Linux面试题汇总
Linux面试题汇总
- 网络拓展
- Linux 概述
-
- 什么是Linux
- Unix和Linux有什么区别?
- 什么是 Linux 内核?
- Linux的基本组件是什么?
- Linux 的体系结构
- BASH和DOS之间的基本区别是什么?
- Linux 开机启动过程?
- Linux系统缺省的运行级别?
- Linux 使用的进程间通信方式?
- Linux 有哪些系统日志文件?
- Linux系统安装多个桌面环境有帮助吗?
- 什么是交换空间?
- 什么是root帐户
- 什么是LILO?
- 什么是BASH?
- 什么是CLI?
- 什么是GUI?
- 开源的优势是什么?
- GNU项目的重要性是什么?
- 磁盘、目录、文件
-
- 简单 Linux 文件系统?
- Linux 的目录结构是怎样的?
- 什么是 inode ?
- 简述 Linux 文件系统通过 i 节点把文件的逻辑结构和物理结构转换的工作过程?
- 什么是硬链接和软链接?
- RAID 是什么?
- 安全
-
- 一台 Linux 系统初始化环境后需要做一些什么安全工作?
- 什么叫 CC 攻击?什么叫 DDOS 攻击?
- 什么是网站数据库注入?
- 如何过滤与预防?
- Shell
-
- Shell 脚本是什么?
- 什么是默认登录 Shell ?
- 在 Shell 脚本中,如何写入注释?
- 语法级
-
- 可以在 Shell 脚本中使用哪些类型的变量?
- Shell脚本中 $? 标记的用途是什么?
- Bourne Shell(bash) 中有哪些特殊的变量?
- 如何取消变量或取消变量赋值?
- Shell 脚本中 if 语法如何嵌套?
- 在 Shell 脚本中如何比较两个数字?
- Shell 脚本中 case 语句的语法?
- Shell 脚本中 for 循环语法?
- Shell 脚本中 while 循环语法?
- do-while 语句的基本格式?
- Shell 脚本中 break 命令的作用?
- Shell 脚本中 continue 命令的作用?
- 如何使脚本可执行?
- #!/bin/bash 的作用?
- 如何调试 Shell脚本?
- 如何将标准输出和错误输出同时重定向到同一位置?
- 在 Shell 脚本中,如何测试文件?
- 在 Shell 脚本如何定义函数呢?
- 如何让 Shell 就脚本得到来自终端的输入?
- 如何执行算术运算?
- 编程题
-
- 判断一文件是不是字符设备文件,如果是将其拷贝到 /dev 目录下?
- 添加一个新组为 class1 ,然后添加属于这个组的 30 个用户,用户名的形式为 stdxx ,其中 xx 从 01 到 30 ?
- 编写 Shell 程序,实现自动删除 50 个账号的功能,账号名为stud1 至 stud50 ?
- 写一个 sed 命令,修改 /tmp/input.txt 文件的内容?
- 实战
-
- 如何选择 Linux 操作系统版本?
- 如何规划一台 Linux 主机,步骤是怎样?
- 请问当用户反馈网站访问慢,你会如何处理?
- 针对网站访问慢,怎么去排查?
- Linux 性能调优都有哪几种方法?
- 文件管理命令
-
- cat 命令
- chmod 命令
- chown 命令
- find 命令
- head 命令
- less 命令
- ln 命令
- locate 命令
- more 命令
- mv 命令
- rm 命令
- tail 命令
- touch 命令
- vim 命令
- whereis 命令
- which 命令
- 文档编辑命令
-
- grep 命令
- wc 命令
- 磁盘管理命令
-
- cd 命令
- df 命令
- du 命令
- ls命令
- mkdir 命令
- pwd 命令
- rmdir 命令
- 网络通讯命令
-
- ifconfig 命令
- iptables 命令
- netstat 命令
- ping 命令
- telnet 命令
- 系统管理命令
-
- date 命令
- free 命令
- kill 命令
- ps 命令
- rpm 命令
- top 命令
- top 交互命令
- yum 命令
- 备份压缩命令
-
- bzip2 命令
- gzip 命令
- tar 命令
- unzip 命令
- Linux 基础
-
- **三次握手,四次挥手**
- **什么是动态资源,什么是静态资源**
- Tomcat和Resin有什么区别,工作中你怎么选择?
- **什么叫网站灰度发布?**
- 请写出Linux命令执行的过程
- 分别写出以下目录和文件一般存放的内容
- 当前目录为/opt/请分别以绝对路径和相对路径进入 /mnt 目录
- 请建立/etc/passwd的软链接到/mnt目录
- 将/etc/文件夹复制到/opt/目录下
- 实时显示/var/log/messages文件的后10行
- 找出/etc目录下fstab文件中以#号开头的行
- 统计/var目录中的第一层子目录的空间占用情况
- 将/etc 下的文件和目录按照建立时间顺序排列倒序显示
- 显示/etc/目录下所有以rc开头,之后是0-6间的数字,其它为任意字符的文件或目录
- 查找/var/log目录下文件名以 “.log” 结尾的所有普通文件,并移动到/mnt目录下
- 把家目录中的abc.txt和123.txt文件压缩成 abc123.tar.gz
- 把家目录中的abc123.tar.bz2文件解归档到 /opt 目录中
- 把1.txt 文件中所有空行都去除
- 把家目录中的abc.txt文件移动到/opt目录中,并把文件名修改成123.txt
- 过滤出/etc/fstab文件中所有非空行
- 过滤出ifconfig ens33 命令中的第二行
- 统计/etc文件中的第一层目录并排序
- 请简述磁盘空间满了你该做怎么样的操作?
- 统计/etc/fstab文件有多少行
- 将当前目录下的所有文件归档,并使用 gzip 压缩
- telnet命令的作用是什么?
- 判断与10.0.0.1上的mysql是否连通的命令
- DNS作用是什么?
- Linux系统什么文件定义了DNS的NameServer
- 结束后台进程的命令是什么?
- 为脚本指定执行权限的命令及参数是什么?
- 欲发送10个分组报文文测试与主机www.aliyuncom的连通性,应使用的命令和参数是?
- 对config目录做归档压缩,生成config.tar.gz文件
- 使用什么命令(非ping) 测试DNS服务器是否能够正确解析域名
- 局域网没有条件建立DNS服务器,但又想让局域网内的用户可以使用计算机名互相访问,应配置什么文件?
- 永久改变主机名
- 查看10.0.0.1机器上提供的网络文件NFS服务
- LVM相关命令有哪些?
- 某系统网卡名为eth0,在什么文件中配置静态网络 (包括ip、掩码、网关等)
- ping命令使用什么协议的数据包来探测目标主机是否连通
- 显示当前所在目录
- 搭建本地yum仓库全过程
- 挂载/dev/sda1到/mnt目录
- 磁盘分区用什么命令?
- Linux磁盘分区的步骤
- 重启命令有哪些
- cp -r是什么意思?
- 磁盘还有空余,为什么却无法继续新建文件?
- pstree -p是什么意思?
- inode号满了怎么办?
- 读、写、执行权限分别用什么字母和数字表示?
- RAID0、1、5、10各自所需最少硬盘数量、可用容量、最多坏几块盘和读写性能
- 查看当前主机的80端口是否被使用
- 建立逻辑卷的步骤
- 写出Linux系统启动过程
- 某文件权限为drw-r--r--用数字怎么表示?
- 怎么确认一个进程是单线程还是多线程?
- Centos7默认网卡位置
- yum provides ftp是什么意思?
- 如何修改用户test的密码
- 查看当前系统实际使用的DNS
- 查看当前系统实际使用的网关
- 给ens33网卡添加一个虚拟网卡
- 回环网卡的作用
- 写出/etc/fstab文件内的格式
- 那些命令可以查看文件的权限属性
- 查找cp命令所在的文件夹
- 删除文件后空间不释放怎么办?
- rpm -ql httpd 是什么意思?
- tr命令的主要作用是什么?
- crontab -l 是什么意思?
- 查看每一个用户最近一次的登录信息命令
- 查看用户的失败尝试登录的相关日志信息命令
- 查看用户正常登录系统的相关日志信息命令
- ssh协议和talnet协议有什么区别?
- 使用yum卸载软件
- ls;cd /opt 是什么意思?
- 编译安装的步骤
- 通配符和正则表达式的区别是什么?
- sed -i 是什么意思?
- 查看/etc/passwd中的内容
- tac命令的作用是什么?
- 查看/dev/sda的前512字节
- 分页查看文件内容可以使用哪些命令?
- 只查看最新发生的日志
- 取/etc/passwd文件中以冒号为分隔符的第三字段
- 简述paste命令的作用
- sort -nr 是什么意思?
- uniq命令的基本作用是什么?
- 过滤出ifconfig ens33命令结果中本机的ipv4地址
- 查看用户UID
- 简述sed与awk的区别
- Centos7默认的文件系统
- 进程之间通讯的方式有哪些?
- 你用过哪些时间同步软件?
- 你用过哪些品牌的服务器?
- GUI是什么?
- SVN是什么?
- MAVEN是什么?
- GIT是什么?
- 统计/var/log/nginx/access.log日志中访问量最多的前十个IP地址
- 日志文件很大,怎么切分?
- 文件系统损坏可以尝试用什么命令修复?
- 如何将标准输出和错误输出同时重定向到一个文件?
- 如何选择Linux操作系统版本?
- 如何刷新文件的atime、ctime、mtime三个时间?
- 运行ifconfig命令报错command not found是为什么?怎么解决?
- 如何过滤出僵尸进程?
- 突然发现磁盘的sdb1分区只读了,哪些情况会这样?怎么办?
- 你知道哪些Linux系统下的压力测试工具?
- 统计出root用户一共运行的进程总数
- 出现CPU死循环该怎么处理
- 服务器CPU负载过高,如何在不影响业务正常运行的情况下,排除故障并解决
- SLA服务级别三个9代表什么意思?
- cp命令危险吗?
- 你编译过Linux系统内核?或升级过系统内核?怎么操作?
- Linux系统刚运行时内存占用率低,运行10天后内存过高,内存过高怎么办?
- 公司中有一台服务器故障,更换服务器后,配置原来的IP地址,无法ssh远程登录该怎么办?
- 给你300台裸机,你会怎么处理
- 日常该怎么巡检?
- Swap交换分区的作用是什么?
- 如何打开、关闭交换分区?
- 立即打开并开机自启动httpd服务
- free命令中buff/cache分别是什么意思?
- 使用du命令的哪个选项,可以控制显示的文件夹层级
- 找到根目录下大于7天的以.log结尾的普通文件
- 管道符(|)的作用是什么?
- 查找进程svn的相关信息
- 统计进程svn的个数
- 回到上一次的文件夹
- 显示磁盘的文件系统类型
- 如何周期性查看内存
- 简述Centos6和Centos7之间的区别
- 不删除文件,怎么清空文件中的内容?
- du和ls都可以看到文件大小,有什么区别?
- 如何检查磁盘是否损坏?
- 简述遗忘root密码的解决办法
- 如何判断CPU是否高负载?
- 简要写出DHCP客户端获取IP地址的一次完整过程
- Linux用户有哪些类型?
- 怎么确定一个用户是不是超级管理员
- 快速过滤/etc文件夹下包含root单词的所有文件
- 备份/dev/sda的前512字节到/mnt目录
- 通过inode号12345678删除当前目录普通文件
- Centos7的默认管理员组
- 文件元数据包括什么?并简要介绍
- /tmp文件夹多了个t权限,显示为drwxrwxrwt,为什么?
- 默认的umask是多少?
- 文件夹的最小权限是什么?文件和文件夹默认的最大权限分别是多少?
- 查看非文本内容命令
- 解挂载时无法解挂载,会有什么原因,并简述解决方法
- top -n5 什么意思?
- 有什么运维相关的命令
- LVS负载均衡
-
- 1. 什么是 LVS?它的主要作用是什么?
- 2. LVS 的架构是什么?
- 3. LVS 的工作原理是什么?
- 4. LVS 的负载均衡算法有哪些?
- 5. LVS 的会话保持机制是什么?
- 6. LVS 的优点和缺点是什么?
- 7.**LVS** **负载均衡有哪些策略?**
- 8.谈谈你对LVS的理解?
- 9.**负载均衡的原理是什么?**
- 10.LVS由哪两部分组成的?
- 11.与lvs相关的术语有哪些?
- 12.LVS-NAT模式的原理
- 13.LVS-NAT模型的特性
- 14. LVS-DR模型的特性
- 15.LVS三种负载均衡模式的比较
- 16.LVS的负载调度算法
- 17. LVS与nginx的区别
- 18. **负载均衡的作用有哪些?**
- 19.nginx实现负载均衡的分发策略
- Nginx负载均衡
-
- 1. 什么是 Nginx?它的主要作用是什么?
- 2. Nginx 的架构是什么?
- 3. Nginx 如何实现反向代理和负载均衡?
- 4. Nginx 如何处理静态和动态资源?
- 5. 如何在 Nginx 中实现 HTTPS 协议?
- 6. Nginx 的优点和缺点是什么?
- 7. nginx做负载均衡实现的策略有哪些
- 8.nginx做负载均衡用到哪些模块
- 9. **负载均衡有哪些实现方式**
- 10. nginx如何实现四层负载?
- 11. 你知道的web服务有哪些?
- 12. 为什么要用nginx
- 13. nginx的性能为什么比apache高?
- 14. epoll的组成
- 15.nginx和apache的区别
- 16 .nginx常用的命令
- 17. **什么是反向代理,什么是正向代理,以及区别?**
- 18.Squid、Varinsh、Nginx **有什么区别?**
- 19. nginx是如何处理http请求的
- 20 .nginx虚拟主机有哪些?
- 21. nginx怎么实现后端服务的健康检查
- 22.nginx的优化你都做过哪些?
- 23.nginx的session不同步怎么办
- 24.nginx的常用模块有哪些?
- 25. nginx常用状态码
- 25.**访问一个网站的流程**
- 26.统计ip访问情况,要求分析nginx访问日志,找出访问页面数量在前十位的ip
- 27.nginx各个版本的区别
- 28.nginx最新版本
- 29. 关于nginx access模块的面试题
- 30. nginx默认配置文件
- 31.location的规则
- 32.配置nginx防盗
- 33.nginx中的lua模块用过没有?
- 34 .正向代理和反向代理的区别?
- 35.nginx电商网站突然打不开了,你会怎么处理?
- 36.nginx返回码502是什么原因?
- 37.nginx返回码504是什么原因?
- 38.nginx返回码500是什么原因?
- 39.nginx返回码405是什么原因?
- 40.nginx返回码499是什么原因?
- 41.nginx返回码301、302是什么原因?
- 42.Nginx访问十分的卡,怎么办?
- 43.前端nginx突然发现大量用户访问导致无法使用,你需要调整什么参数?
- Keepalived高可用
-
- 1.**keepalived** **是什么?**
- 2.你是如何理解VRRP协议的
- 3.keepalived的工作原理?
- 4. **出现脑裂的原因**
- 5.如何解决keepalived脑裂问题?
- Kafka分布式消息
-
- 1.什么是Kafka?
- 2.Kafka中的主题和分区是什么?
- 3.Kafka如何保证消息的可靠性传递?
- 4.什么是Kafka Consumer Group?
- 5.Kafka如何处理复杂数据类型?
- 6.Kafka和其他消息队列系统的区别是什么?
- 7.Kafka如何处理消息丢失问题?
- 8.kafka 中的ISR,AR代表什么,ISR伸缩又代表什么
- 9.kafka中的broker 是干什么的
- 10. kafka中的zookeeper 起到什么作用,可以不用zookeeper么
- 11. kafka follower如何与leader同步数据
- 12. **kafka** **为什么那么快**
- 13. Kafka中的消息是否会丢失和重复消费?
- 14 .为什么Kafka不支持读写分离?
- 15. 什么是消费者组?
- 16. **Kafka** 中的术语
- 17. kafka适用于哪些场景
- 18.Kafka写入流程:
- Tomcat服务
-
- 1. Tomcat 是什么?介绍一下它的作用和特点。
- 2. Tomcat 的体系结构是什么样的?它包括哪些组件?
- 3. Tomcat 的默认端口是什么?如何修改 Tomcat 的端口?
- 4. Tomcat 的启动方式有哪些?如何手动启动和停止 Tomcat 服务器?
- 5. Tomcat 的日志文件存在哪里?如何查看 Tomcat 的日志信息?
- 6. Tomcat 在 Linux 上如何安装和配置?
- 7. 如何在 Tomcat 上部署 Web 应用程序?
- 8. Tomcat作为web的优缺点?
- 9. tomcat的三个端口及作用
- 10.**fastcgi** 和cgi的区别
- 11.Tomcat缺省端口是多少,怎么修改
- 12.Tomcat的工作模式是什么?
- 13.Web请求在Tomcat请求中的请求流程是怎么样的?
- 14.怎么监控Tomcat的内存使用情况
- 15.Tomcat你做过哪些优化
- 16.Tomcat中出现OOM怎么处理?
- Apache服务
-
- 1. 什么是 Apache?它的主要作用是什么?
- 2. 安装 Apache 有哪些常用的方式?如何完成 Apache 的配置?
- 3. 如何启动和停止 Apache 服务器?
- 4. 如何在 Apache 服务器上配置虚拟主机?
- 5. 如何调优 Apache 服务器?
- 6. 如何查看 Apache 的日志信息?
- 7. 如何保护 Apache 服务器的安全性?
- 8.apache中的Worker和Prefork 之间的区别是什么?
- Ansible自动化运维工具
-
- 1.Ansible是什么?
- 2.ansible用过哪些模块?
- 3.什么是 Ansible 模块?
- 4.什么是 Ansible 的 playbooks ?
- 5.描述Ansible是如何工作的?
- 6.ansible的shell模块在哪种场景不能使用?
- 7.ansible的shell模块可以对后端的文件进行修改吗?
- MySQL数据库
-
- 1.什么是MySQL?
- 2.什么是SQL?
- 3.如何在MySQL中创建数据库?
- 4.如何创建用户并授予访问数据库的权限?
- 5.如何在MySQL中备份和恢复数据?
- 6.如何优化MySQL查询?
- 7.drop,delete和truncate删除数据的区别?
- 8.MySQL主从原理
- 9.MySQL主从复制存在哪些问题?
- 10.MySQL复制的方法
- 11.主从延迟产生的原因及解决方案?
- 12.判断主从延迟的方法
- 13.MySQL忘记root密码如何找回
- 14.MySQL的数据备份方式
- 15. innodb的特性
- 16.varchar(100)和varchar(200)的区别
- 17.MySQL主要的索引类型
- 18. **请说出非关系型数据库的典型产品、特点及应用场景?**
- 19.如何加强MySQL安全,请给出可行的具体措施?
- 20.Binlog工作模式有哪些?各什么特点,企业如何选择?
- 21.**生产一主多从从库宕机,如何手工恢复?**
- 22.MySQL中MyISAM与InnoDB的区别,至少5点
- 23.网站打开慢,请给出排查方法,如是数据库慢导致,如何排查并解决,请分析并举例?
- 24.xtrabackup的备份,增量备份及恢复的工作原理
- 25.误执行drop数据,如何通过xtrabackup恢复?
- 26.**如何做主从数据一致性校验?**
- 27. MySQL有多少日志
- 28. MySQL binlog的几种日志录入格式以及区别
- 29. MySQL数据库cpu飙升到500%的话他怎么处理?
- 30.MySQL同步和半同步
- Oracle数据库
-
- 1. 什么是 Oracle 数据库?它的主要作用是什么?
- 2. Oracle 数据库的架构是什么?
- 3. Oracle 数据库体系结构中的实例和数据库有什么区别?
- 4. Oracle 数据库如何提高性能?
- 5. Oracle 数据库如何进行备份和恢复?
- 6. Oracle 数据库的存储结构是什么?
- 7. 如何保证 Oracle 数据库的安全性?
- Redis缓存数据库
-
- 1.什么是Redis?
- 2.Redis支持哪些数据结构?
- 3.Redis的持久化机制是什么?
- 4.Redis的主从复制是什么?
- 5.Redis中如何实现分布式锁?
- 6.Redis中如何实现消息队列?
- 7.redis作用 应用场景
- 8.使用redis好处
- 9.redis主从复制模式下,主挂了怎么办?
- 10.请简述出什么是主从复制、哨兵模式以及集群模式?
- 11.redis为什么任意一个节点挂了(没有从节点)这个集群就挂了?
- 12.redis是单线程还是多线程?
- 13.redis常用的版本是?
- 14.redis的使用场景?
- 16.redis常见的数据结构
- 17.redis持久化你们怎么做的?
- 18. 主从复制实现的原理
- 19.redis哨兵模式原理
- 20.memcache和redis的区别
- 21.redis有哪些架构模式?
- 22.redis **缓存雪崩?**
- 23.redis缓存穿透
- 24.redis **缓存击穿**
- 25. redis为什么这么快
- 26.memcache有哪些应用场景
- 27. memcache服务特点及工作原理
- 28.memcached是如何做身份验证的?
- 29.mongoDB是什么?
- 30.mongodb的优势
- 31.mongodb使用场景
- GFS分布式文件系统
-
- 1.请简要介绍 Google 文件系统(GFS)以及其适用场景。
- 2. 请简要介绍 GFS 的架构组件。
- 3.请问 GFS 是否允许多用户同时访问同一文件?
- 4. 请问 GFS 在数据备份方面有什么考虑?
- 5.请简要介绍 GFS 的缺陷和挑战。
- 6.GlusterFS的工作流程 并且说出术语
- 7.GlusterFS日常使用的哪五种卷,并且说明五种卷作用(原理和特点)?
- 8.如何查看GlusterFS卷
- 9.查看所有卷的信息
- 10.查看所有卷的状态
- 11.如何停止一个卷和删除一个卷?
- 12.如何设置卷的黑白名单?
- ELK日志收集
-
- 1. 什么是 ELK?它的主要作用是什么?
- 2. ELK 的架构是什么?
- 3. ELK 如何实现日志分析和异常监控?
- 4. ELK 如何管理和处理日志?
- 5. ELK 如何解决日志查询效率问题?
- 6. ELK 如何保证数据安全性?
- 7. ELK 的优势和缺点是什么?
- 8.ELK的组成以及功能
- 9.ELK的工作原理
- 10.logstash的架构
- 11.ELK工作流程
- 12. logstash的输入源有哪些?
- 13. logstash的架构
- 14.ELK相关的概念
- 15. es常用的插件
- 16.ELK索引迁移有没有做过,怎么做?
- 17.ELK索引故障是什么原因导致的?
- 18.ELK索引red状态是出现了什么问题?
- Zookeeper 协调服务
-
- 1.什么是ZooKeeper?
- 2.ZooKeeper的主要功能是什么?
- 3.ZooKeeper是如何保证数据的一致性?
- 4.ZooKeeper与其他分布式系统如何交互?
- 5.ZooKeeper适用于哪些应用场景?
- 5.zookeeper的选举机制
- Zabbix监控
-
- 1. 什么是 Zabbix?它的主要作用是什么?
- 2. Zabbix 的架构是什么?
- 3. Zabbix 如何实现监控和告警?
- 4. 如何使用 Zabbix 进行容器监控?
- 5. Zabbix 如何实现对 Web 应用的监控?
- 6. Zabbix 如何进行分布式监控?
- 7. Zabbix 的优势和缺点是什么?
- 8.为什么要使用监控?
- 9.zabbix-proxy分布式使用什么场景?
- 10.zabbix收集数据的方式有哪些,并且说明模式的含义?
- 11.zabbix监控有哪些?
- 12.安装zabbix使用什么方式,服务端与客户端端口是多少?
- 13. zabbix如何监控脑裂?
- 14.zabbix有哪些组件
- 15.zabbix的两种监控模式
- 16. **一个监控系统的运行流程**
- 17.zabbix的工作进程
- 18. zabbix常用术语
- 19.zabbix自定义发现是怎么做的?
- 20.**微信报警**
- 21.zabbix客户端如何批量安装
- 22. zabbix分布式是如何做的
- 23. **zabbix proxy** **的使用场景**
- 24. zabbix你都监控哪些参数
- 25. 你们使用的zabbix版本是多少,是主动模式还是被动模式?
- 26.如果让你使用zabbix监控URL你会怎么做?
- Prometheus (普罗米修斯监控警报系统)
-
- 1. 什么是 Prometheus? 它的主要作用是什么?
- 2.Prometheus 的主要架构是什么?
- 3.Prometheus 的数据模型是什么?
- 4.如何通过 Prometheus 监控系统和服务?
- 5.如何使用 Prometheus 实现告警功能?
- 6.如何使用 Prometheus 和 Grafana 进行数据可视化 ?
- 7.如何保证 Prometheus 的高可用性?
- 8. prometheus工作原理
- 9. prometheus组件
- Docker容器
-
- 1. 什么是 Docker?它的主要作用是什么?
- 2. Docker 中的容器和镜像有什么区别?
- 3. Docker 的主要组件有哪些?
- 4. 如何使用 Docker 构建和发布镜像?
- 5. Docker 的网络模型是怎样的?
- 6. 如何使用 Docker 容器进行应用程序部署?
- 7. Docker 的优点和缺点是什么?
- 8.dockerfile的编写流程
- 9.dockerfile内的操作指令CMD和ENTRYPOINT区别以及同时存在哪个生效
- 10.docker-compose常用命令有哪些?(不少于8个)
- 11.Harbor的核心组件有哪些,并且说出含义?
- 12.docker Harbor私有仓库的过程?
- 13.docker 三大组件
- 14.docker有哪些优势
- 15.docker的十条管理命令(运维常用的命令)
- 16.docker内两个容器如何通讯
- 17.集群里面有一个docker,他的使用率达到80%你怎么做?
- 18.假设一个集群docker有20个,然后有15个利用率已经达到了80%,服务都是可跑的,不能杀的,这个时候你怎么办?(附加题)
- 19.docker 知识点总结
- K8S容器编排
-
- 1. 什么是 Kubernetes? 它的主要作用是什么?
- 2. Kubernetes 的架构包括哪些组件?
- 3. Kubernetes 中的 Pod 是什么?
- 4. Kubernetes 中的 Service 是什么?
- 5. Kubernetes 中的 Volume 是什么?
- 6. 如何使用 Kubernetes 进行应用程序部署?
- 7. Kubernetes 的优缺点是什么?
- 8.k8s整体访问流程
- 9.kube-proxy的三种模式:
- 10.ipvs和iptables的异同
- 11.无状态和有状态分别是什么
- 12. K8S监控指标
- 13. k8s是怎么做日志监控的
- 14.k8s中service和ingress的区别
- 15.k8s组件的梳理
- 运维技术经验文档
-
- 1.aws云主机之前的网络互访可以通过几种方式进行限制?
- 2.如何在linux下模拟一个tcp端口开放?
- 3.k8s中如何查看命名空间test中pod的IP?
- 4.k8s中pod无法启动怎么排查原因?
- 5.客户使用SSH无法连接服务器,怎么排查?
- 6.Tomcat有哪些优化?
- 7.Mysql查询十分的慢,怎么排查原因?
- 9.LVS负载均衡和Nginx负载均衡有什么区别?
- 10.为什么不用Nginx做负载均衡?
- 11.怎么优化dockerfile镜像启动的的速度?
- 12.为什么dockerfile只有200多M,centos系统有几个G?
- 13.CI/CD
- 14.职场情商题
- 15.php进程占用内存太多,怎么办?
- 16.IDC迁移上云该怎么做?
- 17.把原来的LNMP架构迁移到在阿里云上,Mysql有上T的数据,该怎么做?
- 18.如何将阿里云账号A的OSS存储数据迁移到账号B上?
- 19.Elasticsearch索引分片的概念有没有了解?
网络拓展
Linux 概述
什么是Linux
Linux是一套免费使用和自由传播的类Unix操作系统,是一个基于POSIX和Unix的多用户、多任务、支持多线程和多CPU的操作系统。它能运行主要的Unix工具软件、应用程序和网络协议。它支持32位和64位硬件。Linux继承了Unix以网络为核心的设计思想,是一个性能稳定的多用户网络操作系统。
Unix和Linux有什么区别?
Linux和Unix都是功能强大的操作系统,都是应用广泛的服务器操作系统,有很多相似之处,甚至有一部分人错误地认为Unix和Linux操作系统是一样的,然而,事实并非如此,以下是两者的区别。
1、开源性
Linux是一款开源操作系统,不需要付费,即可使用;Unix是一款对源码实行知识产权保护的传统商业软件,使用需要付费授权使用。
2、跨平台性
Linux操作系统具有良好的跨平台性能,可运行在多种硬件平台上;Unix操作系统跨平台性能较弱,大多需与硬件配套使用。
3、可视化界面
Linux除了进行命令行操作,还有窗体管理系统;Unix只是命令行下的系统。
4、硬件环境
Linux操作系统对硬件的要求较低,安装方法更易掌握;Unix对硬件要求比较苛刻,按照难度较大。
5、用户群体
Linux的用户群体很广泛,个人和企业均可使用;Unix的用户群体比较窄,多是安全性要求高的大型企
业使用,如银行、电信部门等,或者Unix硬件厂商使用,如Sun等。
相比于Unix操作系统,Linux操作系统更受广大计算机爱好者的喜爱,主要原因是Linux操作系统具有Unix操作系统的全部功能,并且能够在普通PC计算机上实现全部的Unix特性,开源免费的特性,更容易
普及使用!
什么是 Linux 内核?
Linux 系统的核心是内核。内核控制着计算机系统上的所有硬件和软件,在必要时分配硬件,并根据需要执行软件。
- 系统内存管理
- 应用程序管理
- 硬件设备管理
- 文件系统管理
Linux的基本组件是什么?
就像任何其他典型的操作系统一样,Linux拥有所有这些组件:内核,shell和GUI,系统实用程序和应用程序。Linux比其他操作系统更具优势的是每个方面都附带其他功能,所有代码都可以免费下载。
Linux 的体系结构
从大的方面讲,Linux 体系结构可以分为两块:
1、用户空间(User Space) :用户空间又包括用户的应用程序(User Applications)、C 库(C Library) 。
2、内核空间(Kernel Space) :内核空间又包括系统调用接口(System Call Interface)、内核(Kernel)、平
台架构相关的代码(Architecture-Dependent Kernel Code) 。
为什么 Linux 体系结构要分为用户空间和内核空间的原因?
1、现代 CPU 实现了不同的工作模式,不同模式下 CPU 可以执行的指令和访问的寄存器不同。
2、Linux 从 CPU 的角度出发,为了保护内核的安全,把系统分成了两部分。
用户空间和内核空间是程序执行的两种不同的状态,我们可以通过两种方式完成用户空间到内核空间的
转移:1)系统调用;2)硬件中断。
BASH和DOS之间的基本区别是什么?
BASH和DOS控制台之间的主要区别在于3个方面:
1、BASH命令区分大小写,而DOS命令则不区分;
2、在BASH下,/ character是目录分隔符,\作为转义字符。在DOS下,/用作命令参数分隔符,\是目录分隔符
3、DOS遵循命名文件中的约定,即8个字符的文件名后跟一个点,扩展名为3个字符。BASH没有遵循这样的惯例。
Linux 开机启动过程?
1、主机加电自检,加载 BIOS 硬件信息。
2、读取 MBR 的引导文件(GRUB、LILO)。
3、引导 Linux 内核。
4、运行第一个进程 init (进程号永远为 1 )。
5、进入相应的运行级别。
6、运行终端,输入用户名和密码。
Linux系统缺省的运行级别?
- 关机。
- 单机用户模式。
- 字符界面的多用户模式(不支持网络)。
- 字符界面的多用户模式。
- 未分配使用。
- 图形界面的多用户模式。
- 重启。
Linux 使用的进程间通信方式?
1、管道(pipe)、流管道(s_pipe)、有名管道(FIFO)。
2、信号(signal) 。
3、消息队列。
4、共享内存。
5、信号量。
6、套接字(socket) 。
Linux 有哪些系统日志文件?
比较重要的是 /var/log/messages 日志文件。
该日志文件是许多进程日志文件的汇总,从该文件可以看出任何入侵企图或成功的入侵。
另外,如果胖友的系统里有 ELK 日志集中收集,它也会被收集进去。
Linux系统安装多个桌面环境有帮助吗?
通常,一个桌面环境,如KDE或Gnome,足以在没有问题的情况下运行。尽管系统允许从一个环境切换到另一个环境,但这对用户来说都是优先考虑的问题。有些程序在一个环境中工作而在另一个环境中无法工作,因此它也可以被视为选择使用哪个环境的一个因素。
什么是交换空间?
交换空间是Linux使用的一定空间,用于临时保存一些并发运行的程序。当RAM没有足够的内存来容纳正在执行的所有程序时,就会发生这种情况。
什么是root帐户
root帐户就像一个系统管理员帐户,允许你完全控制系统。你可以在此处创建和维护用户帐户,为每个帐户分配不同的权限。每次安装Linux时都是默认帐户。
什么是LILO?
LILO是Linux的引导加载程序。它主要用于将Linux操作系统加载到主内存中,以便它可以开始运行。
什么是BASH?
BASH是Bourne Again SHell的缩写。它由Steve Bourne编写,作为原始Bourne Shell(由/ bin / sh表示)的替代品。它结合了原始版本的Bourne Shell的所有功能,以及其他功能,使其更容易使用。从那以后,它已被改编为运行Linux的大多数系统的默认shell。
什么是CLI?
命令行界面(英语:command-line interface,缩写]:CLI)是在图形用户界面得到普及之前使用最为广泛的用户界面,它通常不支持鼠标,用户通过键盘输入指令,计算机接收到指令后,予以执行。也有人称之为字符用户界面(CUI)。
通常认为,命令行界面(CLI)没有图形用户界面(GUI)那么方便用户操作。因为,命令行界面的软件通常需要用户记忆操作的命令,但是,由于其本身的特点,命令行界面要较图形用户界面节约计算机系统的资源。在熟记命令的前提下,使用命令行界面往往要较使用图形用户界面的操作速度要快。所以,图形用户界面的操作系统中,都保留着可选的命令行界面。
什么是GUI?
图形用户界面(Graphical User Interface,简称 GUI,又称图形用户接口)是指采用图形方式显示的计算机操作用户界面。
图形用户界面是一种人与计算机通信的界面显示格式,允许用户使用鼠标等输入设备操纵屏幕上的图标或菜单选项,以选择命令、调用文件、启动程序或执行其它一些日常任务。与通过键盘输入文本或字符命令来完成例行任务的字符界面相比,图形用户界面有许多优点。
开源的优势是什么?
开源允许你将软件(包括源代码)免费分发给任何感兴趣的人。然后,人们可以添加功能,甚至可以调试和更正源代码中的错误。它们甚至可以让它运行得更好,然后再次自由地重新分配这些增强的源代码。这最终使社区中的每个人受益。
GNU项目的重要性是什么?
这种所谓的自由软件运动具有多种优势,例如可以自由地运行程序以及根据你的需要自由学习和修改程序。它还允许你将软件副本重新分发给其他人,以及自由改进软件并将其发布给公众。
磁盘、目录、文件
简单 Linux 文件系统?
在 Linux 操作系统中,所有被操作系统管理的资源,例如网络接口卡、磁盘驱动器、打印机、输入输出设备、普通文件或是目录都被看作是一个文件。
也就是说在 Linux 系统中有一个重要的概念:一切都是文件。其实这是 Unix 哲学的一个体现,而 Linux 是重写 Unix 而来,所以这个概念也就传承了下来。在 Unix 系统中,把一切资源都看作是文件,包括硬件设备。UNIX系统把每个硬件都看成是一个文件,通常称为设备文件,这样用户就可以用读写文件的方式实现对硬件的访问。
Linux 支持 5 种文件类型,如下图所示:

Linux 的目录结构是怎样的?
Linux 文件系统的结构层次鲜明,就像一棵倒立的树,最顶层是其根目录:

常见目录说明:
/bin: 存放二进制可执行文件(ls,cat,mkdir等),常用命令一般都在这里;
/etc: 存放系统管理和配置文件;
/home: 存放所有用户文件的根目录,是用户主目录的基点,比如用户user的主目录就
是/home/user,可以用~user表示;
/usr : 用于存放系统应用程序;
/opt: 额外安装的可选应用程序包所放置的位置。一般情况下,我们可以把tomcat等都安装到这里;
/proc: 虚拟文件系统目录,是系统内存的映射。可直接访问这个目录来获取系统信息;
/root: 超级用户(系统管理员)的主目录(特权阶级o);
/sbin: 存放二进制可执行文件,只有root才能访问。这里存放的是系统管理员使用的系统级别的管理命
令和程序。如ifconfig等;
/dev: 用于存放设备文件;
/mnt: 系统管理员安装临时文件系统的安装点,系统提供这个目录是让用户临时挂载其他的文件系统;
/boot: 存放用于系统引导时使用的各种文件;
/lib : 存放着和系统运行相关的库文件 ;
/tmp: 用于存放各种临时文件,是公用的临时文件存储点;
/var: 用于存放运行时需要改变数据的文件,也是某些大文件的溢出区,比方说各种服务的日志文件
(系统启动日志等。)等;
/lost+found: 这个目录平时是空的,系统非正常关机而留下“无家可归”的文件(windows下叫什
么.chk)就在这里。
什么是 inode ?
理解inode,要从文件储存说起。
文件储存在硬盘上,硬盘的最小存储单位叫做"扇区"(Sector)。每个扇区储存512字节(相当于0.5KB)。
操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个"块"(block)。这种由多个扇区组成的"块",是文件存取的最小单位。"块"的大小,最常见的是4KB,即连续八个 sector组成一个 block。
文件数据都储存在"块"中,那么很显然,我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为"索引节点"。
每一个文件都有对应的inode,里面包含了与该文件有关的一些信息。
简述 Linux 文件系统通过 i 节点把文件的逻辑结构和物理结构转换的工作过程?
Linux 通过 inode 节点表将文件的逻辑结构和物理结构进行转换。
inode 节点是一个 64 字节长的表,表中包含了文件的相关信息,其中有文件的大小、文件所有者、文件的存取许可方式以及文件的类型等重要信息。在 inode 节点表中最重要的内容是磁盘地址表。在磁盘地址表中有 13 个块号,文件将以块号在磁盘地址表中出现的顺序依次读取相应的块。
Linux 文件系统通过把 inode 节点和文件名进行连接,当需要读取该文件时,文件系统在当前目录表中查找该文件名对应的项,由此得到该文件相对应的 inode 节点号,通过该 inode 节点的磁盘地址表把分散存放的文件物理块连接成文件的逻辑结构。
什么是硬链接和软链接?
1)硬链接
由于 Linux 下的文件是通过索引节点(inode)来识别文件,硬链接可以认为是一个指针,指向文件索引节点的指针,系统并不为它重新分配 inode 。每添加一个一个硬链接,文件的链接数就加 1 。
不足:
1)不可以在不同文件系统的文件间建立链接;2)只有超级用户才可以为目录创建硬链接。
2)软链接
软链接克服了硬链接的不足,没有任何文件系统的限制,任何用户可以创建指向目录的符号链接。因而现在更为广泛使用,它具有更大的灵活性,甚至可以跨越不同机器、不同网络对文件进行链接。
不足:因为链接文件包含有原文件的路径信息,所以当原文件从一个目录下移到其他目录中,再访问链接文件,系统就找不到了,而硬链接就没有这个缺陷,你想怎么移就怎么移;还有它要系统分配额外的空间用于建立新的索引节点和保存原文件的路径。
实际场景下,基本是使用软链接。总结区别如下:
1、硬链接不可以跨分区,软件链可以跨分区。
2、硬链接指向一个 inode 节点,而软链接则是创建一个新的 inode 节点。
3、删除硬链接文件,不会删除原文件,删除软链接文件,会把原文件删除。
RAID 是什么?
RAID 全称为独立磁盘冗余阵列(Redundant Array of Independent Disks),基本思想就是把多个相对便宜的硬盘组合起来,成为一个硬盘阵列组,使性能达到甚至超过一个价格昂贵、 容量巨大的硬盘。RAID通常被用在服务器电脑上,使用完全相同的硬盘组成一个逻辑扇区,因此操作系统只会把它当做一个硬盘。
RAID 分为不同的等级,各个不同的等级均在数据可靠性及读写性能上做了不同的权衡。在实际应用中,可以依据自己的实际需求选择不同的 RAID 方案。
当然,因为很多公司都使用云服务,大家很难接触到 RAID 这个概念,更多的可能是普通云盘、SSD 云盘酱紫的概念。
安全
一台 Linux 系统初始化环境后需要做一些什么安全工作?
1、添加普通用户登陆,禁止 root 用户登陆,更改 SSH 端口号。
(修改 SSH 端口不一定绝对哈。当然,如果要暴露在外网,建议改下。)
2、服务器使用密钥登陆,禁止密码登陆。
3、开启防火墙,关闭 SElinux ,根据业务需求设置相应的防火墙规则。
4、装 fail2ban 这种防止 SSH 暴力破击的软件。
5、设置只允许公司办公网出口 IP 能登陆服务器(看公司实际需要)
(也可以安装 VPN 等软件,只允许连接 VPN 到服务器上。)
6、修改历史命令记录的条数为 10 条。
7、只允许有需要的服务器可以访问外网,其它全部禁止。
8、做好软件层面的防护。
8.1 设置 nginx_waf 模块防止 SQL 注入。
8.2 把 Web 服务使用 www 用户启动,更改网站目录的所有者和所属组为 www 。
什么叫 CC 攻击?什么叫 DDOS 攻击?
CC 攻击,主要是用来攻击页面的,模拟多个用户不停的对你的页面进行访问,从而使你的系统资源消耗殆尽。
DDOS 攻击,中文名叫分布式拒绝服务攻击,指借助服务器技术将多个计算机联合起来作为攻击平台,来对一个或多个目标发动 DDOS 攻击。
怎么预防 CC 攻击和 DDOS 攻击?
防 CC、DDOS 攻击,这些只能是用硬件防火墙做流量清洗,将攻击流量引入黑洞。
流量清洗这一块,主要是买 ISP 服务商的防攻击的服务就可以,机房一般有空余流量,我们一般是买服务,毕竟攻击不会是持续长时间。
什么是网站数据库注入?
由于程序员的水平及经验参差不齐,大部分程序员在编写代码的时候,没有对用户输入数据的合法性进
行判断。
应用程序存在安全隐患。用户可以提交一段数据库查询代码,根据程序返回的结果,获得某些他想得知的数据,这就是所谓的 SQL 注入。
SQL注入,是从正常的 WWW 端口访问,而且表面看起来跟一般的 Web 页面访问没什么区别,如果管理员没查看日志的习惯,可能被入侵很长时间都不会发觉。
如何过滤与预防?
数据库网页端注入这种,可以考虑使用 nginx_waf 做过滤与预防。
Shell
Shell 脚本是什么?
一个 Shell 脚本是一个文本文件,包含一个或多个命令。作为系统管理员,我们经常需要使用多个命令来完成一项任务,我们可以添加这些所有命令在一个文本文件(Shell 脚本)来完成这些日常工作任务。
什么是默认登录 Shell ?
在 Linux 操作系统,“/bin/bash” 是默认登录 Shell,是在创建用户时分配的。
使用 chsh 命令可以改变默认的 Shell 。示例如下所示:
## chsh <用户名> -s <新shell>
## chsh ThinkWon -s /bin/sh
在 Shell 脚本中,如何写入注释?
注释可以用来描述一个脚本可以做什么和它是如何工作的。每一行注释以 # 开头。例子如下:
#!/bin/bash
## This is a command
echo “I am logged in as $USER”
语法级
可以在 Shell 脚本中使用哪些类型的变量?
在 Shell 脚本,我们可以使用两种类型的变量:
系统定义变量
系统变量是由系统系统自己创建的。这些变量通常由大写字母组成,可以通过 set 命令查看。
用户定义变量
用户变量由系统用户来生成和定义,变量的值可以通过命令 “echo $<变量名>” 查看。
Shell脚本中 $? 标记的用途是什么?
在写一个 Shell 脚本时,如果你想要检查前一命令是否执行成功,在 if 条件中使用 $? 可以来检查前一命令的结束状态。
如果结束状态是 0 ,说明前一个命令执行成功。例如:
root@localhost:~## ls /usr/bin/shar
/usr/bin/shar
root@localhost:~## echo $?
0
如果结束状态不是0,说明命令执行失败。例如:
root@localhost:~## ls /usr/bin/share
ls: cannot access /usr/bin/share: No such file or directory
root@localhost:~## echo $?
2
Bourne Shell(bash) 中有哪些特殊的变量?
下面的表列出了 Bourne Shell 为命令行设置的特殊变量。
内建变量 解释
$0 命令行中的脚本名字
$1 第一个命令行参数
$2 第二个命令行参数
….. …….
$9 第九个命令行参数
$## 命令行参数的数量
$* 所有命令行参数,以空格隔开
如何取消变量或取消变量赋值?
unset 命令用于取消变量或取消变量赋值。语法如下所示:
## unset <变量名>
Shell 脚本中 if 语法如何嵌套?
if [ 条件 ]
then
命令1
命令2
…..
else
if [ 条件 ]
then
命令1
命令2
….
else
命令1
命令2
…..
fi
fi
在 Shell 脚本中如何比较两个数字?
在 if-then 中使用测试命令( -gt 等)来比较两个数字。例如:
#!/bin/bash
x=10
y=20
if [ $x -gt $y ]
then
echo “x is greater than y”
else
echo “y is greater than x”
fi
Shell 脚本中 case 语句的语法?
基础语法如下:
case 变量 in
值1)
命令1
命令2
…..
最后命令
!!
值2)
命令1
命令2
……
最后命令
;;
esac
Shell 脚本中 for 循环语法?
基础语法如下:
for 变量 in 循环列表
do
命令1
命令2
….
最后命令
done
Shell 脚本中 while 循环语法?
如同 for 循环,while 循环只要条件成立就重复它的命令块。
不同于 for循环,while 循环会不断迭代,直到它的条件不为真。
基础语法:
while [ 条件 ]
do
命令…
done
do-while 语句的基本格式?
do-while 语句类似于 while 语句,但检查条件语句之前先执行命令(LCTT 译注:意即至少执行一次。)。下面是用 do-while 语句的语法:
do
{
命令
} while (条件)
Shell 脚本中 break 命令的作用?
break 命令一个简单的用途是退出执行中的循环。我们可以在 while 和 until 循环中使用 break 命令跳出循环。
Shell 脚本中 continue 命令的作用?
continue 命令不同于 break 命令,它只跳出当前循环的迭代,而不是整个循环。continue 命令很多时候是很有用的,例如错误发生,但我们依然希望继续执行大循环的时候。
如何使脚本可执行?
使用 chmod 命令来使脚本可执行。例子如下:chmod a+x myscript.sh 。
#!/bin/bash 的作用?
#!/bin/bash 是 Shell 脚本的第一行,称为释伴(shebang)行。
这里 # 符号叫做 hash ,而 ! 叫做 bang。
它的意思是命令通过 /bin/bash 来执行。
如何调试 Shell脚本?
使用 -x’ 数(sh -x myscript.sh)可以调试 Shell脚本。
另一个种方法是使用 -nv 参数(sh -nv myscript.sh)。
如何将标准输出和错误输出同时重定向到同一位置?
方法一:2>&1 (如## ls /usr/share/doc > out.txt 2>&1 ) 。
方法二:&> (如## ls /usr/share/doc &> out.txt ) 。
在 Shell 脚本中,如何测试文件?
test 命令可以用来测试文件。基础用法如下表格:
Test 用法
-d 文件名 如果文件存在并且是目录,返回true
-e 文件名 如果文件存在,返回true
-f 文件名 如果文件存在并且是普通文件,返回true
-r 文件名 如果文件存在并可读,返回true
-s 文件名 如果文件存在并且不为空,返回true
-w 文件名 如果文件存在并可写,返回true
-x 文件名 如果文件存在并可执行,返回true
在 Shell 脚本如何定义函数呢?
函数是拥有名字的代码块。当我们定义代码块,我们就可以在我们的脚本调用函数名字,该块就会被执行。示例如下所示:
$ diskusage () { df -h ; }
译注:下面是我给的shell函数语法,原文没有
[ function ] 函数名 [()]
{
命令;
[return int;]
}
如何让 Shell 就脚本得到来自终端的输入?
read 命令可以读取来自终端(使用键盘)的数据。read 命令得到用户的输入并置于你给出的变量中。例子如下:
## vi /tmp/test.sh
#!/bin/bash
echo ‘Please enter your name’
read name
echo “My Name is $name”
## ./test.sh
Please enter your name
ThinkWon
My Name is ThinkWon
如何执行算术运算?
有两种方法来执行算术运算:
1、使用 expr 命令:## expr 5 + 2 。
2、用一个美元符号和方括号( [ 表达式 ] ): t e s t = [ 表达式 ]):test= [表达式]):test=[16 + 4] ; test=$[16 + 4] 。
编程题
判断一文件是不是字符设备文件,如果是将其拷贝到 /dev 目录下?
#!/bin/bash
read -p "Input file name: " FILENAME
if [ -c "$FILENAME" ];then
cp $FILENAME /dev
fi
添加一个新组为 class1 ,然后添加属于这个组的 30 个用户,用户名的形式为 stdxx ,其中 xx 从 01 到 30 ?
#!/bin/bash
groupadd class1
for((i=1;i<31;i++))
do
if [ $i -le 10 ];then
useradd -g class1 std0$i
else
useradd -g class1 std$i
fi
done
编写 Shell 程序,实现自动删除 50 个账号的功能,账号名为stud1 至 stud50 ?
#!/bin/bash
for((i=1;i<51;i++))
do
userdel -r stud$i
done
写一个 sed 命令,修改 /tmp/input.txt 文件的内容?
要求:
删除所有空行。
一行中,如果包含 “11111”,则在 “11111” 前面插入 “AAA”,在 “11111” 后面插入 “BBB” 。比如:将内
容为 0000111112222 的一行改为 0000AAA11111BBB2222 。
[root@~]## cat -n /tmp/input.txt
1 000011111222
2
3 000011111222222
4 11111000000222
5
6
7 111111111111122222222222
8 2211111111
9 112222222
10 1122
11
## 删除所有空行命令
[root@~]## sed '/^$/d' /tmp/input.txt
000011111222
000011111222222
11111000000222
111111111111122222222222
2211111111
112222222
1122
## 插入指定的字符
[root@~]## sed 's#\(11111\)#AAA\1BBB#g' /tmp/input.txt
0000AAA11111BBB222
0000AAA11111BBB222222
AAA11111BBB000000222
AAA11111BBBAAA11111BBB11122222222222
22AAA11111BBB111
112222222
1122
实战
如何选择 Linux 操作系统版本?
一般来讲,桌面用户首选 Ubuntu ;服务器首选 RHEL 或 CentOS ,两者中首选 CentOS 。
根据具体要求:
1、安全性要求较高,则选择 Debian 或者 FreeBSD 。
2、需要使用数据库高级服务和电子邮件网络应用的用户可以选择 SUSE 。
3、想要新技术新功能可以选择 Feddora ,Feddora 是 RHEL 和 CentOS 的一个测试版和预发布版本。
【重点】根据现有状况,绝大多数互联网公司选择 CentOS 。现在比较常用的是 6 系列,现在市场占有大概一半左右。另外的原因是 CentOS 更侧重服务器领域,并且无版权约束。
如何规划一台 Linux 主机,步骤是怎样?
1、确定机器是做什么用的,比如是做 WEB 、DB、还是游戏服务器。
2、确定好之后,就要定系统需要怎么安装,默认安装哪些系统、分区怎么做。
3、需要优化系统的哪些参数,需要创建哪些用户等等的。
请问当用户反馈网站访问慢,你会如何处理?
1、服务器出口带宽不够用
本身服务器购买的出口带宽比较小。一旦并发量大的话,就会造成分给每个用户的出口带宽就小,访问速度自然就会慢。
跨运营商网络导致带宽缩减。例如,公司网站放在电信的网络上,那么客户这边对接是长城宽带或联通,这也可能导致带宽的缩减。
2、服务器负载过大,导致响应不过来
可以从两个方面入手分析:
分析系统负载,使用 w 命令或者 uptime 命令查看系统负载。如果负载很高,则使用 top 命令查看 CPU,MEM 等占用情况,要么是 CPU 繁忙,要么是内存不够。
如果这二者都正常,再去使用 sar 命令分析网卡流量,分析是不是遭到了攻击。一旦分析出问题的原因,采取对应的措施解决,如决定要不要杀死一些进程,或者禁止一些访问等。
3、数据库瓶颈
如果慢查询比较多。那么就要开发人员或 DBA 协助进行 SQL 语句的优化。
如果数据库响应慢,考虑可以加一个数据库缓存,如 Redis 等。然后,也可以搭建 MySQL 主从,一台MySQL 服务器负责写,其他几台从数据库负责读。
4、网站开发代码没有优化好
例如 SQL 语句没有优化,导致数据库读写相当耗时。
针对网站访问慢,怎么去排查?
1、首先要确定是用户端还是服务端的问题。当接到用户反馈访问慢,那边自己立即访问网站看看,如果自己这边访问快,基本断定是用户端问题,就需要耐心跟客户解释,协助客户解决问题。
2、如果访问也慢,那么可以利用浏览器的调试功能,看看加载那一项数据消耗时间过多,是图片加载慢,还是某些数据加载慢。
3、针对服务器负载情况。查看服务器硬件(网络、CPU、内存)的消耗情况。如果是购买的云主机,比如阿里云,可以登录阿里云平台提供各方面的监控,比如CPU、内存、带宽的使用情况。
4、如果发现硬件资源消耗都不高,那么就需要通过查日志,比如看看 MySQL慢查询的日志,看看是不是某条 SQL 语句查询慢,导致网站访问慢。
如何去解决?
1、如果是出口带宽问题,那么久申请加大出口带宽。
2、如果慢查询比较多,那么就要开发人员或 DBA 协助进行 SQL 语句的优化。
3、如果数据库响应慢,考虑可以加一个数据库缓存,如Redis 等等。然后也可以搭建MySQL 主从,一台 MySQL 服务器负责写,其他几台从数据库负责读。
4、申请购买 CDN 服务,加载用户的访问。
5、如果访问还比较慢,那就需要从整体架构上进行优化咯。做到专角色专用,多台服务器提供同一个服务。
Linux 性能调优都有哪几种方法?
1、Disabling daemons (关闭 daemons)。
2、Shutting down the GUI (关闭 GUI)。
3、Changing kernel parameters (改变内核参数)。
4、Kernel parameters (内核参数)。
5、Tuning the processor subsystem (处理器子系统调优)。
6、Tuning the memory subsystem (内存子系统调优)。
7、Tuning the file system (文件系统子系统调优)。
8、Tuning the network subsystem(网络子系统调优)。
文件管理命令
cat 命令
cat 命令用于连接文件并打印到标准输出设备上。
cat 主要有三大功能:
1.一次显示整个文件:
cat filename
2.从键盘创建一个文件:
cat > filename
只能创建新文件,不能编辑已有文件。
3.将几个文件合并为一个文件:
cat file1 file2 > file
-b 对非空输出行号
-n 输出所有行号
实例:
(1)把 log2012.log 的文件内容加上行号后输入 log2013.log 这个文件里
cat -n log2012.log log2013.log
(2)把 log2012.log 和 log2013.log 的文件内容加上行号(空白行不加)之后将内容附加到 log.log 里
cat -b log2012.log log2013.log log.log
(3)使用 here doc 生成新文件
at >log.txt <<EOF
>Hello
>World
>PWD=$(pwd)
>EOF
ls -l log.txt
cat log.txt
Hello
World
PWD=/opt/soft/test
(4)反向列示
tac log.txt
PWD=/opt/soft/test
World
Hello
chmod 命令
Linux/Unix 的文件调用权限分为三级 : 文件拥有者、群组、其他。利用 chmod 可以控制文件如何被他人所调用。
用于改变 linux 系统文件或目录的访问权限。用它控制文件或目录的访问权限。该命令有两种用法。一种是包含字母和操作符表达式的文字设定法;另一种是包含数字的数字设定法。
每一文件或目录的访问权限都有三组,每组用三位表示,分别为文件属主的读、写和执行权限;与属主同组的用户的读、写和执行权限;系统中其他用户的读、写和执行权限。可使用 ls -l test.txt 查找。
以文件 log2012.log 为例:
-rw-r--r-- 1 root root 296K 11-13 06:03 log2012.log
第一列共有 10 个位置,第一个字符指定了文件类型。在通常意义上,一个目录也是一个文件。如果第一个字符是横线,表示是一个非目录的文件。如果是 d,表示是一个目录。从第二个字符开始到第十个9 个字符,3 个字符一组,分别表示了 3 组用户对文件或者目录的权限。权限字符用横线代表空许可,r 代表只读,w 代表写,x 代表可执行。
常用参数:
-c 当发生改变时,报告处理信息
-R 处理指定目录以及其子目录下所有文件
权限范围:
u :目录或者文件的当前的用户
g :目录或者文件的当前的群组
o :除了目录或者文件的当前用户或群组之外的用户或者群组
a :所有的用户及群组
权限代号:
r :读权限,用数字4表示
w :写权限,用数字2表示
x :执行权限,用数字1表示
- :删除权限,用数字0表示
s :特殊权限
实例:
(1)增加文件 t.log 所有用户可执行权限
chmod a+x t.log
(2)撤销原来所有的权限,然后使拥有者具有可读权限,并输出处理信息
chmod u=r t.log -c
(3)给 file 的属主分配读、写、执行(7)的权限,给file的所在组分配读、执行(5)的权限,给其他用户分配执行(1)的权限
chmod 751 t.log -c(或者:chmod u=rwx,g=rx,o=x t.log -c)
(4)将 test 目录及其子目录所有文件添加可读权限
chmod u+r,g+r,o+r -R text/ -c
chown 命令
chown 将指定文件的拥有者改为指定的用户或组,用户可以是用户名或者用户 ID;组可以是组名或者组ID;文件是以空格分开的要改变权限的文件列表,支持通配符。
-c 显示更改的部分的信息
-R 处理指定目录及子目录
实例:
(1)改变拥有者和群组 并显示改变信息
chown -c mail:mail log2012.log
(2)改变文件群组
chown -c :mail t.log
(3)改变文件夹及子文件目录属主及属组为 mail
chown -cR mail: test/
cp 命令
将源文件复制至目标文件,或将多个源文件复制至目标目录。
注意:命令行复制,如果目标文件已经存在会提示是否覆盖,而在 shell 脚本中,如果不加 -i 参数,则不会提示,而是直接覆盖!
-i 提示
-r 复制目录及目录内所有项目
-a 复制的文件与原文件时间一样
实例:
(1)复制 a.txt 到 test 目录下,保持原文件时间,如果原文件存在提示是否覆盖。
cp -ai a.txt test
(2)为 a.txt 建议一个链接(快捷方式)
cp -s a.txt link_a.txt
find 命令
用于在文件树中查找文件,并作出相应的处理。
命令格式:
find pathname -options [-print -exec -ok ...]
命令参数:
pathname: find命令所查找的目录路径。例如用.来表示当前目录,用/来表示系统根目录。
-print: find命令将匹配的文件输出到标准输出。
-exec: find命令对匹配的文件执行该参数所给出的shell命令。相应命令的形式为'command' { }
\;,注意{ }和\;之间的空格。
-ok: 和-exec的作用相同,只不过以一种更为安全的模式来执行该参数所给出的shell命令,在执行每一个
命令之前,都会给出提示,让用户来确定是否执行。
命令选项:
-name 按照文件名查找文件
-perm 按文件权限查找文件
-user 按文件属主查找文件
-group 按照文件所属的组来查找文件。
-type 查找某一类型的文件,诸如:
b - 块设备文件
d - 目录
c - 字符设备文件
l - 符号链接文件
p - 管道文件
f - 普通文件
实例:
(1)查找 48 小时内修改过的文件
find -atime -2
(2)在当前目录查找 以 .log 结尾的文件。 . 代表当前目录
find ./ -name '*.log'
(3)查找 /opt 目录下 权限为 777 的文件
find /opt -perm 777
(4)查找大于 1K 的文件
find -size +1000c
查找等于 1000 字符的文件
find -size 1000c
-exec 参数后面跟的是 command 命令,它的终止是以 ; 为结束标志的,所以这句命令后面的分号是不可缺少的,考虑到各个系统中分号会有不同的意义,所以前面加反斜杠。{} 花括号代表前面find查找出来的文件名。
head 命令
head 用来显示档案的开头至标准输出中,默认 head 命令打印其相应文件的开头 10 行。
常用参数:
-n<行数> 显示的行数(行数为复数表示从最后向前数)
实例:
(1)显示 1.log 文件中前 20 行
head 1.log -n 20
(2)显示 1.log 文件前 20 字节
head -c 20 log2014.log
(3)显示 t.log最后 10 行
head -n -10 t.log
less 命令
less 与 more 类似,但使用 less 可以随意浏览文件,而 more 仅能向前移动,却不能向后移动,而且less 在查看之前不会加载整个文件。
常用命令参数:
-i 忽略搜索时的大小写
-N 显示每行的行号
-o <文件名> 将less 输出的内容在指定文件中保存起来
-s 显示连续空行为一行
/字符串:向下搜索“字符串”的功能
?字符串:向上搜索“字符串”的功能
n:重复前一个搜索(与 / 或 ? 有关)
N:反向重复前一个搜索(与 / 或 ? 有关)
-x <数字> 将“tab”键显示为规定的数字空格
b 向后翻一页
d 向后翻半页
h 显示帮助界面
Q 退出less 命令
u 向前滚动半页
y 向前滚动一行
空格键 滚动一行
回车键 滚动一页
[pagedown]: 向下翻动一页
[pageup]: 向上翻动一页
实例:
(1)ps 查看进程信息并通过 less 分页显示
ps -aux | less -N
(2)查看多个文件
less 1.log 2.log
可以使用 n 查看下一个,使用 p 查看前一个。
ln 命令
功能是为文件在另外一个位置建立一个同步的链接,当在不同目录需要该问题时,就不需要为每一个目录创建同样的文件,通过 ln 创建的链接(link)减少磁盘占用量。
链接分类:软件链接及硬链接
软链接:
1.软链接,以路径的形式存在。类似于Windows操作系统中的快捷方式
2.软链接可以 跨文件系统 ,硬链接不可以
3.软链接可以对一个不存在的文件名进行链接
4.软链接可以对目录进行链接
硬链接:
1.硬链接,以文件副本的形式存在。但不占用实际空间。
2.不允许给目录创建硬链接
3.硬链接只有在同一个文件系统中才能创建
需要注意:
第一:ln命令会保持每一处链接文件的同步性,也就是说,不论你改动了哪一处,其它的文件都会发生相同的变化;
第二:ln的链接又分软链接和硬链接两种,软链接就是ln –s 源文件 目标文件,它只会在你选定的位置上生成一个文件的镜像,不会占用磁盘空间,硬链接 ln 源文件 目标文件,没有参数-s, 它会在你选定的位置上生成一个和源文件大小相同的文件,无论是软链接还是硬链接,文件都保持同步变化。
第三:ln指令用在链接文件或目录,如同时指定两个以上的文件或目录,且最后的目的地是一个已经存在的目录,则会把前面指定的所有文件或目录复制到该目录中。若同时指定多个文件或目录,且最后的目的地并非是一个已存在的目录,则会出现错误信息。
常用参数:
-b 删除,覆盖以前建立的链接
-s 软链接(符号链接)
-v 显示详细处理过程
实例:
(1)给文件创建软链接,并显示操作信息
ln -sv source.log link.log
(2)给文件创建硬链接,并显示操作信息
ln -v source.log link1.log
(3)给目录创建软链接
ln -sv /opt/soft/test/test3 /opt/soft/test/test5
locate 命令
locate 通过搜寻系统内建文档数据库达到快速找到档案,数据库由 updatedb 程序来更新,updatedb是由 cron daemon 周期性调用的。默认情况下 locate 命令在搜寻数据库时比由整个由硬盘资料来搜寻资料来得快,但较差劲的是 locate 所找到的档案若是最近才建立或 刚更名的,可能会找不到,在内定值中,updatedb 每天会跑一次,可以由修改 crontab 来更新设定值 (etc/crontab)。
locate 与 find 命令相似,可以使用如 *、? 等进行正则匹配查找
常用参数:
-l num(要显示的行数)
-f 将特定的档案系统排除在外,如将proc排除在外
-r 使用正则运算式做为寻找条件
实例:
(1)查找和 pwd 相关的所有文件(文件名中包含 pwd)
locate pwd
(2)搜索 etc 目录下所有以 sh 开头的文件
locate /etc/sh
(3)查找 /var 目录下,以 reason 结尾的文件
locate -r '^/var.*reason$'(其中.表示一个字符,*表示任务多个;.*表示任意多个字符)
more 命令
功能类似于 cat, more 会以一页一页的显示方便使用者逐页阅读,而最基本的指令就是按空白键(space)就往下一页显示,按 b 键就会往回(back)一页显示。
命令参数:
+n 从笫 n 行开始显示
-n 定义屏幕大小为n行
+/pattern 在每个档案显示前搜寻该字串(pattern),然后从该字串前两行之后开始显示
-c 从顶部清屏,然后显示
-d 提示“Press space to continue,’q’ to quit(按空格键继续,按q键退出)”,禁用响铃
功能
-l 忽略Ctrl+l(换页)字符
-p 通过清除窗口而不是滚屏来对文件进行换页,与-c选项相似
-s 把连续的多个空行显示为一行
-u 把文件内容中的下画线去掉
常用操作命令:
Enter 向下 n 行,需要定义。默认为 1 行
Ctrl+F 向下滚动一屏
空格键 向下滚动一屏
Ctrl+B 返回上一屏
= 输出当前行的行号
:f 输出文件名和当前行的行号
V 调用vi编辑器
!命令 调用Shell,并执行命令
q 退出more
实例:
(1)显示文件中从第3行起的内容
more +3 text.txt
(2)在所列出文件目录详细信息,借助管道使每次显示 5 行
ls -l | more -5
按空格显示下 5 行。
mv 命令
移动文件或修改文件名,根据第二参数类型(如目录,则移动文件;如为文件则重命令该文件)。
当第二个参数为目录时,第一个参数可以是多个以空格分隔的文件或目录,然后移动第一个参数指定的多个文件到第二个参数指定的目录中。
实例:
(1)将文件 test.log 重命名为 test1.txt
mv test.log test1.txt
(2)将文件 log1.txt,log2.txt,log3.txt 移动到根的 test3 目录中
mv llog1.txt log2.txt log3.txt /test3
(3)将文件 file1 改名为 file2,如果 file2 已经存在,则询问是否覆盖
mv -i log1.txt log2.txt
(4)移动当前文件夹下的所有文件到上一级目录
mv * ../
rm 命令
删除一个目录中的一个或多个文件或目录,如果没有使用 -r 选项,则 rm 不会删除目录。如果使用 rm来删除文件,通常仍可以将该文件恢复原状。
rm [选项] 文件…
实例:
(1)删除任何 .log 文件,删除前逐一询问确认:
rm -i *.log
(2)删除 test 子目录及子目录中所有档案删除,并且不用一一确认:
rm -rf test
(3)删除以 -f 开头的文件
rm -- -f*
tail 命令
用于显示指定文件末尾内容,不指定文件时,作为输入信息进行处理。常用查看日志文件。
常用参数:
-f 循环读取(常用于查看递增的日志文件)
-n<行数> 显示行数(从后向前)
(1)循环读取逐渐增加的文件内容
ping 127.0.0.1 > ping.log &
后台运行:可使用 jobs -l 查看,也可使用 fg 将其移到前台运行。
tail -f ping.log
(查看日志)
touch 命令
Linux touch命令用于修改文件或者目录的时间属性,包括存取时间和更改时间。若文件不存在,系统会建立一个新的文件。
ls -l 可以显示档案的时间记录。
语法
touch [-acfm][-d<日期时间>][-r<参考文件或目录>] [-t<日期时间>][--help][--version][文件
或目录…]
参数说明:
a 改变档案的读取时间记录。
m 改变档案的修改时间记录。
c 假如目的档案不存在,不会建立新的档案。与 --no-create 的效果一样。
f 不使用,是为了与其他 unix 系统的相容性而保留。
r 使用参考档的时间记录,与 --file 的效果一样。
d 设定时间与日期,可以使用各种不同的格式。
t 设定档案的时间记录,格式与 date 指令相同。
–no-create 不会建立新档案。
–help 列出指令格式。
–version 列出版本讯息。
实例
使用指令"touch"修改文件"testfile"的时间属性为当前系统时间,输入如下命令:
$ touch testfile #修改文件的时间属性
首先,使用ls命令查看testfile文件的属性,如下所示:
$ ls -l testfile #查看文件的时间属性
#原来文件的修改时间为16:09
-rw-r--r-- 1 hdd hdd 55 2011-08-22 16:09 testfile
执行指令"touch"修改文件属性以后,并再次查看该文件的时间属性,如下所示:
$ touch testfile #修改文件时间属性为当前系统时间
$ ls -l testfile #查看文件的时间属性
#修改后文件的时间属性为当前系统时间
-rw-r--r-- 1 hdd hdd 55 2011-08-22 19:53 testfile
使用指令"touch"时,如果指定的文件不存在,则将创建一个新的空白文件。例如,在当前目录下,使用
该指令创建一个空白文件"file",输入如下命令:
$ touch file #创建一个名为“file”的新的空白文件
vim 命令
Vim是从 vi 发展出来的一个文本编辑器。代码补完、编译及错误跳转等方便编程的功能特别丰富,在程序员中被广泛使用。
·打开文件并跳到第 10 行:vim +10 filename.txt 。
·打开文件跳到第一个匹配的行:vim +/search-term filename.txt 。
·以只读模式打开文件:vim -R /etc/passwd 。
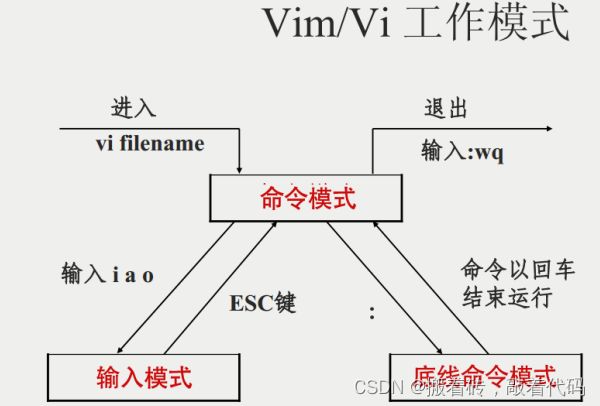
基本上 vi/vim 共分为三种模式,分别是命令模式(Command mode),输入模式(Insert mode)和
底线命令模式(Last line mode)。
简单的说,我们可以将这三个模式想成底下的图标来表示:
whereis 命令
whereis 命令只能用于程序名的搜索,而且只搜索二进制文件(参数-b)、man说明文件(参数-m)和源代码文件(参数-s)。如果省略参数,则返回所有信息。whereis 及 locate 都是基于系统内建的数据库进行搜索,因此效率很高,而find则是遍历硬盘查找文件。
常用参数:
-b 定位可执行文件。
-m 定位帮助文件。
-s 定位源代码文件。
-u 搜索默认路径下除可执行文件、源代码文件、帮助文件以外的其它文件。
实例:
(1)查找 locate 程序相关文件
whereis locate
(2)查找 locate 的源码文件
whereis -s locate
(3)查找 lcoate 的帮助文件
whereis -m locate
which 命令
在 linux 要查找某个文件,但不知道放在哪里了,可以使用下面的一些命令来搜索:
which 查看可执行文件的位置。
whereis 查看文件的位置。
locate 配合数据库查看文件位置。
find 实际搜寻硬盘查询文件名称。
which 是在 PATH 就是指定的路径中,搜索某个系统命令的位置,并返回第一个搜索结果。使用 which命令,就可以看到某个系统命令是否存在,以及执行的到底是哪一个位置的命令。
常用参数:
-n 指定文件名长度,指定的长度必须大于或等于所有文件中最长的文件名。
实例:
(1)查看 ls 命令是否存在,执行哪个
which ls
(2)查看 which
which which
(3)查看 cd
which cd(显示不存在,因为 cd 是内建命令,而 which 查找显示是 PATH 中的命令)
查看当前 PATH 配置:
echo $PATH
或使用 env 查看所有环境变量及对应值
文档编辑命令
grep 命令
强大的文本搜索命令,grep(Global Regular Expression Print) 全局正则表达式搜索。
grep 的工作方式是这样的,它在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。搜索的结果被送到标准输出,不影响原文件内容。
命令格式:
grep [option] pattern file|dir
常用参数:
-A n --after-context显示匹配字符后n行
-B n --before-context显示匹配字符前n行
-C n --context 显示匹配字符前后n行
-c --count 计算符合样式的列数
-i 忽略大小写
-l 只列出文件内容符合指定的样式的文件名称
-f 从文件中读取关键词
-n 显示匹配内容的所在文件中行数
-R 递归查找文件夹
grep 的规则表达式:
^ #锚定行的开始 如:'^grep'匹配所有以grep开头的行。
$ #锚定行的结束 如:'grep$'匹配所有以grep结尾的行。
. #匹配一个非换行符的字符 如:'gr.p'匹配gr后接一个任意字符,然后是p。
* #匹配零个或多个先前字符 如:'*grep'匹配所有一个或多个空格后紧跟grep的行。
.* #一起用代表任意字符。
[] #匹配一个指定范围内的字符,如'[Gg]rep'匹配Grep和grep。
[^] #匹配一个不在指定范围内的字符,如:'[^A-FH-Z]rep'匹配不包含A-R和T-Z的一个字母开头,紧跟
rep的行。
\(..\) #标记匹配字符,如'\(love\)',love被标记为1。
\< #锚定单词的开始,如:'\匹配包含以grep开头的单词的行。
\> #锚定单词的结束,如'grep\>'匹配包含以grep结尾的单词的行。
x\{m\} #重复字符x,m次,如:'0\{5\}'匹配包含5个o的行。
x\{m,\} #重复字符x,至少m次,如:'o\{5,\}'匹配至少有5个o的行。
x\{m,n\} #重复字符x,至少m次,不多于n次,如:'o\{5,10\}'匹配5--10个o的行。
\w #匹配文字和数字字符,也就是[A-Za-z0-9],如:'G\w*p'匹配以G后跟零个或多个文字或数字字
符,然后是p。
\W #\w的反置形式,匹配一个或多个非单词字符,如点号句号等。
\b #单词锁定符,如: '\bgrep\b'只匹配grep。
实例:
(1)查找指定进程
ps -ef | grep svn
(2)查找指定进程个数
ps -ef | grep svn -c
(3)从文件中读取关键词
cat test1.txt | grep -f key.log
(4)从文件夹中递归查找以grep开头的行,并只列出文件
grep -lR '^grep' /tmp
(5)查找非x开关的行内容
grep '^[^x]' test.txt
(6)显示包含 ed 或者 at 字符的内容行
grep -E 'ed|at' test.txt
wc 命令
wc(word count)功能为统计指定的文件中字节数、字数、行数,并将统计结果输出
命令格式:
wc [option] file..
命令参数:
-c 统计字节数
-l 统计行数
-m 统计字符数
-w 统计词数,一个字被定义为由空白、跳格或换行字符分隔的字符串
实例:
(1)查找文件的 行数 单词数 字节数 文件名
wc text.txt
结果:
7 8 70 test.txt
(2)统计输出结果的行数
cat test.txt | wc -l
磁盘管理命令
cd 命令
cd(changeDirectory) 命令语法:
cd [目录名]
说明:切换当前目录至 dirName。
实例:
(1)进入要目录
cd /
(2)进入 “home” 目录
cd ~
(3)进入上一次工作路径
cd -
(4)把上个命令的参数作为cd参数使用。
cd !$
df 命令
显示磁盘空间使用情况。获取硬盘被占用了多少空间,目前还剩下多少空间等信息,如果没有文件名被指定,则所有当前被挂载的文件系统的可用空间将被显示。默认情况下,磁盘空间将以 1KB 为单位进行显示,除非环境变量POSIXLY_CORRECT 被指定,那样将以512字节为单位进行显示:
-a 全部文件系统列表
-h 以方便阅读的方式显示信息
-i 显示inode信息
-k 区块为1024字节
-l 只显示本地磁盘
-T 列出文件系统类型
实例:
(1)显示磁盘使用情况
df -l
(2)以易读方式列出所有文件系统及其类型
df -haT
du 命令
du 命令也是查看使用空间的,但是与 df 命令不同的是 Linux du 命令是对文件和目录磁盘使用的空间的查看:
命令格式:
du [选项] [文件]
常用参数:
-a 显示目录中所有文件大小
-k 以KB为单位显示文件大小
-m 以MB为单位显示文件大小
-g 以GB为单位显示文件大小
-h 以易读方式显示文件大小
-s 仅显示总计
-c或--total 除了显示个别目录或文件的大小外,同时也显示所有目录或文件的总和
实例:
(1)以易读方式显示文件夹内及子文件夹大小
du -h scf/
(2)以易读方式显示文件夹内所有文件大小
du -ah scf/
(3)显示几个文件或目录各自占用磁盘空间的大小,还统计它们的总和
du -hc test/ scf/
(4)输出当前目录下各个子目录所使用的空间
du -hc --max-depth=1 scf/
ls命令
就是 list 的缩写,通过 ls 命令不仅可以查看 linux 文件夹包含的文件,而且可以查看文件权限(包括目录、文件夹、文件权限)查看目录信息等等。
常用参数搭配:
ls -a 列出目录所有文件,包含以.开始的隐藏文件
ls -A 列出除.及..的其它文件
ls -r 反序排列
ls -t 以文件修改时间排序
ls -S 以文件大小排序
ls -h 以易读大小显示
ls -l 除了文件名之外,还将文件的权限、所有者、文件大小等信息详细列出来
实例:
(1) 按易读方式按时间反序排序,并显示文件详细信息
ls -lhrt
(2) 按大小反序显示文件详细信息
ls -lrS
(3)列出当前目录中所有以"t"开头的目录的详细内容
ls -l t*
(4) 列出文件绝对路径(不包含隐藏文件)
ls | sed "s:^:`pwd`/:"
(5) 列出文件绝对路径(包含隐藏文件)
find $pwd -maxdepth 1 | xargs ls -ld
mkdir 命令
mkdir 命令用于创建文件夹。
可用选项:
-m: 对新建目录设置存取权限,也可以用 chmod 命令设置;
-p: 可以是一个路径名称。此时若路径中的某些目录尚不存在,加上此选项后,系统将自动建立好那些尚不在的目录,即一次可以建立多个目录。
实例:
(1)当前工作目录下创建名为 t的文件夹
mkdir t
(2)在 tmp 目录下创建路径为 test/t1/t 的目录,若不存在,则创建:
mkdir -p /tmp/test/t1/t
pwd 命令
pwd 命令用于查看当前工作目录路径。
实例:
(1)查看当前路径
pwd
(2)查看软链接的实际路径
pwd -P
rmdir 命令
从一个目录中删除一个或多个子目录项,删除某目录时也必须具有对其父目录的写权限。
注意:不能删除非空目录
实例:
(1)当 parent 子目录被删除后使它也成为空目录的话,则顺便一并删除:
rmdir -p parent/child/child11
网络通讯命令
ifconfig 命令
ifconfig 用于查看和配置 Linux 系统的网络接口。
查看所有网络接口及其状态:ifconfig -a 。
使用 up 和 down 命令启动或停止某个接口:ifconfig eth0 up 和 ifconfig eth0 down 。
iptables 命令
iptables ,是一个配置 Linux 内核防火墙的命令行工具。功能非常强大,对于我们开发来说,主要掌握如何开放端口即可。例如:
把来源 IP 为 192.168.1.101 访问本机 80 端口的包直接拒绝:iptables -I INPUT -s 192.168.1.101 -p tcp --dport 80 -j REJECT 。
开启 80 端口,因为web对外都是这个端口
iptables -A INPUT -p tcp --dport 80 -j ACCEP
另外,要注意使用 iptables save 命令,进行保存。否则,服务器重启后,配置的规则将丢失。
netstat 命令
Linux netstat命令用于显示网络状态。
利用netstat指令可让你得知整个Linux系统的网络情况。
语法
netstat [-acCeFghilMnNoprstuvVwx][-A<网络类型>][--ip]
参数说明:
-a或–all 显示所有连线中的Socket。
-A<网络类型>或–<网络类型> 列出该网络类型连线中的相关地址。
-c或–continuous 持续列出网络状态。
-C或–cache 显示路由器配置的快取信息。
-e或–extend 显示网络其他相关信息。
-F或–fib 显示FIB。
-g或–groups 显示多重广播功能群组组员名单。
-h或–help 在线帮助。
-i或–interfaces 显示网络界面信息表单。
-l或–listening 显示监控中的服务器的Socket。
-M或–masquerade 显示伪装的网络连线。
-n或–numeric 直接使用IP地址,而不通过域名服务器。
-N或–netlink或–symbolic 显示网络硬件外围设备的符号连接名称。
-o或–timers 显示计时器。
-p或–programs 显示正在使用Socket的程序识别码和程序名称。
-r或–route 显示Routing Table。
-s或–statistice 显示网络工作信息统计表。
-t或–tcp 显示TCP传输协议的连线状况。
-u或–udp 显示UDP传输协议的连线状况。
-v或–verbose 显示指令执行过程。
-V或–version 显示版本信息。
-w或–raw 显示RAW传输协议的连线状况。
-x或–unix 此参数的效果和指定"-A unix"参数相同。
–ip或–inet 此参数的效果和指定"-A inet"参数相同。
实例
如何查看系统都开启了哪些端口?
[root@centos6 ~ 13:20 #55]# netstat -lnp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:*
LISTEN 1035/sshd
tcp 0 0 :::22 :::*
LISTEN 1035/sshd
udp 0 0 0.0.0.0:68 0.0.0.0:*
931/dhclient
Active UNIX domain sockets (only servers)
Proto RefCnt Flags Type State I-Node PID/Program name
Path
unix 2 [ ACC ] STREAM LISTENING 6825 1/init
@/com/ubuntu/upstart
unix 2 [ ACC ] STREAM LISTENING 8429 1003/dbus-daemon
/var/run/dbus/system_bus_socket
如何查看网络连接状况?
[root@centos6 ~ 13:22 #58]# netstat -an
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address
State
tcp 0 0 0.0.0.0:22 0.0.0.0:*
LISTEN
tcp 0 0 192.168.147.130:22 192.168.147.1:23893
ESTABLISHED
tcp 0 0 :::22 :::*
LISTEN
udp 0 0 0.0.0.0:68 0.0.0.0:*
如何统计系统当前进程连接数?
输入命令 netstat -an | grep ESTABLISHED | wc -l 。
输出结果 177 。一共有 177 连接数。
用 netstat 命令配合其他命令,按照源 IP 统计所有到 80 端口的 ESTABLISHED 状态链接的个数?
严格来说,这个题目考验的是对 awk 的使用。
首先,使用 netstat -an|grep ESTABLISHED 命令。结果如下:
tcp 0 0 120.27.146.122:80 113.65.18.33:62721 ESTABLISHED
tcp 0 0 120.27.146.122:80 27.43.83.115:47148 ESTABLISHED
tcp 0 0 120.27.146.122:58838 106.39.162.96:443 ESTABLISHED
tcp 0 0 120.27.146.122:52304 203.208.40.121:443 ESTABLISHED
tcp 0 0 120.27.146.122:33194 203.208.40.122:443 ESTABLISHED
tcp 0 0 120.27.146.122:53758 101.37.183.144:443 ESTABLISHED
tcp 0 0 120.27.146.122:27017 23.105.193.30:50556 ESTABLISHED
ping 命令
Linux ping命令用于检测主机。
执行ping指令会使用ICMP传输协议,发出要求回应的信息,若远端主机的网络功能没有问题,就会回应该信息,因而得知该主机运作正常。
指定接收包的次数
ping -c 2 www.baidu.com
telnet 命令
Linux telnet命令用于远端登入。
执行telnet指令开启终端机阶段作业,并登入远端主机。
语法
telnet [-8acdEfFKLrx][-b<主机别名>][-e<脱离字符>][-k<域名>][-l<用户名称>][-n<记录文件>]
[-S<服务类型>][-X<认证形态>][主机名称或IP地址<通信端口>]
参数说明:
-8 允许使用8位字符资料,包括输入与输出。
-a 尝试自动登入远端系统。
-b<主机别名> 使用别名指定远端主机名称。
-c 不读取用户专属目录里的.telnetrc文件。
-d 启动排错模式。
-e<脱离字符> 设置脱离字符。
-E 滤除脱离字符。
-f 此参数的效果和指定"-F"参数相同。
-F 使用Kerberos V5认证时,加上此参数可把本地主机的认证数据上传到远端主机。
-k<域名> 使用Kerberos认证时,加上此参数让远端主机采用指定的领域名,而非该主机的域名。
-K 不自动登入远端主机。
-l<用户名称> 指定要登入远端主机的用户名称。
-L 允许输出8位字符资料。
-n<记录文件> 指定文件记录相关信息。
-r 使用类似rlogin指令的用户界面。
-S<服务类型> 设置telnet连线所需的IP TOS信息。
-x 假设主机有支持数据加密的功能,就使用它。
-X<认证形态> 关闭指定的认证形态。
实例
登录远程主机
登录IP为 192.168.0.5 的远程主机
telnet 192.168.0.5
系统管理命令
date 命令
显示或设定系统的日期与时间。
命令参数:
-d<字符串> 显示字符串所指的日期与时间。字符串前后必须加上双引号。
-s<字符串> 根据字符串来设置日期与时间。字符串前后必须加上双引号。
-u 显示GMT。
%H 小时(00-23)
%I 小时(00-12)
%M 分钟(以00-59来表示)
%s 总秒数。起算时间为1970-01-01 00:00:00 UTC。
%S 秒(以本地的惯用法来表示)
%a 星期的缩写。
%A 星期的完整名称。
%d 日期(以01-31来表示)。
%D 日期(含年月日)。
%m 月份(以01-12来表示)。
%y 年份(以00-99来表示)。
%Y 年份(以四位数来表示)。
实例:
(1)显示下一天
date +%Y%m%d --date="+1 day" //显示下一天的日期
(2)-d参数使用
date -d "nov 22" 今年的 11 月 22 日是星期三
date -d '2 weeks' 2周后的日期
date -d 'next monday' (下周一的日期)
date -d next-day +%Y%m%d(明天的日期)或者:date -d tomorrow +%Y%m%d
date -d last-day +%Y%m%d(昨天的日期) 或者:date -d yesterday +%Y%m%d
date -d last-month +%Y%m(上个月是几月)
date -d next-month +%Y%m(下个月是几月)
free 命令
显示系统内存使用情况,包括物理内存、交互区内存(swap)和内核缓冲区内存。
命令参数:
-b 以Byte显示内存使用情况
-k 以kb为单位显示内存使用情况
-m 以mb为单位显示内存使用情况
-g 以gb为单位显示内存使用情况
-s<间隔秒数> 持续显示内存
-t 显示内存使用总合
实例:
(1)显示内存使用情况
free
free -k
free -m
(2)以总和的形式显示内存的使用信息
free -t
(3)周期性查询内存使用情况
free -s 10
kill 命令
发送指定的信号到相应进程。不指定型号将发送SIGTERM(15)终止指定进程。如果任无法终止该程序
可用"-KILL" 参数,其发送的信号为SIGKILL(9) ,将强制结束进程,使用ps命令或者jobs 命令可以查看进程号。root用户将影响用户的进程,非root用户只能影响自己的进程。
常用参数:
-l 信号,若果不加信号的编号参数,则使用“-l”参数会列出全部的信号名称
-a 当处理当前进程时,不限制命令名和进程号的对应关系
-p 指定kill 命令只打印相关进程的进程号,而不发送任何信号
-s 指定发送信号
-u 指定用户
实例:
(1)先使用ps查找进程pro1,然后用kill杀掉
kill -9 $(ps -ef | grep pro1)
ps 命令
ps(process status),用来查看当前运行的进程状态,一次性查看,如果需要动态连续结果使用 top
linux上进程有5种状态:
1、运行(正在运行或在运行队列中等待)
2、中断(休眠中, 受阻, 在等待某个条件的形成或接受到信号)
3、不可中断(收到信号不唤醒和不可运行, 进程必须等待直到有中断发生)
4、僵死(进程已终止, 但进程描述符存在, 直到父进程调用wait4()系统调用后释放)
5、停止(进程收到SIGSTOP, SIGSTP, SIGTIN, SIGTOU信号后停止运行运行)
ps 工具标识进程的5种状态码:
D 不可中断 uninterruptible sleep (usually IO)
R 运行 runnable (on run queue)
S 中断 sleeping
T 停止 traced or stopped
Z 僵死 a defunct (”zombie”) process
命令参数:
-A 显示所有进程
a 显示所有进程
-a 显示同一终端下所有进程
c 显示进程真实名称
e 显示环境变量
f 显示进程间的关系
r 显示当前终端运行的进程
-aux 显示所有包含其它使用的进程
实例:
(1)显示当前所有进程环境变量及进程间关系
ps -ef
(2)显示当前所有进程
ps -A
(3)与grep联用查找某进程
ps -aux | grep apache
(4)找出与 cron 与 syslog 这两个服务有关的 PID 号码
ps aux | grep '(cron|syslog)'
rpm 命令
Linux rpm 命令用于管理套件。
rpm(redhat package manager) 原本是 Red Hat Linux 发行版专门用来管理 Linux 各项套件的程序,由于它遵循 GPL 规则且功能强大方便,因而广受欢迎。逐渐受到其他发行版的采用。RPM 套件管理方式的出现,让 Linux 易于安装,升级,间接提升了 Linux 的适用度。
查看系统自带jdk
rpm -qa | grep jdk
删除系统自带jdk
rpm -e --nodeps 查看jdk显示的数据
安装jdk
rpm -ivh jdk-7u80-linux-x64.rpm
top 命令
显示当前系统正在执行的进程的相关信息,包括进程 ID、内存占用率、CPU 占用率等
常用参数:
-c 显示完整的进程命令
-s 保密模式
-p <进程号> 指定进程显示
-n <次数>循环显示次数
实例:
top - 14:06:23 up 70 days, 16:44, 2 users, load average: 1.25, 1.32, 1.35
Tasks: 206 total, 1 running, 205 sleeping, 0 stopped, 0 zombie
Cpu(s): 5.9%us, 3.4%sy, 0.0%ni, 90.4%id, 0.0%wa, 0.0%hi, 0.2%si, 0.0%st
Mem: 32949016k total, 14411180k used, 18537836k free, 169884k buffers
Swap: 32764556k total, 0k used, 32764556k free, 3612636k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
28894 root 22 0 1501m 405m 10m S 52.2 1.3 2534:16 java
前五行是当前系统情况整体的统计信息区。
第一行,任务队列信息,同 uptime 命令的执行结果,具体参数说明情况如下:
14:06:23 — 当前系统时间
up 70 days, 16:44 — 系统已经运行了70天16小时44分钟(在这期间系统没有重启过的吆!)
2 users — 当前有2个用户登录系统
load average: 1.15, 1.42, 1.44 — load average后面的三个数分别是1分钟、5分钟、15分钟的负载情况。
load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了。
第二行,Tasks — 任务(进程),具体信息说明如下:
系统现在共有206个进程,其中处于运行中的有1个,205个在休眠(sleep),stoped状态的有0个,zombie状态(僵尸)的有0个。
第三行,cpu状态信息,具体属性说明如下:
5.9%us — 用户空间占用CPU的百分比。
3.4% sy — 内核空间占用CPU的百分比。
0.0% ni — 改变过优先级的进程占用CPU的百分比
90.4% id — 空闲CPU百分比
0.0% wa — IO等待占用CPU的百分比
0.0% hi — 硬中断(Hardware IRQ)占用CPU的百分比
0.2% si — 软中断(Software Interrupts)占用CPU的百分比
备注:在这里CPU的使用比率和windows概念不同,需要理解linux系统用户空间和内核空间的相关知识!
第四行,内存状态,具体信息如下:
32949016k total — 物理内存总量(32GB)
14411180k used — 使用中的内存总量(14GB)
18537836k free — 空闲内存总量(18GB)
169884k buffers — 缓存的内存量 (169M)
第五行,swap交换分区信息,具体信息说明如下:
32764556k total — 交换区总量(32GB)
0k used — 使用的交换区总量(0K)
32764556k free — 空闲交换区总量(32GB)
3612636k cached — 缓冲的交换区总量(3.6GB)
第六行,空行。
第七行以下:各进程(任务)的状态监控,项目列信息说明如下:
PID — 进程id
USER — 进程所有者
PR — 进程优先级
NI — nice值。负值表示高优先级,正值表示低优先级
VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
SHR — 共享内存大小,单位kb
S — 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
%CPU — 上次更新到现在的CPU时间占用百分比
%MEM — 进程使用的物理内存百分比
TIME+ — 进程使用的CPU时间总计,单位1/100秒
COMMAND — 进程名称(命令名/命令行)
top 交互命令
h 显示top交互命令帮助信息
c 切换显示命令名称和完整命令行
m 以内存使用率排序
P 根据CPU使用百分比大小进行排序
T 根据时间/累计时间进行排序
W 将当前设置写入~/.toprc文件中
o或者O 改变显示项目的顺序

