C++算法:排序之二(归并、希尔、选择排序)
C++算法:排序
排序之一(插入、冒泡、快速排序)
排序之二(归并、希尔、选择排序)
文章目录
- C++算法:排序
- 二、比较排序算法实现
-
- 4、归并排序
- 5、希尔排序
- 5、选择排序
- 原创文章,未经许可,严禁转载
本文续:C++算法:排序之一(插入、冒泡、快速排序)
二、比较排序算法实现
4、归并排序
归并排序和前面介绍的三种排序方法不同,这是一个以空间换时间的排序法。归并就是将二个或多个已排序的的序列合并成一个,常用的就是二路归并,所以它的空间复杂度很高。
所以归并排序适用于数据量大,并且对稳定性有要求的场景。它也适用于链表排序,可以在O(nlogn)时间内排序。此外,归并排序多用于需要外部排序的场景,比如磁盘文件的情况下比快排好,因为快排很依赖数据的随机存取,而归并是顺序存取,对磁盘这种外存比较友好。
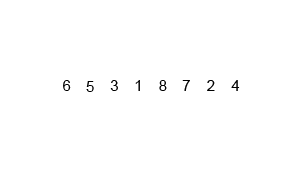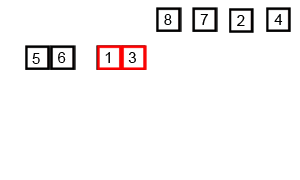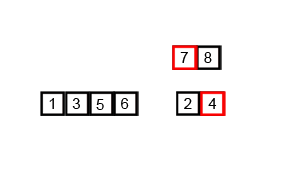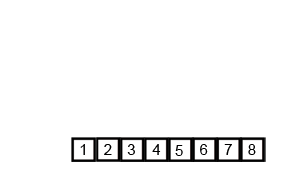
代码如下(示例):
#include 归并排序也是一种遵循分治算法思想的排序方法,它将一个大数组分成两个小数组,对每个小数组进行排序,然后将两个已排序的小数组合并成一个有序的大数组。
在这段代码中,merge_sort 函数是归并排序的主要函数。首先,它检查 vec 的大小是否大于1。如果 vec 的大小小于等于1,则不需要排序,直接返回。否则,将 vec 分成两个部分:arr1 和 arr2。然后,对这两个部分分别调用 merge_sort 函数进行排序。最后,调用 merge 函数将这两个已排序的部分合并成一个有序的大数组。
merge 函数接受三个 vector 类型的引用作为参数:arr1,arr2 和 merg。它将两个已排序的数组 arr1 和 arr2 合并成一个有序的大数组 merg。函数使用三个变量 i,j 和 m 来跟踪三个数组中的位置。当 m < len1 + len2 时(其中 len1 = arr1.size(),len2 = arr2.size()),循环执行以下操作:
- 如果 i == len1,则将 arr2 中剩余的元素复制到 merg 中,并退出循环。
- 如果 j == len2,则将 arr1 中剩余的元素复制到 merg 中,并退出循环。
- 如果 arr1[i] < arr2[j],则将 arr1[i] 复制到 merg[m] 中,并增加 i 和 m 的值。
- 否则,将 arr2[j] 复制到 merg[m] 中,并增加 j 和 m 的值。
这里要注意 i、j 是否等于对应长度的检查,应及时用break退出循环,不然可能引起段错误。归并排序虽然代码有点长,但并不难以理解,逻辑是很简单清晰的。
5、希尔排序
希尔是个人名,这是以人名命名的一个排序算法。这是一种很奇特的排序方法,也难怪发明者可以以此留名。它的时间复杂度在比较排序中是较好的,还是就地排序,不额外占用空间。可惜不能对链表结构排序。
希尔排序是一种基于插入排序的算法,它比插入排序和选择排序要快得多,并且数组越大,优势越大。它适用于大型的数组。排序的时间复杂度会比O(n^2)好,但没有快速排序算法快O(n(logn)),在中等大小规模数组表现良好,总之不怎么常用。
希尔排序也称为缩小增量排序。它的基本原理是将待排序的数组元素按下标的一定增量分组,分成多个子序列,然后对各个子序列进行直接插入排序算法排序;然后依次缩减增量再进行排序,直到增量为1时,进行最后一次直接插入排序,排序结束。
上图的分组过程表现得不是很直观,下方的过程解释和代码是严格匹配这个分组过程的。
- 第一遍是分成两个组,gap是增量的意思,总共10个元素,第一遍gap就是5,从0到5这5个元素为1 组,5到10为一组,对这两组进行插入排序。它其实是将两组同样位置的元素比较(第一次是0和5比较),如果1组同位置元素大于2组的,则交换并继续向前以gap差比较。图中同颜色的元素就是比较过程的演示。0:5,1:6,2:7 …
- 第二遍gap又除以2,gap=2。分成了5组,这样就成了:2组比1组的同位置元素,3组比2组的同位置元素并继续和1组的同位置元素比较,…
- 第三遍gap就等于1了,那就是一个插入排序过程。
代码如下(示例):
#include 首先,我们初始化增量 gap 为序列长度的一半。然后,当 gap 大于等于1时,执行循环。在循环中,我们对每个子序列进行插入排序。如果当前元素小于前一个元素,则交换位置。最后,我们减小增量 gap 的值,并重复执行上述操作。当 gap 的值为1时,整个序列就是有序的。在本例中,子序列其实就是插入排序,只是指针设计得特殊,也有使用冒泡排序来进行子序列排序的。
5、选择排序
选择排序是最直观的排序算法了,每次循环拿走最大的元素放在最后位置。循环 n-1 次后,排序就完成了,当然每次取最小元素放前面也是一样的,小学生就能搞明白的算法。
代码如下(示例):
#include - 首先,初始化 idx 为 0,表示当前排序序列的起始位置。
- 然后,在未排序序列中找到最小元素赋值 mini。
- 接着,交换 mini 和 vec[idx] 的值,将最小元素放到排序序列的起始位置。
- 然后,将 idx 加 1,表示已排序序列的末尾位置。
- 重复步骤 2-4,直到所有元素均排序完毕。
选择排序在以特定顺序排序时是有用的,就是并不是以大小排序的情况。如CSDN每日一练中有一题任务分配问题,就要用到这种排序方式。当然实际上这种排序方法几乎没用,除了应付考试。
未完待续…