Linux 多线程
Linux 多线程
- 前言
- 线程
-
- 概念
- 优点
- 缺点
- 异常
- 进程VS线程
-
- 线程创建
- 线程终止
-
- 线程取消
- 线程分离
-
- 线程库
- 模拟实现创建线程
- 线程互斥
-
- 线程间的互斥相关概念
- 互斥量mutex
- 常见锁的概念
-
- 死锁
- Linux线程同步
-
- 条件变量
- 生产者消费模型
-
- 概念
- 基于阻塞队列的生产消费模型
- POSIX信号量
-
- 概念
- 基于环形队列的生产消费模型
- 线程池
前言
进一步理解地址空间和页表
- 地址空间是进程能看到的资源窗口
- 页表决定进程真正能拥有的资源
- 合理地对地址空间和页表进行资源划分,就可以对一个进程的所有资源分类
页表的结构:
页表中的每一行都是一个结构体,保存着相应的属性;再通过某种数据结构连接在一起
虚拟地址空间的地址有2^32个,页表如果也是
2^32个,就需要相当大的空间;因此,页表的结构并非如此

虚拟地址以10,10,12个比特位分为三份;第一份作为页目录,第二份作为页表,第三分作为偏移量
物理空间按照4KB的大小进行划分,通过结构体struct Page进行描述,再通过某种数据结构进行组织,每一份物理空间称作页框;在之前的学习中磁盘中的程序每次同样是以4KB的大小加载到物理空间的
读取文件信息时,进程先通过虚拟地址的前10位找到对应的页目录,再通过后10位找到对应的页表,通过页表中的地址找到物理空间中页框的起始地址,加上12位的偏移量,读取对应的数据
线程
概念
线程是进程内的一个执行流
我们知道在创建子进程时,只会创建子进程的进程控制块,父进程将自己资源的一部分直接给子进程,比如虚拟地址空间中的代码段和页表;现在有一个想法,就是类似创建子进程一样,给某一个进程创建多个进程控制块,同时指向同一个虚拟地址空间,共用一个页表
图解:

将进程的代码区分为多份,同时创建多个进程控制块指向同一虚拟地址;这些进程控制块分配着不同的系统资源,承担着不同的任务;通过虚拟地址空间+页表的方式对进程进行资源划分,使得单个进程的执行力度一定比之前的进程更细
这里多创建的进程其实就是线程,在Linux中由于线程和进程有许多重叠处,所以直接复用进程控制块来表示线程;线程是CPU调度的基本单位
有了线程之后,再一次解释什么是进程:承担分配系统资源的基本实体;之前的进程也是承担系统资源的基本实体,只不过内部只有一个执行流,这里的进程内部可以有多个执行流
线程在进程内部运行,线程在进程的虚拟地址空间内运行,拥有该进程的一部分资源
- Linux内核中没有真正意义上的线程,是使用进程控制块进行模拟的
- 在CPU角度,每个进程控制块都可以称之为轻量级进程
- Linux线程是CPU调度的基本单位;进程是承担分配系统资源的基本单位
- 进程用来申请资源,线程向进程索要资源
- 线程的好处:简单,维护成本降低
为了理解线程和进程的关系,举个栗子
在家庭中每个成员就是一个线程,整个大家庭便是一个进程;每个成员所承担的责任都不同,但都有一个目的:朝着大家庭和睦的方向发展
代码实现来证明线程
先介绍创建线程函数
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,void *(*start_routine) (void *), void *arg);
pthread_t *thread:输出型参数,线程idpthread_attr_t *attr:线程属性,默认为空void *(*start_routine) (void *):函数指针;当线程创建完毕之后,让其去执行这个函数void *arg:填入函数指针中的参数
mysignal:mysignal.cpp
g++ -o $@ $^ -lpthread -std=c++11
.PHONY:clean
clean:
rm -f mysignal
由于操作系统只认识线程,用户也只认识线程;Linux没有提供创建线程的系统调用接口,只提供了创建轻量级进程的接口;在任何Linux操作系统中都有用户级线程库,在两者之间,线程库向上提供创建线程的接口,向下把对库进行的操作转化成对轻量级进程的操作;所以在创建线程时,需要链接上线程库