将top的结果保存到文件中
top -d 2 -n 5 -b>test.txt
-d 时间间隔,单位是秒,上面的例子中,时间间隔是2秒。
-n 执行次数,上面的例子中,共执行5次top命令并将结果写入test.txt文件中。若不加此参数,top会一直执行。
-b 加上此参数以后,top的结果会以一定格式保存到文件中,文件内容显示时,格式会更加友好一些
可使用cat -n test.txt查看一下文件的内容。
如果需要记录的次数较多或时间较长,需要后台执行,可在命令后方加上&
top -d 5 -b >test &
yum 命令
yum( Yellow dog Updater, Modified)是一个在Fedora和RedHat以及SUSE中的Shell前端软件包管理器。
基於RPM包管理,能够从指定的服务器自动下载RPM包并且安装,可以自动处理依赖性关系,并且一次安装所有依赖的软体包,无须繁琐地一次次下载、安装。
yum提供了查找、安装、删除某一个、一组甚至全部软件包的命令,而且命令简洁而又好记。
1.列出所有可更新的软件清单命令:yum check-update
2.更新所有软件命令:yum update
3.仅安装指定的软件命令:yum install <package_name>
4.仅更新指定的软件命令:yum update <package_name>
5.列出所有可安裝的软件清单命令:yum list
6.删除软件包命令:yum remove <package_name>
7.查找软件包 命令:yum search
8.清除缓存命令:
yum clean packages: 清除缓存目录下的软件包
yum clean headers: 清除缓存目录下的 headers
yum clean oldheaders: 清除缓存目录下旧的 headers
yum clean, yum clean all (= yum clean packages; yum clean oldheaders) :清除缓存目录下的软
件包及旧的headers
实例
安装 pam-devel
[root@www ~]# yum install pam-devel
备份压缩命令
bzip2 命令
- 创建 *.bz2 压缩文件: bzip2 test.txt 。
- 解压 *.bz2 文件: bzip2 -d test.txt.bz2 。
gzip 命令
- 创建一个 *.gz 的压缩文件: gzip test.txt 。
- 解压 *.gz 文件: gzip -d test.txt.gz 。
- 显示压缩的比率: gzip -l *.gz。
tar 命令
用来压缩和解压文件。tar 本身不具有压缩功能,只具有打包功能,有关压缩及解压是调用其它的功能来完成。
弄清两个概念:打包和压缩。打包是指将一大堆文件或目录变成一个总的文件;压缩则是将一个大的文件通过一些压缩算法变成一个小文件
常用参数:
-c 建立新的压缩文件
-f 指定压缩文件
-r 添加文件到已经压缩文件包中
-u 添加改了和现有的文件到压缩包中
-x 从压缩包中抽取文件
-t 显示压缩文件中的内容
-z 支持gzip压缩
-j 支持bzip2压缩
-Z 支持compress解压文件
-v 显示操作过程
有关 gzip 及 bzip2 压缩:
gzip 实例:压缩 gzip fileName .tar.gz 和.tgz 解压:gunzip filename.gz 或 gzip -d
filename.gz
对应:tar zcvf filename.tar.gz tar zxvf filename.tar.gz
bz2实例:压缩 bzip2 -z filename .tar.bz2 解压:bunzip filename.bz2或bzip -d
filename.bz2
对应:tar jcvf filename.tar.gz 解压:tar jxvf filename.tar.bz2
实例:
(1)将文件全部打包成 tar 包
tar -cvf log.tar 1.log,2.log 或tar -cvf log.*
(2)将 /etc 下的所有文件及目录打包到指定目录,并使用 gz 压缩
tar -zcvf /tmp/etc.tar.gz /etc
(3)查看刚打包的文件内容(一定加z,因为是使用 gzip 压缩的)
tar -ztvf /tmp/etc.tar.gz
(4)要压缩打包 /home, /etc ,但不要 /home/dmtsai
tar --exclude /home/dmtsai -zcvf myfile.tar.gz /home/* /etc
unzip 命令
- 解压 *.zip 文件:unzip test.zip 。
- 查看 *.zip 文件的内容:unzip -l jasper.zip 。
Linux 基础
三次握手,四次挥手
三次握手
01)由客户端(用户)发送建立TCP连接的请求报文,其中报文中包含seq序列号,是由发送端随机生成
的。
并且还将报文中SYN字段置为1,表示需要建立TCP连接请求。
02)服务端(就是百度服务器)会回复客户端(用户)发送的TCP连接请求报文,其中包含seq序列号,
也是由回复端随机生成的,
并且将回复报文的SYN字段置1,而且会产生ACK验证字段,ACK验证字段数值是在客户端发过来的seq
序列号基础上加1进行回复:
并且还会回复ack确认控制字段,以便客户端收到信息时,知晓自己的TCP建立请求已得到了确认。
03)客户端收到服务端发送的TCP建立请求后,会使自己的原有序列号加1进行再次发送序列号,
并且再次回复ACK验证请求,在B端发送过来的seq基础上加1,进行回复;同时也会回复ack确认控制字
段,
以便B收到信息时,知晓自己的TCP建立请求已经得到了确认。

四次挥手
第一次挥手:
Client发送一个FIN,用来关闭Client到Server的数据传送,Client进入FIN_WAIT_1状态。
第二次挥手:
Server收到FIN后,发送一个ACK给Client,确认序号为收到序号+1(与SYN相同,一个FIN占用一个序
号),Server进入CLOSE_WAIT状态。
第三次挥手:
Server发送一个FIN,用来关闭Server到Client的数据传送,Server进入LAST_ACK状态。
第四次挥手:
Client收到FIN后,Client进入TIME_WAIT状态,接着发送一个ACK给Server,确认序号为收到序号+1,Server进入CLOSED状态,完成四次挥手。

什么是动态资源,什么是静态资源
静态资源:可以理解为前端的固定页面,这里面包含HTML、CSS、JS、图片等等,不需要查数据库也不
需要程序处理,直接就能够显示的页面,如果想修改内容则必须修改页面,但是访问效率相当高。
动态资源:一般客户端请求的动态资源,先将请求交于web容器,web容器连接数据库,数据库处理数
据之后,将内容交给web服务器,web服务器返回给客户端解析渲染处理。
Tomcat和Resin有什么区别,工作中你怎么选择?
区别:Tomcat用户数多,可参考文档多,Resin用户数少,可考虑文档少
最主要区别则是Tomcat是标准的java容器,不过性能方面比resin的要差一些
但稳定性和java程序的兼容性,应该是比resin的要好
工作中选择:现在大公司都是用resin,追求性能;而中小型公司都是用Tomcat,追求稳定和程序的兼容
什么叫网站灰度发布?
也叫金丝雀发布
AB test就是一种灰度发布方式,让一部用户继续用A,一部分用户开始用B
如果用户对B没有什么反对意见,那么逐步扩大范围,把所有用户都迁移到B上面 来
灰度发布可以保证整体系统的稳定,在初始灰度的时候就可以发现、调整问题,以保证其影响度
请写出Linux命令执行的过程
当你执行命令时,首先去判断是不是别名 ,如果是,直接执行;
不是,判断是否是内部命令,如果是,直接执行;
不是,去看hash表,如果hash表有,直接执行,有,但是找不到,报错;
没有,去外部命令规定的文件夹找命令,如果没有,报错。
速记:别名>内部命令>hash表>外部命令
分别写出以下目录和文件一般存放的内容
①目录
/etc:配置文件保存位置
/mnt:挂载目录
/boot:系统启动目录
/var/log:登陆文件放置的目录
/dev:设备文件保存位置
/root:root 的主目录
/bin:存放二进制文件
/home:普通用户
②文件
/etc/passwd:存放用户信息
/etc/shadow:存放用户密码
/etc/fstab:永久挂载
/etc/exports:NFS共享存储服务配置文件
/etc/hosts:域名解析配置文件:主机名与IP地址的映射
当前目录为/opt/请分别以绝对路径和相对路径进入 /mnt 目录
cd /opt/
绝对:cd /mnt/
相对:cd …/mnt/
请建立/etc/passwd的软链接到/mnt目录
ln -s /etc/passwd /mnt
知识点:ln命令 -s软连接 源文件绝对路径 目标文件地址
将/etc/文件夹复制到/opt/目录下
cp -a /etc /opt/
知识点:-a 保留所有权限,包括软连接文件
实时显示/var/log/messages文件的后10行
tail -f /var/log/messages
找出/etc目录下fstab文件中以#号开头的行
cat /etc/fstab |grep '^#'
统计/var目录中的第一层子目录的空间占用情况
du -d1 /var
知识点:-d1 只显示目录下的第一层
将/etc 下的文件和目录按照建立时间顺序排列倒序显示
ls -lrt /etc
显示/etc/目录下所有以rc开头,之后是0-6间的数字,其它为任意字符的文件或目录
ls -d /etc/rc[0-6]*
知识点:-d 仅列出目录本身,而不是列出目录内的文件数据
查找/var/log目录下文件名以 “.log” 结尾的所有普通文件,并移动到/mnt目录下
find /var/log -name "*.log" -type f -exec mv {} /mnt \;
把家目录中的abc.txt和123.txt文件压缩成 abc123.tar.gz
cd ~
touch abc.txt
touch 123.txt
tar -zcvf abc123.tar.gz abc.txt 123.txt
把家目录中的abc123.tar.bz2文件解归档到 /opt 目录中
cd ~
tar -jxvf abc123.tar.bz2 -C /opt
把1.txt 文件中所有空行都去除
vim 1.txt
:%s /^\n
把家目录中的abc.txt文件移动到/opt目录中,并把文件名修改成123.txt
mv ~/abc.txt /opt/123.txt
过滤出/etc/fstab文件中所有非空行
cat /etc/fstab |grep -v "^$"
或
grep -v '^$' /etc/fstab
过滤出ifconfig ens33 命令中的第二行
ifconfig ens33 |head -2 |tail -1
或
ifconfig ens33 |grep netmask
统计/etc文件中的第一层目录并排序
du -d1 /etc |sort -n
或
ll -S /etc/
请简述磁盘空间满了你该做怎么样的操作?
①删文件
②加硬盘
③上报
统计/etc/fstab文件有多少行
wc -l /etc/fstab
或
cat /etc/fstab |wc -l
知识点:wc命令 -l 只统计行数 对 /etc/fstab 文件进行处理
将当前目录下的所有文件归档,并使用 gzip 压缩
tar zcvf 1.tar.gz ./*
知识点:tar使用归档 z代表使用gzip 压缩 c建立归档 v显示详细过程 f代表使用归档 1.tar.gz 代表自定义的名字 ./ 代表当前文件夹下的所有*
telnet命令的作用是什么?
判断端口连通性
判断与10.0.0.1上的mysql是否连通的命令
talnet 10.0.0.1 3306
DNS作用是什么?
实现IP地址和主机名(域名)之间的映射
Linux系统什么文件定义了DNS的NameServer
/etc/resolv.conf
结束后台进程的命令是什么?
kill
为脚本指定执行权限的命令及参数是什么?
chmod +x
欲发送10个分组报文文测试与主机www.aliyuncom的连通性,应使用的命令和参数是?
ping -c 10 www.aliyun.com
对config目录做归档压缩,生成config.tar.gz文件
tar zcf config.tar config/
使用什么命令(非ping) 测试DNS服务器是否能够正确解析域名
①nslookup
②host
局域网没有条件建立DNS服务器,但又想让局域网内的用户可以使用计算机名互相访问,应配置什么文件?
/etc/hosts
永久改变主机名
hostnamectl set-hostname
bash
或
vim /etc/hostname
reboot
查看10.0.0.1机器上提供的网络文件NFS服务
showmount -e 10.0.0.1
LVM相关命令有哪些?
pvcreate、lvcreate、vgcreate、lvextend、pvdisplay等
某系统网卡名为eth0,在什么文件中配置静态网络 (包括ip、掩码、网关等)
/etc/sysconfig/network-scripts/eth0
ping命令使用什么协议的数据包来探测目标主机是否连通
ICMP协议
显示当前所在目录
pwd
搭建本地yum仓库全过程
mount /dev/sr0 /mnt
cd /etc/yum.repo.d
mkdir bak
mv *.repo bak
vim local.repo
---------------
[local]
name=local
baseurl=file:///mnt
gpgcheck=0
---------------
yum clean all && yum makecache
挂载/dev/sda1到/mnt目录
1. #临时挂载
mount /dev/sda1 /mnt
2. #永久挂载
blkid /dev/sda1 #查看UUID号
vim /etc/fstab #永久挂载
----------------------------------------------
UUID=? /mnt xfs defaults 0 0
----------------------------------------------
mount -a #重新加载
磁盘分区用什么命令?
①fdisk #2T以下
②gdisk #2T以上
Linux磁盘分区的步骤
1. #例如磁盘名为sdb
fdisk /dev/sdb
2. #创建
n
回车
回车
回车
+5G
p
w
3. #格式化
mkfs.xfs /dev/sdb1
4. #挂载(此处演示临时)
mount /dev/sdb1 /mnt
5. #查看验证
df -hT #查看挂载情况
lsblk #查看分区
重启命令有哪些
①reboot
②init 6
cp -r是什么意思?
保留权限递归复制(目录一定要-r)
磁盘还有空余,为什么却无法继续新建文件?
inode号用完了
知识点:每生成一个文件都占用一个inode号,且inode号不可再生,一旦分区数量就确定下来了,数量和磁盘大小有关
pstree -p是什么意思?
树状图显示进程和PID号
inode号满了怎么办?
清理无用文件
知识点:每生成一个文件都占用一个inode号,且inode号不可再生,一旦分区数量就确定下来了,数量和磁盘大小有关
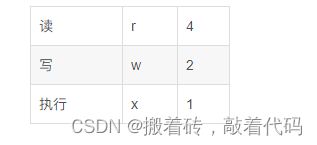
读、写、执行权限分别用什么字母和数字表示?
RAID0、1、5、10各自所需最少硬盘数量、可用容量、最多坏几块盘和读写性能

查看当前主机的80端口是否被使用
ss -ntap |grep 80
或
nestat -ntap |grep 80
建立逻辑卷的步骤
①添加硬盘(记得scan刷新新硬盘)
②分区(2T以下:fdisk/2T以上:gdisk)
③创建物理卷(pvcreate)
④创建卷组(vgcreate)
⑤创建逻辑卷(lvcreate)
⑥格式化逻辑及(mkfs)
⑦挂载逻辑卷(mount)
⑧查看挂载情况(df -h)
写出Linux系统启动过程
①开机自检BIOS
②MBR引导
③GRUB菜单
④加载内核
⑤init初始化进程
某文件权限为drw-r–r–用数字怎么表示?
644
怎么确认一个进程是单线程还是多线程?
1. #方法一
pstree -p
2. #方法二
cd /proc/PID号
cat status
3. #方法三
grep -i threads /proc/PID号/status
Centos7默认网卡位置
/etc/sysconfig/network-scripts/
yum provides ftp是什么意思?
查询ftp属于哪个安装包
如何修改用户test的密码
passwd test
或
echo '密码' |passwd --stdin test
查看当前系统实际使用的DNS
1. #方法一
cat /etc/resolv.conf
2. #方法二
nslookup 127.0.0.1
3. #方法三
cat /etc/sysconfig/network-scripts/网卡
查看当前系统实际使用的网关
1. #方法一
route -n
2. #方法二
ip route show
3. #方法三
cat /etc/sysconfig/network-scripts/网卡
给ens33网卡添加一个虚拟网卡
ifconfig ens33:0 IP地址 子网掩码
回环网卡的作用
回环网卡,即127.0.0.1,进行本地网络回环测试,看自己的物理网卡是否有物理故障
写出/etc/fstab文件内的格式
第一字段:设备
第二字段:挂载点
第三字段:文件系统类型
第四字段:挂载选项权限(default)
第五字段:转储频度,是否备份(0)
第六字段:自检次序(0)
知识点:/etc/fstab文件内容为永久挂载
那些命令可以查看文件的权限属性
①ll
②stat
查找cp命令所在的文件夹
①which cp
②whereis cp
删除文件后空间不释放怎么办?
1. #第一步
#查看文件是否正在使用(进程占用)
ps -aux
2. #第二步
kill对应进程
3. #或者
删除文件不彻底,可以使用命令
lsof |grep delete
echo "" > 文件名
rpm -ql httpd 是什么意思?
显示httpd软件包所有文件列表
tr命令的主要作用是什么?
字符替换、压缩和删除(-d)
crontab -l 是什么意思?
查看当前定时任务列表(周期性计划内容)
查看每一个用户最近一次的登录信息命令
last
查看用户的失败尝试登录的相关日志信息命令
lastb
查看用户正常登录系统的相关日志信息命令
①users
②who
③w
④cat /var/log/messages
ssh协议和talnet协议有什么区别?
①ssh支持压缩;talnet不支持压缩
②ssh加密用公钥;talnet明文传送
③ssh默认端口号为22;talnet默认端口号为23
使用yum卸载软件
yum remove 软件名
ls;cd /opt 是什么意思?
先执行命令ls,在执行cd /opt
编译安装的步骤
①检查安装环境并选择安装功能
./configure
②编译安装进硬盘
make && make install
通配符和正则表达式的区别是什么?
①通配符用于文件名路径匹配
②正则表达式用于文本匹配字符串
sed -i 是什么意思?
备份文件并在原处编辑
查看/etc/passwd中的内容
1. #方法一
cat /etc/passwd
2. #方法二
vim /etc/passwd
3. #方法三
less /etc/passwd
4. #方法四
more /etc/passwd
tac命令的作用是什么?
反向输出文件内容
查看/dev/sda的前512字节
hexdump -C -n 512 /dev/sda
分页查看文件内容可以使用哪些命令?
①less
②more
只查看最新发生的日志
tail -fn0 /var/log/messages
取/etc/passwd文件中以冒号为分隔符的第三字段
cut -d':' -f3 /etc/paswwd
简述paste命令的作用
左右合并文件
sort -nr 是什么意思?
按数字从大到小顺序排序(即倒序排序)
uniq命令的基本作用是什么?
去除连续的重复
过滤出ifconfig ens33命令结果中本机的ipv4地址
1. #方法一
ifconfig ens33 |sed -n '2p' |awk '{print $2}'
2. #方法二
ifconfig ens33 |grep netmask |awk '{print $2}'
3. #方法三
ifconfig ens33 |awk 'NR==2{print $2}'
查看用户UID
uid 用户名
或
cat /etc/passwd |grep 用户名
简述sed与awk的区别
①sed适合按列操作;awk适合按行操作
②sed是一个非交互式的编辑器;awk是一个程序语言
Centos7默认的文件系统
xfs
进程之间通讯的方式有哪些?
①管道(pipe)、流管道(s_pipe)、有名管道(FIFO)
②套接字(socket)
③消息队列
④共享内存
⑤信号(signal)
⑥信号量
你用过哪些时间同步软件?
①Network Time
②Chrony
你用过哪些品牌的服务器?
DELL、IBM、浪潮、联想、华为
GUI是什么?
图形用户界面(Graphical User Interface,简称 GUI,又称图形用户接口)是指采用图形方式显示的计算机操作用户界面。
SVN是什么?
SVN是一个开源版本控制系统代码版本管理工具,它能记住你每一次的代码修改,查看所有的修改记录,恢复到任何历史版本,恢复已经删除的文件。
MAVEN是什么?
MAVEN是一个项目管理工具,可以构建工程,管理jar,编译代码,自动运行单元测试,打包生成报表,部署项目,生成web站点。
GIT是什么?
GIT是一个开源的分布式版本控制系统,用于敏捷高效地处理任何或大或小的项目。
统计/var/log/nginx/access.log日志中访问量最多的前十个IP地址
cat /var/log/nginx/access.log |cut -d " " -f1 |sort -n |uniq -c |sort -nr |head
日志文件很大,怎么切分?
①nginx -s USR1 进行日志分割脚本
②split命令
文件系统损坏可以尝试用什么命令修复?
①fsck
②e2fsck:修复ext系列文件
③xfs_repair:修复xfs文件
如何将标准输出和错误输出同时重定向到一个文件?
&>
如何选择Linux操作系统版本?
①桌面用户首选Ubantu
②服务器首选RHEL或Centos
③安全要求高则选择Debian或FreeBSD
④使用数据库高级服务和电子邮件网络英语选择SUSE
如何刷新文件的atime、ctime、mtime三个时间?
①atime:读取或执行文件,任何对inode的访问
②ctime:写入文件,更改属主、权限或链接设置(更改状态,随inode内容更改而更改)
③mtime:写入文件
运行ifconfig命令报错command not found是为什么?怎么解决?
①检查是否安装ifconfig:ls /sbin |grep ifconfig
没安装就安装工具:yum install -y net-tools
②HASH缓存丢失:清空缓存
③命令不在$PATH下
④命令损坏:重新安装,同理为①
如何过滤出僵尸进程?
ps aux |grep Z
突然发现磁盘的sdb1分区只读了,哪些情况会这样?怎么办?
①挂载选项错误:重新挂载
②磁盘损坏:fsck命令先修,修不好就换盘(先拷贝数据)
你知道哪些Linux系统下的压力测试工具?
①ab
②stress
统计出root用户一共运行的进程总数
ps aux |grep 'root' |wc -l
或
pstree -u root |wc -l
出现CPU死循环该怎么处理
①top定位进程
②定位线程
③分析,kill
服务器CPU负载过高,如何在不影响业务正常运行的情况下,排除故障并解决
①使用top命令查看哪些进程占用了大量的CPU资源
②分析这些进程的日志和配置确定它们为什么会占用大量的CPU资源
③根据分析结果,调整这些进程的配置或优化它们的代码,以减少它们对CPU资源的占用
④如果您无法通过调整配置或优化代码来解决问题,您可以考虑增加服务器的硬件资源,如增加CPU核心数或升级CPU
SLA服务级别三个9代表什么意思?
99.9代表要停机约8.76小时,可用性达到99.9%
cp命令危险吗?
危险,有覆盖原文件的风险:要养成备份的习惯
你编译过Linux系统内核?或升级过系统内核?怎么操作?
连服务器编译(不要使用XShell等远程连接工具)
Linux系统刚运行时内存占用率低,运行10天后内存过高,内存过高怎么办?
cd /proc #清缓存
echo 1 > /proc/sys/vm/drop_caches #值为1、2、3都可以
公司中有一台服务器故障,更换服务器后,配置原来的IP地址,无法ssh远程登录该怎么办?
密钥(mac地址)没更新
给你300台裸机,你会怎么处理
①搭建PXE批量网络装机,自动装机
②初始化(IP地址、主机名、网卡名、本地yum仓库、内核参数优化调整等)脚本执行安全加固和系统调优或ansible
③安装必备软件
④网络调试(搭建DHCP)
日常该怎么巡检?
①物理巡检:磁盘闪灯(绿黄红)、温度湿度、安全等
②软件巡检:脚本检测(五大性能、Keepalived等数据库、服务能否正常登录使用)
③使用Zabbix、普罗米修斯进行监控
Swap交换分区的作用是什么?
物理内存不够用时,从Swap分区取出部分空间使用(将磁盘上的空间当作内存,救急的时候用)
如何打开、关闭交换分区?
swapon #打开
swapoff #关闭
立即打开并开机自启动httpd服务
systemctl start httpd
systemctl enable httpd
或
systemctl enable --now httpd
free命令中buff/cache分别是什么意思?
buff:写缓存
cache:读缓存
使用du命令的哪个选项,可以控制显示的文件夹层级
du -d
或
du --max-depth
找到根目录下大于7天的以.log结尾的普通文件
find / -mtime +7 -name '*.log' -type f
管道符(|)的作用是什么?
连接左右两个命令:将左边命令的结果,当右边命令待处理的结果
查找进程svn的相关信息
ps aux |grep svn
统计进程svn的个数
pstree -p |grep svn |wc -l
回到上一次的文件夹
cd -
显示磁盘的文件系统类型
df -hT
如何周期性查看内存
crontab -e
或
free -s 3 #每三秒显示一次
简述Centos6和Centos7之间的区别
①Centos6系统类型为sysvinit;Centos7系统类型为systemd
②Centos6第一个进程为init;Centos7第一个进程为systemd
③Centos6普通用户UID起始范围为500+;Centos7普通用户UID起始范围为1000-60000
④Centos6程序用户UID起始范围为1-499;Centos7程序用户UID起始范围为201-999
⑤Centos6网卡名称(eth0);Centos7网卡名称(ens33)
⑥Centos6自带的防火墙工具是iptables;Centos7自带的防火墙工具是firewall
⑦Centos6默认使用的文件系统为ext4;Centos7的默认文件系统为xfs
不删除文件,怎么清空文件中的内容?
true > 文件名
或
echo '' > 文件名
du和ls都可以看到文件大小,有什么区别?
①du指文件占用的磁盘空间大小
②ls显示的文件真实大小(会比du显示的小)
如何检查磁盘是否损坏?
①物理环境:磁盘闪红灯
②badblocks命令:检查磁盘中损坏的区块
简述遗忘root密码的解决办法
进入急救模式,重设密码
如何判断CPU是否高负载?
top命令查看CPU(一般75%-80%以上就算高负载)
简要写出DHCP客户端获取IP地址的一次完整过程
①客户端广播发送discover报文寻找服务端
②服务端回应offer报文
③客户端发送request服务请求(只回应第一个响应的服务端)
④服务端回复ACK报文
⑤客户端配置
Linux用户有哪些类型?
超级用户(UID=0)、普通用户、程序(系统)用户
怎么确定一个用户是不是超级管理员
看UID是否等于0
快速过滤/etc文件夹下包含root单词的所有文件
grep -rw 'root' /etc/
备份/dev/sda的前512字节到/mnt目录
dd if=/dev/sda of=/mnt/mbr.bak count=1 bs=512
通过inode号12345678删除当前目录普通文件
find -inum 12345678 -type f -delete
或
find -inum 12345678 -type f -exec rm {} \;
Centos7的默认管理员组
wheel
文件元数据包括什么?并简要介绍
①File:文件名
②Size:字节
③Blocks:文件使用数据块总数
④Block:读写大小
⑤文件类型
⑥设备编号
⑦Inode号
⑧Links:硬链接次数
⑨Access:权限
⑩UID、GID、属主、属组
⑪atime:访问时间
⑫mtime:修改时间
⑬ctime:状态时间
/tmp文件夹多了个t权限,显示为drwxrwxrwt,为什么?
说明这个/tmp文件夹中文件只有root和属主可以删除
默认的umask是多少?
root的umask默认为022;非特权用户为022
文件夹的最小权限是什么?文件和文件夹默认的最大权限分别是多少?
①文件夹最小权限为 执行(x 1)
②文件最大权限为读写(666)
③文件夹最大权限为读写执行(777)
查看非文本内容命令
hexdump -C -n 512 #查看前512字节
解挂载时无法解挂载,会有什么原因,并简述解决方法
①可能会有进程正在使用:kill进程号
②磁盘损坏
③有人在使用挂载目录:fuser -km 强杀
top -n5 什么意思?
动态显示系统处理器(内存、CPU等),五次刷新后自动退出
有什么运维相关的命令
top #内存
iotop #磁盘读写
vmstat #进程、虚拟内存、CPU活动、磁盘读写等
free -m #系统内存使用情况 显示单位为MB
fdisk #磁盘空间
df -hT #磁盘使用情况
find #查找文件
netstat /ss #查看网络连接情况
ps aux #进程
du -sh #当前目录下的所有文件占用磁盘大小和总大小
wc -l #统计文件内的行数
lsblk #磁盘分区情况
uname -r #内核
LVS负载均衡
1. 什么是 LVS?它的主要作用是什么?
LVS(Linux Virtual Server)是一个开源的高性能负载均衡器,是在 Linux 内核层实现的。LVS 的主要作用是在应用层和网络层中实现高可用性和可扩展性,支持通过多个服务器进行负载均衡,也可以进行 IP 地址转发、会话保持等功能。
2. LVS 的架构是什么?
LVS 的架构分为四层,包括负载调度器、服务节点、客户端和网络层。负载调度器是中心节点,用于接受客户端请求,并根据负载均衡算法将请求转发给服务节点。服务节点提供真实的服务,响应客户端请求。客户端向负载调度器发送请求,最终通过服务节点响应。了解网络层结构的基本概念和组成元素,有助于理解透彻 LVS 网络架构。
3. LVS 的工作原理是什么?
LVS 的负载均衡器会将客户端请求路由到服务节点,服务节点会响应客户端发出的请求,用来提供负载均衡的前端设备就是 LVS。LVS 在 IP 层面上对请求进行转发,并通过各种算法来实现负载均衡,将请求分发给后端真实的服务节点,推荐使用 3 层负载均衡算法—IP 转发,来实现高性能的负载均衡。
4. LVS 的负载均衡算法有哪些?
LVS 的负载均衡算法包括:轮询调度算法、加权轮询调度算法、源地址哈希调度算法、IP 转发调度算法、基于URL 的调度算法和指定调度算法等。
5. LVS 的会话保持机制是什么?
LVS 的会话保持机制是指客户端的每次请求都会被分配到同一台服务节点上,以确保与客户端有关联的所有信息都在同一个服务器上处理,而不是在多台之间分配。LVS 可以通过 IP 转发、调度器钩子等方式来实现会话保持。
6. LVS 的优点和缺点是什么?
LVS 的优点包括高性能、高可靠性、可扩展性好、功能丰富,适用于各种不同规模的环境中使用。但是,LVS 也存在一些缺点,例如配置复杂、维护后续高成本, 可能出现负载不均衡等问题。此外
7.LVS 负载均衡有哪些策略?
LVS一共有三种工作模式: DR,Tunnel,NAT
8.谈谈你对LVS的理解?
LVS是一个虚拟的服务器集群系统,在unix系统下实现负载均衡的功能;采用IP负载均衡技术和机遇内容请求分发技术来实现。
LVS采用三层结构,分别是:
第一层: 负载调度器
第二层: 服务池
第三层:共享存储
负载调度器(load balancer/ Director),是整个集群的总代理,它有两个网卡,一个网卡面对访问网站的客户端,一个网卡面对整个集群的内部。负责将客户端的请求发送到一组服务器上执行,而客户也认为服务是来自这台主的。举个生动的例子,集群是个公司,负载调度器就是在外接揽生意,将接揽到的生意分发给后台的真正干活的真正的主机们。当然需要将活按照一定的算法分发下去,让大家都公平的干活。
服务器池(server pool/ Realserver),是一组真正执行客户请求的服务器,可以当做WEB服务器。就是上面例子中的小员工。
共享存储(shared storage),它为服务器池提供一个共享的存储区,这样很容易使得服务器池拥有相同的内容,提供相同的服务。一个公司得有一个后台账目吧,这才能协调。不然客户把钱付给了A,而换B接待客户,因为没有相同的账目。B说客户没付钱,那这样就不是客户体验度的问题了。

