mysql学+练
从开始到放弃!
开始
mysql -uroot -p123456
退出命令
exit 或者 quit
注释
# show databases; 单行注释
-- show databases; 单行注释
/*
多行注释
show databases;
*/
DDL操作数据库
创建
/*
方式1 直接指定数据库名进行创建
*/
CREATE DATABASE db1;
/*
方式2 指定数据库名称,指定数据库的字符集
一般都指定为 utf8
*/
CREATE DATABASE db1_1 CHARACTER SET utf8;
mysql> create database db1;
Query OK, 1 row affected (0.00 sec)
mysql> create database db1_1 character set utf8;
Query OK, 1 row affected (0.00 sec)
查看/选择数据库
命令 说明
use 数据库 切换数据库
select database(); 查看当前正在使用的数据库
show databases; 查看Mysql中 都有哪些数据库
show create database 数据库名; 查看一个数据库的定义信息
-- 切换数据库 从db1 切换到 db1_1
USE db1_1;
-- 查看当前正在使用的数据库
SELECT DATABASE();
-- 查看Mysql中有哪些数据库
SHOW DATABASES;
-- 查看一个数据库的定义信息
SHOW CREATE DATABASE db1_1;
mysql> use db1_1;
Database changed
mysql> SELECT DATABASE();
+------------+
| DATABASE() |
+------------+
| db1_1 |
+------------+
1 row in set (0.00 sec)
mysql> show create database db1_1;
+----------+----------------------------------------------------------------+
| Database | Create Database |
+----------+----------------------------------------------------------------+
| db1_1 | CREATE DATABASE `db1_1` /*!40100 DEFAULT CHARACTER SET utf8 */ |
+----------+----------------------------------------------------------------+
1 row in set (0.00 sec)
修改数据库
| 命令 | 说明 |
|---|---|
| alter database 数据库名 character set 字符集 | 数据库的字符集修改操作 |
-- 将数据库db1 的字符集 修改为 utf8
ALTER DATABASE db1 CHARACTER SET utf8;
-- 查看当前数据库的基本信息,发现编码已更改
SHOW CREATE DATABASE db1;
mysql> alter database db1 character set utf8;
Query OK, 1 row affected (0.00 sec
mysql> show create database db1;
+----------+--------------------------------------------------------------+
| Database | Create Database |
+----------+--------------------------------------------------------------+
| db1 | CREATE DATABASE `db1` /*!40100 DEFAULT CHARACTER SET utf8 */ |
+----------+--------------------------------------------------------------+
1 row in set (0.00 sec)
删库跑路
-- 删除某个数据库
DROP DATABASE db1_1;
mysql> drop database db1_1;
Query OK, 0 rows affected (0.01 sec)
DDL操作数据表
常用的数据类型:
类型 描述
int 整型
double 浮点型
varchar 字符串型
date 日期类型,给是为 yyyy-MM-dd ,只有年月日,没有时分秒
注意:MySql中的 char类型与 varchar类型,区别在于:
char类型是固定长度的: 根据定义的字符串长度分配足够的空间。
varchar类型是可变长度的: 只使用字符串长度所需的空间
x char(10) 占用10个字节
y varchar(10) 占用3个字节
适用场景:
char类型适合存储 固定长度的字符串,比如 密码 ,性别一类
varchar类型适合存储 在一定范围内,有长度变化的字符串
存储空间 查询效率
char 耗费空间 高
varchar 节省空间 不高
创建表
语法
CREATE TABLE 表名(
字段名称1 字段类型(长度),
字段名称2 字段类型 注意 最后一列不要加逗号
);
mysql> create table category(
-> cid int,
-> cname varchar(20)
-> );
Query OK, 0 rows affected (0.01 sec)
快速创建一个表结构相同的表(复制表结构)`
create table 新表名 like 旧表名;
mysql> create table test2 like test1;
Query OK, 0 rows affected (0.01 sec)
查看表
命令 说明
show tables; 查看当前数据库中的所有表名
desc 表名; 查看数据表的结构
mysql> show tables;
+---------------+
| Tables_in_db1 |
+---------------+
| category |
| test1 |
| test2 |
+---------------+
3 rows in set (0.00 sec)
mysql> desc category;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| cid | int(11) | YES | | NULL | |
| cname | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)
mysql> show create table category;
+----------+---------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+----------+---------------------------------------------------------------------------------------------------------------------------------+
| category | CREATE TABLE `category` (
`cid` int(11) DEFAULT NULL,
`cname` varchar(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
+----------+---------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
删除表
命令 说明
drop table 表名; 删除表(从数据库中永久删除某一张表)
drop table if exists 表名; 判断表是否存在, 存在的话就删除,不存在就不执行删除
mysql> drop table test1;
Query OK, 0 rows affected (0.00 sec)
mysql> drop table if exists test2;
Query OK, 0 rows affected (0.00 sec)
mysql> rename table category1 to category;
Query OK, 0 rows affected (0.01 sec)
mysql> alter table category add cdesc varchar(20);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> alter table category modify cdesc varchar(50);
Query OK, 0 rows affected (0.00 sec)
Records: 0 Duplicates: 0 Warnings: 0
整体作业练习
mysql> create database test charset='utf8';
Query OK, 1 row affected (0.01 sec)
mysql> use test;
Database changed
mysql> create table goods(
-> id int auto_increment primary key not null,
-> name varchar(50) not null
-> );
Query OK, 0 rows affected (0.04 sec)
mysql> show tables;
+----------------+
| Tables_in_test |
+----------------+
| goods |
+----------------+
1 row in set (0.00 sec)