#include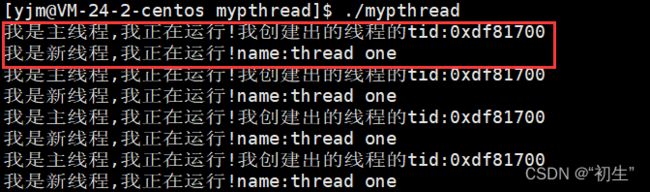
运行结果也证实了,存在两个执行流;线程id的结果貌似是个地址,这里先保留个疑问后面会进行揭晓
查看两执行流的相关信息
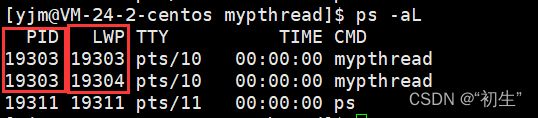
两线程拥有同一个进程id;LWP代表light weight process轻量级进程,两线程的LWP不同,所以CPU调度时,是以LWP为标识符表示特定的执行流
优点
- 创建一个新线程比创建一个进程代价要小的多
- 线程间切换需要操作系统做的工作少很多:切换PCB和上下文切换;线程切换高速缓存
cache不用全部更新,进程切换高速缓存cache全部更新 - 线程占用的资源比进程少很多
- 线程一旦被创建,所有资源都被线程共享
缺点
健壮性降低
#include
当进程中某一个线程出现异常,进程收到系统的信号进行资源回收时,所有的线程都会退出;进程是承担系统资源的实体,资源都被回收,进程中全部的线程也就会退出
异常
线程是进程的执行分支,线程出现异常,会触发信号机制,终止进程,该进程中的所有线程也随之退出
进程VS线程
线程创建
上面已经展示过如何创建一个线程,这里尝试创建一批线程
void *start_routine(void *args)
{
string name=(const char*)args;
while(true)
{
sleep(1);
cout<<"我是新线程,我正在运行!name:"<<name<<endl;
}
}
int main()
{
#define NUM 10
for(int i=0;i<NUM;i++)
{
pthread_t tid;
char namebuffer[64];
snprintf(namebuffer,sizeof(namebuffer),"%s:%d","thread",i);
pthread_create(&tid,nullptr,start_routine,namebuffer);
}
while(true)
{
sleep(1);
cout<<"我是主线程,我正在运行!"<<endl;
}
return 0;
}

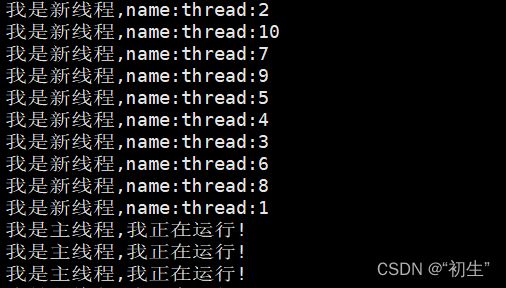
与进程一样,创建线程时,谁先运行是不确定的;而且创建线程时,将缓冲区 namebuffer的起始地址传给函数 start_routine,每次创建线程,都会刷新缓冲区,结果就导致,线程的编号全都是一样的
进行改进,使得每个线程都拥有自己的缓冲区和编号
class ThreadData
{
public:
int number;
pthread_t tid;
char namebuffer[64];
};
void *start_routine(void *args)
{
ThreadData*td=(ThreadData*)args;
while(true)
{
sleep(1);
cout<<"我是新线程,name:"<<td->namebuffer<<endl;
}
}
int main()
{
#define NUM 10
for(int i=0;i<NUM;i++)
{
ThreadData*td=new ThreadData();
td->number=i+1;
char namebuffer[64];
snprintf(td->namebuffer,sizeof(td->namebuffer),"%s:%d","thread",td->number);
pthread_create(&td->tid,nullptr,start_routine,td);
}
while(true)
{
sleep(1);
cout<<"我是主线程,我正在运行!"<<endl;
}
return 0;
}
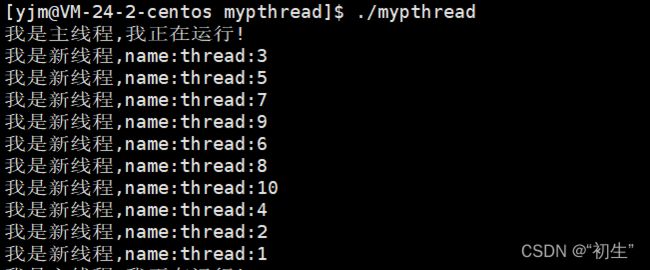
运行结果也证实了,线程运行的先后是不确定的
当创建10个线程之后,此时的函数start_routine是被10个线程都是执行的,也就是说此时的函数是可重入状态;如果再向函数中添加一个变量,打印其地址结果是否是不一样的呢???
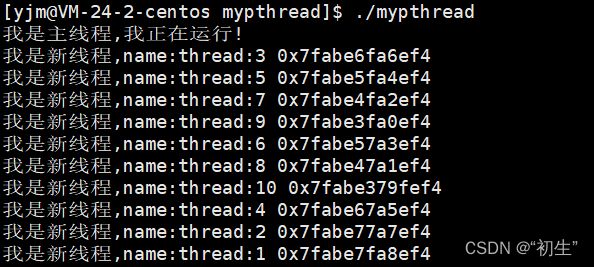
结果与预期是一致的,在函数内部定义的变量具有临时性,也就是证实了每一个线程都有自己独立的栈结构
线程终止
进程退出有两种方式:return nullptr;void pthread_exit(void *retval);参数默认是空
void *start_routine(void *args)
{
ThreadData*td=(ThreadData*)args;
int cnt=10;
while(cnt)
{
sleep(1);
cnt--;
cout<<"我是新线程,name:"<<td->namebuffer<<endl;
}
pthread_exit(nullptr);
}
线程退出时,是将所有新建线程退出,只剩余主线程;其实线程和进程一样,退出之后也是要进行等待资源回收的
int pthread_join(pthread_t thread, void **retval);
回收线程资源时,需要将线程的id传入第一个参数中,后一个参数先设置为空
int main()
{
vector<ThreadData*> threads;
#define NUM 10
for(int i=0;i<NUM;i++)
{
ThreadData*td=new ThreadData();
td->number=i+1;
char namebuffer[64];
snprintf(td->namebuffer,sizeof(td->namebuffer),"%s:%d","thread",td->number);
pthread_create(&td->tid,nullptr,start_routine,td);
threads.push_back(td);
}
for(auto& e:threads)
{
int n=pthread_join(e->tid,nullptr);
assert(n==0);
cout<<"join "<<e->namebuffer<<endl;
}
cout<<"main thread quit"<<endl;
return 0;
}

