Pytorch vgg16 实现CIFAR10数据集分类 以及RuntimeError: mat1 and mat2 shapes cannot be multiplied终极详解
最近从tensorflow转战pytorch,今天又遇到了了一个大坑:RuntimeError: mat1 and mat2 shapes cannot be multiplied,网上的结果大都模模糊糊模棱两可,我在认真分析网络结构的实现模式以后终于弄懂了这个问题。
这次采用的数据集是CIFAR10,大概130M。有50000张训练图以及10000张测试图、每张图尺寸32*32,所有图分为十类,非常适合作为分类目标的数据集。
文章目录
- 1. 导入CIFAR10数据集
- 2.理解图像尺寸与VGG16网络结构的关系
-
-
-
- 终极详解:RuntimeError: mat1 and mat2 shapes cannot be multiplied 问题
-
-
- 3.训练过程
-
-
-
- 训练结果
-
-
1. 导入CIFAR10数据集
注意我这里batch_size设为1,下面要用
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torch import nn,optim,device
from torch.utils.tensorboard import SummaryWriter
device=device("cuda")
train_transform = transforms.Compose([
transforms.ToTensor(),
# 归一化
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
valid_transform=transforms.Compose([
transforms.ToTensor(),
# 归一化
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
train_dataset =torchvision.datasets.CIFAR10(root=r'D:\AAA\PYTHON\pythonproject\jupyter\data\CIFAR10',train=True,transform=train_transform,download=False)
valid_dataset =torchvision.datasets.CIFAR10(root=r'D:\AAA\PYTHON\pythonproject\jupyter\data\CIFAR10',train=False,transform=valid_transform,download=False)
batch_size=1
train_loader =DataLoader(train_dataset,batch_size=batch_size, shuffle=True,num_workers=0)
valid_loader =DataLoader(valid_dataset,batch_size=batch_size, shuffle=True,num_workers=0)
print('train_dataset',len(train_dataset)) #50000
print('valid_dataset',len(valid_dataset)) #10000
2.理解图像尺寸与VGG16网络结构的关系
首先,这个问题是出现在模型对象输入时候的,原因是模型在进入全连接层时候的一对tensor的shape不能够相乘,要解决这个问题就必须搞清楚输入图像尺寸在网络结构里每一层的输入输出细节,还是从这两张最经典的vgg16图解说起:
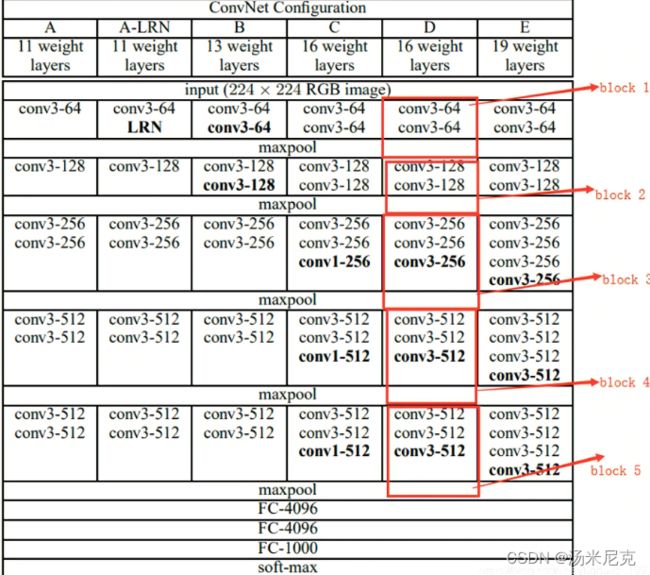
图一的D列的每一行描述了我们要用的vgg16每一层的卷积核尺寸以及输出通道,例如conv3-64就是这一层卷积的卷积核尺寸是(3*3),输出通道数是64
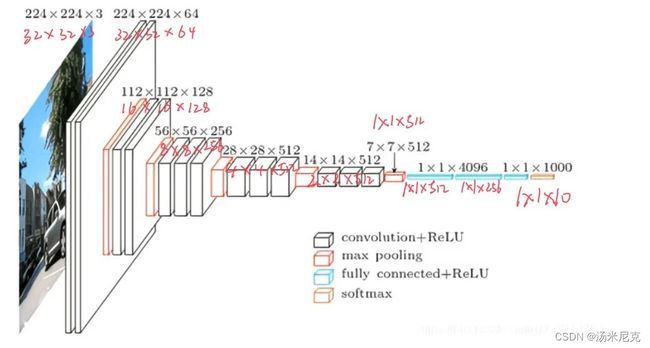
图二描述了默认情况下以224 X 224为尺寸的图形传入图像的vgg16每层操作的输出尺寸以及通道数,例如112 X 112 X 128,此层的输出尺寸是112 X 112,输出通道数是128。我们的32 X 32尺寸的数据集的过程是图二中用红笔批注的那些,注意当图像进入池化层时tensor尺寸已经被卷积为1 X 1了,相当于没有池化,所以别的博主可能会省略不写。
综上,我们可以把vgg16手动搭建出来:
from torch import nn
class vgg16_net(nn.Module):
def __init__(self):
super(vgg16_net,self).__init__()
# 卷积层
self.features=nn.Sequential(
# block1
nn.Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False),
