【网络基础】通俗易懂的搞明白什么是IP地址(小白向)
目录
- 前言
- IP协议
- IP地址
-
- 查看IP地址的方法
- 公有IP地址与私有IP地址
- IP地址的分类
-
- 网络路由传输流程简化版
- IP地址过去的分类
- 过去分类带来的问题
前言
由于博主是一个刚转行没多久的前端,所以本次的文章也是面向像我一样的小白。内容均为个人在网络上搜罗知识点并梳理而来,尽量用浅显易懂的方式讲解,不会讲的很细致,会不定期的“修缮”文章内容,也欢迎大家指出错误和补充。
v-1.1版本
IP协议
在了解什么是IP地址之前首先要知道什么是IP协议。它是“网络之间互联的协议”。我们就可以浅显的理解为一套规则,设备必须遵循这套规则才能实现网络的连接。
IP地址
那么在设备遵循IP协议下,必须拥有一个地址来表示自己在哪里,这样你向网络发送信息的时候,网络会知道是你发出的,然后别人给你发送信息时,网络也能知道是发送给你的。
IP地址的表示是一个32位的二进制数(本次文章我们先只讨论IPv4的地址),例如:
01110000 01010111 01000001 00111100
但我们通常看到的都是转换成十进制的样子,并且每8位转换后都带个”.”来分组,比如例子中转换成十进制位为:
01110000.01010111.01000001.00111100
// 转换
112.87.65.60
查看IP地址的方法
我们想查看自己电脑的IP地址可以通过几种方式
第一种方法
win+R键,输入ipconfig指令。或则在powershell中输入也可以。
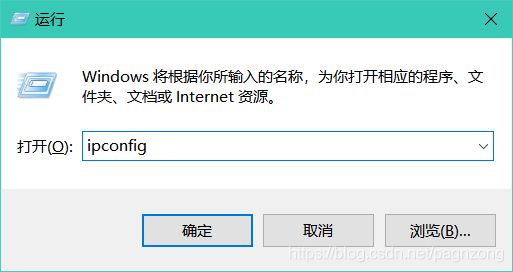
然后弹出

红色圈起的就是本机的IP地址
第二种方法
对你的网络图标右键
找到“网路和共享中心”,打开

点击你连接的网络
点击“详情信息”

第三种方法
直接百度搜索“IP”