mysql> insert into goods values(0,'大豆'),(0,'玉米'),(0,'花生'),(0,'小麦');; -> insert into goods values(0,'大豆'),(0,'玉米'),(0,'花生'),(0,'小麦');
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ';;
insert into goods values(0,'大豆'),(0,'玉米'),(0,'花生'),(0,'小麦' at line 1
mysql> insert into goods values(0,'大豆'),(0,'玉米'),(0,'花生'),(0,'小麦'); Query OK, 4 rows affected (0.03 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> select * from goods;
+----+--------+
| id | name |
+----+--------+
| 1 | 大豆 |
| 2 | 玉米 |
| 3 | 花生 |
| 4 | 小麦 |
+----+--------+
4 rows in set (0.00 sec)
mysql> update goods set name='紫薯' where id=4;
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from goods;
+----+--------+
| id | name |
+----+--------+
| 1 | 大豆 |
| 2 | 玉米 |
| 3 | 花生 |
| 4 | 紫薯 |
+----+--------+
4 rows in set (0.00 sec)
mysql> delete from goods where id=4;
Query OK, 1 row affected (0.00 sec)
mysql> select * from goods where id=4;
Empty set (0.00 sec)
DQL 查询表中数据
简单查询
准备数据
创建员工表
CREATE TABLE emp(
eid INT,
ename VARCHAR(20),
sex CHAR(1),
salary DOUBLE,
hire_date DATE,
dept_name VARCHAR(20)
);
#添加数据
INSERT INTO emp VALUES(1,'孙悟空','男',7200,'2013-02-04','教学部');
INSERT INTO emp VALUES(2,'猪八戒','男',3600,'2010-12-02','教学部');
INSERT INTO emp VALUES(3,'唐僧','男',9000,'2008-08-08','教学部');
INSERT INTO emp VALUES(4,'白骨精','女',5000,'2015-10-07','市场部');
INSERT INTO emp VALUES(5,'蜘蛛精','女',5000,'2011-03-14','市场部');
INSERT INTO emp VALUES(6,'玉兔精','女',200,'2000-03-14','市场部');
INSERT INTO emp VALUES(7,'林黛玉','女',10000,'2019-10-07','财务部');
INSERT INTO emp VALUES(8,'黄蓉','女',3500,'2011-09-14','财务部');
INSERT INTO emp VALUES(9,'吴承恩','男',20000,'2000-03-14',NULL);
INSERT INTO emp VALUES(10,'孙悟饭','男', 10,'2020-03-14','财务部');
- 执行顺序
FROM --> WHERE --> GROUP BY --> HAVING --> SELECT --> ORDER BY
- 查询
select * from 表名
别名查询,使用关键字 as
mysql> select
-> eid as '编码',
-> ename as '姓名',
-> sex as '性别',
-> salary as '薪资',
-> hire_date '入职时间',
-> dept_name '部门名称'
-> from emp;
+--------+-----------+--------+--------+--------------+--------------+
| 编码 | 姓名 | 性别 | 薪资 | 入职时间 | 部门名称 |
+--------+-----------+--------+--------+--------------+--------------+
| 1 | 孙悟空 | 男 | 7200 | 2013-02-04 | 教学部 |
| 2 | 猪八戒 | 男 | 3600 | 2010-12-02 | 教学部 |
| 3 | 唐僧 | 男 | 9000 | 2008-08-08 | 教学部 |
| 4 | 白骨精 | 女 | 5000 | 2015-10-07 | 市场部 |
| 5 | 蜘蛛精 | 女 | 5000 | 2011-03-14 | 市场部 |
| 6 | 玉兔精 | 女 | 200 | 2000-03-14 | 市场部 |
| 7 | 林黛玉 | 女 | 10000 | 2019-10-07 | 财务部 |
| 8 | 黄蓉 | 女 | 3500 | 2011-09-14 | 财务部 |
| 9 | 吴承恩 | 男 | 20000 | 2000-03-14 | NULL |
| 10 | 孙悟饭 | 男 | 10 | 2020-03-14 | 财务部 |
+--------+-----------+--------+--------+--------------+--------------+
10 rows in set (0.00 sec)
- 使用去重关键字 distinct
mysql> select distinct dept_name from emp;
+-----------+
| dept_name |
+-----------+
| 教学部 |
| 市场部 |
| 财务部 |
| NULL |
+-----------+
4 rows in set (0.01 sec)
- 将所有员工的工资 +1000 元进行显示
运算查询 (查询结果参与运算)
mysql> select ename,salary +1000 from emp;
+-----------+--------------+
| ename | salary +1000 |
+-----------+--------------+
| 孙悟空 | 8200 |
| 猪八戒 | 4600 |
| 唐僧 | 10000 |
| 白骨精 | 6000 |
| 蜘蛛精 | 6000 |
| 玉兔精 | 1200 |
| 林黛玉 | 11000 |
| 黄蓉 | 4500 |
| 吴承恩 | 21000 |
| 孙悟饭 | 1010 |
+-----------+--------------+
10 rows in set (0.00 sec)
- 条件查询
如果查询语句中没有设置条件,就会查询所有的行信息,在实际应用中,一定要指定查询条件,对记
录进行过滤
select 列名 from 表名 where 条件表达式
运算符 说明
< <= >= = <> != 大于、小于、小于(大于)等于、等于、不等于
BETWEEN …AND…
显示在某一区间的值
例如: 2000-10000之间: Between 2000 and 10000
IN(集合)
集合表示多个值,使用逗号分隔,例如: name in (悟空,八戒)
in中的每个数据都会作为一次条件,只要满足条件就会显示
LIKE ‘%张%’ 模糊查询
IS NULL 查询某一列为NULL的值, 注: 不能写 = NULL
运算符 说明
And && 多个条件同时成立
Or || 多个条件任一成立
Not 不成立,取反。
- 需求
# 查询员工姓名为黄蓉的员工信息
# 查询薪水价格为5000的员工信息
# 查询薪水价格不是5000的所有员工信息
# 查询薪水价格大于6000元的所有员工信息
# 查询薪水价格在5000到10000之间所有员工信息
# 查询薪水价格是3600或7200或者20000的所有员工信息
mysql> select * from emp where ename='黄蓉';
+------+--------+------+--------+------------+-----------+
| eid | ename | sex | salary | hire_date | dept_name |
+------+--------+------+--------+------------+-----------+
| 8 | 黄蓉 | 女 | 3500 | 2011-09-14 | 财务部 |
+------+--------+------+--------+------------+-----------+
1 row in set (0.00 sec)
mysql> select * from emp where salary=5000;
+------+-----------+------+--------+------------+-----------+
| eid | ename | sex | salary | hire_date | dept_name |
+------+-----------+------+--------+------------+-----------+
| 4 | 白骨精 | 女 | 5000 | 2015-10-07 | 市场部 |
| 5 | 蜘蛛精 | 女 | 5000 | 2011-03-14 | 市场部 |
+------+-----------+------+--------+------------+-----------+
2 rows in set (0.00 sec)
