【JavaScript 逆向】AST 技术反混淆
前言
通过浏览器工具可以清楚的看到网站正在运行的 HTML 和 JavaScript 代码,所以对 JavaScript 代码进行混淆处理是一些网站常用的反爬措施,例如下文介绍到的字符串混淆、控制流平坦化等,这使得 JavaScript 的可读性变得很差,难以进行分析,断点调试、Hook 操作本质上还是在已经混淆的代码上进行操作,代码可读性仍然较差,而通过 AST 技术可以对混淆后的 JavaScript 代码进行还原重组,并可以对其进行一些例如增、删的操作,使代码可读性大大提高,逻辑更为直观。
Hook 相关可参考:https://blog.csdn.net/Yy_Rose/article/details/124216720
JavaScript 常见混淆技术类型
-
变量混淆:将带有含义的变量名、方法名、常量名随机变为无意义的类乱码字符串,降低代码可读性,如转成单个字符或十六进制字符串
-
字符串混淆:将字符串阵列化集中放置、并可进行 MD5 或 Base64 加密存储,使代码中不出现明文字符串,这样可以避免使用全局搜索字符串的方式定位到入口点
-
属性加密:针对 JavaScript 对象的属性进行加密转化,隐藏代码之间的调用关系
-
控制流平坦化:打乱函数原有代码执行流程及函数调用关系,使代码逻变得混乱无序
-
无用代码注入:随机在代码中插入不会被执行到的无用代码,进一步使代码看起来更加混乱
-
调试保护:基于调试器特性,对当前运行环境进行检验,加入一些强制调试 debugger 语句,使其在调试模式下难以顺利执行 JavaScript 代码
-
多态变异:使 JavaScript 代码每次被调用时,将代码自身即立刻自动发生变异,变化为与之前完全不同的代码,即功能完全不变,只是代码形式变异,以此杜绝代码被动态分析调试
-
锁定域名:使 JavaScript 代码只能在指定域名下执行
-
反格式化:如果对 JavaScript 代码进行格式化,则无法执行,导致浏览器假死
-
特殊编码:将 JavaScript 完全编码为人不可读的代码,如表情符号、特殊表示内容等等
以上内容转自:https://cuiqingcai.com/2022111.html
JavaScript 混淆之 javascript-obfuscator 库
JavaScript 混淆可以通过 javascript-obfuscator 库实现,这里简单介绍一下它的效果:
下载方法
- 1. cmd 中 npm 命令(Node.js 12.x 及以上版本):
npm i -D javascript-obfuscator
- 2. javascript-obfuscator 官方网站进行混淆调试:
https://obfuscator.io/

- 3. 下载 javascript-obfuscator 客户端
http://stunnix.com/prod/jo/#download
使用
运行环境:VS Code
// code: 需混淆的代码
const code = `var strings = 'hello world'`;
// 混淆选项
const options = {
// compact 为代码压缩,定义为 true 则 JavaScript 代码被压缩为一行
compact: true,
// 控制流平坦化
controlFlowFlattening: true,
// mangled: 将变量名替换成普通字符(代码体积更小)
// hexadecimal: 将变量名替换成十六进制形式字符串(可读性更低)
indentifierNamesGenerator: 'hexadecimal'
}
// CommonJS 规范,使用 require 引入模块
const obfuscator = require('javascript-obfuscator');
function obfuscate(code, options) {
return obfuscator.obfuscate(code, options).getObfuscatedCode();
}
console.log(obfuscate(code, options));混淆后输出:
var _0x568f1c=_0x5a9b;(function(_0x26e1ef,_0xbea53e){var _0x5afade=_0x5a9b,_0x57e8d8=_0x26e1ef();while(!![]){try{var _0x32fd38=-parseInt(_0x5afade(0x138))/0x1*(-parseInt(_0x5afade(0x140))/0x2)+-parseInt(_0x5afade(0x13d))/0x3*(-parseInt(_0x5afade(0x135))/0x4)+-parseInt(_0x5afade(0x13c))/0x5+-parseInt(_0x5afade(0x139))/0x6*(-parseInt(_0x5afade(0x13a))/0x7)+-parseInt(_0x5afade(0x13b))/0x8*(-parseInt(_0x5afade(0x136))/0x9)+parseInt(_0x5afade(0x137))/0xa+parseInt(_0x5afade(0x13e))/0xb*(-parseInt(_0x5afade(0x141))/0xc);if(_0x32fd38===_0xbea53e)break;else _0x57e8d8['push'](_0x57e8d8['shift']());}catch(_0x3d50a8){_0x57e8d8['push'](_0x57e8d8['shift']());}}}(_0x4748,0xc3023));var strings=_0x568f1c(0x13f);function _0x5a9b(_0x3b7f6d,_0x402a40){var _0x4748ee=_0x4748();return _0x5a9b=function(_0x5a9bb2,_0x15cece){_0x5a9bb2=_0x5a9bb2-0x135;var _0x373874=_0x4748ee[_0x5a9bb2];return _0x373874;},_0x5a9b(_0x3b7f6d,_0x402a40);}function _0x4748(){var _0x31c6b2=['38868yMPUcr','1673TJovNb','1922024Qbpjvs','6720795uMizEi','3891552BuIzIu','1331MexiPi','hello\x20world','525418bbEjUG','345444rYInsB','4UczQom','45JOmBnd','2659050olEXdt','5PjqoQK'];_0x4748=function(){return _0x31c6b2;};return _0x4748();}更多选项参数可参考:https://blog.csdn.net/aqi22221/article/details/116975879
AST 技术简介
AST(Abstract Syntax Tree),译为抽象语法树,是编译原理中的一个概念,为源代码的抽象语法结构的树状表示,树上的每个节点都表示源代码中的一种结构,这种数据结构可以类别为一个大的 JSON 对象。通过 AST 技术,我们面对的就不再是各种符号混杂空格而成的文本字符串,而是一个严谨规范的树形结构,我们可以通过对 AST 树节点的一系列操作,借助机器高效且精准地修改代码。
通过 AST 解析网站:https://astexplorer.net/,左侧为我们要输入的 JavaScript 代码,右侧为 AST 树状结构:
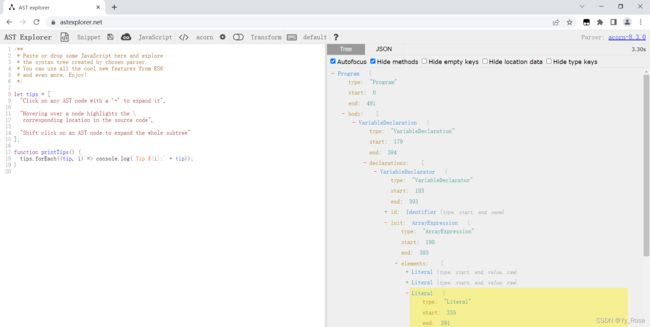
输入一段简单的 JavaScript 代码,通过观察,便于我们对 AST 结构进行理解:
const a = 1;
let string = 'Yy_';
for (let i = 0; i < a; i++) {
string += 'Rose';
}
// console.log(string);
// Yy_Rose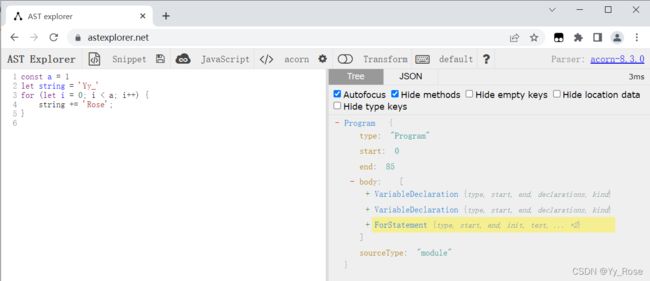
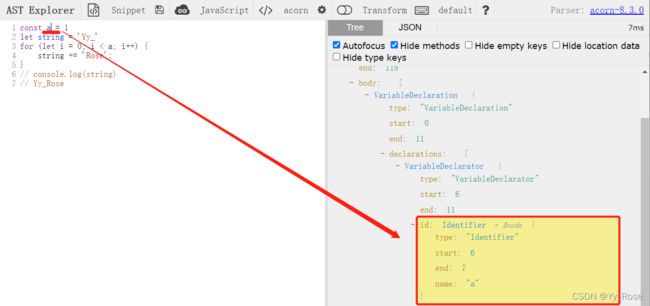
例如此时鼠标点击到 a 的位置,就可以从页面右侧观察到,a 被解析成一个 type 为 Identifier 的数据结构,name 属性代表 Identifier 的名称为 a,start 和 end 表示为起始和终止位置,其他同理:
图解结构(层层嵌套的 AST ):
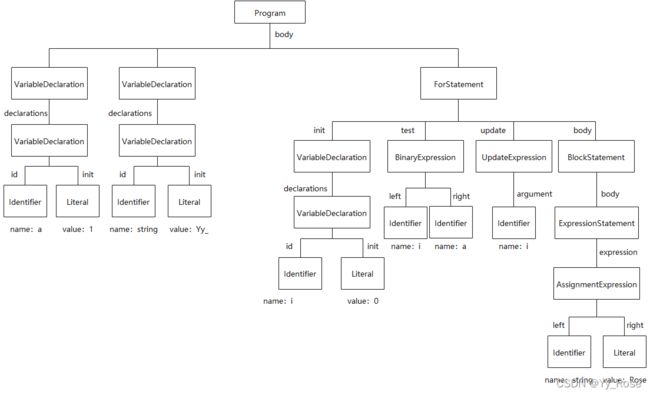
节点类型含义:
- Program:程序,即整段代码
- Declarations:声明,如上图 VariableDeclaration(变量声明)
- Identifier:标识符,指变量名称,例如 a
- Literal:字面量,如上述 1、0、Yy_、Rose
- Statements:语句,如上述代表 for 循环语句的 ForStatement,{...} 中内容为 BlockStatement 类型,即代码块语句,表示一些控制语句或特殊语句
- Expression:表达式,它本身会返回一个计算结果,作用为放在赋值语句的右边进行赋值或作为方法的参数,例如上述 BinaryExpression 为逻辑表达式,代表进行逻辑运算;UpdateExpression 于 i++ 处,即更新逻辑表达式的值;AssignmentExpression 为赋值表达式,将 Rose 赋值给 Yy_ 从而生成字符串 Yy_Rose
综上所述结合编译原理可了解,代码执行前经历了三个步骤:
- 词法分析:代码被分解成一个个的词法单元,const a = 1,即被分解成 const、a、=、1
- 语法分析:编译器对词法单元进行语法分析,将其转换成能代表程序语法结构的数据结构,如 const 被分析为 VariableDeclaration 类型,即声明变量
- 指令生成:将语法树转换成可执行的指令并执行
更多相关资料可参考:https://babeljs.io/docs/en/babel-types
AST 在前端中的运行非常广泛,例如 webpack 中对代码进行压缩混淆反爬方法的底层就运用到了 AST 技术,而我们也可以通过 Babel 在 Node.js 中的一些包对 AST进行转换:
- @babel/parser:Babel 中的 JavaScript 解析器,提供两个方法 parse(支持解析一段 JavaScript 代码 → 输入 JavaScript 代码,输出对应的 AST )和 parseExpression(解析单个 JavaScript 表达式并考虑性能问题)
- @babel/generate:提供 generate 方法将 AST 对象还原成 JavaScript 代码
- @babel/traverse:接收 AST 利用 traverse 方法遍历其中所有节点,于遍历方法中对每个节点做响应的操作
- @babel/types:声明新节点
Node.js 中文文档:http://nodejs.cn/
Babel 官方文档:https://babeljs.io/docs/en/
Babel 中文文档:https://www.wenjiangs.com/doc/babel-babel-traverse
还原混淆代码
表达式还原
混淆前的代码:
const a = true;
const b = false;
const c = 10;
const d = parseInt("50");混淆后的代码(简单表达式复杂化),创建 codes.js 文件输入:
const a = !![];
const b = "abc" == "bcd";
const c = (1 << 3) || 2;
const d = parseInt("5" + "0");混淆代码还原:
import { parse } from "@babel/parser";
import traverse from "@babel/traverse";
import generate from "@babel/generator";
import * as types from "@babel/types";
import fs from "fs"; // 文件系统管理模块,可对文件进行读写操作
// readFileSync 同步读取文件,不接收回调函数,直接返回函数结果
const code = fs.readFileSync("codes.js", "utf-8");
// parse 方法将文件内容转换为 AST
let ast = parse(code);
// traverse 遍历 ast 所有节点,并进行对应操作
traverse(ast, {
// 一元表达式、布尔表达式、条件表达式、调用表达式
"UnaryExpression|BinaryExpression|ConditionalExpression|CallExpression": (
path
) => {
// evaluate 执行 path 对象返回计算结果
const { confident, value } = path.evaluate();
// Infinity 正无穷
if (value == Infinity || value == -Infinity) return;
// 若 confident 为 true,则替换执行结果 value 的值
confident && path.replaceWith(types.valueToNode(value));
},
});
// generate 将 ast 转换为 JavaScript 代码
const { code: output } = generate(ast);
console.log(output);以上几种表达式以键名的形式表示,若 path 对象类型符合以上几种表达式,就会执行回调方法,confident 为可信度
return 语句会 终止函数的执行 并 返回函数的值:
- retrun true; 返回正确的处理结果
- return false;返回错误的处理结果以及阻止代码继续向下执行
- return;终止函数的执行
- return; return false; return true; 在函数内部都中断了程序的执行
若报错:Warning: To load an ES module, set “type“: “module“ in the package.json or use the .mjs extension.

需要在项目文件夹下的 packages.json 文件中添加 “type“: “module“ 即可:

字符串还原
混淆前的代码:
const strings = [hello, world];混淆后的代码(字符串被转换成 UTF-8 编码),创建 codes2.js 文件输入:
const strings = ["\x68\x65\x6c\x6c\x6f", "\x77\x6f\x72\x6c\x64"];混淆代码还原:
通过解析网站:https://astexplorer.net/,输入以上混淆后的代码,可以得到 AST 数据结构:
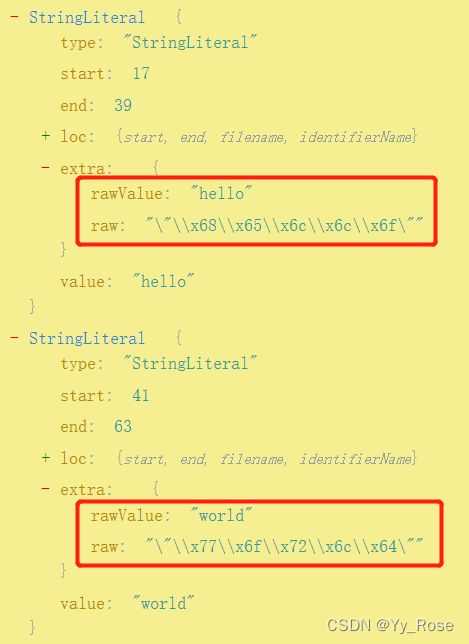
经以上 AST 数据结构可以观察到:混淆后的字符串被解析成了 StringLiteral 类型,在它的 extra 属性节点下有两个值,rawValue 表示原来的真实字符串值,raw 则表示经过混淆后的字符串值,所以将二者的值进行替换即可得到真实的数据值:
import traverse from "@babel/traverse";
import { parse } from "@babel/parser";
import generate from "@babel/generator";
import fs from "fs";
const code = fs.readFileSync("code2.js", "utf-8");
let ast = parse(code);
traverse(ast, {
// 声明 StringLiteral 方法,node 为节点信息
StringLiteral({ node }) {
// 正则表达式,匹配混淆后的字符串,再用混淆前的进行替换,获取正确字符串
// JavaScript 正则表达式结构为 / pattern / flags
if (node.extra && /\\[ux]/gi.test(node.extra.raw)) {
// 将 extra 节点下的 raw 值替换为真实值 rawValue
node.extra.raw = node.extra.rawValue;
}
},
});
// generate 将 ast 转换为 JavaScript 代码
const { code: output } = generate(ast);
console.log(output);gi.test 解析:
每个正则表达式都可带有一或多个标志(flags),用以标明正则表达式的行为,正则表达式支持下列 3 个标志:
- g: 表示全局(global)模式,即模式将被应用于所有字符串,而非在发现第一个匹配项时立即停止
- i : 表示不区分大小写(case-insensitive)模式,即在确定匹配项时忽略模式与字符串的大小写
- m:表示多行(multiline)模式,即在到达一行文本末尾时还会继续查找下一行中是否存在与模式匹配的项
test 用来检测字符串是否匹配某一个正则表达式,如果匹配就会返回 true ,否则返回 false
JavaScript 正则表达式结构为 / pattern / flags
正则表达式相关内容可参考:
https://blog.csdn.net/Yy_Rose/article/details/122139645
https://www.cnblogs.com/onepixel/p/5218904.html
无用代码删除
混淆前的代码:
const _0x16c18d = function () {
console.log("hello world");
};
const _0x1f7292 = function () {
console.log("nice to meet you");
};
_0x16c18d();
_0x1f7292();混淆后的代码:
const _0x16c18d = function () {
// [[]] 为二维数组,是非空对象,故判断条件值为 true
if (!![[]]) {
console.log("hello world");
} else {
// 混淆用的冗余语句
console.log("this");
console.log("is");
}
};
const _0x1f7292 = function () {
// n !== n(110 经过 ASCII 码转换后值为 n),故表达式值为 false
if ("xmv2nOdfy2N".charAt(4) !== String.fromCharCode(110)) {
console.log("this");
console.log("is");
} else {
console.log("nice to meet you");
}
};
_0x16c18d();
_0x1f7292();!![[]] 值为 true,"xmv2nOdfy2N".charAt(4) !== String.fromCharCode(110) 值为 false,所以第一个方法只执行 if 区块对应的语句,即 console.log("hello world"); 第二个方法只执行 else 区块对应的语句 console.log("nice to meet you"),输出结果没问题,但是其他代码是冗余的,造成了分析上的干扰。
混淆代码还原:

通过分析网站获取到的 AST 数据结构可以知道,if ... else ... 语句对应的 AST 节点为 IfStatement,其下 test 节点为 if 判定语句,consequent 节点为对应的代码块,alternate 节点为 else 对应的代码块:
import traverse from "@babel/traverse";
import { parse } from "@babel/parser";
import generate from "@babel/generator";
import * as types from "@babel/types";
import fs from "fs";
const code = fs.readFileSync("code3.js", "utf-8");
let ast = parse(code);