线程退出时返回的参数是 void*,退出函数pthread_exit(nullptr)的参数和线程等待的函数pthread_join( ,nullptr)的第二个参数也相同,并且前一个参数的类型是一级指针,后者的参数类型是二级指针,这其中是不是有什么关联呢???

退出函数将退出信息保存至void* retval进行返回,等待函数对退出信息进行取址void** retval,获取退出信息并进行打印;在主线程中可以设置一个void*变量将退出信息写到该变量中
for(auto& e:threads)
{
void*ret=nullptr;
int n=pthread_join(e->tid,&ret);
assert(n==0);
cout<<"join "<<e->namebuffer<<" "<<(long long)ret<<endl;
}
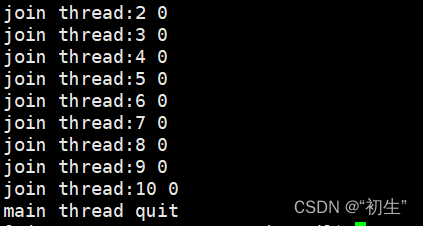
0代表线程正常退出;线程退出时没有对应的信号,pthread_join默认会调用成功,如果失败,整个进程直接退出
线程取消
线程取消也是线程终止的一种方法;线程要被取消,前提是该线程已经运行起来,通过线程取消函数,将正在运行的线程取消,观察其返回结果
int pthread_cancel(pthread_t thread);
for(int i=0;i<threads.size()/2;i++)
{
pthread_cancel(threads[i]->tid);
cout<<"pthread cancel :"<<threads[i]->namebuffer<<"success"<<endl;
}
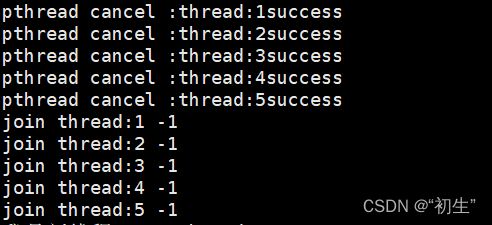
线程如果被取消,线程退出的结果是-1
线程分离
默认情况下,新创建的线程是可等待的,线程退出后,需要对其进行等待操作,否则无法释放资源,从而造成系统泄漏;如果不关心线程的返回值,等待就变成了一种负担,所以可以在线程退出时,告知系统自动释放线程资源,也就是线程分离;线程分离之后,不能进行等待,否则会报错
线程分离函数:
int pthread_detach(pthread_t thread);
获取待分离线程自己的线程id
pthread_t pthread_self(void);
代码展示
由于新线程创建之后,主线程和新线程谁先执行是不确定的,所以最好在新线程执行之后再进行线程分离
string changeid(const pthread_t& thread_id)
{
char tid[64];
snprintf(tid,sizeof(tid),"0x%x",thread_id);
return tid;
}
void* start_routine(void* args)
{
string threadname=(const char*)args;
int cnt=3;
while(cnt--)
{
cout<<threadname<<"running ..."<<changeid(pthread_self())<<endl;
sleep(2);
}
return nullptr;
}
int main()
{
pthread_t tid;
pthread_create(&tid,nullptr,start_routine,(void*)"thread one");
string main_id =changeid(pthread_self());
pthread_detach(tid);
cout<<"mian thread running ... new thread id "<<changeid(tid)<<"main thread id "<<main_id<<endl;
int n=pthread_join(tid,nullptr);
cout<<"result "<<n<<strerror(n)<<endl;
return 0;
}