# block2
nn.Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False),
# block3
nn.Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False),
# block4
nn.Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False),
# block5
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
# 平均池化
self.avgpool=nn.AdaptiveAvgPool2d(output_size=(1, 1))
# 全连接层
self.classifier=nn.Sequential(
nn.Linear(in_features=1*1*512, out_features=512, bias=True),
nn.ReLU(inplace=True),
nn.Dropout(p=0.4, inplace=False),
nn.Linear(in_features=512, out_features=256, bias=True),
nn.ReLU(inplace=True),
nn.Dropout(p=0.4, inplace=False),
nn.Linear(in_features=256, out_features=10, bias=True)
)
def forward(self,input):
input=self.features(input)
input=self.avgpool(input)
# input=input.view(-1,512)
input=self.classifier(input)
return input
model=vgg16_net()
model=model.to(device) #调用GPU
print(model)
此时的模型结构为:
vgg16_net(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(classifier): Sequential(
(0): Linear(in_features=512, out_features=512, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.4, inplace=False)
(3): Linear(in_features=512, out_features=256, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.4, inplace=False)
(6): Linear(in_features=256, out_features=10, bias=True)
)
)
终极详解:RuntimeError: mat1 and mat2 shapes cannot be multiplied 问题
添加一小个测试板块看看
from torch import ones
input=ones((batch_size,3,32,32))
input=input.to(device) #调用GPU
output=model(input)
报错:
![]()
我尝试了很多数据终于找到了这个(512 X 1 and 512 X 512)的组成规律:
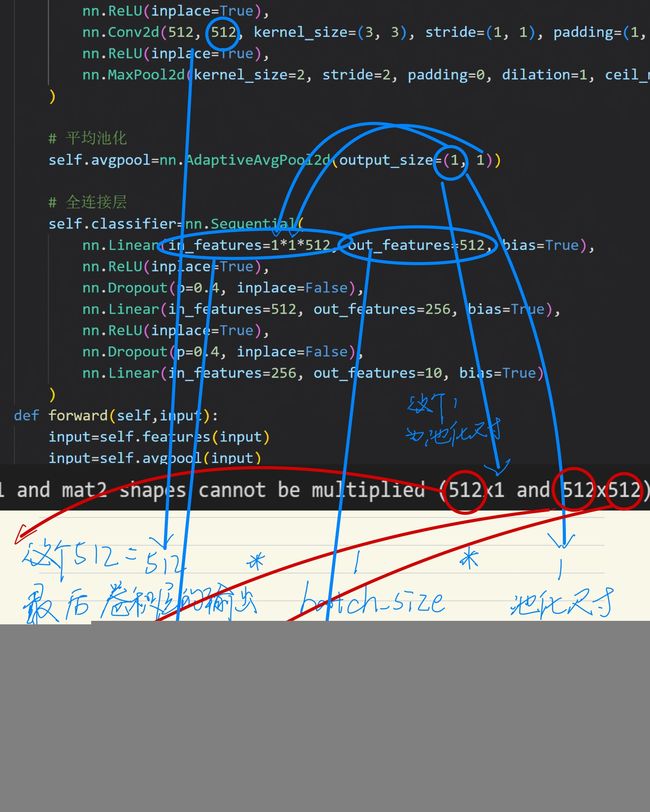
相当于
and左边=(卷积层最后的输出通道数*batch_size*池化尺寸 X 池化尺寸)
and右边=(第一个全连接层的输入尺寸 X 第一个全连接层的输出尺寸)
其中
batch_size就是操作数据集DataLoader时候的自定义的batch_size,我的值为1
第一个全连接层的输入尺寸=池化尺寸*池化尺寸*卷积层最后的输出通道数
定睛一看会发现,and左右两边构成的等式,至少要满足池化尺寸==第一个全连接层的输入尺寸才能相乘,而这两个值没有逻辑关系。再定睛一看,又发现等式两边只有batch_size是自定义的,其他值都是网络结构固定的可以视为常数,所以我们只用把and左边的式子全部展开,然后把batch_size放在X的左边,把池化尺寸*池化尺寸*卷积层最后的输出通道数放在X的右边,这样不就满足前行乘后列永远是恒等的常数相乘了。此时
and左边=(batch_size X 池化尺寸*池化尺寸*卷积层最后的输出通道数)
and右边=(池化尺寸*池化尺寸*卷积层最后的输出通道数 X 第一个全连接层的输出尺寸)
就解决问题了
代码中,在forward方法里,在avgpool平均池化模块之后,在全连接classifier模块之前添上
input=input.view(-1,512)
在我的代码中,只用把那句注释取消了就行。
详解一下view函数:-1为计算后的自动填充值,在上面的分析中知道,这个值就是batch_size,而512是网络模型的常数值,所以换成这样也是对的:
input=input.view(batch_size,512)
