python的scrapy框架----->可以使我们更加强大,为打破写许多代码而生
目录
scrapy框架
pipeline-itrm-shell
scrapy模拟登录
scrapy下载图片
下载中间件
scrapy框架
含义:
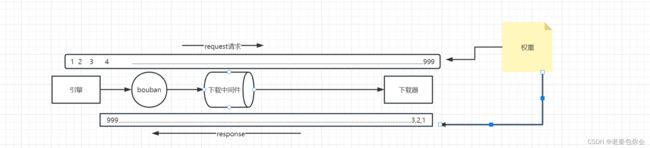
构图: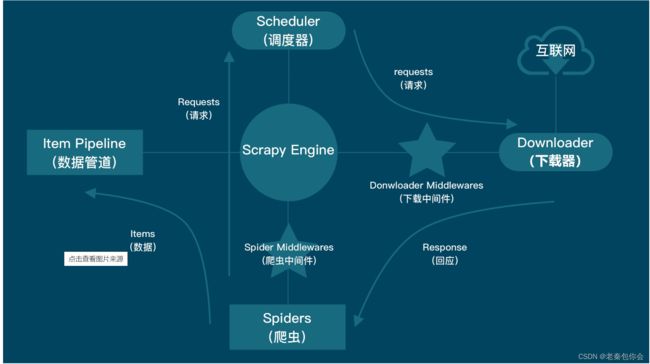
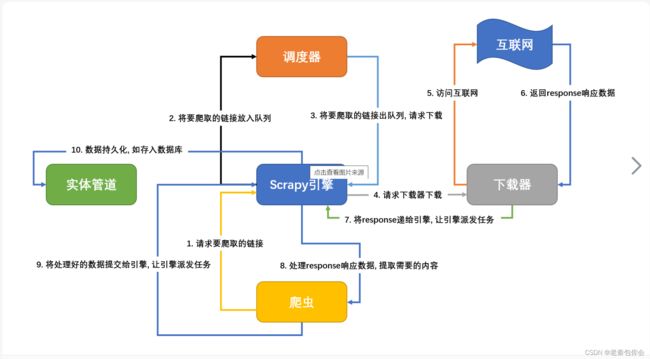
运行流程:1.scrapy框架拿到start_urls构造了一个request请求
2.request请求发送给scrapy引擎,中途路过爬虫中间件,引擎再发送request给调度器(一个队列存储request请求)
3.调度器再把requst请求发送给引擎
4.引擎再把requst请求发送给下载器,中途经过下载中间件
5.下载器然后访问互联网然后返回response响应
6.下载器把得到的response发送给引擎,中途经过下载中间件
7.引擎发送resonse给爬虫,中途路过爬虫中间件
8.爬虫通过response获取数据,(可以获取url,....)如果还想再发请求,就再构造一个request请求进行发送给引擎并再循环一次,如果不发请求,就把数据发送给引擎,中途路过爬虫中间件
9.引擎把数据再发送给管道
10.管道进行保存
我们先来通过cmd页板来创建项目吧
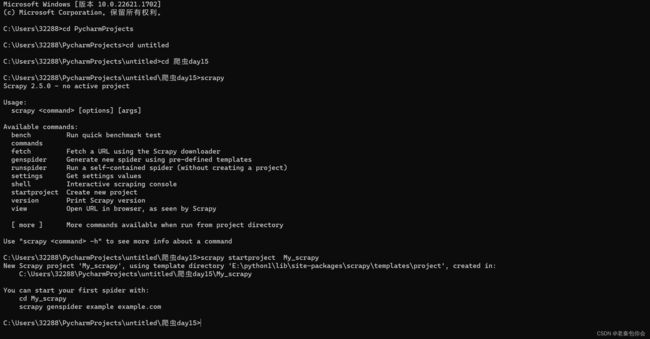

c:/d:/e: --->切换网盘
cd 文件名称 ----->切换进文件
scrapy startproject 项目名称 -------->创建项目
scrapy genspider 爬虫文件名称 域名 ------->创建爬虫文件
scrapy crawl 爬虫文件名称 ------------>运行爬虫文件
我们还可以创建start.py文件运行爬虫文件(要创建在项目下的第一层)
文件的创建位置:

代码运行爬虫文件:
from scrapy import cmdline
# cmdline.execute("scrapy crawl baidu".split())
# cmdline.execute("scrapy crawl novel".split())
cmdline.execute("scrapy crawl shiping".split())导入from scrapy import cmdline
cmdline.execute([ 'scrapy',' crawl',' 爬虫文件名称' ]) :运行爬虫文件
下面我来分析一下里面的文件
爬虫名字.py文件
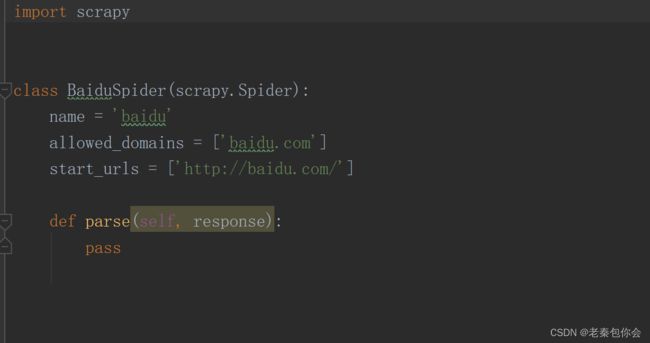
可以看出scrapy框架给出了一些类属性,这些类属性的值可以更改,但是def parse()是不能随意更改名字和传参的
settings.py文件

找到这个并打开,把注释去掉,数值越小越先执行,如果不打开就无法传数据到pipelines.py文件里的
MyScrapyPipeline类中的process_item()中的item参数
下面我来演示,
import scrapy
class BaiduSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ['douban.com']
start_urls = ['https://movie.douban.com/review/best/']
def parse(self, response):
print(response.text)结果:
当我们点击第一个网址是会跳转到下面去

是因为爬虫文件遵守了一个规则,解决方法如下:在settings.py文件找到如下的代码:

把True改为False,然后运行
结果:
可以看出减少了一个错误
但还是有错误,下面我们来解决一下:
解决403的方法有添加UA(header请求头)
如图找到这里:

把My_scrapy (+http://www.yourdomain.com)这个更改为一个请求头:
![]()
结果:
可以正常访问了
middlewares.py文件( 用于加请求头)
但有些小可爱觉得这样太麻烦了,如果是更换header请求头很频繁就很不好用,对于这个问题,我们可以想想,如果在发送请求的过程就加个请求头是不是就不用这么麻烦了,那怎么加呢,
小可爱们可以想想,中间件这个是不是可以利用一下:
那我们就要找到中间件了,中间件在scrapy项目是一个middlewares.py文件

当我们打开这个文件是会看见:
主要是这个文件把爬虫中间件和下载中间件都写在middlewares.py文件
MyScrapyDownloaderMiddleware 这个是下载中间件
MyScrapySpiderMiddleware 这个是爬虫中间件
所以下面我来讲解 MyScrapyDownloaderMiddleware

主要的还是这两个比较常用,下面我们先来process_crawler
代码截图:

当我们打印的时候会发现,怎么没有打印,为什么会这样? 原因是我们的中间件还未打开,下面我们举要找到settings,py文件,并将其注释去掉
代码截图:

一运行成功了:

那我们再来试试process_response
代码截图:

结果:
 可以看出request 是在response前面的
可以看出request 是在response前面的
可能一些小可爱又想到了一些情况,可不可以创建一个请求和响应的呢
下面我们来试试
代码截图:


结果:

细心的小可爱会发现和自己的预想不对,
下面我截取下载中间件来:
这个就是问题所在
下面我来解释一下下面的:
process_request(request, spider)
# - return None: continue processing this request
当return None时就会传递下去,比如duoban的process_request() 返回return None就会运行下载中间件的process_request()
# - or return a Request object
当return (一个Request对象)时不会传递下去,比如duoban的process_request() 返回return (一个Request对象)就不会运行下载中间件的process_request()而是返回到引擎,引擎返回给调度器(原路返回)
# - or return a Response object
当return (一个Responset对象)时不会传递下去,比如duoban的process_request() 返回return (一个Response对象)就不会运行下载中间件的process_request()而是返回到引擎,引擎返回给爬虫文件(跨级)
# - or raise IgnoreRequest: process_exception() methods of
如果这个⽅法抛出异常,则会调⽤process_exception⽅法
# installed downloader middleware will be called
process_response(request, response, spider)
# - return a Response object
# - return a Request object
返回Request对象:停⽌中间器调⽤,将其放置到调度器待调度下载;
# - or raise IgnoreRequest
有些小可爱就会想,那我可不可以自己创建一个中间件用于添加请求头:(要在middlewares.py文件)
from scrapy import signals
import random
class UsertMiddleware:
User_Agent=["Mozilla/5.0 (compatible; MSIE 9.0; AOL 9.7; AOLBuild 4343.19; Windows NT 6.1; WOW64; Trident/5.0; FunWebProducts)",
"Mozilla/4.0 (compatible; MSIE 8.0; AOL 9.7; AOLBuild 4343.27; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)"]
def process_request(self, request, spider):
# 添加请求头
print(dir(request))
request.headers["User-Agent"]=random.choice(self.User_Agent)
# 添加代理ip
# request.meta["proxies"]="代理ip"
return None
class UafgfMiddleware:
def process_response(self, request, response, spider):
# 检测请求头是否添加上
print(request.headers["User-Agent"])
return response
结果
是可以运行的
pipelines.py文件
process_item(self, item, spider)
item:接收爬虫文件返回过来的数据,如字典
下面我们来爬取一下豆瓣吧
练习爬取豆瓣电影的图片
爬虫文件.py:
import scrapy
class BaiduSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ['douban.com','doubanio.com']
start_urls = ['https://movie.douban.com/review/best/']
a=1
def parse(self, response):
divs=response.xpath('//div[@id="content"]//div[@class="review-list chart "]//div[@class="main review-item"]')
for div in divs:
# print(div.extract)
title=div.xpath('./a/img/@title')
src=div.xpath('./a/img/@src')
# print(title.extract_first())
print(src.extract_first())
yield {
"title": title.extract_first(),
"src": src.extract_first(),
"type": "csv"
}
# 再发请求下载图片
yield scrapy.Request(
url=src.extract_first(),
callback=self.parse_url,
cb_kwargs={"imgg":title.extract_first()}
)
#第一种
# next1=response.xpath(f'//div[@class="paginator"]//a[1]/@href').extract_first()
# 第二种方法自己构建
next1="/review/best?start={}".format(20*self.a)
self.a+=1
url11='https://movie.douban.com'+next1
yield scrapy.Request(url=url11,callback=self.parse)
print(url11)
def parse_url(self,response,imgg):
# print(response.body)
yield {
"title":imgg,
"ts":response.body,
"type":"img"
}
pipelines.py文件:
import csv
class MyScrapyPipeline:
def open_spider(self,spider): # 当爬虫开启时调用
header = ["title", "src"]
self.f = open("move.csv", "a", encoding="utf-8")
self.wri_t=csv.DictWriter(self.f,header)
self.wri_t.writeheader()
def process_item(self, item, spider): # 每次传参都会调用一次
if item.get("type")=="csv":
item.pop("type")
self.wri_t.writerow(item)
if item.get("type")=="img":
item.pop("type")
with open("./图片/{}.png".format(item.get("title")),"wb")as f:
f.write(item.get("ts"))
print("{}.png下载完毕".format(item.get("title")))
return item
def close_spider(self,spider):
self.f.close()settings.py文件:


这个可以只输出自己想输出的内容
_____________________________________



以上这些都有打开
记住如果爬虫文件里发送请求失败后就无法回调pipelines.py文件里的函数
暂停和恢复爬虫的方法
有些小可爱觉得有没有可以暂停和恢复爬虫的方法?有的话那是啥
下面我来讲讲
![]()
scrapy crawl 爬虫文件名字 -s JOBDIR=文件路径(随便定义)
Ctrl+c暂停爬虫
当小可爱想再次恢复时会发现不能运行下载了,
原因是啥呢,因为我们写的方法和框架给的不一样,
scrapy.Request如下:

dont_filte(不过滤吗?)r是一个过滤,为False则过滤(相同的url只访问一次),为True则不过滤
小可爱就会觉得那为啥parse()能发送,结果如下:

结果就很明了了,如果要想不过滤,就得更改

如果你想过滤重写方法:

scrapy模拟登录
有两种方法:
● 1 直接携带cookies请求⻚⾯(半自动,用selenium获取或者自己手动获取cookie)
https://www.1905.com/vod/list/c_178/o3u1p1.html来做个案例
第一种方法之手动登录获取之请求页面
爬虫文件代码实例一(在爬虫文件添加cookie);
import scrapy
class A17kSpider(scrapy.Spider):
name = '17k'
allowed_domains = ['17k.com']
start_urls = ['https://www.17k.com/']
# 重写
def start_requests(self):
cook="GUID=f0f80f5e-fb00-443f-a6be-38c6ce3d4c61; __bid_n=1883d51d69d6577cf44207; BAIDU_SSP_lcr=https://www.baidu.com/link?url=v-ynoaTMtiyBil1uTWfIiCbXMGVZKqm4MOt5_xZD0q7&wd=&eqid=da8d6ae20003f26f00000006647c3209; Hm_lvt_9793f42b498361373512340937deb2a0=1684655954,1684929837,1685860878; dfxafjs=js/dfxaf3-ef0075bd.js; FPTOKEN=zLc3s/mq2pguVT/CfivS7tOMcBA63ZrOyecsnTPMLcC/fBEIx0PuIlU5HgkDa8ETJkZYoDJOSFkTHaz1w8sSFlmsRLKFG8s+GO+kqSXuTBgG98q9LQ+EJfeSHMvwMcXHd+EzQzhAxj1L9EnJuEV2pN0w7jUCYmfORSbIqRtu5kruBMV58TagSkmIywEluK5JC6FnxCXUO0ErYyN/7awzxZqyqrFaOaVWZZbYUrhCFq0N8OQ1NMPDvUNvXNDjDOLM6AU9f+eHsXFeAaE9QunHk6DLbxOb8xHIDot4Pau4MNllrBv8cHFtm2U3PHX4f6HFkEpfZXB0yVrzbX1+oGoscbt+195MLZu478g3IFYqkrB8b42ILL4iPHtj6M/MUbPcxoD25cMZiDI1R0TSYNmRIA==|U8iJ37fGc7sL3FohNPBpgau0+kHrBi2OlH2bHfhFOPQ=|10|87db5f81d4152bd8bebb5007a0f3dbc3; c_channel=0; c_csc=web; accessToken=avatarUrl%3Dhttps%253A%252F%252Fcdn.static.17k.com%252Fuser%252Favatar%252F03%252F43%252F75%252F100257543.jpg-88x88%253Fv%253D1685860834000%26id%3D100257543%26nickname%3D%25E8%2580%2581%25E5%25A4%25A7%25E5%2592%258C%25E5%258F%258D%25E5%25AF%25B9%25E6%25B3%2595%25E7%259A%2584%25E5%258F%258D%26e%3D1701413546%26s%3Db67793dfa5cea859; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22100257543%22%2C%22%24device_id%22%3A%221883d51d52d1790-08af8c489ac963-26031a51-1638720-1883d51d52eea0%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E8%87%AA%E7%84%B6%E6%90%9C%E7%B4%A2%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22https%3A%2F%2Fwww.baidu.com%2Flink%22%2C%22%24latest_referrer_host%22%3A%22www.baidu.com%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC%22%7D%2C%22first_id%22%3A%22f0f80f5e-fb00-443f-a6be-38c6ce3d4c61%22%7D; Hm_lpvt_9793f42b498361373512340937deb2a0=1685861547"
yield scrapy.Request(
url=self.start_urls[0],
callback=self.parse,
cookies={lis.split("=")[0]:lis.split("=")[1] for lis in cook.split(";")}
)
def parse(self, response):
# print(response.text)
yield scrapy.Request(url="https://user.17k.com/www/",callback=self.parse_url)
def parse_url(self,response):
print(response.text)
结果:
爬虫文件代码实例二(在下载中间件文件添加cookie);
class MyaddcookieMiddleware:
def process_request(self, request, spider):