mysql> select * from emp where salary!=5000;
+------+-----------+------+--------+------------+-----------+
| eid | ename | sex | salary | hire_date | dept_name |
+------+-----------+------+--------+------------+-----------+
| 1 | 孙悟空 | 男 | 7200 | 2013-02-04 | 教学部 |
| 2 | 猪八戒 | 男 | 3600 | 2010-12-02 | 教学部 |
| 3 | 唐僧 | 男 | 9000 | 2008-08-08 | 教学部 |
| 6 | 玉兔精 | 女 | 200 | 2000-03-14 | 市场部 |
| 7 | 林黛玉 | 女 | 10000 | 2019-10-07 | 财务部 |
| 8 | 黄蓉 | 女 | 3500 | 2011-09-14 | 财务部 |
| 9 | 吴承恩 | 男 | 20000 | 2000-03-14 | NULL |
| 10 | 孙悟饭 | 男 | 10 | 2020-03-14 | 财务部 |
+------+-----------+------+--------+------------+-----------+
8 rows in set (0.00 sec)
mysql> select * from emp where salary>6000;
+------+-----------+------+--------+------------+-----------+
| eid | ename | sex | salary | hire_date | dept_name |
+------+-----------+------+--------+------------+-----------+
| 1 | 孙悟空 | 男 | 7200 | 2013-02-04 | 教学部 |
| 3 | 唐僧 | 男 | 9000 | 2008-08-08 | 教学部 |
| 7 | 林黛玉 | 女 | 10000 | 2019-10-07 | 财务部 |
| 9 | 吴承恩 | 男 | 20000 | 2000-03-14 | NULL |
+------+-----------+------+--------+------------+-----------+
4 rows in set (0.00 sec)
mysql> select * from emp where salary between 5000 and 10000;
+------+-----------+------+--------+------------+-----------+
| eid | ename | sex | salary | hire_date | dept_name |
+------+-----------+------+--------+------------+-----------+
| 1 | 孙悟空 | 男 | 7200 | 2013-02-04 | 教学部 |
| 3 | 唐僧 | 男 | 9000 | 2008-08-08 | 教学部 |
| 4 | 白骨精 | 女 | 5000 | 2015-10-07 | 市场部 |
| 5 | 蜘蛛精 | 女 | 5000 | 2011-03-14 | 市场部 |
| 7 | 林黛玉 | 女 | 10000 | 2019-10-07 | 财务部 |
+------+-----------+------+--------+------------+-----------+
5 rows in set (0.00 sec)
mysql> select * from emp where salary=3600 or salary=7200 or 20000;
+------+-----------+------+--------+------------+-----------+
| eid | ename | sex | salary | hire_date | dept_name |
+------+-----------+------+--------+------------+-----------+
| 1 | 孙悟空 | 男 | 7200 | 2013-02-04 | 教学部 |
| 2 | 猪八戒 | 男 | 3600 | 2010-12-02 | 教学部 |
| 3 | 唐僧 | 男 | 9000 | 2008-08-08 | 教学部 |
| 4 | 白骨精 | 女 | 5000 | 2015-10-07 | 市场部 |
| 5 | 蜘蛛精 | 女 | 5000 | 2011-03-14 | 市场部 |
| 6 | 玉兔精 | 女 | 200 | 2000-03-14 | 市场部 |
| 7 | 林黛玉 | 女 | 10000 | 2019-10-07 | 财务部 |
| 8 | 黄蓉 | 女 | 3500 | 2011-09-14 | 财务部 |
| 9 | 吴承恩 | 男 | 20000 | 2000-03-14 | NULL |
| 10 | 孙悟饭 | 男 | 10 | 2020-03-14 | 财务部 |
+------+-----------+------+--------+------------+-----------+
10 rows in set (0.00 sec)
# 查询薪水价格是3600或7200或者20000的所有员工信息
-- 方式1: or
SELECT * FROM emp WHERE salary = 3600 OR salary = 7200 OR salary = 20000;
-- 方式2: in() 匹配括号中指定的参数
SELECT * FROM emp WHERE salary IN(3600,7200,20000);
需求2
# 查询含有'精'字的所有员工信息
# 查询以'孙'开头的所有员工信息
# 查询第二个字为'兔'的所有员工信息
# 查询没有部门的员工信息
# 查询有部门的员工信息
模糊查询 通配符
通配符 说明
% 表示匹配任意多个字符串,
_ 表示匹配 一个字符
mysql> select * from emp where ename like '%精%';
+------+-----------+------+--------+------------+-----------+
| eid | ename | sex | salary | hire_date | dept_name |
+------+-----------+------+--------+------------+-----------+
| 4 | 白骨精 | 女 | 5000 | 2015-10-07 | 市场部 |
| 5 | 蜘蛛精 | 女 | 5000 | 2011-03-14 | 市场部 |
| 6 | 玉兔精 | 女 | 200 | 2000-03-14 | 市场部 |
+------+-----------+------+--------+------------+-----------+
3 rows in set (0.00 sec)
mysql> select * from emp where ename like '孙%';
+------+-----------+------+--------+------------+-----------+
| eid | ename | sex | salary | hire_date | dept_name |
+------+-----------+------+--------+------------+-----------+
| 1 | 孙悟空 | 男 | 7200 | 2013-02-04 | 教学部 |
| 10 | 孙悟饭 | 男 | 10 | 2020-03-14 | 财务部 |
+------+-----------+------+--------+------------+-----------+
2 rows in set (0.01 sec)
mysql> select * from emp where ename like '_兔%';
+------+-----------+------+--------+------------+-----------+
| eid | ename | sex | salary | hire_date | dept_name |
+------+-----------+------+--------+------------+-----------+
| 6 | 玉兔精 | 女 | 200 | 2000-03-14 | 市场部 |
+------+-----------+------+--------+------------+-----------+
1 row in set (0.00 sec)
mysql> select * from emp where dept_name is null;
+------+-----------+------+--------+------------+-----------+
| eid | ename | sex | salary | hire_date | dept_name |
+------+-----------+------+--------+------------+-----------+
| 9 | 吴承恩 | 男 | 20000 | 2000-03-14 | NULL |
+------+-----------+------+--------+------------+-----------+
1 row in set (0.00 sec)
mysql> select * from emp where dept_name is not null;
+------+-----------+------+--------+------------+-----------+
| eid | ename | sex | salary | hire_date | dept_name |