但我们能够发现一个问题,为啥百度出来的IP地址和我们自己本机查看的不一样呢?
本机为:
172.20.10.4
百度的结果为
112.97.61.59
这就要说一下公有IP地址和私有IP地址了
公有IP地址与私有IP地址
首先我们前面知道,IP地址是由32位二进制组成,那么就会有2的32次方的地址总数可使用,也就是4 294 967 296个。但是有一部分的地址是有其他用途的(以后会讲到),所以能用的打了折。
我们可以简单想下假设全球76亿人口,每个人都有一部手机上网连接,前面我们提到,设备要联网必须遵循IP协议规则,就需要有IP地址,那么每部手机都会有一个独一无二的IP地址,你会发现IP地址的数量根本不够用啊,更别说还有电脑等终端设备没算进去。所以要想想办法怎么才能保证地球上的每一台终端设备连入互联网。
如果一层楼,或者一栋楼,一个区域共享一个IP地址,这样是不是就能大大的缓解数量上的问题。但如果一个区域的人都使用同一个IP地址,那么怎么知道具体是谁向互联网发出信息,互联网怎么知道要把信息发送给这个区域里具体的哪个人。比如你的快递收货地址只填写广东省深圳市福田区,快递小哥怎么给你送,快递都给你扬咯。
所以,拥有这个IP地址的区域可以私自搞个内部管理,比如深圳市光明小区拥有一个IP,然后可以给小区内的每户人家分配一个私有的IP,这个IP就像每户人家的具体地址一样,比如“A幢7楼701房”。然后隔壁一个拥有IP地址的黑暗小区也给每户人家分配一个私有IP,也会有“A幢7楼701房”的地址。
小区的人快递收货地址就可以写上
“广东省深圳市福田区XX街道光明小区 A幢7楼701房”
快递小哥就会把快递送往光明小区,小区的快递站有贴心服务根据“A幢7楼701房”把快递送到你手上。小区的地址就相当于公有的IP,具有发送和接收快递具体地址的标识,而“A幢7楼701房”就相当于私有的IP,小区对你负责,你的快递发送和接收都要靠小区的地址。
所以,百度上搜到的IP地址是你的公有IP,而你在设备上查到的就是私有IP。那么一个收发地址大概就可以意会成
广东省深圳市福田区XX街道光明小区 A幢7楼701房
112.97.61.59 172.20.10.4
是不是就一下子明白了哈,公有IP是唯一的,但私有IP就可以不唯一,比如你也许和隔壁小区的朋友拥有一个一样的私有IP,例如“192.168.1.4”。
懂了什么是公有IP和私有IP,可以知道能连上网的只有公有IP,私有是不行的,必须借助上面的公有IP。
IP地址的分类
在了解IP地址的分类之前,我们需要先知道一个网络请求是怎么传达到目的地的,方便我们对IP地址的分类有更好的理解。
网络路由传输流程简化版
还是寄收快递的例子,这次,我们寄出的收货地址是同城不同区的。
寄:“广东省深圳市福田区XX街道光明小区 A幢7楼701房”
收:“广东省深圳市南山区XX街道奥特曼小区 A幢2楼201房”
当我们从光明小区快递站寄出快递后,一路先到达福田区的快递分站,快递分站查了查福田区的可送达地址列表,发现没有对应的地址,然后再向上面的深圳市快递总站发送快递。深圳市总站收到快递后也查了查深圳市可送达的地址列表,芜湖,发现居然就在下面的南山区,往下面的南山区快递分站发送快递,分站收到后再根据可送达地址列表以此类推的往下发送快递,最终送到收货人的手上。
在这个快递发送和接收的过程,就是一个非常简化的网络信息传输流程。其中快递分站和总站就代表着有层级关系的路由器,而每个站对应的“可送达地址列表”就是路由表。也就是说一个路由器中的路由表会存放下面路由器的公有IP地址,信息的传输过程就是向上层路由发送,上层路由通过找表的形式来看看目标IP地址是否在自己的下层,不在的话再向上层路由发送,每个路由器都有一个公有IP地址。
IP地址过去的分类
在很久之前,人们想到,如果路由器中的路由表存放的是全球所有IP的地址,那每次信息经过路由器的时候有多难找表啊,效率太低下,搭建互联网的成本也增高。不如把所有的IP地址做分类,就像把一个国家分成很多个省市区一样,每个快递站对应管理它下面的可送达地址即可。于是,IP地址的分类就出来了。
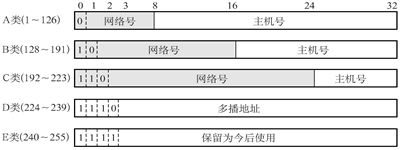
我们可以看到一个IP地址被分为网络号和主机号,然后又根据网络号的占位数来区分A-C类,为啥要这样分?拿A类地址举例。
一个A类地址,前8位是网络号,后26位为主机号。网络号还规定第一位必定是0,也就是网络号的范围为:
0000 0000-0111 1111 转成十进制为 0-127
但因为00000000和后面的主机号组成的是网络地址,01111111和后面的主机号组成的是广播地址,所以除去这两个一头一尾,网络号的范围就为 1-126 。(ps:1是给网关的比如路由器)
也就是A类的IP会长这样:1-126.xxx.xxx.xxx,然后每个网络号下的主机号有16,000,000个组合。例如126.12.3.1这个地址,被分类成了全球IP地址下的A类下的126网络号下的主机号为12.3.1的IP地址。B,C类同理。
在图表中我们可以看到,A类第一位被强制为0,B类前两位被强制为10,C类被强制为110,博主个人认为这样的强制是能让人快速的知道一个IP地址属于哪类。你看,由于被强制,所以每一类的地址前八位被划分了范围:
- A类:1-126
- B类:128-191
- C类:192-233
- …
所以,我们只需要通过IP地址的第一组数值就能快速的判断是属于哪一类,然后就可以知道前多少位是网络号,后多少位是主机号。
IP地址有了分类以后,路由器的路由表就可以做的很小了。
过去分类带来的问题
通过A-C类分的网络号和主机号的占比我们可以知道,A类的网络号很少,但主机号巨多,适合给超级大型公司或者超大政府等机构,因为数量少,但是内部设备很多。给一个完整的A类IP地址,一个机构就能有16,000,000个IP地址,其实很浪费,因为用不完。
B类就给一些较大公司政府之类的,自然数量会比需要A类的机构多,网络号能提供16,384个,每个网络号下的主机号也有65,534多个,也挺浪费的。
C类就是给数量最多的小体量组织或机构等使用啦。
这个把IP地址分成A-E类划分网络号和主机号的规则是在过去的时候,人们认为未来的终端设备不会超过IP总数量的背景下诞生的,如今我们也马后炮的知道这样的想法too young, sometimes naive! 本身分为A-E类没什么问题,但网络号和主机号的划分显然不符合当代的需求。
既然原来的划分方式既浪费又不够用,那就采用新的划分方式吧,于是后来就有了子网掩码这个东西。
下期讲解子网掩码~