traverse(ast, {
IfStatement(path) {
// 节点属性为 consequent, alternate
let { consequent, alternate } = path.node;
// 获取 test 属性对应的 path
let testPath = path.get("test");
// evaluateTruthy 执行返回 path 的真实值
// 若判定语句值为 true,则 evaluateTruthy 为true
const evaluateTest = testPath.evaluateTruthy();
console.log("evaluateTest", evaluateTest);
if (evaluateTest === true) {
if (types.isBlockStatement(consequent)) {
// consequent.body 对应 console.log("hello world"); 语句
consequent = consequent.body;
}
// path.replaceWith 为遍历整个替换
// replaceWithMultiple 多路径替换 path
path.replaceWithMultiple(consequent);
} else if (evaluateTest === false) {
if (alternate != null) {
if (types.isBlockStatement(alternate)) {
// alternate.body 对应 console.log("nice to meet you"); 语句
alternate = alternate.body;
}
path.replaceWithMultiple(alternate);
} else {
path.remove();
}
}
}
});
const { code: output } = generate(ast);
console.log(output);下部分代码意思为,若混淆代码中的 if 后判断条件为 true 则遍历节点整个替换为 if 后的语句块内容,若判断条件为 false 则遍历节点整个替换为 else 后的语句块内容。
反控制流平坦化
控制流平坦化为打乱函数原有代码执行流程及函数调用关系,使代码逻变得混乱无序,例如:
混淆的代码:
const s = "3|1|2".split("|");
let x = 0;
while (true) {
switch (s[x++]) {
case "1":
const a = 1;
continue;
case "2":
const b = 3;
continue;
case "3":
const c = 0;
continue;
}
break;
}字符串切割后为 [“3”,“1”,“2”],所以 s[0] = “3”, s[1] = “1”,s[2] = “2”,switch 语句中的执行顺序就为 3、1、2,即:
const c = 0;
const a = 1;
const b = 3;
混淆代码还原:
还原基本过程:
- 找到 switch 语句在 AST 中的相关节点
- 分析 switch 语句判定条件对应的列表结果
- 遍历对应的列表,将其与 case 语句进行匹配,得到对应的代码区块
- 替换代码

由上图可知,swicth 语句对应 switchStatement 节点,其下节点 discrimination、cases 节点分别对应代码的 s[x++] 语句和 case 语句,三个 case 语句分别对应三个 SwitchCase 节点内容:
import traverse from "@babel/traverse";
import { parse } from "@babel/parser";
import generate from "@babel/generator";
import * as types from "@babel/types";
import fs from "fs";
const code = fs.readFileSync("code4.js", "utf-8");
let ast = parse(code);
// 将 JavaScript 代码转换成 AST 数据结构,获取节点属性
traverse(ast, {
WhileStatement(path) {
// 变量的解析结构赋值(ES6)
// const node = path.node;
// const scope = path.scope;
const { node, scope } = path;
const { test, body } = node;
if (!types.isLiteral(test, { value: true })) return;
if (body.body.length != 2) return;
// SwitchStatement 节点
let switchNode = body.body[0],
// BreakStatement 节点
breakNode = body.body[1];
if (