+------+-----------+------+--------+------------+-----------+
| 1 | 孙悟空 | 男 | 7200 | 2013-02-04 | 教学部 |
| 2 | 猪八戒 | 男 | 3600 | 2010-12-02 | 教学部 |
| 3 | 唐僧 | 男 | 9000 | 2008-08-08 | 教学部 |
| 4 | 白骨精 | 女 | 5000 | 2015-10-07 | 市场部 |
| 5 | 蜘蛛精 | 女 | 5000 | 2011-03-14 | 市场部 |
| 6 | 玉兔精 | 女 | 200 | 2000-03-14 | 市场部 |
| 7 | 林黛玉 | 女 | 10000 | 2019-10-07 | 财务部 |
| 8 | 黄蓉 | 女 | 3500 | 2011-09-14 | 财务部 |
| 10 | 孙悟饭 | 男 | 10 | 2020-03-14 | 财务部 |
+------+-----------+------+--------+------------+-----------+
9 rows in set (0.00 sec)
第二部分 MySQL核心查询
排序 分组 聚合 多表查询 合并查询 子查询
第1节 单表查询
1.1 排序
通过 ORDER BY 子句,可以将查询出的结果进行排序(排序只是显示效果,不会影响真实数据)
语法结构
SELECT 字段名 FROM 表名 [WHERE 字段 = 值] ORDER BY 字段名 [ASC / DESC]
ASC 表示升序排序(默认)
DESC 表示降序排序
1.1.1 单列排序
只按照某一个字段进行排序, 就是单列排序
需求1:
使用 salary 字段,对emp 表数据进行排序 (升序/降序)
mysql> select * from emp order by salary desc,eid desc;
+------+-----------+------+--------+------------+-----------+
| eid | ename | sex | salary | hire_date | dept_name |
+------+-----------+------+--------+------------+-----------+
| 9 | 吴承恩 | 男 | 20000 | 2000-03-14 | NULL |
| 7 | 林黛玉 | 女 | 10000 | 2019-10-07 | 财务部 |
| 3 | 唐僧 | 男 | 9000 | 2008-08-08 | 教学部 |
| 1 | 孙悟空 | 男 | 7200 | 2013-02-04 | 教学部 |
| 5 | 蜘蛛精 | 女 | 5000 | 2011-03-14 | 市场部 |
| 4 | 白骨精 | 女 | 5000 | 2015-10-07 | 市场部 |
| 2 | 猪八戒 | 男 | 3600 | 2010-12-02 | 教学部 |
| 8 | 黄蓉 | 女 | 3500 | 2011-09-14 | 财务部 |
| 6 | 玉兔精 | 女 | 200 | 2000-03-14 | 市场部 |
| 10 | 孙悟饭 | 男 | 10 | 2020-03-14 | 财务部 |
+------+-----------+------+--------+------------+-----------+
10 rows in set (0.00 sec)
1.2 聚合函数
干嘛的?求员工最高工资/平均工资/工资总和,都是聚合函数来做的
之前我们做的查询都是横向查询,它们都是根据条件一行一行的进行判断,而使用聚合函数查
询是纵向查询,它是对某一列的值进行计算,然后返回一个单一的值(另外聚合函数会忽略null空
值。);
聚合,也称为聚合统计或者聚合查询,就需要使用select关键字,有select 就得有from xxx
语法结构
SELECT 聚合函数(字段名) FROM 表名;
聚合函数 作用
count(字段) 统计指定列不为NULL的记录行数
sum(字段) 计算指定列的数值和
max(字段) 计算指定列的最大值
min(字段) 计算指定列的最小值
avg(字段) 计算指定列的平均值
需求1
#1 查询员工的总数
#2 查看员工总薪水、最高薪水、最小薪水、薪水的平均值
#3 查询薪水大于4000员工的个数
#4 查询部门为'教学部'的所有员工的个数
#5 查询部门为'市场部'所有员工的平均薪水
#1 查询员工的总数
-- 统计表中的记录条数 使用 count()
SELECT COUNT(eid) FROM emp; -- 使用某一个字段
SELECT COUNT(*) FROM emp; -- 使用 *
SELECT COUNT(1) FROM emp; -- 使用 1,与 * 效果一样
-- 下面这条SQL 得到的总条数不准确,因为count函数忽略了空值
-- 所以使用时注意不要使用带有null的列进行统计
SELECT COUNT(dept_name) FROM emp;
#2 查看员工总薪水、最高薪水、最小薪水、薪水的平均值
-- sum函数求和, max函数求最大, min函数求最小, avg函数求平均值
SELECT
SUM(salary) AS '总薪水',
MAX(salary) AS '最高薪水',
MIN(salary) AS '最低薪水',
AVG(salary) AS '平均薪水'
FROM emp;
#3 查询薪水大于4000员工的个数
SELECT COUNT(*) FROM emp WHERE salary > 4000;
#4 查询部门为'教学部'的所有员工的个数
SELECT COUNT(*) FROM emp WHERE dept_name = '教学部';
#5 查询部门为'市场部'所有员工的平均薪水
SELECT
AVG(salary) AS '市场部平均薪资'
FROM emp
WHERE dept_name = '市场部';
1.3 分组
分组往往和聚合函数一起时候,对数据进行分组,分完组之后在各个组内进行聚合统计分析
比如:求各个部门的员工数~
分组查询指的是使用 GROUP BY 语句,对查询的信息进行分组,相同数据作为一组
语法格式
SELECT 分组字段/聚合函数 FROM 表名 GROUP BY 分组字段 [HAVING 条件];
- 分组时可以查询要分组的字段, 或者使用聚合函数进行统计操作.不然就没有意义
- 查询其他字段没有意义
- 记住:
–group by的字段必须出现在前面select的位置
—前面select的位置,除了group by的字段、聚合函数,不能出现其他字段
where 与 having的区别 重点注意!!!!!!!!面试必问
过滤方式 特点
where
where 进行分组前的过滤
where 后面不能写 聚合函数
having
having 是分组后的过滤
having 后面可以写 聚合函数
limit 关键字的作用
limit是限制的意思,用于限制返回的查询结果的行数 (可以通过limit指定查询多少行数据)
limit 语法是 MySql的方言,用来完成分页
SELECT 字段1,字段2... FROM 表名 LIMIT offset , length;
需求1
# 查询emp表中的前 5条数据
# 查询emp表中 从第4条开始,查询6条
limit offset , length; 关键字可以接受一个 或者两个 为0 或者正整数的参数
offset 起始行数, 从0开始记数, 如果省略 则默认为 0.
length 返回的行数
# 查询emp表中的前 5条数据
-- 参数1 起始值,默认是0 , 参数2 要查询的条数
SELECT * FROM emp LIMIT 5;
SELECT * FROM emp LIMIT 0 , 5;
+------+-----------+------+--------+------------+-----------+
| eid | ename | sex | salary | hire_date | dept_name |
+------+-----------+------+--------+------------+-----------+
| 1 | 孙悟空 | 男 | 7200 | 2013-02-04 | 教学部 |
| 2 | 猪八戒 | 男 | 3600 | 2010-12-02 | 教学部 |
| 3 | 唐僧 | 男 | 9000 | 2008-08-08 | 教学部 |
| 4 | 白骨精 | 女 | 5000 | 2015-10-07 | 市场部 |
| 5 | 蜘蛛精 | 女 | 5000 | 2011-03-14 | 市场部 |
+------+-----------+------+--------+------------+-----------+
5 rows in set (0.00 sec)
# 查询emp表中 从第4条开始,查询6条
-- 起始值默认是从0开始的.
SELECT * FROM emp LIMIT 3 , 6;
需求2: 分页操作 每页显示3条数据
-- 分页操作 每页显示3条数据
SELECT * FROM emp LIMIT 0,3; -- 第1页
SELECT * FROM emp LIMIT 3,3; -- 第2页 2-1=1 1*3=3
SELECT * FROM emp LIMIT 6,3; -- 第三页
-- 分页公式 起始索引 = (当前页 - 1) * 每页条数
-- limit是MySql中的方言
**
第2节 SQL约束
SQL语句来创建数据库约束
1)约束的作用:
对表中的数据进行进一步的限制,从而保证数据的正确性、有效性、完整性.
违反约束的不正确数据,将无法插入到表中
注意:约束是针对字段的
2)常见的约束
约束名 : 约束关键字
主键 : primary key
唯一 : unique
非空 : not null
外键 : foreign key
2.1 主键约束
特点: 不可重复 唯一 非空
作用 :用来表示数据库中的每一条记录(用来唯一标识数据表中的一条记录)
3) 哪些字段可以作为主键 ?