由于线程已经进行了分离,再次进行等待编译器进行报错
线程库
在程序员或者用户的角度,只认识线程,在Linux中并没有创建线程的接口,只有轻量级进程;线程库的存在能够解决这个问题
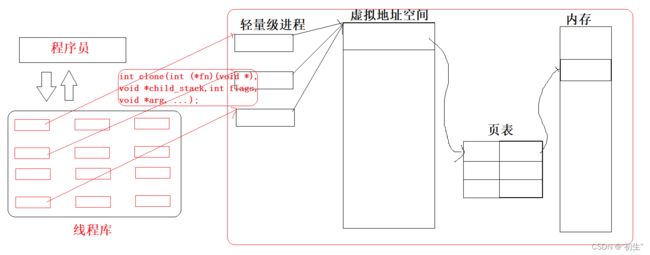
首先,线程库会被不同的用户使用,其中肯定存在着许多的线程,这时便需要进程管理:先描述,再组织;在库中创建线程控制块存储线程的必要属性;线程控制块调用创建轻量级进程的接口,在操作系统中创建对应的轻量级进程,从而以轻量级进程来代替模拟线程

在虚拟地址空间中,存在着 mmp区域其中包含动态库,线程库也在其中;上面介绍到:线程库中存在着线程控制块,也就是结构体,结构体的起始地址就是线程id,线程栈也解释了为什么线程都有自己的私有栈;可通过添加__thread将内置类型数据设置为局部存储
模拟实现创建线程
class Thread;
class Context
{
public:
Thread* _this;
void* _args;
public:
Context()
:_this(nullptr)
,_args(nullptr)
{}
~Context()
{}
};
class Thread
{
public:
typedef function<void*(void*)> func_t;
const int num=1024;
public:
Thread(func_t func,void*args=nullptr,int number=0)
:_func(func)
,_args(args)
{
char buffer[num];
snprintf(buffer,sizeof(buffer),"thread:%d",number);
_name=buffer;
Context* ctx=new Context();
ctx->_this=this;
ctx->_args=_args;
int n=pthread_create(&_tid,nullptr,start_routine,ctx);
assert(n==0);
(void)n;
}
static void* start_routine(void*args)
{
Context* ctx=static_cast<Context*>(args);
void* ret=ctx->_this->run(ctx->_args);
delete ctx;
return ret;
}
void join()
{
int n=pthread_join(_tid,nullptr);
assert(n==0);
(void)n;
}
void* run(void* args)
{
return _func(args);
}
~Thread()
{}
private:
string _name;
func_t _func;
void* _args;
pthread_t _tid;
};
线程互斥
线程间的互斥相关概念
- 临界资源:多线程执行流共享的资源称作临界资源
- 临界区:每个线程内部,访问临界资源的代码
- 互斥:任何时刻,互斥保证有且只有一个执行流进入临界区,访问临界资源,对临界资源起到保护作用
- 原子性:不会被任何调度机制打断的操作,该操作只有两态:要么完成,要么未完成
在没有互斥的情景下,模拟抢票过程
int tickets=1000;
void* getticket(void* args)
{
string username=static_cast<const char*>(args);
while(true)
{
//满足条件才能抢票
if(tickets>0)
{
usleep(1234);
cout<<username<<"正在抢票..."<<tickets<<endl;
tickets--;
}
else{
break;
}
}
}
int main()
{
pthread_t tid1,tid2,tid3,tid4;
pthread_create(&tid1,nullptr,getticket,(void*)"user1");
pthread_create(&tid2,nullptr,getticket,(void*)"user2");
pthread_create(&tid3,nullptr,getticket,(void*)"user3");
pthread_create(&tid4,nullptr,getticket,(void*)"user4");
pthread_join(tid1,nullptr);
pthread_join(tid2,nullptr);
pthread_join(tid3,nullptr);
pthread_join(tid4,nullptr);
return 0;
}