cook = "GUID=f0f80f5e-fb00-443f-a6be-38c6ce3d4c61; __bid_n=1883d51d69d6577cf44207; BAIDU_SSP_lcr=https://www.baidu.com/link?url=v-ynoaTMtiyBil1uTWfIiCbXMGVZKqm4MOt5_xZD0q7&wd=&eqid=da8d6ae20003f26f00000006647c3209; Hm_lvt_9793f42b498361373512340937deb2a0=1684655954,1684929837,1685860878; dfxafjs=js/dfxaf3-ef0075bd.js; FPTOKEN=zLc3s/mq2pguVT/CfivS7tOMcBA63ZrOyecsnTPMLcC/fBEIx0PuIlU5HgkDa8ETJkZYoDJOSFkTHaz1w8sSFlmsRLKFG8s+GO+kqSXuTBgG98q9LQ+EJfeSHMvwMcXHd+EzQzhAxj1L9EnJuEV2pN0w7jUCYmfORSbIqRtu5kruBMV58TagSkmIywEluK5JC6FnxCXUO0ErYyN/7awzxZqyqrFaOaVWZZbYUrhCFq0N8OQ1NMPDvUNvXNDjDOLM6AU9f+eHsXFeAaE9QunHk6DLbxOb8xHIDot4Pau4MNllrBv8cHFtm2U3PHX4f6HFkEpfZXB0yVrzbX1+oGoscbt+195MLZu478g3IFYqkrB8b42ILL4iPHtj6M/MUbPcxoD25cMZiDI1R0TSYNmRIA==|U8iJ37fGc7sL3FohNPBpgau0+kHrBi2OlH2bHfhFOPQ=|10|87db5f81d4152bd8bebb5007a0f3dbc3; c_channel=0; c_csc=web; accessToken=avatarUrl%3Dhttps%253A%252F%252Fcdn.static.17k.com%252Fuser%252Favatar%252F03%252F43%252F75%252F100257543.jpg-88x88%253Fv%253D1685860834000%26id%3D100257543%26nickname%3D%25E8%2580%2581%25E5%25A4%25A7%25E5%2592%258C%25E5%258F%258D%25E5%25AF%25B9%25E6%25B3%2595%25E7%259A%2584%25E5%258F%258D%26e%3D1701413546%26s%3Db67793dfa5cea859; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22100257543%22%2C%22%24device_id%22%3A%221883d51d52d1790-08af8c489ac963-26031a51-1638720-1883d51d52eea0%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E8%87%AA%E7%84%B6%E6%90%9C%E7%B4%A2%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22https%3A%2F%2Fwww.baidu.com%2Flink%22%2C%22%24latest_referrer_host%22%3A%22www.baidu.com%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC%22%7D%2C%22first_id%22%3A%22f0f80f5e-fb00-443f-a6be-38c6ce3d4c61%22%7D; Hm_lpvt_9793f42b498361373512340937deb2a0=1685861547"
cookies = {lis.split("=")[0]: lis.split("=")[1] for lis in cook.split(";")}
request.cookies=cookies
return None爬虫文件代码实例三(在下载中间件文件添加cookie);
def sele():
#创建一个浏览器
driver=webdriver.Chrome()
#打开网页
driver.get("https://user.17k.com/www/bookshelf/")
print("你有15秒的时间登入")
time.sleep(15)
print(driver.get_cookies())
print({i.get("name"):i.get("value") for i in driver.get_cookies()})
class MyaddcookieMiddleware:
def process_request(self, request, spider):
sele()
return None找接⼝发送post请求存储cookie
代码1:
import scrapy
class A17kSpider(scrapy.Spider):
name = '17k'
allowed_domains = ['17k.com']
start_urls = ['https://www.17k.com/']
# # 重写
# def start_requests(self):
# cook="GUID=f0f80f5e-fb00-443f-a6be-38c6ce3d4c61; __bid_n=1883d51d69d6577cf44207; BAIDU_SSP_lcr=https://www.baidu.com/link?url=v-ynoaTMtiyBil1uTWfIiCbXMGVZKqm4MOt5_xZD0q7&wd=&eqid=da8d6ae20003f26f00000006647c3209; Hm_lvt_9793f42b498361373512340937deb2a0=1684655954,1684929837,1685860878; dfxafjs=js/dfxaf3-ef0075bd.js; FPTOKEN=zLc3s/mq2pguVT/CfivS7tOMcBA63ZrOyecsnTPMLcC/fBEIx0PuIlU5HgkDa8ETJkZYoDJOSFkTHaz1w8sSFlmsRLKFG8s