通常针对业务去设计主键,往往每张表都设计一个主键
主键是给数据库和程序使用的,跟最终的客户无关,所以主键没有意义没有关系,只要能够保证
不重复就好
比如 身份证号列就可以作为主键.
另外,如果没有和业务关联太大的可以设计为主键的列的话,我们在进行数据库设计的时
候往往人为加一列作为主键列,习惯上起名为id,rid等
2.1.2 删除主键约束
删除 表中的主键约束 (了解)
-- 使用DDL语句 删除表中的主键
ALTER TABLE emp2 DROP PRIMARY KEY;
DESC emp2;
2.1.3 主键的自增
注: 主键如果让我们自己添加很有可能重复,我们通常希望在每次插入新记录时,数据库自动生成
主键字段的值.
-- 创建主键自增的表
CREATE TABLE emp2(
-- 关键字 AUTO_INCREMENT,主键类型必须是整数类型
eid INT PRIMARY KEY AUTO_INCREMENT,
ename VARCHAR(20),
sex CHAR(1)
);
INSERT INTO emp2(ename,sex) VALUES('张三','男');
INSERT INTO emp2(ename,sex) VALUES('李四','男');
INSERT INTO emp2 VALUES(NULL,'翠花','女');
INSERT INTO emp2 VALUES(NULL,'艳秋','女');
2.1.4 修改主键自增的起始值
默认地 AUTO_INCREMENT 的开始值是 1,如果希望修改起始值,请使用下面的方式
-- 创建主键自增的表,自定义自增其实值
CREATE TABLE emp2(
eid INT PRIMARY KEY AUTO_INCREMENT,
ename VARCHAR(20),
sex CHAR(1)
)AUTO_INCREMENT=100;
-- 插入数据,观察主键的起始值
INSERT INTO emp2(ename,sex) VALUES('张百万','男');
INSERT INTO emp2(ename,sex) VALUES('艳秋','女');
2.1.5 DELETE和TRUNCATE对自增长的影响
删除表中所有数据有两种方式
清空表数据的方式 特点
DELETE :只是删除表中所有数据,对自增没有影响
TRUNCATE
truncate: 是将整个表删除掉,然后创建一个新的表
自增的主键,重新从 1开始
2.2 非空约束
特点:某⼀列不允许为空
需求1: 为 ename 字段添加非空约束
mysql> create table emp2_3(
-> eid int primary key auto_increment,
-> ename varchar(20) not null,
-> sex char(1)
-> );
Query OK, 0 rows affected (0.00 sec)
mysql> desc emp2_3;
+-------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+----------------+
| eid | int(11) | NO | PRI | NULL | auto_increment |
| ename | varchar(20) | NO | | NULL | |
| sex | char(1) | YES | | NULL | |
+-------+-------------+------+-----+---------+----------------+
3 rows in set (0.00 sec)
2.3 唯一约束
唯一约束的特点: 表中的某一列的值不能重复( 对null不做唯一的判断 )
语法格式
字段名 字段值 unique
#创建emp3表 为ename 字段添加唯一约束
CREATE TABLE emp3(
eid INT PRIMARY KEY AUTO_INCREMENT,
ename VARCHAR(20) UNIQUE,
sex CHAR(1)
);
-- 测试唯一约束 添加一条数据
INSERT INTO emp3 (ename,sex) VALUES('张百万','男');
-- 添加一条 ename重复的 数据
-- Duplicate entry '张百万' for key 'ename' ename不能重复
INSERT INTO emp3 (ename,sex) VALUES('张百万','女');
mysql> INSERT INTO emp3 (ename,sex) VALUES('张百万','男');
Query OK, 1 row affected (0.00 sec)
mysql> INSERT INTO emp3 (ename,sex) VALUES('张百万','女');
ERROR 1062 (23000): Duplicate entry '张百万' for key 'ename'
mysql>
主键约束与唯一约束的区别:
- 主键约束 唯一且不能够为空(主键约束=非空约束+唯一约束)
- 唯一约束,唯一 但是可以为空
- 一个表中只能有一个主键 , 但是可以有多个唯一约束
2.4 外键约束
FOREIGN KEY 表示外键约束,将在多表中学习。
2.5 默认值
默认值约束 用来指定某列的默认值
语法格式
字段名 字段类型 DEFAULT 默认值
- 创建emp4表, 性别字段默认 女
-- 创建带有默认值的表
CREATE TABLE emp4(
eid INT PRIMARY KEY AUTO_INCREMENT,
-- 为ename 字段添加默认值
ename VARCHAR(20) DEFAULT '女',
sex CHAR(1)
);
- 测试 添加数据使用默认值
-- 添加数据 使用默认值
INSERT INTO emp4(ename,sex) VALUES(DEFAULT,'男');
INSERT INTO emp4(sex) VALUES('女');
-- 不使用默认值
INSERT INTO emp4(ename,sex) VALUES('艳秋','女');
第3节 多表查询
3.1 外键约束
主键:数据表A中有一列,这一列可以唯一的标识一条记录
外键:数据表A中有一列,这一列指向了另外一张数据表B的主键
3.1.1 什么是外键
-
外键指的是在 从表 中 与 主表 的主键对应的那个字段,比如员工表的 dept_id,就是外键
-
使用外键约束可以让两张表之间产生一个对应关系,从而保证主从表的引用的完整性
多表关系中的主表和从表
主表: 主键id所在的表, 约束别人的表
从表: 外键所在的表多, 被约束的表
3.1.2 创建外键约束
语法格式:
- 新建表时添加外键
[CONSTRAINT] [外键约束名称] FOREIGN KEY(外键字段名) REFERENCES 主表名(主键字
段名)
- 已有表添加外键
ALTER TABLE 从表 ADD [CONSTRAINT] [外键约束名称] FOREIGN KEY (外键字段名)
REFERENCES 主表(主 键字段名);
-- 重新创建 employee表,添加外键约束
CREATE TABLE employee(
eid INT PRIMARY KEY AUTO_INCREMENT,
ename VARCHAR(20),
age INT,
dept_id INT, -- 外键字段类型要和主表的主键字段类型保持一致
-- 添加外键约束
CONSTRAINT emp_dept_fk FOREIGN KEY(dept_id) REFERENCES department(id)
);
3.1.3 删除外键约束
添加/删除外键针对的都是从表
语法格式
alter table 从表 drop foreign key 外键约束名称
- 删除 外键约束
1) 删除 外键约束
2) 再将外键 添加回来
- 再将外键 添加回来
语法格式
ALTER TABLE 从表 ADD [CONSTRAINT] [外键约束名称] FOREIGN KEY (外键字段名)
REFERENCES 主表(主 键字段名);
-- 可以省略外键名称, 系统会自动生成一个
ALTER TABLE employee ADD FOREIGN KEY (dept_id) REFERENCES department (id);
3.1.4 外键约束的注意事项
- 从表外键类型必须与主表主键类型一致 否则创建失败
- 添加数据时, 应该先添加主表中的数据.