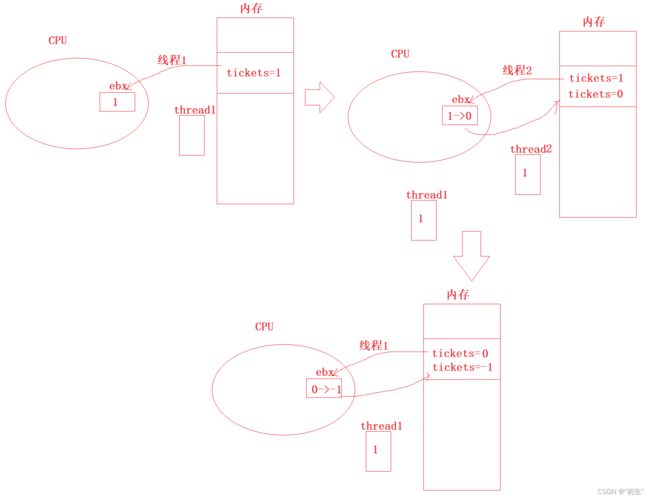
火车票是共享资源,这四个线程交叉执行,频繁地发生调度与切换;当线程从内核态返回用户态时,线程需要对调度状态进行检测,如果可以,直接发现线程切换;由结果来看,对一个全局变量进行多线程更改并不是安全的

正常来说,单线程对全局变量进行修改,分为三个步骤:将变量读取到CPU中的寄存器;进行运算;将运算结果写回内存中
但是,多线程对全局变量进行修改却不是如此;由于更改数据并不是原子性的,会存在某一个线程正在执行时,突然被切换的情况
例如:当 tickets==1,线程1将数据读取到寄存器中,发生线程切换;线程1只能将自身的上下文进行保存;待线程2执行完毕,此时tickets==0,将线程1切回,但是由于线程1所保存的上下文中tickets==1,再次读取数据,进行运算,写回,由此车票的数目就变成了tickets==-1;为了解决这个问题,引入了互斥概念
互斥量mutex
- 大部分情况,线程使用的数据都是局部变量,变量的地址空间在线程栈空间内;这种情景,变量属于单个线程,其他线程无法获得该变量
- 有时,许多变量需要在线程内共享,此变量称作共享变量,可以通过数据共享,完成线程之间的交互
- 多线程并发操作的共享变量,会引发一些问题
互斥量就是锁,使用互斥量可以让线程串行执行,由此了解决上面的问题
锁的使用分为两种:
全局
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
局部,需要先初始化后销毁
int pthread_mutex_init(pthread_mutex_t *restrict mutex,
const pthread_mutexattr_t *restrict attr);
int pthread_mutex_destroy(pthread_mutex_t *mutex);
接下来采取全局定义锁的方式对线程进行上锁,在加锁和解锁之间的代码称为临界区
//锁的定义
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
int tickets=1000;
void* getticket(void* args)
{
string username=static_cast<const char*>(args);
//加锁
pthread_mutex_lock(&lock);
while(true)
{
if(tickets>0)
{
usleep(1234);
cout<<username<<"正在抢票..."<<tickets<<endl;
tickets--;
//解锁
pthread_mutex_unlock(&lock);
}
else{
//解锁
pthread_mutex_unlock(&lock);
break;
}
//抢票成功之后的工作
usleep(1000);
}
}
int main()
{
pthread_t tid1,tid2,tid3,tid4;
pthread_create(&tid1,nullptr,getticket,(void*)"user1");
pthread_create(&tid2,nullptr,getticket,(void*)"user2");
pthread_create(&tid3,nullptr,getticket,(void*)"user3");
pthread_create(&tid4,nullptr,getticket,(void*)"user4");
pthread_join(tid1,nullptr);
pthread_join(tid2,nullptr);
pthread_join(tid3,nullptr);
pthread_join(tid4,nullptr);
return 0;
}

