Redis之GeoHash底层原理与实战
1:计算附近的人
如上图所示,结合地球的经度与纬度。我们将地图元素的位置数据使用二维的经纬度表示。当两个元素的距离不是很远时,可以直接使用勾股定理就能算得元素之间的距离。我们平时使用的「附近的人」的功能,元素距离都不是很大,勾股定理算距离足矣。

1:需求
1:如果要计算「附近的人」,也就是给定一个元素的坐标,然后计算这个坐标附近的其它元素,按照距离进行排序,该如何下手?
2:如果现在元素的经纬度坐标使用关系数据库 (元素 id, 经度 x, 纬度 y) 存储,你该如何计算?
2:分析
你不可能通过遍历来计算所有的元素和目标元素的距离然后再进行排序,这个计算量太大了,性能指标肯定无法满足。一般的方法都是通过矩形区域来限定元素的数量,然后对区域内的元素进行全量距离计算再排序。这样可以明显减少计算量。如何划分矩形区域呢?可以指定一个半径 r,使用一条 SQL 就可以圈出来。当用户对筛出来的结果不满意,那就扩大半径继续筛选
select id from positions where x0-r < x < x0+r and y0-r < y < y0+r
为了满足高性能的矩形区域算法,数据表需要在经纬度坐标加上双向复合索引 (x, y),这样可以最大优化查询性能。
但是数据库查询性能毕竟有限,如果「附近的人」查询请求非常多,在高并发场合,这可能并不是一个很好的方案。
2:GEO 模块引入
Redis 在 3.2 版本以后增加了地理位置 GEO 模块,意味着可以使用 Redis 来实现摩拜单车「附近的 Mobike」、美团和饿了么「附近的餐馆」这样的功能了。
3:Geo 指令基本使用
Redis 钟的Geo本质上只是一个普通的 zset 结构。
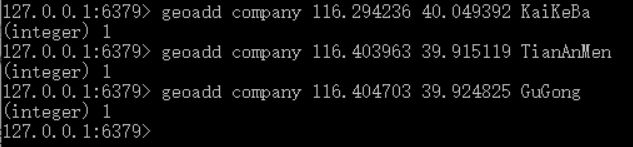
1:添加坐标
geoadd 指令携带集合名称以及多个经纬度名称三元组,注意这里可以加入多个三元组。
2:距离计算
geodist 指令可以用来计算两个元素之间的距离,携带集合名称、2 个名称和距离单位。
其中距离单位可以是 m、km、ml、ft,分别代表米、千米、英里和尺

3:获取元素位置
geopos 指令可以获取集合中任意元素的经纬度坐标,可以一次获取多个。

我们观察到获取的经纬度坐标和 geoadd 进去的坐标有轻微的误差,原因是 geohash 对二维坐标进行的一维映射是有损的,通过映射再还原回来的值会出现较小的差别。对于「附近的人」这种功能来说,这点误差根本不是事。
4:获取元素的 hash 值
geohash 可以获取元素的经纬度编码字符串,可以使用这个编码值去 http://geohash.org/${hash}中进行直接定位,它是 geohash 的标准编码值。

5:附近的公司
georadiusbymember 可以用来查询指定元素附近的其它元素
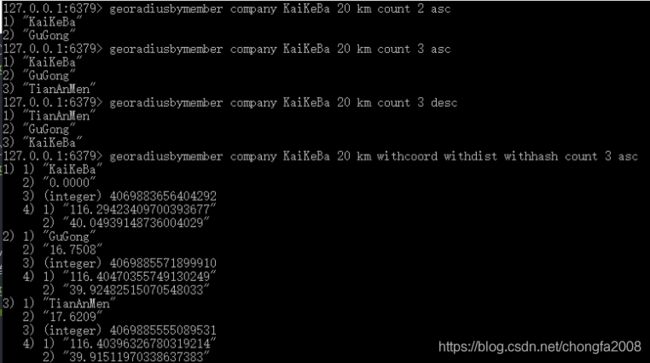
如上图所示,
第一句命令表示显示KKB距离20公里内,由近到远显示2个地址。
第三句命令表示显示KKB距离20公里内,由远到近显示3个地址。
第四句命令中添加了参数 withcoord withdist withhash
其中withdist 很有用,它可以用来显示距离。

如果将georadiusbymember 指令根据元素更改为其他的经纬度,则就可以实现根据用户的定位来计算「附近的车」,「附近的餐馆」等功能了。
4:重点注意
在一个地图应用中,车的数据、餐馆的数据、人的数据可能会有百万千万条,如果使用Redis 的 Geo 数据结构,它们将全部放在一个 zset 集合中。在 Redis 的集群环境中,集合可能会从一个节点迁移到另一个节点,如果单个 key 的数据过大,会对集群的迁移工作造成较大的影响,在集群环境中单个 key 对应的数据量不宜超过 1M,否则会导致集群迁移出现卡顿现象,影响线上服务的正常运行。
建议 Geo 的数据使用单独的 Redis 实例部署,不使用集群环境。
如果数据量过亿甚至更大,就需要对 Geo 数据进行拆分,按国家拆分、按省拆分,按市拆分,在人口特大城市甚至可以按区拆分。这样就可以显著降低单个 zset 集合的大小。