-- 添加一个新的部门
INSERT INTO department(dep_name,dep_location) VALUES('市场部','北京');
-- 添加一个属于市场部的员工
INSERT INTO employee(ename,age,dept_id) VALUES('老胡',24,3);
- 删除数据时,应该先删除从表中的数据.
-- 删除数据时 应该先删除从表中的数据
-- 报错 Cannot delete or update a parent row: a foreign key constraint
fails
-- 报错原因 不能删除主表的这条数据,因为在从表中有对这条数据的引用
DELETE FROM department WHERE id = 3;
-- 先删除从表的关联数据
DELETE FROM employee WHERE dept_id = 3;
-- 再删除主表的数据
DELETE FROM department WHERE id = 3;
3.2 什么是多表查询
- DQL: 查询多张表(至少涉及2张表),获取到需要的数据
- 比如 我们要查询家**电分类下 都有哪些商品,**那么我们就
-
分类表+商品表
3.3 数据准备
- 创建db3_2 数据库
-- 创建 db3_2 数据库,指定编码
CREATE DATABASE db3_2 CHARACTER SET utf8;
- 创建分类表与商品表
#分类表 (一方 主表)
CREATE TABLE category (
cid VARCHAR(32) PRIMARY KEY ,
cname VARCHAR(50)
);
#商品表 (多方 从表)
CREATE TABLE products(
pid VARCHAR(32) PRIMARY KEY ,
pname VARCHAR(50),
#分类表 (一方 主表)
CREATE TABLE category (
cid VARCHAR(32) PRIMARY KEY ,
cname VARCHAR(50)
);
#商品表 (多方 从表)
CREATE TABLE products(
pid VARCHAR(32) PRIMARY KEY ,
pname VARCHAR(50),
3.插入数据
#分类数据
INSERT INTO category(cid,cname) VALUES('c001','家电');
INSERT INTO category(cid,cname) VALUES('c002','鞋服');
INSERT INTO category(cid,cname) VALUES('c003','化妆品');
INSERT INTO category(cid,cname) VALUES('c004','汽车');
#商品数据
INSERT INTO products(pid, pname,price,flag,category_id) VALUES('p001','小
米电视机',5000,'1','c001');
INSERT INTO products(pid, pname,price,flag,category_id) VALUES('p002','格
力空调',3000,'1','c001');
INSERT INTO products(pid, pname,price,flag,category_id) VALUES('p003','美
的冰箱',4500,'1','c001');
INSERT INTO products (pid, pname,price,flag,category_id) VALUES('p004','篮
球鞋',800,'1','c002');
INSERT INTO products (pid, pname,price,flag,category_id) VALUES('p005','运
动裤',200,'1','c002');
INSERT INTO products (pid, pname,price,flag,category_id) VALUES('p006','T
恤',300,'1','c002');
INSERT INTO products (pid, pname,price,flag,category_id) VALUES('p007','冲
锋衣',2000,'1','c002');
INSERT INTO products (pid, pname,price,flag,category_id) VALUES('p008','神
仙水',800,'1','c003');
INSERT INTO products (pid, pname,price,flag,category_id) VALUES('p009','大
宝',200,'1','c003');
3.4 笛卡尔积
交叉连接查询,因为会产生笛卡尔积,所以 基本不会使用
- 语法格式
SELECT 字段名 FROM 表1, 表2;
- 使用交叉连接查询 商品表与分类表
SELECT * FROM category , products;
- 观察查询结果,产生了笛卡尔积 (得到的结果是无法使用的)
3.5 多表查询的分类
3.5.1 内连接查询
内连接的特点:
通过指定的条件去匹配两张表中的数据, 匹配上就显示,匹配不上就不显示
比如通过: 从表的外键 = 主表的主键 方式去匹配
- 隐式内链接
form子句 后面直接写 多个表名 使用where指定连接条件的 这种连接方式是 隐式内连接.
使用where条件过滤无用的数据
语法格式
SELECT 字段名 FROM 左表, 右表 WHERE 连接条件;
- 查询所有商品信息和对应的分类信息
# 隐式内连接
mysql> select * from products,category where category_id =cid;
+------+------------------+-------+------+-------------+------+-----------+
| pid | pname | price | flag | category_id | cid | cname |
+------+------------------+-------+------+-------------+------+-----------+
| p001 | 小
米电视机 | 5000 | 1 | c001 | c001 | 家电 |
| p002 | 格
力空调 | 3000 | 1 | c001 | c001 | 家电 |
| p003 | 美
的冰箱 | 4500 | 1 | c001 | c001 | 家电 |
| p004 | 篮
球鞋 | 800 | 1 | c002 | c002 | 鞋服 |
| p005 | 运
动裤 | 200 | 1 | c002 | c002 | 鞋服 |
| p006 | T
恤 | 300 | 1 | c002 | c002 | 鞋服 |
| p007 | 冲
锋衣 | 2000 | 1 | c002 | c002 | 鞋服 |
| p008 | 神
仙水 | 800 | 1 | c003 | c003 | 化妆品 |
| p009 | 大
宝 | 200 | 1 | c003 | c003 | 化妆品 |
+------+------------------+-------+------+-------------+------+-----------+
9 rows in set (0.00 sec)
- 查询商品表的商品名称 和 价格,以及商品的分类信息
可以通过给表起别名的方式, 方便我们的查询(有提示)
mysql> select pname,price,cname from products,category where category_id=cid;
+------------------+-------+-----------+
| pname | price | cname |
+------------------+-------+-----------+
| 小
米电视机 | 5000 | 家电 |
| 格
力空调 | 3000 | 家电 |
| 美
的冰箱 | 4500 | 家电 |
| 篮
球鞋 | 800 | 鞋服 |
| 运
动裤 | 200 | 鞋服 |
| T
恤 | 300 | 鞋服 |
| 冲
锋衣 | 2000 | 鞋服 |
| 神
仙水 | 800 | 化妆品 |
| 大
宝 | 200 | 化妆品 |
+------------------+-------+-----------+
9 rows in set (0.00 sec)
- 查询 格力空调是属于哪一分类下的商品
mysql> select p.pname,c.cname from products p,category c where category_id=c.cid and p.pid='p002';
+---------------+--------+
| pname | cname |
+---------------+--------+
| 格
力空调 | 家电 |
+---------------+--------+
1 row in set (0.00 sec)
2) 显式内连接
使用 inner join …on 这种方式, 就是显式内连接
语法格式
- 查询所有商品信息和对应的分类信息
# 显式内连接查询
SELECT * FROM products p INNER JOIN category c ON p.category_id = c.cid;
- 查询鞋服分类下,价格大于500的商品名称和价格
# 查询鞋服分类下,价格大于500的商品名称和价格
-- 我们需要确定的几件事
-- 1.查询几张表 products & category
-- 2.表的连接条件 从表.外键 = 主表的主键
-- 3.查询的条件 cname = '鞋服' and price > 500
-- 4.要查询的字段 pname price
mysql> select pname,price from products,category where category_id=cid and cname='鞋服'and price>500;
+------------+-------+
| pname | price |
+------------+-------+
| 篮
球鞋 | 800 |
| 冲
锋衣 | 2000 |
+------------+-------+
2 rows in set (0.00 sec)
mysql> SELECT
-> p.pname,
-> p.price
-> FROM products p INNER JOIN category c ON p.category_id = c.cid
-> WHERE p.price > 500 AND cname = '鞋服';
+------------+-------+
| pname | price |
+------------+-------+
| 篮
球鞋 | 800 |
| 冲
锋衣 | 2000 |
+------------+-------+
2 rows in set (0.00 sec)
3.5.2 外连接查询
- 左外连接
左外连接 , 使用 LEFT OUTER JOIN , OUTER 可以省略
左外连接的特点
以左表为基准, 匹配右边表中的数据,如果匹配的上,就展示匹配到的数据
如果匹配不到, 左表中的数据正常展示, 右边的展示为null.