+GO+kqSXuTBgG98q9LQ+EJfeSHMvwMcXHd+EzQzhAxj1L9EnJuEV2pN0w7jUCYmfORSbIqRtu5kruBMV58TagSkmIywEluK5JC6FnxCXUO0ErYyN/7awzxZqyqrFaOaVWZZbYUrhCFq0N8OQ1NMPDvUNvXNDjDOLM6AU9f+eHsXFeAaE9QunHk6DLbxOb8xHIDot4Pau4MNllrBv8cHFtm2U3PHX4f6HFkEpfZXB0yVrzbX1+oGoscbt+195MLZu478g3IFYqkrB8b42ILL4iPHtj6M/MUbPcxoD25cMZiDI1R0TSYNmRIA==|U8iJ37fGc7sL3FohNPBpgau0+kHrBi2OlH2bHfhFOPQ=|10|87db5f81d4152bd8bebb5007a0f3dbc3; c_channel=0; c_csc=web; accessToken=avatarUrl%3Dhttps%253A%252F%252Fcdn.static.17k.com%252Fuser%252Favatar%252F03%252F43%252F75%252F100257543.jpg-88x88%253Fv%253D1685860834000%26id%3D100257543%26nickname%3D%25E8%2580%2581%25E5%25A4%25A7%25E5%2592%258C%25E5%258F%258D%25E5%25AF%25B9%25E6%25B3%2595%25E7%259A%2584%25E5%258F%258D%26e%3D1701413546%26s%3Db67793dfa5cea859; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22100257543%22%2C%22%24device_id%22%3A%221883d51d52d1790-08af8c489ac963-26031a51-1638720-1883d51d52eea0%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E8%87%AA%E7%84%B6%E6%90%9C%E7%B4%A2%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22https%3A%2F%2Fwww.baidu.com%2Flink%22%2C%22%24latest_referrer_host%22%3A%22www.baidu.com%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC%22%7D%2C%22first_id%22%3A%22f0f80f5e-fb00-443f-a6be-38c6ce3d4c61%22%7D; Hm_lpvt_9793f42b498361373512340937deb2a0=1685861547"
# yield scrapy.Request(
# url=self.start_urls[0],
# callback=self.parse,
# cookies={lis.split("=")[0]:lis.split("=")[1] for lis in cook.split(";")}
# )
#
# def parse(self, response):
# # print(response.text)
# # yield scrapy.Request(url="https://user.17k.com/www/bookshelf/",callback=self.parse_url)
# pass
# def parse_url(self,response):
#
# # print(response.text)
# pass
#发送post请求
def parse(self, response):
data={
"loginName": "15278307585",
"password": "wasd1234"
}
yield scrapy.FormRequest(
url="https://passport.17k.com/ck/user/login",
callback=self.prase_url,
formdata=data
)
#适用于该页面有form表单
# yield scrapy.FormRequest.from_response(response,formdata=data,callback=self.start_urls)
def prase_url(self,response):
print(response.text)除了这些还可以通过下载中间件返回respose对象来
from scrapy import signals
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
import time
from scrapy.http.response.html import HtmlResponse
lass MyaaacookieMiddleware:
def process_request(self, request, spider):
# 创建一个浏览器
driver=webdriver.Chrome()
# 打开浏览器
driver.get("https://juejin.cn/")
driver.implicitly_wait(3)
# js语句下拉
for i in range(3):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight)")
time.sleep(3)
html=driver.page_source
return HtmlResponse(url=driver.current_url,body=html,request=request,encoding="utf-8")以上就是这些内容了.
总结
scrapy框架就是为了解决我们爬取许多数据而造成大量的代码重写,通过少数代码解决问题