9.负载均衡的原理是什么?
当客户端发起请求时,请求直接发给Director Server(调度器),这时会根据设定的调度算法,将请求按照算法的规定智能的分发到真正的后台服务器。以达到将压力均摊。
但是我们知道,http的连接时无状态的,假设这样一个场景,我登录某宝买东西,当我看上某款商品时,我将它加入购物车,但是我刷新了一下页面,这时由于负载均衡的原因,调度器又选了新的一台服务器为我提供服务,我刚才的购物车内容全都不见了,这样就会有十分差的用户体验。
所以就还需要一个存储共享,这样就保证了用户请求的数据是一样的
10.LVS由哪两部分组成的?
LVS 由2部分程序组成,包括 ipvs 和 ipvsadm。
1.ipvs(ip virtual server):一段代码工作在内核空间,叫ipvs,是真正生效实现调度的代码。
2.ipvsadm:另外一段是工作在用户空间,叫ipvsadm,负责为ipvs内核框架编写规则,定义谁是集群服务,而谁是后端真实的服务器(Real Server)
11.与lvs相关的术语有哪些?
DS:Director Server。指的是前端负载均衡器节点。
RS:Real Server。后端真实的工作服务器。
VIP:Virtual IP 向外部直接面向用户请求,作为用户请求的目标的IP地址。
DIP:Director Server IP,主要用于和内部主机通讯的IP地址。
RIP:Real Server IP,后端服务器的IP地址。
CIP:Client IP,访问客户端的IP地址。
12.LVS-NAT模式的原理

(a). 当用户请求到达Director Server,此时请求的数据报文会先到内核空间的PREROUTING链。
此时报文的源IP为CIP,目标IP为VIP
(b). PREROUTING检查发现数据包的目标IP是本机,将数据包送至INPUT链
©. IPVS比对数据包请求的服务是否为集群服务,若是,修改数据包的目标IP地址为后端服务器
IP, 然后将数据包发至POSTROUTING链。 此时报文的源IP为CIP,目标IP为RIP
(d). POSTROUTING链通过选路,将数据包发送给Real Server
(e). Real Server比对发现目标为自己的IP,开始构建响应报文发回给Director Server。 此时报文的源IP为RIP,目标IP为CIP
(f). Director Server在响应客户端前,此时会将源IP地址修改为自己的VIP地址,然后响应给客户端。 此时报文的源IP为VIP,目标IP为CIP
13.LVS-NAT模型的特性
RS应该使用私有地址,RS的网关必须指向DIP
DIP和RIP必须在同一个网段内
请求和响应报文都需要经过Director Server,高负载场景中,Director Server易成为性能瓶颈
支持端口映射RS可以使用任意操作系统
缺陷:对Director Server压力会比较大,请求和响应都需经过director server
14. LVS-DR模型的特性
特点1:保证前端路由将目标地址为VIP报文统统发给Director Server,而不是RS
RS可以使用私有地址;也可以是公网地址,如果使用公网地址,此时可以通过互联网对RIP进行直接访问
RS跟Director Server必须在同一个物理网络中
所有的请求报文经由Director Server,但响应报文必须不能进过Director Server
不支持地址转换,也不支持端口映射
RS可以是大多数常见的操作系统
RS的网关绝不允许指向DIP(因为我们不允许他经过director)
RS上的lo接口配置VIP的IP地址
缺陷:RS和DS必须在同一机房中
15.LVS三种负载均衡模式的比较
三种负载均衡: nat,tunneling,dr
|类目|NAT|TUN|DR|
|–|–|–|–|
操作系统|任意|支持隧道|多数(支持non-arp)
|服务器网络|私有网络|局域网/广域网|局域网
|服务器数目|10-20|100|大于100
|服务器网关|负载均衡器|自己的路由|自己的路由|
效率|一般|高|最高
16.LVS的负载调度算法
轮叫调度
加权轮叫调度
最小连接调度
加权最小连接调度
基于局部性能的最少连接
带复制的基于局部性能最小连接
目标地址散列调度
源地址散列调度
17. LVS与nginx的区别
lvs的优势(互联网老辛):
1.抗负载能力强,因为lvs工作方式的逻辑是非常简单的,而且工作在网络的第4层,仅作请求分发用,没有流量,所以在效率上基本不需要太过考虑。lvs一般很少出现故障,即使出现故障一般也是其他地方(如内存、CPU等)出现问题导致lvs出现问题。
2.配置性低,这通常是一大劣势同时也是一大优势,因为没有太多的可配置的选项,所以除了增减服务器,并不需要经常去触碰它,大大减少了人为出错的几率。
3.工作稳定,因为其本身抗负载能力很强,所以稳定性高也是顺理成章的事,另外各种lvs都有完整的双机热备方案,所以一点不用担心均衡器本身会出什么问题,节点出现故障的话,lvs会自动判别,所以系统整体是非常稳定的。
4.无流量,lvs仅仅分发请求,而流量并不从它本身出去,所以可以利用它这点来做一些线路分流之用。没有流量同时也保住了均衡器的IO性能不会受到大流量的影响。
5.lvs基本上能支持所有应用,因为lvs工作在第4层,所以它可以对几乎所有应用做负载均衡,包括http、数据库、聊天室等。
nginx与LVS的对比:
nginx工作在网络的第7层,所以它可以针对http应用本身来做分流策略,比如针对域名、目录结构等,相比之下lvs并不具备这样的功能,所以nginx单凭这点可以利用的场合就远多于lvs了;但nginx有用的这些功能使其可调整度要高于lvs,所以经常要去触碰,由lvs的第2条优点来看,触碰多了,人为出现问题的几率也就会大。
nginx对网络的依赖较小,理论上只要ping得通,网页访问正常,nginx就能连得通,nginx同时还能区分内外网,如果是同时拥有内外网的节点,就相当于单机拥有了备份线路;lvs就比较依赖于网络环境,目前来看服务器在同一网段内并且lvs使用direct方式分流,效果较能得到保证。另外注意,lvs需要向托管商至少申请多于一个ip来做visual ip。
nginx安装和配置比较简单,测试起来也很方便,因为它基本能把错误用日志打印出来。lvs的安装和配置、测试就要花比较长的时间,因为同上所述,lvs对网络依赖性比较大,很多时候不能配置成功都是因为网络问题而不是配置问题,出了问题要解决也相应的会麻烦的多。nginx也同样能承受很高负载且稳定,但负载度和稳定度差lvs还有几个等级:nginx处理所有流量
所以受限于机器IO和配置;本身的bug也还是难以避免的;nginx没有现成的双机热备方案,所以跑在单机上还是风险比较大,单机上的事情全都很难说。
nginx可以检测到服务器内部的故障,比如根据服务器处理网页返回的状态码、超时等等,并且会把返回错误的请求重新提交到另一个节点。目前lvs中ldirectd也能支持针对服务器内部的情况来监控,但lvs的原理使其不能重发请求。比如用户正在上传一个文件,而处理该上传的节点刚好在上传过程中出现故障,nginx会把上传切到另一台服务器重新处理,而lvs就直接断掉了。
两者配合使用:
nginx用来做http的反向代理,能够upsteam实现http请求的多种方式的均衡转发。由于采用的是异步转发可以做到如果一个服务器请求失败,立即切换到其他服务器,直到请求成功或者最后一台服务器失败为止。这可以最大程度的提高系统的请求成功率。
lvs采用的是同步请求转发的策略。这里说一下同步转发和异步转发的区别。同步转发是在lvs服务器接收到请求之后,立即redirect到一个后端服务器,由客户端直接和后端服务器建立连接。异步转发是nginx在保持客户端连接的同时,发起一个相同内容的新请求到后端,等后端返回结果后,由nginx返回给客户端。
进一步来说:当做为负载均衡服务器的nginx和lvs处理相同的请求时,所有的请求和响应流量都会经过nginx;但是使用lvs时,仅请求流量经过lvs的网络,响应流量由后端服务器的网络返回。
也就是,当作为后端的服务器规模庞大时,nginx的网络带宽就成了一个巨大的瓶颈。
但是仅仅使用lvs作为负载均衡的话,一旦后端接受到请求的服务器出了问题,那么这次请求就失败了。
但是如果在lvs的后端在添加一层nginx(多个),每个nginx后端再有几台应用服务器,那么结合两者的优势,既能避免单nginx的流量集中瓶颈,又能避免单lvs时一锤子买卖的问题。
18. 负载均衡的作用有哪些?
1、转发功能
按照一定的算法【权重、轮询】,将客户端请求转发到不同应用服务器上,减轻单个服务器压力,提高系统并发量。
2、故障移除
通过心跳检测的方式,判断应用服务器当前是否可以正常工作,如果服务器期宕掉,自动将请求发送到其他应用服务器。
3、恢复添加
如检测到发生故障的应用服务器恢复工作,自动将其添加到处理用户请求队伍中。
19.nginx实现负载均衡的分发策略
Nginx 的 upstream目前支持的分配算法:
1)、轮询 ——1:1 轮流处理请求(默认)
每个请求按时间顺序逐一分配到不同的应用服务器,如果应用服务器down掉,自动剔除,剩下的继续轮询。
2)、权重 ——you can you up
通过配置权重,指定轮询几率,权重和访问比率成正比,用于应用服务器性能不均的情况。
3)、ip_哈希算法
每个请求按访问ip的hash结果分配,这样每个访客固定访问一个应用服务器,可以解决session共享
的问题。
Nginx负载均衡
1. 什么是 Nginx?它的主要作用是什么?
Nginx 是一个轻量级的 Web 服务器和反向代理服务器,也是一款高性能的 HTTP 和反向代理服务器。其主要作用是实现高性能的 Web 服务和动态内容的加速和负载均衡,以及提供 TCP/UDP 代理服务和 HTTP 代理服务等。
2. Nginx 的架构是什么?
Nginx 的架构采用事件驱动的异步模型,包括主进程(master process)和工作进程(worker process)两个层次。主进程主要负责管理和启动 Worker 进程。Worker 进程则处理客户端请求,包括连接请求、监管和处理客户端请求等。
3. Nginx 如何实现反向代理和负载均衡?
Nginx 可以通过反向代理和负载均衡实现高性能成功扩展。反向代理是指将客户端的请求转发到后端的应用服务器,代替应用服务器和客户端进行通信,并负责请求的路由和负载均衡。使用轻量级的反向代理服务器而不是使用客户端和服务器之间直接通信,可以减轻服务器压力,从而提高性能和可靠性。
4. Nginx 如何处理静态和动态资源?
Nginx 可以通过配置对静态和动态资源进行不同处理。对于静态资源,可以设置 Nginx 的静态资源访问缓存,如内存缓存、磁盘缓存等,以减轻服务器的压力,提高性能。对于动态资源,可以通过反向代理或 FastCGI 协议等进行转发和处理,提高应用程序的运行效率。
5. 如何在 Nginx 中实现 HTTPS 协议?
在 Nginx 中实现 HTTPS 协议需要生成 SSL 证书并配置 Nginx 的 SSL 模块。可以使用 OpenSSL 工具生成 SSL 证书,然后将证书文件注入 Nginx 的配置文件中,如使用 SSL_certificate 指令指定证书文件和 SSL_certificate_key 指令指定私钥文件。在 Nginx 的配置文件中还可以进行 SSL 协议的优化,如启用 SSL 缓存、压缩等。
6. Nginx 的优点和缺点是什么?
Nginx 的优点包括高性能、高可靠性、异步非阻塞模型、可扩展性好、功能丰富、易于配置等,适合处理大量的并发请求。但其缺点包括不支持动态扩展
7. nginx做负载均衡实现的策略有哪些
-
轮询(默认)
-
权重
-
ip_hash
-
fair(第三方插件)
-
url_hash(第三方插件)
8.nginx做负载均衡用到哪些模块
upstream 定义负载节点池。
location 模块 进行URL匹配。
proxy模块 发送请求给upstream定义的节点池。
9. 负载均衡有哪些实现方式
-
硬件负载
-
HTTP重定向负载均衡
-
DNS负载均衡
-
反向代理负载均衡
-
IP层负载均衡
-
数据链路层负载均衡
10. nginx如何实现四层负载?
四层负载分为动态和静态负载
Nginx的四层静态负载均衡需要启用ngx_stream_core_module模块
默认情况下,ngx_stream_core_module是没有启用的,需要在安装Nginx时,添加–with-stream配置参数启用
配置HTTP负载均衡时,都是配置在http指令下,配置四层负载均衡,则是在stream指令下,结构如下所示.
stream {
upstream mysql_backend {
server 192.168.175.100:3306 max_fails=2 fail_timeout=10s weight=1;
least_conn;
}
server { #监听端口,默认使用的是tcp协议,如果需要UDP协议,则配置成listen 3307 udp;
listen 3307; #失败重试 proxy_next_upstream on;
proxy_next_upstream_timeout 0;
proxy_next_upstream_tries 0; #超时配置 #配置与上游服务器连接超时时间,默认60s
proxy_connect_timeout 1s; #配置与客户端上游服务器连接的两次成功读/写操作的超时时间,如果超
时,将自动断开连接 #即连接存活时间,通过它可以释放不活跃的连接,默认10分钟 proxy_timeout 1m;
#限速配置 #从客户端读数据的速率,单位为每秒字节数,默认为0,不限速 proxy_upload_rate 0; #从
上游服务器读数据的速率,单位为每秒字节数,默认为0,不限速 proxy_download_rate 0; #上游服务器
proxy_pass mysql_backend;
}
}
使用Nginx的四层动态负载均衡有两种方案:使用商业版的Nginx和使用开源的nginx-stream-upsync-module模块。注意:四层动态负载均衡可以使用nginx-stream-upsync-module模块,七层动态负载均衡可以使用nginx-upsync-module模块。
11. 你知道的web服务有哪些?
-
apache
-
nginx
-
IIS
-
tomcat
-
lighttpd
-
weblogic
12. 为什么要用nginx
-
跨平台、配置简单,非阻塞、高并发连接:处理2-3万并发连接数,官方监测能支持5万并发,
-
内存消耗小:开启10个nginx才占150M内存 ,nginx处理静态文件好,耗费内存少,
-
内置的健康检查功能:如果有一个服务器宕机,会做一个健康检查,再发送的请求就不会发送到宕机的服务器了。重新将请求提交到其他的节点上。
-
节省宽带:支持GZIP压缩,可以添加浏览器本地缓存
-
稳定性高:宕机的概率非常小
-
接收用户请求是异步的
13. nginx的性能为什么比apache高?
nginx采用的是epoll模型和kqueue网络模型,而apache采用的是select模型
举一个例子来解释两种模型的区别:
菜鸟驿站放着很多快件,以前去拿快件都是短信通知你有快件,然后你去了之后,负责菜鸟驿站的人在
一堆快递里帮你找,直到找到为止。
但现在菜鸟驿站的方式变了,他会发你一个地址,比如 3-3-5009. 这个就是第三个货架的第三排,从做
往右第九个。
如果有几百个人同时去找快递,这两种方式哪个更有效率,不言而喻。
之前还看到这个例子也比较形象
> 假设你在大学读书,住的宿舍楼有很多间房间,你的朋友要来找你。
select版宿管大妈就会带着你的朋友挨个房间去找,直到找到你为止。
而epoll版宿管大妈会先记下每位同学的房间号,你的朋友来时,只需告诉你的朋友你住在哪个房间即可,不用亲自带着你的朋友满大楼找人。
如果来了10000个人,都要找自己住这栋楼的同学时,select版和epoll版宿管大妈,谁的效率更高,不言自明。
同理,在高并发服务器中,轮询I/O是最耗时间的操作之一,select和epoll的性能谁的性能更高,同样十分明了
select 采用的是轮询的方式来处理请求,轮询的次数越多,耗时也就越多。
14. epoll的组成
epoll的接口非常简单,一共就三个函数:
1. int epoll_create(int size);
创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大。
这个参数不同于select()中的第一个参数,给出最大监听的fd+1的值。
需要注意的是,当创建好epoll句柄后,它就是会占用一个fd值,在linux下如果查看/proc/进程id/fd/,
是能够看到这个fd的,所以在使用完epoll后,必须调用close()关闭,否则可能导致fd被耗尽。
2. int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
epoll的事件注册函数,它不同与select()是在监听事件时告诉内核要监听什么类型的事件,
而是在这里先注册要监听的事件类型。第一个参数是epoll_create()的返回值,
第二个参数表示动作,用三个宏来表示:
EPOLL_CTL_ADD:注册新的fd到epfd中;
EPOLL_CTL_MOD:修改已经注册的fd的监听事件;
EPOLL_CTL_DEL:从epfd中删除一个fd;
第三个参数是需要监听的fd,第四个参数是告诉内核需要监听什么事
3. int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int
timeout);
等待事件的产生,类似于select()调用。
参数events用来从内核得到事件的集合,maxevents告之内核这个events有多大,这个 maxevents的值不
能大于创建epoll_create()时的size,参数timeout是超时时间(毫秒,0会立即返回,-1将不确定,也
有说法说是永久阻塞)。
该函数返回需要处理的事件数目,如返回0表示已超时
15.nginx和apache的区别
Nginx
-
轻量级,采用 C 进行编写,同样的 web 服务,会占用更少的内存及资源
-
抗并发,nginx 以 epoll and kqueue 作为开发模型,处理请求是异步非阻塞的,负载能力比apache 高很多,而 apache 则是阻塞型的。在高并发下 nginx 能保持低资源低消耗高性能 ,而apache 在 PHP 处理慢或者前端压力很大的情况下,很容易出现进程数飙升,从而拒绝服务的现象。
-
nginx 处理静态文件好,静态处理性能比 apache 高三倍以上
-
nginx 的设计高度模块化,编写模块相对简单
-
nginx 配置简洁,正则配置让很多事情变得简单,而且改完配置能使用 -t 测试配置有没有问题,apache 配置复杂 ,重启的时候发现配置出错了,会很崩溃
-
nginx 作为负载均衡服务器,支持 7 层负载均衡七层负载可以有效的防止ddos攻击
-
nginx本身就是一个反向代理服务器,也可以左右邮件代理服务器来使用
Apache
-
apache 的 rewrite 比 nginx 强大,在 rewrite 频繁的情况下,用 apache
-
apache 发展到现在,模块超多,基本想到的都可以找到
-
apache 更为成熟,少 bug ,nginx 的 bug 相对较多
-
apache 对 PHP 支持比较简单,nginx 需要配合其他后端用
-
apache 在处理动态请求有优势,nginx 在这方面是鸡肋,一般动态请求要 apache 去做,nginx 适合静态和反向。
-
apache 仍然是目前的主流,拥有丰富的特性,成熟的技术和开发社区
两者最核心的区别在于 apache 是同步多进程模型,一个连接对应一个进程,而 nginx 是异步的,多个连接(万级别)可以对应一个进程。
需要稳定用apache,需要高性能用nginx
16 .nginx常用的命令
启动 nginx 。
停止 nginx -s stop 或 nginx -s quit 。
重载配置 ./sbin/nginx -s reload(平滑重启) 或 service nginx reload 。
重载指定配置文件 .nginx -c /usr/local/nginx/conf/nginx.conf 。
查看 nginx 版本 nginx -v 。
检查配置文件是否正确 nginx -t 。
显示帮助信息 nginx -h 。
17. 什么是反向代理,什么是正向代理,以及区别?
正向代理:
所谓的正向代理就是: 需要在用户端去配置的。配置完再去访问具体的服务,这叫正向代理
正向代理,其实是"代理服务器"代理了"客户端",去和"目标服务器"进行交互。
正向代理的用途:
-
提高访问速度
-
隐藏客户真实IP
反向代理:
反向代理是 在服务端的,不需要访问用户关心。用户访问服务器A, A服务器是代理服务器,将用户服务再转发到服务器B.这就是反向代理
反向代理的作用:
1.缓存,将服务器的响应缓存在自己的内存中,减少服务器的压力。
2.负载均衡,将用户请求分配给多个服务器。
3.访问控制
18.Squid、Varinsh、Nginx 有什么区别?
三者都实现缓存服务器的作用
-
Nginx本来是反向代理/web服务器,用了插件可以做做这个副业(缓存服务器)。但本身支持的特性不是很多,只能缓存静态文件
-
varinsh 和squid是专业的cache服务,而nginx这些需要使用第三方模块
-
varnish本身在技术上的优势要高于squid,它采用了可视化页面缓存技术。
在内存的利用上,Varnis h比 Squid 具有优势,性能要比 Squid 高。
还有强大的通过 Varnish 管理端口,可以使用正则表达式快速、批量地清除部分缓存
Varnish 是内存缓存,速度一流,但是内存缓存也限制了其容量,缓存页面和图片一般是挺好的。
要做 cache 服务的话,我们肯定是要选择专业的 cache 服务,优先选择Squid 或者 Varnish
19. nginx是如何处理http请求的
四个步骤:
读取解析请求行;
读取解析请求头;
开始最重要的部分,即多阶段处理;
nginx把请求处理划分成了11个阶段,也就是说当nginx读取了请求行和请求头之后,将请求封装
了结构体ngx_http_request_t,然后每个阶段的handler都会根据这个ngx_http_request_t,对请
求进行处理,例如重写uri,权限控制,路径查找,生成内容以及记录日志等等;
最后将结果放回给客户单。
也可以这么回答:
首先,Nginx 在启动时,会解析配置文件,得到需要监听的端口与 IP 地址,然后在 Nginx 的Master 进程里面先初始化好这个监控的Socket(创建 S ocket,设置 addr、reuse 等选项,绑定到指定的 ip 地址端口,再 listen 监听)。
然后,再 fork(一个现有进程可以调用 fork 函数创建一个新进程。由 fork 创建的新进程被称为子进程 )出多个子进程出来。
之后,子进程会竞争 accept 新的连接。此时,客户端就可以向 nginx 发起连接了。当客户端与nginx进行三次握手,与 nginx 建立好一个连接后。此时,某一个子进程会 accept 成功,得到这个建立好的连接的 Socket ,然后创建 nginx 对连接的封装,即 ngx_connection_t 结构体。
-接着,设置读写事件处理函数,并添加读写事件来与客户端进行数据的交换。
最后,Nginx 或客户端来主动关掉连接,到此,一个连接就寿终正寝了。
20 .nginx虚拟主机有哪些?
基于域名的虚拟主机
基于端口的虚拟主机
基于IP的虚拟主机
21. nginx怎么实现后端服务的健康检查
方式一
利用 nginx 自带模块 ngx_http_proxy_module 和 ngx_http_upstream_module 对后端节点做健康检查。
方式二
利用 nginx_upstream_check_module 模块对后端节点做健康检查。(推荐此方法)
22.nginx的优化你都做过哪些?
. gzip压缩优化
. expires缓存有还
. 网络IO事件模型优化
. 隐藏软件名称和版本号
. 防盗链优化
. 禁止恶意域名解析
. 禁止通过IP地址访问网站
. HTTP请求方法优化
. 防DOS攻击单IP并发连接的控制,与连接速率控制
. 严格设置web站点目录的权限
. 将nginx进程以及站点运行于监牢模式
. 通过robot协议以及HTTP_USER_AGENT防爬虫优化
. 配置错误页面根据错误码指定网页反馈给用户
. nginx日志相关优化访问日志切割轮询,不记录指定元素日志、最小化日志目录权限
. 限制上传到资源目录的程序被访问,防止木马入侵系统破坏文件
. FastCGI参数buffer和cache配置文件的优化
. php.ini和php-fpm.conf配置文件的优化
. 有关web服务的Linux内核方面深度优化(网络连接、IO、内存等)
. nginx加密传输优化(SSL)
. web服务器磁盘挂载及网络文件系统的优化
. 使用nginx cache
一: 配置文件中对优化有明显效果的:
1. worker_processes 8;
nginx 进程数,建议按照cpu 数目来指定,一般为它的倍数 (如,2个四核的cpu计为8)。
2. worker_cpu_affinity 00000001 00000010 00000100 00001000 00010000 00100000
01000000 10000000;
为每个进程分配cpu,上例中将8 个进程分配到8 个cpu,当然可以写多个,或者将一个进程分配到多
个cpu。
3. worker_rlimit_nofile 65535;
这个指令是指当一个nginx 进程打开的最多文件描述符数目,理论值应该是最多打开文件数(ulimit
-n)与nginx 进程数相除,但是nginx 分配请求并不是那么均匀,所以最好与ulimit -n 的值保持一致。
现在在linux 2.6内核下开启文件打开数为65535,worker_rlimit_nofile就相应应该填写
65535。
这是因为nginx调度时分配请求到进程并不是那么的均衡,所以假如填写10240,总并发量达到3-4万
时就有进程可能超过10240了,这时会返回502错误。
4. use epoll
5. worker_connections 65535
每个进程允许的最多连接数, 理论上每台nginx 服务器的最大连接数为
worker_processes*worker_connections。
6. keepalive_timeout 60;
7. client_header_buffer_size 4k;
客户端请求头部的缓冲区大小,这个可以根据你的系统分页大小来设置,一般一个请求头的大小不会超过1k
8. open_file_cache max=65535 inactive=60s;
这个将为打开文件指定缓存,默认是没有启用的,max 指定缓存数量,建议和打开文件数一致,
inactive 是指经过多长时间文件没被请求后删除缓存。
9. open_file_cache_valid 80s;
这个是指多长时间检查一次缓存的有效信息。
10. open_file_cache_min_uses 1;
open_file_cache 指令中的inactive 参数时间内文件的最少使用次数,如果超过这个数字,文件
描述符一直是在缓存中打开的,如上例,如果有一个文件在inactive 时间内一次没被使用,它将被移除。
23.nginx的session不同步怎么办
我们可以采用ip_hash指令解决这个问题,如果客户已经访问了某个服务器,当用户再次访问时,会将该请求通过哈希算法,自动定位到该服务器。即每个访客固定访问一个后端服务器,可以解决session的问题。
其他办法:那就是用spring_session+redis,把session放到缓存中实现session共享。
24.nginx的常用模块有哪些?
1、ngx_http_core_module #包括一些核心的http参数配置,对应Nginx的配置为HTTP区块部分
2、ngx_http_access_module #访问控制模块,用来控制网站用户对Nginx的访问
3、ngx_http_gzip_module #压缩模块,对Nginx返回的数据压缩,属于性能优化模块
4、ngx_http_fastcgi_module #FastCGI模块,和 动态应用相关的模块,例如PHP
5、ngx_http_proxy_module #Proxy代理模块
6、ngx_http_upstream_module #负载均衡模块,可以实现网站的负载均衡功能及节点的健康检查
7、ngx_http_rewrite_module #URL地址重写模块
8、ngx_http_limit_conn_module #限制用户并发连接数及请求数模块(防止ddos)
9、ngx_http_limit_req_module #根据定义的key限制Nginx请求过程的速率
10、ngx_http_log_module #访问日志模块,以指定的格式记录Nginx客户访问日志等信息
11、ngx_http_auth_basic_module #Web认证模块,设置Web用户通过账号、密码访问Nginx
12、ngx_http_ssl_module #ssl模块,用于加密的http连接,如https
13、ngx_http_stub_status_module #记录Nginx基本访问状态信息等模块
25. nginx常用状态码
200 (成功) 服务器已成功处理了请求。 通常,这表示服务器提供了请求的网页。
201 (已创建) 请求成功并且服务器创建了新的资源。
202 (已接受) 服务器已接受请求,但尚未处理。
203 (非授权信息) 服务器已成功处理了请求,但返回的信息可能来自另一来源。
204 (无内容) 服务器成功处理了请求,但没有返回任何内容。
205 (重置内容) 服务器成功处理了请求,但没有返回任何内容。
206 (部分内容) 服务器成功处理了部分 GET 请求。
300 (多种选择) 针对请求,服务器可执行多种操作。 服务器可根据请求者 (user agent) 选择一项操
作,或提供操作列表供请求者选择。
301 (永久移动) 请求的网页已永久移动到新位置。 服务器返回此响应(对 GET 或 HEAD 请求的响应)
时,会自动将请求者转到新位置。
302 (临时移动) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请
求。
303 (查看其他位置) 请求者应当对不同的位置使用单独的 GET 请求来检索响应时,服务器返回此代码。
304 (未修改) 自从上次请求后,请求的网页未修改过。 服务器返回此响应时,不会返回网页内容。
305 (使用代理) 请求者只能使用代理访问请求的网页。 如果服务器返回此响应,还表示请求者应使用代
理。
307 (临时重定向) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请
求。
400 (错误请求) 服务器不理解请求的语法。
401 (未授权) 请求要求身份验证。 对于需要登录的网页,服务器可能返回此响应。
403 (禁止) 服务器拒绝请求。
404 (未找到) 服务器找不到请求的网页。
405 (方法禁用) 禁用请求中指定的方法。
406 (不接受) 无法使用请求的内容特性响应请求的网页。
407 (需要代理授权) 此状态代码与 401(未授权)类似,但指定请求者应当授权使用代理。
408 (请求超时) 服务器等候请求时发生超时。
409 (冲突) 服务器在完成请求时发生冲突。 服务器必须在响应中包含有关冲突的信息。
410 (已删除) 如果请求的资源已永久删除,服务器就会返回此响应。
411 (需要有效长度) 服务器不接受不含有效内容长度标头字段的请求。
412 (未满足前提条件) 服务器未满足请求者在请求中设置的其中一个前提条件。
413 (请求实体过大) 服务器无法处理请求,因为请求实体过大,超出服务器的处理能力。
414 (请求的 URI 过长) 请求的 URI(通常为网址)过长,服务器无法处理。
415 (不支持的媒体类型) 请求的格式不受请求页面的支持。
416 (请求范围不符合要求) 如果页面无法提供请求的范围,则服务器会返回此状态代码。
417 (未满足期望值) 服务器未满足"期望"请求标头字段的要求。
500 (服务器内部错误) 服务器遇到错误,无法完成请求。
501 (尚未实施) 服务器不具备完成请求的功能。 例如,服务器无法识别请求方法时可能会返回此代码。
502 (错误网关) 服务器作为网关或代理,从上游服务器收到无效响应。
503 (服务不可用) 服务器目前无法使用(由于超载或停机维护)。 通常,这只是暂时状态。
504 (网关超时) 服务器作为网关或代理,但是没有及时从上游服务器收到请求。
505 (HTTP 版本不受支持) 服务器不支持请求中所用的 HTTP 协议版本。
25.访问一个网站的流程
用户输入网站按回车, 查找本地缓存,如果有就打开页面,如果没有,利用DNS做域名解析,递归查
询,一级一级的向上提交查询请求,知道查询到为止
HOSTS表–> 本地DNS -->上层DNS(包括根DNS)
经过了DNS解析,知道了网站的IP地址,然后建立tcp三次握手; 建立请求后,发送请求报文,默认请求
的是index.html
传送完毕,断开连接
26.统计ip访问情况,要求分析nginx访问日志,找出访问页面数量在前十位的ip
cat access.log | awk '{print $1}' | uniq -c | sort -rn | head -10
27.nginx各个版本的区别
Nginx官网提供了三个类型的版本
Mainline version:Mainline 是 Nginx 目前主力在做的版本,可以说是开发版
Stable version:最新稳定版,生产环境上建议使用的版本
Legacy versions:遗留的老版本的稳定版
28.nginx最新版本
1.19 ,稳定版本1.18
29. 关于nginx access模块的面试题
编写一个Nginx的access模块,要求准许192.168.3.29/24的机器访问,准许10.1.20.6/16这个网段的所
有机器访问,准许34.26.157.0/24这个网段访问,除此之外的机器不准许访问。
location/{
access 192.168.3.29/24;
access 10.1.20.6/16;
access 34.26.157.0/24;
deny all;
}
30. nginx默认配置文件
在 nginx 的配置文件中,大概分为几个区域:events {}、http {}、和没有被 {}包裹的区域。而 http {}中还有 server {},以及 server {} 中的 location {}。结构如下:
...
worker_processes 1;
events {
worker_connections 1024;
}
http {
...
server {
...
location {
...
}
}
server {
...
}
}
-
没有被 {} 包裹的部分为全局配置,如 worker_processes 1; 设置工作进程(子进程)数为 1
-
events {} 为 nginx 连接配置的模块,如 worker_connections 1024; 设置每一个子进程最大允许连接 1024 个连接
-
http {} 为 nginx http 核心配置模块
-
server {} 为虚拟主机配置模块,包括监听端口、监听域名等
-
location {} URI 匹配
31.location的规则
在 Nginx 的配置文件中,通常会用两个常用的区块(Block)来进行设置:
1.Server 区块
2.Localtion 区块
sever 区块主要是真的主机的配置,比如配置主机的域名,IP,端口等内容。当然,在一个 Nginx 的配
置文件里面,我们是可以指定多个 Sever 区块的配置的。
而 Location 区块则是在 Sever 区块里面,细分到针对不同的路径和请求而进行的配置。因为一个站点中
的 URI 通常会非常多,所以在 Location 区块设置这部分,你也是可以写多个 Location 的配置的。
location optional_modifier location_match {
# 这个 {} 里面的配置内容就是一个区块 Block
}
上面的 optional_modifier 配置项是可以使用正则表达式的。常用的几种如下:
留空。在留空的情况下,配置表示请求路径由 location_match 开始。
= ,等于号还是非常容易理解的:就是请求路径正好等于后面的 location_match 的值;跟第一项留空还
是有区别的。
~,飘号(注意是英文输入的飘号)表示大小写敏感的正则匹配。
~*表示大小写不敏感的正则匹配。
^~ 表示这里不希望有正则匹配发生。
nginx 处理localtion区块的顺序
每一个请求进来 Nginx 之后,Nginx 就会选择一个 Location 的最佳匹配项进行响应,处理的具体流程
是逐一跟 location 的配置进行比对,这个步骤可以分为以下几步:
先进行前缀式的匹配(也就是 location 的 optional_modifier 为空的配置)。
Nginx 其次会根据 URI 寻找完全匹配的 location 配置(也就是 location 的 optional_modifier
为 = 的配置).
如果还是没有匹配到,那就先匹配 ^~ 配置,如果找到一个配置的话,则会停止寻找过程,直接返回响应内
容。
如果还是没有找到匹配项的话,则会先进行大小写敏感的正则匹配,然后再是大小不写敏感的正则匹配
举例子:
location = / {
# = 等号配置符,只匹配 / 这个路由
}
location /data {
# 留空配置,会匹配有 /data 开始的路由,后续有匹配会往下匹配。
}
location ^~ /img/ {
# 注意 ^~ 配置,这里匹配到 /img/ 开始的话,直接就返回了。
}
location ~* .(png|gif|ico|jpg|jpeg)$ {
# 匹配以 png, gif, ico, jpg or jpeg 结尾的请求;这个通常用来设置图片的请求响应。
}
32.配置nginx防盗
Nginx的防盗链原理是加入location项,用正则表达式过渡图片类型文件,对于信任的网址可以正常使用,
对于不信任的网址则返回相应的错误图片,在源主机(bt.com)的配置文件中加入以下代码:
vi /usr/local/nginx/conf/nginx.conf
location ~*\.(jpg|gif|swf)$ {
valid_referers none blocked *.test.com test.com;
if ($invalid_referer) {
rewrite ^/http://www.bt.com/error.png;
}
}
下面分析一下这段代码:
~*\.(jpg|gif|swf)$:这段正则表达式表示匹配不区分大小写,以.jpg或.gif或.swf结尾的文件。
valid_referers:设置信任的网站,可以正常使用图片。
none:浏览器中referer为空的情况,这就是直接在浏览器访问图片。
blocked:浏览器中referer不可空的情况,但是值被代理或防火墙删除了,这些值不以http://或
https://开头。
后面的网站或者域名:referer中包含相关字符串的网址。
if语句:如果链接的来源域名不在valid_referers所列出的列表中,$invalid_referer为1,则执行后
面的操作,即进行重写或返回403页面。
把图片error.png放到源主机(bt.com)的工作目录下。
ls /usr/local/nginx/html
50x.html index.html logo.jpg error.png
这是重启服务器,重新访问http://www.test.com/index.html,显示的是被重写的图片。
33.nginx中的lua模块用过没有?
ngx_lua是nginx的一个模块,将Lua嵌入到nginx中,从而可以使用Lua来编写脚本,这样就可以使用Lua编写应用脚本,部署到nginx中运行,即 nginx变成了一个web容器。
34 .正向代理和反向代理的区别?
正向代理是客户端和其他所有服务器(重点:所有)的代理者,而反向代理是客户端和所要代理的服务器之间的代理。一个对客户端负责,一个对所代理的服务器负责。
35.nginx电商网站突然打不开了,你会怎么处理?
首先文件的格式是否正常,看我服务端html目录下是否有文件,若确定在,再去nginx的配置文件中查看是否支持我的格式,所以我会去/usr/local/nginx/conf/nginx.conf,添加我上传图片的格式,然后去我的测试端浏览器中清空缓存再次测试
检查服务端服务是否启动成功
检查Nginx配置文件是否有错误
在服务端使用wget和curl测试下返回的是否正常
防火墙是否关闭,端口是否开放
查看缓冲区内存是否过小,若上传的文件大小大于我的缓冲区,肯定就无法加载出来,去/usr/local/nginx/conf/nginx.conf中的gzip_buffers参数的大小
36.nginx返回码502是什么原因?
502错误最通常的出现情况就是后端主机当机。
37.nginx返回码504是什么原因?
504后端服务器在超时时间内,未响应Nginx代理请求
一般原因:后端服务器在超时时间内,未响应Nginx代理请求
解决方法:根据后端服务器实际处理情况,调正后端请求超时时间。
proxy_read_timeout 90;
proxy_send_timeout 90;
一般原因:可能网站页面缓存大,而fastcgi默认进程响应缓存区8k
解决方法:配置nginx.conf相关设置
38.nginx返回码500是什么原因?
一般原因:脚本错误(php语法错误、lua语法错误)
访问量过大,系统资源限制,不能打开过多文件
磁盘空间不足。(access log开启可能导致磁盘满溢 关闭)
解决方法:语法错误查看nginx_err_log php_err_log。
文件访问量:
1.修改nginx配置文件
worker_rlimit_nofile 65535;
2.修改/etc/security/limits.conf
* soft nofile 65535
* hard nofile 65535
39.nginx返回码405是什么原因?
httppost请求目标网站会出现405 状态码,原因为 Apache、IIS、Nginx等绝大多数web服务器,都不允许静态文件响应POST请求, 所以将post请求改为get请求即可。
40.nginx返回码499是什么原因?
一般原因:499, Client Closed Request, 客户端主动断开连接。 是指一次http请求在客户端指定的时间内没有返回响应,此时,客户端会主动断开连接,此时表象为客户端无响应返回,而nginx的日志中会status code 为499。
解决方法:根据实际Nginx后端服务器的处理时间修改客户端超时时间
41.nginx返回码301、302是什么原因?
301是永久重定向的状态码,302是临时重定向的状态码。一般来说,301跳转多用于网站改版时新旧网站的对接,302跳转一般用于404页面的跳转(如果我们访问一个网站出错,会被服务器设置成访问404页面,这时用302跳转直接从错误页面跳转到首页)。这是最常用的方法。
42.Nginx访问十分的卡,怎么办?
修改配置为gzip on
配置expires起到控制页面缓存
sendfile on 用于开启文件高效传输模式,同时将tcp_nopush on 和tcp_nodelay on 两个指令设置为on,可防止网络及磁盘I/O阻塞,提升Nginx工作效率
优化worker服务进程数,worker_processes模块
如果是动态请求(如 PHP),那么 Nginx 就会把它通过 FastCGI 接口发送给 PHP 引擎服务, (即 php-fpm)进行解析
FastCGI参数调优:
fastcgi_connect_timeout 240; # Nginx服务器和后端FastCGI服务器连接的超时时间
fastcgi_cache ngx_fcgi_cache; # 缓存FastCGI生成的内容
日志优化,排除不需要的日志,日志切割:nginx日志默认不做处理,都会存放到access.log,error.log, 导致越积越多。 可写个定时脚本按天存储,每天凌晨00:00执行限制HTTP的请求
43.前端nginx突然发现大量用户访问导致无法使用,你需要调整什么参数?
前端高并发策略本质要解决的是由访问量激增带来的问题,开启CDN加速,高防CDN可以自动识别恶意攻击流量,进行服务器扩容,优化数据库访问,禁止外部的盗链;避免同一客户端长时间占用连接–在http段设置相应的连接超时参数keepalive_timeout,当Nginx将网页数据返回给客户端后,可针对静态网页设置缓存时间,通过在配置文件内的http段内的server段内添加location,更改字段expires 1d来实现;避免重复请求,加快了访问速度,在高并发场景,需要启动更多的nginx进程以保证快速响应,避免造成阻塞;配置worker_processes开启多进程,可在配置文件中加入相应的压缩功能参数对压缩性能进行优化,nginx的PHP解析功能实现是交给FPM处理的,为了提高PHP的处理速度,要根据服务器的内存与服务负载进行FPM模块参数调整;比如增加dynamic(动态)的方式产生fpm进程 。
Keepalived高可用
1.keepalived 是什么?
广义上讲是高可用,狭义上讲是主机的冗余和管理
Keepalived起初是为LVS设计的,专门用来监控集群系统中各个服务节点的状态,它根据TCP/IP参考模型的第三、第四层、第五层交换机制检测每个服务节点的状态,如果某个服务器节点出现异常,或者工作出现故障,Keepalived将检测到,并将出现的故障的服务器节点从集群系统中剔除,这些工作全部是自动完成的,不需要人工干涉,需要人工完成的只是修复出现故障的服务节点。
后来Keepalived又加入了VRRP的功能,VRRP(VritrualRouterRedundancyProtocol,虚拟路由冗余协议)出现的目的是解决静态路由出现的单点故障问题,通过VRRP可以实现网络不间断稳定运行,因此Keepalvied一方面具有服务器状态检测和故障隔离功能,另外一方面也有HAcluster功能。
所以keepalived的核心功能就是健康检查和失败且换。
所谓的健康检查,就是采用tcp三次握手,icmp请求,http请求,udp echo请求等方式对负载均衡器后面的实际的服务器(通常是承载真实业务的服务器)进行保活;
而失败切换主要是应用于配置了主备模式的负载均衡器,利用VRRP维持主备负载均衡器的心跳,当主负载均衡器出现问题时,由备负载均衡器承载对应的业务,从而在最大限度上减少流量损失,并提供服务的稳定性
2.你是如何理解VRRP协议的
为什么使用VRRP?
主机之间的通信都是通过配置静态路由或者(默认网关)来完成的,而主机之间的路由器一旦发生故障,通信就会失效,因此这种通信模式当中,路由器就成了一个单点瓶颈,为了解决这个问题,就引入了VRRP协议。
VRRP协议是一种容错的主备模式的协议,保证当主机的下一跳路由出现故障时,由另一台路由器来代替出现故障的路由器进行工作,通过VRRP可以在网络发生故障时透明的进行设备切换而不影响主机之间的数据通信。
VRRP的三种状态:
VRRP路由器在运行过程中有三种状态:
1.Initialize状态: 系统启动后就进入Initialize,此状态下路由器不对VRRP报文做任何处理;
2.Master状态;
3.Backup状态;
一般主路由器处于Master状态,备份路由器处于Backup状态。
3.keepalived的工作原理?
keepalived采用是模块化设计,不同模块实现不同的功能。
keepalived主要有三个模块,分别是core、check和vrrp。
core:是keepalived的核心,负责主进程的启动和维护,全局配置文件的加载解析等
check: 负责healthchecker(健康检查),包括了各种健康检查方式,以及对应的配置的解析包括LVS的
配置解析;可基于脚本检查对IPVS后端服务器健康状况进行检查
vrrp:VRRPD子进程,VRRPD子进程就是来实现VRRP协议的
Keepalived高可用对之间是通过 VRRP进行通信的, VRRP是通过竞选机制来确定主备的,主的优先级高于备,因此,工作时主会优先获得所有的资源,备节点处于等待状态,当主宕机的时候,备节点就会接管主节点的资源,然后顶替主节点对外提供服务在Keepalived服务对之间,只有作为主的服务器会一直发送 VRRP广播包,告诉备它还活着,此时备不会抢占主,当主不可用时,即备监听不到主发送的广播包时,就会启动相关服务接管资源,保证业务的连续性.接管速度最快
4. 出现脑裂的原因
什么是脑裂?
-
在高可用(HA)系统中,当联系2个节点的“心跳线”断开时,本来为一整体、动作协调的HA系统,就分裂成为2个独立的个体。
-
由于相互失去了联系,都以为是对方出了故障。两个节点上的HA软件像“裂脑人”一样,争抢“共享资源”、争起“应用服务”,就会发生严重后果。共享资源被瓜分、两边“服务”都起不来了;或者两边“服务”都起来了,但同时读写“共享存储”,导致数据损坏
都有哪些原因导致脑裂?
高可用服务器对之间心跳线链路发生故障,导致无法正常通信。
因心跳线坏了(包括断了,老化)。
因网卡及相关驱动坏了,ip配置及冲突问题(网卡直连)
因心跳线间连接的设备故障(网卡及交换机)
因仲裁的机器出问题(采用仲裁的方案)
高可用服务器上开启了 iptables防火墙阻挡了心跳消息传输。
高可用服务器上心跳网卡地址等信息配置不正确,导致发送心跳失败
其他服务配置不当等原因,如心跳方式不同,心跳广插冲突、软件Bug等。
5.如何解决keepalived脑裂问题?
在实际生产环境中,我们从以下方面防止脑裂:
-
同时使用串行电缆和以太网电缆连接、同时使用两条心跳线路,这样一条线路断了,另外一条还是好的,依然能传送心跳消息
-
当检查脑裂时强行关闭一个心跳节点(这个功能需要特殊设备支持,如stonith、fence)相当于备节点接收不到心跳消息,通过单独的线路发送关机命令关闭主节点的电源
-
做好对脑裂的监控报警
解决常见方案:
-
如果开启防火墙,一定要让心跳消息通过,一般通过允许IP段的形式解决
-
可以拉一条以太网网线或者串口线作为主被节点心跳线路的冗余
-
开发检测程序通过监控软件检测脑裂
Kafka分布式消息
1.什么是Kafka?
Kafka是一种开源分布式消息系统。它最初由LinkedIn开发,并于2011年贡献给Apache软件基金会进行管理和维护。Kafka具有高吞吐量,可水平扩展,容错性好等特点,适用于许多不同的应用场景。
2.Kafka中的主题和分区是什么?
在Kafka中,主题是消息的逻辑容器。每个主题都可以有多个分区,每个分区都是一个有序的消息日志。
3.Kafka如何保证消息的可靠性传递?
Kafka使用多种技术来保证消息的可靠性传递。其中包括:
- 数据复制:每个分区都可以有多个副本,以防止数据丢失。
- 重试机制:生产者在发送消息时可以进行重试,以确保消息成功发送。
- 处理顺序:Kafka保证同一分区中的消息按照顺序进行处理。
- 消息确认:消费者在接收消息后可以向Kafka确认消息已收到。
4.什么是Kafka Consumer Group?
Kafka Consumer Group是一组消费者,它们共同消费一个或多个主题的数据。每个消费者可以消费一个或多个分区,以实现负载平衡。
5.Kafka如何处理复杂数据类型?
Kafka本身不支持复杂数据类型,例如数组、嵌套对象等。通常需要将这些数据类型转换为字符串或字节数组的形式,然后在生产者和消费者之间进行解析。
6.Kafka和其他消息队列系统的区别是什么?
Kafka与其他消息队列系统的主要区别在于它的高吞吐量和可水平扩展性。Kafka使用分区和副本来实现负载均衡和故障转移,能够处理大量的并发数据,并且能够在不停机的情况下进行扩展。
7.Kafka如何处理消息丢失问题?
Kafka使用多个备份副本来保证数据不会丢失。如果发生硬件故障或其他问题导致数据丢失,Kafka会自动从备份副本中恢复数据。此外,消费者在接收到消息后可以向Kafka发送确认信息,以确保消息已经被正常处理。
8.kafka 中的ISR,AR代表什么,ISR伸缩又代表什么
ISR:In-Sync Replicas 副本同步队列
AR:Assigned Replicas 所有副本
ISR是由leader维护,follower从leader同步数据有一些延迟(包括延迟时间replica.lag.time.max.ms和延迟条数replica.lag.max.messages两个维度, 当前最新的版本0.10.x中只支持replica.lag.time.max.ms这个维度),任意一个超过阈值都会把follower剔除出ISR, 存入OSR(Outof-Sync Replicas)列表,新加入的follower也会先存放在OSR中。AR=ISR+OSR。
9.kafka中的broker 是干什么的
broker 是消息的代理,Producers往Brokers里面的指定Topic中写消息,Consumers从Brokers里面拉取指定Topic的消息,然后进行业务处理,broker在中间起到一个代理保存消息的中转站。
10. kafka中的zookeeper 起到什么作用,可以不用zookeeper么
zookeeper 是一个分布式的协调组件,早期版本的kafka用zk做meta信息存储,consumer的消费状态,group的管理以及 offset的值。考虑到zk本身的一些因素以及整个架构较大概率存在单点问题,新版本中逐渐弱化了zookeeper的作用。新的consumer使用了kafka内部的group coordination协议,也减少了对zookeeper的依赖,但是broker依然依赖于ZK,zookeeper 在kafka中还用来选举controller 和 检测broker是否存活等等
11. kafka follower如何与leader同步数据
Kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。完全同步复制要求All Alive Follower都复制完,这条消息才会被认为commit,这种复制方式极大的影响了吞吐率。
而异步复制方式下,Follower异步的从Leader复制数据,数据只要被Leader写入log就被认为已经commit,这种情况下,如果leader挂掉,会丢失数据,kafka使用ISR的方式很好的均衡了确保数据不丢失以及吞吐率。Follower可以批量的从Leader复制数据,而且Leader充分利用磁盘顺序读以及sendfile(zero copy)机制,这样极大的提高复制性能,内部批量写磁盘,大幅减少了Follower与Leader的消息量差。
12. kafka 为什么那么快
-
Cache Filesystem Cache PageCache缓存
-
顺序写 由于现代的操作系统提供了预读和写技术,磁盘的顺序写大多数情况下比随机写内存还要快。
-
Zero-copy 零拷技术减少拷贝次数
-
Batching of Messages 批量量处理。合并小的请求,然后以流的方式进- 行交互,直顶网络上限。
-
Pull 拉模式 使用拉模式进行消息的获取消费,与消费端处理能力相符。
13. Kafka中的消息是否会丢失和重复消费?
要确定Kafka的消息是否丢失或重复,从两个方面分析入手:消息发送和消息消费。
1、消息发送
Kafka消息发送有两种方式:同步(sync)和异步(async),默认是同步方式,可通过producer.type属性进行配置。Kafka通过配置request.required.acks属性来确认消息的生产:
0—表示不进行消息接收是否成功的确认;
1—表示当Leader接收成功时确认;
-1—表示Leader和Follower都接收成功时确认;
综上所述,有6种消息生产的情况,下面分情况来分析消息丢失的场景:
(1)acks=0,不和Kafka集群进行消息接收确认,则当网络异常、缓冲区满了等情况时,消息可能丢失;
(2)acks=1、同步模式下,只有Leader确认接收成功后但挂掉了,副本没有同步,数据可能丢失;
2、消息消费
Kafka消息消费有两个consumer接口,Low-level API和High-level API:
Low-level API:消费者自己维护offset等值,可以实现对Kafka的完全控制;
High-level API:封装了对parition和offset的管理,使用简单;
如果使用高级接口High-level API,可能存在一个问题就是当消息消费者从集群中把消息取出来、并提交了新的消息offset值后,还没来得及消费就挂掉了,那么下次再消费时之前没消费成功的消息就“诡异”的消失了;
解决办法:
针对消息丢失:同步模式下,确认机制设置为-1,即让消息写入Leader和Follower之后再确认消息发送成功;异步模式下,为防止缓冲区满,可以在配置文件设置不限制阻塞超时时间,当缓冲区满时让生产者一直处于阻塞状态;
针对消息重复:将消息的唯一标识保存到外部介质中,每次消费时判断是否处理过即可。
14 .为什么Kafka不支持读写分离?
在 Kafka 中,生产者写入消息、消费者读取消息的操作都是与 leader 副本进行交互的,从 而实现的是一种主写主读的生产消费模型
Kafka 并不支持主写从读,因为主写从读有 2 个很明 显的缺点:
(1)数据一致性问题。数据从主节点转到从节点必然会有一个延时的时间窗口,这个时间 窗口会导致主从节点之间的数据不一致。某一时刻,在主节点和从节点中 A 数据的值都为 X, 之后将主节点中 A 的值修改为 Y,那么在这个变更通知到从节点之前,应用读取从节点中的 A 数据的值并不为最新的 Y,由此便产生了数据不一致的问题。
(2)延时问题。类似 Redis 这种组件,数据从写入主节点到同步至从节点中的过程需要经 历网络→主节点内存→网络→从节点内存这几个阶段,整个过程会耗费一定的时间。而在 Kafka 中,主从同步会比
Redis 更加耗时,它需要经历网络→主节点内存→主节点磁盘→网络→从节 点内存→从节点磁盘这几个阶段。对延时敏感的应用而言,主写从读的功能并不太适用。
15. 什么是消费者组?
消费者组是 Kafka 独有的概念,如果面试官问这 个,就说明他对此是有一定了解的。我先给出标准答案:
1、定义:即消费者组是 Kafka 提供的可扩展且具有容错性的消费者机制。
2、原理:在 Kafka 中,消费者组是一个由多个消费者实例 构成的组。多个实例共同订阅若干个主题,实现共同消费。同一个组下的每个实例都配置有 相同的组 ID,被分配不同的订阅分区。当某个实例挂掉的时候,其他实例会自动地承担起 它负责消费的分区。
此时,又有一个小技巧给到你:消费者组的题目,能够帮你在某种程度上掌控下面的面试方向。
如果你擅长位移值原理,就不妨再提一下消费者组的位移提交机制;
如果你擅长 Kafka Broker,可以提一下消费者组与 Broker 之间的交互;
如果你擅长与消费者组完全不相关的 Producer,那么就可以这么说:“消费者组要消 费的数据完全来自于Producer 端生产的消息,我对 Producer 还是比较熟悉的。”
16. Kafka 中的术语
-
代理(borker): 一个kafka进程(kafka进程又被称为实例),被称为一个代理broker节点。
-
生产者(producer)
Producer将消息记录发送到Kafka集群指定的主题(Topic)中进行存储,同时生产者(Producer)也能通过自定义算法决定将消息记录发送到哪个分区(Partition)。
例如,通过获取消息记录主键(Key)的哈希值,然后使用该值对分区数取模运算,得到分区索引。
针对消息丢失:同步模式下,确认机制设置为-1,即让消息写入Leader和Follower之后再确认消息发送成功;异步模式下,为防止缓冲区满,可以在配置文件设置不限制阻塞超时时间,当缓冲区满时让生产者一直处于阻塞状态;
针对消息重复:将消息的唯一标识保存到外部介质中,每次消费时判断是否处理过即可。
- 消费者Consumer
消费者(Consumer)从Kafka集群指定的主题(Topic)中读取消息记录。在读取主题数据时,需要设置消费组名(GroupId)。如果不设置,则Kafka消费者会默认生成一个消费组名称。
- 消费者组: Consumer Group
消费者程序在读取Kafka系统主题(Topic)中的数据时,通常会使用多个线程来执行。一个消费者组可以包含一个或多个消费者程序,使用多分区和多线程模式可以极大提高读取数据的效率。
一般而言,一个消费者对应一个线程
- 主题Topic
Kafka系统通过主题来区分不同业务类型的消息记录。例如,用户登录数据存储在主题A中,用户充值记录存储在主题B中,则如果应用程序只订阅了主题A,而没有订阅主题B,那该应用程序只能读取主题A中的数据
- 分区(Partition)
每一个主题(Topic)中可以有一个或者多个分区(Partition)。在Kafka系统的设计思想中,分区是基于物理层面上的,不同的分区对应着不同的数据文件。Kafka通过分区(Partition)来支持物理层面上的并发读写,以提高Kafka集群的吞吐量。
一个分区只对应一个代理节点(Broker),一个代理节点可以管理多个分区。
- 副本(replication)
在Kafka系统中,每个主题(Topic)在创建时会要求指定它的副本数,默认是1。通过副本(Replication)机制来保证Kafka分布式集群数据的高可用性
在创建主题时,主题的副本系数值应如下设置
(1)若集群数量大于等于3,则主题的副本系数值
可以设置为3;
(2)若集群数量小于3,则主题的副本系数值可以设置为小于等于集群数量值。例如,集群数为2,则副本系数可以设置为1或者2;集群数为1,则副本系数只能设置为1。
- 记录(Record)
被实际写入到Kafka集群并且可以被消费者应用程序读取的数据,被称为记录(Record)。每条记录包含一个键(Key)、值(Value)和时间戳(Timestamp)。
- replica:
partition 的副本,保障 partition 的高可用。
- leader:
replica 中的一个角色, producer 和 consumer 只跟 leader 交互。
- follower:
replica 中的一个角色,从 leader 中复制数据。
- controller:
kafka 集群中的其中一个服务器,用来进行 leader election 以及 各种 failover。
- zookeeper:
kafka 通过 zookeeper 来存储集群的 meta 信息。

