Linux-Shell编程
前言:补充知识
- 指令: ps
作用:查看系统进程,比如正在运行的进程有哪些,什么时候开始运行的,哪个用户运行的,占用了多少资源。
参数:
-e 显示所有进程
-f 显示所有字段(UID,PPIP,C,STIME字段)
-h 不显示标题
-l 长格式
-w 宽输出
-a 显示一个终端的所有进程
-r 只显示正在运行的进程。
-u 显示当前用户进程和内存使用情况
-x 显示没有控制终端的进程
–sort 按照列名排序 - ps命令常用的方式有三种:
ps -ef:查看所有进程
ps -aux:查看所有进程
ps -ef | grep tomcat:查看指定进程(| 符号,是个管道符号,表示ps 和 grep 命令同时执行)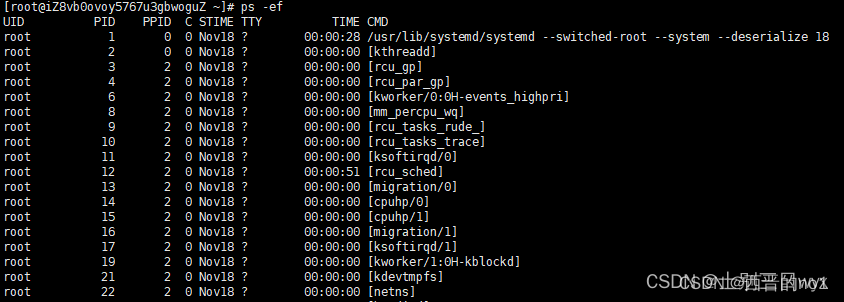
- 字段含义
UID:用户ID,即进程的拥有者
PID:进程ID
PPID:该进程的父级进程id,如果一个程序的父级进程找不到,该程序的进程被称为僵尸进程
C:cpu的占用率,形式是百分数(%)
STIME:进程开始启动时间
TTY:终端设备,发起该进程的设备识别符号,如果显示‘ ?’表示该进程并不是由终端发起
TIME:进程的执行时间
CMD:该进程的名称或对应的路径
一,shell编程的概念