SELECT 字段名 FROM 左表 LEFT [OUTER] JOIN 右表 ON 条件
-- 左外连接查询
SELECT * FROM category c LEFT JOIN products p ON c.`cid`=
p.`category_id`;
# 查询每个分类下的商品个数
/*
1.连接条件: 主表.主键 = 从表.外键
2.查询条件: 每个分类 需要分组
3.要查询的字段: 分类名称, 分类下商品个数
*/
mysql> select cname '分类',count(pid)'商品个数' from category left join products on cid=category_id group by cname;
+-----------+--------------+
| 分类 | 商品个数 |
+-----------+--------------+
| 化妆品 | 2 |
| 家电 | 3 |
| 汽车 | 0 |
| 鞋服 | 4 |
+-----------+--------------+
4 rows in set (0.00 sec)
2) 右外连接
右外连接 , 使用 RIGHT OUTER JOIN , OUTER 可以省略
右外连接的特点
以右表为基准,匹配左边表中的数据,如果能匹配到,展示匹配到的数据
如果匹配不到,右表中的数据正常展示, 左边展示为null
#语法格式
SELECT 字段名 FROM 左表 RIGHT [OUTER ]JOIN 右表 ON 条件
-- 右外连接查询
SELECT * FROM products p RIGHT JOIN category c ON p.`category_id` =
c.`cid`;
3.5.3 各种连接方式的总结
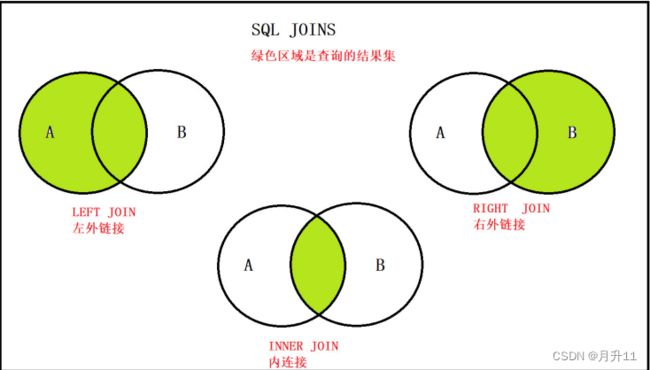
- 内连接: inner join , 只获取两张表中 交集部分的数据.
- 左外连接: left join , 以左表为基准,查询左表的所有数据, 以及与右表有交集的部分
- 右外连接: right join , 以右表为基准,查询右表的所有的数据,以及与左表有交集的部分
内连接和左外连接使用居多
第4节 合并查询
4.1 UNION
UNION 操作符用于合并两个或多个 SELECT 语句的结果集,并消除重复行。
注意,UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同。
UNION 子句的基本语法如下所示:
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
UNION
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
建表
CREATE TABLE Customers(
Id INT PRIMARY KEY AUTO_INCREMENT,
Name VARCHAR(20),
Sex VARCHAR(20),
Address VARCHAR(20),
Salary INT
);
CREATE TABLE Orders(
Oid INT PRIMARY KEY AUTO_INCREMENT,
Date VARCHAR(20),
Customers_Id VARCHAR(20),
Amount INT
);
插入数据
INSERT INTO Customers (Name, Sex, Address, Salary) VALUES ('孙悟空', '男',
'花果山',2000);
INSERT INTO Customers (Name, Sex, Address, Salary) VALUES ('猪八戒', '男',
'高老庄',1500);
INSERT INTO Customers (Name, Sex, Address, Salary) VALUES ('唐僧', '男',
'东土大唐',3000);
INSERT INTO Customers (Name, Sex, Address, Salary) VALUES ('沙僧', '男',
'流沙河',2500);
INSERT INTO Customers (Name, Sex, Address, Salary) VALUES ('女儿国王',
'女', '女儿国',10000);
INSERT INTO Customers (Name, Sex, Address, Salary) VALUES ('黄蓉', '女',
'桃花岛',7500);
INSERT INTO Customers (Name, Sex, Address, Salary) VALUES ('郭静', '男',
'牛家村',6000);
INSERT INTO Orders (Oid, Date, Customers_Id, Amount) VALUES (102, '2019-
12-08 00:00:00', 3, 2000);
INSERT INTO Orders (Oid, Date, Customers_Id, Amount) VALUES (100, '2019-
10-06 00:00:00', 3, 1500);
INSERT INTO Orders (Oid, Date, Customers_Id, Amount) VALUES (101, '2019-
09-20 00:00:00', 6, 3000);
INSERT INTO Orders (Oid, Date, Customers_Id, Amount) VALUES (103, '2020-
05-20 00:00:00', 5, 5000);
用 SELECT 语句将这两张表连接起来:
SELECT Id,NAME,Amount,Date
FROM customers
LEFT JOIN orders
on customers.Id = orders.Customers_Id
UNION
SELECT Id,NAME,Amount,Date
from customers
RIGHT JOIN orders
on customers.Id = orders.Customers_Id;
结果如下所示:
+------+----------+--------+---------------------+
| ID | NAME | AMOUNT | DATE |
+------+----------+--------+---------------------+
| 3 | 唐僧 | 1500 | 2019-10-06 00:00:00 |
| 6 | 黄蓉 | 3000 | 2019-09-20 00:00:00 |
| 3 | 唐僧 | 2000 | 2019-12-08 00:00:00 |
| 5 | 女儿国王 | 5000 | 2020-05-20 00:00:00 |
| 1 | 孙悟空 | NULL | NULL |
| 2 | 猪八戒 | NULL | NULL |
| 4 | 沙僧 | NULL | NULL |
| 7 | 郭静 | NULL | NULL |
小结:
- 选择的列数必须相同;
- 所选列的数据类型必须在相同的数据类型组中(如数字或字符)
- 列的名称不必相同
- 在重复检查期间,NULL值不会被忽略
4.2 UNION ALL
UNION ALL 运算符用于将两个 SELECT 语句的结果组合在一起,重复行也包含在内。
UNION ALL 运算符所遵从的规则与 UNION 一致。
语法:
UNION ALL的基本语法如下:
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
UNION ALL
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
现在,让我们用 SELECT 语句将Customers、Orders两张表连接起来:
SELECT Id,NAME,Amount,Date
FROM customers
LEFT JOIN orders
on customers.Id = orders.Customers_Id
UNION ALL
SELECT Id,NAME,Amount,Date
from customers
RIGHT JOIN orders
on customers.Id = orders.Customers_Id;
+------+----------+--------+---------------------+