生产者(Producer)负责写入消息数据。将审计日志、服务日志、数据库、移动App日志,以及其他类型的日志主动推送到Kafka集群进行存储。
消费者(Consumer)负责读取消息数据。例如,通过Hadoop的应用接口、Spark的应用接口、Storm的应用接口、ElasticSearch的应用接口,以及其他自定义服务的应用接口,主动拉取Kafka集群中的消息数据。
17. kafka适用于哪些场景
-
日志收集
-
消息系统
-
用户轨迹(记录浏览器用户或者app用户产生的各种记录,点击和搜索浏览等)
-
记录运营监控数据
-
实现流处理
18.Kafka写入流程:
1.producer 先从 zookeeper 的 “/brokers/…/state” 节点找到该 partition 的 leader
2.producer 将消息发送给该 leader
3.leader 将消息写入本地 log
4.followers 从 leader pull 消息,写入本地 log 后 leader 发送 ACK
5.leader 收到所有 ISR 中的 replica 的 ACK 后,增加 HW(high watermark,最后 commit 的offset) 并向 producer 发送 ACK
Tomcat服务
1. Tomcat 是什么?介绍一下它的作用和特点。
Tomcat 是一个免费开源的 Web 应用服务器,它实现了 Java Servlet、JavaServer Pages (JSP)、Java Expression Language (EL) 和 Java WebSocket 技术,可用于开发和部署 Java Web 应用程序。Tomcat 作为一个轻量级的 Web 服务器和应用服务器,具有简单易用、高性能、可扩展、可移植等特点,广泛应用于互联网和企业应用领域。
2. Tomcat 的体系结构是什么样的?它包括哪些组件?
Tomcat 的体系结构由三个部分组成:容器、组件和连接器。其中,容器包括引擎(Engine)、主机(Host)和上下文(Context)三个层次;组件包括 Servlet、过滤器、监听器和 JSP 组件等;连接器处理客户端请求和服务器响应之间的通信,包括 HTTP 连接器、AJP 连接器等。
3. Tomcat 的默认端口是什么?如何修改 Tomcat 的端口?
Tomcat 的默认端口是 8080。可以通过编辑 server.xml 文件并修改 Connector 标签中的 port 属性来更改 Tomcat 的端口号。
4. Tomcat 的启动方式有哪些?如何手动启动和停止 Tomcat 服务器?
Tomcat 的启动方式有命令行启动、服务启动、IDE 启动等。手动启动 Tomcat 服务器可以使用 startup.bat (Windows) 或 startup.sh (Linux) 脚本,手动停止 Tomcat 服务器可以使用 shutdown.bat (Windows) 或 shutdown.sh (Linux) 脚本。
5. Tomcat 的日志文件存在哪里?如何查看 Tomcat 的日志信息?
Tomcat 的日志文件位于 Tomcat 的 log 目录下,包括 catalina.out、localhost.log、localhost_access_log.txt 等文件。可以使用文本编辑器查看日志信息,也可以使用命令行工具如 less、tail 等来查看实时日志信息。
6. Tomcat 在 Linux 上如何安装和配置?
在 Linux 上安装 Tomcat 可以下载二进制文件并解压到指定目录,然后设置环境变量和用户权限等。配置 Tomcat 可以编辑 server.xml 文件和 context.xml 文件,修改日志配置、连接器配置、虚拟主机配置等。
7. 如何在 Tomcat 上部署 Web 应用程序?
在 Tomcat 上部署 Web 应用程序可以将 WAR 文件放置在 Tomcat 的 webapps 目录下,然后重启 Tomcat 服务器即可自动部署应用程序。也可以手动配置 context.xml 文件和 web.xml 文件,修改应用程序的数据库配置、缓存配置、安全配置等。
8. Tomcat作为web的优缺点?
优点:
动态解析容器,处理动态请求,是编译JSP/Servlet的容器,轻量级
缺点:
tomcat 只能用做java服务器,处理静态请求的能力不如nginx和apache。,高并发能力有限
9. tomcat的三个端口及作用
8005: 关闭Tomcat通信接口
8009: 与其他httpd服务器通信接口,用于http服务器的集合
8080: 建立httpd连接用,如浏览器访问
10.fastcgi 和cgi的区别
cgi:
web 服务器会根据请求的内容,然后会 fork 一个新进程来运行外部 c 程序(或 perl 脚本…), 这个进程会把处理完的数据返回给 web 服务器,最后 web 服务器把内容发送给用户,刚才 fork 的进程也随之退出。
如果下次用户还请求改动态脚本,那么 web 服务器又再次 fork 一个新进程,周而复始的进行。
fastcgi
web 服务器收到一个请求时,他不会重新 fork 一个进程(因为这个进程在 web 服务器启动时就开启了,而且不会退出),web 服务器直接把内容传递给这个进程(进程间通信,但 fastcgi 使用了别的方式,tcp 方式通信),这个进程收到请求后进行处理,把结果返回给 web 服务器,最后自己接着等待下一个请求的到来,而不是退出。
11.Tomcat缺省端口是多少,怎么修改
找到Tomcat目录下的conf文件夹
进入conf文件夹里面找到server.xml文件
打开server.xml文件
在server.xml文件里面找到下列信息
把Connector标签的8080端口改成你想要的端口
12.Tomcat的工作模式是什么?
Tomcat作为servlet容器,有三种工作模式:
1、独立的servlet容器,servlet容器是web服务器的一部分;
2、进程内的servlet容器,servlet容器是作为web服务器的插件和java容器的实现,web服务器插件在内
部地址空间打开一个jvm使得java容器在内部得以运行。反应速度快但伸缩性不足;
3、进程外的servlet容器,servlet容器运行于web服务器之外的地址空间,并作为web服务器的插件和
java容器实现的结合。反应时间不如进程内但伸缩性和稳定性比进程内优;
进入Tomcat的请求可以根据Tomcat的工作模式分为如下两类:
Tomcat作为应用程序服务器:请求来自于前端的web服务器,这可能是Apache, IIS, Nginx等;
Tomcat作为独立服务器:请求来自于web浏览器;
13.Web请求在Tomcat请求中的请求流程是怎么样的?
-
浏览器输入URL地址;
-
查询本机hosts文件寻找IP;
-
查询DNS服务器寻找IP;
-
向该IP发送Http请求;
-
Tomcat容器解析主机名;
-
Tomcat容器解析Web应用;
-
Tomcat容器解析资源名称;
-
Tomcat容器获取资源;
-
Tomcat响应浏览器。
14.怎么监控Tomcat的内存使用情况
使用JDK自带的jconsole可以比较明了的看到内存的使用情况,线程的状态,当前加载的类的总量等;
JDK自带的jvisualvm可以下载插件(如GC等),可以查看更丰富的信息。如果是分析本地的Tomcat的话,还可以进行内存抽样等,检查每个类的使用情况在java/bin目录下
15.Tomcat你做过哪些优化
- Tomcat的运行模式 : bio,nio, apr
一般使用nio模式,bio效率低,apr对系统配置有一些更高的要求
- 关键配置
maxThreads: 最大线程数,默认是200,
minspareThread: 最小活跃线程数,默认是25
maxqueuesize: 最大等待队列个数
- 影响性能的配置:
compression 设置成on,开启压缩
禁用AJP连接器: 用nginx+Tomcat的架构,用不到AJP
enableLookups=false 关闭反查域名,直接返回ip,提高效率
disableUploadTimeou=false上传是否使用超时机制
acceptCount=300 , 当前所有可以使用的处理请求都被使用时,传入请求连接最大队列长队,超过个数不予处理,默认是100
keepalive timeout=120000 场链接保持时间
- 优化jvm
/bin/catalina.sh
-server:jvm的server工作模式,对应的有client工作模式。使用“java -version”可以查看当前工作
模式
-Xms1024m:初始Heap大小,使用的最小内存
-Xmx1024m:Java heap最大值,使用的最大内存。经验: 设置Xms大小等于Xmx大小
-XX:NewSize=512m:表示新生代初始内存的大小,应该小于 -Xms的值
-XX:MaxNewSize=1024M:表示新生代可被分配的内存的最大上限,应该小于 -Xmx的值
-XX:PermSize=1024m:设定内存的永久保存区域,内存的永久保存区域,VM 存放Class 和 Meta
信息,JVM在运行期间不会清除该区域
-XX:MaxPermSize=1024m:设定最大内存的永久保存区域。经验: 设置PermSize大小等于
MaxPermSize大小
-XX:+DisableExplicitGC:自动将System.gc() 调用转换成一个空操作,即应用中调用System.gc()
会变成一个空操作,避免程序员在代码里进行System.gc()这种危险操作。System.gc()
除非是到了万不得也的情况下使用,都应该交给 JVM。
16.Tomcat中出现OOM怎么处理?
OOM(out of memory)内存溢出,内存不够用了。调整应用的内存占用,可能是代码有问题优化代码,Tomcat垃圾回收机制,调整Tomcat配置:-Xms、-Xmn、-Xmx ---- 其内存的配置需要根据服务器(或虚拟机)的实际内存来配置,优化最大工作数、队列数量。
Tomcat垃圾回收机制:垃圾回收机制会不定时的向堆内存中清理不可达(没有被程序引用)的对象。
finalize方法:java虚拟机在垃圾回收之前会先调用垃圾对象的finalize方法。(因为垃圾回收机制只负责回收内存,并不负责资源的回收,资源回收要由程序员完成)。
final方法:用于修饰类、成员变量和成员方法。final修饰的类不能被继承,其中所有的方法都不能被重写所以不能同时使用abstract(抽象类是用于被子类继承的和final起相反的作用)和final修饰类。
**1、内存溢出:**运行一个应用程序需要4g内存,项目只支持3g内存 溢出
**2、内存泄露:**程序中定义很多静态变量,但是垃圾回收机制不会进行回收,这个对象没有被引用,再次申请内存,会报错泄露。
Apache服务
1. 什么是 Apache?它的主要作用是什么?
Apache 是一款自由、开源的 web 服务器软件,可以在几乎所有的计算机操作系统上运行,是世界上最流行的 Web 服务器软件之一。它的主要作用是提供静态或动态的 web 内容,支持多种协议和语言以及扩展模块等,为用户提供高效可靠的 Web 服务。
2. 安装 Apache 有哪些常用的方式?如何完成 Apache 的配置?
Apache 的安装可以通过二进制包、源码包、软件仓库等多种方式实现,不同的操作系统和发布版本可能有所不同。Apache 的配置主要包括全局配置和虚拟主机配置等,可以通过编辑配置文件(如 httpd.conf、apache2.conf 等)对服务器进行配置,常见的配置包括目录访问权限、日志文件设置、URL 重定向等。
3. 如何启动和停止 Apache 服务器?
Apache 服务器的启动和停止可以使用相应的命令行工具,例如在 Linux 平台上,使用“systemctl start/stop/restart httpd.service” 命令启动、停止、重启 Apache 服务器。在 Windows 平台上,可以使用“net start/stop Apache2.4”命令启动和停止 Apache 服务器。
4. 如何在 Apache 服务器上配置虚拟主机?
在 Apache 服务器上配置虚拟主机可以使得一台服务器支持多个域名或 IP 地址,在一个服务器上托管多个网站。可以通过编辑 Apache 配置文件,添加 VirtualHost 段来定义不同的虚拟主机。需要在每个虚拟主机上定义 Web 内容、日志、SSL 加密等相关配置。
5. 如何调优 Apache 服务器?
Apache 服务器的性能调优可以通过一系列手段来实现,例如更改缓存策略、调整并发连接数、禁用不必要的模块、使用性能更高的网络协议等。还可以通过使用 CDNs(内容分发网络)或使用反向代理的方式实现负载均衡和高可用性。
6. 如何查看 Apache 的日志信息?
Apache 服务器的日志信息可以通过查看它记录的访问、错误和系统日志来实现。在 Apache 服务器日志目录下,可以找到默认的 access_log 和 error_log 文件,其中 access_log 记录用户的请求信息,error_log 记录服务器运行中的系统和错误信息。
7. 如何保护 Apache 服务器的安全性?
保护 Apache 服务器的安全性可以通过多种方式来实现,例如通过密码保护目录访问、限制 IP 访问、使用 SSL 加密、禁用不必要的模块等。此外,定期更新 Apache 服务器和相关软件的版本、配置提示信息、对系统进行安全审计等措施都可以增强 Apache 服务器的安全性。
8.apache中的Worker和Prefork 之间的区别是什么?
它们都是MPM, Worker 和 prefork 有它们各自在Apache上的运行机制. 它们完全依赖于你想要以哪一种模式启动你的Apache.
1.Worker 和 MPM基本的区别在于它们产生子进程的处理过程. 在Prefork MPM中, 一个主httpd进行被启动,这个主进程会管理所有其它子进程为客户端请求提供服务. 而在worker MPM中一个httpd进程被激活,则会使用不同的线程来为客户端请求提供服务.
2.Prefork MPM 使用多个子进程,每一个进程带有一个线程而 worker MPM 使用多个子进程,每一个进程带有多个线程.
3.Prefork MPM中的连接处理, 每一个进程一次处理一个连接而在Worker mpm中每一个线程一次处理一个连接.
4.内存占用 Prefork MPM 占用庞大的内存, 而Worker占用更小的内存.
Ansible自动化运维工具
1.Ansible是什么?
Ansible是一个自动化运维工具,基于Python开发,集合了众多运维工具的优点,可以实现批量系统配置、批量程序部署、批量运行命令等功能。并且它是基于模块工作的,本身没有批量部署的能力,真正批量部署的是ansible所运行的模块,而ansible只是提供一种框架。
2.ansible用过哪些模块?
command、shell、cron、user、group、copy、file、ping、yum、systemd、setup、hostname、script
3.什么是 Ansible 模块?
模块被认为是 Ansible 的工作单元。每个模块大多是独立的,可以用标准的脚本语言编写,如 Python、Perl、Ruby、bash 等。模块的一个重要属性是幂等性,意味着一个操作执行多次不会产生副作用。
4.什么是 Ansible 的 playbooks ?
Playbooks 是 Ansible 的配置、部署和编排语言,它是基于YAML语言编写的。他们可以描述您希望远程系统实施的策略,或者描述一般 IT 流程中的一系列步骤。
5.描述Ansible是如何工作的?
Ansible由节点和控制机器组成。 控制机器是安装Ansibles的地方,节点由这些机器通过SSH管理。 借助SSH协议,控制机器可以部署临时存储在远程节点上的模块。
控制机器使用ansible或者ansible-playbooks在服务器终端输入的Ansible命令集或者playbook后,Ansible会遵循预先编排的规则将PLAYbook逐条拆解为Play,再将Play组织成Ansible可以识别的任务tasks,随后调用任务涉及到的所有MODULES及PLUGINS,根据主机清单INVENTORY中定义的主机列表通过SSH协议将任务集以临时文件或者命令的形式传输到远程节点并返回结果,如果是临时文件则执行完毕后自动删除。
6.ansible的shell模块在哪种场景不能使用?
当需要在远程主机上执行命令并且命令需要从标准输入中获取数据时,shell 模块不能使用,因为它不支持从标准输入中读取数据。
当需要在远程主机上执行长时间运行的命令时,shell 模块不能使用。因为 shell 模块默认使用 SSH 连接,在 SSH 连接超时时间到达之前,必须等待命令完成,这可能会导致超时错误。
当需要在远程主机上执行复杂的命令管道时,shell 模块不能使用。因为在执行复杂的管道时,可能需要使用 bash 或其他 shell 的高级特性,而 shell 模块只能执行简单的命令,因此不能满足此类需求。
7.ansible的shell模块可以对后端的文件进行修改吗?
Ansible的shell模块可以在远程主机上执行shell命令,因此可以通过该模块来修改后端文件。但是,使用Ansible的shell模块直接对后端文件进行修改并不是最佳的做法,因为这样可能会导致文件权限或者所有权问题。
相反,最好使用Ansible的file或template模块来修改后端文件。file模块可以设置文件的所有权、权限和时间戳,而template模块可以使用变量和模板文件来生成文件。这两个模块都可以保证文件修改的安全性和正确性,因此推荐使用它们来修改后端文件。
MySQL数据库
1.什么是MySQL?
MySQL是一种开源的关系型数据库管理系统,在类Unix操作系统(如Linux)和Windows操作系统上都可以运行。它是最流行的关系型数据库之一,也是Web开发中使用最广泛的数据库之一。
2.什么是SQL?
SQL(Structured Query Language)是指结构化查询语言。它是一种用于管理关系型数据库的编程语言,可以用于执行各种数据库操作,如插入、更新、删除和查询数据。
3.如何在MySQL中创建数据库?
可以使用CREATE DATABASE语句来创建数据库。例如,要创建名为“mydb”的数据库,可以使用以下语句:
CREATE DATABASE mydb;
4.如何创建用户并授予访问数据库的权限?
可以使用CREATE USER语句创建用户,并使用GRANT语句授予访问数据库的权限。例如,要创建名为“myuser”的用户,并授予访问名为“mydb”的数据库的所有权限,可以使用以下语句:
CREATE USER 'myuser'@'localhost' IDENTIFIED BY 'mypassword';
GRANT ALL PRIVILEGES ON mydb.* TO 'myuser'@'localhost';
5.如何在MySQL中备份和恢复数据?
可以使用mysqldump工具来备份和恢复数据。要备份名为“mydb”的数据库,可以使用以下命令:
mysqldump -u username -p mydb > mydb_backup.sql
要恢复备份的数据,可以使用以下命令:
mysql -u username -p mydb < mydb_backup.sql
6.如何优化MySQL查询?
可以通过以下方法来优化MySQL查询:
- 创建索引以加快查询速度
- 避免在WHERE子句中使用函数或表达式,以免影响查询性能
- 只请求需要的列,避免不必要的数据传输
- 对于需要返回大量记录的查询,使用LIMIT子句限制返回的记录数,减少查询响应时间
7.drop,delete和truncate删除数据的区别?
-
delete 语句执行删除是每次从表中删除一行,并且同时将改行的删除操作作为事务记录在日志中保存以便进行回滚。
-
truncate 则是一次从表中删除所有的数据并不把单独的删除操作记录计入日志,删除行是不能恢复的。执行速度很快
-
drop 是将表所占的空间全部释放掉。
在删除速度上, drop>truncate>delete
想要删除部分数据用delete,想要删除表用drop。 想保留表但是把数据删除,如果和事务无关用
truncate
8.MySQL主从原理