!types.isSwitchStatement(switchNode) ||
!types.isBreakStatement(breakNode)
) {
// 若满足上述任一条件即于函数内部终止函数执行
return;
}
let { discriminant, cases } = switchNode;
if (!types.isMemberExpression(discriminant)) return;
let { object, property } = discriminant;
if (!types.isIdentifier(object) || !types.isUpdateExpression(property))
return;
// 获取 object 节点的 name 属性,即 "s"
let arrName = object.name;
// 获取 s 绑定节点的原始定义:"3|1|2".split("|");
let binding = scope.getBinding(arrName);
if (!binding || !binding.path || !binding.path.isVariableDeclarator())
return;
let { init } = binding.path.node;
if (
!types.isCallExpression(init) ||
!types.isMemberExpression(init.callee) ||
!init.arguments.length > 0
) {
return;
}
// 获取声明表达式对应节点
// init:"3|1|2".split("|");
// callee:"3|1|2".split
// object:"3|1|2"
// property:split
object = init.callee.object;
property = init.callee.property;
// "|"
let argument = init.arguments[0].value;
if (!types.isStringLiteral(object) || !types.isIdentifier(property)) {
return;
}
// arrayFlow:表达式运算结果 → ["3", "1", "2"]
let arrayFlow = object.value[property.name](argument);
// 用于保存匹配到的 case 代码
let resultBody = [];
// 遍历结果列表
arrayFlow.forEach((index) => {
// switchCase 节点,匹配 case 语句
let switchCases = cases.filter(
(switchCase) => switchCase.test.value == index
);
// 解释器在访问尚未初始化的变量或对象属性时返回 undefined,没给变量赋值时默认值为 undefined
// 若 switchCases 节点数量大于 0 返回第一个节点值
let switchCase = switchCases.length > 0 ? switchCases[0] : undefined;
if (!switchCase) {
return;
}
// case 语句代码块
let caseBody = switchCase.consequent;
// 移除 case 语句块中的 continue 语句
if (types.isContinueStatement(caseBody[caseBody.length - 1])) {
caseBody.pop();
}
resultBody = resultBody.concat(caseBody);
});
// 将最外层 path 替换为 resultBody 内容
path.replaceWithMultiple(resultBody);
},
});
const { code: output } = generate(ast);
console.log(output);代码来源:https://github.com/Python3WebSpider/Deobfuscate
总结
以上是对 JavaScript 逆向相关知识 AST 技术反混淆的学习总结,如有见解欢迎评论区或私信指正交流~
参考资料:
https://blog.csdn.net/terrychinaz/article/details/112552669
https://github.com/Python3WebSpider/Deobfuscate
https://cuiqingcai.com/17777.html
https://blog.csdn.net/kaimo313/article/details/115477560
https://www.cnblogs.com/onepixel/p/5218904.html
https://wangdoc.com/es6/destructuring.html
https://blog.csdn.net/weixin_48193717/article/details/119982120