上面的问题完美解决
该如何看待锁呢?
- 首先,加锁的前提是先让线程看到锁,类似全局变量,锁的本质也是共享资源;全局变量由锁来保护,锁由操作系统来保护
- 锁如果申请成功,线程向后执行;如果暂时没有成功,线程会发生阻塞
- 线程持有锁,才能进入临界区
- 当持有锁的线程被切换时,锁也被切换,其他线程是无法申请成功的,直到当前线程的锁被释放
- 加锁解锁的本质也是原子性的
常见锁的概念
死锁
概念
在多把锁的情况下,持有自己的锁,还要索要对方的锁;对方亦是如此便会造成死锁问题
死锁存在的原因:多线程中大部分资源是共享的,多线程访问可能会出现数据不一致的问题,为保证线程安全需要使用锁,由此便出现死锁的问题
死锁的必要条件
- 互斥:一个资源每次只能被一个执行流使用
- 请求与保持:一个执行流因请求资源而阻塞时,对已获得的资源持有不放
- 不剥夺:一个执行流已获得的资源,在未使用完之前,不能强行剥夺
- 循环等待:若干执行流之间形成一种头尾相接的循环等待资源的关系
避免死锁
- 破坏死锁的四个必要条件
- 加锁顺序一致
- 避免锁未释放的场景
- 资源一次性分配
Linux线程同步
条件变量
当一个线程互斥地访问某个变量时,他可能发现在其他线程改变状态之前,自己什么也做不了
举个栗子
在企业招聘时,每个应聘者都被告知自己的号码。当叫号到自己时,就到对应的屋子里去面试,这里的号码就是条件变量,当没有叫到自己时,只能排队等待,只有叫到自己才能去面试
当条件不满足时,线程必须去某些定义好的条件变量进行等待
条件变量函数
全局定义
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
局部定义
int pthread_cond_init(pthread_cond_t *restrict cond,const pthread_condattr_t *restrict attr);
等待条件满足
int pthread_cond_wait(pthread_cond_t *restrict cond,pthread_mutex_t *restrict mutex);
唤醒等待线程
唤醒一个
int pthread_cond_signal(pthread_cond_t *cond);
唤醒一批
int pthread_cond_broadcast(pthread_cond_t *cond);
销毁
int pthread_cond_destroy(pthread_cond_t *cond);
在抢票线程中加入条件变量,先让所有线程等待,间隔几秒后全部唤醒
//票数
int tickets=100;
pthread_mutex_t mutex=PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t cond=PTHREAD_COND_INITIALIZER;
void*start_routine(void*args)
{
string name=static_cast<const char*>(args);
while(true)
{
pthread_mutex_lock(&mutex);
//等待条件满足
pthread_cond_wait(&cond,&mutex);
//省略判断
cout<<name<<tickets<<endl;
tickets--;
pthread_mutex_unlock(&mutex);
}
}
int main()
{
pthread_t t[5];
for(int i=0;i<5;i++)
{
char name[64];
snprintf(name,sizeof(name),"thread: %d",i+1);
pthread_create(t+i,nullptr,start_routine,name);
}
while(true)
{
sleep(2);
pthread_cond_broadcast(&cond);
cout<<"mian thread wakeup ..."<<endl;
}
for(int i=0;i<5;i++)
{
pthread_join(t[i],nullptr);
}
return 0;
}

为上面代码中pthread_cond_wait中之所以会存在互斥量
是因为当该函数调用时,如果线程将锁抱走等待,就会导致其他线程只能进行等待,所以会以原子性的方式将锁释放,然后将自己挂起;当等待被唤醒时,会重新获取锁以保证后续共享资源的安全
条件等待是线程间同步的一种手段,如果只有一个线程,条件不满足,会一直等下去;因此必须有一个线程通过某些操作改变共享资源,使之前不满足的条件变得满足,然后通知等待在条件变量上的线程;条件不会无缘无故地变得满足,必然会牵扯到共享资源,使用互斥量,以保证其安全
生产者消费模型
概念
举个栗子

在学校里,超市中存放着许多商品,这些商品并不是超市生产的而是由供应商供货,通过超市这一交易场所为学生提供商品
由于超市的存在,学生与供应商之间就不需要产生联系也就是所谓的“解耦”;学生不需要到供应商那里购买商品,两者在生产和消费之间没有任何联系
在超市中,学生与学生之间可能会存在购买同一商品,且商品库存不够的情景,在线程中称作互斥关系;在供应商向超市提供商品时,同一商品的不同品牌也存在着互斥关系,只能存在其中一个
学生与供应商之间:只有货架上存在商品时,才能去购买,不能说商品边生产边消费,这也是一种互斥关系;供应商一定是生产一部分,学生消费一部分,待消费得差不多时,再进行生产,这里存在着同步的关系
概念:
生产者消费者模型就是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而是通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力,这个阻塞队列就是用来给生产者和消费者解耦的
优点
- 生产线程和销毁线程进行解耦
- 支持生产和消费的一段忙闲不均
- 提高效率
总结
- 3种关系:生产者与生产者(互斥),消费者与消费者(互斥),生产者与消费者(互斥,同步)
- 2种角色:生产者,消费者
- 1个交易场所:一段特定结构的缓冲区
不过呢,还存在一个问题:

当超市的商品已经足够时,由于供应商并不知道,所以需要对超市(共享资源)加锁,判断,解锁;学生的优先级较低,只能看着供应商一直在重复着加锁,判断,解锁的操作,条件变量就是用来解决这一问题的
基于阻塞队列的生产消费模型