| ID | NAME | AMOUNT | DATE |
+------+----------+--------+---------------------+
| 3 | 唐僧 | 1500 | 2019-10-06 00:00:00 |
| 6 | 黄蓉 | 3000 | 2019-09-20 00:00:00 |
| 3 | 唐僧 | 2000 | 2019-12-08 00:00:00 |
| 5 | 女儿国王 | 5000 | 2020-05-20 00:00:00 |
| 1 | 孙悟空 | NULL | NULL |
| 2 | 猪八戒 | NULL | NULL |
| 4 | 沙僧 | NULL | NULL |
| 7 | 郭静 | NULL | NULL |
| 3 | 唐僧 | 1500 | 2019-10-06 00:00:00 |
| 6 | 黄蓉 | 3000 | 2019-09-20 00:00:00 |
| 3 | 唐僧 | 2000 | 2019-12-08 00:00:00 |
| 5 | 女儿国王 | 5000 | 2020-05-20 00:00:00 |
+------+----------+--------+---------------------+
总结:
UNION和UNION ALL关键字都是将两个结果集合并为一个,也有区别。
1、重复值:UNION在进行表连接后会筛选掉重复的记录,而Union All不会去除重复记录。
2、UNION ALL只是简单的将两个结果合并后就返回。
3、在执行效率上,UNION ALL 要比UNION快很多,因此,若可以确认合并的两个结果集中不
包含重复数据,那么就使用UNION ALL。
第5节 子查询
5.1 什么是子查询
子查询概念
一条select 查询语句的结果, 作为另一条 select 语句的一部分
子查询的特点
子查询必须放在小括号中
子查询的场景中还会有另外一个特点,整个sql至少会有两个select关键字
子查询常见分类
where型 子查询: 将子查询的结果, 作为父查询的比较条件 =
from型 子查询 : 将子查询的结果, 作为 一张表,提供给父层查询使用
exists型 子查询: 子查询的结果是单列多行, 类似一个数组, 父层查询使用 IN 函数 ,包含子查询的结果
5.2 子查询的结果作为查询条件
SELECT 查询字段 FROM 表 WHERE 字段=(子查询);
- 通过子查询的方式, 查询价格最高的商品信息
# 通过子查询的方式, 查询价格最高的商品信息
-- 1.先查询出最高价格
SELECT MAX(price) FROM products;
-- 2.将最高价格作为条件,获取商品信息
SELECT * FROM products WHERE price = (SELECT MAX(price) FROM products);
- 查询化妆品分类下的 商品名称 商品价格
#查询化妆品分类下的 商品名称 商品价格
-- 先查出化妆品分类的 id
SELECT cid FROM category WHERE cname = '化妆品';
-- 根据分类id ,去商品表中查询对应的商品信息
SELECT
p.`pname`,
p.`price`
FROM products p
WHERE p.`category_id` = (SELECT cid FROM category WHERE cname = '化妆品');
- 查询小于平均价格的商品信息
-- 1.查询平均价格
SELECT AVG(price) FROM products; -- 1866
-- 2.查询小于平均价格的商品
SELECT * FROM products
WHERE price < (SELECT AVG(price) FROM products);
mysql> select avg(price) from products;
+------------+
| avg(price) |
+------------+
| 1866.6667 |
+------------+
1 row in set (0.00 sec)
mysql> select * from products where price<(select avg(price) from products);
+------+------------+-------+------+-------------+
| pid | pname | price | flag | category_id |
+------+------------+-------+------+-------------+
| p004 | 篮
球鞋 | 800 | 1 | c002 |
| p005 | 运
动裤 | 200 | 1 | c002 |
| p006 | T
恤 | 300 | 1 | c002 |
| p008 | 神
仙水 | 800 | 1 | c003 |
| p009 | 大
宝 | 200 | 1 | c003 |
+------+------------+-------+------+-------------+
5 rows in set (0.00 sec)
5.3 子查询的结果作为一张表
- 查询商品中,价格大于500的商品信息,包括 商品名称 商品价格 商品所属分类名称
mysql> select pname,price,cname from products p
-> inner join(select * from category)c
-> on p.category_id=c.cid where p.price >500;
+------------------+-------+-----------+
| pname | price | cname |
+------------------+-------+-----------+
| 小
米电视机 | 5000 | 家电 |
| 格
力空调 | 3000 | 家电 |
| 美
的冰箱 | 4500 | 家电 |
| 篮
球鞋 | 800 | 鞋服 |
| 冲
锋衣 | 2000 | 鞋服 |
| 神
仙水 | 800 | 化妆品 |
+------------------+-------+-----------+
6 rows in set (0.00 sec)
注意: 当子查询作为一张表的时候,需要起别名,否则无法访问表中的字段。
5.4 子查询结果是单列多行
子查询的结果类似一个数组, 父层查询使用 IN 函数 ,包含子查询的结果
语法格式
SELECT 查询字段 FROM 表 WHERE 字段 IN (子查询);
- 查询价格小于两千的商品,来自于哪些分类(名称)
# 查询价格小于两千的商品,来自于哪些分类(名称)
-- 先查询价格小于2000 的商品的,分类ID
SELECT DISTINCT category_id FROM products WHERE price < 2000;
-- 在根据分类的id信息,查询分类名称
-- 报错: Subquery returns more than 1 row
-- 子查询的结果 大于一行
SELECT * FROM category
WHERE cid = (SELECT DISTINCT category_id FROM products WHERE price <
2000);
使用in函数, in( c002, c003 )
-- 子查询获取的是单列多行数据
SELECT * FROM category
WHERE cid IN (SELECT DISTINCT category_id FROM products WHERE price <
2000);
- 查询家电类 与 鞋服类下面的全部商品信息
# 查询家电类 与 鞋服类下面的全部商品信息
-- 先查询出家电与鞋服类的 分类ID
SELECT cid FROM category WHERE cname IN ('家电','鞋服');
-- 根据cid 查询分类下的商品信息
SELECT * FROM products
WHERE category_id IN (SELECT cid FROM category WHERE cname IN ('家电','鞋
服'));
5.5 子查询总结
- 子查询如果查出的是一个字段(单列), 那就在where后面作为条件使用.
单列单行 =
单列多行 in - 子查询如果查询出的是多个字段(多列), 就当做一张表使用(要起别名).