1.0Shell与内核的关系
内核是Linux系统的核心,它是操作系统的最底层部分,负责管理计算机的硬件资源,例如CPU、内存、磁盘等。内核还提供了许多系统调用,供应用程序使用,例如打开文件、读写文件、创建进程、网络通信等等。
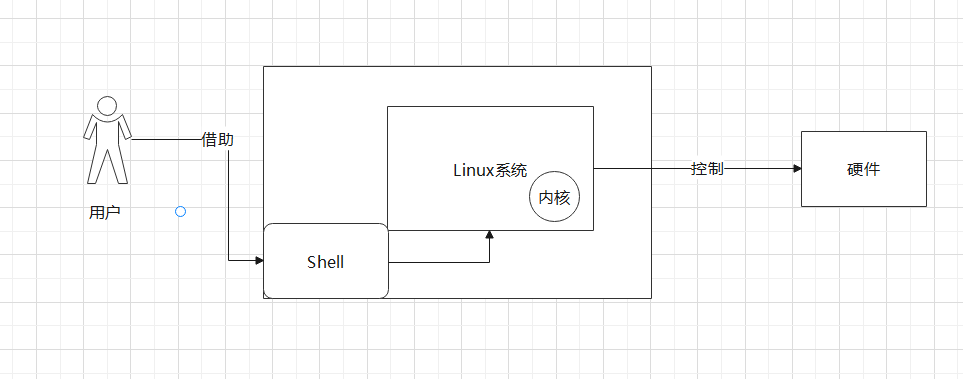
由于用户无法直接操作内核,所以需要借助Shell来进行命令的传输: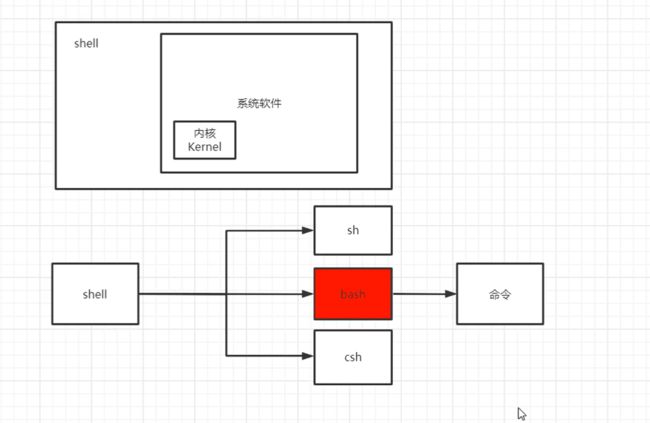
shell的编辑器查看:
 Shell是Linux系统中的一个用户界面,它是用户与内核之间的一个接口。Shell提供了一个命令行界面和一个脚本语言,用户可以使用各种命令和脚本来与操作系统交互。Shell解释器接受用户输入的命令,将其解析为系统调用和其他操作,并将它们传递给内核执行。
Shell是Linux系统中的一个用户界面,它是用户与内核之间的一个接口。Shell提供了一个命令行界面和一个脚本语言,用户可以使用各种命令和脚本来与操作系统交互。Shell解释器接受用户输入的命令,将其解析为系统调用和其他操作,并将它们传递给内核执行。
在Linux中,Shell与内核之间的交互主要通过系统调用来实现。当用户在Shell中输入一个命令时,Shell解释器将命令解析为系统调用和其他操作,并将它们传递给内核执行。当内核执行完命令后,将结果返回给Shell解释器,Shell解释器将结果显示给用户。
另外,Shell还可以通过环境变量来影响内核的行为。例如,PATH环境变量指定了可执行文件的搜索路径;HOME环境变量指定了当前用户的主目录;LD_LIBRARY_PATH环境变量指定了动态链接库的搜索路径等等。这些环境变量可以影响系统调用的执行结果。
总之,Shell和内核是Linux系统中两个非常重要的概念,它们之间的关系非常密切。Shell作为用户与内核之间的接口,负责解析用户输入的命令,并将其转换为系统调用和其他操作,从而影响内核的行为。
1.1Shell与Shell脚本
1.1.1Shell
Shell是一种命令行解释器,用来解释执行用户的命令,它是操作系统内核和用户之间的接口。一般是用户一条条输入,Shell一条条执行,这种方式称为交互式。它接收用户的命令,并将其转化为内核可以理解的指令,同时将内核的输出返回给用户。
1.1.2Shell脚本
Shell还有一种执行命令的方式就是批处理(Batch),用户实现写好一个Shell脚本(Script),里面包含很多条命令,Shell一次性执行完所有命令,不用一条条输入执行。Shell脚本是一种用于自动化任务和管理系统的脚本语言。它们是在Shell中编写的一系列命令和控制结构,以执行特定的任务。Shell脚本可以通过命令行运行,并可以接受用户输入和参数。
因此,Shell是一种交互式的命令行解释器,而Shell脚本是一种脚本语言,用于编写自动化任务和管理系统。Shell脚本通常包含一系列Shell命令和控制结构,可以在Shell中运行。
1.2Shell脚本与编程语言的区别
Shell脚本是一种脚本语言,用于编写自动化任务和管理系统。它们通常用于在Linux和其他Unix系统上编写脚本,以执行诸如文件操作、系统管理、网络编程等任务。
编程语言是一种通用的编程语言,可以用于编写广泛的应用程序。它们可以用于开发Web应用程序、桌面应用程序、移动应用程序、游戏等各种应用程序。
Shell脚本是一种解释性语言,与编译性语言(如C、Java等)不同。解释器读取脚本并将其转换为机器指令,而编译器将源代码转换为机器指令。
Shell脚本通常使用命令行界面(CLI)与用户交互,而编程语言可以使用GUI界面或CLI与用户交互。
Shell脚本通常使用一些基本的控制结构,例如条件语句和循环语句,而编程语言通常提供更丰富的控制结构和数据类型。
总的来说,Shell脚本是一种特定用途的脚本语言,用于自动化系统管理任务,而编程语言则更通用,可用于编写广泛的应用程序。
二,Shell编程基本语法
2.1系统调用fork 和exec介绍
在Shell编程中,fork和exec是两个重要的系统调用,常用于创建新的进程和执行新的程序。
2.1.1fork
fork是一个系统调用,用于创建一个新的进程。调用fork时,操作系统会在当前进程的地址空间中创建一个完全相同的子进程,包括所有变量和指令。子进程是父进程的副本,它从父进程继承了所有的资源和状态,并获得了自己的进程ID。父进程和子进程共享文件描述符,但它们各自拥有独立的地址空间。
fork()函数的语法如下:
pid_t pid = fork();
if (pid == 0) {
// 子进程
} else if (pid > 0) {
// 父进程
} else {
// fork失败
}
2.1.2exec
exec是一个系统调用,用于执行一个新的程序。调用exec时,**操作系统会将当前进程的地址空间替换为新的程序的地址空间,**并开始执行新程序的指令。exec函数有多个变体(如execl、execv、execle等),它们之间的差异在于参数的传递方式和路径的表示方式等。
exec()函数的语法如下:
int execvp(const char *file, char *const argv[]);
其中,file参数指定要执行的程序的文件名,argv参数是一个包含命令行参数的字符串数组。exec函数将通过file参数指定的程序替换当前进程,并将argv参数传递给新程序。
一般情况下,fork和exec会组合在一起使用,以创建一个新的进程并执行新的程序。
下面是一个示例代码:
#include 这个示例代码创建一个新进程,然后执行"ls -l"命令。子进程使用execvp函数来执行新程序,而父进程使用wait函数等待子进程的结束,并打印一条消息以指示子进程已经完成。
2.1.3ps命令
ps命令(process status)是用来查看当前状态下系统中运行的进程,并展示出来,ps命令给出的结果是进程的快照,也就是执行ps命令那一刻系统中运行的进程。
对系统中进程进行监测控制,查看状态,内存,CPU使用情况:
ps:仅显示瞬间进程状态,并不动态的连续;
1)ps a 显示现行终端机下的所有程序,包括其他用户的程序。
2)ps -A 显示所有进程。
3)ps c 列出程序时,显示每个程序真正的指令名称,而不包含路径,参数或常驻服务的标示。
4)ps -e 此参数的效果和指定"A"参数相同。
5)ps e 列出程序时,显示每个程序所使用的环境变量。
6)ps f 用ASCII字符显示树状结构,表达程序间的相互关系。
7)ps -H 显示树状结构,表示程序间的相互关系。
8)ps -N 显示所有的程序,除了执行ps指令终端机下的程序之外。
9)ps s 采用程序信号的格式显示程序状况。
10)ps S 列出程序时,包括已中断的子程序资料。
11)ps -t<终端机编号> 指定终端机编号,并列出属于该终端机的程序的状况。
12)ps u 以用户为主的格式来显示程序状况。
13)ps x 显示所有程序,不以终端机来区分。
top(nums):可以对进程长时间进行监控。
-b:以批处理模式操作。
-c:显示完整的命令。
-d:屏幕刷新间隔时间。
-I:忽略失效过程。
-s:保密模式。
-S:累积模式。
-i<时间>:设置间隔时间。
-u<用户名>:指定用户名。
-p<进程号>:指定进程。
-n<次数>:循环显示的次数。
2.2Linux中外部命令与内建命令
2.2.1外部命令
外部命令是指由可执行文件或脚本文件组成的命令。这些命令通常是独立的可执行文件,可以在终端中使用绝对路径或相对路径来执行它们。Linux系统提供了许多外部命令,例如**ls、grep、**awk、sed等等。这些命令通常是由操作系统提供的,也可以是由第三方软件提供的。通过环境变量 PATH来设这配置,在执行相应的外部命令的时候系统会向PATH中的地址去寻找相关的支持。
2.2.2 内建命令
内建命令是指由Shell解释器本身提供的命令。这些命令不需要单独的可执行文件或脚本文件,它们直接由Shell解释器处理。Linux系统中的常见内建命令包括cd、echo、export、alias、history等等。由于内建命令不需要启动新进程,因此它们通常比外部命令执行得更快。
在执行命令时,Shell优先查找内建命令,如果找到了就直接执行;如果没有找到,则查找可执行文件或脚本文件,如果找到了则执行。如果既没有找到内建命令,也没有找到可执行文件或脚本文件,则Shell会显示一个错误消息。
可以使用type命令来查看一个命令是内建命令还是外部命令。例如:
$ type cd
cd is a shell builtin
$ type ls
ls is aliased to `ls --color=auto'
ls is /bin/ls
这个示例中,type命令显示cd是一个内建命令,而ls是一个外部命令。注意,ls还有一个别名(alias),它指向/bin/ls可执行文件。
2.3Shell编程的基本语法
注释:用 # 开头的行表示注释,注释可以出现在代码任何位置。
变量:使用变量时,变量名不需要使用 $ 符号,赋值时需要使用 = 符号。
输出:使用 echo 命令可以将指定的文本输出到屏幕上。
输入:使用 read 命令可以从用户处获取输入,并将其存储在变量中。
条件语句:使用 if 语句可以根据指定条件执行不同的命令。
循环语句:使用 for 循环和 while 循环可以多次执行相同的命令。
函数:使用函数可以编写可重用的代码块。
- 注释
# 这是一条注释
- 变量
name="Tom"
- 输出
echo "Hello, world!"
- 输入
read -p "请输入您的名字:" name
echo "您好,$name!"
- 条件语句
if [ $age -gt 18 ]
then
echo "您已经成年了!"
else
echo "您还未成年!"
fi
- 循环语句
for i in {1..10}
do
echo $i
done
while [ $count -lt 10 ]
do
echo $count
count=$((count+1))
done
- 函数
function greet {
echo "Hello, $1!"
}
greet "Tom"
三,shell脚本
3.1基本格式和执行脚本文件
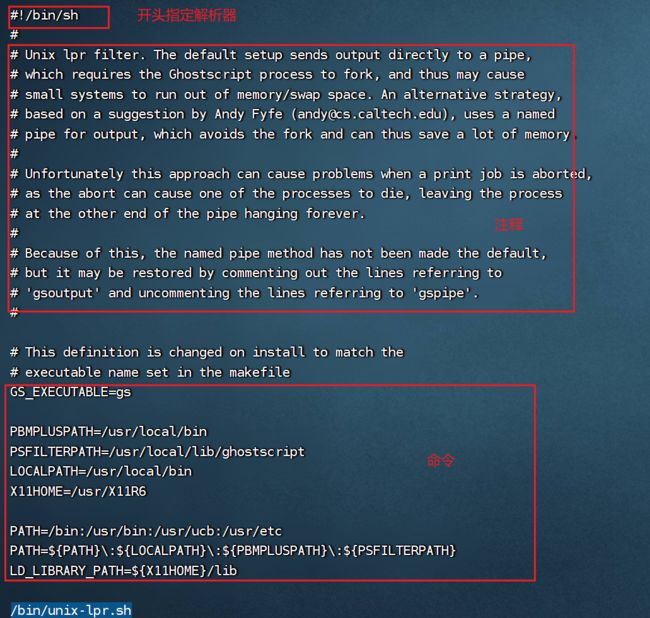
3.1.1shell脚本格式
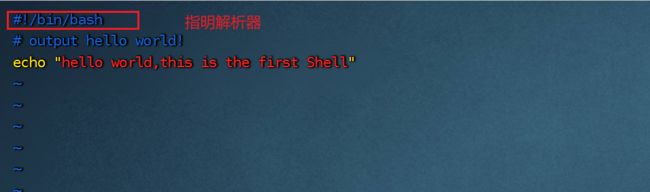
如下图,脚本都是以#!/bin/bash开始,用来指定解析器。且脚本后缀一般是.sh
3.1.2脚本执行方式
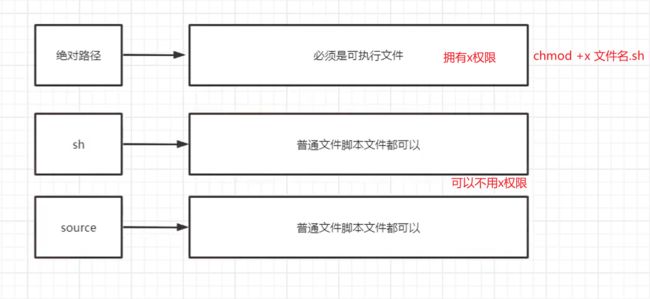
三种执行方式,执行的方式不同,直接输入绝对路径和bash 文件名,这两种方法,都需要另外开启一个新进程进行执行文件,并且会导致父进程bash中创建的变量在这两种方法中无法使用,因为进程间不共享变量,而source则不需要重新创建新进程,且变量可共享使用。
方式一:直接采用输入脚本的绝对路径或者相对路径执行脚本(必须具有可执行权限+x):
chmod +x Script/hello.sh
查看此文件的权限:只有读写权限,没有执行权限,我们需要给他加上可执行权限:


文件变绿色表示可执行文件。
再次执行查看结果:
变量测试:

方式二:直接通过bash或者sh+脚本的相对路径或者绝对路径即可
bash ./hello.sh
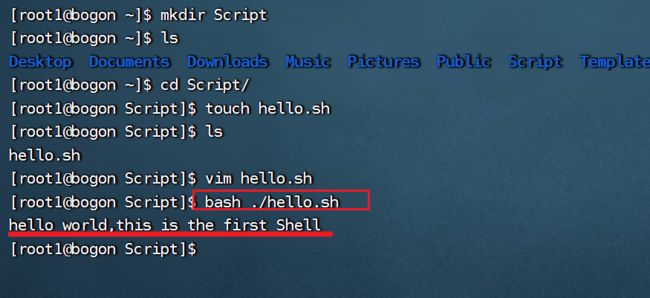
变量测试:

方式三:source加路径
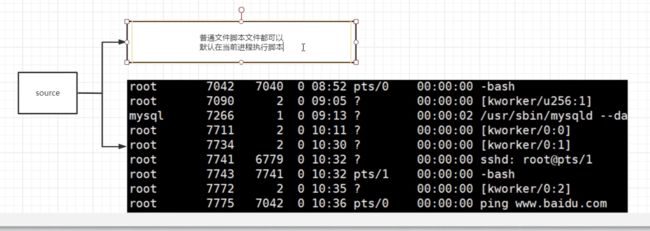
变量测试:

将变量设置为全局变量:


3.2编写一个脚本输出hello world!
- 创建文件夹script并在此文件夹内创建hello.sh文件
- 通过vim命令进入文件内部,进行文件编辑
3.3变量
3.3.0数组定义

3.3.1系统变量
反引号和$ ()的作用相同,用于命令替换(command substitution),即完成引用的命令的执行,将其结果替换出来。$ (())
(1)系统中自定义的变量有:$ HOME、$ PWD、 $ SHELL、$USER等,一般是全局变量。
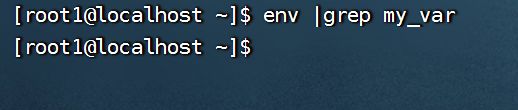
查看系统变量:env命令查看所有的系统变量

验证查看HOME变量:

(2)less命令 是一个 Linux 终端中的文本查看器,可以查看文件内容,并支持上下翻页和搜索。
用法: less [options]
常用选项:
-N:显示行号
-f:强制打开大文件
-g:高亮搜索结果
-i:忽略大小写
使用方法:
翻页: 按空格键或者 ‘f’ 键向下翻页,按 ‘b’ 键向上翻页。
搜索: 按 ‘/’ 键进入搜索模式,输入关键词,按 ‘n’ 键查找下一个匹配项,按 ‘N’ 键查找上一个匹配项。
退出: 按 ‘q’ 键退出 less。
示例: less -N file.txt 查看文件file.txt并显示行号
env | less -N#显示行号
3.3.2自定义变量
-
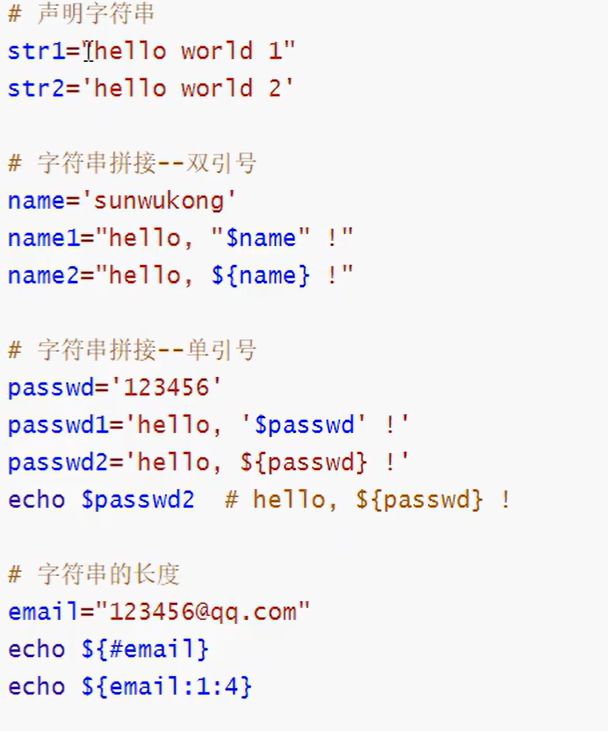
单引号与双引号定义字符串变量的区别:
(1)单引号里的任何字符都会原样输出,单引号字符串中的变量是无效的;单引号中不能单独出现一个单引号,但可以成对出现,作为字符串拼接使用。
(2)双引号:可以有变量,可出现转义字符
-
基本语法:变量名=变量值:注意“=”两侧不能存在空格
-
撤销变量:unset 变量名
-
静态变量:readonly 变量,不能撤销unset
-
在bash中变量默认类型都是字符串类型,无法直接进行数值运算,变量中如果有空格,需要用引号
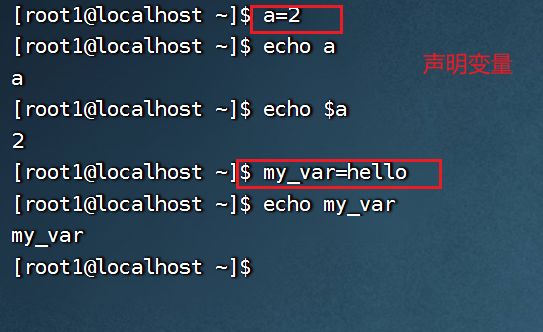 5. 注意:如果复制内容存在空格,需要用引号引起来
5. 注意:如果复制内容存在空格,需要用引号引起来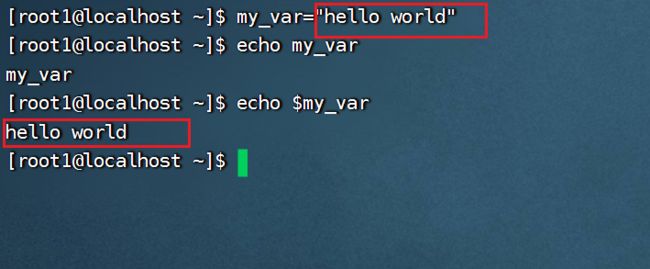
-
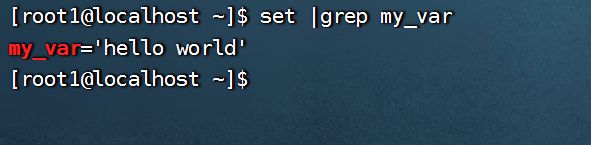
env只能查看系统定义的变量,而使用set可以查看系统以及用户自定义的变量:
-
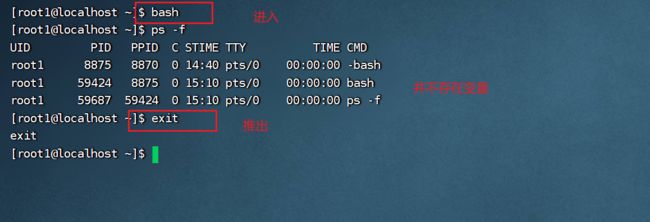
注意此时创建的变量my_var是局部变量,通过以下方式验证:创建一个子bash,并输出此子bash中的进程状况,查看是否存在定义的变量,如果没有则证明此变量是局部变量,在新创建的子bash中无法查看与使用。
-
将变量声明为全局变量:
export 变量名
以下情况证明已经进入子bash:

查看: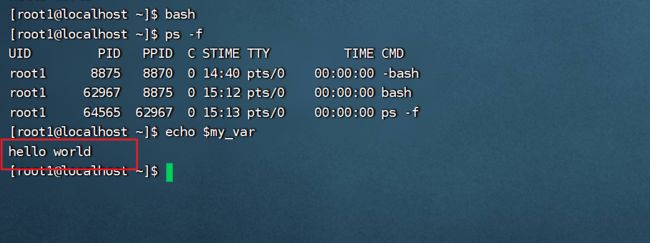
在子bash中将变量改变: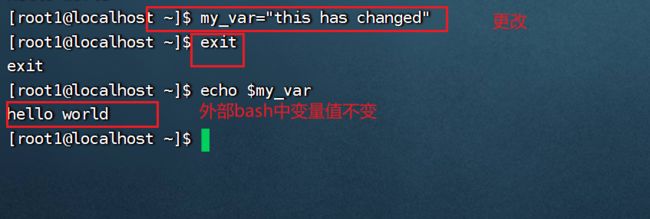
3.4将脚本文件设置成可直接执行的命令
(1)像ls,pwd,cd,等命令,直接输入就可直接执行,原因是他们的可执行文件在bin文件夹或其他文件夹中进行了声明,所以我们也可以将写好的脚本文件拷贝到bin目录下,使得下次直接输入脚本文件名称就可直接执行相关的命令:
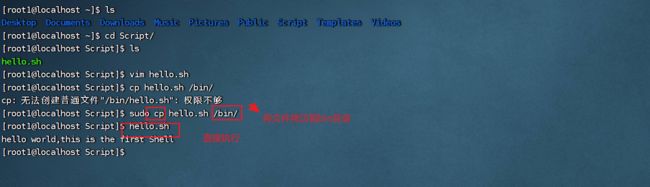
(2)但是bin目录中的可执行文件一般都是系统自己定义好的,尽量不要去更改bin目录内容,所以我们要使用其他方法达到此目的,先将文件移除:
**通过定义 P A T H 变量实现: ∗ ∗ 查看 PATH变量实现:**查看 PATH变量实现:∗∗查看PATH变量的定义格式:通过冒号分隔

