择不同的代码分支alternative功能,自组装代码等, 修改target代码区域,如果已经被翻译,那么TB翻译好的代码和target代码已经不一致了,需要重新翻译。
QEMU管理代码的基本单元不是 TB 而是 page, 此时就需要将整个page中的 TB unlink下来。
在 unlink 场景下,将 TB 从链上拆解下来,就和双向链表一样需要拆 前向 和 后向 的链接关系。
后向好拆,它只有两个分支跳转目标,根据tb->jmp_dest[n] 赋为空就可以了。
前向关系就不好管理了,因为不仅局限于两个TB会跳到该位置,所以需要一个链表的方式来管理前向关系,也就是 jmp_list_head 和 jmp_list_next。
假设有tb1 和 tb3 都跳转 到 tb2, 首先执行TB1 跳转到 TB2 的过程中 链接 tb1 -> tb2, 之后执行TB3 跳转到 TB2 的过程中 链接 tb3 -> tb2, 在direct jump 链接阶段,它会形成一个这样的链表关系:
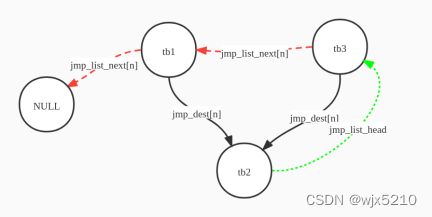
其中 tb2->jmp_list_head 表示当前跳转到该 tb 的 链表头tb3位置,然后根据 tb3->jmp_list_next遍历 所有的 tb 直至 链表尾部NULL, 解除 tbx -> tb2 的链接关系;