在多线程编程中阻塞队列是一种常用于实现生产者和消费者模型的数据结构;当队列为空时,从队列中获取元素的操作将会被阻塞,直到队列中放入元素;当队列满时,向队列中存放元素的操作也会被阻塞,直到有元素被从队列中取出
阻塞队列实现
const int bmaxcap=5;
template<class T>
class BlockQueue
{
public:
BlockQueue(const int&maxcap=bmaxcap)
:_maxcap(maxcap)
{
pthread_mutex_init(&_mutex,nullptr);
pthread_cond_init(&_pcond,nullptr);
pthread_cond_init(&_ccond,nullptr);
}
//输入型参数 const &
void push(const T&in)
{
pthread_mutex_lock(&_mutex);
//充当条件判断的语句必须是while
//可能会存在假唤醒
while(is_full())
{
pthread_cond_wait(&_pcond,&_mutex);
}
_q.push(in);
pthread_cond_signal(&_ccond);
pthread_mutex_unlock(&_mutex);
}
//输出型参数 *
void pop(T*out)
{
pthread_mutex_lock(&_mutex);
while(is_empty())
{
pthread_cond_wait(&_ccond,&_mutex);
}
*out=_q.front();
_q.pop();
pthread_cond_signal(&_pcond);
pthread_mutex_unlock(&_mutex);
}
~BlockQueue()
{
pthread_mutex_destroy(&_mutex);
pthread_cond_destroy(&_pcond);
pthread_cond_destroy(&_ccond);
}
private:
bool is_empty()
{
return _q.empty();
}
bool is_full()
{
return _q.size()==_maxcap;
}
private:
queue<T> _q;
int _maxcap;//队列的上限
//互斥量以保证共享资源安全
pthread_mutex_t _mutex;
//生产者对应的条件变量
pthread_cond_t _pcond;
//消费者对应的条件变量
pthread_cond_t _ccond;
};
生产任务代码
class Task
{
using func_t=function<int(int,int,char)>;
public:
Task()
{}
Task(int x,int y,char op,func_t func)
:_x(x)
,_y(y)
,_op(op)
,_callback(func)
{}
string operator()()
{
int result=_callback(_x,_y,_op);
char buffer[1024];
snprintf(buffer,sizeof(buffer),"%d %c %d = %d",_x,_op,_y,result);
return buffer;
}
string toTaskString()
{
char buffer[1024];
snprintf(buffer,sizeof(buffer),"%d %c %d = ?",_x,_op,_y);
return buffer;
}
private:
int _x;
int _y;
char _op;
func_t _callback;
};
测试代码
const string oper="+-*/%";
int mymath(int x,int y,char op)
{
int result=0;
switch(op)
{
case '+':
result=x+y;
break;
case '-':
result=x-y;
break;
case '*':
result=x*y;
break;
case '/':
if(y==0)
{
cout<<"div zero!"<<endl;
result=-1;
}
else
result=x/y;
break;
case '%':
if(y==0)
{
cout<<"mod zero!"<<endl;
result=-1;
}
else
result=x%y;
break;
default:
break;
};
}
//消费者
void*consumer(void*_bq)
{
BlockQueue<Task>*bq=static_cast<BlockQueue<Task>*>(_bq);
while(true)
{
Task t;
bq->pop(&t);
cout<<"消费任务: "<<t()<<endl;
}
return nullptr;
}
//生产者
void*productor(void*_bq)
{
BlockQueue<Task>*bq=static_cast<BlockQueue<Task>*>(_bq);
while(true)
{
int x=rand()%10+1;
int y=rand()%5;
int opercode=rand()%oper.size();
Task t(x,y,oper[opercode],mymath);
bq->push(t);
cout<<"生产任务: "<<t.toTaskString()<<endl;
sleep(1);
}
return nullptr;
}
int main()
{
srand((unsigned long)time(nullptr)^getpid());
BlockQueue<Task>*bq=new BlockQueue<Task>();
pthread_t c,p;
pthread_create(&c,nullptr,consumer,bq);
pthread_create(&p,nullptr,productor,bq);
pthread_join(c,nullptr);
pthread_join(p,nullptr);
return 0;
}
运行结果