3.5特殊变量
3.5.1脚本参数设置(位置参数)
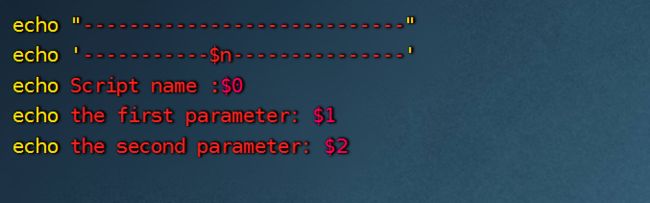
(1)$n:n是指0~9数字,用来代表执行脚本是应该在后面中输入的参数位置,如果大于10 ,用大括号括起来:${11}
(2)创建一个新的脚本:parameter.sh

对脚本内容进行编写:vim parameter.sh
注意:单引号括起来的内容不会被认为是变量,如果用双引号则会被认为是变量:
给脚本加上:x可执行权限![]()
执行脚本文件并输入相关参数:
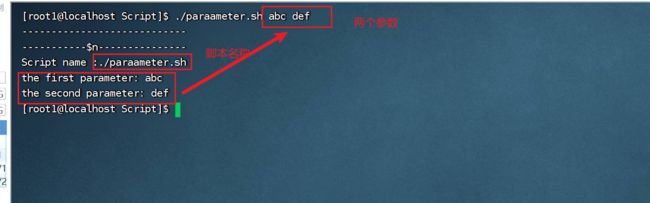
上述第一个参数$0对应的是脚本名称,但是如果输入的执行路径很长,此名称也会很长,我们只需要获取最后的文件名即可, basename 命令读取 String 参数,删除以 /(斜杠) 结尾的前缀以及任何指定的 Suffix 参数,并将剩余的基本文件名称写至标准输出。basename 命令应用以下创建基本文件名称的规则:
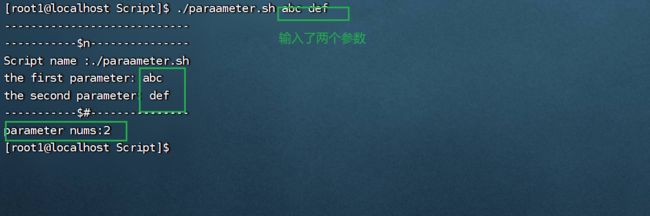
3.5.2$#获取参数个数
常用于循环中,判断参数个数是否正确以及加强脚本的健壮性。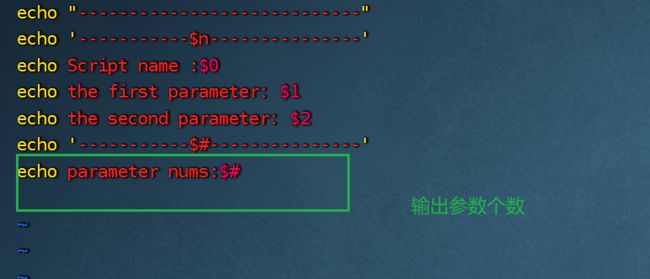
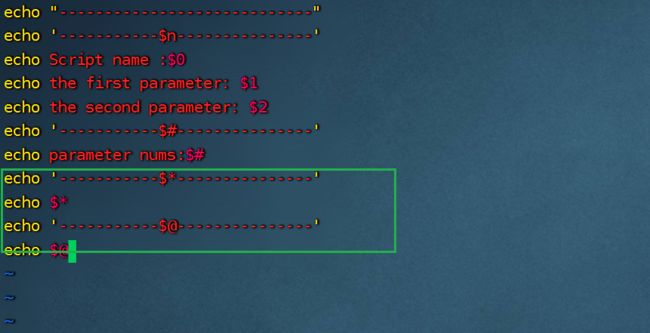
3.5.3获取命令行所有参数
$* :获取变量代表命令 行中所有参数,并把所有参数看作一个整体。
$@:获取变量代表命令 行中所有参数,**把每个参数区别对待。**可以使用for循环遍历参数。
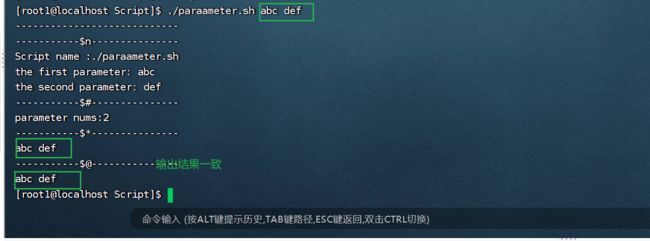
3.5.4 $?判断命令执行情况
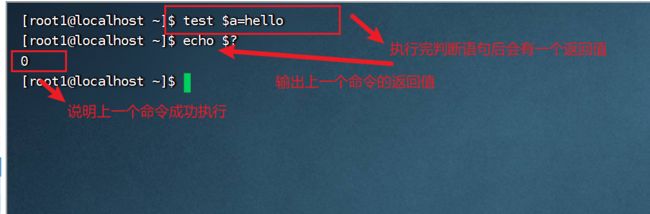
$?:最后一次执行的命令返回状态,如果这个变量的值是0,证明上一个命令正确执行,非零则上一个命令执行不正确。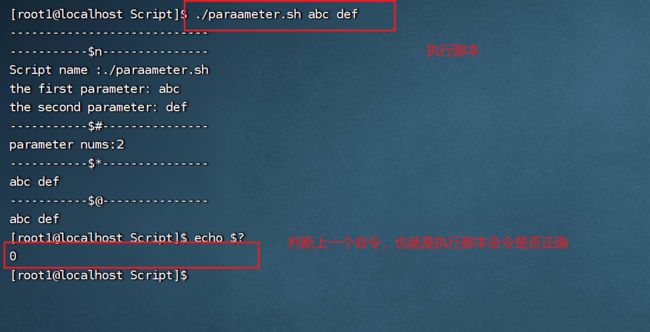
3.6运算符
3.6.1加减乘除运算
Liunx的shell编程中不可以直接将两个数值进行运算:
- 加减法运算
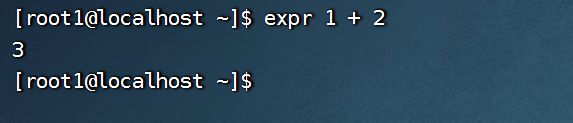
前面必须加上expr,而且后面参加运算的运算符之间必须有空格隔开。
expr 1 + 2
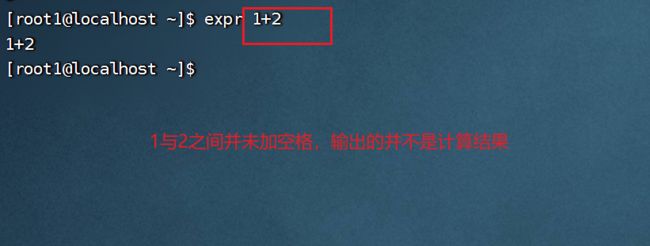
- 乘法运算:不能直接用号,因为号在Linux中有特殊含义,必须将其进行转义:


3.6.2简化运算
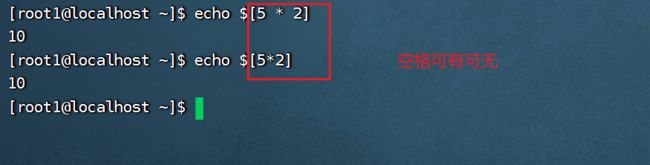
- 基本语法:$((运算式))双小括号或者 $[运算式]
- 实例演示:中括号内的运算公式之间空格可以不用写,由于$[5*2]属于一个命令,要想看输出结果,前面还必须加上echo命令将结果输出
3.7条件判断
- 基本语法:test condition
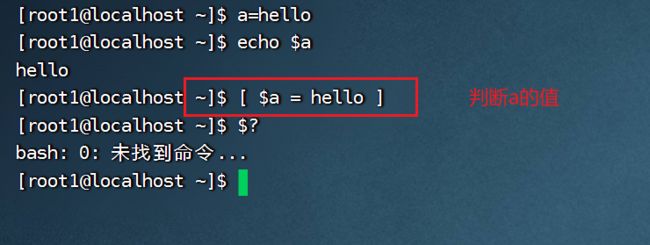
- 简写:[ condition ],conditon前后有空格
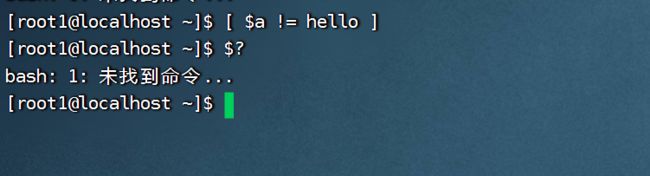
- 判断是否不等于!=
- 大于小于判断应用在整数
前面的 = 与! = 判断的是字符串之间的关系 前面的=与!=判断的是字符串之间的关系 前面的=与!=判断的是字符串之间的关系

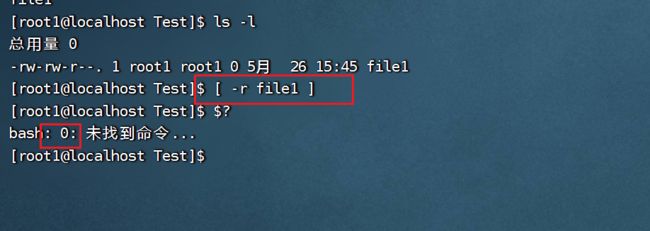
文件判断:-r 文件名
- &&与符号,多重判断
[ 条件1 ]&&[ 条件2 ]:只有条件1为真才能执行条件2
3.8流程控制
3.8.0if 单分支
(1)单分支
在命令输入行中,每一条命令都要用分号隔开,如果写在脚本中则不必,如下写一个脚本文件:
if [条件判断];
then
程序
fi

(2)定义脚本文件
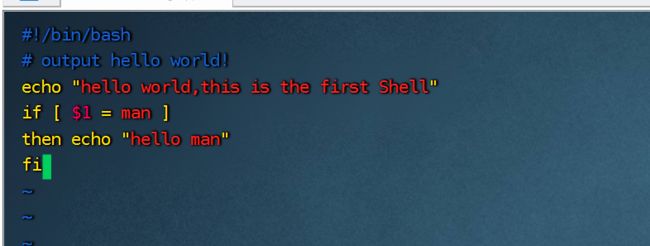
给脚本文件添加-x执行权限:
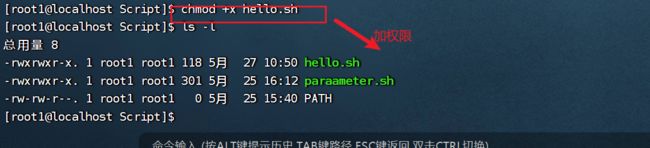
运行脚本:
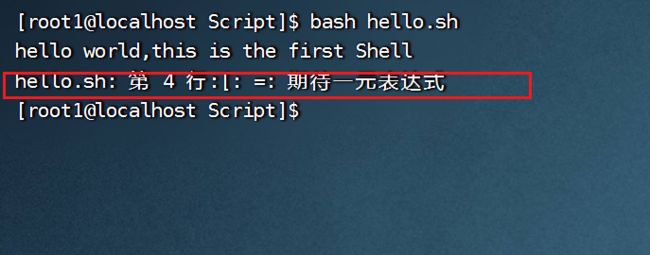
原因:
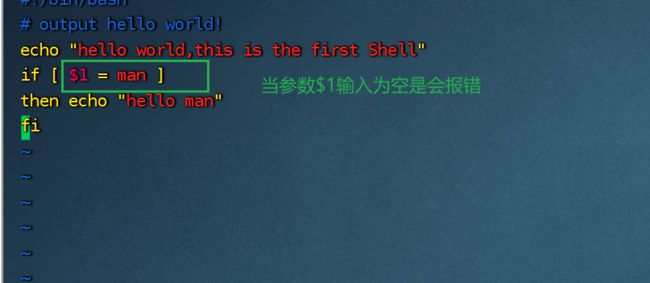
解决:
测试:不输入参数时