3.训练过程
训练过程并未优化,但总体框架大至如此
import time
import torch
# 损失函数
loss_fn=nn.CrossEntropyLoss()
# 优化器
lr=0.01
#每n次epoch更新一次学习率
step_size=2
# momentum(float)-动量因子
optimizer=optim.SGD(model.parameters(),lr=lr,momentum=0.8,weight_decay=0.001)
schedule=optim.lr_scheduler.StepLR(optimizer,step_size=step_size,gamma=0.5,last_epoch=-1)
train_step=0
vali_step=0
writer=SummaryWriter('./logs')
epoch=5
for i in range(1,epoch+1):
starttime=time.time()
train_acc=0
# -----------------------------训练过程------------------------------
for data in train_loader:
img,tar=data
img=img.to(device)
tar=tar.to(device)
outputs=model(img)
train_loss=loss_fn(outputs,tar)
# print(outputs.argmax(1),tar)
train_acc+=sum(outputs.argmax(1)==tar)/batch_size
# 优化器优化模型
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
train_step+=1
if train_step%5000==0:
print("train_step",train_step)
vali_loss=0
vali_acc=0
# -----------------------------验证过程------------------------------
with torch.no_grad():
for vali_data in valid_loader:
img,tar=vali_data
img=img.to(device)
tar=tar.to(device)
outputs=model(img)
vali_loss+=loss_fn(outputs,tar)
vali_acc+=sum(outputs.argmax(1)==tar)/batch_size
vali_step+=1
if vali_step%2000==0:
print("vali_step",vali_step)
endtime=time.time()
spendtime=endtime-starttime
ave_train_acc=train_acc/(len(train_loader))
ave_vali_loss=vali_loss/(len(valid_loader))
ave_vali_acc=vali_acc/(len(valid_loader))
# 训练次数:每一个epoch就是所有train的图跑一遍:1968*3/batch_size,每次batch_size张图
print("Epoch {}/{} : train_step={}, vali_step={}, spendtime={}s".format(i,epoch,train_step,vali_step,spendtime))
print("ave_train_acc={}, ave_vali_acc={}".format(ave_train_acc,ave_vali_acc))
print("train_loss={}, ave_vali_loss={} \n".format(train_loss,ave_vali_loss))
# tensorboard --logdir=logs
with SummaryWriter('./logs/ave_train_acc') as writer:
writer.add_scalar('Acc', ave_train_acc, i)
with SummaryWriter('./logs/ave_vali_acc') as writer:
writer.add_scalar('Acc', ave_vali_acc, i)
with SummaryWriter('./logs/train_loss') as writer:
writer.add_scalar('Loss', train_loss, i)
with SummaryWriter('./logs/ave_vali_loss') as writer:
writer.add_scalar('Loss', ave_vali_loss, i)
writer.close()
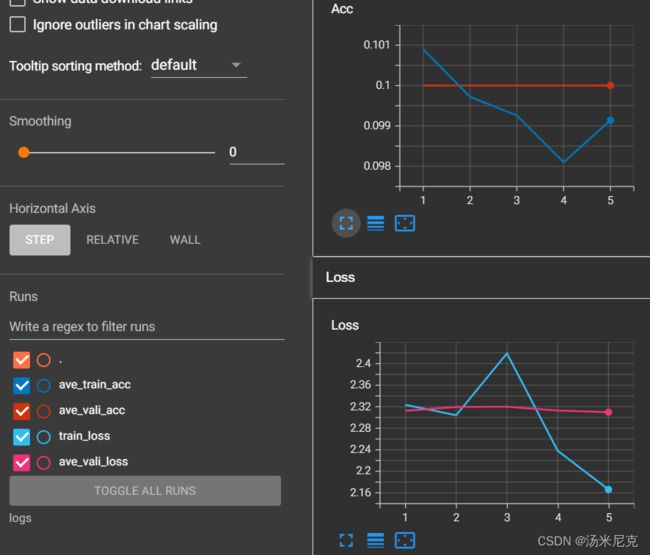
训练结果
训练结果还是很拉的,等优化好了再更新