从库生成两个线程,一个I/O线程,一个SQL线程;
i/o线程去请求主库 的binlog,并将得到的binlog日志写到relay log(中继日志) 文件中;
主库会生成一个 log dump 线程,用来给从库 i/o线程传binlog;
SQL 线程,会读取relay log文件中的日志,并解析成具体操作,来实现主从的操作一致,而最终数据一致;
9.MySQL主从复制存在哪些问题?
mysql主从复制存在的问题:主库宕机后,数据可能丢失,从库只有一个sql Thread,主库写压力大,
复制很可能延时。
解决方法: 用半同步复制解决数据丢失的问题
用并行复制解决从库复制延迟的问题。
10.MySQL复制的方法
级联复制:将主库的数据同步到级联库,然后级联库把自己的数据同步到从库上,这样可以减少主库的压力

半同步复制:
默认情况下,MySQL的复制功能是异步的,异步复制可以提供最佳的性能,主库把binlog日志发送给从库即结束,并不验证从库是否接收完毕。这意味着当主库或从库发生故障时,有可能从库没有接收到主库发送过来的binlog日志,这就会造成主库和从库的数据不一致,甚至在恢复时造成数据的丢失。
在开启了半同步复制机制后,主库只有当有任意一台从库已经接收到主库的数据后,告诉主库。主库收到从库同步成功的信息后,才继续后面的操作。
11.主从延迟产生的原因及解决方案?
-
主库的并发比较高的时候,产生的DDL数量超过了从库的一个sql线程所承受的范围,那么延时就产生了。
-
还有可能是与从库的大型query语句产生的了锁等待 。
-
网络抖动
解决方案:
1)、架构方面
1.业务的持久化层的实现采用分库架构,mysql服务可平行扩展,分散压力。
2.单个库读写分离,一主多从,主写从读,分散压力。这样从库压力比主库高,保护主库。
3.服务的基础架构在业务和mysql之间加入memcache或者redis的cache层。降低mysql的读压力。
4.不同业务的mysql物理上放在不同机器,分散压力。
5.使用比主库更好的硬件设备作为slave总结,mysql压力小,延迟自然会变小。
2)、mysql主从同步加速
1、sync_binlog在slave端设置为0
2、–logs-slave-updates 从服务器从主服务器接收到的更新不记入它的二进制日志。
3、直接禁用slave端的binlog
12.判断主从延迟的方法
可以通过命令 show slave status 查看
比如通过seconds_behind_master的值来判断
NULL - 表示io_thread或是sql_thread有任何一个发生故障,也就是该线程的Running状态是No,而非Yes.
0 - 该值为零,是我们极为渴望看到的情况,表示主从复制状态正常
13.MySQL忘记root密码如何找回
1.在配置文件里加上skip-grant-tables ,重启MySQL
2.使用MySQL-uroot -p 进入
3.使用update 修改密码
mysql> USE mysql ;
mysql> UPDATE user SET Password = password ( 'new-password' ) WHERE User =
'root' ;
14.MySQL的数据备份方式
工具一 MySQLdump工具备份
工具二: xtrabackup工具备份
备份分为:冷备,温备和热备
根据要备份的数据集合又分为: 完全备份,增量备份和差异备份
需要备份的对象:
-
数据
-
配置文件
-
OS相关的配置文件
-
代码: 存储过程,存储函数和处罚器
-
复制相关的配置
-
二进制日志
数据量比较大的时候用xtrabackup
基于MySQLdump做备份策略: 周日做全备,备份同时滚动日志
周一到周六:备份二进制文件
恢复的时候: 完全备份+二进制文件中到此处的事件
xtrabackup的特点:
1) 备份过程快速、可靠;
2) 备份过程不会打断正在执行的事务;
3) 能够基于压缩等功能节约磁盘空间和流量;
4) 自动实现备份检验;
5) 还原速度快;

逻辑备份: 类似于select * from 查询满足条件的备份
物理本分: 备份文件+日志文件
所以xtrabackup就是物理备份
MySQLdump就是逻辑备份
15. innodb的特性
一:插入缓冲
二:二次写
三:自适应哈希
四:预读
16.varchar(100)和varchar(200)的区别
varchar(100)最多存放100个字符,varchar(200)最多存放200个字符,varchar(100)和(200)存储hello所占空间一样,但后者在排序时会消耗更多内存,因为order by col采用fixed_length计算col长度(memory引擎也一样
17.MySQL主要的索引类型
普通索引:是最基本的索引,它没有任何限制;
唯一索引:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一;
主键索引:是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值;
组合索引:指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被
使用。使用组合索引时遵循最左前缀集合;
全文索引:主要用来查找文本中的关键字,而不是直接与索引中的值相比较,mysql中MyISAM支持全文
索引而InnoDB不支持;
18. 请说出非关系型数据库的典型产品、特点及应用场景?
MongoDB
特点:1.高性能,易部署,易使用。
2.面向集合存储,易存储对象类型的数据。
3.模式自由
4.自动处理碎片,以支持云计算层次的扩展性。
应用场景:
网站数据:mongodb非常适合实时的插入,更新与查询。
缓存:适合作为信息基础设施的缓存层
大尺寸、低价值的数据
高伸缩性的场景
```
```
Redis
特点:1.性能极高,能支持超过100k+每秒的读写频率
2.丰富的数据类型
3.所有操作都是原子性的
使用场景:
少量的数据存储,高速读写访问
SQLlite
特点:
1.嵌入式的,零配置,无需安装和管理配置
2.ACID事务
3.存储在单一磁盘文件中的一个完整的数据库。
应用场景:
1.需要数据库的小型桌面软件。
2.需要数据库的手机软件。
3.作为数据容器的应用场景。
19.如何加强MySQL安全,请给出可行的具体措施?
1.避免直接从互联网访问mysql数据库,确保特定主机才拥有访问权限。
2.定期备份数据库
3.禁用或限制远程访问
在my.cnf文件里设置bind-address指定ip
4.移除test数据库(默认匿名用户可以访问test数据库)5.禁用local infile
mysql> select load_file(“/etc/passwd”);
在my.cnf里[mysqld]下添加set-variable=local-infile=0
6.移除匿名账户和废弃的账户
7.限制mysql数据库用户的权限
8.移除和禁用.mysql_history文件
20.Binlog工作模式有哪些?各什么特点,企业如何选择?
1.row level行级模式
优点:记录数据详细(每行),主从一致
缺点:占用大量的磁盘空间,降低了磁盘的性能
2.statement level模式(默认)
优点:记录的简单,内容少 ,节约了IO,提高性能 缺点:导致主从不一致
3.MIXED混合模式
结合了statement和row模式的优点,会根据执行的每一条具体的SQL语句来区分对待记录的日志形式。
对于函数,触发器,存储过程会自动使用row level模式
企业场景选择:
1.互联网公司使用mysql的功能较少(不用存储过程、触发器、函数),选择默认的statement模式。
2.用到mysql的特殊功能(存储过程、触发器、函数)则选则MIXED模式
3.用到mysql的特殊功能(存储过程、触发器、函数),有希望数据最大化一致则选择row模式。
21.生产一主多从从库宕机,如何手工恢复?
处理方法:重做slave
-
停止slave
-
导入备份数据
3.配置master.info信息
-
启动slave
-
检查从库状态
22.MySQL中MyISAM与InnoDB的区别,至少5点
a. InnoDB支持事务,而MyISAM不支持事务。
b. InnoDB支持行级锁,而MyISAM支持表级锁
c. InnoDB支持MVCC,而MyISAM不支持
d. InnoDB支持外键,而MyISAM不支持
e. InnoDB不支持全文索引,而MyISAM支持
23.网站打开慢,请给出排查方法,如是数据库慢导致,如何排查并解决,请分析并举例?
-
检查操作系统是否负载过高
-
登陆mysql查看有哪些sql语句占用时间过长,show processlist;
-
用explain查看消耗时间过长的SQL语句是否走了索引
-
对SQL语句优化,建立索引
24.xtrabackup的备份,增量备份及恢复的工作原理
XtraBackup基于InnoDB的crash-recovery功能,它会复制InnoDB的data file,由于不锁表,复制出来的数据是不一致的,在恢复的时候使用crash-recovery,使得数据恢复一致。
InnoDB维护了一个redo log,又称为transaction log(事务日志),它包含了InnoDB数据的所有改动情况。当InnoDB启动的时候,它会先去检查data file和transaction log,并且会做两步操作:
XtraBackup在备份的时候,一页一页的复制InnoDB的数据,而且不锁定表,与此同时,XtraBackup还有另外一个线程监视着transaction log,一旦log发生变化,就把变化过的log pages复制走。为什么要着急复制走呢?因为transaction log文件大小有限,写满之后,就会从头再开始写,所以新数据可能会覆盖到旧的数据。
在prepare过程中,XtraBackup使用复制到的transaction log对备份出来的InnoDB data file进行crash recover
25.误执行drop数据,如何通过xtrabackup恢复?
-
关闭mysql服务
-
移除mysql的data目录及数据
-
将备份的数据恢复到mysql的data目录
-
启动mysql服务
26.如何做主从数据一致性校验?
主从一致性校验有多种工具 例如checksum、mysqldiff、pt-table-checksum等
27. MySQL有多少日志
错误日志:记录出错信息,也记录一些警告信息或者正确的信息。
查询日志:记录所有对数据库请求的信息,不论这些请求是否得到了正确的执行。
慢查询日志:设置一个阈值,将运行时间超过该值的所有SQL语句都记录到慢查询的日志文件中。
二进制日志:记录对数据库执行更改的所有操作。
中继日志。
事务日志。
le/details/111957929
28. MySQL binlog的几种日志录入格式以及区别
1.Statement:每一条会修改数据的sql都会记录在binlog中。
优点:不需要记录每一行的变化,减少了binlog日志量,节约了IO,提高性能。(相比row能节约多少性能 与日志量,这个取决于应用的SQL情况,正常同一条记录修改或者插入row格式所产生的日志量还小于Statement产生的日志量,但是考虑到如果带条 件的update操作,以及整表删除,alter表等操作,ROW格式会产生大量日志,因此在考虑是否使用ROW格式日志时应该跟据应用的实际情况,其所 产生的日志量会增加多少,以及带来的IO性能问题。)
缺点:由于记录的只是执行语句,为了这些语句能在slave上正确运行,因此还必须记录每条语句在执行的时候的 一些相关信息,以保证所有语句能在slave得到和在master端执行时候相同 的结果。另外mysql 的复制,像一些特定函数功能,slave可与master上要保持一致会有很多相关问题(如sleep()函数,last_insert_id(),以及user-defined functions(udf)会出现问题).
使用以下函数的语句也无法被复制:
-
LOAD_FILE()
-
UUID()
-
USER()
-
FOUND_ROWS()
-
SYSDATE() (除非启动时启用了 --sysdate-is-now 选项)同时在INSERT …SELECT 会产生比 RBR 更多的行级锁
2.Row:不记录sql语句上下文相关信息,仅保存哪条记录被修改。
优点: binlog中可以不记录执行的sql语句的上下文相关的信息,仅需要记录那一条记录被修改成什么
了。所以rowlevel的日志内容会非常清楚的记录下 每一行数据修改的细节。而且不会出现某些特定情况
下的存储过程,或function,以及trigger的调用和触发无法被正确复制的问题
缺点:所有的执行的语句当记录到日志中的时候,都将以每行记录的修改来记录,这样可能会产生大量的日志内容,比 如一条update语句,修改多条记录,则binlog中每一条修改都会有记录,这样造成binlog日志量会很大,特别是当执行alter table之类的语句的时候,由于表结构修改,每条记录都发生改变,那么该表每一条记录都会记录到日志中。
3.Mixedlevel: 是以上两种level的混合使用,一般的语句修改使用statment格式保存binlog,如一些函数,statement无法完成主从复制的操作,则 采用row格式保存binlog,MySQL会根据执行的每一条具体的sql语句来区分对待记录的日志形式,也就是在Statement和Row之间选择 一种.新版本的MySQL中队row level模式也被做了优化,并不是所有的修改都会以row level来记录,像遇到表结构变更的时候就会以statement模式来记录。至于update或者delete等修改数据的语句,还是会记录所有行的变更。
29. MySQL数据库cpu飙升到500%的话他怎么处理?
当 cpu 飙升到 500%时,先用操作系统命令 top 命令观察是不是 mysqld 占用导致的,如果不是,找出占用高的进程,并进行相关处理
如果是 mysqld 造成的, show processlist,看看里面跑的 session 情况,是不是有消耗资源的 sql 在运行。找出消耗高的 sql,看看执行计划是否准确, index 是否缺失,或者实在是数据量太大造成。
一般来说,肯定要 kill 掉这些线程(同时观察 cpu 使用率是否下降),等进行相应的调整(比如说加索引、改 sql、改内存参数)之后,再重新跑这些 SQL。
也有可能是每个 sql 消耗资源并不多,但是突然之间,有大量的 session 连进来导致 cpu 飙升,这种情况就需要跟应用一起来分析为何连接数会激增,再做出相应的调整,比如说限制连接数等
30.MySQL同步和半同步
一般面试官问这个问题,都伴随着另外一个问题,叫:小伙子,你说一下MySQL主从原理?
当你回答完原理之后,就会问到关于MySQL主从的几种方式的问题。
一般我们的主从同步,分为:半同步复制和异步复制:
MySQL主从复制默认采用的是异步复制的机制进行同步,所谓的异步指的是主库执行完客户端提交的事务之后立即将结果返回给客户端,并不关心从库是否已经接收道binlog并同步。
如果从库还没有接收到binlog的时候主库发生宕机,那么进行主从切换后的从库数据并不能和主库完全
一致。为了解决这个问题,从MySQL 5.5开始以插件的形式支持半同步复制(另需要注意由于半同步复制仅与默认复制通道(for channel “”)兼容,不支持与多源复制混用。)。半同步复制中,当一个客户端提交事务时主库执行完事务并不会立即响应该客户端,而是等待至少有一个从库接收到了binlog并将事务写到自己的relay log中,最后收到从库的ACK响应后才返回给客户端。
半同步这边根据存储引擎处理的逻辑不同又分为after-commit和after-sync两种:
after-commit
主库未收到从库的ACK消息之前,虽然不会让发起事务的会话收到事务提交结果,但是会在存储引擎层先执行提交。这样一来虽然提交事务的会话无法知道事务结果,但其他会话在主库上却是可以正常查询的。如果发生主从切换,那么原本在主库可以查询到的数据,在从库却丢失了
after-sync
也可以叫做增强半同步复制或者无损复制,是MySQL 5.7默认的半同步方式。主库未收到从库的ACK消息之前,发起事务的会话收无法到事务提交结果,存储引擎层也不会执行提交,解决了after-commit的缺陷,保证了数据的严格一致。由于OLTP应用场景大多数是读多写少,读不会产生binlog,所以即便开启无损复制,相比异步复制所损失的性能也并不多半同步复制发生超时,可以由rel_semi_sync_master_timeout参数设置关闭半同步,转而使用异步。
Oracle数据库
1. 什么是 Oracle 数据库?它的主要作用是什么?
Oracle 数据库是一款商业关系型数据库管理系统(RDBMS),它基于 SQL 语言,适用于大型企业环境下的数据处理和管理。它的主要作用是提供可靠的数据存储和管理,支持复杂事务处理和高级查询,以及为企业提供应用程序运行的基础数据服务。
2. Oracle 数据库的架构是什么?
Oracle 数据库的架构主要由以下组件组成:物理组件(包括数据文件、控制文件、归档日志文件、备份文件等)、内存组件(如 SGA、PGA 等)、进程组件(如后台进程、前台进程等)以及逻辑组件(包括表空间、表、索引、视图等)。
3. Oracle 数据库体系结构中的实例和数据库有什么区别?
Oracle 数据库分为实例和数据库两个主要组成部分。实例是正在运行的数据库程序进程,包括了 SGA、PGA、后台进程和前台进程等,用于处理用户请求并管理数据库资源。而数据库则是物理上的数据存储区域,包括了数据文件、控制文件、归档日志文件和参数文件等。
4. Oracle 数据库如何提高性能?
Oracle 数据库的性能优化可以从多个方面入手,例如通过合理使用索引、优化 SQL 语句、设置合理的内存和存储配置、监控和调整资源消耗等。此外,Oracle 提供了多个通用的性能优化工具,如 Oracle Enterprise Manager、AWR 和 ASH 等。
5. Oracle 数据库如何进行备份和恢复?
Oracle 数据库备份可以通过多种方式实现,如全量备份、差异备份、增量备份等。恢复则可以根据不同的备份方式选择不同的恢复策略,如通过闪回(Flashback)技术、重做日志归档等方式进行恢复。此外,Oracle 还提供了 Data Guard 和 RMAN 等专业备份和恢复工具。
6. Oracle 数据库的存储结构是什么?
Oracle 数据库的存储结构主要包括表空间、数据文件、段、区和块等几个层次。其中,表空间是数据存储的最高层次,包含了一个或多个数据文件,数据文件是将实际数据存储到磁盘的文件,而段、区和块则是文件分配和数据管理的辅助结构。
7. 如何保证 Oracle 数据库的安全性?
保证 Oracle 数据库的安全性可以通过多种手段来实现,如使用密码和账户管理策略、设置权限结构和资源限制、启用安全审计和加密传输等措施,此外可以使用专业的安全工具,如访问控制、审计追踪、数据加密等技术。
Redis缓存数据库
1.什么是Redis?
Redis(Remote Dictionary Server)是一种基于内存的开源键值存储系统,是当前最流行的NoSQL数据库之一。它广泛用于缓存、队列、消息发布、订阅等场景,支持多种数据结构(如字符串、哈希、列表、集合、有序集合等)。
2.Redis支持哪些数据结构?
Redis支持多种数据结构,包括:
- 字符串(string)
- 哈希(hash)
- 列表(list)
- 集合(set)
- 有序集合(sorted set)
3.Redis的持久化机制是什么?
Redis支持两种持久化机制:RDB(Redis Database)和AOF(Append Only File)。
- RDB:将内存中的数据以快照的方式保存到磁盘上,可以在Redis重启后使用快照恢复数据。快照可以手动触发,也可以设定自动间隔时间进行。
- AOF:将每个写操作记录下来,以日志的形式追加到文件末尾。Redis重启后会重新执行日志中的所有操作来恢复数据。
4.Redis的主从复制是什么?
Redis支持主从复制机制,它的实现方式是将主数据库的整个数据集复制到从数据库上。主数据库将写操作传播到所有从数据库,从数据库只能读取数据。主从复制在分布式系统的架构中被广泛应用,可以扩展系统的性能和容量。
5.Redis中如何实现分布式锁?
Redis可以使用SETNX命令来实现分布式锁。这个命令可以将一个键设置为一个值,如果该键不存在,则创建,否则不做任何操作。如果在同一时刻有多个请求竞争这个锁,只有一个请求会成功,其他的请求则会失败。
SETNX lock_key 1
6.Redis中如何实现消息队列?
Redis提供了List类型来实现消息队列。将消息放入List的头部,消费者从List的尾部取出消息进行消费,就可以实现一个基本的消息队列。可以使用LPUSH命令将消息放入列表中,使用RPOP命令从列表的尾部取出消息。
7.redis作用 应用场景
作用:
主要用Redis实现缓存数据的存储,可以设置过期时间.对于一些高频读写、临时存储的数据特别适合.
应用场景:
缓存 分布式会话 分布式锁 最新列表 消息系统
8.使用redis好处
①.速度快
②.支持丰富数据类型 (list set hash string)
③.支持事务(原子性)
④.丰富的特性
9.redis主从复制模式下,主挂了怎么办?
redis提供了哨兵模式(高可用)
何谓哨兵模式?就是通过哨兵节点进行自主监控主从节点以及其他哨兵节点,发现主节点故障时自主进行故障转移。
10.请简述出什么是主从复制、哨兵模式以及集群模式?
主从复制:主从复制是高可用Redis的基础,哨兵和集群都是在主从复制基础上实现高可用的。主从复制主要实现了数据的多机备份,以及对于读操作的负载均衡和简单的故障恢复。
缺陷:故障恢复无法自动化;写操作无法负载均衡;存储能力受到单机的限制。
●哨兵:在主从复制的基础上,哨兵实现了自动化的故障恢复。
缺陷:写操作无法负载均衡;存储能力受到单机的限制;哨兵无法对从节点进行自动故障转移,在读写分离场景下,从节点故障会导致读服务不可用,需要对从节点做额外的监控、切换操作。
●集群:通过集群,Redis解决了写操作无法负载均衡,以及存储能力受到单机限制的问题,实现了较为完善的高可用方案。
11.redis为什么任意一个节点挂了(没有从节点)这个集群就挂了?
因为集群内置了16384个slot (哈希槽),并且把所有的物理节点映射到了这16384[0-16383]个slot上,或者说把这些slot均等的分配给了各个节点
当需要在Redis集群存放一个数据(key-value)时, redis会先对这个key进行crc16算法, 然后得到一个结果,再把这个结果对16384进行求余,这个余数会对应[0-16383]其中一个槽,进而决定key-value存储到哪个节点中。所以一旦某个节点挂了,该节点对应的slot就无法使用,那么就会导致集群无法正常工作。
12.redis是单线程还是多线程?
这个问题已经被问过很多次了,从redis4.0开始引入多线程,redis 6.0 中,多线程主要用于网络 I/O 阶段,也就是接收命令和写回结果阶段,而在执行命令阶段,还是由单线程串行执行。由于执行时还是串行,因此无需考虑并发安全问题。
redis 中的多线程组不会同时存在“读”和“写”,这个多线程组只会同时“读”或者同时“写”
在 redis 6.0 之前,redis 的核心操作是单线程的。
因为 redis 是完全基于内存操作的,通常情况下CPU不会是redis的瓶颈,redis 的瓶颈最有可能是机器
内存的大小或者网络带宽。
既然CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了,因为如果使用多线程的话会更复杂,同时需要引入上下文切换、加锁等等,会带来额外的性能消耗。
而随着近些年互联网的不断发展,大家对于缓存的性能要求也越来越高了,因此 redis 也开始在逐渐往多线程方向发展。
13.redis常用的版本是?
redis5.0,redis6.0
14.redis的使用场景?
缓存、分布式锁、排行榜(zset)、计数(incrby)、消息队列(stream)、地理位置(geo)、访客统计(hyperloglog)
16.redis常见的数据结构
常见的5种:
String:字符串,最基础的数据类型。
List:列表。
Hash:哈希对象。
Set:集合。
Sorted Set:有序集合,Set 的基础上加了个分值。
高级的2 种:
-
HyperLogLog:通常用于基数统计。使用少量固定大小的内存,来统计集合中唯一元素的数量。统计结果不是精确值,而是一个带有0.81%标准差(standard error)的近似值。所以,HyperLogLog适用于一些对于统计结果精确度要求不是特别高的场景,例如网站的UV统计。
-
Stream:主要用于消息队列,类似于 kafka,可以认为是 pub/sub 的改进版。提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。
17.redis持久化你们怎么做的?
redis持久化主要有两种 ROD和AOF,当先现在还有混合的,从reids4.0后引入的
RDB实现原理:
RDB类似于快照,在某个时间点,将 Redis 在内存中的数据库状态(数据库的键值对等信息)保存到磁盘里面。RDB 持久化功能生成的 RDB 文件是经过压缩的二进制文件。
RDB的优点:
RDB文件是经过压缩的,占用空间很小,它保存了某个时间点的数据集,很适合做备份。 比如你可以在24小时内,每个小时备份一次RDB文件,并且每个月的每一天备份一个RDB文件。
RDB非常适合用来做灾备恢复,可以加密后传送到数据中心
RDB可以最大化redis的性能
从恢复速度来看,RDB明显要比AOF要快
但是RDB也有一定的缺点:
RDB在服务器故障的时候,容易造成数据损失。 我们通常设置每5分钟保存一次快照,这样数据丢失也只有5分钟的数据。
RDB保存时使用fork子进程数据的持久化,如果数据量大的话,会非常耗时,造成redis停止处理服务N毫秒。
AOF:
保存 Redis 服务器所执行的所有写操作命令来记录数据库状态,并在服务器启动时,通过重新执行这些命令来还原数据集。
AOF默认是关闭的,可以通过appendonley yes 开启AOF 持久化功能的实现可以分为三个步骤:命令追加、文件写入、文件同步。
AOF的优点:
1)AOF 比 RDB可靠。你可以设置不同的 fsync 策略:no、everysec 和 always。默认是 everysec,在这种配置下,redis 仍然可以保持良好的性能,并且就算发生故障停机,也最多只会丢失一秒钟的数据。
2)AOF文件是一个纯追加的日志文件。即使日志因为某些原因而包含了未写入完整的命令(比如写入时磁盘已满,写入中途停机等等), 我们也可以使用 redis-check-aof 工具也可以轻易地修复这种问题。
3)当 AOF文件太大时,Redis 会自动在后台进行重写:重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。整个重写是绝对安全,因为重写是在一个新的文件上进行,同时 Redis 会继续往旧的文件追加数据。当新文件重写完毕,Redis 会把新旧文件进行切换,然后开始把数据写到新文件上。
4) AOF 文件有序地保存了对数据库执行的所有写入操作以 Redis 协议的格式保存, 因此 AOF 文件的内容非常容易被人读懂, 对文件进行分析(parse)也很轻松。如果你不小心执行了 FLUSHALL 命令把所有数据刷掉了,但只要 AOF 文件没有被重写,那么只要停止服务器, 移除 AOF 文件末尾的FLUSHALL 命令, 并重启 Redis , 就可以将数据集恢复到 FLUSHALL 执行之前的状态。
AOF缺点:
1) 对于相同的数据集,AOF的文件一般会比RDB大
2) AOF所使用的fsync策略,备份速度也会比RDB曼
如何使用:
如果想尽量保证数据安全性, 你应该同时使用 RDB 和 AOF 持久化功能,同时可以开启混合持久化。
如果想尽量保证数据安全性, 你应该同时使用 RDB 和 AOF 持久化功能,同时可以开启混合持久化。
如果你的数据是可以丢失的,则可以关闭持久化功能,在这种情况下,Redis 的性能是最高的。
18. 主从复制实现的原理
Redis虽然读取写入的速度都特别快,但是也会产生读压力特别大的情况,为分担读压力,Redis支持主从复制,Redis的主从结构可以采用一主多从或者级联结构,Redis主从复制可以根据是否是全量分为全量同步和增量同步
19.redis哨兵模式原理
哨兵是特殊的redis服务,不提供读写服务,主要用来监控redis实例节点。 哨兵架构下client端第一次从哨兵找出redis的主节点,后续就直接访问redis的主节点,不会每次都通过 sentinel代理访问redis的主节点,当redis的主节点发生变化,哨兵会第一时间感知到,并且哨兵会早主从模式的从节点中重新选出来一个新的master,并且将新的master信息通知给client端。
这里面redis的client端一般都实现了订阅功能,订阅sentinel发布的节点变动消息。Redis服务是通过配置文件启动的,比如上面的从节点设置了只读模式,它被选举成了master之后就是可读写的了,感觉很奇怪,后来看了下重新选举之后的各redis服务的配置文件,发现文件里面的内容会被哨兵修改。要想真的高可用,我们的哨兵也要集群模式。

20.memcache和redis的区别
1、 Redis和Memcache都是将数据存放在内存中,都是内存数据库。不过memcache还可用于缓存其他东西,例如图片、视频等等。
2、Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,hash等数据结构的存储。
3、虚拟内存–Redis当物理内存用完时,可以将一些很久没用到的value 交换到磁盘
4、过期策略–memcache在set时就指定,例如set key1 0 0 8,即永不过期。Redis可以通过例如expire设定,例如expire name 10
5、分布式–设定memcache集群,利用magent做一主多从;redis可以做一主多从。都可以一主一从
6、存储数据安全–memcache挂掉后,数据没了;redis可以定期保存到磁盘(持久化)
7、灾难恢复–memcache挂掉后,数据不可恢复; redis数据丢失后可以通过aof恢复
8、Redis支持数据的备份,即master-slave模式的数据备份。
redis和memecache的不同在于[2]:
1、存储方式:
memecache 把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小
redis有部份存在硬盘上,这样能保证数据的持久性,支持数据的持久化(笔者注:有快照和AOF日志两
种持久化方式,在实际应用的时候,要特别注意配置文件快照参数,要不就很有可能服务器频繁满载做dump)。
2、数据支持类型:
redis在数据支持上要比memecache多的多。
3、使用底层模型不同:
新版本的redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
4、运行环境不同:
redis目前官方只支持LINUX 上去行,从而省去了对于其它系统的支持,这样的话可以更好的把精力用于本系统 环境上的优化,虽然后来微软有一个小组为其写了补丁。但是没有放到主干上
个人总结一下,有持久化需求或者对数据结构和处理有高级要求的应用,选择redis,其他简单的key/value存储,选择memcache。
21.redis有哪些架构模式?


Redis 的复制(replication)功能允许用户根据一个 Redis 服务器来创建任意多个该服务器的复制品,其中被复制的服务器为主服务器(master),而通过复制创建出来的服务器复制品则为从服务器(slave)。 只要主从服务器之间的网络连接正常,主从服务器两者会具有相同的数据,主服务器就会一直将发生在自己身上的数据更新同步 给从服务器,从而一直保证主从服务器的数据相同。
特点:
1、master/slave 角色2、master/slave 数据相同
3、降低 master 读压力在转交从库
问题:
无法保证高可用
没有解决 master 写的压力
Redis sentinel 是一个分布式系统中监控 redis 主从服务器,并在主服务器下线时自动进行故障转移。其中三个特性:
监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作。
特点:
1、保证高可用
2、监控各个节点
3、自动故障迁移
缺点:
主从模式,切换需要时间丢数据
没有解决 master 写的压力