输入参数man时: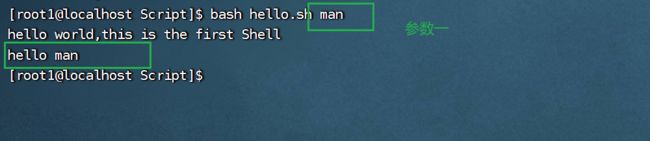
(3)多重判断条件:if [条件1] && [条件2];then 执行语句 ; fi;
如果在同一个[]存在两个判断条件,且是逻辑与:中间加-a,逻辑或加-o
if[conditon -a condition];then ;fi;
if[conditon -o condition];then;fi;
3.8.1if else多分支
if[]
then
代码1
else
代码2


if[condition]
then
代码1
elif[condition]
then
代码2
else
代码3
fi
总结:if判断语句实现的仅仅是二分支,如果想实现多重分支还需要用其他的判断语句
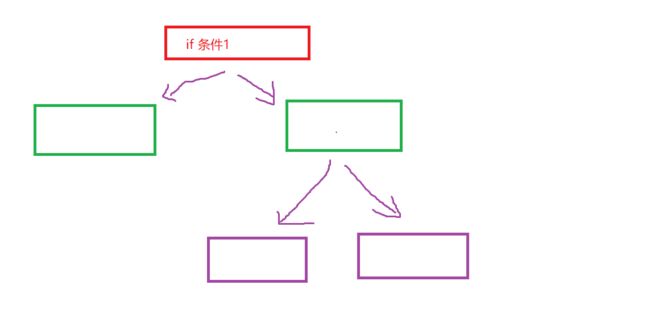
3.8.2case语句
每一个匹配模式均以右半括号结束,且每个命令序列下一行都有两个分号
case 变量值 in
匹配模式1)
命令序列1
;;
匹配模式2)
命令序列2
;;
........
........
*) #表示不是以上模式则执行
命令序列
;;
esac
- case行必须以“in”结尾
- 匹配模式必须以“)”结尾
- “;;” 双分号表示命令序列结束
- “*)”表示默认模式,“ * ”于通配符含义相同
3.8.3for循环
语法1:
for ((初始值;循环控制条件;变量变化))
do
程序
done
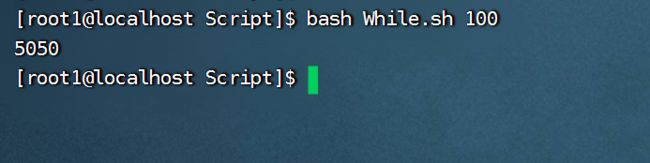
案例:从0加到100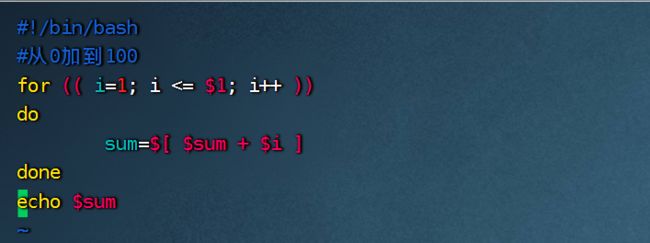
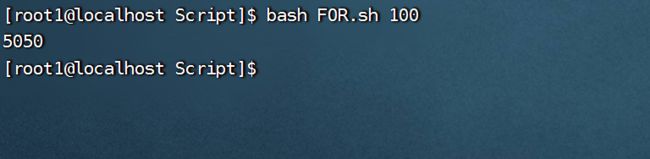
注意:我们在for循环中直接运用了<=符号进行判断,而没有使用-lt原因是外面用了双重括号(()),当使用了双重括号时,可以直接使用数学中的一些表达式。


语法2:
for 变量 in 值1 值2....
do
程序
done
案例打印所有输入数值:

内部运算符:大括号{}:从1到100的序列可以写成{1…100}
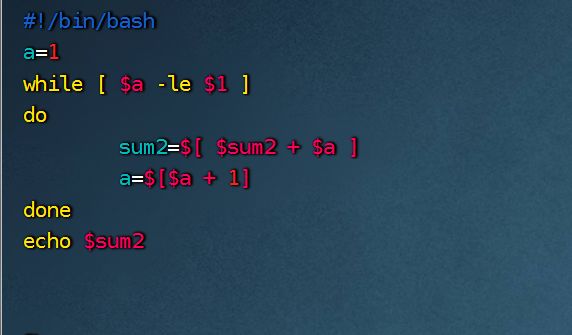
3.8.4while循环
while[条件判断]
do
程序
done
3.9read读取控制台输入
-
基本语法
read (选项)(参数)
(1)选项:-p:指定读取值时的提示符;-t:指定读取值时的等待时间,如果不加-t,则一直等待。
(2)参数:指定读取值的变量名 -
案例实操
提示七秒内,读取控制台输入的值
#!/bin/bash
read -t 10 -p "请输入您的名字!" name
echo $name
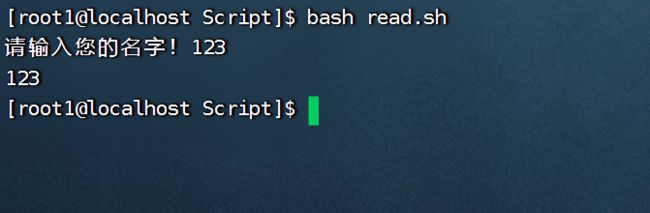
如果10秒内仍未输入直接退出
3.10函数
系统函数可以直接通过$(函数名 参数)进行调用
3.10.1自定义函数
(1)基本语法
function funnname(参数)
{
action;
return int;
}
(2)注意:
在调用函数之前必须先声明函数,shell脚本是逐行执行的,不会像其他编程语言先编译;
函数返回值,只能通过$?系统变量获取,可以显示加:return 返回,如果不加,则将最后一条命令运行结果作为返回值,return 返回的数值n(0~255),只能是此范围内的数值。
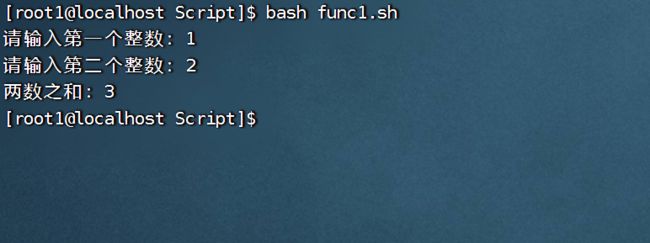
(3)案例:
#!/bin/bash
#定义函数
function add()
{
s=$[$1 + $2]
echo "两数之和:"$s
}
#调用函数
read -p "请输入第一个整数:" a
read -p "请输入第二个整数:" b
add $a $b
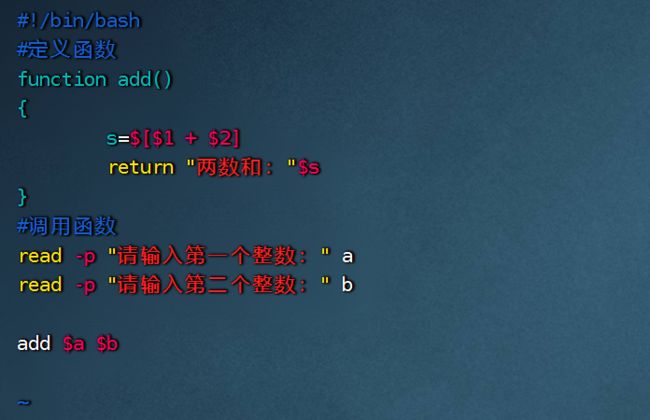
将函数中的echo命令换成return:
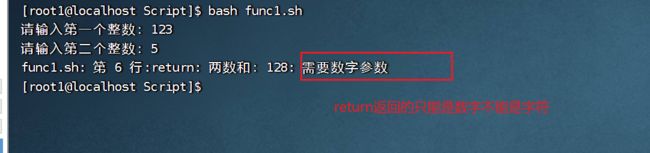
改进:
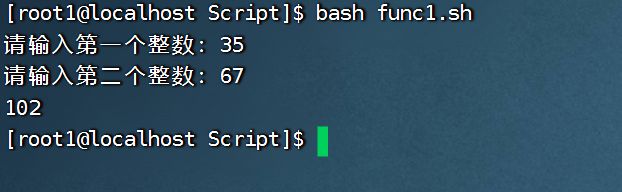
但输入的数值比较大,大于255时就会出现运算错误: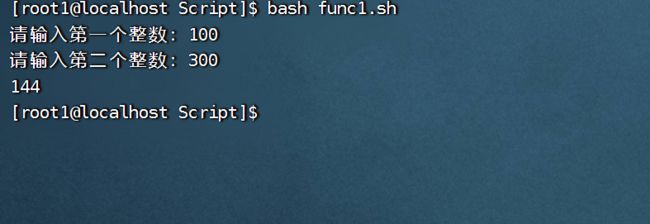
再次改进:通过$()将括号内的值做变量替换,将结果复制给其他变量:


四,综合案例
4.1 实现文件归档

#!/bin/bash
#1.判断当前给的参数是否正确,$#获取参数的个数,判断参数个数是否唯一,一个地址
if [ $# -ne 1 ]
then
echo"参数个数不对,应该输入一个参数,作为归档目录名"
#直接推出脚本
exit
fi
#2.从参数中获取目录名称,先判断是否为一个目录 -d
if [ -d $1 ]
then
echo
else
echo "目录不存在!"
exit
fi
#3通过系统函数basename或者dirname对输入的路径进行截取,此处我们需要一个绝对路径
#4获取到文件名DIR_NAME和路径DIR_PATH
DIR_NAME=$(basename $1)
DIR_PATH=$(cd $(dirname $1); pwd)
#5获取日期
DATE=$(date +%y%m%d)
#6定义生成归档文件名称
FILE=archive_${DIR_NAME}_$DATE.tar.gz
#保存路径
DEST=/root/archive/$FILE
#7开始归档
echo "----------开始归档-----------"
echo
tar -czf $DEST $DIR_PATH/$DIR_NAME
#8判断是否执行成功
if [ $? -eq 0 ]
then
echo
echo "归档成功"
echo "归档文件为:$DEST"
else
echo"归档失败"
fi
exit
(1)创建归档目录 (2)运行不输入参数
(2)运行不输入参数
(3) sudo ./daily_archive.sh ../Script
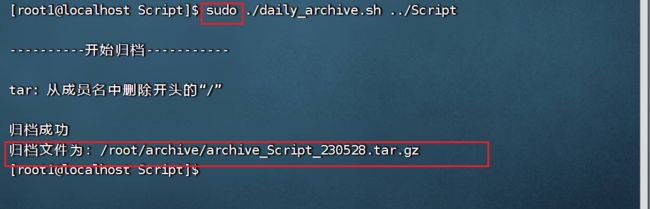
4.2实现自动归档
实现每天凌晨两点自动归档:
加入定时任务:
4.2.1定时人物crontab
-
crontab在Linux主要用于周期定时任务管理。通常安装操作系统后,默认已启动crond服务。crontab可理解为cron_table,表示cron的任务列表。类似crontab的工具还有at和anacrontab,但具体使用场景不同。
安装命令:yum install crontabs
crontab命令的一般形式为:crontab [-u user] -e -l -r-u 用户名(user)
-e 编辑crontab文件(edit)
-l 列出crontab文件的内容(list)
-r 删除crontab文件(remove)
如果是使用当前用户执行crontab命令,便不需要使用-u选项,因为crontab命令会自动识别当前用户。
-
查看当前用户设置的定时任务
crontabl -l#查看当前系统中是否有定时任务

3. 设置定时任务
(1)编辑器内时间格式如下:
f1 f2 f3 f4 f5 program
参数说明:
f1:分钟
f2:小时 范围0~23
f3:日
f4:月 范围1~12
f5:星期 范围0~7 0/7表示星期日
program:表示要执行的程序
凌晨两点:0 2 * * * 程序
(注意:由于不需要限定日期、月份、星期,所以日期、月份和星期域用*号表示)
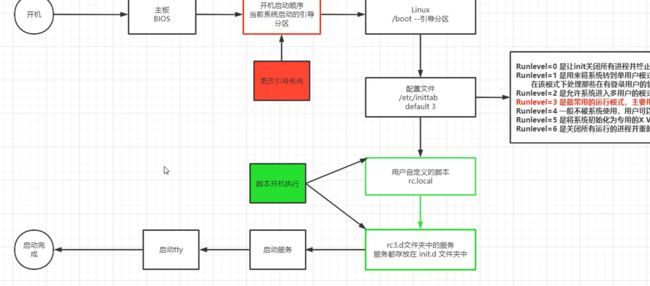
五,开机启动