在这里可以理解生产消费模型的高效:生产者在将任务放到队列之前,获取和构建任务需要消耗大量时间;消费者从队列中取出任务之后,执行任务同样也需要时间;模型的出现使线程在任务在生产之前,消费之后并行执行,因此而变得高效
POSIX信号量
概念
在上面阻塞队列中,生产者产生任务时,队列必须有空的资源,也就是满足产生任务的条件;判断公共资源是否满足条件在没有访问之前是无法得知的,只能通过先加锁,进行检测,接着操作,最后解锁,而且默认情况下只要对资源加锁,就意味着对整个资源都使用,但事实并不是如此,也可能是使用同一资源的不同区域
信号量的引入就可以提前得知资源的情况,也可以实现访问同一资源的不同区域
概念:
信号量本质是一个计数器,用来衡量资源数量的计数器。在线程访问某一资源之前先申请信号量,如果申请成功,就说明资源满足条件,自己也就拥有资源的这一区域,如果失败说明条件不满足,只能等待;所以申请信号量的本质是对资源中特定小块资源的预定
举个栗子
临界资源就是电影院,在电影开幕之前,观众需要进行买票,买票这一操作就是预定,座位就可以看作是资源的不同区域;买票成功,就表示可以进行观影
线程想要访问临界资源中的某一区域,需要先申请信号量,申请的前提是所有线程都能看到,也就是说信号量本质也是公共资源
信号量 sem_t sem的结构能够保证其操作是原子性的
信号量初始化
int sem_init(sem_t *sem, int pshared, unsigned int value);
pshared:0表示线程间共享;!0表示进程间共享
value:信号量初值,表示资源的多少
销毁信号量
int sem_destroy(sem_t *sem);
等待信号量
int sem_wait(sem_t *sem);
等待信号量,相当于 sem++;申请资源
发布信号量
int sem_post(sem_t *sem);
发布信号量,表示资源使用完毕,相当于sem--;归还资源
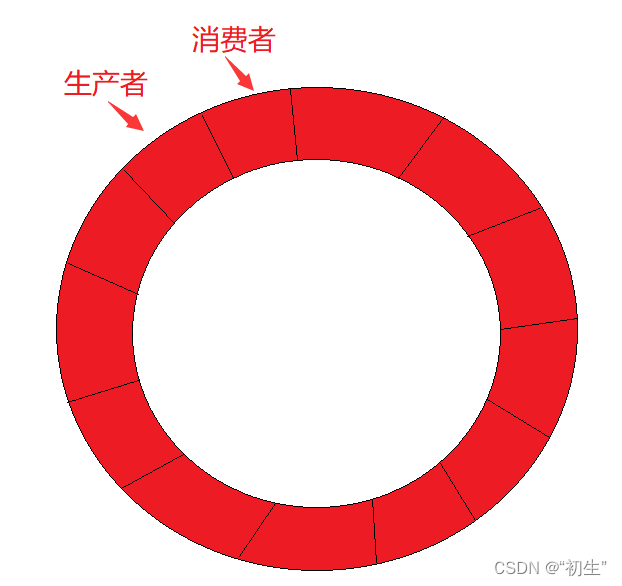
基于环形队列的生产消费模型

-
环形队列为空或为满时,生产者和消费者可能会访问同一个位置
-
为空时,生产者先生产,所以消费者只能在生产者后面的位置,不可能超越

-
未满时,只有消费者消费一个任务,生产者才能生产任务,所以生产者在消费者的后面,不可能超越
对于生产者:productor_sem
申请成功,将生产的任务放到环形队列中,生产者信号量总数减少P(productor_sem),消费者的信号量增加V(consumer_sem)
对于消费者:consumer_sem
消费一个任务,消费者信号量减少P(consumer_ssem),生产者信号量增加V(productor_sem)
生产者和消费者的位置其实就是队列的下标
static const int gcap=5;
template<class T>
class Ringqueue
{
private:
void P(sem_t &sem)
{
int n=sem_wait(&sem);
assert(n==0);
(void)n;
}
void V(sem_t &sem)
{
int n=sem_post(&sem);
assert(n==0);
(void)n;
}
public:
Ringqueue(const int&cap=gcap)
:_queue(cap)
,_cap(cap)
{
int n=sem_init(&_spaceSem,0,_cap);
assert(n==0);
n=sem_init(&_dataSem,0,0);
assert(n==0);
_productor=_consumer=0;
pthread_mutex_init(&_pmutex,nullptr);
pthread_mutex_init(&_cmutex,nullptr);
}
//生产者
void Push(const T&in)
{
//申请信号量-减少空间信号量
P(_spaceSem);
pthread_mutex_lock(&_pmutex);
_queue[_productor++]=in;
_productor%=_cap;
pthread_mutex_unlock(&_pmutex);
//增加数据信号量
V(_dataSem);
}
//消费者
void Pop(T*out)
{
//减少数据信号量
P(_dataSem);
pthread_mutex_lock(&_cmutex);
*out=_queue[_consumer++];
_consumer%=_cap;
pthread_mutex_unlock(&_cmutex);
//减少消费者信号量
V(_spaceSem);
}
~Ringqueue()
{
sem_destroy(&_spaceSem);
sem_destroy(&_dataSem);
pthread_mutex_destroy(&_pmutex);
pthread_mutex_destroy(&_cmutex);
}
private:
vector<T> _queue;
//队列上限
int _cap;
sem_t _spaceSem;//生产者,空间资源
sem_t _dataSem;//消费者,数据资源
int _productor;//生产者位置
int _consumer;//消费者位置
pthread_mutex_t _pmutex;
pthread_mutex_t _cmutex;
};
线程池
一种线程使用的模式。线程过多会带来调度开销,进而影响效率;线程池维护着多个线程,等待着分配的可并发的任务,避免了在处理短时间任务创建和销毁线程的代价

简单来说,线程池就是一批提前创建完成的线程。当有任务到来时,就去处理任务;没有任务时,线程就进行休眠,通过空间来换取时间