Twemproxy 是一个 Twitter 开源的一个 redis 和 memcache 快速/轻量级代理服务器; Twemproxy 是一个快速的单线程代理程序,支持 Memcached ASCII 协议和 redis 协议。
特点:
1、多种 hash 算法:MD5、CRC16、CRC32、CRC32a、hsieh、murmur、Jenkins
2、支持失败节点自动删除
3、后端 Sharding 分片逻辑对业务透明,业务方的读写方式和操作单个 Redis 一致
缺点:
增加了新的 proxy,需要维护其高可用。
failover 逻辑需要自己实现,其本身不能支持故障的自动转移可扩展性差,进行扩缩容都需要手动干预
22.redis 缓存雪崩?
在前面学习我们都知道Redis不可能把所有的数据都缓存起来(内存昂贵且有限),所以Redis需要对数据
设置过期时间,并采用的是惰性删除+定期删除两种策略对过期键删除。Redis对过期键的策略+持久化
如果缓存数据设置的过期时间是相同的,并且Redis恰好将这部分数据全部删光了。这就会导致在这段时间内,这些缓存同时失效,全部请求到数据库中
什么是缓存雪崩?
Redis挂掉了,请求全部走数据库。
对缓存数据设置相同的过期时间,导致某段时间内缓存失效,请求全部走数据库。
缓存雪崩如果发生了,很可能就把我们的数据库搞垮,导致整个服务瘫痪!
解决方法:
在缓存的时候给过期时间加上一个随机值,这样就会大幅度的减少缓存在同一时间过期。
对于“Redis挂掉了,请求全部走数据库”这种情况,我们可以有以下的思路:
**事发前:**实现Redis的高可用(主从架构+Sentinel 或者Redis Cluster),尽量避免Redis挂掉这种情况发生。
**事发中:**万一Redis真的挂了,我们可以设置本地缓存(ehcache)+限流(hystrix),尽量避免我们的数据库被干掉(起码能保证我们的服务还是能正常工作的)
**事发后:**redis持久化,重启后自动从磁盘上加载数据,快速恢复缓存数据。
23.redis缓存穿透
什么是缓存穿透
缓存穿透是指查询一个一定不存在的数据。由于缓存不命中,并且出于容错考虑,如果从数据库查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,失去了缓存的意义
请求的数据在缓存大量不命中,导致请求走数据库。
缓存穿透如果发生了,也可能把我们的数据库搞垮,导致整个服务瘫痪!
如何解决缓存穿透
由于请求的参数是不合法的(每次都请求不存在的参数),于是我们可以使用布隆过滤器(BloomFilter)或者压缩filter提前拦截,不合法就不让这个请求到数据库层!
当我们从数据库找不到的时候,我们也将这个空对象设置到缓存里边去。下次再请求的时候,就可以从缓存里边获取了。
这种情况我们一般会将空对象设置一个较短的过期时间。
24.redis 缓存击穿
某一个热点key,在不停地扛着高并发,当这个热点key在失效的一瞬间,持续的高并发访问就击破缓存直接访问数据库,导致数据库宕机。
设置热点数据"永不过期" 加上互斥锁:上面的现象是多个线程同时去查询数据库的这条数据,那么我们可以在第一个查询数据的请求上使用一个互斥锁来锁住它 其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后将数据放到redis缓存起来。
后面的线程进来发现已经有缓存了,就直接走缓存
总结:
雪崩是大面积的key缓存失效;穿透是redis里不存在这个缓存key;击穿是redis某一个热点key突然失效,最终的受害者都是数据库。
25. redis为什么这么快
1、完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于 HashMap,HashMap 的优势就是查找和操作的时间复杂度都是O(1);
2、数据结构简单,对数据操作也简单,Redis 中的数据结构是专门进行设计的;
3、采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
4、使用多路 I/O 复用模型,非阻塞 IO;
5、使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis 直接自己构建了 VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求
26.memcache有哪些应用场景
作为数据库的前端缓存应用: 完整缓存,静态缓存。
比如 商品分类,商品信息
27. memcache服务特点及工作原理
a. 完全基于内存缓存的
b、节点之间相互独立
c、C/S模式架构,C语言编写,总共2000行代码。
d、异步I/O 模型,使用libevent作为事件通知机制。
e、被缓存的数据以key/value键值对形式存在的。
f、全部数据存放于内存中,无持久性存储的设计,重启服务器,内存里的数据会丢失。
g、当内存中缓存的数据容量达到启动时设定的内存值时,就自动使用LRU算法删除过期的缓存数据。
h、可以对存储的数据设置过期时间,这样过期后的数据自动被清除,服务本身不会监控过期,而是在访问的时候查看key的时间戳,判断是否过期。
j、memcache会对设定的内存进行分块,再把块分组,然后再提供服务
28.memcached是如何做身份验证的?
没有身份认证机制,如果你想限制访问,可以使用防火墙
29.mongoDB是什么?
MongoDB是一个文档数据库,提供好的性能,领先的非关系型数据库。采用BSON存储文档数据。
BSON()是一种类json的一种二进制形式的存储格式,简称Binary JSON.
相对于json多了date类型和二进制数组。
30.mongodb的优势
面向文档的存储:以 JSON 格式的文档保存数据。
任何属性都可以建立索引。
复制以及高可扩展性。
自动分片。
丰富的查询功能。
快速的即时更新。
31.mongodb使用场景
大数据
内容管理系统
移动端Apps
数据管理
GFS分布式文件系统
1.请简要介绍 Google 文件系统(GFS)以及其适用场景。
Google 文件系统(GFS)是一个分布式文件系统,旨在解决大规模数据存储和处理的问题。GFS 的适用场景包括需要存储大型、高可用性数据集的企业,如 Web 搜索、科学模拟、大规模数据分析等。GFS 在存储、管理和处理海量数据方面具有出色的性能和可靠性。
2. 请简要介绍 GFS 的架构组件。
GFS 的架构由三个主要组件组成:客户端、主服务器和各个分布式存储单元(chunkserver)。客户端处理文件系统接口的请求,主服务器负责元数据的管理和调度操作,分布式存储单元(chunkserver)则负责数据的实际存储、读取和备份。
3.请问 GFS 是否允许多用户同时访问同一文件?
是的。GFS 允许多个用户同时访问同一个文件。GFS 使用文件锁定机制来控制并发访问,保证文件安全。
4. 请问 GFS 在数据备份方面有什么考虑?
GFS 将数据分为固定大小的块并进行备份。每个数据块在多个 chunkserver 上进行备份,以实现数据冗余和可靠性。通常,数据块备份数量可以配置,在三个副本以上为最佳实践。在数据块损坏时,GFS 会自动尝试恢复。
5.请简要介绍 GFS 的缺陷和挑战。
GFS 最大的缺陷之一是不支持并发写入和文件追加操作。此外,在管理和维护一个大型分布式系统方面也具有挑战性。例如,需要维护大量的服务器、网络连接和数据备份等。 GFS 的设计需要在可靠性、性能和可扩展性之间权衡,这也是一个挑战。
6.GlusterFS的工作流程 并且说出术语
工作流程
(1)客户端或应用程序通过 GlusterFS 的挂载点访问数据。
(2)linux系统内核通过 VFS API 收到请求并处理。
(3)VFS 将数据递交给 FUSE 内核文件系统,并向系统注册一个实际的文件系统 FUSE,而 FUSE 文件系统则是将数据通过 /dev/fuse 设备文件递交给了 GlusterFS client 端。可以将 FUSE 文件系统理解为一个代理。
(4)GlusterFS client 收到数据后,client 根据配置文件的配置对数据进行处理。
(5)经过 GlusterFS client 处理后,通过网络将数据传递至远端的 GlusterFS Server,并且将数据写入到服务器存储设备上。
各流程中的术语
- brick 存储服务器:实际存储用户数据的服务器
- volumen 本地文件系统的"分区” 多个磁盘融合 逻辑卷
- FUSE :用户空间的文件系统(类比EXT4),"这是一个伪文件系统”
以本地文件系统为例,用户想要读写一个文件,会借助于EXT4文件系统,然后把数据写在磁盘上而如果是远端的GFS,客户端的请求则应该交给 - FUSE(为文件系统),就可以实现跨界点存储在GFS上FUSE(用户空间的文件系统)伪文件系统用户端的交互模块 接口
- VFS(虚拟端口):内核态的虚拟文件系统,用户是先提交请求交给VFS 然后VFS交给FUSE 再交给GFs客户端,最后由客户端交给远端的存储
7.GlusterFS日常使用的哪五种卷,并且说明五种卷作用(原理和特点)?
① 分布式卷:File1 和 File2 存放在 Server1,而 File3 存放在 Server2,文件都是随机存储,一个文件(如 File1)要么在 Server1 上,要么在 Server2 上,不能分块同时存放在 Server1和 Server2 上
特点:文件分布在不同的服务器,不具备冗余性更容易和廉价地扩展卷的大小单点故障会造成数据丢失依赖底层的数据保护
② 条带卷:类似 RAID0,文件被分成数据块并以轮询的方式分布到多个 Brick Server 上,文件存储以数据块为单位,支持大文件存储, 文件越大,读取效率越高,但是不具备冗余性
特点:根据偏移量将文件分成N块(N个条带点),轮询的存储在每个Brick Serve 节点.分布减少了负载,在存储大文件时,性能尤为突出.没有数据冗余,类似于Raid 0
③ 复制卷:file1 同时存在 Server1 和 Server2,File2 也是如此,相当于 Server2 中的文件是 Server1 中文件的副本
特点:卷中所有的服务器均保存一个完整的副本。具备冗余性.卷的副本数量可由客户创建的时候决定,但复制数必须等于卷中 Brick 所包含的存储服务器数。至少由两个块服务器或更多服务器。若多个节点上的存储空间不一致,将按照木桶效应取最低节点的容量作为改卷的总容量
④ 分布式条带卷:File1 和 File2 通过分布式卷的功能分别定位到Server1和 Server2。在 Server1 中,File1 被分割成 4 段,其中 1、3 在 Server1 中的 exp1 目录中,2、4 在 Server1 中的 exp2 目录中。在 Server2 中,File2 也被分割成 4 段,其中 1、3 在 Server2 中的 exp3 目录中,2、4 在 Server2 中的 exp4 目录中
特点:Brick Server 数量是条带数(数据块分布的 Brick 数量)的倍数,兼具分布式卷和条带卷的特点。 主要用于大文件访问处理**,创建一个分布式条带卷最少需要 4 台服务器
⑤ 分布式复制卷:File1 和 File2 通过分布式卷的功能分别定位到 Server1 和 Server2。在存放 File1 时,File1 根据复制卷的特性,将存在两个相同的副本,分别是 Server1 中的exp1 目录和 Server2 中的 exp2 目录。在存放 File2 时,File2 根据复制卷的特性,也将存在两个相同的副本,分别是 Server3 中的 exp3 目录和 Server4 中的 exp4 目录
特点:Brick Server 数量是镜像数(数据副本数量)的倍数,兼具分布式卷和复制卷的特点,主要用于需要冗余的情况下。
8.如何查看GlusterFS卷
gluster volume list
9.查看所有卷的信息
gluster volume info
10.查看所有卷的状态
gluster volume status
11.如何停止一个卷和删除一个卷?
停止卷
gluster volume stop dis-stripe
删除卷
gluster volume delete dis-stripe
12.如何设置卷的黑白名单?
#仅拒绝 黑
gluster volume set dis-rep auth.deny 192.168.10.23
#仅允许 白
gluster volume set dis-rep auth.allow 192.168.10.* #设置192.168.10.0网段的所有IP地址都能访问dis-rep卷(分布式复制卷)
ELK日志收集
1. 什么是 ELK?它的主要作用是什么?
ELK 是一组开源软件的缩写,包括 Elasticsearch、Logstash 和 Kibana。Elasticsearch 是一个分布式搜索和分析引擎,Logstash 是一个用于收集、解析和转换数据的工具,Kibana 是一个用于展示和可视化 Elasticsearch 数据的 Web 界面。ELK 的主要作用是实现实时的日志分析和可视化监控,帮助 IT 运维人员实时掌握系统状态,快速诊断和解决问题。
2. ELK 的架构是什么?
ELK 的架构分为三层,每一层都可分别扩展,以处理大量的日志数据。第一层是数据采集层,使用 Logstash 将各个源数据收集并解析成规范格式;第二层是数据存储层,使用 Elasticsearch 存储和搜索数据;第三层是数据展示层,使用 Kibana 将 Elasticsearch 中的数据进行可视化展示。
3. ELK 如何实现日志分析和异常监控?
ELK 可以通过收集整理和存储大量的日志数据,通过使用 Elasticsearch 的查询语句进行实时分析和搜索。当出现异常时,ELK 可以通过预设的警告规则和告警机制,及时的通知用户或记录异常信息。
4. ELK 如何管理和处理日志?
ELK 可以通过 Logstash 的管道(Pipeline)配置文档来定义从源采集、处理、转换和路由到目标的流程。在流程中,可以通过各种插件来对收集到的日志进行过滤、正则匹配、格式化等操作。最终将处理好的数据通过 Elasticsearch 这个 NoSQL 数据库进行存储分析和搜索查询。
5. ELK 如何解决日志查询效率问题?
Elasticsearch 是一款分布式搜索引擎,能够快速处理任意数量级的日志数据,较高的查询效率得益于其基于分布式的倒排索引技术。另外,可以通过配置 Elasticsearch 的索引、分片、副本、缓存等参数,来提高查询效率。
6. ELK 如何保证数据安全性?
ELK 可以使用支持 HTTPS 协议的安全套接字层,将数据加密传输。同时,Elasticsearch 还提供了访问控制和数据加密机制,用于管理和保护 Elasticsearch 中的数据。
7. ELK 的优势和缺点是什么?
ELK 的优势包括易于安装和使用、自定义性强、可扩展性高等特点,还可以通过自适应模式对停机时间进行优化处理。缺点则包括可能出现数据丢失和安全性问题、配置和维护上的复杂度
8.ELK的组成以及功能
ELK是三个开源软件的缩写,分别表示:Elasticsearch、Logstash、Kibana
Elasticsearch是个开源分布式搜索引擎,提供搜集,分析,存储数据三大功能
Logstash主要用来日志的收集、分析、过滤日志的工具、支持大量数据获取方式。
Kibana也是一个开源和免费的工具,kibana可以为Logstash和Elasticserch提供日志分析友好的web界面,可以帮助汇总、分析和搜索重要的数据日志
9.ELK的工作原理
1、在所有需要日志的服务器上部署Logstash,或者先将日志进行集中化管理在日志服务器上,在日志服务器上部署Logstash。
2、Logstash收集日志,将日志格式化并输出到Elasticsearch集群中。
3、Elasticserarch对格式化后的数据进行索引和存储
4、kibana从ES集群中查询数据生成图表,并进行前端数据的展示。
Elasticsearch的默认端口9200;Kibana默认端口5601
FileBeat,他是一个轻量级的日志收集处理工具(Agent)FileBeat占用资源少,适合在各个服务器上收集日志后传输给Logstash
10.logstash的架构
input: 数据收集
filter: 数据加工
output: 数据输出
shipper: 用于收集日志数据,监控本地日志数据的变化,及时把日志文件的最新内容收集起来,然后经
过加工,过滤,输出到broker
broker: 相当于日志的hub,用来连接多个shipper和多个indexer
indexer: 从boker读取文本,经过加工,过滤输出到指定介质。 redis服务器就是官方推荐的broker
11.ELK工作流程

12. logstash的输入源有哪些?
Logstash输入来源有那些?
本地文件、kafka、数据库、mongdb、redis。
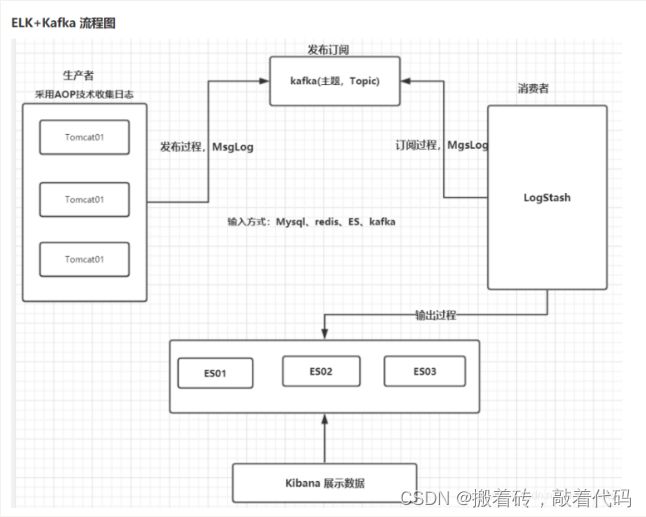
13. logstash的架构
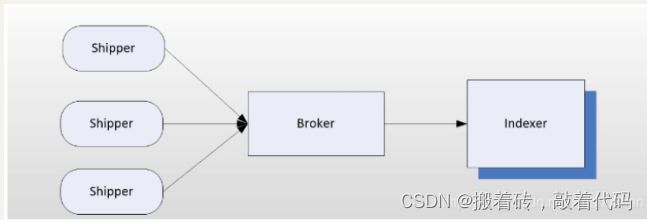
input: 数据收集
filter: 数据加工
output: 数据输出
shipper: 用于收集日志数据,监控本地日志数据的变化,及时把日志文件的最新内容收集起来,然后经过加工,过滤,输出到broker
broker: 相当于日志的hub,用来连接多个shipper和多个indexer
indexer: 从boker读取文本,经过加工,过滤输出到指定介质。 redis服务器就是官方推荐的broker
14.ELK相关的概念
Node: 装有一个 ES 服务器的节点。
Cluster: 有多个Node组成的集群
Document: 一个可被搜素的基础信息单元
Index: 拥有相似特征的文档的集合Type: 一个索引中可以定义一种或多种类型
Filed: 是 ES 的最小单位,相当于数据的某一列
Shards: 索引的分片,每一个分片就是一个 Shard
Replicas: 索引的拷贝
15. es常用的插件
-
公司的代码用的gitlab,所以我们使用gitlab插件来拉取代码
-
gitlab webhook 支持gogs 代码仓库的触发
-
在构建过程中,需要用到脚本语言,比如groovy,powershell,这些脚本语言就需要相应的插件来执行脚本
-
构建完了之后需要发送邮件,可以使用 Email Extension Plugin来定义发送邮件
-
jenkins与钉钉结合实现告警: DingDing plugin
-
能够支持一件构建的: bulid pipeline plugin ,一次构建几十个jobs
-
传送文件到目标服务然后执行命令: publish over ssh
-
git插件,用于托管自动化测试代码和协作开发
-
build history metrics plugin 用于job进行统计的插件
10.jenkins与ansible结合: ansibleplaybook
16.ELK索引迁移有没有做过,怎么做?
elasticsearch-dump迁移
Elasticsearch-Exporter迁移:可实现跨机器索引的迁移
logstash定向索引迁移
elasticsearch-migration工具
支持多个版本间的数据迁移,使用scroll+bulk
1.版本支持1.x,2.x.5.0 (0.x未测试)
2.支持http basic auth 认证的es集群
3.支持导入覆盖索引名称(目前只支持单个索引导入的情况下可指定)
4.支持index setting和mapping的同步(相关es大版本,2.x和5.0之间不支持)
5.支持dump到本地文件
6.支持从dump文件加载导入到指定索引
Elasticsearch-Exporter在索引迁移方面相对更好用
17.ELK索引故障是什么原因导致的?
硬件故障:硬件故障是导致 Elasticsearch 集群中索引出现问题的常见原因之一。例如,磁盘损坏、内存故障等问题都可能导致索引无法正常工作。
索引数据异常:索引数据异常也可能导致 Elasticsearch 索引出现问题。例如,可能会出现文档损坏、字段格式错误、数据类型不匹配等问题。
资源限制:Elasticsearch 集群的资源限制也可能导致索引出现问题。例如,如果 Elasticsearch 集群中的节点过于繁忙,可能会导致某些索引无法正常工作。
配置错误:错误的配置也可能导致 Elasticsearch 索引出现问题。例如,可能会出现节点配置错误、索引配置错误等问题。
版本兼容性问题:如果 Elasticsearch 集群中的不同节点运行的版本不兼容,也可能导致索引出现问题。因此,要确保所有节点运行的 Elasticsearch 版本相同。
18.ELK索引red状态是出现了什么问题?
缺少副本分片:Elasticsearch 会自动将每个主分片分配到不同的节点上,并复制多个副本分片以保证数据的高可用性。如果某个主分片丢失,副本分片将会自动接管。但是,如果某个主分片所对应的所有副本分片都不可用,那么该分片所在的索引就会变成红色。这通常是由于某些节点故障或者集群中的可用资源不足导致的。
索引损坏:如果索引中某个分片损坏,那么该分片所在的索引也会变成红色。通常,这种情况可能是由于硬件故障、节点宕机等原因引起的。
内存不足
Zookeeper 协调服务
1.什么是ZooKeeper?
ZooKeeper是一种分布式开源协调服务,可用于分布式系统的管理和协调。它提供了一个可靠的、高可用性的协调性服务,使得应用程序可以更容易地管理分布式系统的配置信息、命名服务、集群状态和分布式同步等。
2.ZooKeeper的主要功能是什么?
ZooKeeper的主要功能包括:
- 命名服务:ZooKeeper为分布式系统提供了一个可靠的命名服务,允许客户端在分布式环境中访问和管理数据节点。
- 分布式同步:ZooKeeper提供了一个统一的机制来管理分布式系统中的同步和序列化问题,使得多个客户端可以安全地共享数据。
- 实时监控:ZooKeeper可以实时监控分布式系统的状态和运行情况,包括节点的连接状态、数据变更等。
- 配置管理:ZooKeeper提供了一种可靠的方法来管理和动态更新分布式系统的配置信息。
3.ZooKeeper是如何保证数据的一致性?
ZooKeeper使用基于Paxos算法的原子广播协议来保证数据的一致性。在基于ZooKeeper的应用程序中,客户端可以发送事务更新请求,ZooKeeper会根据时间戳的方式对请求进行编号,然后将其广播到所有参与的服务器。一旦大多数服务器都接受了相同的事务消息,就会形成一个完整的事务,然后该事务将被提交并写入存储中。
4.ZooKeeper与其他分布式系统如何交互?
ZooKeeper可以与其他分布式系统进行交互,例如Hadoop、Kafka、Storm等。这些系统可以使用ZooKeeper作为协调服务,以确保它们在分布式环境下的正确运行。
5.ZooKeeper适用于哪些应用场景?
ZooKeeper适用于许多不同的分布式应用场景,例如:
- 分布式锁:使用ZooKeeper的临时顺序节点,可以实现分布式锁机制,用于控制多个进程对共享资源的访问。
- 选主机制:多个服务器之间可以通过ZooKeeper进行通信,使用ZooKeeper的选举机制,可以动态选举一台服务器为主机,保证系统的稳定性和可用性。
- 配置管理:通过将配置信息存储在ZooKeeper的节点中,可以实现分布式系统的管理和配置,从而简化应用程序的部署和维护。
- 发现服务:使用ZooKeeper的命名服务可以动态发现网络中的其他服务实例,从而实现负载均衡和故障转移。
5.zookeeper的选举机制
两个答案都可以
4.1 第一个答案
●第一次启动选举机制
(1)服务器1启动,发起一次选举。服务器1投自己一票。此时服务器1票数一票,不够半数以上(3票),选举无法完成,服务器1状态保持为LOOKING;
(2)服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的myid比自己目前投票推举的(服务器1)大,更改选票为推举服务器2。此时服务器1票数0票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持LOOKING
(3)服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING;
(4)服务器4启动,发起一次选举。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为FOLLOWING;
(5)服务器5启动,同4一样当小弟。
●非第一次启动选举机制
(1)当ZooKeeper 集群中的一台服务器出现以下两种情况之一时,就会开始进入Leader选举:
1)服务器初始化启动。
2)服务器运行期间无法和Leader保持连接。
(2)而当一台机器进入Leader选举流程时,当前集群也可能会处于以下两种状态:
1)集群中本来就已经存在一个Leader。
对于已经存在Leader的情况,机器试图去选举Leader时,会被告知当前服务器的Leader信息,对于该机器来说,仅仅需要和 Leader机器建立连接,并进行状态同步即可。
2)集群中确实不存在Leader。
假设ZooKeeper由5台服务器组成,SID分别为1、2、3、4、5,ZXID分别为8、8、8、7、7,并且此时SID为3的服务器是Leader。某一时刻,3和5服务器出现故障,因此开始进行Leader选举。
选举Leader规则:
1.EPOCH大的直接胜出
2.EPOCH相同,事务id大的胜出
3.事务id相同,服务器id大的胜出
4.2第二种答案
第一次选举,通过比较myid.myid最大的获取选票,当选票过半数确定leader的节点。之后再加入的节点无论myid多大都会作为follower加入这个集群
非第一次选举,当原Leader故障,其它节点会选举新的Leader,先比较EPOCH(任期〉最大的直接胜出,如果EPOCH相同再比较事务ID,最大的胜出,如果事务1p也相同,最后比较服务器ID,大的胜出
5、zookeeper的工作机制
是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应。也就是说 Zookeeper = 文件系统 + 通知机制。
Zabbix监控
1. 什么是 Zabbix?它的主要作用是什么?
Zabbix 是一款开源的网络监控和告警系统,可用于监控各种服务器、网络设备、应用程序和数据库等资源的状态。其主要作用是帮助 IT 运维人员实时监控和识别问题,快速定位和解决故障,提高系统的可用性和性能。
2. Zabbix 的架构是什么?
Zabbix 的架构主要由以下几个部分组成:Zabbix Server、Zabbix Agent、Zabbix Proxy 和 Zabbix Web UI。Zabbix Server 负责监控和收集数据,Zabbix Agent 用于监控本地资源,Zabbix Proxy 用于分散监控压力,Zabbix Web UI 可以提供 Web 界面查询监控数据和设置监控配置。
3. Zabbix 如何实现监控和告警?
Zabbix 通过内置的数据收集器进行数据获取,或通过 Zabbix Agent 从被监控设备收集数据。数据收集器将获取到的数据汇集到 Zabbix Server 中,然后触发预定义的告警或自定义告警,并将告警信息发送给管理员。Zabbix 还支持自定义的阈值和监控策略,可根据不同的需求进行监控和提醒。
4. 如何使用 Zabbix 进行容器监控?
可以使用 Zabbix Agent 或 Zabbix Exporter 进行容器级别的监控。使用 Zabbix Agent 进行容器监控时,需要在容器内部运行 Agent,并使用 Hostmetadata 参数将容器 ID 传递到 Zabbix Server。而 Zabbix Exporter 是一个用于抓取谷歌 Prometheus 数据的插件,可以将 Prometheus 中的指标数据转发给 Zabbix Server 进行监控。
5. Zabbix 如何实现对 Web 应用的监控?
可以使用 Zabbix 的 HTTP 监控功能来监控 Web 应用。Zabbix 提供了一个内置的 Web 监控项,可以用来检查 Web 应用的 HTTP 响应代码、响应时间等,如果 Web 页面无法访问,或 HTTP 状态码为 404 等,Zabbix 将触发预定义的告警并发送给管理员。
6. Zabbix 如何进行分布式监控?
Zabbix 可以使用 Zabbix Proxy 进行分布式监控。Zabbix Proxy 是一种用于代理 Zabbix Server 的中间件,可以将 Zabbix Server 的监控任务分配给多个 Proxy 进行处理,从而减轻 Zabbix Server 的负担,并实现分布式监控。
7. Zabbix 的优势和缺点是什么?
Zabbix 的优势包括易于安装和配置、集成化和自动化特性等,可以支持多种监控方式,并提供强大的可视化和报告功能。但 Zabbix 也存在一些缺点,如配置复杂、侵入性高、资源消耗大等,需要适当的调整和管理才能更好地发挥其监控和告
8.为什么要使用监控?
①.对系统不间断实时监控
②.实时反馈系统当前状态
③.保证服务可靠性安全性
④.保证业务持续稳定运行
9.zabbix-proxy分布式使用什么场景?
Zabbix-proxy使用场景:
监控远程位置,解决跨机房
监控主机多,性能跟不上,延迟大
解决网络不稳定
10.zabbix收集数据的方式有哪些,并且说明模式的含义?
主动模式与被动模式
1、主动模式
zabbix客户端主动向zabbix server请求监控项列表,并主动将监控项内需要的数据提交给zabbix server
2、被动模式
zabbix server向agent请求获取监控项的数据,zabbix agent返回数据
注:zabbix的主动和被动模式是以zabbix客户端为基准的
11.zabbix监控有哪些?
硬件监控:通过 SNMP 来进行路由器交换机的监控。
系统监控:如 CPU 的负载,上下文切换、内存使用率、磁盘读写、磁盘使用率、磁盘 inode 节点。
服务监控:比如公司用 LNMP nginx 自带 Status 模块、 PHP 也有相关的 Status 、 MySQL 的话可以通过 ODBC协议 来进行监控。
网络监控:如果是云主机又不是跨机房,那么可以选择不监控网络。
安全监控:如果是云主机可以考虑使用自带的安全防护。当然也可以Zabbix监控 iptables 。如果是硬件,那么推荐以Zabbix监控硬件防火墙。
Web 监控:web 监控的话题其实还是很多。比如可以使用自带的 web 监控来监控页面相关的延迟、 js 响应时间、下载时间、等等。
日志监控:如果是 web 的话可以使用监控 Nginx 的 500x 日志。PHP 的 ERROR 日志。
流量分析:平时我们分析日志都是拿 awk sed xxx 一堆工具来实现。这样对我们统计 ip 、 pv 、 uv 不是很方便。那么可以使用百度统计、 google 统计、商业,让开发嵌入代码即可 (不想关建议去掉)。
可视化:通过 screen 以及引入一 些第三方的库来美化界面,同时我们也需要知道、订单量突然增加、 突然减少。或者说突然来了一大波流量,这流量从哪儿来,是不是推广了,还是被攻击了。可以结合监控平台来梳理各个系统之间的业务关系。
自动化监控:如上我们做了那么多的工作,当然不能是一台一台的来加 key 实现。可以通过Zabbix 的主动模式以及被动模式来实现。当然最好还是通过 API 来实现。
12.安装zabbix使用什么方式,服务端与客户端端口是多少?
安装zabbix两中方式
1、编译安装(单机架构)–> LAMP或LNMP
2、使用yum网络源安装(下载AMP的网络源)LAMP
服务端端口:10051
客户端端口:10050
13. zabbix如何监控脑裂?
监控只是监控发生脑裂的可能性,不能保证一定是发生了脑裂,因为正常的主备切换VIP也是会到备上的监控脚本:
[root@slave ~]# mkdir -p /scripts && cd /scripts
[root@slave scripts]# vim check_keepalived.sh
#!/bin/bash
if [ `ip a show ens33 |grep 192.168.32.250|wc -l` -ne 0 ]
then
echo "keepalived is error!"
else
echo "keepalived is OK !"
fi


14.zabbix有哪些组件
1)Zabbix Server:负责接收agent发送的报告信息的核心组件,所有配置、统计数据及操作数据均由其组织进行
2)Database Storage:专用于存储所有配置信息,以及有zabbix收集的数据
3)Web interface(frontend):zabbix的GUI接口,通常与server运行在同一台机器上4)Proxy:可选组件,常用于分布式监控环境中,代理Server收集部分被监控数据并统一发往Server端
5)Agent:部署在被监控主机上,负责收集本地数据并发往Server端或者Proxy端
15.zabbix的两种监控模式
Zabbix agent检测分为两种模式:主动模式和被动模式
主动模式:也是默认的Zabbix监控模式,被动模式是相对于proxy来说的。proxy主动发送数据就是主动模式,proxy等待server的请求再发送数据就是被动模式。
使用zabbix主动模式的好处:可以监控不可达的远程设备;监控本地网络不稳定区域;当监控项目数以万计的时候使用代理可以有效分担zabbix server的压力;简化zabbix分布式监控的维护。
被动模式:由server向agent发出指令获取数据, 即agent被动的去获取数据并返回给server,server周期性的向agent 索取数据, 这总模式的最大问题就是会加大server的工作量, 在数百台服务器的环境下server不能及时获取到最新数据, 但这也是默认的工作方式。
16. 一个监控系统的运行流程
zabbix agent 需要安装到被监控的主机上,它负责定期收集各项数据,并发送到 zabbix server 端,
zabbix server 将数据存储到数据库中,zabbix web 根据数据在前端进行展示和绘图。
17.zabbix的工作进程
默认情况下 zabbix 包含6个进程:zabbix_agentd、zabbix_get、zabbix_proxy、zabbix_sender、zabbix_server,另外一个zabbix_java_gateway是可选的,这个需要单独安装。
- zabbix_get
zabbix 工具,单独使用的命令,通常在 server 或者 proxy 端执行获取远程客户端信息的命令。通常用于排错。例如在 server 端获取不到客户端的内存数据,可以使用 zabbix_get 获取客户端的内容的方式来做故障排查。
- zabbix_sender
zabbix 工具,用于发送数据给 server 或者 proxy,通常用于耗时比较长的检查。很多检查非常耗时间,导致 zabbix 超时。于是在脚本执行完毕之后,使用 sender 主动提交数据。
- zabbix_server
zabbix 服务端守护进程。zabbix_agentd、zabbix_get、zabbix_sender、zabbix_proxy、zabbix_java_gateway的数据最终都是提交到server(说明:当然不是数据都是主动提交给zabbix_server,也有的是 server 主动去取数据,主要看是使用了什么模式进行工作)
- zabbix_proxy
zabbix 代理守护进程。功能类似server,唯一不同的是它只是一个中转站,它需要把收集到的数据提交/被提交到 server 里。
- zabbix_agentd
客户端守护进程,此进程收集客户端数据,例如cpu负载、内存、硬盘使用情况等。
18. zabbix常用术语
1.主机(host):要监控的网络设备,可由IP或DNS名称指定;
2.主机组(hostgroup):主机的逻辑容器,可以包含主机和模板,但同一个组织内的主机和模板不能互相链接;主机组通常在给用户或用户组指派监控权限时使用;
3.监控项(item):一个特定监控指标的相关的数据;这些数据来自于被监控对象;item是zabbix进行数据收集的核心,相对某个监控对象,每个item都由"key"标识;
4.触发器(trigger):一个表达式,用于评估某监控对象的特定item内接收到的数据是否在合理范围内,也就是阈值;接收的数据量大于阈值时,触发器状态将从"OK"转变为"Problem",当数据再次恢复到合理范围,又转变为"OK";
5.事件(event):触发一个值得关注的事情,比如触发器状态转变,新的agent或重新上线的agent的自动注册等;
6.动作(action):指对于特定事件事先定义的处理方法,如发送通知,何时执行操作;
7.报警升级(escalation):发送警报或者执行远程命令的自定义方案,如每隔5分钟发送一次警报,共发送5次等;
8.媒介(media):发送通知的手段或者通道,如Email、Jabber或者SMS等;
9.通知(notification):通过选定的媒介向用户发送的有关某事件的信息; 远程命令(remote command):预定义的命令,可在被监控主机处于某特定条件下时自动执行;
10.模板(template):用于快速定义被监控主机的预设条目集合,通常包含了item、trigger、graph、screen、application以及low-level
11.discovery rule:模板可以直接链接至某个主机; 应用(application):一组item的集合;
12.web场景(webscennario):用于检测web站点可用性的一个活多个HTTP请求; 前端(frontend):Zabbix的web接口;
19.zabbix自定义发现是怎么做的?
zabbix发现有3种类型:
-
自动网络发现
-
主动客户端自动注册
-
低级别的发现
实现方式: 规则+动作
-
首先需要在模板当中创建一个自动发现的规则,这个地方只需要一个名称和一个键值。
2.过滤器中间要添加你需要的用到的值宏。
3.然后要创建一个监控项原型,也是一个名称和一个键值。
4.然后需要去写一个这样的键值的收集。
自动发现实际上就是需要首先去获得需要监控的值,然后将这个值作为一个新的参数传递到另外一个收集数据的item里面去。
20.微信报警
首先要有企业微信,然后需要几个参数,从企业微信后台获取:Agetid,Secret,成员账号,组织部门ID,应用ID
使用Python或者shell脚本来实现微信报警
就是一个获取企业微信接口,和调用邮件接口来发送信息的过程。
21.zabbix客户端如何批量安装
可以使用ansible+shell脚本自动化部署 zabbix-agent软件包和管理配置文件。
22. zabbix分布式是如何做的
使用zabbix proxy
zabbix proxy 可以代替 zabbix server 收集性能和可用性数据,然后把数据汇报给 zabbix server,并且在一定程度上分担了zabbix server 的压力.此外,当所有agents和proxies报告给一个Zabbix server并且所有数据都集中收集时,使用proxy是实现集中式和分布式监控的最简单方法。
zabbix proxy 仅仅需要一条 tcp 连接到 zabbix server,所以防火墙上仅仅需要加上一条规则即可。
proxy 收集到数据之后,首先将数据缓存在本地,然后在一定得时间之后传递给 zabbix server,这样就不会因为服务器的任何临时通信问题而丢失数据。这个时间由 proxy配置文件中参数 ProxyLocalBuffer和 ProxyOfflineBuffer 决定。
23. zabbix proxy 的使用场景
1.远程监控设备
2.监控网络不稳定的区域
3.当zabbix监控大型架构的时候
4.为了分布式
24. zabbix你都监控哪些参数
说到监控,在运维这个行业其实有很多开源的监控方案,目前最常见的就是zabbix+grafana, 我工作那时候还是用cacti和nagios的比较多。
还记得以前去面试,面试官来了一句,zabbix会搭建吗,会的话你在这搭建下,30分钟搭建出来就入职。
不管是zabbix,还是其他的开源监控,说到底都是在做五件事:
-
数据的采集
-
采集过来的数据存储
-
把存储起来的数据进行分析
-
把分析的结果使用图标展示
-
把有问题的地方采用各种方式告警。
而我们要监控的也无非是5大块,服务器,中间件,数据库,网络设备,应用。
监控指标举例
1.监控web服务
-
web服务是否正常
-
业务(网页是否能访问、是否可以完成下订单、注册用户)
-
服务的响应时间
-
服务的并发量(活动用户、非活动用户)
2.监控数据库
-
监控磁盘使用情况
-
监控内存内存使用
-
查看并发连接数量
-
检查数据库执行增删改查的频率
-
检查主从状态
-
检查数据库的备份情况
3.服务器监控
磁盘
-
使用率
-
inode数
-
block数
-
读写速率
CPU
-
监控cpu负载
-
监控使用cpu资源最多的进程
内存
-
使用率
-
缓冲区
-
缓存区
-
交换分区大小
网络
-
监控每个网卡的上先行速率
-
监控占用网络带宽见多的进程
-
监控数据包的丢包
-
监控网络数据包的阻塞情况
进程
-
当前系统中的总进程数
-
监控特定的程序的进程数
企业监控架构图

如何回答问题
示例:
我们主要用的是zabbix作为监控,主要监控 数据库,web,网络,中间件和一些其他应用,比如我们监控mysql,主要关注磁盘,内存,并发数,数据库的增啥改查频率,主从状态等等。
数据库性能方面,主要关注:
-
查询吞吐量
-
查询执行性能
-
连接情况
-
缓冲池使用情况
补充扩展
zabbix常用的术语
主机(host): 要监控的网络设备,可由ip或DNS名称指定
主机组(host group): 主机的逻辑容器,可以包含主机和模板,但同一个组内的主机和模版不能互相链接,主机组通常在组用户或用户组指派监控权限时使用。
监控项(item): 一个特定监控指标的相关的数据,这些数据来自于被监控对象,item是zabbix进行数据收集的核心,没有item,就没有数据,每个item都由“key”进行标识。
触发器(trigger): 一个表达式,用于评估某监控对象的某特定item内所接收到的数据是否在合理范围内,即阈值;接收到的数据量大于阈值时,触发器状态将从“OK”转变为“Problem”,当数据量再次回到合理范围时,其状态将从“Problem”转换回“OK”。
事件(event): 即发生的一个值得关注的事件,如触发器的状态转变,新的agent或重新上线的agent的自动注册等。
动作(action): 指对于特定事件事先定义的处理方法,通过包含操作(如发送通知)和条件(何时执行操作)。
报警升级(escalation): 发送警报或执行远程命令的自定方案,如每隔多长时间发送一次警报,共发送多少次。
媒介(media): 发送通知的手段或通道,如Email,Jabber或SMS等。
通知(motification): 通过选定的媒介向用户发送的有关某事件的信息。
远程命令(remote command):预定义的命令,可在被监控主机处于某特定条件下时自动执行。
模版(template): 用于快速定义被监控主机的预设条目集合,通常包含了item,trigger,graph,screen,application,low-level discovery rule,模板可以直接链接到单个主机。
应用(application): 用于检测web站点可用性的一个或多个HTTP请求。
前端(frontend): zabbix的web接口。
单纯对于面试来说这个题目还是很好回答的,但真正操作起来会稍微麻烦点,因为节点数多,监控的项多,好在公司里都有现成的。
当然面试官问完这个问题会可能会问的问题有:
-
zabbix监控你都用过哪些模板
-
你都写过哪些模板
-
微信报警怎么做的
-
如何添加一台主机
这些问题也需要提前准备。
切记: 面试只分为两种,准备过和没有准备过。 我们不打无准备之仗。
后记:
1.硬件监控——路由器、交换机、防火墙
2.系统监控——cpu、内存、磁盘、网络、进程、tcp3.服务监控——nginx、php、tomcat、redis、memcache、mysql
4.web监控——响应时间、加载时间、渲染时间,页面是不是200
5.日志监控——ELK、(收集、存储、分析、展示)日志
6.安全监控——firewalld、WAF(nginx+lua)、安全宝、牛盾云、安全狗
25. 你们使用的zabbix版本是多少,是主动模式还是被动模式?
5.0,**被动模式:**被动模式就是由zabbix server向zabbix agent发出指令获取数据, 即zabbixagent被动的去获取数据并返回给zabbix server, zabbix server周期性的向agent 索取数据, 这总模式的最大问题就是会加大zabbix server的工作量, 在数百台服务器的环境下zabbix server不能及时获取到最新数据, 但这也是默认的工作方式。
主动模式是有zabbix agent主动采集数据并返回给zabbix server, 不再需要zabbix serve进行干预, 因此主动模式在一定程度上可减轻zabbix server的压力。
26.如果让你使用zabbix监控URL你会怎么做?
方法一:使用模板监控(不推荐)
先创建模板,创建web场景,创建触发器
方法二:直接使用web检测(推荐)
对监控的主机创建web监控,添加步骤,创建触发器
Prometheus (普罗米修斯监控警报系统)
1. 什么是 Prometheus? 它的主要作用是什么?
Prsometheus 是一款开源的监控和警报系统,用于记录和统计系统和服务的度量数据。它支持跨平台,支持多种语言和第三方应用程序适配器,提供强大的查询语言、图形化界面以及高效的警报机制,可以帮助 IT 运维人员快速诊断和解决问题。
2.Prometheus 的主要架构是什么?
Prometheus 的主要架构由以下几个组件组成:1)收集器(collector):负责收集指标和存储数据;2)存储层(storage layer):负责存储数据,并支持多维度查询;3)数据查询(query):提供灵活的查询语言,可对存储层中的数据进行查询和聚合;4)警报(alerting):根据事先定义的规则,主动发送警报信息给监控管理员。
3.Prometheus 的数据模型是什么?
Prometheus 的数据模型主要包括以下三个要素: metric、label 和 timestamp。Metric 是监控指标的名称,Label 是对 Metric 进行细分划分的附加信息,通过 Label 可以对 Metric 进行区分。Timestamp 是指标值的时间戳,用于标记指标值的时间范围。
4.如何通过 Prometheus 监控系统和服务?
Prometheus 通过提供一系列的 Exporter 工具来监控目标系统和服务。Exporter 可以将系统和服务的指标数据暴露给 Prometheus,Prometheus 然后将这些指标数据存储下来,并提供查询和分析功能。Prometheus 还可以通过 PushGateway 收集一些短周期任务的指标数据。
5.如何使用 Prometheus 实现告警功能?
Prometheus 可以通过 AlertManager 实现告警功能。AlertManager 负责接收来自 Prometheus Server 的告警,并对告警进行整理、去重、分组等操作,最后发送到指定的目标,如邮件、Slack、PagerDuty 等。
6.如何使用 Prometheus 和 Grafana 进行数据可视化 ?
Prometheus 可以通过提供 Grafana 数据源的方式和 Grafana 集成实现数据可视化。在 Grafana 上配置 Prometheus 数据源,连接到 Prometheus 服务器,然后定义 Dashboard 来可视化 Prometheus 中收集到的指标数据,如 CPU 使用情况、内存使用情况等。
7.如何保证 Prometheus 的高可用性?
Prometheus 可以通过以下几种方式来提高其高可用性:
1)使用多实例部署,将存储层和查询层分开部署;
2)使用分布式存储方案,如 Thanos 和 VictoriaMetrics 等;
3)将本地存储转为远程存储,如使用 S3、Hadoop 等云存储方案。
8. prometheus工作原理

-
prometheus server定期从配置好的jobs或者exporters中拉取metrics,或者接收来自Pushgateway发送过来的metrics,或者从其它的Prometheus server中拉metrics。
-
Prometheus server在本地存储收集到的metrics,并运行定义好的alerts.rules,记录新的时间序列或者向Alert manager推送警报。
-
Alertmanager根据配置文件,对接收到的警报进行处理,发出告警。
-
在图形界面中,可视化采集数据。
9. prometheus组件
1.Prometheus Server:
Prometheus Sever是Prometheus组件中的核心部分,负责实现对监控数据的获取,存储及查询。
Prometheus Server可以通过静态配置管理监控目标,也可以配合使用Service Discovery的方式动态管理监控目标,并从这些监控目标中获取数据。其次Prometheus Sever需要对采集到的数据进行存储,
Prometheus Server本身就是一个实时数据库,将采集到的监控数据按照时间序列的方式存储在本地磁盘当中。Prometheus Server对外提供了自定义的PromQL,实现对数据的查询以及分析。另外
Prometheus Server的联邦集群能力可以使其从其他的Prometheus Server实例中获取数据。
2.Exporters:
Exporter将监控数据采集的端点通过HTTP服务的形式暴露给Prometheus Server,Prometheus Server
通过访问该Exporter提供的Endpoint端点,即可以获取到需要采集的监控数据。可以将Exporter分为2类:
直接采集:这一类Exporter直接内置了对Prometheus监控的支持,比如cAdvisor,Kubernetes,Etcd,Gokit等,都直接内置了用于向Prometheus暴露监控数据的端点。
间接采集:原有监控目标并不直接支持Prometheus,因此需要通过Prometheus提供的Client Library编写该监控目标的监控采集程序。例如:Mysql Exporter,JMX Exporter,Consul Exporter等。
3 AlertManager:
在Prometheus Server中支持基于Prom QL创建告警规则,如果满足Prom QL定义的规则,则会产生一条告警。在AlertManager从 Prometheus server 端接收到 alerts后,会进行去除重复数据,分组,并
路由到对收的接受方式,发出报警。常见的接收方式有:电子邮件,pagerduty,webhook 等。
4 PushGateway:
Prometheus数据采集基于Prometheus Server从Exporter pull数据,因此当网络环境不允许Prometheus Server和Exporter进行通信时,可以使用PushGateway来进行中转。通过PushGateway将内部网络的监控数据主动Push到Gateway中,Prometheus Server采用针对Exporter同样的方式,将监控数据从PushGateway pull到Prometheus Server。
Docker容器
1. 什么是 Docker?它的主要作用是什么?
Docker 是一款开源的容器编排工具,可以将应用程序及其依赖项打包到一个容器中,实现轻量化、快速部署和跨平台运行的特点。Docker 的主要作用是简化应用程序的开发、部署和管理,并提高应用程序的可移植性和可重复性。
2. Docker 中的容器和镜像有什么区别?
Docker 的镜像是一个只读的模板,包括了应用程序及其依赖项和配置等,用于构建 Docker 容器。而容器是一个运行时的实体,包括了应用程序镜像和运行时系统资源等,用于执行应用任务和处理资源。
3. Docker 的主要组件有哪些?
Docker 的主要组件包括 Docker Engine、Docker Hub、Docker Compose、Docker Swarm 等。Docker Engine 是负责构建和运行 Docker 容器的核心组件;Docker Hub 是 Docker 中心仓库,可用于存储和分享 Docker 镜像;Docker Compose 可以通过定义一个 YAML 文件来定义和运行多个 Docker 容器;Docker Swarm 是 Docker 的集群管理工具。
4. 如何使用 Docker 构建和发布镜像?
可以通过编写 Dockerfile 文件来定义 Docker 镜像的构建方式和配置信息,然后使用 Docker 命令构建 Docker 镜像,如“docker build –t myimage:v1 .”,最后将 Docker 镜像发布到 Docker Hub 等仓库中。
5. Docker 的网络模型是怎样的?
Docker 的网络模型包括四种网络模式,分别是:bridge、host、none 和 container,分别用于不同的运行场景和需求。其中,bridge 是 Docker 的默认网络模式,通过 Docker 网桥来为容器提供网络连接,可以通过“docker network create”命令创建用户自定义的网桥。
6. 如何使用 Docker 容器进行应用程序部署?
可以将应用程序及其依赖项打包成 Docker 镜像并发布到 Docker Hub 仓库中,然后使用 Docker 命令创建 Docker 容器并运行对应的镜像即可。Docker 还提供了多种管理和调度工具,如 Docker Compose、Docker Swarm、Kubernetes 等。
7. Docker 的优点和缺点是什么?
Docker 的优点主要包括:快速构建和部署、轻量和便携、可移植性和可重复性、跨平台支持等。Docker 的缺点主要包括:容器对存储和 I/O 性能的影响、Docker 环境的网络配置和管理、Docker 安全性问题等。
8.dockerfile的编写流程
首先先写FROM
指定基础镜像
然后安装这个jar包所需要的依赖环境
然后RUN 进行指定解压的jar包
中间需要配置环境变量
然后workdir进入对应的工作目录
需要的话再进行配置编译
然后可以执行volume 进行挂载
然后使用cmd或者entrypoint 配置容器启动时的启动命令或者shell
当然 dockerfile 文件需要放在指定的目录中,并且把jar包同样放在这个目录中
然后使用docker build -t 打tag 然后指定“点”指定上下文环境
9.dockerfile内的操作指令CMD和ENTRYPOINT区别以及同时存在哪个生效
1、相同点:
都是容器启动时加载的命令,启动涉及到两种模式:
exec模式和shell模式:
exec:容器加载时使用的启动的第一个任务进程;直接nginx
shell:容器加载时使用的第一个bash环境;/bin/sh -c nginx
2、不同点:
CMD:容器环境启动时默认加载的脚本或命令
ENTRYPOINT:是容器环境启动时第一个启动的程序或者命令;默认跑一个init进程
如果ENTRYPOINT使用了shell 模式,CMD指令会被忽略。
如果ENTRYPOINT使用了exec模式,CMD指定的内容被追加为ENTRYPOINT指定命令的参数。
如果ENTRYPOINT使用了exec 模式,CMD 也应该使用exec 模式。
10.docker-compose常用命令有哪些?(不少于8个)
字段 描述
build 重新构建服务
ps 列出容器
up 创建和启动容器
exec 在容器里面执行命令
scale 指定一个服务容器启动数量
top 显示容器进程
logs 查看容器输出
down 删除容器、网络、数据卷和镜像
stop/start/restart 停止/启动/重启服务
11.Harbor的核心组件有哪些,并且说出含义?
①Proxy
通过一个前置的反向代理统一接收浏览器、Docker 客户端的请
求,并将请求转发给后端不同的服务
这是一个反向代理组件
②Registry
负责储存 Docker 镜像
处理 docker push/pull 命令来上传和下载
③Core services
Harbor 的核心功能,包括UI、webhook、 token 服务
webhook:网站的一些服务功能
token:令牌,提供身份验证服务
④Database
为 core services 提供数据库服务
数据库记录镜像的元信息及用户的身份信息
⑤Log collector
负责收集其他组件的日志,以供然后进行分析
健康检查等
12.docker Harbor私有仓库的过程?
1.所有的请求或认为的操作都会首先交给proxy(反向代理)
2.proxy会先将请求转发给后端Core services,Core services 中包含 3.UI、token(身份验证服务)、webhook(网站的一些服务功能)
4.转发给registry(镜像存储),若需要下载镜像等权限操作,需要通过Core services中的token令牌的身份验证服务才行
5.每一次下载和上传都产生操作记录,生成日志,保存至database中
6.database记录保存镜像的元信息及用户与组的身份信息,通过验证授权才能允许相关操作
13.docker 三大组件
镜像:模板;组资源集合,包含了应用程序软件包、应用程序相关的依赖包、运行应用程序所需要的基础环境(泛指操作系统环境),可以理解为容器的模板
容器:基于镜像的一种运行时状态
仓库:存放image镜像模板,仓库大类: 1、公共仓库一》docker hub 2、私有仓库registry harbor
14.docker有哪些优势
docker 把容器化技术做成了标准化平台CAAS (docker统一/指定了容器化技术的标准化平台)
使用docker有什么意义:(实现了3个统一)
docker引擎统一了基础设施环境:docker环境------》image------>封装一个简易的操作系统(3.0+G)
docker引擎统一了程序打包(装箱/封装-类比于集装箱)方式:docker镜像一》 images
docker 引擎统一了程序部署(运行)方式:docker容器一 》基于镜像——》运行为容器(可运行的环境)
实现了一次构建、多次、多处使用
15.docker的十条管理命令(运维常用的命令)
docker image ###查看镜像
docker pa -aq ##查看容器
docker -v/version ###查询docker版本
docker info ##用于显示 docker 的系统级信息,比如内核,镜像数,容器数等
docker save -o ##镜像导出
docker load < hello-world ##镜像导入
docker export 容器ID >文件名 ##容器导出
docker import 导出的文件名(容器) 指定镜像名称(打上标签) ##容器导入
docker rm -f docker ps -aq ##强制批量删除容器
docker search nginx ##搜索镜像名中包含nginx的镜像
16.docker内两个容器如何通讯
docker中的回答方式:
以docker的三种网络模式角度/切入点回答
host:基于local
container:基于其他提供IP的container
bridge:基于dicker 0 网桥
17.集群里面有一个docker,他的使用率达到80%你怎么做?
把这个docker干掉,然后他的资源可能会释放,然后重新再建一个,因为集对于集群来说它会有高可用的设置,所以干掉一个影响并不大
18.假设一个集群docker有20个,然后有15个利用率已经达到了80%,服务都是可跑的,不能杀的,这个时候你怎么办?(附加题)
这个时候就要进行向上级汇报,然后对服务进行扩容
19.docker 知识点总结
docker是什么?
容器技术之一,是虚拟化技术迭代后的产物–》容器和虚拟化有何区别(容器和KVM有何区别)
核心点:KVM是完整的操作系统,但是容器共享内核的进程来支持
容器优势—》对于市场的流行的技术来说 微服务
容器:对应用程序和系统进行了解耦、发布方便、更新方便、移植方便、冗余备份方便(LB副本集)
docker的 三个统一方式
统一应用的封装 image
统一应用环境 docekr engine
统一应用的运行的方式 container容器 runc(容器运行时环境)
docker 三要素
镜像:包含了各种环境或者服务(tomcat)的一个模板
容器:是镜像(run)起来之后的一个实例,可以把容器看做一个简易版的linux环境容器就是集装箱(大鲸鱼logo上的集装箱)
仓库:是存放镜像的场所,私有仓库 共有仓库 Docker hub (https://hub.docker.com)
同时 docker是一种 C/S端架构,server端位于系统,表现形势为dameon(守护进程)
docker的底层原理
① cgroup(资源限制)
② namespace(资源隔离) 6个命名空间(隔离)
docker 常规命令 (至少记忆 10个)
基于images
基于container的命令
docker images
ps
run
start/stop/restart
create
tag
rm/rmi
build
push
login/logout
commit
-it/-d/-v/-p(-P)/-c
exec
version/info
pull/search
logs
cp
save/load < 重定向输入(导入)
export/import
network
top
stats
docker-compose up/down/scale/exec/build/ -d
docker 网络
1、node
2、host * *
3、bridge * *
4、container (k8s * *)
5、overlay 是叠加网络 * * * 指的就是在物理网络层上搭建一层网络,通过某种技术再去构建一张相同的网络 这张称为逻辑网
docker 散装的功能
1)挂载: ① 数据卷 ② 数据卷容器
2)暴露: ① -p 指定 ② -P “默认分配” 49153为起始
3)自定义网络 (指定容器IP)
dockerfile
1)docker image 的流程
docker image 的制作–》过程:docker image镜像分层(① 内核-共享,② base image基础镜像层③ image 镜像层—》container容器工作层----》缓存复用)
基于镜像层介绍2个点:
① 叠加能力:现在借助于overlay2 (存储引擎)
② 分层分类(4层):lower(下层) upper(上层) worker(容器层) merged(视图/展示层)
dockerfile 内的 常规指令
FROM 基础镜像(buid)
MAINTAINER 维护人的信息
RUN 表示执行 ,并且RUN指令会产生一层新的镜像层
ENV 环境变量传入
ADD/COPY * *
EXPOSE
VOLUME
WORKDIR
USER
HEATHCHECK
CMD * *
ENTRYPOINT * *
附加题: dockerfile中有哪些指令 或者 公司中你们的镜像是怎么制作(比如微服务xxxxxxxx.jar)
docker 底层原理
cgroup控制容器资源 (CPU 内存 上限)
docker镜像仓库
registry 私有仓库的核心, 只有字符终端
进阶版 harbor
Harbor的核心组件
①Proxy
通过一个前置的反向代理统一接收浏览器、Docker 客户端的请
求,并将请求转发给后端不同的服务
这是一个反向代理组件
②Registry
负责储存 Docker 镜像
处理 docker push/pull 命令来上传和下载
③Core services
Harbor 的核心功能,包括UI、webhook、 token 服务
webhook:网站的一些服务功能
token:令牌,提供身份验证服务
④Database
为 core services 提供数据库服务
数据库记录镜像的元信息及用户的身份信息
⑤Log collector
负责收集其他组件的日志,以供然后进行分析
健康检查等
docker Harbor私有仓库的过程
1.所有的请求或认为的操作都会首先交给proxy(反向代理)
2.proxy会先将请求转发给后端Core services,Core services 中包含 3.UI、token(身份验证服务)、webhook(网站的一些服务功能)
4.转发给registry(镜像存储),若需要下载镜像等权限操作,需要通过Core services中的token令牌的身份验证服务才行
5.每一次下载和上传都产生操作记录,生成日志,保存至database中
6.database记录保存镜像的元信息及用户与组的身份信息,通过验证授权才能允许相关操作
私有仓库指向私有仓库的方式 有两种
1、/etc/docker/daemon.json
2、/usr/lib/systemd/system/docker.servce
insecure-registrues $HARBOR_IP (私有仓库的IP地址)
docker-compose
1)yml文件内部的控制参数
① name
② 自定义挂载卷
③ 自定义env环境变量 运行前》自定义网络
④ 自定义端口
⑤ 自定义传参(运行后)
⑥ 可以同时对多个容器个性化定义/编排
2)docker-compose命令
字段 描述
build 重新构建服务
ps 列出容器
up 创建和启动容器
exec 在容器里面执行命令
scale 指定一个服务器启动数量
top 显示容器进程
logs 查看容器输出(日志)
down 删除容器、网络、数据卷和镜像
stop/start/restart 停止/启动/重启服务
consul 注册中心
动态 发现和更新应用(配置中心 temlate)
consul agent 的server模式
consul agent dev 模式开发者模式 (能使用所有功能)
可以用在 consul集群
K8S容器编排
1. 什么是 Kubernetes? 它的主要作用是什么?
Kubernetes 是一款开源的容器编排系统,可以实现容器的自动部署、自动扩缩容、自动容错和自动管理等功能,是一种云原生应用的支撑平台。Kubernetes 的主要作用是简化应用程序在分布式系统上的部署和扩展,使得开发人员和运维人员能够更加专注于应用程序本身,提高应用程序的部署质量和部署效率。
2. Kubernetes 的架构包括哪些组件?
Kubernetes 的体系结构主要由以下几个组件组成:1)控制面板组件:如 API 服务器、etcd 等;2)工作节点组件:如 kubelet、kube-proxy 等;3)服务发现和负载均衡组件:如 CoreDNS、kube-proxy 等;4)扩展和自定义组件:如 Operator、Custom Resource Definition 等。
3. Kubernetes 中的 Pod 是什么?
Pod 是 Kubernetes 的最小部署单元,可以包含一个或多个应用容器(Containers),共享同一个 IP 地址、网络命名空间和存储卷,被用来完成一系列工作任务,例如微服务、批处理任务等。
4. Kubernetes 中的 Service 是什么?
Service 是 Kubernetes 中的一种抽象机制,用于为一组相同的 Pod 提供一个共享的 VIP(Virtual IP)和 DNS 名称,并通过 Selector 来实现将客户端的请求流量路由到相应的 Pod 上。Service 在实现服务发现和负载均衡的过程中发挥了重要作用。
5. Kubernetes 中的 Volume 是什么?
Volume 是用来持久化存储数据的 Kubernetes 对象,它定义了容器和宿主机共享的文件、目录等资源,可以在 Pod 启动时自动挂载到容器中,也可以在容器内使用命令行手动挂载和卸载。Volume 的类型包括 hostPath、NFS、iSCSI、Secret、ConfigMap 等。
6. 如何使用 Kubernetes 进行应用程序部署?
可以通过编写 Kubernetes 配置文件(如 YAML 文件)来定义应用程序的部署、服务、存储等配置,然后使用 Kubernetes 的命令行工具来创建和管理这些资源对象。
7. Kubernetes 的优缺点是什么?
Kubernetes 的优点包括:可伸缩性、高可用性、灵活性、操作简单、跨云平台等。Kubernetes 的缺点主要包括学习成本高、部署和管理复杂、资源占用较大等。
8.k8s整体访问流程
用户执行kubectl/userClient向apiserver发起一个命令,经过认证授权后,经过scheduler的各种策略,得到一个目标node,然后告诉apiserver,apiserver 会请求相关node的kubelet,通过kubelet把pod运行起来,apiserver还会将pod的信息保存在etcd;pod运行起来后,controllermanager就会负责管理pod的状态,如,若pod挂了,controllermanager就会重新创建一个一样的pod,或者像扩缩容等;pod有一个独立的ip地址,但pod的IP是易变的,如异常重启,或服务升级的时候,IP都会变,这就有了service;完成service工作的具体模块是kube-proxy;在每个node上都会有一个kube-proxy,在任何一个节点上访问一个service的虚拟ip,都可以访问到pod;service的IP可以在集群内部访问到,在集群外呢?service可以把服务端口暴露在当前的node上,外面的请求直接访问到node上的端口就可以访问到service了
9.kube-proxy的三种模式:
userspace代理模式
iptables代理模式(默认)
IPVS代理模式
10.ipvs和iptables的异同
iptables与IPVS都是基于Netfilter实现的,但因为定位不同,二者有着本质的差别:iptables是为防火墙而设计的;IPVS则专门用于高性能负载均衡,并使用更高效的数据结构(Hash表),允许几乎无限的规模扩张。
与iptables相比,IPVS拥有以下明显优势:
为大型集群提供了更好的可扩展性和性能;
支持比iptables更复杂的复制均衡算法(最小负载、最少连接、加权等);
支持服务器健康检查和连接重试等功能;
可以动态修改ipset的集合,即使iptables的规则正在使用这个集合。
11.无状态和有状态分别是什么
无状态服务:就是没有特殊状态的服务,各个请求对于服务器来说统一无差别处理,请求自身携带了所有服务端所需要的所有参数(服务端自身不存储跟请求相关的任何数据,不包括数据库存储信息
有状态服务:与之相反,有状态服务在服务端保留之前请求的信息,用以处理当前请求,比如session等
12. K8S监控指标
一般在公司里我们都是使用prometheus进行监控,先说一下prometheus的工作核心:
prometheus是使用 Pull (抓取)的方式去搜集被监控对象的 Metrics 数据(监控指标数据),然后,再把这些数据保存在一个 TSDB (时间序列数据库,比如 OpenTSDB、InfluxDB 等)当中,以便后续可以按照时间进行检索。
有了这套核心监控机制, Prometheus 剩下的组件就是用来配合这套机制的运行。比如Pushgateway,可以允许被监控对象以 Push 的方式向 Prometheus 推送 Metrics 数据。
而 Alertmanager,则可以根据 Metrics 信息灵活地设置报警。当然, Prometheus 最受用户欢迎的功能,还是通过 Grafana 对外暴露出的、可以灵活配置的监控数据可视化界面。
kubernetes的监控体系:
宿主机的监控数据: 比如节点的负载,CPU,内存,磁盘,网络这些常规的信息,当然你也可以查看https://github.com/prometheus/node_exporter#enabled-by-default来看看这些指标,实在是太多了。
对apiserver,kubelet等组件的监控,比如工作队列的长度,请求的QPS和数据延迟等,主要是检查k8s本身的工作情况
k8s相关的监控数据,比如对pod,node,容器,service等主要k8s概念进行监控。
在监控指标的规划上需要遵从USE原则和RED原则
USE:
-
利用率
-
饱和度
-
错误率
RED原则:
-
每秒请求数
-
每秒错误数
-
服务响应时间
这里需要注意: promotheus采用的是pull的模式。
13. k8s是怎么做日志监控的
一般有三种方式:
1.将fluentd项目安装在宿主机上,然后把日志转发到远端的elsticSearch里保存起来以备检索。
这样做的优点是: 在一个节点上只需要部署一个agent,并且不会对应用和pod有任何入侵性,这种用的比较多一些。
缺点: 它要求应用输出日志,都必须直接输出到容器的stdout和stderr里
2.第二种方案:当容器日志只能输出某些文件的时候,我们可以通过一个sidecar容器把这些日志文
件,重新输出到sidecar的stdout和stderr上,然后在使用第一种方案。其实第二种方案就是对第一种方案缺点的补充
3.第三种方案,通过一个sidecar的容器,直接把应用的日志发送到远程存储里面。
这种其实也是第一种的延伸,就是把fluentd部署到pod中,后端存储还是可以用elasticsearch,知识fluentd输入源变成了应用文件日志。
但是这种方法sidecar容器会消耗过多资源。
日过日志量特比大,我们可以增加配额: 给容器上挂存储,讲日志输出到存储上。
你在回答这个问题的时候,可以说第一种方式,只要你们的日志量不大即可,如果大的话,需要加存储。
14.k8s中service和ingress的区别
serivce是如何被设计的:
在pod中运行的容器在动态,弹性的变化(比如容器的重启IP地址会变化),为了给pod提供一个固定的,统一访问的接口,以及负载均衡的能力,并借助DNS系统实现服务发现功能,解决客户端发现容器难的问题,于是变设计了service
service 和pod对象的IP地址,在集群内部可达,但集群外部用户无法接入服务,解决的思路有:
-
node pod端口上做端口暴露
-
在工作节点上用公用网络名称空间(hostname)
-
使用service的nodeport或者loadbalancer
-
ingress七层负载和反向代理资源。
service 提供pod的负载均衡的能力,但只在4层有负载,而没有功能,只能到IP层面。
service的几种类型:
clusetr IP: 默认类型,自动分配一个仅可以在内部访问的虚拟IP,仅供内部访问
nodeport: 在clusterip的基础上,为集群内的每台物理机绑定一个端口,外网通过任意节点的物理机IP来访问服务,应用方式: 外服访问服务
loadbalance: 在nodeport的基础上,提供外部负载均衡与外网统一IP,此IP可以将讲求转发到对应的服务上。 应用方式: 外服访问服务
externalname : 引用集群外的服务,可以在集群内部通过别名的方式访问。
ingress:
service 只能提供四层的负载,虽然可以通过nodeport的方式来服务,但随着服务的增多,会在物理机上开辟太多的端口,不便于管理,所以ingress换了思路来暴露服务
创建一个具有n个副本的nginx服务,在nginx服务内配置各个服务的域名与集群内部的服务的ip,这些nginx服务在通过nodeport的方式来暴露,外部服务可以通过域名:nginx nodeport端口来访问nginx,nignx在通过域名反向代理到真实的服务器。
ingress分为ingress controller和ingress 配置。
ingress controller就是反向代理服务器,对外通过nodeport 来暴露端口。

总结:
service: 主要用来解决pod动态变化时候的IP变化,一旦podip变化,客户端就无法找到,service就是来解决这个问题的。 一个service就可以看做一组提供相同服务的pod的对外接口。
service服务于哪些pod是通过标签选择器来定义的。
而且service只能通过四层负载就是ip+端口的形式来暴露
ingress可以提供7层的负责对外暴露接口,而且可以调度不同的业务域,不同的url访问路径的业务流量。
15.k8s组件的梳理
Master组件
Master 组件对集群进行全局决策(例如,调度),并检测和响应集群事件(例如,当不满足部署的replicas 字段时,启动新的 pod)。
1、kube-apiserver
master节点上提供k8sapi服务的组件,
2、etcd
保存了k8s集群的一些数据,比如pod的副本数,pod的期望状态与现在的状态
3、scheduler
master节点上的调度器,负责选择节点让pod在节点上运行
kube-scheduler 给一个 pod 做调度选择包含两个步骤:
1、过滤
2、打分
过滤阶段会将所有满足 Pod 调度需求的 Node 选出来。例如,PodFitsResources 过滤函数会检查候选Node 的可用资源能否满足 Pod 的资源请求。在过滤之后,得出一个 Node 列表,里面包含了所有可调度节点;通常情况下,这个 Node 列表包含不止一个 Node。如果这个列表是空的,代表这个 Pod 不可调度。在打分阶段,调度器会为 Pod 从所有可调度节点中选取一个最合适的 Node。根据当前启用的打分规则,调度器会给每一个可调度节点进行打分。
最后,kube-scheduler 会将 Pod 调度到得分最高的 Node 上。如果存在多个得分最高的 Node,kube-scheduler 会从中随机选取一个。
4、controller
master节点的控制器,负责在节点出现故障时进行通知和响应,负责对节点的pod状态进行监控
Node组件
1、kubelet
一个在集群中每个节点上运行的代理。它保证容器都运行在 Pod 中。
他负责管理在该节点上的属于k8s集群的容器
2、kube-proxy
一个代理,可以通过代理创建一个虚拟ip,通过这个ip来与pod进行交流
3、Container Runtime
容器运行环境是负责在节点上运行容器的软件
附加组件
1、DNS
负责对k8s集群进行域名解析
2、Dashboard
Dashboard是k8s集群的一个web界面,
3、集群层面日志
集群层面日志机制负责将容器的日志数据保存到一个集中的日志存储中,该存储能够提供搜索和浏览接口。
4、容器资源监控
容器资源监控将关于容器的一些常见的时间序列度量值保存到一个集中的数据库中,并提供用于浏览这些数据的界面。
k8s流程 仅供参考:
1、准备好对应的yaml文件,通过kubectl发送到Api Server中
2、Api Server接收到客户端的请求将请求内容保存到etcd中
3、Scheduler会监测etcd,发现没有分配节点的pod对象通过过滤和打分筛选出最适合的节点运行pod
4、节点会通过conteiner runntime 运行对应pod的容器以及创建对应的副本数
5、节点上的kubelet会对自己节点上的容器进行管理
6、controler会监测集群中的每个节点,发现期望状态和实际状态不符合的话,就会通知对应的节点
7、节点收到通知,会通过container runtime来对pod内的容器进行收缩或者扩张
常见问题:
K8S是如何对容器编排?
在K8S集群中,容器并非最小的单位,K8S集群中最小的调度单位是Pod,容器则被封装在Pod之中。由此可知,一个容器或多个容器可以同属于在一个Pod之中。
Pod是怎么创建出来的?
Pod是由Pod控制器进行管理控制,其代表性的Pod控制器有Deployment、StatefulSet等。
(1)客户端提交创建请求,可以通过API Server的Restful API,也可以使用kubectl命令行工具。支持的数据类型包括JSON和YAML。
(2)API Server处理用户请求,存储Pod数据到etcd。
(3)调度器通过API Server查看未绑定的Pod。尝试为Pod分配主机。
(4)过滤主机 (调度预选):调度器用一组规则过滤掉不符合要求的主机。比如Pod指定了所需要的资源量,那么可用资源比Pod需要的资源量少的主机会被过滤掉。
(5)主机打分(调度优选):对第一步筛选出的符合要求的主机进行打分,在主机打分阶段,调度器会考虑一些整体优化策略,比如把容一个Replication Controller的副本分布到不同的主机上,使用最低负载的主机等。
(6)选择主机:选择打分最高的主机,进行binding操作,结果存储到etcd中。
(7)kubelet根据调度结果执行Pod创建操作: 绑定成功后,scheduler会调用APIServer的API在etcd中创建一个boundpod对象,描述在一个工作节点上绑定运行的所有pod信息。运行在每个工作节点上的kubelet也会定期与etcd同步boundpod信息,一旦发现应该在该工作节点上运行的boundpod对象没有更新,则调用Docker API创建并启动pod内的容器。
Pod资源组成的应用如何提供外部访问的?
Pod组成的应用是通过Service这类抽象资源提供内部和外部访问的,但是service的外部访问需要端口的映射,带来的是端口映射的麻烦和操作的繁琐。为此还有一种提供外部访问的资源叫做Ingress。
Service又是怎么关联到Pod呢?
在上面说的Pod是由Pod控制器进行管理控制,对Pod资源对象的期望状态进行自动管理。而在Pod控制器是通过一个YAML的文件进行定义Pod资源对象的。在该文件中,还会对Pod资源对象进行打标签,用于Pod的辨识,而Servcie就是通过标签选择器,关联至同一标签类型的Pod资源对象。这样就实现了从service–>pod–>container的一个过程。
可以这么理解: pod是一个虚拟机,容器就是一个应用程序,k8s相当于操作系统,镜像相当于.exe安装包。
运维技术经验文档
1.aws云主机之前的网络互访可以通过几种方式进行限制?
安全组
acl访问控制
2.如何在linux下模拟一个tcp端口开放?
nc -l -p 端口
3.k8s中如何查看命名空间test中pod的IP?
kubectl get pods -n test -o wide
4.k8s中pod无法启动怎么排查原因?
kubectl describe pod
kubectl logs
5.客户使用SSH无法连接服务器,怎么排查?
思路:检查客户端软件配置与网络配置
检查中间网络
安全配置检查
SSH 服务与监听状态检查
SSH 登录错误进一步分析
两个机器之间是否通畅,看物理网络(网线网卡,IP是不是正确)
ping
端口没开netstat -Intup|grep 22放,服务器没有监听你连接的端口。
6.Tomcat有哪些优化?
采用动静分离
调优Tomcat线程池
调优Tomcat的连接器Connector
通过修改Tomcat的运行模式
禁用AJP连接器
内存调优
垃圾回收策略调优
7.Mysql查询十分的慢,怎么排查原因?
硬件资源不足
系统层面未进行基本的优化,或不同进程间资源抢占
MySQL配置不科学
SQL语句写的太差,索引没有优化
9.LVS负载均衡和Nginx负载均衡有什么区别?
lvs负载能力强,工作逻辑简单,仅仅是请求分发,而且工作在第四层,没有流量,所以效率特别高。
nginx工作在网路的七层,可以对HTTP应用实施分流策略,比如域名,结构等。
nginx处理流量受服务器的IO等配置影响,负载能力相对LVS来说较弱。
10.为什么不用Nginx做负载均衡?
这些工具从应用程序,服务器和基础架构收集指标,它们允许检索指标,绘制图表并发送警报。
将负载平衡器集成到我们的监控系统中至关重要。
nginx只提供7种不同的指标。
Nginx仅在所有站点上给出总和。 单个站点或应用程序则没有任何数字对应。
11.怎么优化dockerfile镜像启动的的速度?
使用轻量化基础镜像
多阶段构建
12.为什么dockerfile只有200多M,centos系统有几个G?
docker是层层叠加的,可以多阶段构建镜像
13.CI/CD
这个问题在面试中也经常被问到,主要考察几个方面:
-
你对新技术的了解?
-
你们公司是如何落地的,来我们公司是否可以借鉴?
三个概念:
持续集成CI: 代码合并,构建,部署,测试都在一起,不断的执行这个过程,并对结果进行反馈。
通过这个过程,在未上线前去反复测试,减少上线后出现bug的几率
持续部署CD: 部署到测试环境,预生产环境,生产环境。
持续交付:CD: 把最终的产品发布到生产环境中,让用户去使用,在使用的过程中反馈结果。
这个过程涉及到运维,开发,测试。
CI/CD的最终目的是为了减少人工干预,实现自动化,提高产品交付的效率和质量。
CI/CD是一种解决方案,而实现这个方案又有很多种方法。
非容器化解决方案:
从开发上传代码到版本库中,jenkins拉取代码使用maven进行编译,然后部署上线。
这个过程很容易出问题,比如开发环境没问题,但是预生产环境出现问题,大家相互扯皮。
容器化解决方案

开发上传到代码到版本库,jenkins拉取进行编译,然后打包传到镜像仓库(harbor).在harbor中进行测试。
如果不使用容器,脚本和配置文件会越来越多,越来越乱。
而使用了容器后,这个问题就容易解决了,在容器中,我们只需要交付镜像就可以了。
docker从镜像仓库中进行拉取,然后在进行部署。
补充:
传统网站部署流程:

使用jenkins后的部署流程:

有了k8s之后:
开发写完代码上传到git版本仓库,jenkins拉取代码在maven进行编译,构建镜像,把镜像推送到镜像仓库,然后就可以在k8s中部署。 部署完成中,调用k8s的API进行健康检查(healthcheck)
使用k8s去做有什么好处?
-
环境稳定
-
服务不间断
-
一次构建多环境去运行
K8S node管理
k8s中有三个组件与node交互,分别是node controller,kubelet,kubectl
在node的整个生命周期中,node controller充当多个角色,
第一个:在node注册入集群的时候,给他分配一个CIDR地址快。
第二个是维护node controller 内部节点可用列表,如果node controller检测node不健康,他就会向供应商询问节点虚拟机是否可用,如果不可应就从列表剔除。
第三个是监控节点的健康状态,当node controller检测node不可达时,负责将node状态中的not ready condition 跟新到 condition unknown, 然后将node上所有的pod删除,(默认不可达超过40S就会标记成condition unkunown,此时并没有发生删除pod的操作,系统会尝试重新联系node,如果恢复就被标记为node ready. 如果不可达超过5分钟,就会采取删除pod的操作)
每隔多少秒去检测一次节点的状态是: --node-monitor-period
node controller 源码中,monitor node health 是定时更新node的信息:
获取所有的node信息,按照哪些是新增的,哪些是需要删除的,以及哪些是需要重新规划的返回节点相应的信息
对新增node,删除node以及待规划的node做对应的处理
遍历所有node,更新node状态,调用tryupdatenodehealth方法
而kubelet运行在node上,维持运行中的pods以及k8s运行的环境,主要完成以下使命:
-
监视分配给node的节点pods
-
挂载pod所需要的volumes
-
下载pod的secret
-
通过docker来运行pod中的容器9. 周期的执行pod中为容器定义的liveness探针
-
上报pod的状态给系统的其他组件
-
上报node的状态
14.职场情商题
1、如果你维护的甲方的购物平台的支付系统突然全部宕机,客户情绪十分不好,你该如何与客户沟通,如何解决该问题?
主观题,主要体现自己对故障的积极修复、处理,还要舔客户
2、客户有一个新项目需要100台1:8配置的云服务器,但是阿里云产品中没有1:8的只有1:10的,所以客户说如果不给他1:8的云服务器就要使用华为云或者腾讯云,但是负责云服务器的负责人说单独为该客户创建100台1:8的服务器会亏本,你该如何与客户、负责人沟通进行调节?
主观题,在客户坚持的情况下为了不流失客户,主要逼负责人满足客户要求。
15.php进程占用内存太多,怎么办?
首先需要查看你的程序是否分配了过多的内存,在程序没有问题的情况下,你可以增加PHP的内存限制(memory_limit)。.检查php的内存限制值,查看这个值,你需要建立一个空的php文件,比如view-php-info.php。. 然后将一下代码贴到里面。将这个脚本放到你的Web服务器上,然后在浏览器中调用它。这时你可以看到你的PHP环境配置的信息,其中有一部分是关于“memory_limit”。
memory_limit应该设为多少?如何设置memory_limit?
这个完全依赖于你的应用的要求。比如Wordpress,运行起核心代码需要32MB。如果你又安装不少的插件(plugins),尤其是那些要进行图像处理的模块,那么你可能需要128MB或更高的内存。
设置memory_limit常用的方法是修改php.ini,首先找到对你的网站生效的php.ini文件,有多个地方都可以设置php的参数,首先找到正确的配置文件上面的方法建立的php文件可以查看其配置参数,找到 “Loaded Configuration File” 这一项,Linux可以执行“php -i | grep Loaded Configuration File”来找到对应的配置文件。
编辑php.ini 在php.ini中,找到“memory_limit”这一项,如果没有,你可以在文件的尾部自己增加这个参数。
memory_limit = 128M ; 可以将128M改为任何你想设置的值保存文件
然后重启web服务器。
16.IDC迁移上云该怎么做?
整理机房所有服务资料,与开发人员确认一些服务的存放以及配置。
在阿里云上搭建一套新的服务。
服务搭建完成后开始进行数据迁移,先预迁移一批整体数据,后续增量同步。
云上服务测试(这里我使用了测试域名,然后由测试人员和研发人员进行新环境可用性测试)。
确认无误后进行整体迁移,为了避开业务高峰我们在晚上进行迁移。
补充后续脚本和配置项(这里基本上就已经迁移完成了)。
17.把原来的LNMP架构迁移到在阿里云上,Mysql有上T的数据,该怎么做?
通过规划表格以及文档,将阿里云上网络架构构建好后去修改对于机器配置的ip,然后优化linux系统,部署服务,配置slb,对公司以前架构内的老服务进行版本升级,优化。
服务搭建完成后开始进行数据迁移,先预迁移一批整体数据,后续增量同步
一般服务的数据迁移其中有的数据需要迁有的不用,rabbitmq这些就不用Redis数据直接rsync –agopz 同步/data目录下的rdb文件和/etc下的配置文件即可,其他服务一般都是导配置,代码方面提前弄一个分支或者新project,包括nginx等都是,用来适配云上,这里我们比较多的是gfs的数据,两个gfs1.5个T,我直接在idc机房弄出一台新机器,挂载目录后rsync同步到云上gfs(有公网ip),先做一次全量,后面每3天做一次增量,保证数据不会丢失太多。
Mysql的数据迁移,直接rsync同步整个数据库目录是不可取的,如果mysql不停则拷贝过去的数据直接不可用,而且innodb引擎不支持直接拷贝。如果你想进行不停机迁移,那么最好的方案是用innobackupex热备mysql一个实例的库,然后rsync到云上进行恢复,再接入idc主从,云上当从,实时同步,当然想法是很好的,你接入主从可能直接就会报错因为主从数据不同步,执行的某些操作从库没有这些数据,比较好的解决办法,就是执行备份脚本前,去实例里执行 show master status,记录当前binlog和pos存到文件,在云上还原接入主从的时候,将记录的binlog和pos填入主从配置并启动从,这时候查看从状态 show slave status 可能仍会有报错,不用担心,一般这时候的错都是 error 1062 1032,这个错的意思是从库重复执行了事务和更改的数据不存在,因为我们记录的点可能过早出现的,不用担心在my.cnf配置文件里加入 slave-skip-errors=1062,1032跳过该类型错误即可解决,自此数据同步成功,innobackupex还原的时候先使用参数 –defaults-file=./my.cnf --apply-log 否则直接还原接入主从后可能会出现mysql无线重启的bug,这个bug也可能是innodb引擎损坏,推荐新建库,然后在原机房的实例上用mysqldump导出了关于使用了tokudb引擎的,
如果使用这个还原仍出现找不到数据文件,仍然推荐mysqldump,虽然慢,但是导出的数据是完全没问题的。
18.如何将阿里云账号A的OSS存储数据迁移到账号B上?
使用阿里云在线迁移服务。
19.Elasticsearch索引分片的概念有没有了解?
因为ES是个分布式的搜索引擎, 所以索引通常都会分解成不同部分, 而这些分布在不同节点的数据就是分片. ES自动管理和组织分片, 并在必要的时候对分片数据进行再平衡分配, 所以用户基本上不用担心分片的处理细节,一个分片默认最大文档数量是20亿。
每个分片本质上就是一个Lucene索引, 因此会消耗相应的文件句柄, 内存和CPU资源。
每个搜索请求会调度到索引的每个分片中. 如果分片分散在不同的节点倒是问题不太. 但当分片开始竞争相同的硬件资源时, 性能便会逐步下降。
ES使用词频统计来计算相关性,当然这些统计也会分配到各个分片上. 如果在大量分片上只维护了很少的数据, 则将导致最终的文档相关性较差。
对大数据集, 我们非常鼓励你为索引多分配些分片–当然也要在合理范围内. 上面讲到的每个分片最好不超过30GB的原则依然使用
不过, 你最好还是能描述出每个节点上只放一个索引分片的必要性. 在开始阶段, 一个好的方案是根据你的节点数量按照1.5~3倍的原则来创建分片,如果你有3个节点, 则推荐你创建的分片数最多不超过9(3x3)个
*ES的默认配置(5个分片)*